基于改進Trie 樹的歧義消解方法?
2020-11-02 09:00:56樂紅兵
計算機與數(shù)字工程 2020年9期
關(guān)鍵詞:信息
陳 倩 樂紅兵
(江南大學物聯(lián)網(wǎng)工程學院 無錫 214122)
1 引言
分詞是中文語言處理的基礎(chǔ)性工作。近年來,中文分詞經(jīng)歷了很大的發(fā)展。將分詞看作序列標記問題是比較普遍的方法[1],序列標記的目標是給序列中所有元素分配標簽,包括最大熵和條件隨機場等監(jiān)督學習算法[2]。但是語言搭配是隨著時間不斷變化的,陳舊的語料訓練出的基于統(tǒng)計的分詞方法難以駕馭人們?nèi)找娓碌恼Z言習慣,且人工進行語料庫更新是十分巨大繁瑣的工作,國內(nèi)沒有能夠獲取并持續(xù)更新的語料庫,這是基于統(tǒng)計學習的分詞方法所遇到的阻礙[3]。
在現(xiàn)實生活中需要切分的語料是多種多樣的,并不是所有待切分語料都具有上下文信息,一些需要處理的語料往往以單個句子的形式出現(xiàn)并要求切分。例如在網(wǎng)絡(luò)上查詢信息時輸入的文本、網(wǎng)上聊天和電子郵件中輸入的單句、問答系統(tǒng)種用戶輸入的句子等都沒有上下文信息[3]。由此可見基于上下文信息進行分詞方法具有局限性。在基于詞典的分詞方法中,未登錄詞造成的分詞精度降低和容易產(chǎn)生歧義是它的缺陷所在,因此未登陸詞識別和歧義處理是衡量基于詞典的分詞系統(tǒng)優(yōu)劣的重要標準。
針對分詞算法的詞典構(gòu)造方法,目前形成了成熟的詞典加載結(jié)構(gòu)。如:整詞二分法、Trie 索引樹、逐字二分法。根據(jù)文獻[4],三種詞典機制的空間大小排序,Trie 索引>整詞二分=逐字二分;時間大小排序,Trie索引樹>逐字二分>整詞二分。分詞詞典是劃分出每個詞的重要依據(jù),因此分詞詞典的構(gòu)造至關(guān)重要,它無需通過語料庫的訓練,計算量小,原理簡單且易于實現(xiàn)。
宗中等[5]依據(jù)雙字詞占比重較高,單字和多字不常用的特點,提出了雙字Hash 詞典機制。僅對詞語的前兩個字順次建立Hash 索引,構(gòu)成了深度只為2 的Trie 子樹,詞的剩余部分構(gòu)成詞組作為詞典正文,從而避免了枝干過長,大大提高了詞組查詢速度。分詞速度得到提升,由于沒有歧義方面的處理,分詞準確率提高不大。
李江波等[6]提出了雙數(shù)組Trie 思想。首先把所有GB2312 中的基本漢字的順序碼轉(zhuǎn)化成1-6768 的順序碼,然后將所有的順序碼作為初始狀態(tài)放入Base 數(shù)組;接下來將不同詞語的后續(xù)漢字順序放進數(shù)組,生成新的狀態(tài),并對數(shù)組中初始狀態(tài)的Base 值進行調(diào)整,以保證所有后續(xù)漢字能夠放入數(shù)組。雙數(shù)組Trie 改進了數(shù)組指針空置的缺陷,實現(xiàn)在空間占有較少的同時還要保證查詢的效率。但是雙數(shù)組Trie內(nèi)存消耗大,實現(xiàn)復雜。
交集型分詞歧義是自動分詞遇到的主要歧義類型。以往所提出的歧義處理方法,常需上下文信息的統(tǒng)計進行辨別歧義,例如使用互信息原理、N元統(tǒng)計模型,t-測試原理、HMM 模型、字標注統(tǒng)計等方法或模型進行上下文信息統(tǒng)計以實現(xiàn)歧義消解,無法在沒有上下文信息的情況下進行歧義消解,或者上下文信息量少影響歧義消解的質(zhì)量。
文中進一步改進Trie樹詞典加載機制,采用雙哈希索引,即首字和次字使用哈希索引,詞的剩余字串則按字典順序組成類似“整詞二分”的詞典正文,最大限度地提高匹配時間效率。然后運用詞頻和詞性信息進行交集型歧義處理,該方法使用于對上下文信息匱乏的語料。
2 雙字Hash詞典機制
Trie 樹是一種以樹的多重鏈表表示的鍵樹,主要有首字散列表和結(jié)點兩部分組成,在語句切分過程中只需一次掃描,無需知道待分詞的長度,沿著樹鏈逐字匹配進行分詞,避免了整詞二分的詞典機制中不必要的多次試探性查詢。Tire 樹進行詞典加載一般采用哈希算法,把任意長度的輸入通過散列算法,變換成固定長度的輸入,該輸出就是散列值,這種轉(zhuǎn)換就是一種壓縮映射。哈希算法的基礎(chǔ)是哈希表的建立,散列表(哈希表)是根據(jù)關(guān)鍵碼值直接進行訪問的數(shù)據(jù)結(jié)構(gòu)。當關(guān)鍵字集合很大時,關(guān)鍵字值不同的元素可能會映射到哈希表的同一地址上,從而產(chǎn)生沖突。
與英文不同,目前漢字已經(jīng)超過8 萬字,常用字就有7000多個,27萬個詞組,如果一條枝干僅代表一個字,將有27 萬個葉子節(jié)點,Trie 索引樹的廣度擴大,浪費了一定的存儲空間,并且Trie 樹中一個關(guān)鍵字關(guān)聯(lián)多個值導致散列表查找碰撞嚴重,分詞速度相應(yīng)變慢。
因此,用Trie進行中文詞典加載會產(chǎn)生大量空指針,散列查找也需要額外的時間,為了最大限度地提高匹配時間的效率并兼顧空間利用率。本文提出雙字哈希詞典存儲,二字詞以下的短語使用Trie 索引樹機制實現(xiàn),三字詞以上的長詞的剩余部分用線性表組織,逐詞匹配三字詞以上的長詞的剩余字符串,從而避免了深度搜索,一定程度上優(yōu)化了查詢性能,提高了分詞的速度。雖然與莫建文[4]等提出的雙字哈希結(jié)構(gòu)相似,但是本文對詞典正文進行了最大長度、詞性、使用頻率字段的擴充,提高了分詞歧義判斷的準確性。
根據(jù)權(quán)威統(tǒng)計,雙字詞語所占比例很大,使用頻率也很高,多(四字以上)字詞語占比例很小,使用頻率較低。漢語各字詞條的詞頻統(tǒng)計如表1 所示:兩字詞的詞頻占了一半以上,而五字以上的詞的出現(xiàn)概率就非常小,使用頻率低。

表1 不同字長的頻率比
結(jié)合中文字的編碼體系和中文詞的分布以及哈希索引結(jié)構(gòu)的詞典查詢速度快的優(yōu)點,本文設(shè)計了一個基于雙字哈希的三層索引詞典結(jié)構(gòu)基本結(jié)構(gòu)如下:
1)首字哈希表(Hashmap 存儲):全部中文字符的區(qū)位碼的哈希值,哈希值的大小由小到大依次排列,由首字哈希表值可以直接找到對應(yīng)的首字地址。
漢字在計算機中以內(nèi)碼形式存在,將內(nèi)碼計算后轉(zhuǎn)為區(qū)位碼,再將區(qū)位碼轉(zhuǎn)換為一個十進制的數(shù)字,這個數(shù)字就是該漢字在哈希表中的序號。該序號指示了以該字為首字的詞長表的入口地址,根據(jù)Hash函數(shù)入口地址的計算,如式(1)所示:

其中,Offset 為該字在哈希表中的序號,ch1,ch2分別為該字機內(nèi)碼的高字節(jié)和低字節(jié)。
2)次字哈希表
采用除留余數(shù)法的散列函數(shù)處理次字哈希索引。
次字哈希函數(shù)為
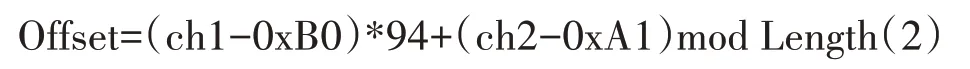
其中,Offset 為該字在哈希表中的序號,ch1,ch2 分別為該字機內(nèi)碼的高字節(jié)和低字節(jié)。Length是求模系統(tǒng),文中對其長度進行統(tǒng)一分配。
3)詞典正文
詞典正文是由詞中除首次字外剩余部分組成的按內(nèi)碼順序排序的有序表。
4)雙哈希索引樹中的節(jié)點用DictSegment類來表示。其中,DictSegment類的單元結(jié)構(gòu)如下。
(1)keyChar(4bit):當前節(jié)點對應(yīng)的字符。
(2)nodeState(1bit):到詞節(jié)點的前綴部分是否為詞,nodestate=1為詞,nodestate=0不為詞。
(3)point(4bit):獲取下一層存儲結(jié)構(gòu)的容器對象,null代表葉子節(jié)點,詞組組成結(jié)束。
(4)nMaxLength(4bit):該首字開始的最長詞條長度,一般用于首字。
(5)nWordType:詞條的詞性,一般用于詞典正文。
(6)nFrequenery:詞條使用的頻率,一般用于詞典正文。核心詞典的邏輯結(jié)構(gòu)如表2所示。

表2 部分關(guān)鍵字對應(yīng)AMCTT結(jié)構(gòu)
雙字hash 索引可以使查詢速度和存儲空間達到最優(yōu)。如:“啊呀/啊哈/大案要案/大青蟲/大壩/大白鼠/大白天說夢話”構(gòu)成本文提出的AMCTT 詞典樹如圖1所示。

圖1 雙字哈希索引分詞詞典機制(正向)
雙字Hash 在查找某一個詞語時,首先要進行詞語首字的查找,獲得相對應(yīng)的以次字為首字的最大詞長,并根據(jù)具體的詞長獲得次字的Hash 值,進而得到次字和剩余字串,從而得到所要查找的詞語。這樣的查找方法可以快速準確地獲得所查詢的詞語在詞典中的精確位置,減少了不必要的過程,縮短了查詢詞語的時間,提高了分詞的效率,在分詞速度上要優(yōu)于基于傳統(tǒng)詞典的中文分詞方法。
3 歧義消解
歧義現(xiàn)象指一種形式對應(yīng)著兩種或兩種以上的解釋,在人類豐富的自然語言中充斥著大量的歧義現(xiàn)象。漢語由于缺乏嚴格意義的形態(tài)變化,語法形式和語法意義之間的對應(yīng)關(guān)系錯綜復雜,因此歧義現(xiàn)象比形態(tài)發(fā)達的語言更具有普遍性。
使用雙向最大匹配分別對原始語料進行切分。雙向最大匹配是從左到右和從右到左將待分詞文本中的幾個連續(xù)字符與詞表匹配,如果匹配上,并且保證下一個掃描不是詞表中的詞或詞的前綴則切分出一個詞。結(jié)合詞性和詞頻信息,有兩種方法進行詞組歧義消解:
1)詞頻消解:由m 個漢字組成的歧義切分字段C=c1c2...cm有兩種切分結(jié)果W=w1w2...wn和V=v1v2...vk。

則選擇切分結(jié)果W,若

則選擇切分結(jié)果V;其中,frq(w)表示詞w的頻率。
單純使用詞頻信息,沒有考慮到詞性及詞義信息,更沒有考慮到不同詞性和詞義之間的概率轉(zhuǎn)移關(guān)系,錯誤率高。對于低頻字不能正確切分。
例:他的確切菜了

錯誤切分結(jié)果:他/的/確切/菜/了。所以需要結(jié)合詞性信息共同切分。
2)動詞消解:對于交集型歧義,即對于字段C=c1c2c3,c1c2∈C,C 為詞表,則稱C 為交集型歧義。對于這樣的歧義,根據(jù)中文的規(guī)則,如果交集詞的前面的詞在動詞詞典中,則直接將該詞切分為c1c2/c3,如果后面的詞在動詞詞典中,則將該詞切分為c1/c2c3。
顯然,切為動詞,例句正確切分為他/的確/切/菜/了。
4 實驗分析比較
系統(tǒng)環(huán)境是core2 i7、雙核8G 內(nèi)存、win7 64位、jdk 1.7 普通pc 壞境。通用詞典來自搜狐研發(fā)中心發(fā)布的搜狗實驗室數(shù)據(jù)(http://www.sogou.com/labs/resource/w.php),其中詞頻和詞性是Sogou 搜索引擎索引到的中文互聯(lián)網(wǎng)語料統(tǒng)計出的15 萬條高頻詞,統(tǒng)計時間是2006 年10 月。數(shù)據(jù)格式示例如表3所示。

表3 詞典中數(shù)據(jù)格式示例
4.1 評價指標說明
本文采用準確率、召回率及F 值作為評價指標。
準確率:

其中tp為分析結(jié)果中正確的數(shù)目,fp為分析結(jié)果中錯誤的數(shù)據(jù)量。
召回率:

其中tp為分析結(jié)果中正確的數(shù)目,fn為正確的但是沒有被識別出的數(shù)目。使用調(diào)和平均值表現(xiàn)出準確率和召回率的共同效果。
調(diào)和平均值:

4.2 詞典分詞比較
從文件中讀取詞典信息、詞頻和詞性信息及原始語料,放入內(nèi)存中。
測試1:為使測評結(jié)果盡量公平,我們從互聯(lián)網(wǎng)上下載5 篇不同領(lǐng)域的測試語料作為樣本,平均大小為60KB。
1)本文將所構(gòu)建的詞典機制(圖中樣本中右面第一個)與常用的3 種詞典機制(圖中樣本從左往右依次為:基于整詞二分法的詞典構(gòu)造機制,基于Trie 索引樹的詞典構(gòu)造機制和基于逐字二分的詞典構(gòu)造機制)進行比較,采用相同的測試樣本進行中文分詞,具體數(shù)據(jù)如圖2所示。

圖2 不同詞典分詞時間對比
通過不同分詞方法的比較和分詞效率的分析,本文方法的分詞速度相比于其他分詞詞典的速度有了一定的提高。
2)得出的測試結(jié)果如表4所示。
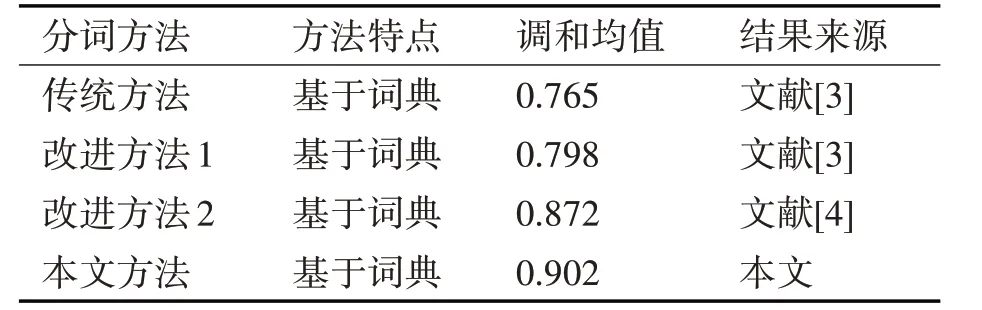
表4 詞典加載方法數(shù)據(jù)對比
根據(jù)測試1、測試2,使用傳統(tǒng)的基于詞典的正向最大匹配法和反向最大匹配法的測評結(jié)果與本文方法進行比較:使用改進的正向最大匹配分詞算法[9]及中國科學院計算研究所研制的漢語詞法分詞系統(tǒng)ICTCLAS(http://ictclas.nlpir.org)的分詞結(jié)果進行對比,結(jié)果如表5所示。

表5 匹配方法數(shù)據(jù)對比
本文大體上解決了由于機械匹配產(chǎn)生的歧義字段的識別不足問題,可以得出:使用雙字哈希詞典加載,結(jié)合詞頻和詞性進行分詞消歧的方法得出的調(diào)和平均數(shù)明顯高于其他方法。
該方法在搜索引擎、自動問答系統(tǒng)、電子郵件過濾、信息檢索與信息摘錄、文本分類和自動摘要、自然語言理解等需要對無上下文信息預料進行切分的實際運用領(lǐng)域中具有較強的實用性。既能夠不使用上下文信息,又能準確提取出需要的詞語信息,也不需要各領(lǐng)域的語料作為訓練對象,是一種通用高效的中文分詞方法。
5 結(jié)語
在沒有上下文信息或許上下文信息匱乏的情況下,顯然不能使用統(tǒng)計學知識進行分詞。本文提出用改進Trie 樹的雙字Hash 詞典提高分詞速度,再用詞典中記載的詞頻詞性信息進行分詞的歧義消解,提高了分詞的準確率。也存在以下需要改進的方面:
1)本文提出的根據(jù)詞頻和詞性的歧義消解只能消解一部分歧義,一些非正式場合沒有嚴格根據(jù)構(gòu)詞法使用語句,可能需要運用調(diào)節(jié)語序,更換詞語等方法再進行歧義消解。
2)缺少上下文,組合型歧義和真歧義沒有辦法解決。
3)分詞詞典的覆蓋面以及測試語料的選取對分詞的結(jié)果有很大影響,所以下一步的研究重點是如何把專業(yè)詞典和未登錄詞典附加到通用詞典中,以此為基礎(chǔ),在不同領(lǐng)域以及不同大小的語料中進行分詞,更加全面地證明本文方法在分詞中的優(yōu)勢。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創(chuàng)業(yè)(2009年10期)2009-10-08 04:52:00
數(shù)字社區(qū)&智能家居(2009年7期)2009-09-29 08:16:48
數(shù)字社區(qū)&智能家居(2009年11期)2009-06-25 04:30:34
數(shù)字社區(qū)&智能家居(2009年3期)2009-04-21 03:09:04
數(shù)字社區(qū)&智能家居(2009年2期)2009-03-27 04:33:44
數(shù)字社區(qū)&智能家居(2009年12期)2009-02-03 07:50:48
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
