基于殘差空洞卷積神經網絡的網絡安全實體識別方法
2020-10-21 17:58:58謝博申國偉郭春周燕于淼
網絡與信息安全學報 2020年5期
謝博,申國偉,郭春,周燕,于淼
(1.貴州大學計算機科學與技術學院,貴州 貴陽 550025;2.貴州省公共大數據重點實驗室,貴州 貴陽 550025;3.中國科學院信息工程研究所,北京 100093)
1 引言
在網絡空間安全態勢日趨復雜的形勢下,威脅情報驅動的網絡安全防御成為業界關注的重點[1]。從海量碎片化的網絡數據中挖掘威脅情報,采用知識圖譜模型進行組織,支撐攻擊路徑預測、攻擊溯源等,可實現海量數據驅動的威脅情報智能分析。
網絡安全實體識別是威脅情報知識圖譜構建任務中非常重要的一個基礎任務[2],其目標是從網絡安全領域的文本數據中提取出安全實體的語義類,如攻擊組織、企業、漏洞、軟件等。
網絡安全實體識別屬于一種特定領域的命名實體識別。命名實體識別是自然語言處理中的一項重要研究內容,主要有基于規則的命名實體識別方法、基于機器學習的命名實體識別方法和基于深度學習的命名實體識別方法[3]。由于深度學習方法能夠自適應地提取文本的特征信息,不依賴大量的特征工程和額外的語言學知識,因此,深度學習被廣泛地應用在命名實體識別任務中[4]。
Georgescu等[5]通過基于命名實體識別的解決方案來增強和檢測物聯網系統中可能存在的漏洞。王通等[2]使用深度置信網絡對威脅情報知識圖譜實體識別子任務中的安全實體進行有效識別。2003年,Hammerton[6]利用長短記憶模型(LSTM)抽取句子的序列信息,并通過條件隨機場(CRF,conditional random fields)對命名實體的標簽進行分類。之后,很多命名實體識別方法是在LSTM-CRF網絡架構下融入各種句子隱含的特征信息。Collobert等[7]在2011年使用窗口化方法的神經網絡和基于句子的卷積神經網絡方法對命名實體識別進行了深入探索,在命名實體識別任務中取得了不錯的效果。隨后,Santos等[8]使用字符級的特征向量作為卷積神經網絡的輸入,來增強CNN-CRF模型。Chiu等[9]在Hammerton和Collobert等的工作基礎上使用雙向LSTM并融合卷積神經網絡來獲取詞的字符特征,與Collobert的模型相比,利用雙向LSTM模型打破固定窗口大小的限制。由于傳統的卷積神經網絡在提取大的上下文特征信息時會丟掉一些信息,2017年,Strubell等[10]提出利用空洞卷積神經網絡進行命名實體識別,實驗表明該網絡能夠彌補傳統卷積神經網絡的不足且進一步提高網絡的訓練速度。
He[11]、Liu[12]、Li[13]等通過實驗表明了基于字符的命名實體識別方法一般比基于詞的命名實體識別方法好。因此,秦婭等[14]針對傳統的命名實體識別方法難以識別網絡安全實體,提出一種基于特征模板的字符級CNN-BiLSTM-CRF網絡安全實體識別模型。除了基于字的命名實體識別,還有基于詞、融合字和詞特征信息的命名實體識別方法。Xu等[15]將字和詞的特征信息聯合訓練進行融合,其中,Zhang等[16]提出的Lattice LSTM中文命名實體識別網絡結構取得了較好的實體識別效果,該方法將傳統的LSTM單元改為網格LSTM,在字模型的基礎之上利用詞典,從而得到詞與詞序的特征信息,降低了分詞帶來的錯誤傳播問題。
注意力機制(attention mechanism)[17]被廣泛應用于自然語言處理任務。Bahdanau等[18]將注意力機制和循環神經網絡(RNN,recurrent neural network)結合起來解決機器翻譯任務,使注意力機制成功融入自然語言處理領域。Yin等[19]提出一種基于注意力機制的卷積神經網絡,并成功地應用于句子對建模任務。Wang等[20]在關系抽取任務中證明了注意力機制和卷積神經網絡結合的有效性。
與傳統領域的實體識別相比,網絡安全領域的實體識別發展比較緩慢,且仍存在以下幾方面的挑戰。
1)深度學習依賴大規模的標簽數據,然而網絡安全領域中缺乏大規模高質量的網絡安全實體標注數據。
2)網絡安全實體識別比較復雜,包含大量的多種混合安全實體,如“SQL注入”“80端口”。
3)全文非一致問題。即在一篇文章、段落或者長句子中相同的實體被賦予不同的類別標簽。此外,存在實體縮寫情況,即第一次提到實體時給出全稱,在其后提到該實體時,僅僅給出該實體的縮寫。
針對上述挑戰,本文提出一種殘差空洞卷積神經網絡的安全實體識別方法。本文的主要貢獻如下。
1)構建并開放了一個網絡安全實體識別語料庫,標注了6類典型的網絡安全實體。
2)提出一種基于BERT[21]語言模型的殘差空洞卷積神經網絡命名實體識別方法,與基于注意力機制的BiLSTM-CRF網絡結構相比,本文的模型可以接收句子的平行化輸入,降低了模型的訓練時間。
3)將殘差連接與空洞卷積神經網絡模型相結合,構建網絡安全實體識別模型,無須使用諸如詞性、依存句法等額外的特征信息。此外,以字符級特征向量作為模型的輸入,降低了分詞錯誤導致的誤識別率。實驗表明,本文提出的模型取得了比BiLSTM-CRF等模型好的安全實體識別效果。
2 任務定義
網絡安全實體識別任務可以看作特定領域中的命名實體識別,其相當于自然語言處理中的序列標注問題。由于網絡安全文本數據中的詞條存在歧義和安全實體構成比較復雜,為了防止分詞帶來的錯誤傳播問題,在字符層面進行序列標注是解決網絡安全實體識別的關鍵問題。
本文以網絡安全文本中的句子為基本單元,針對其中的任意一個句子,xN],xi是句子s中的第i個字符。在BIO標注方法[14]的指導下,識別句子s中的安全實體相當于給出標注序列。例如,句子s為“騰訊安全防御威脅情報中心檢測到一款通過驅動人生系列軟件升級通道傳播的木馬突然爆發”,其對應的序列標注sL是“B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG O O O O O O O B-SW I-SW I-SW I-SW O O O O O O O O O O O B-RT I-RT O O O O”。
3 基于殘差空洞卷積神經網絡的網絡安全實體識別模型
針對網絡安全實體識別任務,本文在BERT預訓練模型的基礎上,提出基于殘差空洞卷積神經網絡和CRF相結合的網絡安全實體識別模型BERT-RDCNN-CRF,如圖1所示。
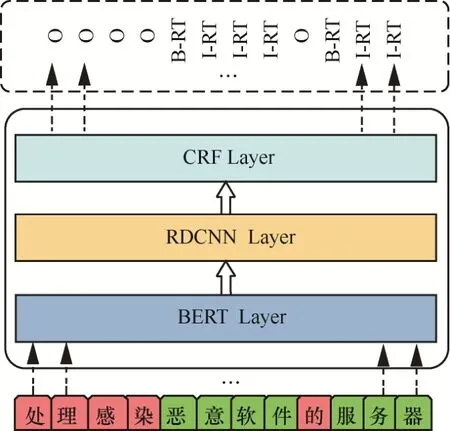
圖1 基于BERT-RDCNN-CRF的網絡安全實體識別模型Figure 1 Network security entity recognition model based on BERT-RDCNN-CRF
該模型在BERT預訓練模型的基礎上,采用RDCNN提取文本中的特征,為實體識別奠定基礎,最后通過CRF層處理給出標注序列。
3.1 BERT預訓練語言模型
BERT模型能從大量的無標簽數據中學習詞條或者字的前向和后向這種雙向表示,并且在學習詞條或者字的上下文表示過程中通過微調來解決詞或字的歧義問題。BERT模型的框架如圖2所示,其主要由輸入層、雙向的Transformer編碼層和輸出層組成。輸入層接收輸入句子的字嵌入(token embedding)、段嵌入(segment embedding)和位置嵌入(position embedding)拼接而成的一個特征矩陣。Transformer編碼層主要提取輸入層特征矩陣中重要的特征信息。輸出層通過一個前饋神經網絡輸出每一個字的嵌入表示。

圖2 微調BERT模型在單句標注任務圖示Figure 2 Illustrations of fine-tuning BERT on single sentence tagging tasks
本文以字為單位并將其作為BERT模型的輸入,對于長度為n的句子s,其字嵌入表示為

其中,⊕為拼接操作符。
由于本文的輸入為文本句子,所以對于長度為n的句子s,引入段嵌入作為句子對的區分界限。段嵌入全部初始化為0,如式(2)所示。

在網絡安全實體識別任務中,字的位置特征是識別的關鍵特征。因此,BERT模型加入了位置嵌入,如式(3)~式(5)所示。


其中,pos為位置,i為維度,dmodel為模型的輸出維度,為拼接操作符。
最后,將字嵌入、段嵌入和位置嵌入拼接起來作為BERT模型的輸入,如式(6)所示。
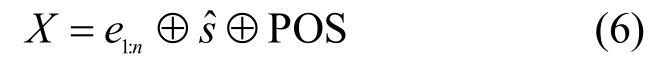
雙向Transformer編碼層通過“多頭”注意力機制(multi-head attention mechanism)擴展了模型專注于不同位置的能力,增大注意力單元的“表示子空間”。“多頭”注意力機制的基礎是自注意力機制,自注意力機制主要計算句子中的每個字對于這個句子中所有字的相互關系,即將與該字相關聯的其他字的特征信息編碼進該字的嵌入表示中。自注意力機制的計算如式(7)所示。
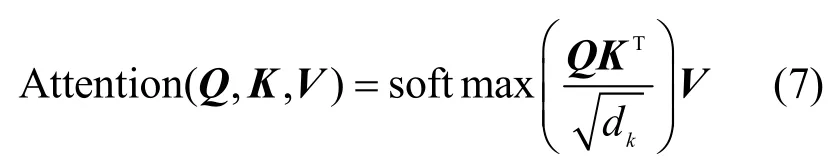
其中,Q、K、V分別是自注意力機制中的查詢向量(query vector)、鍵向量(key vector)和值向量(value vector),計算方法如下。
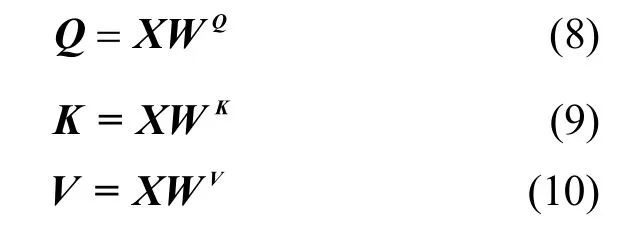
其中,WQ、WK、WV為權重矩陣,在模型開始訓練時隨機初始化。
由此,實現“多頭”注意力機制的計算如式(11)所示。
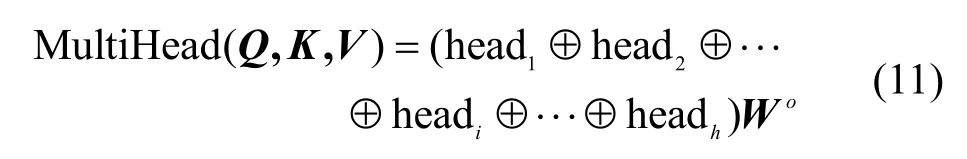
其中,⊕為拼接操作符,Wo為形狀變換矩陣,是一個需要學習的參數,headi=Attention,。
最后,通過一個全連接層,輸出每個字的嵌入表示,其計算如式(12)所示。
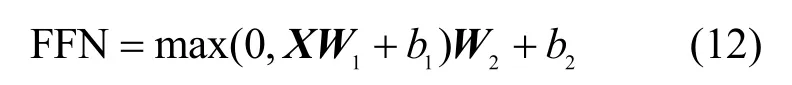
其中,W1、W2為權重矩陣,b1、b2為偏置,FFN為BERT模型的輸出結果。
3.2 RDCNN -CRF命名實體識別模型
本節在BERT模型的基礎上,提出網絡安全實體識別模型RDCNN-CRF,如圖3所示。RDCNN-CRF主要由輸入層、空洞卷積層和CRF層組成。輸入層接收輸入句子的特征矩陣;空洞卷積層利用卷積核對輸入的基本單位進行卷積操作提取特征。RDCNN的輸入層將BERT模型的輸出構建為一個特征矩陣傳入模型中;CRF層通過提取到的特征信息輸出字的命名實體標簽分類結果。

圖3 RDCNN-CRF模型框架Figure 3 Illustrations of RDCNN-CRF model framework
在空洞卷積神經網絡的卷積層中,給定長度為h的卷積核,可以把句子分為,然后對每一個分量進行卷積操作,通過式(13)得到卷積特征圖。
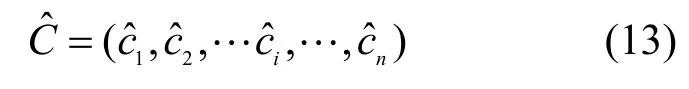
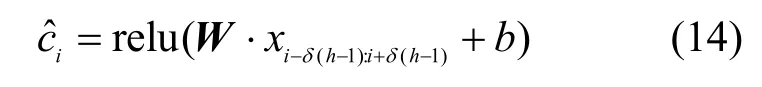
其中,W為卷積核權重,b為偏置,δ>1為空洞卷積神經網絡的膨脹系數。若δ=1,此時的空洞卷積神經網絡和傳統的卷積神經網絡等價。
由于對空洞卷積神經網絡的卷積層進行簡單的線性堆疊會使網絡在訓練過程中產生過擬合和退化問題,本文引用文獻[22]提出的殘差連接來防止退化問題,使用批正則化(BN,batch normalization)防止過擬合問題。殘差連接的殘差塊計算如式(15)所示。

其中,x為輸入,F()表示殘差函數。
最后,通過CRF層得到字的實體標簽分類結果。CRF能夠考慮相鄰字的實體標簽之間的關系,這符合字的實體標簽關系之間并不獨立的特點,且充分利用了字實體標簽的上下文信息。而通過直接對殘差空洞卷積神經網絡的輸出獲取其對應字的實體標簽的結果取決于數據的性質和質量。CRF層的具體算法如下。
首先,定義一個狀態轉移矩陣A,這里的Ai,j表示標簽i轉移到標簽j的得分,該得分會隨著模型的訓練而更新。另外,定義分值矩陣為空洞卷積層的輸出分值,其中,[fθ]i,t是第t個字、第i個標簽的RDCNN的輸出分值,θ是RDCNN的參數。針對句子,N為句子的長度。定義為整個RDCNN-CRF模型需要學習的參數。這樣,一個句子在給定標簽序列的總得分計算為
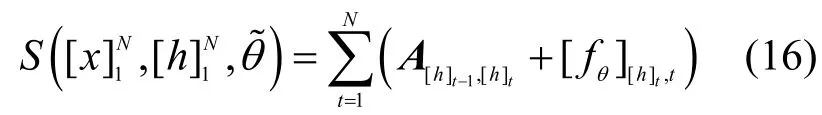

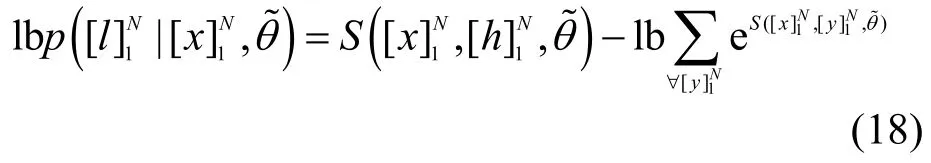
模型訓練結束后,本文采用維特比算法來找到最佳標簽序列。
3.3 模型訓練過程
本文基于Tensorflow深度學習框架實現所提出的網絡安全實體識別方法,具體訓練過程如下。
本文提出的安全實體模型在訓練的過程中先對BERT、RDCNN和CRF模型進行初始化,然后BERT對字進行編碼,隨后RDCNN進行解碼提取出句子局部特征信息,接著CRF模型計算出字的安全實體標簽;最后將錯誤向前傳播更新各個模型的參數。
算法1BERT-RDCNN-CRF
輸入
訓練數據集T=(X,Y),其中,X,Y∈?V×n,|V|是數據集的大小,n是句子最大長度;
輸出
實體標簽序列;
1)初始化BERT,RDCNN和CRF;
2)fori=0,1,2,do
3)for batch do
4)BERT和RDCNN模型前向傳播;
5)CRF前向傳播和后向傳播,計算出序列的全局似然概率;
6)對RDCNN和BERT模型進行后向傳播;
7)更新BERT,RDCNN,CRF模型的參數;
8)end for
9)end for
4 實驗與結果分析
本節將所提出的方法在構建的數據集上進行實驗。在本文的實驗中,字向量均采用Google預訓練好的BERT中文字向量。BERT模型采用Fine-tuning策略,即模型參數采用Google預訓練好的參數進行初始化,并可以在網絡訓練過程中自適應地調整BERT模型的參數。
4.1 實驗數據
實驗數據主要來自烏云漏洞數據庫、Freebuf網站、國家漏洞庫等主流網絡安全平臺的公開數據。網絡安全實體主要有6種類型,分別是人名(PER,person)、地名(LOC,location)、組織名(ORG,organization)、軟件名(SW,software)、網絡安全相關術語(RT,relevant term)和漏洞編號(VUL_ID,vulnerability ID)。網絡安全實體數據均采用BIO命名實體標注策略。數據集的具體統計信息如表1所示。實驗中將標注好的數據集劃分為訓練集、驗證集和測試集,分別占總數據集規模的70%、10%和20%。詳見Github官網。

表1 數據集的統計信息Table 1 Statistic of datasets
本文采用精確率(P,Precision)、召回率(R,Recall)、F1值(F1-measure)和準確率(Accuracy)作為評價標準。
4.2 對比實驗
為了驗證本文提出的網絡安全實體識別方法BERT-RDCNN-CRF的有效性,對12種模型進行對比實驗。其中,前6組實驗的詞向量和字符向量是基于word2vec語言模型訓練的,后 6組基于BERT預訓練語言模型。實驗代碼可到Github官網下載。
1)CRF:文獻[23]提出使用CRF對序列數據進行標注。
2)LSTM:文獻[24]提出使用LSTM進行命名實體識別的模型。
3)LSTM-CRF:文獻[25]提出結合CRF的LSTM命名實體識別模型。
4)BiLSTM-CRF:文獻[26]提出考慮詞上下文的雙向LSTM結合CRF進行命名實體識別模型。
5)CNN-BiLSTM-CRF:文獻[27]提出使用CNN學習詞條的字符級特征信息,并將其和詞拼接在一起作為BiLSTM的輸入進行命名實體識別的模型。
6)FT-CNN-BiLSTM-CRF:文獻[14]提出結合特征模板的網絡安全實體識別模型。
7)BERT-CRF:在文獻[21]中模型的基礎上結合CRF進行命名實體識別的模型。
8)BERT-LSTM-CRF:在文獻[25]的基礎上將語言模型使用BERT代替。
9)BERT-BiLSTM-CRF:在文獻[26]的基礎上將語言模型使用BERT代替。
10)BERT-GRU-CRF:在BERT的基礎上,使用普通GRU與CRF結合的命名實體識別模型。
11)BERT-BiGRU-CRF:在BERT的基礎上,使用普通雙向GRU與CRF結合的命名實體識別模型。
12)BERT-RDCNN-CRF:本文提出的識別方法彌補了CNN提取特征信息有限,并使用殘差連接防止模型在訓練的過程中出現過擬合的情況。
4.3 實驗模型參數
在實驗中,使用多種窗口卷積核對BERT的輸出矩陣進行卷積操作。卷積核函數為rectified linear units,激活函數為Leaky ReLU。模型訓練過程中采用Zeiler[28]提出的Adadelta更新規則,其他參數見表2。

表2 實驗參數設置Table 2 Hyper parameters of experiment
4.4 整體對比實驗及分析
本文將12組實驗在網絡安全實體識別數據集上進行實驗,分析網絡安全實體識別。表3給出了12組實驗在網絡安全實體識別數據集上總體的實體識別準確率、精確率、召回率和F1值。
從表3結果可以看出,整體上本文提出的方法在網絡安全實體數據集上取得了不錯的實體標簽分類效果。其中,BERT-CRF、BERT-LSTMCRF、BERT-BiLSTM-CRF、BERT-GRU和BERTBiGRU-CRF模型在網絡安全實體數據集中的命名實體識別準確率比傳統基于特征的CRF命名實體識別模型、LSTM模型、BiLSTM模型、CNN-BiLSTM模型和基于特征模板的FT-CNNBiLSTM模型好。
對比文獻[26]提出的CNN-BiLSTM-CRF模型和文獻[13]提出的FT-CNN-BiLSTM-CRF模型可以看出,考慮了字特征信息的BERT-RDCNNCRF模型在網絡安全實體數據集上的實體識別準確率相比考慮了詞特征信息和字特征信息的模型的準確率高。這是因為網絡安全的實體是由字母、數字和中文構成的,在分詞的過程中會產生大量的分詞錯誤,這種錯誤會隨著模型的訓練往后傳播,影響模型最后對實體標簽的分類效果。
從表3的結果還可以看出,模型BERTCRF的F1值相比不使用BERT模型的實體識別模型沒有提高,但是加了能夠提取文本的句法和表層特征的序列模型后,其F1值有較大的提高。說明安全實體識別模型在含有豐富的語義特征基礎上利用文本的句法和表層特征能提高實體識別性能。
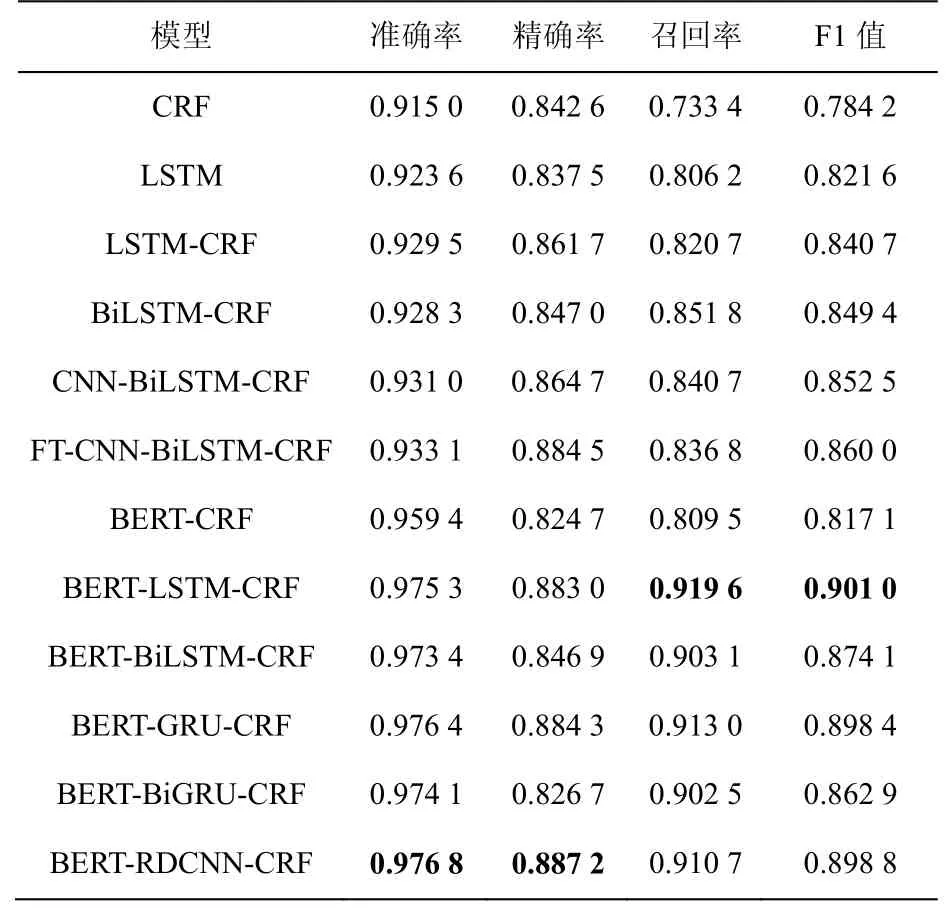
表3 不同模型的網絡安全實體識別對比結果Table 3 Comparison of cyber security entity recognition results of different models
為了進一步說明基于BERT預訓練模型的LSTM、BiLSTM、GRU和BiGRU模型與本文提出的方法在網絡安全實體識別任務中的實體識別效果,本文進一步做了對比實驗。從表3的結果可以看出,在準確率和精確率方面,本文提出的方法比其他基于BERT模型的網絡安全實體識別模型好,說明本文提出的方法在網絡安全實體識別任務中的有效性,并且在使用BERT模型的前提下,單向的LSTM模型和GRU模型比雙向的LSTM模型和GRU模型在網絡安全實體識別任務中效果更好。然而,從召回率和F1值的結果來看,BERT- LSTM-CRF均取得了最好的結果,分別是91.96%和90.10%。與本文提出的方法在召回率(91.07%)和F1值(89.88%)上相比,分別提升了0.89%和0.22%,說明本文提出的方法在這兩個評價指標上與能夠提取字的序列特征的模型相比差距不大。
4.5 6類安全實體識別對比實驗及分析
為了進一步比較基于BERT模型的安全實體識別模型在不同安全實體上的識別效果,本文計算出這6種安全實體的精確率、召回率和F1值,其中精確率如圖4所示。
從圖4可以看出,BERT-CRF模型在SW和VUL_ID兩類安全實體上的實體識別效果非常差。所有實體識別模型在安全實體SW上的精確度比較低,最高的精確率才50.26%,其中BERT-LSTM-CRF模型、BERT-GRU-CRF模型和BERT-RDCNN-CRF模型的精確度相近,說明這些模型不擅長識別安全實體SW,這是因為一方面該實體在安全實體數據集中的數量較少,另一方面這類實體通常由數字、字母和漢字組成,構成非常復雜,特征不好提取。
6種安全實體識別模型在安全實體LOC、ORG和PER上的實體識別效果相差無幾且精確率較高,說明6種模型能夠對LOC、ORG和PER這種簡單的實體特征信息進行充分提取。對于安全實體RT,BERT-CRF模型的精確率最低,本文提出的方法比BERT-LSTM模型的精確率高0.52%,說明無論是使用改進的卷積網絡還是使用能夠存儲句子序列信息的LSTM,在安全實體RT上都能取得較好的精確率。在安全實體VUL_ID的結果中,BERT-GRU-CRF模型取得了最高的精確率,比BERT-LSTM-CRF模型提升了0.28%,比本文提出的方法提升了4.13%,說明能夠存儲句子序列信息的LSTM模型和GRU模型在安全實體VUL_ID的精確率上更有優勢。
從圖4中還可以看出,使用雙向BiLSTM模型和雙向BiGRU模型的精確率比使用單向的LSTM模型和GRU模型的精確率低,這是因為模型的復雜度增加會產生過擬合問題,損失函數的損失值在模型訓練過程中很難下降。為了更進一步比較6種模型的安全實體識別性能,對不同模型在不同安全實體上的召回率進行對比,如圖5所示。
從圖5的結果可以看出,6種模型在6類安全實體上的召回率和圖4的結果差不多。值得注意的是,BERT-LSTM-CRF模型和BERT-GRUCRF模型比其他模型取得了更好的召回率,這說明在召回率這一評價指標上,這兩種模型能夠召回更多的安全實體。

圖4 不同模型在不同安全實體上的精確率對比Figure 4 Comparison of accuracy of different models on different security entities

圖5 不同模型在不同安全實體上的召回率對比Figure 5 Comparison of recall of different models on different security entities
為了平衡精確率和召回率,不同模型的F1值如圖6所示。從圖6中可以看出,BERT-CRF模型、BERT-BiLSTM-CRF模型和BERT-BiGRUCRF模型對于復雜的安全實體RT、SW和VUL_ID的識別效果不是很好。對于安全實體PER的識別效果這6種模型相差無幾,說明這6種模型都適合用來識別PER這樣的安全實體。對于安全實體LOC的識別效果,BERT-RDCNN- CRF模型、BERT-LSTM-CRF模型、BERT-GRU- CRF模型和BERT-BiGRU-CRF模型的F1值比BERT-CRF模型和BERT- BiLSTM-CRF的F1值有不同程度的提升。對于安全實體ORG,BERT-RDCNN-CRF模型和BERT-LSTM-CRF模型的F1值比其他模型的F1值有不同程度的提升。以上結果表明,本文提出的方法在各種安全實體識別任務中的魯棒性和有效性。
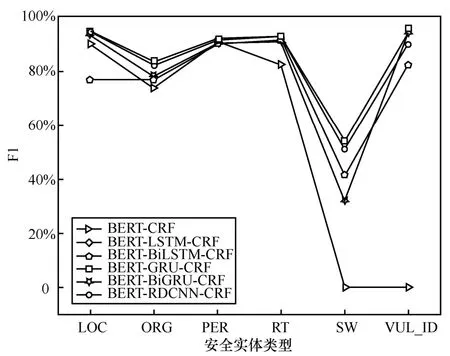
圖6 不同模型在不同安全實體上的F1值對比Figure 6 Comparison of F1-measure of different models on different security entities
4.6 參數調整分析
本文提出的安全實體識別方法和其他傳統的神經網絡方法一樣,通過最小化損失函數來進一步更新模型的參數。而損失值在模型訓練過程中的變化情況表示該模型在訓練過程中是否學習和是否穩定等。進一步分析模型在訓練過程中損失值的變化情況如圖7所示。
從圖7可以看出,模型在整個訓練過程中損失值是下降的,說明模型能夠學習網絡安全實體的相關特征信息。此外,由于本文提出的方法參數太多并且損失值整體上下降,進一步表明本文模型在訓練過程中具有魯棒性。從圖7中還可以看出,損失值的下降曲線并不是平滑的,這主要與最小化損失函數的優化算法和學習率的設置有關,從整體上看依然能夠說明本文所提方法的魯棒性。
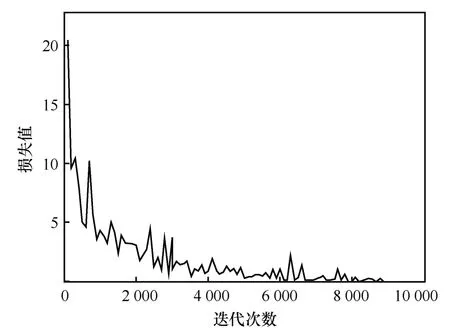
圖7 損失值曲線Figure 7 Loss value curves during training on network security entity datasets
4.7 實例分析
為了進一步分析本文提出方法的實用性,從網絡安全實體識別數據集中抽取一些典型句子的實體標簽分類結果進行分析。經典句型分析如表4所示。
從表4中可以看出,對于句子1這種結構簡單的實體識別,本文提出的方法能正確識別出實體的標簽。在句子2中,本文提出的方法除了準確識別出安全實體PER和RT,還識別出了安全數據測試集中沒有標注的ORG實體類型。另外,在句子3和句子7中,本文提出的方法均能準確識別出安全數據測試集中沒有標注的ORG和SW實體類型,說明本文提出的方法具有識別與訓練集中相似實體的新實體的能力。對于句子8和句子9這種VUL_ID類型的英文字母和數字構成的實體,不管該實體是單獨出現在句子中還是成對出現在句子中,本文提出的方法均能準確識別出該類型的實體。此外,諸如“暗云Ⅲ”這種漢字加羅馬字符的安全實體,本文提出的方法均能準確將其識別出來。“IP地址”這類英文字母加漢字構成的實體也能被準確識別出來,如句子5所示。
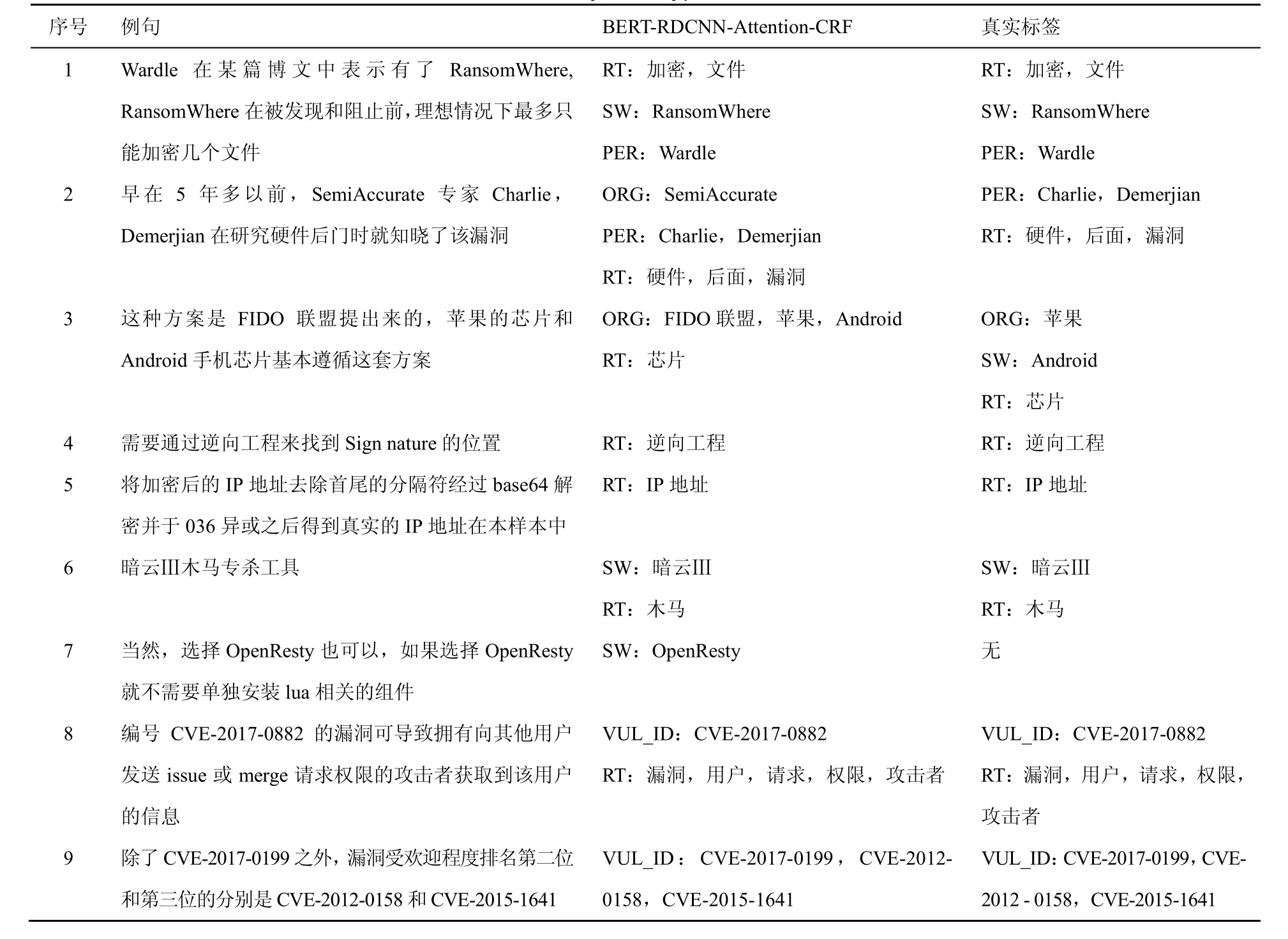
表4 經典句型例子分析Table 4 Analysis of typical sentences
然而,在句子3中,前一個實體“芯片”被準確識別出,而后一個實體“芯片”卻沒有被準確識別出來,Android卻被誤識別為ORG實體類型,這可能是因為Android前面有兩個ORG實體類型,算法在提取上下文信息的時候誤認為android也是ORG類型的實體。
除了表4展示的這些典型例子,在實驗過程中,對于較長的ORG這種實體類型算法,往往不能準確將其識別。換句話說,對于名稱較長的實體,不管是構成簡單的還是構成復雜的模型往往不能將其準確識別出來。所以,本文提出的方法更加適用于安全實體中名稱不是很長和實體構成相對規律的安全實體。
5 結束語
針對開放網絡文本數據中的安全實體構成非常復雜的問題,本文提出了一種基于殘差空洞卷積神經網絡的網絡安全實體識別方法。使用BERT模型對字進行向量化表示,進一步結合空洞卷積神經網絡和CRF準確地識別網絡安全實體。在網絡安全實體識別數據集上的實驗結果表明,本文提出的基于殘差空洞卷積神經網絡的方法在準確率和精確率方面優于許多已有的實體識別方法。
通過分析經典句型可以看出,本文提出的方法在某些安全實體類型的識別上是存在不足的,仍然不能準確識別出一些安全實體。在下一步的工作中,考慮從網上爬取大量的網絡安全數據,使用表示能力較強的語言模型訓練出網絡安全領域的字嵌入。并且,針對網絡安全數據集中安全實體的數量不平衡問題,對相應的安全實體數量進行補充或者在模型訓練的過程中采用解決數據不平衡的訓練技巧。此外,進一步提高較長的安全實體的識別準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
小學生必讀(中年級版)(2018年4期)2018-07-05 06:00:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
