基于超文本標記語言的文檔信息自動提取技術研究
2020-09-30 06:45:53余俊余少鋒周宇鵬廖崇陽羅勇
粘接 2020年8期
余俊 余少鋒 周宇鵬 廖崇陽 羅勇
摘要:文章研究探索了如何使用文檔分解(文檔結構研究),文檔標記(具有可擴展標記語言(XMI),超文本標記語言(HMI)和可伸縮矢量圖形(SVG),以及多方面的分類機制。文檔內(nèi)容提取是通過計算機編程(使用Java)實現(xiàn)的。在這項研究中開發(fā)的文檔信息自動提取技術證明:作為信息提供者,可以使信息用戶(包括工程師)以更易于訪問的方式制作文檔內(nèi)容。
關鍵詞:文檔信息自動提取;超文本標記語言;分解方案;文檔標記;分面分類
中圖分類號:TP391
文獻標識碼:A
文章編號:1001-5922(2020)08-0080-05
Research on Automatic Extraction of Document InformationBased on Hypertext Markup Language
SHE Jun,YU Shao-feng,ZHOU Yu-peng,LIAO Chong-yang,LUO Yong
(1.lnformation & Communication Branch of China Southern Power Grid Peaking & Frequency Modulation Power(Generation Co..Ltd..Guangzhou Guangdong 511400,China;2.Westem Maintenance Test Branch of China SouthernPower CJrid Peaking & Frequency Modulatio Generation Co..Ltd.,Xingyi Guizhou 562400.China)
Abstract : This paper explores how to use document decomposition (document structure research) .document mark-up (with Extensihle Markup Language (XML),Hypertext Markup Language (HML).and Scalable Vector (Graphics(SVG) .and more classification mechanism.The document content extraction is realized through computer program -ming (using Java).The automatic extraction technology of document information (AETDI) developed in this re-search proves that as an information provider,you can make Information users (including engineers) can create doc-ument content in a more accessible way.
Key words : automatic extraction of document information;hypertext markup language;decomposition scheme;docu-ment markup;faceted classification
0前言
當前正在開展生產(chǎn)域信息平臺( Production Do-main information Platform)的研究與建設工作,其軟件環(huán)境分為數(shù)據(jù)中心和應用中心兩大部分,在公司內(nèi)部被稱作“兩個中心”[1-2]。“兩個中心”建設目的在于探索以“數(shù)據(jù)應用”作為企業(yè)信息化核心,通過組件技術去系統(tǒng)化的新途徑,克服傳統(tǒng)信息系統(tǒng)相對孤立,系統(tǒng)間數(shù)據(jù)資源難以互相調用的弊端[3-4]。目前,生產(chǎn)域信息平臺已具備了對實時數(shù)據(jù)、關系型數(shù)據(jù)的處理能力,需要增加對文檔型數(shù)據(jù)(非關系型數(shù)據(jù))的處理能力,為此急需要先期開展對文檔型數(shù)據(jù)的信息提取和處理方法的研究。已經(jīng)發(fā)現(xiàn)參與設計過程的工程師花費了多達20%-30%的時間來搜索和訪問設計信息[5-6]。這可以看作是提供更好的信息系統(tǒng)以使工程師能夠更輕松地搜索和檢索信息的重要性的指示。但是,要使信息系統(tǒng)成功,就必須基于對工程師工作方式的理解和超文本標記語言的特征。
1支持AETDI的方法和技術
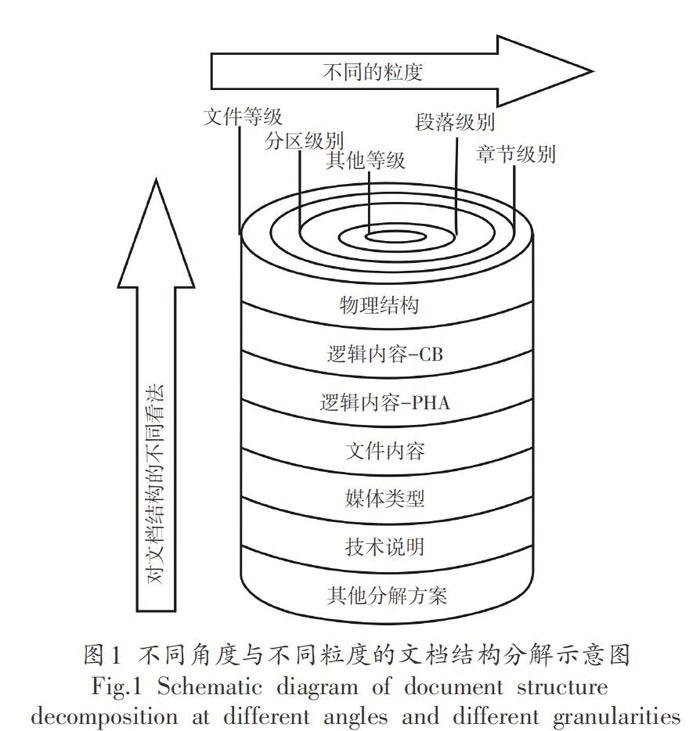
信息通常分為3種類型:結構化信息,半結構化信息和非結構化信息[2]。數(shù)據(jù)庫中的數(shù)據(jù)通常是結構化信息,而文檔(例如電子郵件和對話)是非結構化信息的示例。AETDI處理具有邏輯結構的半結構文檔,因此可以進行搜索。為了理解文檔的邏輯結構,我們進行了研究,探索了如何分解文檔。它從不同的角度和粒度定義了11種分解方案。為了使半結構化文檔的內(nèi)容能夠由計算機自動準確地解釋,使用了標記技術,包括可擴展標記語言(XML),超文本標記語言(HMI)和可縮放矢量圖形(SVG)被雇傭。使用多面分類機制對文檔內(nèi)容進行分類。針對AETDI設計了一種基于超文本標記語言的概念層次結構,以適應其在超文本標記語言中的應用。
1.1超文本標記語言文檔結構
文檔結構定義了文檔中內(nèi)容對象的組織方式。在電子商務中,如果業(yè)務合作伙伴對文檔結構有共同的了解,則可以用一致的方式創(chuàng)建,傳輸和解釋文檔,同時保留發(fā)送者想要的語義。只有確定并遵循了文檔結構,才可以有效地訪問和檢索文檔內(nèi)容。應該以盡可能標準化的結構創(chuàng)建超文本標記語言,以便可以在公司中保持一致性,并且可以在協(xié)作成員之間實現(xiàn)溝通的完整性。該研究項目通過不同的分解策略研究文檔結構。已經(jīng)定義了11種分解方案以提供對文檔結構的全面理解。圖1說明了定義不同分解方案以從不同角度和不同粒度查看文檔結構的想法。
1.2文檔標記
以結構化和可定義的方式交換信息的需求導致了標記技術的誕生。標記是用于解釋文檔中的結構和信息的代碼。文檔可以被計算機標記和自動處理。標記可用于幫助搜索文檔內(nèi)容,例如在文檔信息自動提取系統(tǒng)中。通用標記首先由Scribe文檔格式器普及,隨后在LATEX中普及。它也被合并到SGML和ODA中。隨著Web技術和諸如XML,HML和SVG之類的標記語言的出現(xiàn),標記技術已經(jīng)表現(xiàn)出了代表文檔結構的優(yōu)勢。
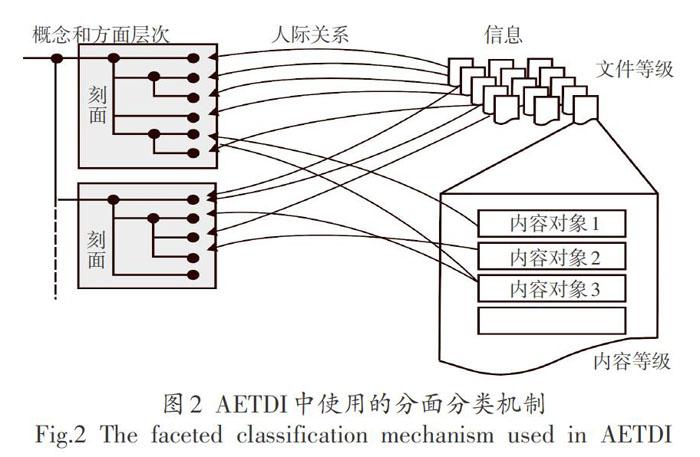
在AETDI中,如圖2所示,XML用于標記文檔文本,SVG用于標記圖形,HML用于嵌入圖像。在系統(tǒng)中,圖形與圖像的不同之處在于,圖形的內(nèi)容被視為一組元素(例如在復雜的圖形中,其中某些元素可以重復使用或重復),而圖像被視為一個整體,并且無法進一步分解。圖形中的嵌入文本也被視為一個單獨的元素,可以進行搜索。
1.3超文本標記語言領域的概念層次結構的分面分類和設計
對信息進行分類是一門傳統(tǒng)且至關重要的學科。分類將孤立的,不連貫的感官印象轉化為可識別的對象和重復出現(xiàn)的模式。現(xiàn)代文獻分類方法的起源是基于圖書館科學家最初提出的原理。隨著Web和網(wǎng)絡的出現(xiàn),信息的組織和分類被視為使人們能夠應對越來越多的他們可以訪問的文檔的關鍵。已經(jīng)針對不同的用途開發(fā)了不同類型的分類方案。圖2顯示了如何通過正確的關系(由約束定義)將信息(在文檔和內(nèi)容級別上)分類為正確的概念和方面。
2文檔超文本標記語言化后的數(shù)據(jù)自動提取及處理
文檔到移動終端上的時候其實是一個離線文件,通過開發(fā)了特定的APP來顯示轉換后的文檔,并在填寫試驗數(shù)據(jù)后APP能自動提取數(shù)據(jù),對于數(shù)據(jù)提取其實現(xiàn)在有2種方式:①原生開發(fā),②混合開發(fā),本文通過對2個方式進行比較,最后來確定哪種技術方案適合本次研究課題。
2.1原生方案
當應用程序需要展示網(wǎng)頁時,而需求上卻不允許打開系統(tǒng)瀏覽器時,安卓為了解決這種需求提供了WebView控件。WebView控件類似于嵌入了一個瀏覽器,而且原生的WebView是支持本地文件系統(tǒng)打開文本標記語言。
本方案最重要的就是內(nèi)容的提取,提取內(nèi)容采用超文本標記語言中已經(jīng)用Javascript寫好,所以APP要能提取到表單中的數(shù)據(jù)需要原生代碼去調用離線文件中的Javascript的代碼。原生webView.loadUrl方法其實支持調用離線網(wǎng)頁中的js,但是不能獲取函數(shù)返回的結果。
提取到離線試驗數(shù)據(jù)后,為了方便系統(tǒng)數(shù)據(jù)導入,需要把數(shù)據(jù)寫入到本地的文件系統(tǒng)系統(tǒng)中,對于原生APP支持操作文件的API就能實現(xiàn),所以對文件的支持非常好,API也非常豐富。
2.2混合開發(fā)方案
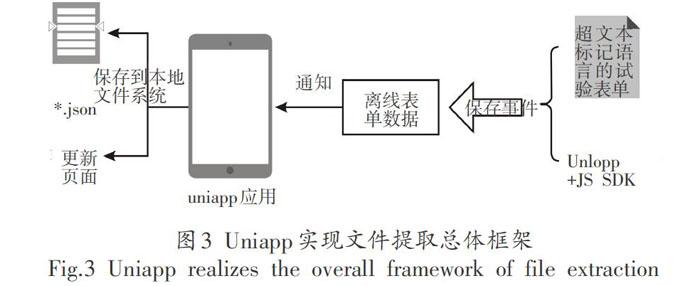
混合開發(fā)方案采用基于VUE的Uniapp,因為Lni-app能實現(xiàn)一次開發(fā),支持適配Android與IOS等平臺,對于后期維護非常方便,所以混合開發(fā)內(nèi)容是居于Uniapp來比較的。本地超文本標記語言顯示的支持上Uniapp的web-view組件支持,web-view是一個web瀏覽器組件,可以用來承載網(wǎng)頁的容器。
內(nèi)容提取的支持和原生采用不通的方式,網(wǎng)頁向應用發(fā)送消息,在的message事件回調event.detail.data中接收消息,所以內(nèi)容提取上非常容易實現(xiàn),不是采用app組件去調用離線網(wǎng)頁Javascript,而是離線網(wǎng)頁通知的方式,然后app獲取到通知的數(shù)據(jù),所以內(nèi)容提取支持非常好,不單如此umapp還提供了一些調用app應用的函數(shù),所以說非常米方便。
最后就是文件系統(tǒng)的寫入,Uniapp本質也是基于H5來實現(xiàn)APP開發(fā),對文件系統(tǒng)支持其實不是非常好,但是也是提供的保存文件到本地的接口,但是接口不是非常完善,但是可以實現(xiàn)文件的基本操作。
Uniapp實現(xiàn)文件提取總體流程如下圖3所示。
通過對上述2個技術的比對總結:離線超文本標記語言上顯示上無論是原生還是混合開發(fā)支持上都非常好;在數(shù)據(jù)提取區(qū)域,原生采用原生代碼去調用離線網(wǎng)頁的JS來實現(xiàn),js返回的數(shù)據(jù)無法接收,而混合開發(fā)支持離線的網(wǎng)頁支持通知App自生,所以數(shù)據(jù)提取上混合開發(fā)更強;文件保存上兩者都支持;綜上3點本文采用混合開發(fā)方案更好,而且混合開發(fā)還有一次開發(fā)支持多端等優(yōu)點。
3文檔信息自動提取過程
文中討論AETDI系統(tǒng)的實施,并重點關注當前研究項目中執(zhí)行的4個方面的關鍵問題。它們是文檔結構,文檔標記,文檔內(nèi)容的提取以及導航機制的創(chuàng)建。但在此不討論分面分類和結果發(fā)布的實現(xiàn),因為這些操作是由作者先前研究中開發(fā)的Waypoint系統(tǒng)執(zhí)行的。
3.1文檔結構的實施
由于文檔結構的復雜性,UML類圖已被設計為實現(xiàn)由文檔分解方案定義的文檔元素之間的關系。圖4是表示物理結構分解方案的UML類圖的頂層結構。從圖5可以看出,文檔具有3個主要類別:標題,正文和注釋。聚集關系表明標題,正文或注釋是文檔的“部分”(菱形指向“整個”)。根據(jù)文檔正文解釋標題的詳細信息,并且注釋可以補充正文,已經(jīng)在Heading和Body類之間以及Body和Note類之間指定了關聯(lián)關系。為每個類指定的多重性指標定義參與關系的對象數(shù)。如圖5所示,一個“正文”對象可以與一個或沒有“標題”對象相關,但可以與零個或多個“注釋”對象相關。一個標題或注釋對象與一個“正文”對象完全相關。對于這3個類的每一個,已經(jīng)定義了兩個屬性,一個ID屬性使每個類都是唯一的,一個IDREF屬性用于保持另一個類的ID,從而可以實現(xiàn)從一個類到另一個類的信息導航指南。
Body,Heading和Note類的擴展結構。Body是一個相對復雜的類,可以是Part,Chapter,Section,Paragraph,Sentence或Word。Bodv類及其子類之間的繼承關系意味著Part,Chapter,Section,Section,Sentence和Word類都從Body類繼承其屬性和操作。已經(jīng)在相關子類之間指定了聚合關系以施加所需的限制。已根據(jù)Section的類別將反射聚合關系指定給See-tion類,根據(jù)文檔的復雜性,可以將Section分解為更小的部分(即小節(jié)或子小節(jié))。圖像屬性已定義為允許在文檔中將文本與圖像實體相關聯(lián)。
上面圖5的UML類圖清楚地指定了文檔元素以及根據(jù)文檔分解方案的元素之間的關系。使用UML類模型定義文檔結構還非常有助于使人們理解長文檔,以便與參與研究項目的每個人進行交流,并在技術上開發(fā)XML DTD數(shù)據(jù)模型以有效實施文檔標記。
3.2文檔加標的實施
標記一詞指代置于文檔中以指示如何解釋(非標記)數(shù)據(jù)的代碼或令牌。無需加價,計算機就可以通過頻繁計數(shù)或通過操作員的指示,基于發(fā)現(xiàn)的關鍵字或短語以某種程度的準確性來識別內(nèi)容。但是,文檔標記可以毫不含糊地指示可以找到某些內(nèi)容的位置。在信息檢索系統(tǒng)中使用文檔標記技術將獲得更高的準確性。XML和HML以及SVG(一種用于二維圖形的基于XML的語言)已用于在AETDI中標記超文本標記語言。本文重點介紹XML標記的實現(xiàn)。在其他地方描述了圖像和圖形的標記。在XML文檔中,合法的或不合法的由文檔類型定義(DTD)或模式指定。DTD或模式還建立了文檔有效性的標準,可以由專用計算機軟件自動檢查該標準。如果計算機軟件可用于驗證和反饋結構復雜的非常長的超文本標記語言(例如,500P的報告)上的標記錯誤,那么這將是一個優(yōu)勢,否則這將非常困難甚至無法實現(xiàn)校驗。因此,DTD或模式的生成是XML標記的核心。在本文中,正是DTD數(shù)據(jù)模型將UML類圖中的文檔結構信息傳輸?shù)娇赡軒в袠擞浀腦ML文檔中。
DTD定義中的一個重要概念是創(chuàng)建元素內(nèi)容模型,該模型指示允許元素具有哪些內(nèi)容,例如子元素,文本數(shù)據(jù),空元素或任何內(nèi)容。如圖6所示的Body類相對應的DTD的摘錄。在上面的DTD數(shù)據(jù)模型中,已經(jīng)創(chuàng)建了兩種重要類型的內(nèi)容模型來反映兩個重要的關系。為了捕獲DTD中Body元素及其子元素之間的繼承關系,內(nèi)容模型已定義為<!-- ELEMENT body(部分|章|節(jié)|段落|句子|單詞)*-->以支持子元素的選擇。因此,為文檔創(chuàng)建適當?shù)腄TD時,應牢記兩個重要事項:首先,元素的內(nèi)容模型應明確聲明子元素之間的關系(例如順序或選擇)。其次,必須正確指定子元素的數(shù)量(例如零個或一個,或一對多)。此處創(chuàng)建的DTD數(shù)據(jù)模型提供了XML標記的語法規(guī)則。有了DTD數(shù)據(jù)模型后,完成XML標記的其余工作需要將標簽(DTD中元素指定的名稱)插入文檔的正確位置,這可以手動完成,自動或通過計算機程序自動執(zhí)行。
4實驗與結果分析
AETDI專為管理任何工程文檔(包括工程圖)而開發(fā)。文檔內(nèi)容可以是文本,圖像或圖形。實驗以CADCAM教科書作為1個長文檔的示例,以及巴斯大學賽車隊提供的一組賽車項目海報作為許多工程文檔的緊湊表示(包含正式文檔的內(nèi)容)結構,其中包含各種文本和表格,以及各種說明性材料,例如照片,繪圖和圖表等)。本文將探討進行的實驗,其中使用了一系列問題來說明AETDI對工程師的作用。它著重于分解方案的使用。
總而言之,此實驗研究表明,AETDI在某種意義上比普通信息系統(tǒng)先進:
用戶可以通過對結構和內(nèi)容(不是僅內(nèi)容)進行復雜的查詢來檢索非常特定的文檔內(nèi)容。概念樹中的分解方案表示結構,如圖7所示,超文本標記語言主題索引和關鍵字搜索表示內(nèi)容。ED-CMS中實施的分解方案意義重大,因為就文檔結構而言,不同類別的信息對文檔用戶而言具有同等重要的意義。例如,書本章節(jié)標題中的“產(chǎn)品建模”返回給讀者的意義遠大于書帖本身,在圖形標題中找到的“電動機驅動器”比在書帖中找到的“電動機驅動器”也是如此。章節(jié)文字。因此,在AETDI中實施分解方案對用戶來說意義重大,尤其是當用戶使用分解方案從結構復雜的長文檔中訪問和檢索特定內(nèi)容時。
5結語
文章討論了超文本標記語言的文檔信息自動提取。文檔分解方案的復雜性和超文本標記語言的概念樹是AETDI的強大功能,但同時也是其最大的局限性。該系統(tǒng)需要大量的文檔結構方面的專業(yè)知識來定義分解方案,并且需要相關的知識來讓文檔標記作者正確地掌握和應用這些方案。此外,由于系統(tǒng)采用Waypoint平臺(基于多面分類機制),因此檢索到的信息結果將極大地依賴于設計概念樹的人員的專業(yè)知識以及使信息分類過程自動化的約束條件。期望這樣的人應該對超文本標記語言領域有豐富的知識。
參考文獻
[1]匡成寶.HTML語言的網(wǎng)頁制作方法與技巧探討[J].電腦迷,2017(03):190-191.
[2]羅正蓉,范靈.應用HTML和css制作網(wǎng)頁[J].科技展望,2016(26):10.
[3]朱敏.JavaScript在HTML中的應用探討[J].科技視界,2016(24):227-228.
[4]劉霜,潘立武.HTML發(fā)展應用中的探索與研究[J].信息與電腦(理論版).2016(11):72-73.
[5]魏佳欣,葉飛躍.基于HTML特征與層次聚類的Web查詢接口發(fā)現(xiàn)[J].計算機工程,2016(02):56-61.
[6] Choi,H.,&Sim,S..(2015).A studv on efficiency ofmarkup language using dom tree.Wireless Personal Com-munications, 86(1),143-163.
收稿日期:2020-01-02
作者簡介:佘俊(1973-),男,漢族,高級工程師,研究方向:電力企業(yè)信息化。
基金項目:南方電網(wǎng)調峰調頻發(fā)電有限公司科技項目(STKJXM20180065)
