基于條件生成對(duì)抗網(wǎng)絡(luò)的圖像轉(zhuǎn)化方法研究
2020-10-12 02:38:39冷佳明曾振劉廣源鄭新陽(yáng)劉瓔慧
數(shù)碼世界 2020年9期
冷佳明 曾振 劉廣源 鄭新陽(yáng) 劉瓔慧


摘要:近年來(lái),利用設(shè)備將手繪圖像轉(zhuǎn)換為自然圖像的方法是當(dāng)前的圖像處理領(lǐng)域主流方向之一。生成式對(duì)抗網(wǎng)絡(luò)(GAN, Generative Adversarial Networks )是一種深度學(xué)習(xí)模型,是近年來(lái)復(fù)雜分布上無(wú)監(jiān)督學(xué)習(xí)最具前景的方法之一。本文提出一種基于生成對(duì)抗網(wǎng)絡(luò)的圖像轉(zhuǎn)換方法,它可以改善原本存在的圖像轉(zhuǎn)換方法的差異大、模糊不清等缺點(diǎn),減小手繪圖像與自然圖像的視覺(jué)差異。實(shí)驗(yàn)中生成器由U-net構(gòu)成,判別器為patch-GAN,對(duì)網(wǎng)絡(luò)模型使用L1進(jìn)行約束。二者交替訓(xùn)練,通過(guò)改變學(xué)習(xí)率、迭代次數(shù)等參數(shù)來(lái)進(jìn)行對(duì)比訓(xùn)練效果。最后得到的網(wǎng)絡(luò)模型可以對(duì)人臉的手繪圖進(jìn)行輪廓和部分細(xì)節(jié)的還原。
關(guān)鍵詞:手繪圖像;條件生成對(duì)抗網(wǎng)絡(luò);人臉
1 引言
近年來(lái),隨著越來(lái)越多的智能化設(shè)備的開(kāi)發(fā),人類正一步步邁向智能化生活,也期待著存在更加方便快捷的設(shè)備或系統(tǒng)可以滿足人們的設(shè)想。在日常生活中,手繪是一種常見(jiàn)的交流方式,人類自古以來(lái)就以繪畫的方式描繪生活中的一點(diǎn)一滴。概括地說(shuō),手繪可以快速地對(duì)某個(gè)場(chǎng)景進(jìn)行較為完整的描述。在當(dāng)今社會(huì),通過(guò)普遍存在的觸屏設(shè)備,人們能在智能設(shè)備上手繪出一幅簡(jiǎn)單的圖片,而設(shè)備給出符合程度相對(duì)較高的實(shí)物圖片,這在互聯(lián)網(wǎng)信息時(shí)代是有價(jià)值的。
在手繪圖像轉(zhuǎn)化為自然圖像的過(guò)程中,亟需解決的重要問(wèn)題是消除二者之間的視覺(jué)差異。消除此差異有三個(gè)思路:第一種是可以使用一些邊緣提取算法將自然圖像轉(zhuǎn)換為手繪圖像; 第二種是可以使用一些圖像渲染算法將手繪圖像轉(zhuǎn)換為自然圖像; 第三種是將二者映射到相同的特征空間,但應(yīng)用此思路的方法較少。第一種雖有算法工具的優(yōu)勢(shì),但轉(zhuǎn)化過(guò)程前后容易存在較大的圖片差異,所以本文采用第二種想法——利用近些年取得重大進(jìn)展的生成對(duì)抗網(wǎng)絡(luò)(generative adversarial networks, GAN)模型實(shí)現(xiàn)手繪圖像到自然圖像的轉(zhuǎn)化。
相比于其它模型,利用GAN模型實(shí)現(xiàn)的轉(zhuǎn)化圖像更清晰,模糊部分減少。本文由此模型聯(lián)想到GAN家族中的條件生成對(duì)抗網(wǎng)絡(luò)(conditional generative adversarial networks, CGAN),就像GAN學(xué)習(xí)數(shù)據(jù)的生成模型一樣,CGAN也學(xué)習(xí)了條件生成模型,這使得CGAN更適合于圖像到圖像的轉(zhuǎn)換任務(wù)。該模型更加符合本文所要完成的任務(wù),而且它展示了很好的邊緣圖至自然圖像的轉(zhuǎn)換能力。
2 方法
生成式對(duì)抗網(wǎng)絡(luò)(GAN)框架于2014年被Ian J. Goodfellow等人開(kāi)創(chuàng)性地提出,此框架同時(shí)訓(xùn)練用于捕獲數(shù)據(jù)分布的生成模型和用于估計(jì)樣本來(lái)自訓(xùn)練數(shù)據(jù)而不是生成器的概率的判別模型,整體系統(tǒng)通過(guò)反向傳播進(jìn)行訓(xùn)練,而且訓(xùn)練過(guò)程或生成模型期間不需要任何馬爾科夫鏈或展開(kāi)近似推理網(wǎng)絡(luò)。與以往的模型不同,本文的生成器使用以U-Net為基礎(chǔ)的架構(gòu),判別器使用卷積的PatchGAN分類器,它只在圖像patch的尺度上對(duì)結(jié)構(gòu)進(jìn)行懲罰,曾有論文提出了一個(gè)類似PatchGAN的架構(gòu)并將其用于捕獲本地風(fēng)格數(shù)據(jù)。本文證明這種方法可以用在更廣泛的問(wèn)題上。
2.1 CGAN原理
傳統(tǒng)GAN在圖像應(yīng)用方面只能保證輸入x盡可能地靠近真實(shí)圖片,并不能使輸入符合描述條件c的要求。2014年Mirza等人提出了有條件生成對(duì)抗網(wǎng)絡(luò)(CGAN),此模型中判別器的輸入x被修改為同時(shí)輸入c和x,而輸出一方面判斷x是否為真實(shí)圖片,另一方面判斷x和c是否匹配;它還演示了如何使用該模型來(lái)學(xué)習(xí)一個(gè)多模態(tài)模型,并提供了一個(gè)應(yīng)用于圖像標(biāo)記的示例。
在生成器模型G和判別器模型D的比較中,CGAN的學(xué)習(xí)過(guò)程相比于GAN的只有隨機(jī)噪聲向量z到輸出圖像y的G:z→y的匹配關(guān)系,增加了被觀察圖像x的輸入,即是G:{x,z}→y的匹配關(guān)系。
CGAN的目標(biāo)函數(shù)為
在此式中,生成器G要最小化該目標(biāo)函數(shù)。相反地,判別器D要最大化該目標(biāo)函數(shù):
.
在CGAN中加入損失函數(shù)會(huì)使網(wǎng)絡(luò)更加有效。例如加入L1范數(shù)損失函數(shù)后:
VL1 (G)=Ex,y~p(x,y),z~p(z)
[‖y-G(x,z) ┤‖1]
目標(biāo)函數(shù)變?yōu)?/p>
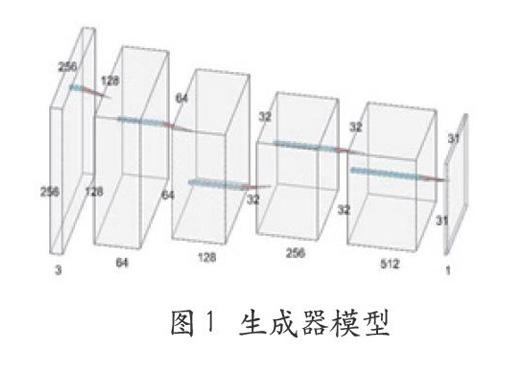
2.2 生成器
兩種圖像之間的轉(zhuǎn)換問(wèn)題的特點(diǎn)是將高分辨率輸入網(wǎng)格映射到高分辨率輸出網(wǎng)格。對(duì)于本文研究的問(wèn)題,在表層外觀方面輸入和輸出是不同的,但都具有相同的底層渲染架構(gòu)。因此輸入中的架構(gòu)大致與輸出中的架構(gòu)對(duì)齊。在本文所涉及到的領(lǐng)域中,很多以前的模型都是用了編碼器-解碼器網(wǎng)絡(luò)。在這樣的網(wǎng)絡(luò)中,輸入經(jīng)過(guò)一系列層,逐步向下采樣,直到達(dá)到瓶頸層后進(jìn)行反轉(zhuǎn)。此網(wǎng)絡(luò)要求所有的信息流通過(guò)瓶頸層在內(nèi)的所有層。而對(duì)于圖像翻譯問(wèn)題,輸入和輸出之間有大量的底層信息共享,所以可以選擇直接通過(guò)網(wǎng)絡(luò)傳輸這些信息。
本文使用一種繞過(guò)此類信息瓶頸層的方法——U-Net跳過(guò)連接,即在第i層和第n-i層之間跳過(guò)連接(n是層次總數(shù)),每次跳轉(zhuǎn)連接將第i層所有通道與第n-i層的通道連接起來(lái)。
2.3 判別器-PatchGAN原理
很多模型的判別器都是在網(wǎng)絡(luò)的最后使用一個(gè)全連接層將判別的結(jié)果以一個(gè)結(jié)點(diǎn)的形式輸出,即將輸入映射為一個(gè)實(shí)數(shù)。PatchGAN不然,該模型的判別器完全由全卷積層組成,會(huì)將輸入映射為N×N的矩陣,矩陣中的每個(gè)元素值表示是真實(shí)樣本的概率,然后對(duì)所有元素取平均值,得到的結(jié)果即為最終判別器的輸出。在此過(guò)程中,形成的矩陣就是由卷積層輸出的特征圖,以此特征圖為起點(diǎn)可以找尋原圖像中的某個(gè)位置,進(jìn)而獲得此位置對(duì)最終輸出結(jié)果的作用。
在圖像風(fēng)格遷移方面,PatchGAN有著很好的效果。為了使生成圖像具有更高的清晰度和更微小的細(xì)節(jié),本文也將采用此模型。
本文將采用生成器和判別器如圖1、圖2所示。
3 實(shí)驗(yàn)分析與結(jié)果
3.1 實(shí)驗(yàn)平臺(tái)
本文實(shí)驗(yàn)平臺(tái)為Tensor-Flow,實(shí)驗(yàn)均在windows 10 64位操作系統(tǒng),Intel i7處理器,內(nèi)存8GB上進(jìn)行,其中所用到的GPU為NVIDIA GeFore GTX 1060。
3.2 實(shí)驗(yàn)數(shù)據(jù)與處理
本文訓(xùn)練所用到的人臉圖像數(shù)據(jù)集是CelebA-HQ,它是由香港中文大學(xué)開(kāi)放提供,廣泛用于人臉相關(guān)的計(jì)算機(jī)視覺(jué)訓(xùn)練任務(wù)的人臉屬性數(shù)據(jù)集CelebA的升級(jí)版,總共30k張圖片,每一張的分辨率都是1024*1024。由于機(jī)器性能有限,我們截取了其中500張作為訓(xùn)練集,100張為測(cè)試集。部分人臉圖像如圖3所示:
接下來(lái)利用PIL(Python Image Library)庫(kù)對(duì)人臉圖像進(jìn)行處理:對(duì)于輸入的圖片利用像素間的梯度值以及虛擬深度值進(jìn)行重構(gòu),為了得到形如手繪式的人臉圖像,需要調(diào)節(jié)圖片灰度以模擬人類視覺(jué)的明暗程度;然后通過(guò)構(gòu)造光源效果加強(qiáng)所得圖片效果,即設(shè)置光源的方位角度和俯視角度;最后梯度歸一化將梯度與光源相互作用,得到新的圖片灰度,過(guò)程中注意灰度值的取值范圍。提取出的手繪圖像效果如圖4。
3.3模型訓(xùn)練
訓(xùn)練過(guò)程中,我們使用Mini batch SGD和Adam優(yōu)化器在生成器和判別器間交替執(zhí)行梯度下降,實(shí)驗(yàn)中我們對(duì)三組參數(shù)進(jìn)行了測(cè)試,每隔100step保存可視化結(jié)果,同時(shí)保存訓(xùn)練日志(loss值),參數(shù)如表1:
將人臉原像、處理后的手繪圖像和訓(xùn)練中的還原效果圖片進(jìn)行拼接,從而有更好的對(duì)效果,如圖5。
3.4實(shí)驗(yàn)結(jié)果
為了評(píng)估訓(xùn)練模型對(duì)人臉的還原效果,本文使用訓(xùn)練好的模型對(duì)訓(xùn)練集中的100張人臉圖像進(jìn)行測(cè)試,自動(dòng)還原效果如圖6所示。從損失值(如圖7)上來(lái)看,對(duì)判別器來(lái)說(shuō),生成器在測(cè)試集上的輸出有非常好的效果,但是如果使用L1損失進(jìn)行計(jì)算,則生成器的輸出效果不是很好。本文認(rèn)為L(zhǎng)1損失太大的原因是背景飾品和膚色的原因。從生成器生成的圖像來(lái)看,雖然生成的圖像在細(xì)節(jié)方面不是很好,但是生成的圖像與原圖像大體上是接近的,因此可以認(rèn)為生成器與判別器均有不錯(cuò)的訓(xùn)練效果。而且由于實(shí)驗(yàn)機(jī)器受限,本文只選取了500張作為訓(xùn)練集,存在樣本不足的問(wèn)題,如果用整個(gè)數(shù)據(jù)集訓(xùn)練的話效果會(huì)好很多。
4 結(jié)語(yǔ)
本文提出了一種基于條件生成對(duì)抗網(wǎng)絡(luò)的圖像轉(zhuǎn)化方法,構(gòu)建了能還原人像的條件生成對(duì)抗網(wǎng)絡(luò)模型,通過(guò)改進(jìn)CGAN的損失函數(shù)保證了輸入和輸出圖像的相似度,其中生成器采用了U模型,判別器采用patchGAN結(jié)構(gòu)。在訓(xùn)練過(guò)程中交替訓(xùn)練生成器和判別器,并使用了minibatch SGD 和Adam優(yōu)化器,最終得到的網(wǎng)絡(luò)可以對(duì)人臉的手繪圖進(jìn)行輪廓和部分細(xì)節(jié)的還原。后續(xù)我們希望能對(duì)如何提高生成的人像圖的清晰度做進(jìn)一步的研究,進(jìn)一步實(shí)現(xiàn)更高精度的還原效果。
參考文獻(xiàn)
[1]Isola P, Zhu J Y, Zhou T H, et al. Image-to-image translation with conditionaladversarial networks[C] //Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition.Los Alamitos:IEEEComputer Society Press, 2017: 1125-1134.
[2]Goodfellow I J,Pouget-Abadie J,Mirza M,et al. Generative Adversarial Nets[C]. International Conference on Neural Infor-mation Processing Systems. MIT Press, 2014.
[3]C. Li and M.Wand. Precomputed real-time texture synthesis with markovian g-enerative adversarial networks. ECCV,2016.
[4]M. Mirza and S. Osindero. Condition-al generative adversarial nets. arXiv pre-print arXiv:1411.1784, 2014.
[5]Pathak D, Krahenbuhl P, Donahue J, et al. Context encoders:feature learning by inpainting[C] //Proceedings of the IEEE conference on Computer Vision and P-attern Recognition. Los Alamitos: IEEE C-omputer Society Press, 2016: 2536-2544.
[6]CANNY J. A computational approach to edge detection[J]. IEEE Transactions on Pattern Analysis and Machine Intellige--nce, 1986,PAMI-8(6): 679-698.
[7]MARTIN D R, FOWLKES C C, MALIK J. Learning to detect natural image boun-daries using local brightness, color, andtexture cues[J]. IEEE Transactions on Patt-ern Analysis and Machine Intelligence, 2004, 26(5):530-549.
[8]劉玉杰,竇長(zhǎng)紅,趙其魯.基于條件生成對(duì)抗網(wǎng)絡(luò)的手繪圖像檢索[J].計(jì)算機(jī)輔助設(shè)計(jì)與圖形學(xué)學(xué)報(bào),2017,29(17):2336-2341.
作者簡(jiǎn)介
姓名:冷佳明,性別:男,民族:漢,出生年月:1999年11月,籍貫:吉林省四平市公主嶺市,單位:吉林大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,專業(yè):計(jì)算機(jī)科學(xué)與技術(shù),單位所在省市:吉林省長(zhǎng)春市,郵編 130012。曾振,吉林大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,130012,劉廣源,吉林大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,130012。
