基于預約帶寬的HTB 改進算法的研究?
2020-11-02 09:00:12孟祥奎張瓊聲李村合徐晨升
計算機與數字工程 2020年9期
關鍵詞:設置
孟祥奎 張瓊聲 李村合 徐晨升
(中國石油大學(華東)計算機與通信工程學院 青島 266580)
1 引言
在互聯網時代,網絡上的數據量出現了爆炸式的增長,如何實現高帶寬低延遲的網絡通信具有現實意義。網絡通信對數據處理的延遲要求往往會很高,比如使用即時聊天軟件時,用戶幾乎感覺不到數據處理和傳輸的延遲。如何實現這種高效率的網絡數據的處理,在操作系統層面減小數據傳輸延遲相關的理論和技術研究具有重要意義。
在數據包的傳輸過程中,操作系統內核負責完成對數據包的封裝和解封裝;帶寬分配以及數據包發送方式;采用輪詢或觸發中斷的方式,查看網卡是否有數據包到達,以及是否接收。因此,數據包在傳輸的過程中的延遲主要包括五個部分:數據包的封裝、數據包的發送、數據包在網絡中間設備中的傳輸、數據包的接收以及數據包的解封裝。為了提高帶寬的利用率,降低數據包發送延遲,系統為每個網絡設備設置隊列規則。將到達的數據包按照一定的規則進行分類,并為每個分類分配不同的帶寬,根據隊列規則的設置,每次選擇一個數據包進行發送。本文針對常用的HTB 帶寬分配算法,在數據包發送的過程中,通過對各個應用程序的帶寬使用的歷史狀況進行分析,將帶寬合理地分配給各個應用程序,降低數據包在發送過程中的時間消耗,降低數據包傳輸的時延,提高帶寬的利用率。
本文主要闡述HTB 算法、HTB 的改進算法、實驗與性能評估。
2 HTB算法
HTB 算法,全稱為Hierarchical Token Bucket,分層令牌桶算法,是一種功能強大的流量整型算法。
2.1 HTB算法的基本結構
HTB算法在Linux內核中被實現為一種樹形分層結構,如圖1所示。
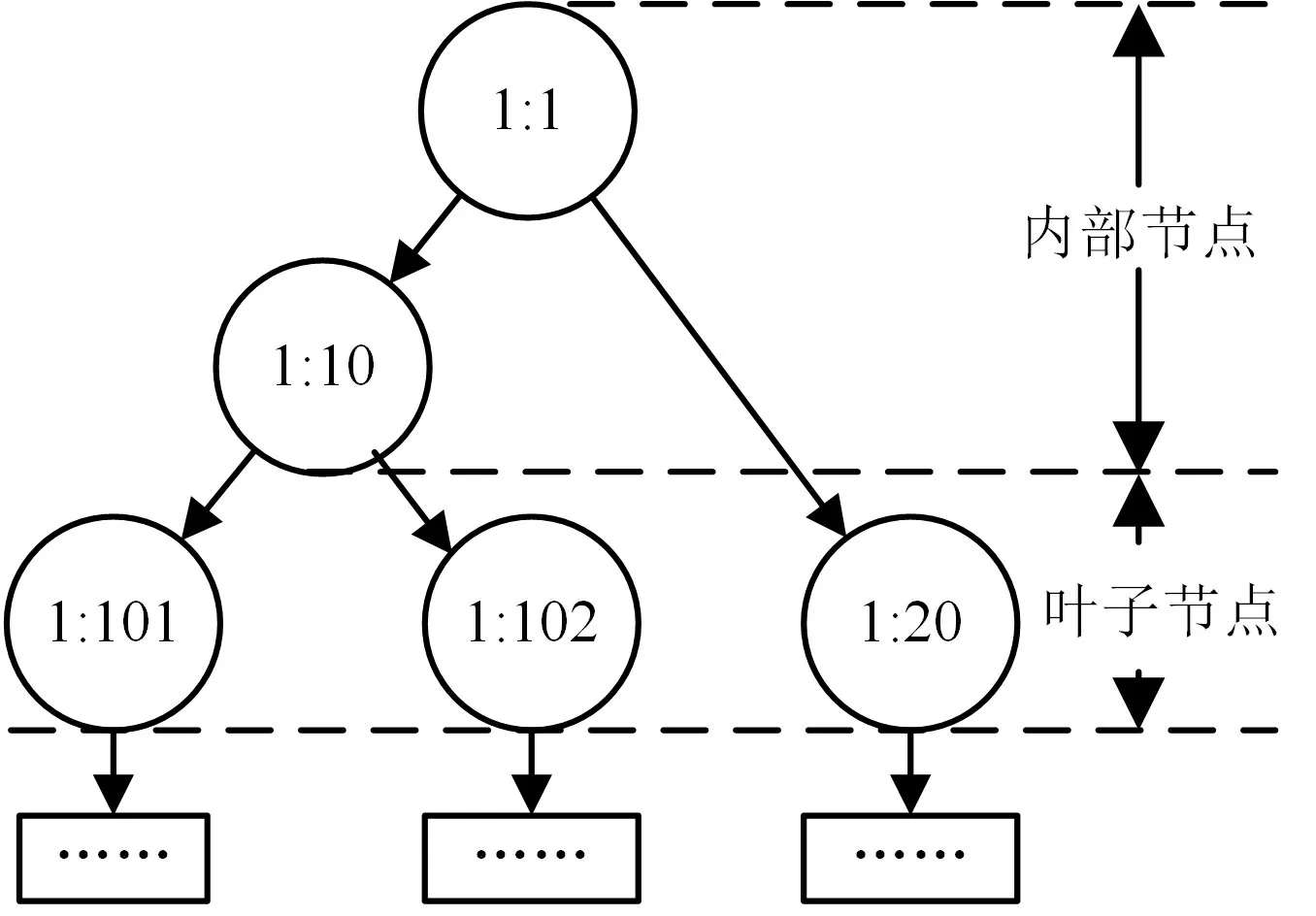
圖1 HTB算法結構圖
HTB 算法主要包括三個部分:隊列規則(Qdisc,Queue Discipline)、分類(Classes)以及分類器(Filters)。Linux 內核為每個網絡設備設置一個隊列規則,規定到達這個網絡設備的數據包如何分類、如何獲取、如何發送,以及帶寬如何分配[3]。
在HTB 算法中,節點分為兩類:內部節點和葉子節點[5]。內部節點中,根節點作為入口與數據流進行交互,其余內部節點實現對流量的整形、令牌租借等功能。內部節點不掛載數據包,只有葉子節點中才掛載數據包。每個節點中設置如下參數,實現高效的令牌租借機制:節點模式(cmode)、保證速率(AR,Assured Rate)、最大速率(CR,Ceil Rate)、額定量(Quantum)、優先級(priority)以及節點層級(level)。
Linux 內 核 中 節 點 模 式 有 三 種 :HTB_CANT_SEND ( 無 法 發 送 模 式) 、HTB_MAY_BORROW( 可 租 借 模 式)以 及HTB_CAN_SEND(可發送模式)。
AR 和CR 是為每個節點設置的兩個閾值。AR表示系統保證該節點可以獲得的數據包的發送速率。當數據包發送速率小于AR 時,節點處于可發送模式,無限制。CR 為系統能為該節點提供的最大的數據包發送速率。當數據包發送速率大于CR時,節點變為不可發送模式。當數據包發送速率介于AR和CR之間時,表明該節點處于可租借模式。
Quantum 為額定量參數,系統從某節點獲取數據包時,累計數據包的字節總數超過此數值或者數據包剩余個數為0 時,就要停止從此節點中獲取數據包,轉向處理其他的節點。同時,在節點向其父節點租借令牌時,也是以Quantum為單位。
Linux 內核中,共設置8 個不同的優先級,用于描述數據包發送的先后順序。
節點層級表示該節點在HTB 算法的樹結構中所處的層次,葉子節點為0層。
2.2 HTB算法執行流程
HTB算法的執行流程主要包括兩個部分:數據包的入隊列和出隊列。當數據包到達網絡設備時,根據數據包的優先級、目的IP 地址等信息進行分類,進入到不同的數據鏈路中,加入到葉子節點的數據包隊列。以圖2為例,介紹HTB算法的執行流程。
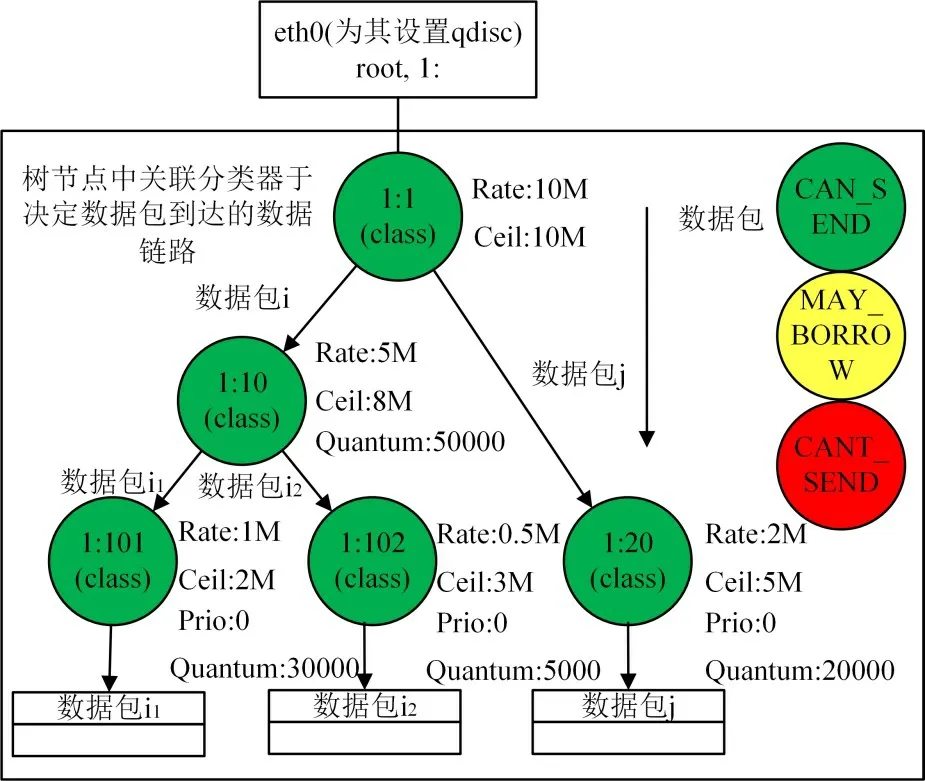
圖2 HTB算法樹結構圖
網絡設備的名稱為eth0,在eth0上根據HTB算法設置隊列規則,并為該隊列規則分配ID 為1。樹節點的id 包括兩部分,左側部分表示隊列規則的id,右側表示節點id。根節點的id 為1:1。其余四個id 的節點如圖2 所示。假設該網絡設備可用的帶寬總量為10M。在根節點時還未進行帶寬的分配,所以根節點的Rate 和Ceil 參數相同,均為10M。HTB 算法為不同的數據流分配不同量的帶寬,以保證不同應用的帶寬需求。將節點1:10 的Rate 值設置為5M,節點1:20 的Rate 值設置為2M,兩個節點的Rate參數之和小于10M,但是兩個節點的Ceil 參數之和大于10M,當有節點流量突增時,存在調節的空間,使系統具有一定應對流量突發狀況的能力。在Linux 系統中,Quantum 參數的設置默認為Rate 參數的1/10。在此處,節點1:10 的Quantum 設 置 為50000,1:20 的Quantum 設 置 為20000,其余節點的Rate、Ceil 和Quantum 參數設置均如圖2 所示,單位為字節,使得不同的數據鏈路占用網絡設備的時間不同,體現出HTB 算法對帶寬的分配作用。節點的優先級均設置為最高的0。數據包i1、i2和j 到達網絡設備eth0 之后,根據在內部節點中得到的判決,進入到相應數據鏈路中,最終加入到葉子節點的數據包隊列中。
數據包在出隊列時,首先尋找一個可以發送數據包的葉子節點,隨后從該節點的數據包隊列里選擇一個數據包進行發送。在圖2 所示的結構圖中,假設所有的節點的優先級均為0。節點1:10 為1:101 和1:102 的父節點,1:1 為1:10 和1:20 的父節點。在HTB 算法中,使用紅黑樹來管理每層的節點,不同優先級的節點屬于不同的紅黑樹。在紅黑樹中,根據節點ID的大小進行排序,因此1:20節點為左孩子,1:101 節點為根節點,1:102 為右孩子。以圖2為示例說明數據包出隊列的過程。
1)最初三個節點均處于可發送模式,當有報文掛載到三個節點下時,節點被激活。
2)從第0 層節點開始尋找處于可發送模式且優先級最高的節點。在圖2 所示的示例中找到1:101/1:102/1:20三個節點構成的紅黑樹,選取ID 最小的節點1:20,發送該節點數據包隊列中的數據包。
3)當從1:20 中獲取的數據包的字節總數達到其Quantum 參數設置的值,即20000 字節時,開始尋找下一個葉子節點,此時找到的是ID 較小的節點1:101。節點1:101 和1:102 的發送模式與1:20相同。
4)三個節點不斷發送數據包,三個節點陸續達到參數Rate 的設置,節點的模式變為可租借模式,并對節點進去行激活處理,同時激活父節點,將1:20 加入到其父節點的供給樹中。供給樹是為內部節點維護的一個字段,用于管理向該節點借用帶寬的節點,按優先級,分為8個紅黑樹結構。
5)此時第0 層已經沒有激活的節點,轉而向高層即第1 層尋找激活的節點。此時找到節點1:10。由于節點1:10 為非葉子節點,因此首先找到1:10 的優先級最高的供給樹,然后從樹中找到ID最小的節點,作為發送數據包的節點。
6)繼續發送數據包,當節點的數據包發送速率達到其設置的Ceil 參數后,節點變為不可發送模式,無法再發送數據包。
7)隨著時間的推移,令牌會不斷生成。令牌生成的數量足夠多時,節點的模式可以從不可發送模式變為可租借模式或可發送模式。
8)重復上面的過程,繼續發送數據包,直到數據包發送完成。
在HTB 算法中,將數據包按照優先級、目的ip等信息進行分類,優先保障高優先級的數據包被發送出去。同時設置參數quantum,可以保證高優先級的數據包優先發送的前提下,優先級較低的數據包不會因為饑餓而失去發送的機會。Ceil 參數大于rate 參數的設置,可以使系統擁有一定的應對流量突發狀況的能力。當數據包流量突然增大時,通過從父節點中借用帶寬的方式,完成數據包的發送。
3 HTB的改進算法
在HTB 算法中,為節點設置了三種模式,隨著數據包的不斷發送,節點的模式變化可能有多種情況。
1)數據包發送之后節點的模式不變,對節點發送數據包的個數和字節數進行統計,不做其他操作。
2)數據包發送之后節點的模式發生改變,由可發送模式變為不可發送模式或可租借模式時,需要將節點插入到該節點所在層次的等待隊列中,將節點去激活;節點模式在可租借模式和不可發送模式之間變化時,首先將節點從等待隊列中取出,然后重新加入到等待隊列中;節點模式由可租借模式或不可發送模式變化為可發送模式時,需要將節點從等待隊列中取出并激活節點。在完成上述操作后,兩種情況都需要對節點發送數據包的個數和字節數進行統計。
3)當節點長時間處于不可發送狀態時,會消耗大量時間等待令牌的生成,因此會降低帶寬利用率,增加數據包發送的延遲。
當節點的模式頻繁發生改變時,會頻繁觸發這些操作,從而增加在OS 內核層面發送數據包需要的時間,增加了數據包發送的延遲。本文提出一種HTB算法的改進算法,通過定期對每個節點的帶寬使用情況進行分析,對于帶寬使用量較大的節點,由系統為其預留出部分帶寬,變相地增大其rate 和Ceil 參數的設置,從而減少節點的模式改變次數,降低延遲,提高帶寬的利用率。
在HTB 算法中,使用結構體struct HTB_class來描述節點。此結構體中有一個聯合類型的字段un,其中定義了兩種結構體,struct leaf 和struct in?ner,分別用于表示葉子節點和內部節點。在struct leaf結構中添加三個字段:
unsigned long tokens_reserved;
unsigned long tokens_used;
unsigned long pkts_nums;
tokens_reserved用于記錄父節點為孩子節點預留下令牌數量,tokens_used用于記錄該節點在一段時間內的令牌消耗數量,pkts_nums 記錄發送的數據包個數。這兩個參數的初值均設置為0。當從該節點中獲取數據包時,便進行統計,對數據包的長度進行累計,一共參數調節時使用,當參數調節完成后清0,重新開始計數。
在struct inner結構中添加字段:
struct list_reserved*head_reserved;
此字段用于記錄該節點為其子節點預留的令牌數量。由于HTB 算法為多叉樹結構,因此struct list_reserved結構體的定義如下:
struct list_reserved{
u32 classid;
unsigned long tokens;
struct list_reserved*next;}
tokens 字段表示該節點為id 為classid 的節點預留的令牌數量。
在得到上述參數之后,對節點進行令牌使用情況的分析。
1)在系統中設置參數調節的頻率,當系統發送出相應數量(程序中設置的數量為1000,參數可調)的數據包之后,便進行分析。
2)分析時,遍歷所有的葉子節點,再由葉子節點,上溯到根節點,對節點的參數進行處理。針對之前獲取的該節點在此此發送過程中的表現(即從該節點中獲取的數據包的個數和字節數),計算其數據包發送的速率,若數據包發送的速率超過了該節點的rate 參數的限制,則認為此節點屬于帶寬消耗量較高的節點,為其預留帶寬,預留帶寬數量設置為其參數quantum,即tokens_reseved 字段設置為quantum,并且可以累加,并以此參數來增加節點的rate和Ceil參數。
3)在后續進行使用情況的分析時,首先保留tokens_reserved 字段不清除,從rate 和Ceil 參數中減去tokens_reserved 字段的值,即恢復初值。而且如果此時節點的數據包發送速率仍然高于rate 參數的限制,則在tokens_reserved 值的基礎上遞加quantum 參數的值;若此時節點的數據包發送速率小于rate 參數的限制,則將tokens_reserved 減去quantum的值,而非立即清0。
4 實驗與性能評估
4.1 實驗平臺
在64 位Ubuntu16.04LTS 系統下,在應用層實現HTB 算法,模擬在內核代碼中HTB 算法實現過程中所需要的所有數據結構和函數調用,并在原HTB 算法的基礎上,實現HTB 改進算法。讓兩個算法在相同的數據集上執行,得到發送數據包所消耗的時間。
為了測試程序在不同帶寬下數據量大小不同情況下的性能,實驗中設置了2000 個數據集。一共設置了12 種不同的帶寬,800KB,1200KB,1600KB,2000KB,2400KB,2800KB,3200KB,4800KB, 6400KB, 8000KB, 9600KB 以 及11200KB,每種帶寬下設置200種不同的數據量,以數據包的個數為單位,512 個數據包為步長,從512個數據包一直到102400 個數據包,每個數據包的大小被隨機設置為500/600/800/1000/1200 五種值之一。
在應用層環境中,仿真實現兩種算法,并在相同的數據集上運行,得到發送數據包花費的時間數據。
4.2 性能評估
圖3 表示的是帶寬為11200KB 時的算法運行時間的對比圖,每25 個數據為一組,取平均值,得到表1中的數據。表1中耗時改進比率一欄表示為改進前后耗時之差與改進前耗時比值,用以表示算法的改進效果。由此可以看到,當數據包個數較少時,可以看到改進后的HTB 算法的改進效果比較明顯,但隨著數據包個數的增多,改進后的HTB 算法的效果迅速減小,但趨于穩定,能夠有效降低數據包發送的時間延遲。
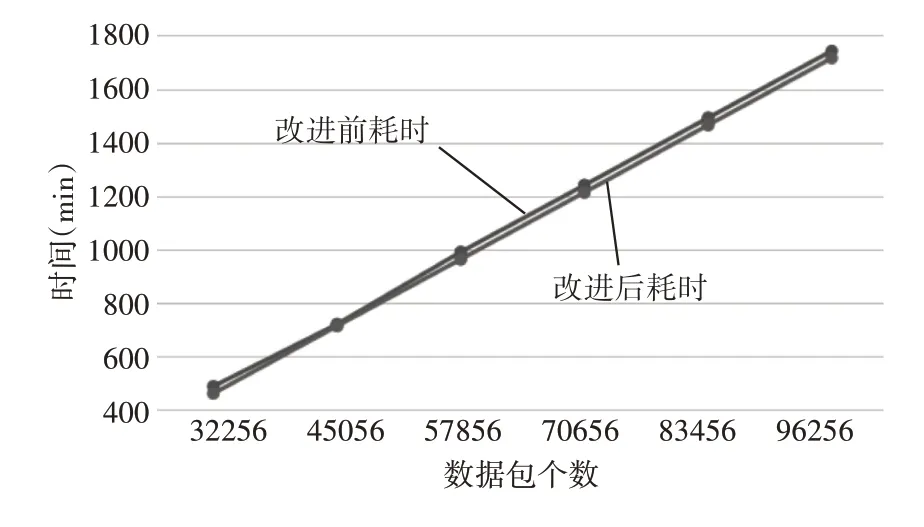
圖3 帶寬為11200KB時的數據包獲取時間對比圖
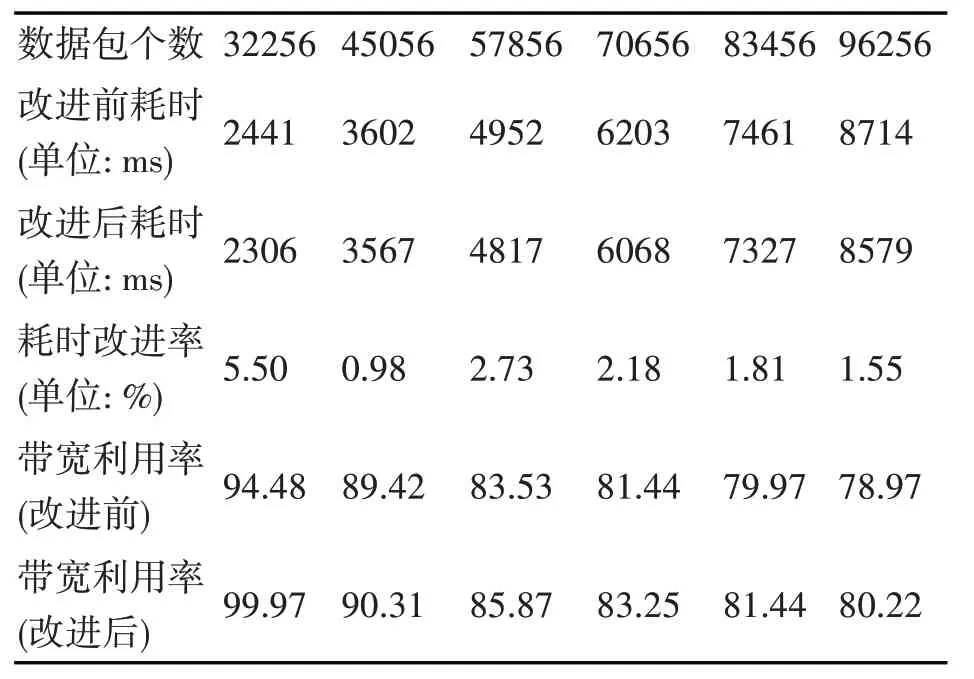
表1 帶寬為11200KB的實驗用例中的數據
下面以45056個數據包為例,計算帶寬利用率。
在數據集中,45056 個數據包中的數據總量為36945920B,即36080KB,3602.56ms 間獲取了總量為36080KB 數據,帶寬為11200KB,因此帶寬利用率為

由表1中數據可以看出,改進后的HTB 算法能夠有效提高帶寬利用率,降低數據包發送的時間延遲。
5 結語
雖然HTB 改進算法能夠在一定程度上降低數據包發送的延遲,提高帶寬利用率,但是該算法的魯棒性較差,有較小的概率程序會運行崩潰,且對復雜環境的適應能力較弱。因此下一步的工作目標就是針對算法在不同應用場景下都能取得較好效果以及提高魯棒性的改進。
猜你喜歡
少先隊活動(2021年4期)2021-07-23 01:46:22
水上消防(2020年5期)2020-12-14 07:16:18
中國畢業后醫學教育(2020年5期)2020-12-06 06:52:46
鐵道通信信號(2019年7期)2019-10-08 08:38:02
攝影之友(影像視覺)(2019年3期)2019-03-30 01:36:50
鐵道通信信號(2018年1期)2018-06-06 02:27:38
玩具世界(2017年9期)2017-11-24 05:17:29
作文評點報·低幼版(2017年42期)2017-11-16 22:12:34
沈陽醫學院學報(2015年1期)2015-12-27 13:44:40
醫學教育管理(2015年3期)2015-12-01 06:43:16
