面向云數據中心資源均衡分配需求的聚類調度算法研究
2020-09-27 08:41:50徐雨婷陳世平
上海理工大學學報 2020年4期
關鍵詞:資源
徐雨婷, 陳世平
(上海理工大學 光電信息與計算機工程學院,上海 200093)
由于全球經濟的發展,云計算已經成為社會的一種重要計算模式[1],并在發展過程中形成了性能佳、費用低、可靠性強等一些獨特的特點。隨著云計算數據中心數據量的快速增長,人們開始研究數據中心在進行資源分配的過程中如何提高系統資源利用率的方法[2-3]。
已有許多學者針對虛擬機?服務器的資源映射問題進行了研究。Selim 等[4]利用CPU 利用率差異概念,通過計算出所有物理服務器的CPU 利用率的最小方差,選擇最合適的主機分配虛擬機,但該算法僅考慮了CPU 利用率,未考慮其他資源的使用情況。Combarro 等[5]針對三層數據中心提出了一種基于功率和網絡感知調度模型,可通過資源整合和負載均衡調整的方式來實現降低能耗的目標,但未考慮資源利用率的優化。房丙午等[6]通過建立虛擬機放置模型,基于兩個階段的啟發式算法來求解虛擬機放置模型,該啟發式算法僅針對資源分配過程中的能耗問題進行研究,未考慮資源利用率的問題。
本文主要在包簇框架[7]基礎上,研究數據中心資源調度策略。首先,基于包資源需求的分布密度,將資源需求(CPU 需求以及內存需求)具有差異性的包通過改進的k-means 算法進行聚類;其次,通過皮爾遜相關系數得到資源的相關性,定義包與簇之間的距離,將包映射到最近的簇;最后,通過Hadoop 框架和實驗工具CloudSim 分別進行實驗,驗證包聚類算法以及資源調度算法的有效性。
1 傳統的k-means 算法
傳統的k-means 算法具有良好的可擴展性,kmeans 算法的思想主要是將聚類的中心點(質心)移動到聚類中包含其他樣本點的平均位置,然后重新劃分類。k值是通過算法計算出來的參數,表示類的數量。k-means 的參數包括類的質心位置及其內部觀測值的位置。傳統的k-means 算法過程如下[8]:
步驟1輸入樣本點集合,隨機確定k個中心點;
步驟2計算樣本集合中每個點到中心點之間的距離,將集合按照最小距離原則分配到最鄰近聚類;
步驟3計算類中樣本均值,更新每個類中心點的位置;
步驟4重復步驟2 和步驟3,直到所有中心不再更新或到達設定條件停止,輸出k個類劃分和最終的聚類中心。
2 包聚類算法
2.1 改進的k-means 算法初始值選定
為了解決傳統的k-means 算法由于隨機確定初始值對聚類結果造成影響的問題,需首先采用canopy 算法確定k-means 算法的初始值k及其初始中心[9],通過canopy 算法對數據的預處理,可提高k-means 算法的處理速度,同時提高聚類準確性。
為了具體地實施包的聚類任務,采用基于canopy 算法的k-means 算法來實現包的聚類,將包的分布密度作為參數代入到canopy 算法中,并定義與包的CPU 需求、內存需求的相關距離度量因子,實現聚類過程。
將通過聚類形成的包簡稱為聚類包。現定義以下幾種參數:
a. 集合中2 個需求差異最大的包之間的距離L。現假設集合中有點i:(xi,1,xi,2),j:(xj,1,xj,2),其中,xi,1和xj,1表示包的CPU 需求,xi,2和xj,2表示包的內存需求,若在某時刻這2 個包的需求差異最大,則將它們之間的距離定義為集合中包之間的最大距離。
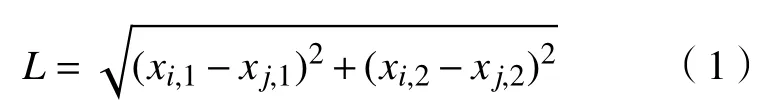
b. 距離因子d(xi,xj)。d(xi,xj)表示聚類的距離度量因子,xi,xj分別代表包的CPU 需求和內存需求。
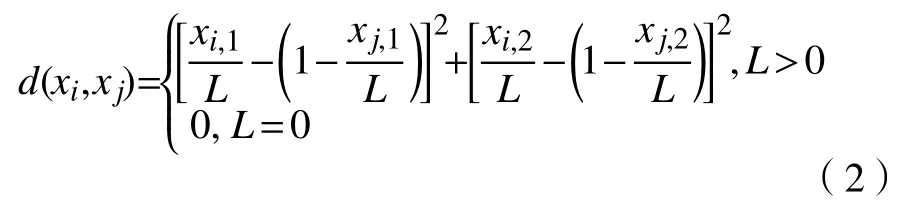
當L>0時,可由式(2)計算點i與點j之間的距離因子。以CPU 需求差異為例,若點i與點j的CPU 需求xi,1與xj,1之間的差異越大,則xi,1/L與(1?xj,1/L)的值越接近,則滿足聚類原則中距離相近的點聚為一類的條件;當L=0時,表示集合中任意2 個包之間的資源需求均相等,包之間不存在資源需求差異,此時d(xi,xj)=0。因此,若包之間的CPU 需求、內存需求差異越大,則2 點之間的距離因子越近,最終需求差異大的2 個包將處于1 個聚類中。
c. 距離因子均值Dis。Dis為集合中所有包的距離因子的均值。n為集合中所有包樣本點的數目。
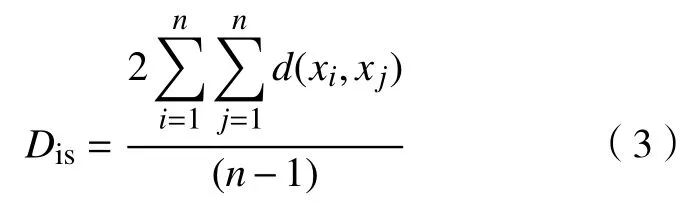
d. 包樣本點分布密度f(i)。f(i)定義為集合中與包樣本點i之間的距離因子小于Dis的包樣本點數目,表示點i的分布密度,所有滿足條件的包樣本點構成一個聚類。
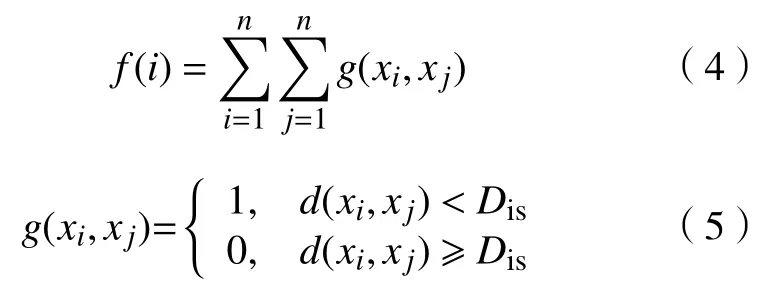
e. 聚類包中的距離因子均值 θ(i)。θ(i)表示已經形成的聚類包的距離因子的平均值。
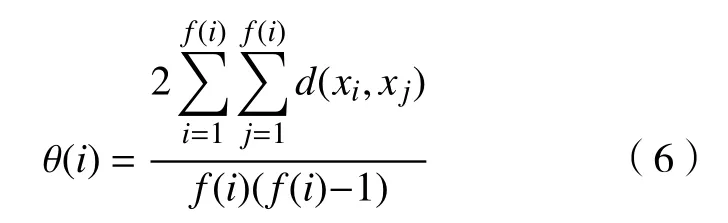
f. 2 個不同分布密度的聚類包的距離因子h(i)。h(i)表示聚類包中心點i與其他聚類包中心點之間的距離因子。現存在2 種情形:
(a)若存在聚類包中心點j1,j2,···,jR,R為聚類包的總個數,它們的分布密度均大于f(i),分別計算點i與它們之間的距離因子,若點i與點jr(r∈R)之間的距離因子d(i,jr)最小,則h(i)=d(i,jr)。
(b)若點i的分布密度f(i)大于任意一個聚類中心點的分布密度,分別計算點i與其他聚類中心點之間的距離,若點i與點b之間的距離因子d(i,b)最大,則h(i)=d(i,b)。
g. 聚類包的最大分布密度乘積 μ 。由上述分析可知,f(i) 值越大,則i的周圍的點就越多;θ(i)值越小,聚類包中的點就越緊密;h(i)值越大,則2 個聚類包的差異性就越大。由聚類的基本原則定義最大分布密度乘積μ, μ為聚類包中的距離因子均值、聚類包內的分布密度、聚類以后的包之間的距離的倒數這三者的乘積。
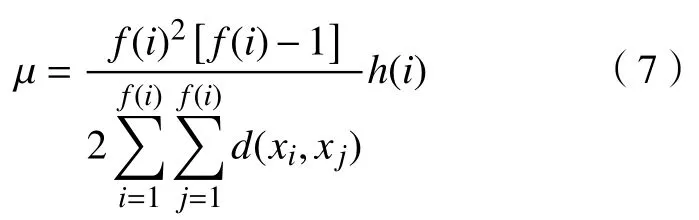
2.2 基于資源需求差異的k-means 算法
將基于資源需求差異的k-means 算法流程分為兩部分進行描述,第一部分為基于canopy 算法確定k-means 算法的k值和中心,第二部分為k-means的算法流程。
首先介紹第一部分的算法流程。
步驟1定義由包組成的數據集D,計算集合中包的距離因子均值Dis和包樣本點分布密度f(i)。
步驟2定義數據集A。步驟1 計算出的具有最大分布密度值的包a1被選擇成為第一個聚類的中心點,將點a1加入到數據集A中,將滿足與初始類中心點a1之間的距離因子小于Dis條件的所有包樣本點從D中刪除。
步驟3計算由步驟2 確定的D中剩余包樣本點的 θ(i),以及h(i)值,然后根據式(7)計算點i與a1之間的 μ 值,選擇具有最大 μ 值所對應的點i,作為第二個聚類中心a2,并將a2放入集合A中。同樣,將滿足與a2之間距離因子小于Dis的包樣本點從D中刪除。
步驟4計算D中剩余的樣本點i與a1和a2的之間的 μ 值,分別記作 μ1和μ2,選取具有最大分布密度乘積(μ1μ2)的點i,將點i作為第三個聚類的中心a3,并將a3放入集合A中。同樣,將滿足與a3之間距離因子小于Dis的包樣本點從D中刪除。
步驟5同理,若包樣本點j與聚類中心a1,a2,…,ak?1之間具有最大分布密度乘積(μ1μ2···μk?1),則包j將被設置成第k個聚類中心。
步驟6循環步驟5,最終得到k值,以及初始類中心ai,i∈k。
由上述步驟最終確定的k值以及初始中心ai,代入到k-means 算法中,執行k-means 算法流程:
步驟1計算集合中每個包樣本點i到ai的 距離因子。
步驟2將與ai之間的距離因子最小的樣本點分配到ai所在的類中。
步驟3計算每個類中的平均值,并更新聚類中心。
步驟4重復執行步驟2 和步驟3,直到所有點聚類完成。
2.3 示例說明
假設在t時刻,有8 個待分配的包,如表1 所示。假設包需求為(1, 1)的含義是對CPU 的需求為1 核,對內存的需求為1 MB。
a. 定義集合D,并將表1 中所有包需求參數放入集合D中。首先根據式(2)分別計算8 個包的距離因子,根據式(3)計算出距離因子均值Dis,再根據式(4)計算包樣本點分布密度f(i)。
b. 定義集合A,將分布密度f(i)最大的包設為第一個聚類中心點,首先選擇f(i)最大為4 的包樣本點,即編號為7 的包樣本點,作為第一個聚類中心,將其放入集合A中,并將滿足與編號為7 包樣本點之間的距離因子小于Dis的樣本點從D中刪除,刪除包編號為3,4,6,8 的樣本點。
c. 通過b 的計算,D中剩下包編號為1,2,5 的點,再分別根據式(6)計算其 θ(i),以及它們各自的h(i),根據式(7)分別計算它們與b 確定的編號為7 的包樣本點之間的 μ ,得出編號為1 的包樣本點具有最大 μ ,作為第二個聚類中心,并將其放入集合A中,并將滿足與編號為1 包樣本點之間的距離因子小于Dis的樣本點從D中刪除,刪除包編號為2,5 的樣本點,此時集合D為空,基于分布密度的canopy 算法結束。
d. 執行k-means 算法聚類流程。根據上述步驟得到k值為2,初始類中心點為編號1 和7 的包。繼續計算表1 中其他樣本點與它們之間的距離因子,將距離因子與中心點最小的樣本點分配到它們所在的類中,計算平均值,更新類中心,根據k-means 算法步驟,一直循環,直至聚類完成。
本示例形成了2 個聚類包。第一個聚類包括編號3,4,6,7,8 的包,其中,編號3,4,6 為對CPU 需求較高的包樣本點,編號7,8 為對內存需求較高的包樣本點;第二個聚類包包括編號為1,2,5 的包,其中,編號5 為對CPU 需求較高的包樣本點,編號2 為對內存需求較高的包樣本點。形成的2 個聚類包均為需求差異較大的包,由此可知,基于canopy 算法的k-means 算法可將資源需求差異較大的包聚類,從而提高各資源的利用率。最終得到的聚類結果如圖1 所示。
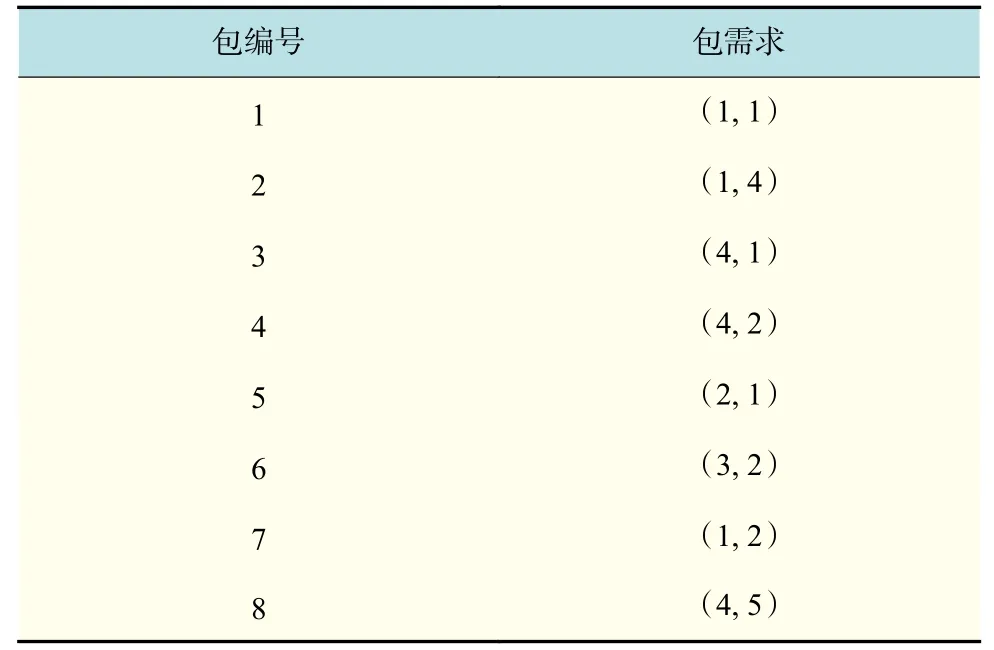
表 1 包需求參數(1)Tab.1 Package demand parameters(1)
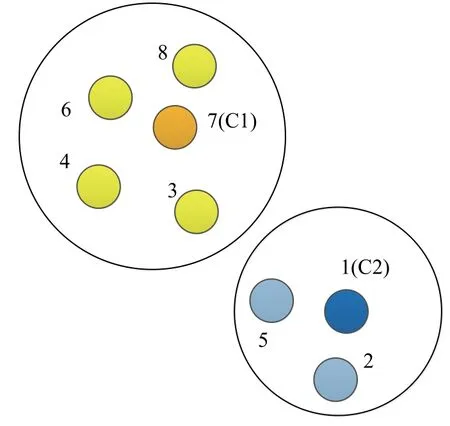
圖 1 聚類以后的包Fig. 1 Package after clustering
C1,C2 分別為第一個、第二個聚類包的聚類中心點。
3 包簇資源調度算法
3.1 包簇資源利用率及能耗定義
經過前面的聚類算法后,系統中共有k個待分配的聚類包,定義包集合為{x1,x2,···,xk},定義簇集合為{y1,y2,···,yn}。現假設t時刻,包v(1 ?v?k)的資源需求總量為Rv[t],簇p(1 ?p?n)可提供資源使用總量為Sp[t],定義簇p中已使用資源總量為Wp[t],規定每個簇的資源只能分配給一個包,即包中使用的資源不能超過簇中擁有的總資源,資源利用率
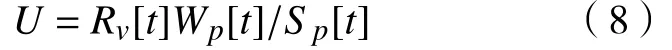
式中,0 ?U?1。
在資源分配過程中,除了需要考慮資源利用率以外,還需考慮資源分配過程中產生的能源消耗,可建立資源利用率與能耗之間的關系式[10],式(9)為混合任務負載環境下的能耗模型。
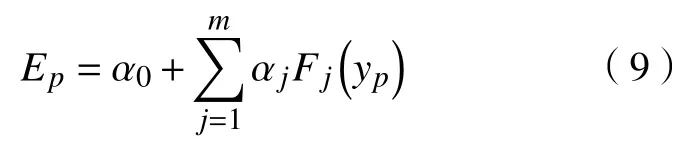
式中:Ep為能耗;Fjyp為Ep的核函數,由指數函數表示;yp為各類資源(CPU、內存)利用率; α0,αj為核函數的參數,由模型訓練可得;m為用于訓練的數據集中的數據總數目。
3.2 包簇之間的距離計算
簇與聚類包之間的距離由資源之間的相關性進行定義,采用Pearson(皮爾遜)[11]相關系數描述簇中已使用的資源總量與包的需求總量之間的相關性,分別將Rv[t],Sp[t],Wp[t]代入相關系數,由于相關系數ρRv(t),Wp(t)的因子取值為[0,1],所以,將Rv[t]與Wp[t]進行歸一化,再代入式(10),可得
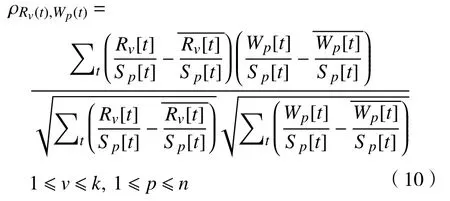
由于相關系數的區間為[?1,1],因此,定義簇與聚類之后的包之間的距離
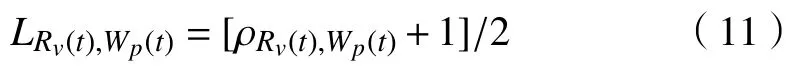
式(11)表示包簇之間的距離,區間為[0,1],當由式(11)計算得出的LRv(t),Wp(t)值處于[0,1/2)時,表示Rv[t]與Wp[t]之間具有負相關性,具有負相關性的虛擬機與物理節點之間一般具有更多的資源互補[12-13]。因此,在進行包簇資源分配過程時,首先將包映射到與其距離的區間在[0,1/2)之間的簇,且在這區間中距離值越小,代表包與簇之間的資源互補性越大,最終可在資源分配時使得包能夠集中映射到簇,從而減少簇的使用個數,提高資源利用率,降低分配過程中產生的能耗。
3.3 包簇資源調度算法的流程
基于改進的k-means 包簇資源調度算法(IKPC)步驟:
步驟1將所有待分配的聚類包放入隊列,計算每個聚類的包到簇的距離,并將符合條件的聚類包映射到離它最近的簇中;
步驟2若簇資源不夠分配給任何一個聚類包,則將聚類包放入隊列尾部,直到聚類包找到具有符合條件的簇進行映射;
步驟3循環步驟1 和步驟2,直到所有的經過聚類以后的包映射到相應的簇中。
4 相關實驗
實驗1包聚類算法驗證。
為了驗證包聚類算法的有效性,現定義幾種包參數,具體參數如表2 所示。包需求為(100,100)的含義是對CPU 的需求為100 核,對內存的需求為100 MB。
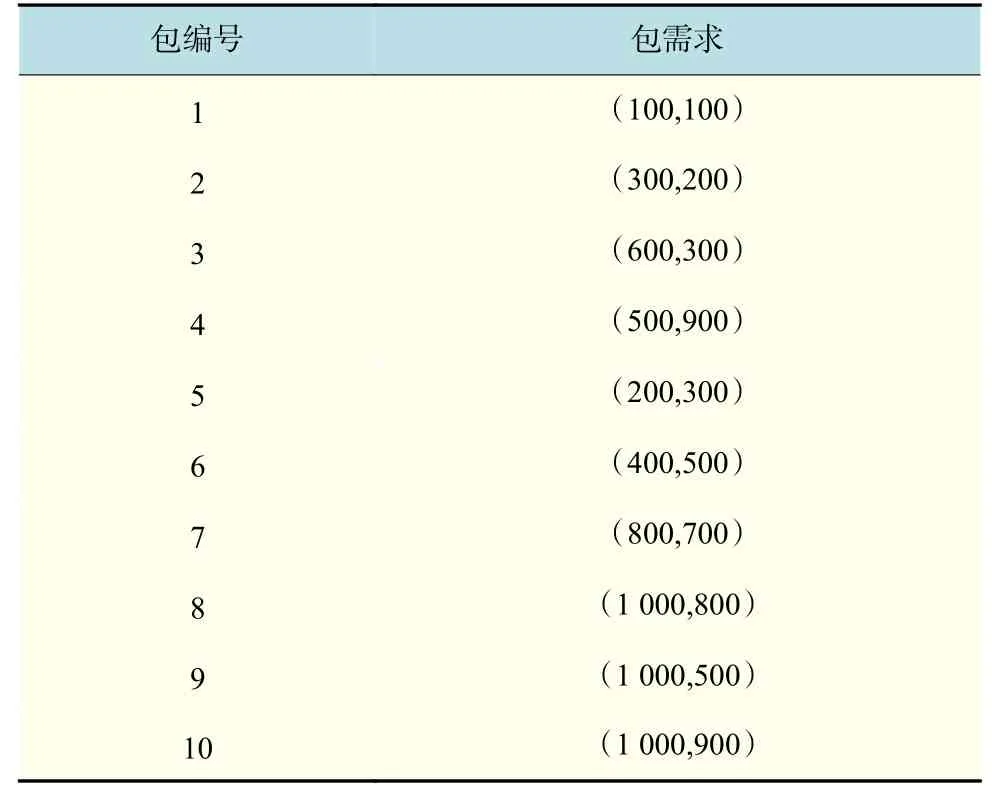
表 2 包需求參數(2)Tab.2 Package demand parameters(2)
通過Hadoop 框架的MapReduce 思想進行改進的k-means 算法的驗算,實驗結果如圖2 所示。
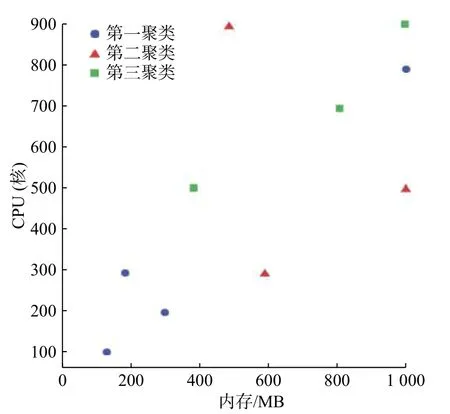
圖 2 實驗聚類結果Fig.2 Clustering experiment results
由圖2 的實驗結果可得,10 個包樣本,經過聚類最終形成3 個聚類包。第一類包編號為1,2,5,8 的聚類包,編號2,8 為對CPU 需求較高的包,編號5 為對內存需求較高的包;第二類編號為3,4,9 的聚類包,編號3,9 為對CPU 需求較高的包,編號4 為對內存需求較高的包;第三類編號為6,7,10 的包,編號7,10 為對CPU 需求較高的包,編號6 為對內存需求較高的包。因此,本實驗在將包進行聚類時,具有一定的有效性和靈活性。
實驗2資源調度算法驗證。
采用云仿真軟件Cloudsim3.0[14]進行實驗,實驗環境中計算機參數為Intel Core i5-8250U CPU@1.60 GHz,內存為8.00 GB,64 位操作系統。
為了說明在資源調度算法之前首先將具有需求差異的包進行聚類的重要性,將本文的IKPC 算法與未經聚類直接采用資源調度算法(PC,package-cluster)進行對比,此外,進行對比的算法還有傳統啟發式算法、降序首次適應算法(FFD)[15],FFD 算法是通常用來解決資源調度問題的方法。為了驗證在包的需求更多以及簇資源規模更大時算法的有效性,現采用2 000 個簇和1 600 個包進行實驗。
如圖3 所示,本文中經過包聚類以后的IKPC算法的簇使用個數最少,相比未經過聚類,直接調用PC 算法的簇的個數少100 左右,相比于簇使用個數最多的FFD 算法,IKPC 的簇使用個數少500 左右。因此,本文中的IKPC 能在最少的簇中盡可能多地分配資源,具有一定的可用性。
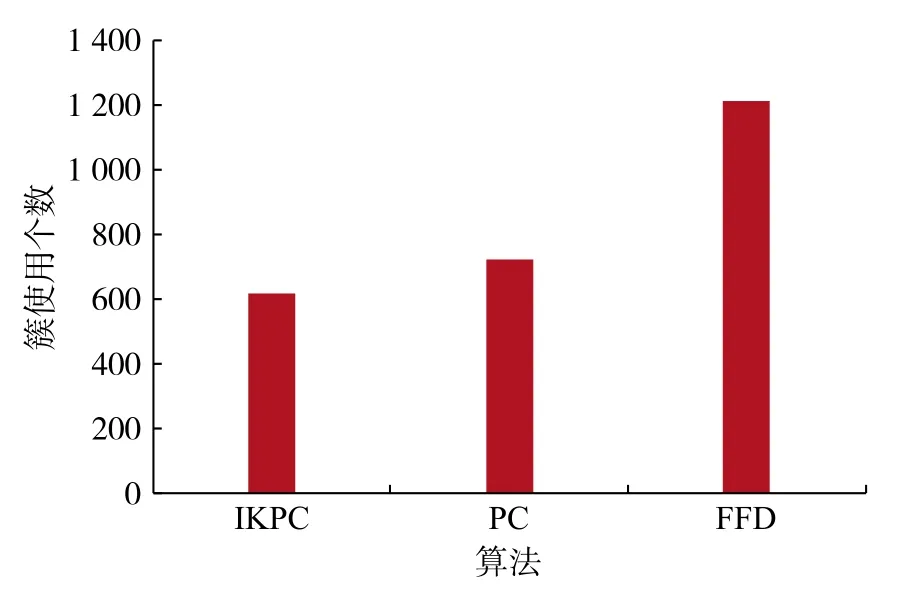
圖 3 簇使用個數比較Fig.3 Cluster number comparison
如圖4 所示,本文的資源調度算法IKPC 的CPU 利用率最高,FFD 算法與其他兩種算法相比,其CPU 利用率最低。IKPC 算法比FFD 算法的CPU 利用率總體高10%左右,比未聚類的PC高6%左右。顯而易見,本文的資源調度算法在CPU 利用率方面更有優勢。
如圖5 所示,IKPC 的內存利用率最高,相比于內存利用率最低的FFD 算法,IKPC 的內存利用率高了將近15%,比未聚類的PC 高7%左右。因此,本文的資源調度算法IKPC 在提高內存利用率方面具有有效性。
圖6 為3 種算法的能耗比較結果。由于本文的IKPC 算法在資源分配過程中使得包能夠集中映射到簇中,從而降低了資源分配過程中產生的能耗,而PC 和FFD 算法在資源分配過程中側重于尋找合理的資源分配解,忽略了能耗、資源利用率的優化,因此,本文的IKPC 算法在降低數據中心的能耗方面具有一定的可用性。
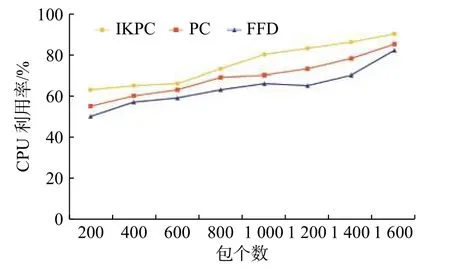
圖 4 CPU 利用率比較Fig. 4 CPU utilization comparison
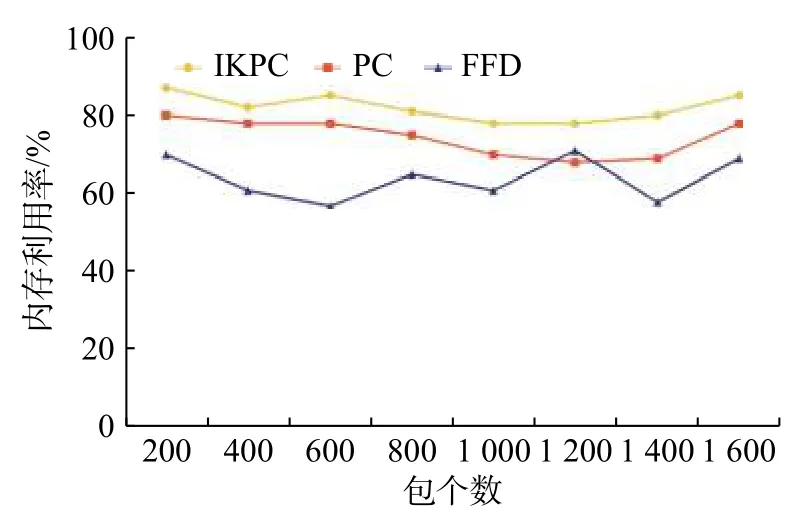
圖 5 內存利用率比較Fig. 5 Memory utilization comparison
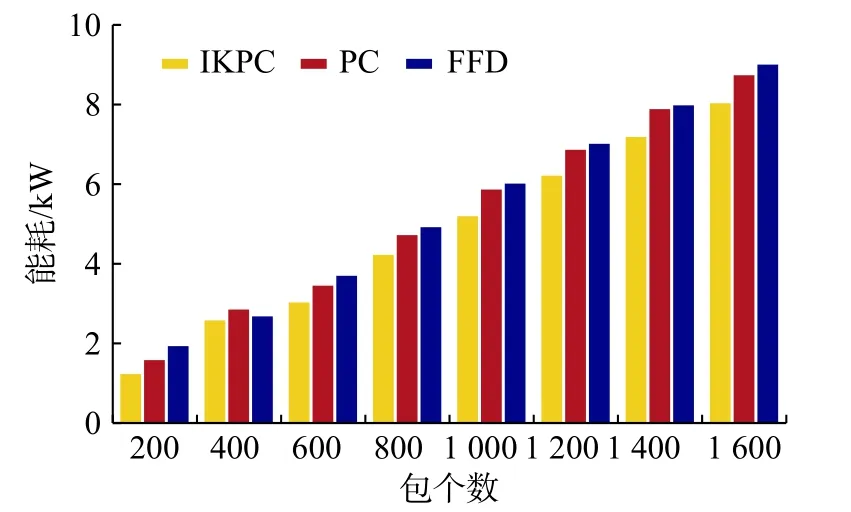
圖 6 能耗比較Fig. 6 Energy consumption comparison
5 結束語
針對數據中心包簇框架下的資源分配問題,本文在進行包簇資源映射工作之前,首先將具有資源需求差異的包采用改進的k-means 進行聚類,然后,通過皮爾遜相關系數將聚類以后的包的需求和簇可提供資源之間的相關性作為距離度量因子,實現了包簇資源的映射。實驗研究表明,改進后k-means 算法能夠有效地對包聚類,資源調度算法能夠有效地減少簇的使用個數,不僅能夠提高各類資源利用率,而且可以降低數據中心由于資源分配而產生的能耗。
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
資源節約與環保(2022年8期)2022-09-20 02:25:22
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
藝術品鑒(2020年7期)2020-09-11 08:04:44
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
當代貴州(2018年28期)2018-09-19 06:39:04
資源再生(2017年3期)2017-06-01 12:20:59
決策(2015年9期)2015-09-10 07:22:44
