基于多神經網絡混合的短文本分類模型①
2020-11-13 07:11:28侯雪亮陳遠平
計算機系統應用 2020年10期
侯雪亮,李 新,陳遠平
1(中國科學院 計算機網絡信息中心,北京 100190)
2(中國科學院大學,北京 100049)
在NLP 領域中,與文本分類算法相關的研究受到了越來越多的關注.文本分類的目的是通過對文本信息的挖掘與處理,來解決信息紊亂的問題,從而能幫助用戶更加精準地定位所需信息,并可根據已定的類別集合將其判定為已知的某一類.目前,在新聞推薦、情感評價、郵件分類等領域受到廣泛應用.文本分類的特點在于能在文本數據量不明確和復雜的情況下,根據預先確定的類別信息,輸出成有價值的信息.
隨著machine learning 和deep learning 等研究方法的不斷完善,文本分類問題的解決路徑也從先前的向量空間模型(VSM)逐步轉移至機器學習和深度學習結合的方法上來[1].在深度學習網絡中,卷積神經網絡CNN 可以識別出文本中預言性的n元語法;卷積結構支持有相似成分的n元語法共同分享其預測行為,即使是在預測的過程中遇見未曾登錄過的特定n元語法也是可以的;而層次化CNN 每層則著眼在句子中更長的n元語法,這樣模型還可以對非連續的n元語法更加敏感,可以對文本分類的效果產生顯著的影響[2].
但是目前的主要研究均集中在長文本和富文本上,對于短文本的研究較少.短文本相比較于長文本和富文本而言,其所含的信息量較少,無法采用統計學觀點進行詞向量分析,傳統的神經網絡對短文本的分類效果較差,尤其是對于標簽值較少的短文本而言,比如新聞標題分類、知識庫分類等,其詞匯量往往不到50 個,而標簽值默認只有一個(相互獨立的分類標簽)[3].所以,本文提出了一種應用于短文本分類的模型,利用TextRank 算法提取短文本中的關鍵詞,然后進行值序列化分析和特征重構,然后在基于FastText 和TextCNN的混合短文本分類模型中進行類別向量的輸出.對比實驗表明,在短文本的分類實驗上,該模型較傳統方法而言,在準確率和處理速度上均有明顯提升.
1 相關概念與基本理論
關于文本分類的模型主要分3 大類:基于概率統計、基于幾何和基于統計,如神經網絡、貝葉斯方法、KNN、決策樹(Decision Tree)、支持向量機(Support Vector Machines,SVM)等.
1.1 基于概率的模型
基于概率的文本模型的核心思想是,假設待分類的文本是D,它所屬的類別集是C={c1,c2,c3,···,cm},基于概率模型的文本分類就是對1≤i≤n計算出對應的條件概率(ci|d),并且將條件概率中出現的最大的類別看作是該待分類文本的類別.當前,基于概率的文本分類模型應用最廣的是樸素貝葉斯分類器[4].
樸素貝葉斯分類器(NaiveBayes)是一種較簡單的分類算法,它的思想基礎是對于指定的待分類項,求解出該項出現條件下,類別出現的概率P,哪個類別的概率最大,就視為該待分類項歸屬于哪個[5,6].基于貝葉斯分類器的貝葉斯規則如式(1):

其中,C和D是隨機變量.
首先計算文本d在每個給定類別下的概率P(ci|d),其后根據概率值的比較,概率最大的對應的類別即為文本d所屬類別.我們對文本d的計算如下:

先驗概率P(ci)的計算如式(3):

其中,N(ci)是 train 樣本中文本類別ci的樣本數量,N為train 樣本的總數,P(ci)表示類別ci在訓練集中所占的比例.
概率P(d|ci)是基于貝葉斯假設得出的:文本d中各詞組間是相互獨立的.因為表示被簡化,所以這就是“樸素”的緣由.事實上,詞組并不是真正意義上的相互獨立,實驗只是假設存在獨立性.在實際應用中,樸素貝葉斯仍可在文本分類的處理中有較好的分類效果.該假設給出了計算聯合概率的方法,并且聯合概率可用條件概率乘積來表示.
P(d|ci)的計算公式如式(4):
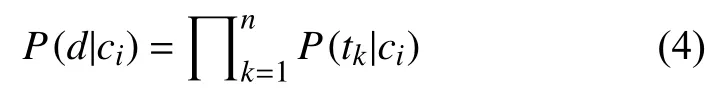
其中,tk表示含有n個詞組的表Vi中的某一詞組,所以,計算P(d|ci)轉為計算詞組表V中每個詞組在每個類別下的概率P(tk|ci).
1.2 基于幾何的模型
基于幾何的模型方法是以向量空間模型為基本出發點,把文本表示為多維的空間向量,其為多維空間里的一個點.構建一個擁有分類性質的超平面,它能把劃分出各個類別.其中最經典的分類器是支持向量機,而最簡單的SVM 本質上就是一個二分類器,可以用來區分常見的正反例數據.SVM 可以構建一個區分類別的N維空間的決策超平面[6,7],并且該超平面可以平行移動,且不會造成錯誤的分類.因此,為了保證預測時的穩定性和魯棒性,我們會希望該超平面與樣本的距離足夠大,即該超平面能夠在邊界區域的中界上.這個理論最初是由Vapnik 等人提出的,并被發展成經典的統計機器學習理論,在二分類問題上擁有非常高效的處理能力.
SVM 中采用了結構風險最小原則,這項原則的提出是以support vector 為基礎,在多維空間里確定一個能把樣本分成兩個類別,且具有最大邊緣值,達到最大化的分類精確度,這樣的超平面為最優超平面[8].
1.3 基于統計的模型
在NLP 研究領域中,基于統計學習的方法稱為了主流,其中最典型的就是K最近鄰分類算法(KNN).它是一種基本的分類與回歸方法.其基本思想是,給定測試用例,用距離去度量找出訓練數據中和它最近的K個實例,然后用這K個最近鄰的實例來做預測處理,最終確定測試用例的類別[6–9].
KNN 算法的過程描述:
1)計算測試用例和各個訓練用例間的距離;
2)對上述計算得出的距離進行排序;
3)選擇距離絕對值最小的K個用例;
4)計算這K個用例對應類別的頻率;
5)選擇頻率最高的類別作為該測試用例的類別.
2 基于多神經網絡混合的短文本分類模型
2.1 關鍵詞提取與特征重構
從短文本中對關鍵詞進行提取,首先需要考慮到短文本與長文本的不同之處在于,在短文本里每個關鍵詞的頻數較小,傳統的關鍵詞提取模型如SKE、RAKE、LDA 和TF-IDF 等則需對大量文本采用統計學分析,從而得到相應的詞頻向量.所以在短文本中關鍵詞的提取方法可以用TextRank 進行處理.
TextRank 模型時主要用于文本的排序算法,它是基于圖特征構建的,并有Google 的PageRank 模型演化而來.其主要思想就是構建一個特征圖,把文本里出現的詞看作節點,邊與邊連接,并且節點和權重一一對應,權重高的節點可以作為關鍵字[10,11].
TextRank 的計算公式如下:

其中,d是阻尼系數,取值范圍0 到1,它表示從圖中某一點指向任意點的概率,一般取0.85.用TextRank算法估計各點的得分時,需給圖中的點初始化任意的數值,并且遞歸計算達到收斂,即圖中任意點的誤差率小于極限值時就視為達到收斂,一般情況極限值取0.0001[12].
TextRank 在短文本中關鍵詞提取的算法如下:
1)將短文本T進行分割:
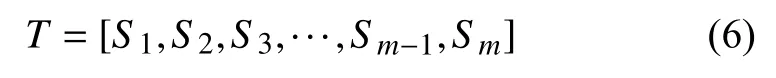
2)進行分詞和處理詞性標注,將停用詞等過濾掉,只留下詞性的部分詞:

3)構建詞圖,候選關鍵詞構成節點集合V.實驗采用了共現關系連接任意兩個節點,并約定兩節點間有邊當且僅當其對應的詞在長度是K的窗口里共現.
4)由TextRank 公式,進行迭代傳播各個節點的權重值.
5)將權重倒序排列,TopN的詞作為待選keyword.
6)在上個步驟中獲取T個詞后,標記原始的文本,若發現產生相鄰詞組,則組合為多詞關鍵詞.
我們對關鍵詞進行向量化處理,并采用了相關性分析,以此能夠對以上產生的關鍵詞特征向量重構.首先在相關性分析方法的選擇上,采用斯皮爾曼相關系數(Spearman’s rank correlation coefficient),又叫秩相關系數,對變量間的秩次作分析,對變量的分布不做規定,是非參數統計方法.與之類似的還有皮爾遜相關系數(Pearson correlation coefficient),但相比之下,斯皮爾曼相關系數擁有更廣泛的適用范圍,并且更契合本文的目的,因此我們用Spearman 秩系數來分析統計特征間的相關性[13].
Spearman’s 系數ρ 的取值范圍為[?1,1].當ρ=?1 時,兩種統計特征負相關,當ρ=1 時,兩種統計特征正相關,當ρ=0 時,兩種統計特征不存在相關性.
Spearman 相關系數的計算公式如下:

其中,N表示樣本總量,和分別表示X,Y的均值.
考慮到我們需對詞向量中各個特征之間的相關性關系進行分析,所以我們采用了Spearman’s 的秩相關系數,并且,更進一步設置了各特征之間的系數閾值,規定短文本數據新特征由系數小于閾值的統計特征決定.
本文實驗中根據短文本的數據特征值進行關鍵詞提取,并創建相關的詞向量,采用Spearman 相關系數進一步分析各個統計特征間的關聯性,最后,我們基于相關性分析的結果組成新的詞向量特征.這種基于關鍵詞提取算法創建短文本的特征空間,可以生成低密度的文本向量,對短文本的分類效果起到顯著的影響.
2.2 多神經網絡混合的短文本分類模型框架
在本次實驗中,我們提出了一種基于多神經網絡混合的短文本分類模型[14],融合了TextCNN 和FastText兩種神經網絡.
FastText 模型分為3 方面:模型架構、層次Softmax和n-gram 特征.模型架構是一個線性模型.它首先需要輸入詞序列到輸入層中,再把字向量級別的n元語法向量組成模型的新特征向量;從inputlayer 到hiddenlayer的過程中,模型把詞信息用文本來完成表示,反饋到線性模型分類中,在outputlayer 中采用Softmax 完成類的概率分布計算[15].
原始的FastText 模型有輸入層、隱藏層以及輸出層,我們的目的是想讓其應用在短文本內容的分類任務上,我們對該模型的輸入層進行了改進,添加了計算模型,即先使用TextRank 算法對短文本內容進行關鍵詞提取處理,然后計算關鍵詞向量化間的相關系數,這一步采用Spearman 進行實現.最后,根據Spearman’s秩相關系數分析詞向量內部各個特征之間的相關性,并選取若干個特征向量作為輸入.這部分輸入后續會經過n-gram 處理得到新的詞序列特征,傳到隱藏層中.改進后的FastText 模型架構圖如圖1.
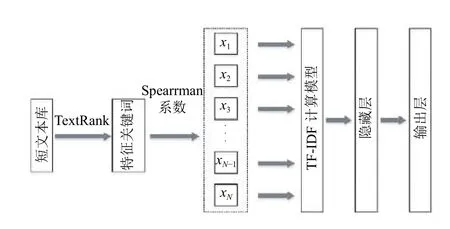
圖1 改進后的FastText 模型架構圖
圖1中,模型的輸入(x1,x2,x3,···)是詞序列或短文本,單層的神經網絡作為hiddenlayer,最終模型的輸出是輸入數據所屬不同類別的概率向量.
在實際實驗中,由于n-gram 易產生冗余詞條,為此,我們將詞條進行條件過濾.在inputlayer 中加入TF-IDF模型,這樣能保存有價值的詞向量,構建新的特征向量.通過映射到hiddenlayer 中,在求解完最大似然函數后做Softmax 處理,構建哈夫曼樹[16].
在這個過程中,葉子節點表征著類別,在構建非葉子節點時要選擇左右分支,若用邏輯回歸表示概率,如下式所示:
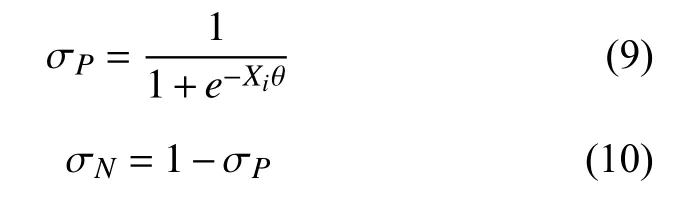
其中,σP表示正類別的概率,σN表示負類別概率,θ為模型中哈夫曼樹節點的一個參數,構建的哈夫曼樹中每個類別均有一條路徑,即訓練樣本的特征向量Xi和類別標簽Yi在哈夫曼樹均會有對應的路徑進行表示.換句話說,我們對Xi的類別進行預測,本質上就是計算Xi屬于標簽Yi的概率,正如下式所示:
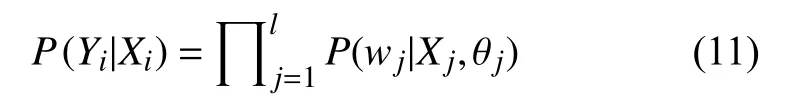
其中,l是樣本詞向量數量,wj是詞向量.
在TextCNN 模型的中,我們對其進行了改進[17].由于短文本中句子的長度有所不同,因此,我們使用padding 操作獲得固定長度n.這樣我們可以保證對于句子里的每個標記信息,都可以擁有固定的維數d.因此,我們的輸入是一個二維矩陣:(n,d).
首先,我們將對輸入進行卷積運算.卷積是過濾器和輸入之間的特殊運算,可將其視為逐元素相乘的運算過程.在模型中,我們有k個濾波器,而且大小為二維矩陣(f,d).現在輸出將是k個列表.每個列表的長度為n–f+ 1.列表中的元素均為標量,第二維采用了詞潛入的維.我們使用不同大小的過濾器,以從文本輸入中獲取豐富的功能.
其次,實驗對模型的卷積運算輸出max-pooling 操作.對于k個列表,我們將得到k個標量.
第三,我們將連接標量以形成最終特征.它是一個固定大小的向量.它與我們使用的過濾器的大小無關.
最后,我們將使用線性層將這些特征投影到每個定義的標簽上.
多模型神經網絡框架的提出主要是根據分治原則用來解決復雜的問題.前人主要利用它解決分類問題,包括臉部的圖像分類和非平衡問題.它將原始集分為多個集合,最后進行策略合并來輸出分類的結果.本文提出引入的多神經網絡的目的與之類似,主要采用不同類型的神經網絡特點彌補單一類型神經網絡的缺點.
改進后的TextCNN 模型結構圖如圖2.

圖2 改進后的TextCNN 模型結構圖
給定一個輸入input1={Ci|w1,w2,w3,···,wn},即每個輸入由一個類別Ci和若干詞wn組成的句子構成,其中Ci是該輸入數據的目標類別,每個輸入僅有一個,對應這個輸入的一個方面.比如輸入“國際| 美國總統特朗普9月11日宣布國會議員人選將不再限制綠卡持有量”,其中“國際”代表著該輸入的目標類別,象征著該輸入的一個特定屬性.而本文主要解決的問題就是在未知類別屬性下,通過對語句的識別與理解,將該短語正確的劃分到給定的類別中.但是由于短文本分類中存在很多棘手的問題,比如輸入信息不足,類別向量太少,噪音太大等,導致短文本分類一直處于較低的準確水平.我們嘗試將原始輸入數據進行關鍵詞特征重構,通過對短文本的詞義分析進行挖掘重要特征,并采用更適合多分類的模型進行向量輸出.在已知原始輸入input1={Ci|w1,w2,w3,···,wn}的情況下,通過特征重構得到input2=其中是通過對詞義分析而得到的特征詞,用以表征該輸入的多個類別信息,用作對Ci的有效補充.在上述輸入例句中,可將“特朗普”、“美國”、“總統”、“國會”、“綠卡”等關鍵詞特征進行重構提取.
在區域ri中,其長度為h,我們將每個詞映射成m維的值向量,從而可將區域表示成ri={x1,x2,x3,···,xh}.把文本里每個區域作為TextCNN 的輸入矩陣,并對該區域進行卷積運算[18],卷積核的長度為l:

式中,w∈Rm×l是模型的卷積核權重值,而b∈R則是模型的偏置項數據,在這個模型中通過卷積層,每個區域均可獲取區域ri對 應的特征圖c∈Rh?l+1:

在區域ri中,采用max-over-time pooling 對局部特征進行采樣,提取特征圖的有效信息[18],即=max{c},下采樣的信息圖可表示為:
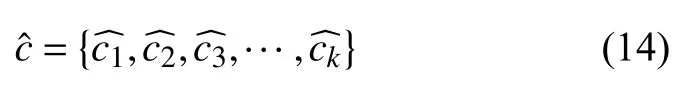
我們假設了兩種文本分類算法可以應用于不同的處理場景.如上文所述,TextCNN 和FastText 都可以用來進行文本分類,但解決的問題存在區別,TextCNN 在短文本分類中較重視詞向量,作文本分析或者主題分析較合適,但由于TextCNN 需對詞向量進行多次卷積運算,導致運行時間較長.所以從模型結構角度來說,FastText 采用了更加簡單而又高效的文本分類以及表征學習方法,所以在文本分類中的多標簽值問題中更為合適,且運行耗時很短,但是在短文本中由于缺少更多信息的補充,導致算法的準確度大幅降低.
因此,我們利用TextCNN 來處理單標簽分類與短文本工作,用FastText 來處理多關鍵詞的主題分類工作.優化后的神經網絡框架如圖3所示,不同于傳統的單一任務處理工作,本模型將原始集進行分而治之,分別采用TextCNN 和FastText 進行文本的處理工作,并在合并層進行類別向量的融合:

在多神經網絡混合的短文本分類模型框架中,在輸入層部分,數據來源有兩個類型:“標簽值+多關鍵詞”作為多分類,“標簽值+短文本”作為文本分析.簡言之,這個模型的輸入主要有多關鍵詞和短文本構成.FastText 模型負責處理多關鍵詞特征,而TextCNN 負責處理短文本內容.
我們采用Softmax 函數處理文本的類別輸出:

其中,W為權重矩陣,b為偏置項,我們用最小化的交叉熵優化混合模型,交叉熵計算如下:
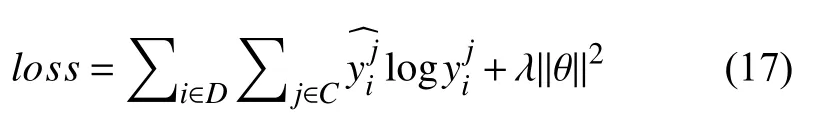
式中,D為訓練集文本數據,C為數據的類別樹,y是待分類短文本句子的預測性類別,為短文本的實際類別,λ∥θ∥2為式子的交叉熵正則項.

圖3 多神經網絡混合的短文本分類模型框架
兩種神經網絡模型的輸出在合并層進行融合,形成短文本類別的向量輸出,合并層的具體融合方式如式所示執行,C1和C2分別表示兩種分類算法的中間輸出向量,代表混合短文本分類模型中關鍵詞和短文本各自的影響力,由于C1和C2都是用來表征文本類別向量,所以它們的維數是一致的.它們按照影響比例進行相加,其中 β參數負責控制FastText 和TextCNN 模型對最終類別向量輸出的影響效力,β的數值越大,即表示混合模型中FastText 模型的類別輸出向量對短文本類別向量的影響力就越高;反之,混合模型中TextCNN模型的類別輸出向量對短文本類別向量的影響力就越高.
2.3 Dropout 防止混合模型的過擬合
在文本分類模型框架中加入Dropout 的目的是將其應用于詞向量的分類中,能夠使得模型降低對于噪音的敏感度,防止因噪音導致過擬合[19].在某種程度上,Dropout 可作為文本數據增強的方法,將詞向量修剪得更為準確.
2.4 模型對比
傳統的短文本處理方法有RNN、LSTM、GRU、RCNN 等模型,一般通過Doc2Vec 或者lDA 模型將文本轉換成一個固定緯度的特征向量,然后再基于抽取的特征訓練一個分類器.
FastText 模型相比于其他模型,在訓練速度和算法準確率上有了更好的表現,主要做了如下改進:
層次Softmax:針對有大量類別的數據集或者是類別不均衡分布的數據集,FastText 模型的層次Softmax技巧通過對標簽信息進行編碼,可以縮小模型預測的目標數量.該技巧建立在Huffman 編碼的基礎上,用來表征類別的樹形結構,當類別數為K,word embedding大小為d時,計算復雜度可以從O (Kd)降到O (dlog(K)),使得模型的計算效率更高.
n-gram:相比于傳統方法采用的詞袋模型不能考慮詞之間的順序,FastText 模型加入了n-gram 特征,通過對詞序的記錄進行區分詞的信息,使得模型的可讀性更強,提高了短文本的語義理解能力.模型把所有的n-gram 哈希到buckets 數量的桶中,并共享一個向量,這樣既保證了在查找時 O (1)的效率,也把內存消耗控制在O (buckets?dim)范圍內.
Subwords:subwords 可以理解為是字級別的ngram,它豐富了詞表示的層次,對相同字信息能夠有更好的語義相似性識別能力.這種技巧對低頻詞生成的詞向量效果會更好,并且對于訓練詞庫之外的單詞,也可以構建詞向量.
FastText 模型的架構中只有一層的隱藏層和輸出層,保證了模型在CPU 上能實現分鐘級的訓練,更容易在工程應用上進行部署.但是也正因此,模型只能對單個標簽進行分類,在做多標簽處理時,模型也僅會隨機選一個label 進行模型的更新,導致其他信息被忽略,不適合做多標簽的分類應用.
TextCNN 模型是CNN 模型的一個變種,可以充分發揮CNN 的并行計算能力,訓練速度更快,在保留了原始CNN 的特點之外,還加入了對文本特征的抽取能力.TextCNN 采用一維卷積來獲取句子的n-gram 特征表示,具有很強的文本淺層特征抽取能力.模型可以識別出任務里具有語言性的n元語法,在預測過程中遇見未登錄的特定n元語法時,它的卷積結構還可以讓有相似元素的n元語法分享預測的行為,并且層次化的CNN 的每一層都關注著句子里更長的n元語法,使得模型可以對非連續的n元語法更加敏感.TextCNN通過調整卷積核的高度,可以對綜合詞匯的多種時序信息進行靈活處理,提高了模型對文本的解讀能力.
2.5 混合模型的特點
模型對數據的整體處理流程為:文本序列中的詞和詞組構成特征向量,特征向量通過線性/非線性變換映射到中間層,中間層再映射到標簽數據上,輸出文本對應的標簽值.本文中混合模型其實是兼顧了文檔向量和特征抽取的能力,保證了模型在遇到復雜多變的數據集時的多態性.
FastText 模型的輸入層到隱藏層部分,主要生成用來表征文本的向量;模型的隱藏層到輸出層是一個Softmax 線性的多類別分類器.它更適用于分類類別非常大且數據集足夠大的情況,當類別數較小或數據集較小時容易導致過擬合.而TextCNN 采用了max pooling操作,可以保證文本的特征的位置與旋轉不變性,強特征的提取效果不受其位置所限制.此外,max pooling能夠減少模型參數數量,有利于減少過擬合問題.但是這也容易導致TextCNN 丟失特征的位置信息,并且無法記錄同一特征的強度信息.
此外,FastText 模型為了保證句子詞向量的相似性(模型要求詞向量按照相同的方向更新),沒有添加正則項,從而導致模型的泛化能力減弱.而TextCNN使用預訓練產生的詞向量作embedding layer,并且在本文實驗中采用混合向量(基于字向量、靜態詞向量、動態詞向量)進行文本中詞信息的表示,能夠捕捉到更多的語義信息,以此來減少數據集的影響,提高模型的準確率.同時,TextCNN 在池化層后加了全臉階層和Softmax 層做分類任務,并且加上了L2 正則項和Dropout 方法,來防止模型的過擬合問題,最后整體使用梯度法進行參數的更新模型的優化.
3 實驗驗證
3.1 實驗數據
為了確認該短文本分類的混合模型的算法有效性,同時也為了在長文本中驗證其效果,實驗選擇了相關的公開數據集:
1)TTNews:短文本采用今日頭條的公開新聞數據集進行實驗驗證,數據文件中每行是一條數據,以_!_符號進行分割,文本格式內容依次為新聞的ID 編號,新聞分類編碼code,新聞分類的名稱信息,新聞標題title 和新聞關鍵詞keyword.數據采集時間為2018年05月,共計有382 688 條,有15 種新聞類別,每種新聞類別對應的數據量大小如表1所示.

表1 TTNews 數據集中類別統計
為了保證是短文本數據集,本次實驗是選用兩個關鍵數據:新聞分類名稱和新聞對應的標題,比如“news_entertainment 胡歌為林心如澄清娛樂界謠言,最后發現純屬烏龍”.
2)THUCNews:長文本實驗方面,實驗采用了清華大學的THUCNews 數據集,該數據集是由新浪新聞在2005~2011年間的所有數據經過濾產生的,包含了74 萬篇的新聞文檔,均是UTF-8 純文本格式.進一步在原始的分類基礎之上,劃分了14 個待選的類別:Education,Technology,Finance,Stocks,Home,Social,Games,Fashion,Current Affairs,Lottery,Real Estate,Sports,Constellation,Entertainment[20].如表2.

表2 THUCNews 數據集中類別統計
3.2 數據處理
首先需要對上述文本數據集進行自動分詞,本文采用中文分詞工具NLPIR 漢語粉刺系統,調用GitHub上開源的工具包進行文本分詞,每個詞用空格分開.并且將數據處理為每條新聞文本為一行,每行的末尾使用“__label__”特殊字符串.
對分詞后的數據進行清洗,去除無意義的語氣詞、特殊符號、錯詞等,把有效數據進行整理.我們將traindata 和testdata 按照8:2 的比例劃分,并用shuffle函數將原始數據打散.
3.3 評估指標
本次實驗我們采用了常用的評估標準,包括:召回率R(Recall)、準確率P(Precision)和F1-分數(F1-score).
我們假設文本分類針對數據c1的類別劃分結果如表3所示.

表3 類別劃分結果
實驗在類別c1的召回率計算如下式:

實驗在類別c1的準確率計算如下式:

F1-score:也稱F1 分數,是分類問題中的重要衡量指標.在計算方法上,它同時考慮了模型的精確率和召回率兩個指標,所以可將其視為準確率和召回率的調和平均數,最大是1,最小是0.計算方式為:

3.4 實驗對比算法模型
本次實驗的對比算法包括:CNN、RNN、TextCNN、TextRNN、FastText、Seq2seqAttn、RCNN 等模型.
3.5 實驗參數
在混合模型的實際訓練中,模型整體保持了較高的運行效率,在訓練時間上的消耗見實驗結果表3.
FastText 模型中最重的兩個參數分別是:詞向量大小維度dim 和subwords 范圍的大小subsize.其中,dim 越大,模型就能獲得更多的信息但同時對訓練數據的要求也就更高,而且訓練速度也會降低,因此本實驗中詞向量的維度dim 選100.Subwords 是單詞序列中包含最小min 到最大max 之間的所有字符串,根據本文實驗數據我們設置為1~3 之間靈活調整,以便能夠從數據中識別出中文特有的屬性(如人名、專有名詞等信息).在訓練參數上,本實驗的epochs 設為10,學習率Lr 設為0.1.FastText 是基于多線程的,根據本文實驗環境,對CPU 核數調整為16.
TextCNN 模型的輸入采用基于Word2Vec 和glove的混合詞向量,具體包括字向量、靜態詞向量和動態詞向量.因為在處理NLP 任務時需要對文本進行截取,在短文本實驗中padding 值為50,長文本實驗中padding值為300,卷積核的尺寸filter_size 范圍區間可取(1,10),在短文本實驗中取{2,3,4},在長文本實驗中取{3,4,5},每個filter 的feature maps 取100,因此,短文本實驗中的卷積層大小為50×100,長文本實驗中卷積層大小為300×100.卷積核的數量filter_nums 范圍區間可取(100,600),dropout 范圍區間可取(0,0.5),在本文實驗中統一取filter_nums 為150,dropout 取0.5.實驗中采用ReLU 激活函數進行處理,池化層選擇了1–max pooling,為了進一步檢驗模型的性能水平,本文實驗采取了交叉驗證處理.在模型的訓練參數上,本實驗主要設置batch_size 為64,num_epochs 為10.
3.6 實驗結果分析
本次實驗采用短文本數據集TTNews 對算法模型進行測試驗證,并用長文本數據集THUCNews 對各算法模型進行比較,進一步驗證所提的多神經網絡混合的短文本分類模型在實驗數據上的有效性,實驗結果如表4和圖4所示.
從表4和圖4的實驗結果可以看出,本文提出的多神經網絡混合的短文本分類模型在TTNews 數據集和THUCNews 數據集上都取得了較好的文本分類效果.尤其是在短文本分類(TTNews 數據集)上,該模型的分類準確率達到了92.03%,相比于原始的FastText模型、TextCNN 模型分別提升了13.98%、6.92%;在長文本分類(THUCNews 數據集)上,該模型的分類準確率達到了95.65%,相比于原始的FastText 模型、Text-CNN 模型分別提升了1.48%、3.81%.在模型的召回率和F1 分數等評價指標上,也能很明顯看出混合短文本分類模型的效果相比于原始的FastText 模型、TextCNN模型均有明顯的提升效果,從而驗證了本文提出模型的有效性.

表4 不同模型在數據集上的實驗結果(單位:%)

圖4 不同模型在數據集上的準確率、召回率和F1 均值
β超參數的主要作用在于調節關鍵詞和短文本內容對混合分類模型最終分類向量輸出結果的影響.因此針對不同的特點的文本分類數據集,β參數的取值會影響到多神經網絡最優的輸出結果.在圖5中我們可以發現,在短文本數據集TTNews 下,β在0.35 取值時整體的文本分類精確度達到了最高,在長文本數據集THUCNews 下,β在0.70 取值時整體的文本分類精確度達到了最高.產生這一現象是因為,FastText 更適合長文本分類,且對標簽值的依賴性更高,需要輸入多個標簽值對文本進行劃分.而TextCNN 采用了多層神經網絡和卷積層,對文本的要求度不高.實驗結果在某種程度上也證明了神經網絡分類模型中對文本大小的關聯性.
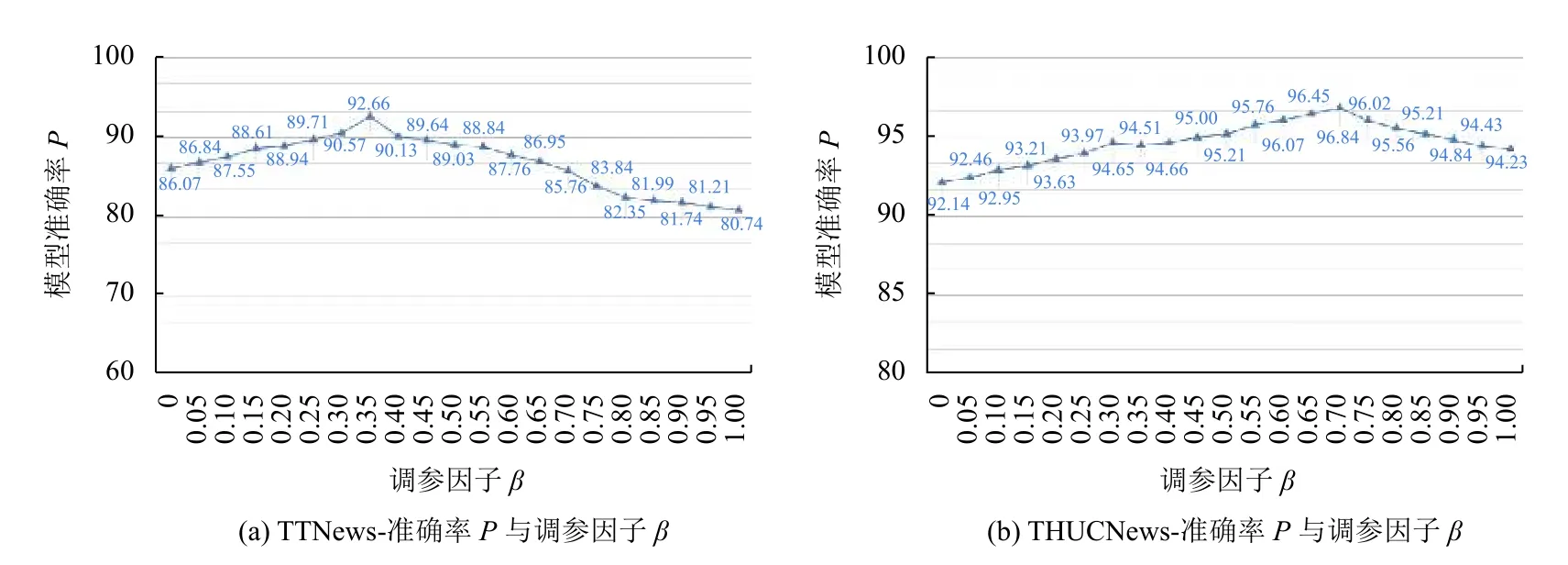
圖5 本文模型的準確率與調參因子β 的變化
本文在相同數據集和相同的訓練環境下(保證了各變量的控制條件),分析了各模型的訓練時間,并對比分析了它們分別在短文本數據集(TTNews)和長本文數據集(THUCNews)上的實際效果,結果如圖6.

圖6 不同模型在數據集上的訓練時間對比
從圖6可以看出,在相同的訓練環境下,本文所提出的多神經網絡混合短文本分類模型兼顧了FastText模型訓練收斂較快的優點.相比于其他的神經網絡模型而言,混合短文本分類模型能夠大幅降低訓練時間,這是因為在處理多關鍵詞的分類時,將數據灌入了FastText模型,而短文本內容則在TextCNN 模型中進行分類,這樣能夠使訓練任務得到均衡分配.
4 結論與展望
本文提出了將短文本內容進行關鍵詞提取并重構短文本特征,將重構后的特征值作為FastText 模型的輸入,原始的短文本內容作為TextCNN 模型的輸入,并引入參數 β將類別向量進行調節,作為融合的輸出向量進行類別分析.在多神經網絡混合的短文本分類模型中,把兩種文本分類算法進行深度融合,針對短文本分類的特點進行實質化改進,從而兼顧了FastText 模型和TextCNN 模型的特點.最終實驗結果表明本文提出的多神經網絡混合的短文本分類模型在短文本分類情景下的精確率、召回率和F1 分數等指標都表現出優越的算法性能,相比其他的文本分類算法更為突出、高效.
本文的主要研究關鍵點在于短文本內容的分類算法和對分類算法的融合應用,同時也針對短文本內容的特點進行了特征重構,將分類任務均衡化來解決相應的問題.但是對于從短文本中提取與主題關聯度契合度更高的關鍵詞這一步仍有很大的改進空間.由于短文本內容往往包含的信息量較少,如新聞標題、用戶評價文本等,所以如何從信息度較低的短文本內容中提煉出符合要求的關鍵詞是下一步需要研究的工作重點.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
