一種基于YOLO 的交通目標實時檢測方法?
2020-11-02 09:00:30王思雨TanvirAhmad
計算機與數字工程 2020年9期
王思雨 Tanvir Ahmad
(華北電力大學控制與計算機工程學院 北京 102206)
1 引言
近年來,我國城市道路建設規模日益擴大,城市交通需求逐步增加,交通道路擁堵、交通事故猛增已成了交通管理部門所關注的重點問題[1]。隨著大數據、云計算、移動互聯網等技術的迅速發展,“互聯網+”概念已經引起了各行各業的高度重視。“互聯網+交通”[2]是將互聯網新技術應用到智能交通領域,如通過傳感器、通訊設備、光學影像設備等,使得機器能夠識別車輛、行人、信號燈等一系列交通目標,從而為智能交通提供基礎設施。人工智能[3]作為當下最火爆的科技之一,在車輛顏色、車牌識別、無牌車檢測方面應用已經比較成熟。目前已經有許多大型公司投入大量資金,致力于自動駕駛汽車的研究。然而,如何能夠提高車輛安全性能,提高交通目標檢測準確率和檢測速度是實現無人駕駛的關鍵。
基于上述背景介紹,交通安全問題是實現自動駕駛需要考慮的首要問題。因此,在進行交通目標檢測任務時,如果可以在保持實時檢測速度的情況下,還能夠大幅提升檢測精度,對自動駕駛技術而言是一項重要舉措。本文將YOLOv3 應用于車輛、行人等交通目標檢測[19],與YOLOv2 相比能夠大幅提升檢測精度。
2 目標檢測
傳統的交通目標檢測技術包括基于雷達、超聲波、紅外線等傳感器檢測方法[4]。其中基于雷達的目標檢測是根據雷達發射的電磁波來探測車輛目標位置;而基于超聲波的目標檢測無法檢測低速行駛車輛;基于紅外線的檢測方法抗干擾能力低。隨著社會的發展,視頻采集設備的價格越來越低廉,采集圖像的質量越來越高,基于計算機視覺[5]的目標檢測技術逐漸興起。早期的圖像檢測技術是根據圖像的顏色[6~8]、紋理、圖形特征模型[9~10]等一系列特征變化來完成特征提取。Liu et al.[11]提出了一種新的單個視頻對象提取的半自動分割方法。受Hubel 和Wiesel 對貓視覺皮層研究啟發,有人提出卷積神經網絡[12]。Yann Lecun[13]是最早將CNN 用于手寫數字識別,并一直保持了其在該領域的霸主地位。2012 年ImageNet 競賽冠軍獲得者Hinton 和他的學生Alex Krizhevsky 設計了AlexNet[14]。VGG?Net[15]是 牛 津 大 學 計 算 機 視 覺 組 和Google Deep?Mind 公司的研究員一起研發的深度卷積神經網絡。GoogLeNet[16]是2014 年Christian Szegedy 提 出的一種全新的深度學習結構。ResNet[17]在2015 年被微軟亞洲研究院何凱明團隊提出,ResNet 有152層,除了在層數上面創紀錄,ResNet 的錯誤率也低得驚人。2015 年,Redmond J 提出了一種全新的端到端的目標檢測算法——YOLO[18]。YOLO 借鑒了GoogLeNet 的分類網絡結構。相比其他的檢測網絡,它能夠達到45f/s的檢測速度。
在自動駕駛系統中,目標檢測任務主要是預測目標類別以及目標位置。現有的基于CNN 的目標檢測方法,大多第一步是先提取感興趣的區域候選框,然后利用卷積神經網路提取區域特征,最后將提取的區域特征送入分類器進行分類。與其他目標檢測方法不同的是,YOLO 運行一次神經網絡就可以得到預測邊框以及所屬類別,而不是區域候選框提取之后再進行分類。這樣做的結果就是提高了檢測速度,但以犧牲精度為代價。到目前為止,YOLO 已經經歷了兩次版本的更迭,最新版是YO?LOv3。
3 YOLO原理
3.1 YOLOv1
目標檢測任務主要是分類。在YOLO 之前的目標檢測方法主要是通過區域建議產生大量可能包含目標的候選框,再使用分類器進行分類,判斷候選框中是否含有待檢測目標,并計算目標所屬類別的概率。而YOLO 是一個端到端的目標檢測框架,它把目標檢測任務當作回歸問題來處理,通過一次圖像輸入就可以同時得到預測邊框的坐標、邊框包含目標的置信度,以及所屬類別的概率。由于YOLO 實現目標檢測是在一個神經網絡里完成的,因此,檢測目標更快。選出預測框的位置以及其含有目標的置信度和屬于目標類別的可能性。
如圖1 所示,YOLOv1 的核心思想是將每個圖像劃分成S×S 的網格。每個網格預測B 個邊界框,和C 個類別概率。每個邊界框負責預測目標中心位置和大小x,y,w,h,以及置信度共5 個變量。其中x,y 表示預測邊界框的中心落在當前網格的相對位置。w,h 表示邊界框的寬和高相對整個圖像的比例。置信度則反映了目標位置預測的準確性。其計算公式如下:
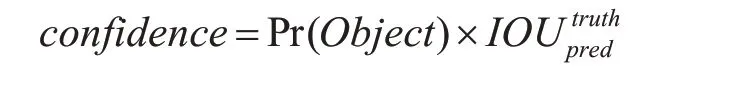
如果有目標中心落到一個網格中,公式右邊第一項Pr(Object)取1,否則取0。第二項IOU 指的是預測邊框和真實標注邊框之間的重疊度。網絡模型最后的輸出維度為S×S×(B×5+C)。
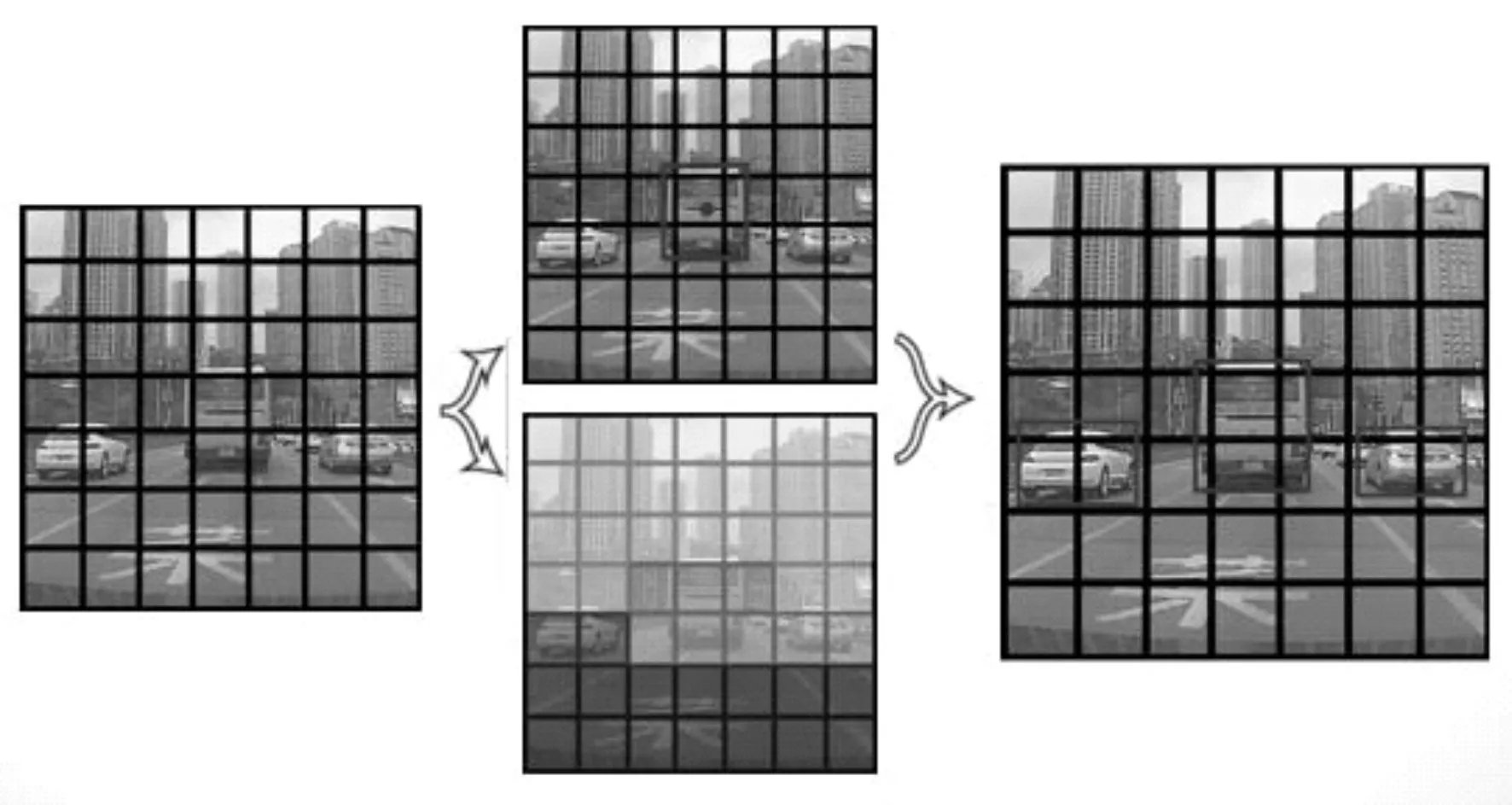
圖1 YOLOv1 思想模型
檢測目標時,由以下計算公式得到每個網格預測目標類別的置信度得分。
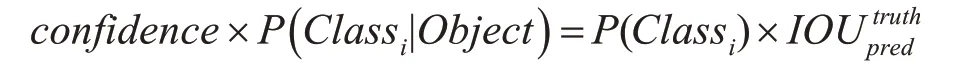
最后通過非極大值抑制,如圖2 所示。過濾掉得分低的預測框,從而確定預測目標的最終位置。而置信度得分用來判斷目標所屬類別。
以VOC 數據為例,YOLOv1 采用7×7 網格,每個網格預測兩個邊界框。因為VOC 數據集待檢測目標有20 個種類,所以輸出張量為7×7×(2×5+20)=30,YOLOv1檢測網絡包括24個卷積層和兩個全連接層。YOLOv1 借鑒了GoogLeNet,但是與之不同的是,YOLOv1 使用1×1 和3×3 的卷積核代替了GoogLeNet的inception module。

圖2 非極大值抑制
YOLOv1 相比其他基于CNN 的網絡模型而言很好地提升了檢測速度,但是由于YOLOv1 的檢測機制使得一個網格只能預測一個目標,此時,如果有兩個物體同時落入一個網格,就會使得漏檢率比較高,而且一幅圖像只預測98 個邊界框,對于目標定位誤差較大。
3.2 YOLOv2
YOLOv2[20]則參考了YOLOv1 和SSD[21]的網絡結構,采用類似VGG16 的網絡結構,多次使用3×3卷積核,并且在每一次池化操作之后都會把通道數翻倍。網絡使用全局評價池化,把1×1 的卷積核置于3×3 的卷積核之間,用來壓縮特征。最后得到Darknet-19 的基礎網絡模型,其中包含19 個卷積層和5 個最大池化層。但是Darknet-19 計算量要比VGG16 小得多,在ImageNet[22]分類top-1 準確率能夠達到72.9%,top-5準確率達到91.2%。
YOLOv2把初始輸入圖像分辨率由224×224提高到448×448,使得高分辨率的訓練模型mAP 獲得4%的提升。其次由于YOLOv1 最后使用全連接層預測邊框和分類,導致丟失許多空間信息,導致定位不準確,YOLOv2 借鑒了RPN 中anchor 的思想,在卷積層使用下采樣,使得416×416 的輸入圖像最終得到13×13 的特征圖,最終預測13×13×9 個邊框,大幅度提升了目標檢測的召回率。YOLOv2 還改進了預測邊框的方法。使用K-Means 聚類方法訓練邊框。而傳統的K-Means 方法使用的是歐式距離,這意味著大的邊框會比小邊框更容易產生誤差。因此,作者提出使用IOU 得分來評判距離大小。使得預測的邊框更具代表性,從而提升檢測準確率。YOLOv2采用SSD使用不同的特征圖以適應不同尺度目標的思想,對原始網絡添加了一個轉移層,把26×26×512的淺層特征圖疊加成13×13×2048的深層特征圖,這樣的細粒度特征對小尺度的物體檢測有幫助。最后,YOLOv2 還結合單詞向量樹方法,能夠檢測上千種目標,雖然對本文檢測任務來說參考意義不大,但這對多目標檢測任務來說也是一個很大的突破。
3.3 YOLOv3
YOLOv3[23]相對于YOLOv2 的改進主要體現在多尺度預測。對坐標預測和YOLOv2 一樣使用的維度聚類作為anchor boxes來預測邊界框。在訓練期間,使用平方誤差損失的總和,這樣計算快一些。對于類別的預測,YOLOv3再使用Softmax進行分類,而是每個邊框通過邏輯回歸預測該邊框屬于某一個類別目標的得分,這樣可以檢測一個目標屬于兩個標簽類別的情況。對于跨尺度預測,主要是為了適應不同尺度的目標,使得模型更具有通用性。尤其對小目標的檢測,精度有了很大提升。YOLOv3 采用了Darknet-53,網絡結構相比YO?LOv1和YOLOv2稍大了一些,但是準確度提高了很多,尤其是對小目標的檢測精度有了很大提升。并且在實現相近性能時,YOLOv3 比SSD 速度提高3倍,比RetinaNet速度提高近4倍。
4 實驗與結果分析
本實驗環境的操作系統是Ubuntu16.04,所有實驗都是在GPU 的配置下完成的,INVIDIA 顯卡型號GTX1070,顯存8G。使用到的開發包有CUDA、cuDNN 以及OpenCV。OpenCV 是為了將檢測結果可視化。
實驗數據是根據車載攝像頭捕捉的交通道路視頻,利用視頻分幀軟件得到靜態圖像。并對其進行手工標注。其中用于車輛、行人、非機動車的數據集有40765張圖像。
4.1 實驗指標
本實驗將現有的數據集劃分成圖像數量分別為6500、13000、19500、26000、32500、39000 的6 個不同大小的訓練數據集,其余1765 張圖像用作測試集。通過設定不同參數,得到多個訓練模型。通過計算平均精度(AP)作為衡量模型的指標。
在本實驗中,通過計算預測邊框與真實邊框的交并比(IOU),一般認為只要滿足下述條件的就是正確的檢測結果,稱為正樣本。
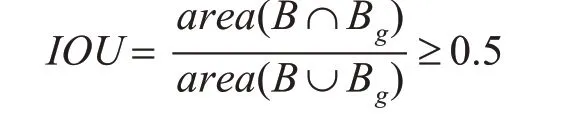
其中B 為檢測模型預測的邊框,Bg為人工標注的目標真實邊框。
為了計算AP值,我們需要知道以下幾個概念:

表1 正負樣本概念
其中,準確率(Precision)的計算公式為


圖3 準確率-召回率曲線圖
如圖3 所示,準確率-召回率(PR)曲線是根據對應的準度率召回率曲線繪制的。而AP 則是PR曲線下的面積值,可以通過準確率和召回率計算函數積分得到,計算公式如下:
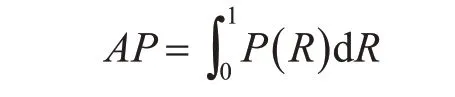
有時候為了評估模型的整體性能,需要對所有目標的AP求平均值得到mAP。計算公式為

其中,N是待檢測目標類別個數。
4.2 實驗結果和分析
本文使用YOLOv3和YOLOv2分別在訓練集上訓練模型,檢測車輛、行人和非機動車三類目標。如圖4 所示,是在39000 的訓練集以及45000 次迭代次數的情況下,三類目標分別在YOLOv3 和YO?LOv2 訓練模型得到的AP 值。顯然,改進了的YO?LOv3 要比之前的檢測框架精度有了大幅提升。如圖5 所示,YOLOv3 對于交通目標檢測的mAP 明顯高于YOLOv2。而YOLOv3 檢測速度相比YOLOv2減慢了1/3,如圖6所示,YOLOv3和YOLOv2訓練模型分別對1765 張測試集圖像進行測試所耗費的時間,均達到了每秒30 幀以上的檢測速度。這對于實時的目標檢測任務也是足夠的。因此,選擇YO?LOv3實現交通目標檢測任務再合適不過。
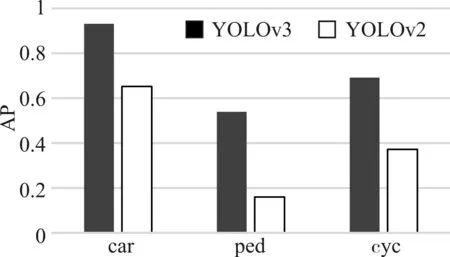
圖4 兩種方法的AP

圖5 兩種方法的mAP

圖6 兩種方法的檢測時間
圖7、圖8、圖9 是通過YOLOv3 在不同數據集上訓練不同模型測試的結果。圖中展示了對于同一類檢測目標,數據集的規模大小以及迭代次數的多少對目標檢測精度AP的影響。通過對比三類不同的目標發現,不同的數據集對于車輛的檢測精度變化并不大,而對于行人和非機動車而言,6500 的訓練集確實檢測效果不佳。因此,大量的數據訓練還是有必要的,隨著數據集規模的增加,檢測精度明顯呈上升趨勢。
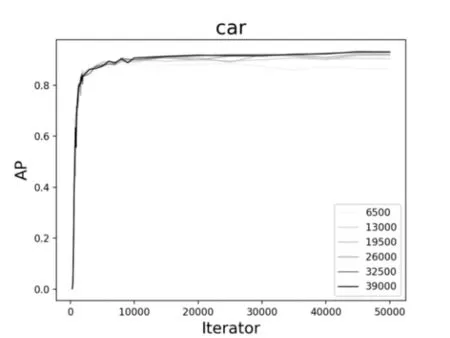
圖7 不同數據集下car的AP變化曲線圖
如圖10、圖11、圖12 所示,對于同樣的訓練數據集,當迭代次數增加到1000 次左右的時候,AP有一個較為明顯的變化,這是因為當訓練模型迭代到1000次左右時loss收斂較快。其次,對于車輛而言,隨著迭代次數的不斷增加,AP已逐漸趨近于1,從統計結果來看,迭代次數增加對車輛的檢測精度提高并不明顯。而對于行人和非機動車而言,AP還有很大上升空間,從圖中的趨勢也可以看出,如果繼續增加迭代次數,對ped 和cyc 的檢測精度還是可以繼續提高的。

圖8 不同數據集下cyc的AP變化曲線圖
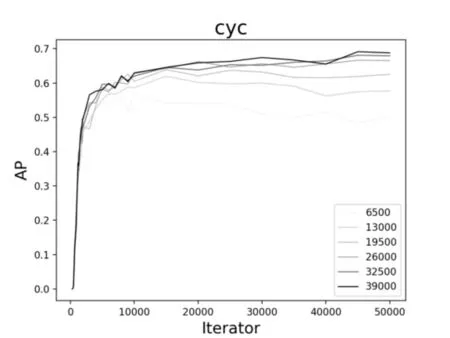
圖9 不同數據集下ped的AP變化曲線圖
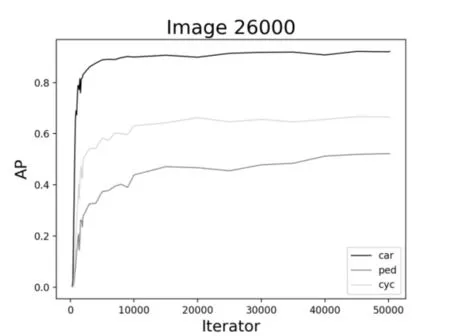
圖10 26000數據集時AP的變化曲線
進一步綜合圖7~12,可以看到,對于車輛、行人和非機動車的檢測結果是不同的。對于車輛的檢測,AP 最高達到93%左右,而對于行人,AP 最高也才55%左右。究其原因可能有二:一是,在所有的數據集中,目標分配極不均衡;這也提醒我們在基于YOLO 的深度學習訓練中以后要盡量保持目標均衡,效果則較好。二是,車輛特征比較明顯,而行人和非機動車特征變化多端,再加上交通道路場景復雜,對于行人的檢測精度還有待提高。
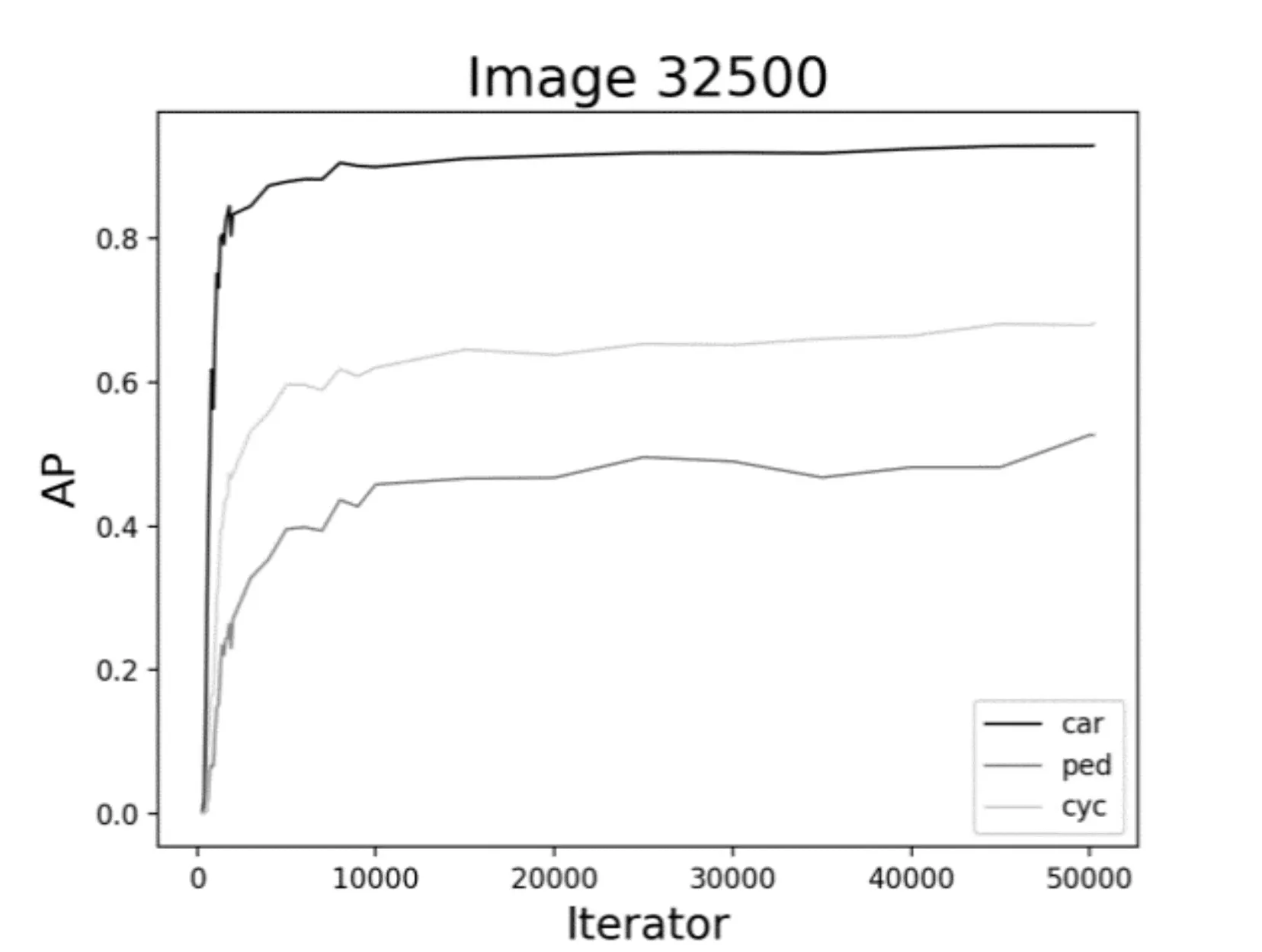
圖11 32500數據集時AP的變化曲線
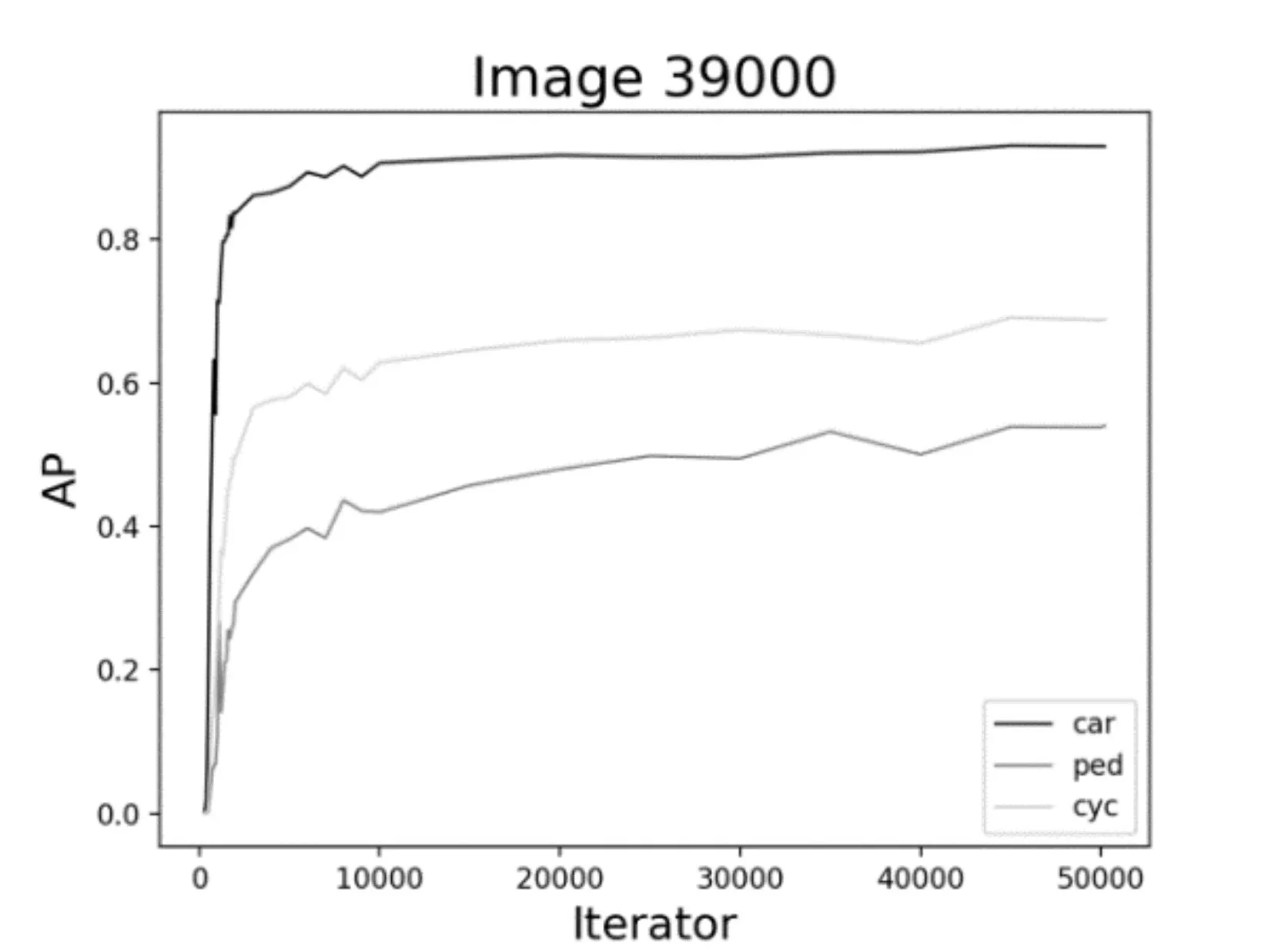
圖12 39000數據集時AP的變化曲線
5 結語
本文通過在YOLOv3 和YOLOv2 上對比實驗,驗證了YOLOv3 應用于交通目標檢測精度確實要比YOLOv2 高出很多。YOLOv3 在不同數據集和迭代次數的各種組合情況下,表現出了訓練集越大,迭代次數越多,檢測精度越高的特性。并且能夠保證檢測的實時性。盡管YOLOv3 檢測精度已經有了很大提升,但是,還沒有達到百分百準確的程度。由于無人駕駛與人類生命息息相關,因此,在圖像目標檢測應用在無人駕駛領域的方法還不夠成熟,檢測精度還有待提高。下一步考慮如何能夠平衡不同目標的檢測準確度,將模型泛化,使其能夠應用到更多的領域中。并將加入和其他目標檢測方法的對比,驗證YOLO 在交通目標檢測領域的有效性及高效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
