融合多特征的老撾機構名實體識別方法
2020-10-13 05:20:56晏雷周蘭江張建安周楓
現代電子技術 2020年19期
晏雷 周蘭江 張建安 周楓

摘? 要: 為了解決老撾機構名實體構詞方法和語法規則復雜的問題,提出融合多特征的CRF與SVM的實體識別框架。面向老撾語機構名構詞特點,將老撾機構名稱分為前綴詞和后綴詞,將前綴詞提取構造成一個機構名稱特征詞典,基于詞典與SVM模型確定老撾機構名稱前界,再使用融合多特征的CRF模型識別機構名稱;最后使用SVM確定的前綴詞修正CRF的識別結果。實驗結果表明,精確率達到83.49%,召回率達到81.99%,證明了該方法的有效性。文中方法結合了SVM模型與CRF模型的優點,并融合了老撾機構名稱的相關語言學特征,取得了較好的識別效果。
關鍵詞: 老撾語; 機構名稱識別; 多特征融合; 前綴詞提取; 識別結果修正; 實驗結果分析
中圖分類號: TN911.1?34; TP391? ? ? ? ? ? ? ? ? ?文獻標識碼: A? ? ? ? ? ? ? ? ? ? 文章編號: 1004?373X(2020)19?0122?04
Abstract: In order to solve the problem that the word?formation method and grammatical rules of Lao organization name entities are complex, an entity identification framework of CRF (conditional random field) and SVM (support vector machine) fusing multiple features is proposed. According to the word?formation characteristics of institution names in Lao language, the Lao institution names are divided into prefix words and suffix words. The prefix words are extracted to build a dictionary about institutional name features. The prezones of the Lao institution names are determined on the basis of the dictionary and SVM model. The CRF model fusing multiple features is used to identify the institution names. Finally, the prefix words determined by SVM are used to correct the recognition results of CRF. The experimental results show that the accuracy rate of the method reaches 83.49% and its recall rate reaches 81.99%, which prove the effectiveness of the method. In the proposed method, the advantages of the SVM model and CRF model are combined, and the relevant linguistic features of Lao institution names are integrated, which achieve good recognition results.
Keywords: Lao; organization name recognition; multi?feature fusion; prefix word extraction; recognized result correction; experiment result analysis
0? 引? 言
命名實體識別一直是自然語言處理領域的基礎任務,如信息抽取、文本摘要、機器翻譯等[1]。命名實體一般分為七大類,分別為人名、地名、機構名、時間、日期、貨幣和百分比[2]。時間、日期、貨幣和百分比由于形式比較固定,識別比較簡單;相較于人名、地名而言,機構名結構復雜、長短不一、組成多樣,不同機構名差異較大,這些都加大了機構名識別的難度。本文的研究內容主要是面向老撾語中機構名稱的識別。
近年來,在命名實體識別領域主要使用的是基于統計的方法與基于神經網絡的方法。文獻[3]采用SVM與HMM疊加的方法對實體詞進行識別,但是由于HMM模型需要嚴格的獨立性假設,使其不能學習長遠的上下文特征。文獻[4]提出一種基于角色集的方法識別實體名并取得了較好結果,但該方法對于不同語種移植性較差,同時角色集的設計對實驗結果影響較大,需要多次實驗才能確定最優角色集。文獻[5]中使用的基于神經網絡的深度學習方法具有泛化性強、更少依賴人工特征的優點,但是目前老撾語命名實體識別語料稀少,并不能為神經網絡提供大量的標注數據,所以該方法移植到老撾語上效果一般。
針對老撾機構名實體構詞方法和語法規則復雜的問題,本文提出融合多特征的CRF模型與SVM相結合的方法。首先,利用SVM模型結合特征詞典對老撾機構名前綴詞進行識別;再利用融合詞的上下文信息、詞性、特征詞典、左右指界詞特征的CRF模型對機構名實體進行識別;最后,使用SVM的前綴詞的識別結果對CRF的識別結果進行修正。實驗表明,本文方法能夠明顯提高識別結果的準確率。
1? 系統框架
本文進行的老撾語機構名實體識別的研究以詞匯為最小判別單元,使用的標注集合為[{B,I,O}],其中,命名實體首字符標為[B]、命名實體其他字符標為[I]、非實體字符標為[O]。系統的框架結構如圖1所示,共分為三層。第一層為輸入層,首先將句子做分詞處理,再將句子處理為模型所需的格式輸入到模型中進行訓練。第二層為模型層,將句子輸入到訓練好的兩個模型中,得到標記結果,當SVM模型標記該詞為老撾機構名稱前綴詞[B]并且CRF模型也標記該詞為[B]時,方可確定該詞為老撾機構名前綴詞,并取CRF中[I]的標記結果確定一個完整的實體名;當只有一個模型認為該詞為前綴詞,另一個模型沒有進行該標記則跳過該詞。第三層為輸出層,綜合兩個模型的輸出得到最終的標注結果。
2? SVM模型
2.1? SVM原理
根據老撾語機構名稱的特點構建特征向量,使用SVM模型對特征向量進行分類,可以抽象成一個非線性分類問題。解決非線性分類問題的辦法是將原來低維空間的訓練數據映射到一個使訓練數據線性可分的更高維的空間中,通過SVM模型找到最優分類超平面[6],對數據進行分類,訓練模型。
定義訓練集如下:
SVM模型通過找到最優分類超平面對數據進行劃分[7],該超平面可通過凸二次規劃方程求解得到:
對句子中存在于特征詞典中的詞,使用SVM模型進行判斷,若得到標簽為+1,則確定其為老撾機構名稱的前界;若得到標簽為-1,則確定其不是老撾機構名稱中的詞。
2.2? 特征詞典的構造
老撾機構名稱形式相對固定。在老撾語中一般實體都會以特征詞作為一個機構實體詞的開頭,形式為前綴詞+后綴詞,如老撾國立大學(???????????????????)分為前綴詞(????????????)與后綴詞(???????)。將形如大學(????????????)這種機構名稱前綴詞加入特征詞詞典。為了更加符合實際應用情況,只將訓練集中的機構名稱特征詞提出來并去重后加入特征詞詞典,測試集中的詞不加入特征詞詞典。表1中是部分特征詞。
2.3? SVM識別老撾機構名稱前綴詞
前綴詞的識別可以看作是一個二分類問題。SVM模型是一個使用監督學習的方式對數據進行二值分類的分類器。使用SVM對老撾語機構名稱前綴詞進行識別,當句子中存在特征詞典的詞出現時,將其加入前綴詞候選詞,使用SVM模型進行識別,確認其是否為老撾語機構名稱前綴詞。根據語料特性,結合識別效果和效率,定義11維向量,格式如下:
其中:[L]表示標簽類型,[L∈-1,? 1],[L= 1]表示該特征向量為正類,該詞是機構名稱前綴詞,[L=-1]表示該特征向量為負類,該詞不是機構名稱前綴詞;[W]表示老撾語單詞的詞形;[P]表示其詞性;-2,-1,0,1,2表示單詞的位置信息,0代表當前詞,1代表當前詞后面的第一個詞,-1代表當前詞前面的第一個詞,以此類推。根據定義的向量格式構建相應向量如下所示:
1???ADJ?????????? N????? N??????? N?????N
將標注語料輸入SVM模型進行訓練與測試,得到老撾機構名稱前綴詞識別結果。
3? 條件隨機場模型
3.1? 條件隨機場原理
自Laggerty等在2001年提出條件隨機場以來,在自然語言處理領域得到了廣泛的應用[8]。對比HMM與MEMM模型,其打破了條件獨立性假設,在給定觀察序列[X]和輸出的標注序列[Y]時,使用條件概率[PYX]描述概率模型,并以序列化進行全局參數優化,解決了labelbias問題,使其在序列標注問題上獲得了更好的表現。
條件隨機場是一種無向圖模型[9],其中最簡單的鏈式結構圖如圖2所示,此處只將觀察序列[Y]作為條件,不對其做任何獨立性假設。
在給定觀察序列[X={x1,x2,…,xn}]的情況下,計算并輸出對應的狀態序列[Y={y1,y2,…,yn}],其條件概率為:
式中:[ZX]為歸一化因子,使得所有狀態序列的概率和為1;[tjyi-1,yi,xi]是關于觀測序列和位置[i]及[i-1]標記的轉移概率的函數,稱為轉移函數;[t′jyi,xi]是關于觀測序列和位置[i]標記的狀態特征的函數,稱為狀態函數;[λj]和[λ′j]分別為[tj]和[t′j]的權重,需要通過訓練得到。
最大可能的標注序列可通過維特比算法解碼得出:
3.2? 特征選擇
在使用CRF進行機構名稱識別時,除了語料大小會對結果產生重要的影響,特征模版也會對結果產生直接影響。本文針對老撾組織機構名實體識別的任務結合老撾語句子的詞匯特征、句法特征提取如下特征模板。
1) 詞匯上下文特征
根據老撾機構名的語言特性,本文將詞匯上下文特征的窗口設置為5。此時輸入句子序列的具體形式為[i=2NWi],其中,[N]為句子長度,[Wi]為一個大小為5的窗口,具體如下所示:
式中:[wi]為當前觀察的詞匯;[ti]為當前詞匯的標簽。具體的特征模板如表2所示。
2) 詞性特征
當前的觀察詞與該詞所對應的詞性[pi]。此時輸入的句子序列如下所示:
對應的詞性特征[wipi]也加入特征模板中。
3) 特征詞表
特征詞是表示該組織機構名實體類別屬性的構件[10],如“?????????????????(坦克?裝甲局)”中的“???(局)”即為一個特征詞。此處特征詞表與上一節中特征詞典內容一致。在輸入的句子序列中,加上一列特征詞標記[ci],如果當前觀察詞匯出現在特征詞表中,令[ci=Y],否則,令[ci=N]。
4) 左右指界詞表
指界詞即出現在機構名前或后的第一個詞,例如左指界詞????(通過)后面會伴隨出現機構名;右指界詞?????(主席)一般出現在機構名后。出現次數不同的指界詞對機構名邊界的指示作用不同,受語料大小所限,本文實驗中只取出現頻率最高的20個指界詞。同樣,在句子輸入序列中,加上一列左右指界詞標記[mi],如果當前觀察詞匯出現在特征詞表中,令[mi=Y],否則,令[mi=N]。
根據以上4個特征,構造4組不同的訓練語料:第一組為詞+[BIO]標簽;第二組為詞+詞性+[BIO]標簽;第三組為詞+詞性+特征詞表+[BIO]標簽;第四組為詞+詞性+特征詞表+左右指界詞表+[BIO]標簽。第四組語料標注示例如表3所示。
4? 實? 驗
4.1? 數據集
本文的實驗語料主要通過對老撾新聞網站的爬取,然后再通過老撾語專家和老撾留學生進行標注,并對語料進行分詞、詞性標注等預處理,并設計程序對左右指界詞進行統計。語料庫約18.9 MB,其中,70%的語料用來訓練,30%的語料用來測試。
4.2? 結果分析
本文使用3個指標對實驗結果進行評價,分別是準確率[P]、召回率[R]和[F]值。準確率指的是一個算法的查準率,召回率指的是一個算法的查全率,[F]值是綜合考慮準確率和召回率的指標[11]。計算公式如下:
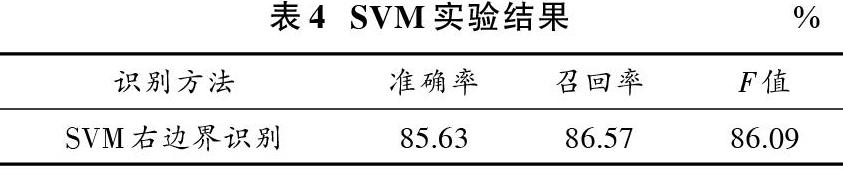
使用SVM模型對上述老撾機構名稱前綴詞的識別實驗結果如表4所示。
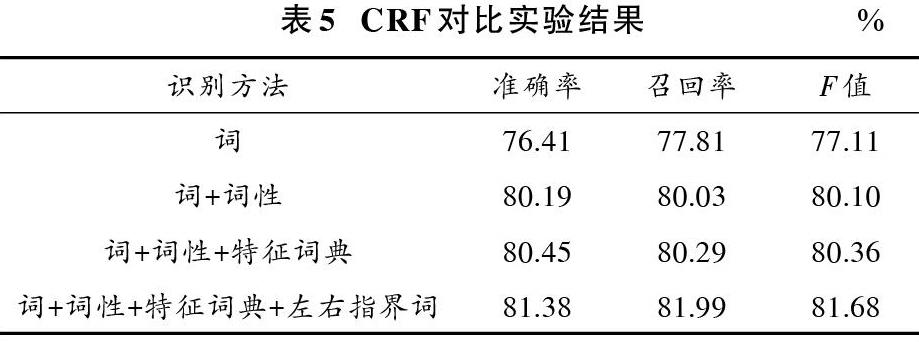
使用4組不同的模板訓練CRF模型,得到的對比實驗結果如表5所示。
使用SVM與融合多特征的CRF方法進行實驗,對比CRF模型中取得的最好實驗結果,對比結果如表6所示。
從實驗結果可以看出:由于標注語料有限,可以看出在詞與詞性的基礎上融合特征詞典的特征對識別準確率提升不大;CRF模型中融合了詞、詞性、特征詞典、左右指界詞的模型效果,在CRF的4組實驗中效果最好,說明融合的特征都是有效的。單純使用特征詞典+SVM模型,對老撾機構名左邊界的識別效果較好。基于SVM與融合多特征的CRF的模型在CRF的基礎上有效地提高了準確率,召回率沒有改變,說明SVM對左邊界的識別結果能夠有效剔除CRF中的錯誤實體結果,減小FP的數量,從而提高識別機構名實體的準確率。但是由于本文的實驗結果是基于正確分詞和詞性標注的基礎上,實際上分詞與詞性標注上的錯誤都會降低識別的精確度。
5? 結? 語
本文針對老撾語機構名稱構詞的語法特點,建立一種基于SVM和CRF的雙層模型,對老撾機構名稱進行識別。在特征詞詞典的基礎上,使用SVM模型對老撾語機構名稱特征詞進行識別,并通過CRF模型融合老撾機構名稱特征對機構名稱進行標注,結合SVM的前綴詞識別結果,有效降低了CRF模型預測錯誤實體的個數,從而達到了提高準確率的目的。
實驗表明,本文方法能夠獲得較好的老撾機構實體的識別準確率,但是不足之處也較為明顯,特征詞典為人工收集,對于未錄入特征詞詞典的機構名稱則無法進行識別,這還有待于后續進一步深入的研究;語料的不足也對實驗結果有一定的影響,后續工作還要繼續擴充標注好的語料庫。
參考文獻
[1] 武惠,呂立,于碧輝.基于遷移學習和BiLSTM?CRF的中文命名實體識別[J].小型微型計算機系統,2019,40(6):1142?1147.
[2] 段韶鵬.老撾語命名實體識別研究[D].昆明:昆明理工大學,2017.
[3] 祝繼鋒.基于SVM和HMM算法的中文機構名稱識別[D].吉林:吉林大學,2017.
[4] 李麗雙,郭元凱.基于CNN?BLSTM?CRF模型的生物醫學命名實體識別[J].中文信息學報,2018,32(1):116?122.
[5] 潘璀然,王青華,湯步洲,等.基于句子級Lattice?長短記憶神經網絡的中文電子病歷命名實體識別[J].第二軍醫大學學報,2019,40(5):497?506.
[6] 許華.基于有監督學習的醫療實體抽取方法研究[D].武漢:武漢科技大學,2016.
[7] 周曉磊,趙薛蛟,劉堂亮,等.基于SVM?BiLSTM?CRF模型的財產糾紛命名實體識別方法[J].計算機系統應用,2019,28(1):245?250.
[8] LAFFERTY J D, MCCALLUM A, PEREIRA F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data [C]// Proceedings the Eighteenth International Conference on Machine Learning. San Francisco: Morgan Kaufmann, 2001: 282?289.
[9] SARAWAGI S. Sequence segmentation using semi?Markov conditional random fields [J]. Journal of the Indian Institute of Science, 2019, 99(2): 215?224.
[10] 李明鑫.基于信息抽取的實體知識庫系統研究[D].北京:北京交通大學,2017.
[11] 羅鈺敏,劉丹,尹凱,等.加權平均Word2Vec實體對齊方法[J].計算機工程與設計,2019,40(7):1927?1933.
[12] 楊夢杰.老撾語命名實體識別方法的研究[D].昆明:昆明理工大學,2016.
