基于深度學習的隱私攝像安全防護方案
2020-10-30 05:49:00劉田田
科學技術創新 2020年31期
劉田田
(江蘇開放大學信息工程學院,江蘇 南京210017)
現代社會,安全隱私是每個人甚至每個企業不得不面對的問題,安全隱私涉及到的問題,在生活中隨處可見,如教育、醫療、交通等領域。近年來,隨著網絡技術的發展,視頻作為信息傳遞載體具有諸多優勢,而視頻來源的重要設備——攝像頭則備受關注。如何安全、可控的采集視頻成為使用者不得不面對的問題。現有技術的重點僅僅為了保護視頻的安全,然而內容的安全卻少有關注。2010 年新一代信息技術變革,深度學習技術也隨之迅猛發展,因此利用深度學習來進行研究探索視頻內容的安全與可控問題,不失為一種有效的方法。
1 研究現狀
1956 年美國漢諾斯小鎮的達特茅斯“用機器來模仿人類學習以及其他方面的智能”的會議上,“人工智能”首次被提出,經歷了繁榮、低谷的輪回期,于2010 年新一代信息技術引發的海量信息與數據的變革中迎來了增長爆發期。深度學習是機器學習研究領域目前發展勢頭最好的一個新的領域,由Hinton 等人于2006 年,在頂級期刊《科學》上的一篇論文中提出[1],核心是模擬人腦的機制來解釋數據,例如圖像、聲音和文本。對人工神經網絡進行學習訓練,試圖尋找最優解。語義分割,是計算機視覺中的基本任務,在語義分割中我們需要將視覺輸入分為不同的語義可解釋類別,也就是像素級圖像分類任務[2]。視頻動作識別也是深度學習領域一個較新的研究方向,潘陳聽等人研究了復雜背景下的視頻動作識別[3]。
2 技術分析
U-Net[4]是Olaf Ronneberger 等人參加ISBI Challenge 提出的一種分割網絡,能夠適應很小的訓練集(大約30 張圖)。U-Net 是很小的分割網絡,既沒有使用空洞卷積,也沒有后接CRF(隨機場),結構簡單。整個U-Net 網絡結類似于一個大大的U 字母:首先進行Conv+Pooling 下采樣;然后Deconv 反卷積進行上采樣,crop 之前的低層feature map,進行融合;然后再次上采樣。重復這個過程,直到獲得輸出388x388x2 的feature map,最后經過softmax 獲得分割圖。總體來說與FCN 思路非常類似。U-Net 采用將特征在通道維度拼接在一起,形成更“厚”的特征。
MTCNN 網絡是Kaipeng Zhang 等人于2016 年發表的“基于多任務級聯卷積神經網絡的人臉檢測和對齊”一文中提出[5],主要作用主要可以實現特定目標檢測與對齊,其網絡結構為三層網絡。第一層PNet 網絡的結果經過bounding boxes regression 和NMS 處理之后變為24*24 的圖像大小放入第二層處理;第二層RNet 處理后的結果同樣經過bounding boxes regression 和NMS處理變成48*48 大小圖像放入第三層處理;結果同樣經過bounding boxes regression 和NMS 處理輸出目標框與類別信息。
3 系統分析與設計
本方案所應用的語義分割深度網絡U-NET 是一種經典網絡,最初用來處理醫學影像問題,經過改進后用來處理分割人體前景與背景的問題。基于深度學習的圖像分類技術,是輸入圖像對該圖像內容分類的描述的問題。本方案所應用的手勢分類深度網絡MTCNN-P 為較淺網絡,最初用來處理人臉識別定位問題,經過改進后用來處理手勢識別的問題。基于深度學習的人臉識別技術,是當下人臉識別的主要方向,以數據作為驅動引擎,解決諸多傳統算法的弊端。本方案所應用的人臉識別網絡為IsightFace 網絡,用來解決視頻中人臉識別的問題。
3.1 功能分析
本方案采用改進MTCNN 網絡,即MTCNN-P 網絡。MTCNN網絡模型尺寸足夠小,使得其可以應用于嵌入式,滿足系統性能要求。MTCNN 網絡主要作用主要可以實現特定目標檢測與對齊,其網絡結構為三層網絡。微調后MTCNN-P 其基本的構造是一個簡單分類網絡,去除原有的框回歸,輸出二值信息,判斷類別。基于MTCNN-P 的手勢分類采用的是基于深度學習的普通分類算法,該網絡用來檢測人臉,可以勝任簡單的分類任務。
IsightFace 網絡核心部分損失函數(Centre loss)主要懲罰了深層特征與其相應的歐幾里得空間類中心之間的距離,以實現類內緊湊性。假設在最后一個完全連接的層中的線性變換矩陣可以用角空間中的類中心來表示,并且以乘法方式懲罰深度特征與其相應的權重之間的角度。特征和最后一個完全連接的層之間的點積等于特征和權重歸一化之后的余弦距離。利用余弦函數(arc-cosine function)計算人臉特征和目標權重之間的夾角。然后,在目標角度上增加一個附加的角余量,通過余弦函數再次得到目標logit。最后,用一個固定的特征范數重新縮放所有logits,并且后續步驟與softmax loss 中的步驟完全相同。傳統的softmax loss 損失函數為:
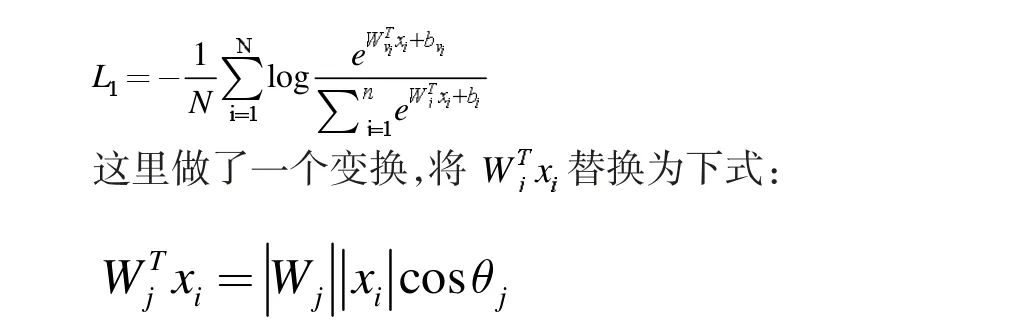
也就是向量內積的結果是向量各自的模相乘,在乘上向量夾角的余弦值。那么向量相乘得到的結果其實就是xi對應在第j 類的夾角。然后使用L2 正則化處理Wj使得,L2 正則化就是將Wj向量中的每個值都分別除以Wj的模,從而得到新的Wj,新的Wj的模就是1,實際上是個方向向量進而獲得概率。

3.2 系統設計
集成三種深度神經網絡,分別實現人體輪廓分割、手勢識別、人臉識別三大功能。人體輪廓分割為主要處理任務,手勢識別與人臉識別相當于外層邏輯,實現“隱私”控制。整套系統架構如圖1 系統架構圖所示。
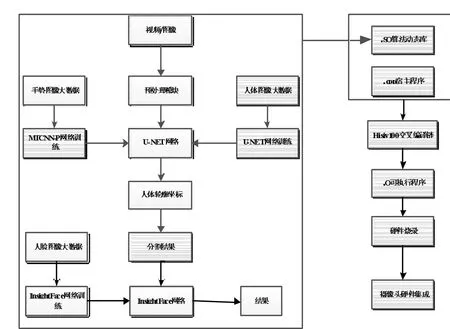
圖l 系統架構圖
整體代碼為C++程序,便于后續集成宿主程序。深度學習模型代碼文件經過特定平臺編譯器,生成.SO 算法動態庫,這個動態庫與宿主程序經過Hisiv100 交叉編譯工具生成.o 可執行程序,燒錄進攝像頭,實現最終軟硬件結合。
集成到攝像頭終端的三個深度學習模型,為提前訓練好的模型。為了滿足在嵌入式設備上運行深度學習模型,需要進一步優化。本方案使用了常見的int8 量化方法,進一步壓縮模型,提升性能。原始圖像經過預處理模塊簡單進行噪聲過濾處理,消除常見噪聲對圖像質量的影響。圖像在進入U-NET 網絡之前,會進行手勢判斷,檢測手部區域并定位手部關節點,根據手部關鍵節點的形狀判斷屬于哪種手勢。這個手勢為人的手掌“OK”造型時,表示驗證通過,視頻流可以進入U-NET 網絡。這樣做的目的就是錄像的自主可控,在不想要錄制的時候可以“示意”攝像頭“拳頭”造型,表示終止視頻流。視頻流進入U-NET 網絡,實現人體輪廓分割,得到輪廓坐標,進一步提取人體前景與背景信息,并對背景部分進行遮擋,實現視頻流隱私的保護。在進行最終結果輸出的時候,會進行人臉識別判斷,如果非設定人員,則不會輸出最終結果,實現視頻流的自主控制。
本方案組合新穎,核心部分均采用以數據為驅動的深度學習網絡,對原創視頻(直播)數據進行多層防加密護,真正做到數據的安全自主可控。系統架構清晰,可輕松移植到嵌入式、服務器中,而且不需要過多代碼。整個架構魯棒性較強,應對人為破壞能力較強,安全性和穩定性較高。
結束語
本方案為了解決視頻內容的安全與可控問題,提出集成三種深度神經網絡。通過人體輪廓分割處理視頻內容任務,通過手勢識別與人臉識別,實現“隱私”控制。本方案中集成到攝像頭終端的三個深度學習模型,是提前訓練好的模型,若將該模型應用到嵌入式設備上,后續需要進一步優化。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學生天地(2020年31期)2020-06-01 02:32:06
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
