基于端到端句子級別的中文唇語識別研究*
2020-09-23 07:32:10張曉冰龔海剛戴錫笠
軟件學報 2020年6期
關鍵詞:模型
張曉冰, 龔海剛, 楊 帆, 戴錫笠
(電子科技大學 計算機科學與工程學院,四川 成都 611731)
唇語識別主要通過觀察說話者嘴唇的運動變化序列從而識別出相應的文本信息,其研究內容涉及到模式識別、圖像處理、語音識別及自然語言處理等多個領域,具有廣闊的應用場景.例如在高噪環境中,由于說話者音頻受到環境的干擾,導致識別率降低,而視覺信息相對很穩定,因此,通過唇語識別利用視覺信息從而能夠極大地輔助提高語音識別的準確率.在非噪聲環境下,當進行語音識別時,輔助觀察說話者的臉部表情變化、嘴唇運動以及人體肢體動作等信息,能夠更加準確地理解對方所要表達的內容.此外,嘴唇同虹膜、鼻子等一樣,作為人臉的一項重要生物特征,在人臉身份檢測中發揮了重要作用.例如在人臉活體檢測應用中,通過核查說話者嘴唇運動,可進一步提高活體識別的安全性,從而排除了傳統人臉識別中使用其他工具造假的可能.此外,唇語識別可與手語識別相互依存,一起促進聾啞人在日常生活中的正常交流.
目前為止,唇語識別研究已經取得了一定的成果.然而,由于日常應用場景及條件的多樣化和復雜化,使得唇語識別技術在實際應用中依然面臨巨大的挑戰:(1) 人的嘴唇是一個三維的非剛性物體,不同的說話者對象、不同的語句內容,都會使得人的嘴唇運動在視頻中顯示不同的變化,這給識別帶來了很大的困擾;(2) 光源照射和人臉角度的不同等因素,使得人的嘴唇在視頻中有不同的形態,從而對識別率造成很大的影響.
近幾年來,深度學習在各個領域取得的顯著成果,也促進了應用神經網絡來解決唇語識別的研究.隨著技術的成熟,唇語識別率也在不斷提高,例如DeepMind 的WLAS[1]和LipNet[2].然而,已有的這些研究都是基于單詞分類或者英文句子的識別,與中文唇語識別的內容截然不同.漢語與英語不同:英語是由26 個字母組成的字母語言,所有的單詞都是由字母拼讀而成,通過拼讀可以準確地確定某個單詞;而漢語不同,漢語的發音是由23 個元音字母和24 個輔音字母組成,去掉一些不可能的拼讀組合,再加上4 種不同的音調,拼音總共大約有1 000 種,然而漢語中的漢字總數超過90 000 個,其中有3 000 個是經常使用的,也就是說,每個拼音平均對應3~90 個漢字.據統計,漢語是信息熵含量最大的語言.因此,從漢語這種高模糊性語言中提取具有顯著區別的特征信息,是中文唇語識別中的一個重要并且富有挑戰性的任務.
本文根據中文的特點,首次提出了句子級別的中文唇語識別模型ChLipNet,該模型由兩個子模塊組成,即嘴唇圖片序列映射到拼音字符序列的拼音序列識別模塊和拼音字符序列轉換為漢字序列的漢字序列識別模塊,如圖1 所示.其中,
(1) 拼音序列識別主要利用卷積神經網絡Convolutional Neural Network(CNN)作為嘴唇圖片幀序列的特征提取器,然后,使用循環神經網絡Recurrent Neural Network(RNN)理解并分析提取的特征,最后利用Connectionist Temporal Classification(CTC)損失函數匹配輸入輸出序列.該過程簡稱為P2P 過程,生成的拼音序列識別網絡簡稱為P2P 網絡;
(2) 漢字序列識別是一個基于語言模型的Encoder-Decoder 網絡框架,這個過程簡稱為P2CC 過程.P2CC網絡的輸入是拼音字符序列,其中Encoder 網絡負責對拼音字符序列進行編碼,而Decoder 網絡則對Encoder 的輸出進行解碼,從而生成漢語句子.
當P2P 和P2CC 兩個子模塊分別訓練好后,把它們聯合在一起組成中文唇語識別網絡ChLipNet 并進行最終的端到端訓練.
由于現有的唇語數據集都是針對字符、單詞、數字或者短語的,且都是關于非中文的.為此,我們采集了6個月的CCTV 新聞聯播視頻及其對應的文稿,使用半自動化技術,通過視頻剪輯、文本和時間戳生成以及嘴唇檢測等操作生成包含14 975 條中文句子及其對應嘴唇序列的中文唇語數據集CCTVDS.此外,在漢字序列識別P2CC 的預訓練過程中,還額外統計了近30 個月的新聞聯播文稿內容作為輔助數據.
1 相關工作
Petajan 等人在1984 年最初提出了唇語識別系統[3],該系統把單個詞作為最小的識別單元,通過計算輸入的嘴唇圖片序列,得到能夠表示的特征向量,并與數據集中所有詞的特征模板進行相似度匹配,最后將相似度最高的詞作為預測結果并輸出.之后,在1988 年,Petajan 等人在原唇語識別系統上引入矢量化和動態時間規整等算法,主要用于解決訓練和識別過程中說話人語速變化較大的問題,從而對唇語識別系統進行改進[4],極大地提高了唇語識別的正確率.
近幾年也出現了很多嘗試用深度學習解決唇語識別的工作,例如:
1)Noda[5]利用VGGNet 對人嘴唇圖片進行單詞和短語的預訓練,然后通過RNN 網絡,可分別實現44.5%短語識別和56.0%單詞分類準確率;
2)Chung 等人提出了利用VGG 時空卷積神經網絡在BBCTV 數據集上進行單詞分類[6],并再次提出了一種用于學習嘴部特征的視聽最大邊緣匹配模型[7],并將其作為一個 LSTM 的輸入,從而用于OuluVS2 數據集上的10 個短語的分類;
3)Wand 等人[8]在2016 年將LSTM 遞歸神經網絡引入用于唇語識別的研究,雖然該研究沒有包含句子序列的預測和說話者的獨立性,但在GRID 語料庫上,模型識別講話人的準確率可達79.6%;
4)Chung 等人在2017 年提出由卷積神經網絡和循環神經網絡組成的WLAS 模型,其在含有1 萬條樣本句子的LRC 數據集上可取得46.8%的句子準確率,是目前句子級別的英語唇語識別中較好的成績.
2 漢語發音規則及中文特征
漢語是一種非形態語言.漢語中的詞語沒有嚴格意義的形態變化,只有音節符號.漢語中的音節是由聲母、韻母和聲調按照拼音規則組合而成,其中,聲母有23 個,韻母有24 個,另外還包括4 種聲調,見表1.因此,粗略計算得音節種類不超過2 208 個(包括不合理拼音).
自1955 年開始,漢語拼音被用作是輔助漢字發音的一種工具.它和英語的音標類似,但又大不相同.其中,聲母又叫做輔音字母,用在韻母之前,并跟韻母一起構成完整的音節.輔音的主要特點是發音時氣流在口腔中會受到各種不同的阻礙,因此可以說,聲母發音的過程也就是氣流受阻和克服阻礙的過程.除聲母、音調之外的部分,就是韻母,包括韻頭、韻腹和韻尾這3 部分.音節是人類聽覺系統能感受到的最小語音單位,在漢語中,單個漢字就是單個音節(但漢字不是音節文字).然而,在1994 年出版的《中華字海》中,約有87 019 個漢字(其中重復字320 個),因此漢字數量空間是遠遠大于音節數量空間的(最多2 208 維).單個漢字具有豐富的信息和意義,例如,“中”可解釋為“里面”,或者“適于”“合適”等含義.當漢字與漢字通過語言規則相互組合成詞、短語或者句子時,才有具體含義,例如“中間”“中計”等.如圖2 為“中國人”短語示例,其中,綠色框代表拼音序列,黃色框代表聲調,藍色虛線框代表單個漢字.
據統計,漢字中超過85%的是同音字,即:同一個發音(嘴型)可至少對應2 個,至多對應120 個漢字.這也是中文比其他語言更難識別的一個重要原因之一.如表2 所示為部分音節和對應的常見漢字,其中的數字表示該音節可對應不同漢字的總個數.
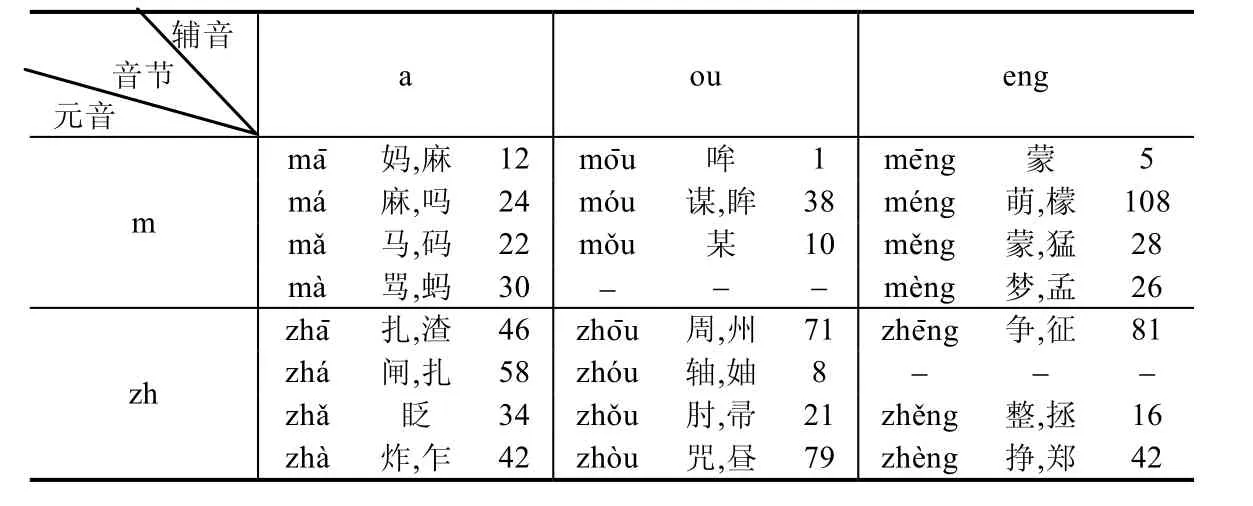
Table 2 List of syllables and the corresponding common Hanzi表2 音節及對應常見漢字示例
3 ChLipNet 整體框架
3.1 拼音序列識別模型(P2P)
與大多數圖像識別任務不同,拼音序列識別中需要網絡能夠捕捉圖像最細微的特征,尤其是嘴唇圖片間的運動變化.圖片到拼音的拼音序列識別P2P 模型的結構如圖3 所示.
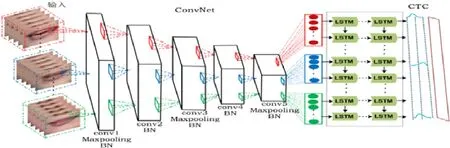
Fig.3 Model architecture of Pinyin-to-Hanzirecognition (P2P)圖3 圖片到拼音識別(P2P)網絡模型
在P2P 網絡模型中,嘴唇圖片先轉換成灰度圖,其中,每隔兩幀的連續5 張120×120 灰度圖片作為輸入,因此,若一個樣本有n張嘴唇圖片,則輸入長度為■(n-4)/2■,然后用卷積網絡ConvNet 提取圖像特征信息.假設P2P 模型的輸入為X=x1,x2,…,xk,其中,xi包含連續5 張嘴唇圖片序列,則ConvNet 將圖片序列按公式(1)轉換為特征向量:


其中,K是維度為d×512 的矩陣,d是LSTM 單元中embedding 空間的大小,b是維度為d的誤差參數.
最終,連續的特征向量vi序列作為n-LSTM 的輸入,通過n-LSTM 輸出一個維度為d′的向量vi′.在n-LSTM中,其LSTM 單元的運算過程見公式(3):
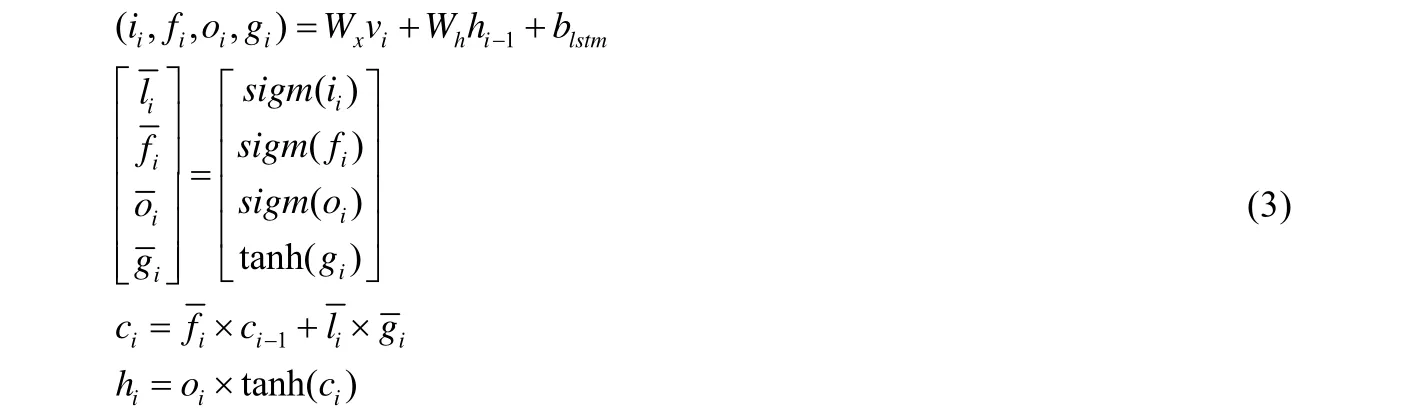
其中,blstm表示誤差參數矩陣,維度為4d′;Wx和Wh分別表示LSTM 單元中與輸入x和隱藏狀態h有關的參數矩陣,維度為4d×d′;表示在i時刻LSTM 單元輸入門的輸出;表示i時刻LSTM 單元遺忘門的輸出;表示在i時刻LSTM 單元的細胞更新信息;表示在i時刻LSTM 單元的細胞狀態;表示在i時刻LSTM 單元的隱藏狀態,同時也表示在i時刻LSTM 的輸出.最后,經過全連接網絡生成一個26 維的向量并傳遞給CTC 函數.整個P2P 模型的損失函數如公式(4):
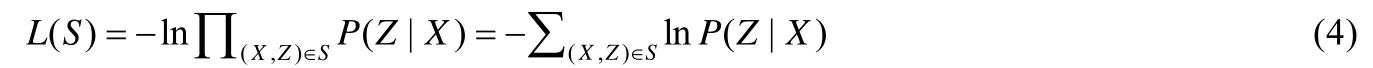
其中,S表示整個數據集,(X,Z)為數據樣本,Z為輸入圖片對應的真實拼音字符序列標簽,P(Z|X)為輸入X得到Z的概率模型.
3.1.1 Connectionist Temporal Classification (CTC)
CTC[9]是一種通用的損失函數,主要用于解決未知輸入序列和輸出序列對齊的網絡系統.由于CTC 損失函數比傳統的隱馬爾科夫模型等具有更好的性能,因此在P2P 模型中,本文我們采用CTC 損失函數來實現輸入圖片和輸出拼音序列的自動劃分與對齊.給定一個拼音序列的分布并且用空白字符進行增強,那么CTC 通過最大化所有與之等價的序列來定義生成該序列的可能性.假設拼音序列的標簽為表示空白字符增強后的拼音序列,其中,“-”表示空白字符.定義映射函數表示移除空白字符并且刪除相鄰相同的拼音字符,對于一個序列y∈L*,CTC 計算如下:
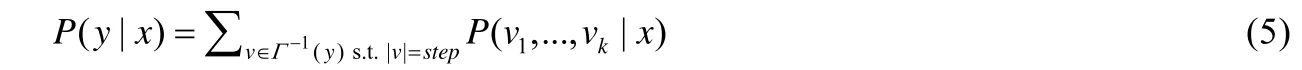
其中,step是序列模型中步長.例如,假設step=3,CTC 計算‘qi’的概率為:p(qqi)+p(qii)+p(-qi)+p(q-i)+(qi-).
3.2 漢字序列識別模型(P2CC)
3.2.1 P2CC 輔助數據
在P2CC 模型中,訓練數據為拼音字符序列和對應的漢字語句.在CCTVDS 數據集中,共有14 975 個樣本.為了克服漢語的語義模糊性,同時保證輔助數據跟原始樣本同源,從而減少冗余信息,加速模型的訓練,我們在CCTV 官網上額外下載了近30 個月的新聞文稿,并生成對應的拼音序列以對P2CC 進行預訓練.最后訓練中,刪除新增數據集中過短(字數少于4)和過長(字數大于25)的句子,得到的輔助數據共約304 223 條拼音漢字樣本.
3.2.2 Encoder-Decoder 模型
自從Bengio 提出使用神經網絡來訓練語言模型[10]后,越來越多的基于語言模型的網絡框架[11-13]被用來解決自然語言處理中的各種問題.其中,Encoder-Decoder 框架[14]被廣泛應用.
在一個Encoder-Decoder 框架中,Encoder 和Decoder 可選用循環神經網絡RNN(LSTM 或者GRU)的組合,如圖4 所示為LSTM 組成的Encoder-Decoder 模型示例.
在RNN 網絡中,t時刻的隱藏狀態是由上一個時刻t-1 的隱藏狀態和輸入數據Xt共同決定的,見公式(6):

在RNN 組成的Encoder 網絡中,實際上的語義編碼往往用最后時刻的隱藏狀態代替,見公式(7):

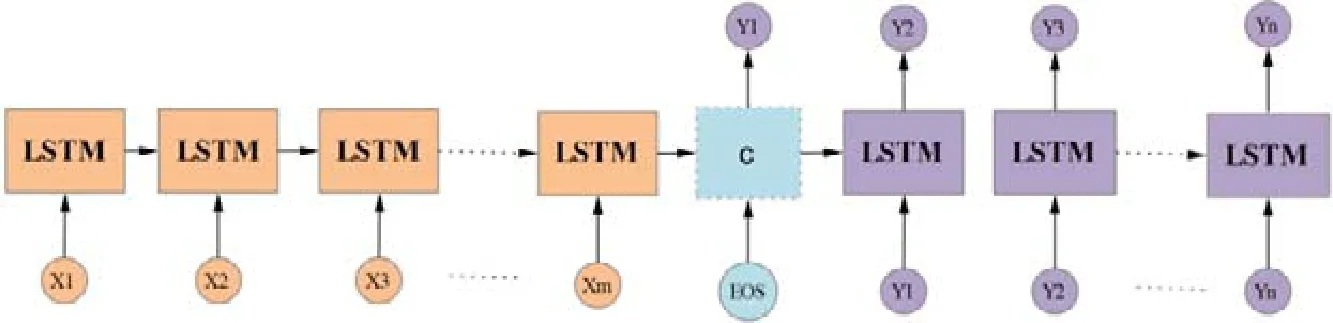
Fig.4 Example of Encoder-Decoder model composed of LSTM圖4 LSTM 組成的Encoder-Decoder 網絡示例
在圖4 中,若Encoder 的輸入是X={X1,X2,X3,…,Xm}序列,得到Encoder 的輸出為C=hm.Decoder 是通過當前已經輸出的序列Y1,Y2,…,Yt-1來預測當前Yt的輸出,那么Decoder 輸出序列為Y={Y1,Y2,Y3,…,Yn}的聯合概率見公式(8):
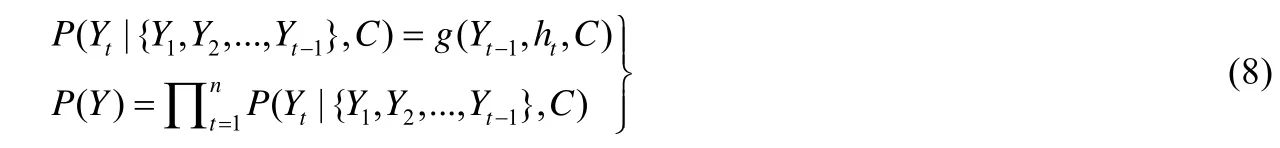
其中,g(·)是一種多層網絡函數,用于計算輸出Yt的概率,是一種非線性映射.
3.2.3 Sequence-to-sequence 模型
基于對語言模型框架Encoder-Decoder 的理解,我們構建了一個將發音(拼音)字符序列轉化為漢字序列的模型P2CC,如圖5 所示.
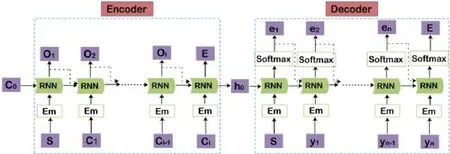
Fig.5 Model architecture of Pinyin-to-Hanzi recognition (P2CC)圖5 拼音到漢字識別(P2CC)網絡模型
在P2CC 模型中,每一個RNN 單元表示2 層GRU 單元連接(后面的實驗分析表明,2 個GRU 效果最好).在Encoder 模塊的訓練階段,輸入是拼音字符序列C=C1,C2,…,Cl,Ci表示拼音序列中第i個字母,為26 維的向量.Encoder 先將輸入序列通過Embedding(Em 單元)進行升維,然后輸入給RNN,最后,輸出序列為O=O1,O2,…,O.第i時刻的輸出向量Oi用于參數化下一個時刻輸入Ci+1的預測分布Pr(Ci+1|Oi).
Encoder 模塊的目標函數LEncoder(C)如下公式(9):
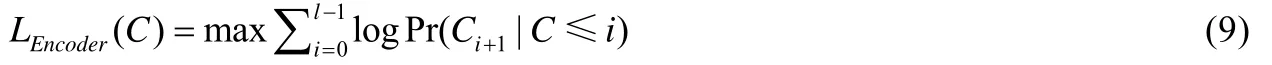
其中,C表示拼音語句序列的訓練數據.
在Decoder 模塊的訓練階段,輸入是漢字序列〈S,y1,y2,…,yn〉,yi表示輸入序列中第i個漢字,為M維的向量(M表示數據集CCTVDS 中漢字的數量).Decoder 先利用Embedding 對輸入序列進行升維,然后再傳遞給RNN,最后,通過softmax 非線性激活運算,輸出序列〈e1,e2,…,en,E〉.其中,S和E分別表示輸入開始標識和輸出結束標識.Decoder 模塊的目標函數LDecoder(Y)如公式(10):
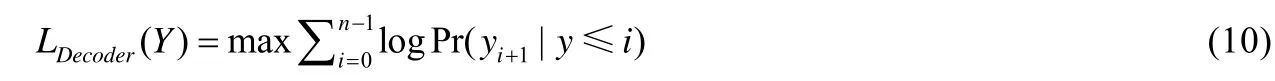
當Encoder 和Decoder 都訓練收斂之后,將Encoder 的輸出作為Decoder 的輸入,從而進行拼音到漢字模型的整體訓練.設定Fe(·)和Fd(·)分別表示已經預訓練好的Encoder 和Decoder 模型,則整個P2CC 模型的映射關系如公式(11)所示:
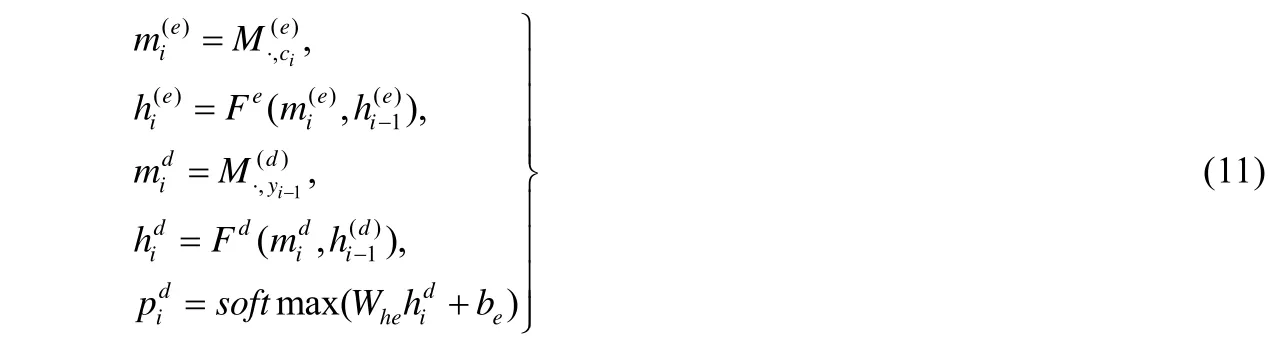
其中表示拼音序列C=C1,C2,…,Cl中第i個發音字符Ci對應的Embedding 向量,表示第i個發音字符Ci經過RNN 運算后的隱藏狀態.在訓練階段,yi-1表示真實的樣本標簽;在測試階段,則表示在i-1 時刻的預測值.
3.3 中文唇語識別整體網絡架構
通過對分別已經收斂的拼音序列識別模型P2P 和漢字序列識別模型P2CC 進行整體端到端的優化,從而構建中文唇語識別的整體架構ChLipNet.在ChLipNet 中,P2P 模型中的CTC 損失函數被移除,即P2P 產生的輸出序列直接依次作為P2CC 模塊的輸入序列.中文唇語識別整體網絡模型ChLipNet 如圖6 所示.
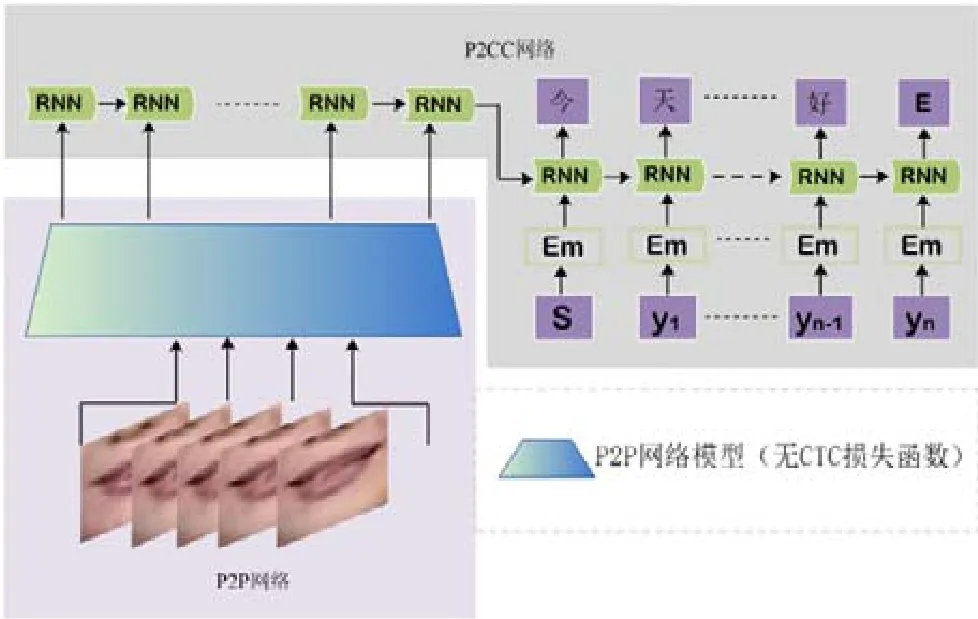
Fig.6 Chinese lip reading architecture of ChLipNet圖6 中文唇語識別模型ChLipNet
在ChLipNet 網絡中,輸入是一個句子對應的嘴唇圖片,相當于普通網絡的一個mini-batch 輸入.由于句子長度是可變的,所以ChLipNet 是一個動態的模型.
4 數據集
4.1 已有數據集介紹
目前,公開常用的唇語識別數據集有:
(1) AVLetter 英語數據集.該數據集由5 男5 女錄制而成,語料為26 個字母.每個人要求對每個字母讀3遍,共計78 個樣本;
(2) AVLetters2 英語數據集.該數據庫是對上述AVLetter 的擴展,由5 個人錄制,每人對26 個字母重復讀7遍,共計182 個樣本;
(3) OuluVS1 數據集.本數據集包含了10 個日常簡單的單詞或者短語,由20 個人錄制而成,且每人要求對每一個短語重復5 次;
(4) MIRACL-VC1 數據集.該數據集中的語料為10 個單詞和10 個短語,每個人對每個單詞和短語重復10遍,最終獲得3 000 個樣本;
(5) GRID 數據集.該數據集是由給定單詞根據固定格式組成的“句子”,例如“Place red at J 2,Please”,第1個單詞為動詞,第2 個單詞為顏色詞,然后依次分別為介詞、字母、數字等,且每個單詞有可選的固定候選集,所以這種固定形式構成的數據集從實際意義來說并不是基于“句子”級別的,樣本總共大約有9 000 個;
(6) BBCTV 數據集.該數據集收集了從2010 年~2016 年期間約6 年的BBC 視頻,涉及到新聞和討論內容,約有118 116 個句子,共17 428 個單詞.
4.2 自建唇語數據集CCTVDS
CCTVDS 來源于CCTV 官網上2016 年4 月~10 月連續6 個月的新聞聯播視頻,通過對視頻進行半自動化處理,最終生成形如(嘴唇圖片序列,中文語句)的數據集.其中,嘴唇圖片大小為120×120.
如圖7 所示為CCTVDS 數據集中“今天”字段的連續嘴唇圖片.

Fig.7 Continuous lip pictures of “today” in CCTVDS dataset圖7 CCTVDS 數據集中“今天”字段的連續嘴唇圖片
下面詳細介紹CCTVDS 數據集的生成過程,具體流程如圖8 所示.
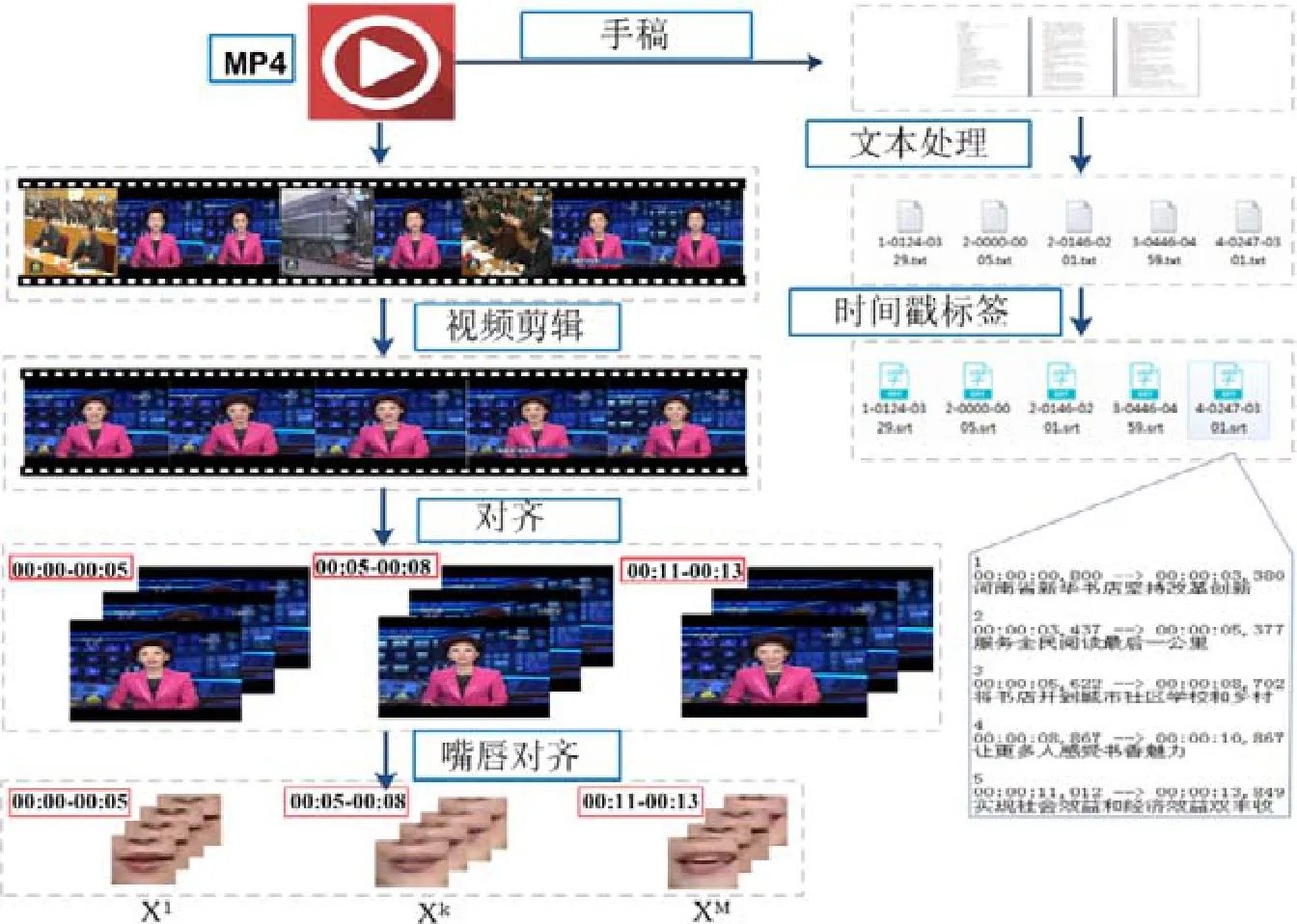
Fig.8 Semi-automatic generation process of CCTVDS dataset圖8 CCTVDS 數據集的半自動生成過程
4.2.1 視頻剪輯
在鏡頭檢測模塊,采用圖像的全局直方圖來判斷CCTV 視頻中鏡頭在主播單獨說話和其他場景之間的切換,得到粗略的單人主播視頻片段.全局直方圖通過統計幀內所有像素點在各個顏色(灰度)等級的個數,按照公式(12)計算出兩幀間的差異值:

其中,Hi(j)表示的是第i幀內等級為j的直方圖的值,M是直方圖的總等級數.然后,再通過人工二次檢驗核查視頻片段的正確性,生成合理可用的視頻片段;同時,以25fps 的頻率將視頻轉換為連續的幀圖片,生成包含有人臉的初始樣本集.
4.2.2 文本處理和時間戳標記
文本處理主要由人工完成,在保證語句含義合理的前提下,以每行不超過18 個字的標準規范文本格式.通過OksrtClient 實現視頻和文本語句的自動對齊,同時可獲得視頻片段中每句話的起始和結束時間戳.根據時間戳和圖片的保存頻率可將每句話的對應幀圖片自動查找出來.
4.2.3 嘴唇檢測與分割
1) 人臉檢測
在嘴唇檢測前,首先對圖片進行人臉檢測.在所裁剪的圖片數據中,均是包含正面角度的人臉,且無顯著的光照影響,因此采用經典的人臉檢測算法——Viola-Jones 檢測器進行檢測便可滿足需求.該算法在圖像矩形區域進行像素處理時,使用積分圖方法加速Haar-like 特征的計算,再在整張圖片上通過滑動窗口提取類Haar 特征,并以此通過多個級聯弱分類器進行判斷.當所有的分類器判定均為正樣本時,才把該窗口確定為人臉圖片.
2) 嘴唇定位與分割
人臉檢測之后,再次用相同算法對人眼睛進行定位,根據人臉的空間幾何特征,實現對單張圖像中人嘴唇區域的首次定位.然后,根據同一系列的人臉圖像嘴唇區域位置信息,利用最小二乘法對圖像幀序列中的嘴唇位置進行二次定位,最終將圖片裁剪成120×120 大小的嘴唇區域.如圖9 所示為利用人臉空間幾何特征定位嘴唇.
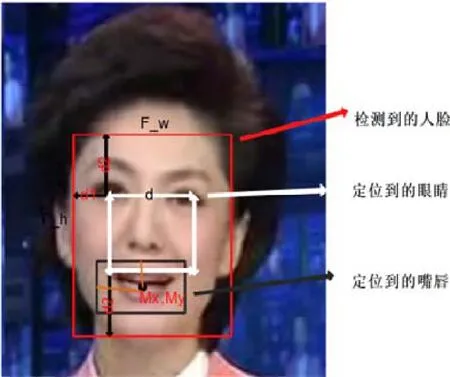
Fig.9 Locate the lips according to the geometric features of face space圖9 根據人臉空間幾何特征定位嘴唇
其中,d表示眼睛間距,d1=0.4d,d2=0.7d,F_h=2.4d,F_w=1.8d.嘴唇中點坐標為(Mx,My),其中,Mx=0.5F_w=0.8F_h,嘴唇寬和高分別為0.3F_w和0.67F_h.
4.3 CCTVDS數據集統計
在CCTVDS 數據集中,每個樣本句子對應的嘴唇圖片序列長度范圍為10~196,平均包含了2~25 個漢字,樣本數量共計14 975 個,且樣本標簽中共計2 972 355 個漢字.CCTVDS 具體統計見表3,訓練集、測試集和驗證集按照7:2:1 進行劃分.
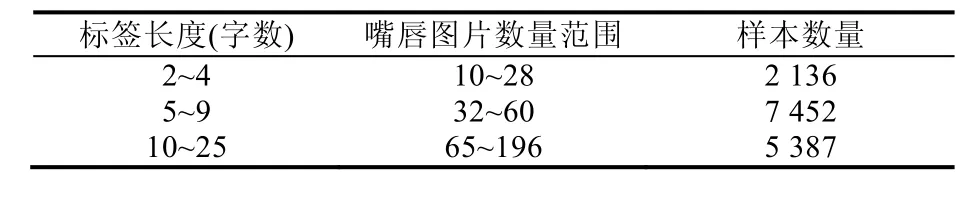
Table 3 Sample statistics of CCTVDS dataset表3 CCTVDS 數據集的樣本統計數據
5 實驗結果及分析
對模型進行訓練之前,先對數據進行整理,移除標簽數據中的特殊字符(例如@,!,?,<等),并將少于2 個漢字的句子刪除.此外,根據句子的長度,將數據分成3 個子數據集,各自分別包含的漢字個數為2~9,10~15 和16~25,樣本數量分別為95 883 619 和1 768.
實驗過程中,使用拼音準確率(PAR)、漢字準確率(HAR)和混淆值來衡量模型的性能.PAR和HAR定義為1-錯誤率=1-(D+S+I)/N,其中:D,S,I分別為從結果序列轉換到真實標簽時,需要刪除、代替和插入的拼音字母或者漢字的數量;N為真實標簽中拼音字母或者漢字的數量.混淆度是概率分布的一個衡量,越小的混淆值,表明分布的預測越好.
5.1 P2P網絡模型實驗分析
5.1.1 訓練技巧
批度規范化(batch normalization,簡稱BN)在運行過程中需要統計每一個mini-batch 的一階統計量和二階統計量,不適合用于動態的網絡結構和循環神經網絡RNN 中.因此在P2P 模型中,卷積神經網絡ConvNet 使用了BN 操作,而動態的RNN 網絡在訓練過程中嘗試使用其他規范算法:層規范化(layer normalization,簡稱LN)、參數規范化(weight normalization,簡稱WN)、余弦規范化(cosine normalization,簡稱CN).
使用BN 算法后,在訓練時,P2P 網絡可以設置較高的初始學習率,加速網絡的收斂.然而,過高的初始學習率會導致P2P 模型中的n-LSTM 很難收斂.針對這個問題,我們給P2P 中不同的模塊設置不同的初始學習率.在ConvNet 網絡中,選取較高的初始學習率,如0.1.而在n-LSTM 網絡中,選取較小的初始學習率,如0.001.通過給兩個不同的模塊設置不同的學習率,促使ConvNet 和n-LSTM 盡量同時收斂,進而達到P2P 模型完全收斂的效果,使其具有更好的拼音序列識別能力.
5.1.2 實驗結果
P2P 模型由卷積神經網絡ConvNet、循環神經網絡RNN 和CTC 組成.實驗結果表明:P2P 模型中使用不同的特征提取器ConvNet,產生的結果也不相同.實驗中共嘗試了VGG-M,VGG-16,IncepV2 和AlexNet 這4 種不同卷積網絡,且網絡中的后三層全連接均用一個平均值池化層代替.其中,VGG-M 取得的最高識別準確率為58.51%,VGG-16 的41.28%次之,IncepV2 和AlexNet 的準確率分別為40.11%和39.19%,見表4.

Table 4 Pinyin-level recognition accuracy statistics of P2P network (%)表4 P2P 網絡的拼音識別準確率統計 (%)
在所有實驗中,無論采用哪種特征提取器,當循環神經網絡為1-512-LSTM(1 層512 的LSTM)時,均取得最好的結果.GRU 表現較差,可能是因為CTC 損失函數的使用,導致在反向傳播的過程中不能找到有效的梯度回傳路徑.同時,在訓練時發現:以VGG-16 作為特征提取器時,若對VGG-16 模型微調,模型的性能會急劇下降;以IncepV2 或者ResNet 作為嘴唇圖片序列的特征提取器時,由于網絡層數太深,訓練時很容易發生梯度消失.
此外,實驗表明:使用不同的學習率去訓練網絡,其收斂速度最快;而在RNN 中分別使用層規范化LN、參數規范化WN 和余弦規范化CN 的速度次之;無任何訓練技巧時網絡收斂最慢.同時,在對循環神經網絡進行規范化(LN、WN 和CN)時,使用CN 能夠得到比LN 和WN 更穩定的損失值.在訓練期間,嘗試在P2P 模型中使用雙向的LSTM 神經網絡,結果顯示:準確率并沒有顯著提高;與單向的LSTM 網絡相比,反而更加消耗存儲空間和計算成本.因此,最終在模型中采用普通的LSTM 提取圖片間的序列信息.
5.2 P2CC網絡模型實驗分析
5.2.1 Encoder 的訓練技巧
大量實驗表明:在序列模型中,當時間步數過長時,網絡收斂得很慢且很難訓練[15].因此,我們將P2CC 模型分為Encoder 和Decoder 兩個模塊分別進行預訓練.
我們從CCTV 官網上額外下載了從2016 年1 月1 日~2017 年6 月15 日的文本數據作為輔助數據集,并采用相同的分組方式,將句子按照長度分別分為3 個子數據集.輔助數據集中的漢字總數和句子總數分別為2972355,215697.受curriculum learning的啟發,模型先用短的數據集進行訓練,然后再不斷加長訓練數據的長度.實驗中可觀察到:這樣訓練模型的收斂速度會快很多,并且可以大幅度地減少過擬合.猜測可以把這種訓練方式看作是數據增強的一種,所以模型表現出更好的性能.
在預訓練過程中,Encoder 的輸入是拼音字符序列.而在整個唇語識別ChLipNet 網絡中,拼音序列識別模型P2P 的輸出作為P2CC 的輸入序列.由于P2P 網絡存在損失,無法輸出完全正確的拼音字符序列.為了模擬P2P模型的生成序列,我們對P2CC 模型中Encoder 的輸入進行隨機增加、刪除以及替換等錯誤處理,并且字符的隨機增加、刪除和替換率保證在0 到25%之間.
例如,將拼音字符序列“jintiantianqihenhao”變為“jingtiantanqqihenghhao”.
5.2.2 Decoder 的訓練技巧
在訓練循環神經網絡時,通常將前一時刻的真實輸出作為下一時刻的輸入,這有助于模型學習一種超過預期目標的語言模型.然而在推斷過程中,樣本的真實標簽是不可用的,均使用前一時刻的預測輸出,但是模型還無法容忍之前時刻的錯誤預測輸出,從而導致較差的性能.于是,我們采用Bengio 等人提出的預定抽樣方法[16],彌補Decoder 在訓練和推斷過程中的差異.如圖10 所示為預定抽樣方法示例圖.
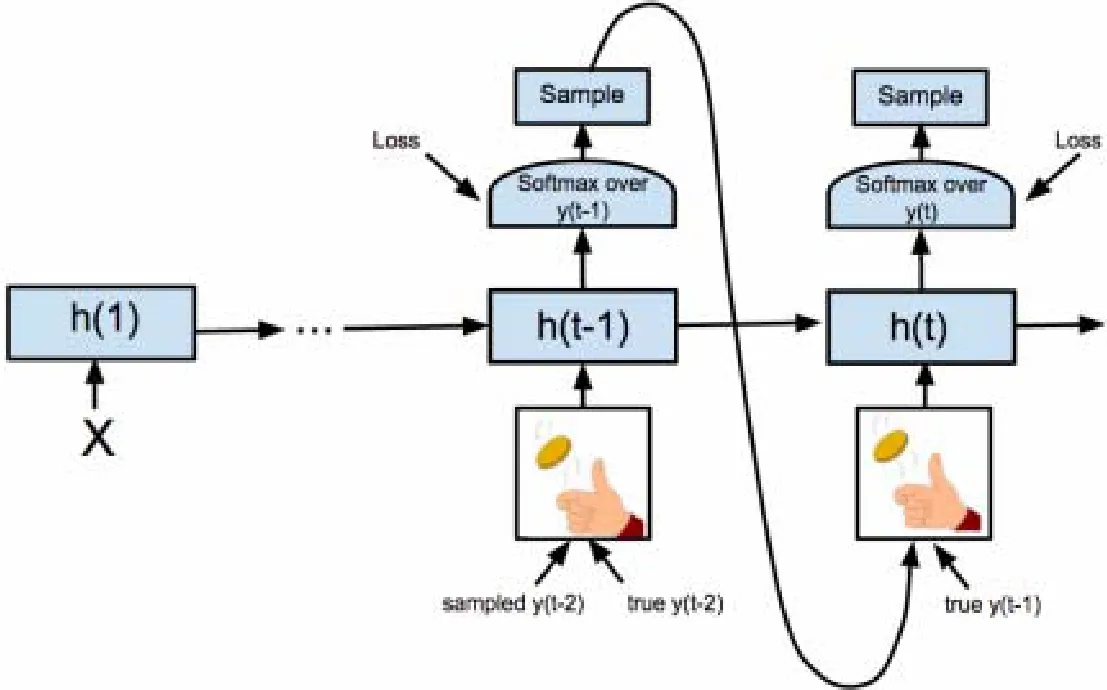
Fig.10 Example of a predetermined sampling method圖10 預定抽樣方法示例
在訓練Decoder 網絡時,若輸入序列較短,則直接使用真實的樣本標簽;當輸入序列較長時,則從前一時刻的輸出中隨機采樣,而不是始終使用真實的樣本標簽作為下一個RNN 單元的輸入,采樣概率隨著時間從0 增加到0.2.實驗表明:當抽樣概率大于0.2 時,無法實現Decoder 網絡的穩定學習.
5.2.3 實驗結果
P2CC 模型的參數初始化范圍為[-0.02,0.02],初始學習率設為0.001.實驗結果顯示:P2CC 模型結構直接決定著其性能,在不同的RNN 配置下,模型混淆度和損失值均不相同.隨著隨機錯誤率的增加,網絡的損失值也略微增加,混淆度和最小損失值分別為2.69 和0.99;錯誤率為15%,則最小混淆度和最小損失值分別為2.77 和1.02;當RNN 采用2-1024-GRU 時,P2CC 在4 種不同錯誤率下的混淆度和損失值均為最小.錯誤率為10%時,錯誤率為20%時,最小混淆度和最小損失值分別為2.97 和1.09;錯誤率為25%時,最小混淆度和最小損失值分別為3.00和1.10.當采用2-512-GRU 時,模型的最小混淆度為2.94,最小損失值為1.08.由于當采用1024-GRU 時,其結果并不明顯優于512-GRU 的結果,而且還存在大量的網絡計算,因此,從實驗結果和網絡訓練效率層面來看,RNN采用2-512-GRU 便可很好地滿足漢字序列識別研究.表5 為P2CC 模型在隨機抽樣率為10%時,不同RNN 網絡的實驗結果.

Table 5 Experimental results of P2CC with different RNN networks under 10% sampling rate表5 P2CC 在錯誤率為10%下不同RNN 網絡下的實驗結果
5.3 ChLipNet模型實驗分析
通過將ChLipNet 網絡與其他唇語識別模型在CCTVDS 數據集上進行對比分析,進而來測試ChLipNet 模型的整體性能.表6 所示為不同唇語識別模型在CCTVDS 上的實驗對比結果,并且包括模型的各自網絡結構以及相關的訓練數據集和語言類別,其中,AiC表示模型在各自原文章中的準確率,AiS表示模型在CCTCDS 上重新訓練所取得的最高句子識別準確率,AiP表示在CCTVDS 上所取得的拼音字母序列的準確率.

Table 6 Experimental results of different lip reading models on CCTVDS表6 不同唇語模型在CCTVDS 上的實驗結果
通過實驗結果,在基于深度學習的唇語識別模型中,可得出以下結論.
(1) 對比NN+LSTM 和CNN+LSTM 的實驗結果,發現CNN 表現出強大的特征提取能力;
(2) 通過和STCNN+BiLSTMCTC 對比,時空卷積網絡的性能不一定比傳統的2D-CNN 更優,尤其是在唇語識別研究中;
(3) 從序列模型中可得,RNN(LSTM/GRU)在語義解碼方面具有強大的優勢,適用于文本編譯和生成.
除了WLAS 模型外,其他唇語識別模型都是用來預測非中文的單詞或者短語的.因此,它們在句子級別的CCTVDS 數據集上效果較差.另外,WLAS 模型的輸入為嘴唇圖片和音頻數據,由于CCTVDS 數據集中不包含音頻信息,因此WLAS 在CCTVDS 也不能產生較高的準確率.正如實驗結果所示:本文提出的中文句子級別的唇語識別模型ChLipNet 可分別取得45.7%的句子準確率和58.5%的拼音序列準確率,而WLAS 相應的準確率分別為36.7%和49.8%.
6 總結
本文首次提出了端到端的中文唇語識別模型ChLipNet,該模型可以將輸入嘴唇圖片不用分割直接自動地轉化為漢語句子輸出.在訓練過程中,兩個不同的網絡模塊分別各自解決圖片到拼音和拼音到漢字的識別,當這兩個模塊分別訓練好后,再整體進行端到端的優化調整.通過增加訓練技巧,實驗結果表明:在中文唇語數據集CCTVDS 上,ChLipNet 的性能超過之前相關的唇語架構.
在之后的工作中,我們將會進行以下的嘗試.
(1) 采集更為豐富的數據集.在深度神經網絡中,數據集的樣本量直接決定了網絡模型參數訓練的完成度以及分類回歸的準確率;
(2) 對網絡輸入進行擴充.目前的ChLipNet 網絡只支持視覺信息的輸入,我們將嘗試增加網絡輸入數據類型,實現多種類型數據的輸入.例如,在輸入中增加音頻數據,實現視覺和音頻的整合,提高網絡識別精度;
(3) 將ChLipNet 應用到不同的方言中;
(4) 在Encoder-Decoder 模型使用Attention 機制,Attention 機制能夠避免因為輸入序列過長造成的錯誤輸出,使得網絡輸出更加精準的結果.此外,Attention 能夠解釋和可視化我們的網絡模型,加強對網絡的理解.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
