基于標記語言的跨平臺并行編程框架設計①
2020-11-13 07:11:54唐佩佳鐘旭陽
計算機系統應用 2020年10期
唐佩佳,徐 云,鐘旭陽
1(中國科學技術大學 計算機科學與技術學院,合肥 230027)
2(安徽省高性能計算重點實驗室,合肥 230026)
并行計算是目前主流的提高計算機系統計算速度和處理能力的一種有效手段,可將原有的串行程序改造為并行程序來解決性能問題,充分利用并行計算技術提高數據處理能力.而串行程序并行化的過程需要專業的并行編程能力,需要大量的工程成本.同時,隨著各種并行計算平臺數量的增加,并呈現出多樣化,需要保證并行程序有一定的跨平臺性,使得并行程序可在多個并行平臺上跨平臺運行.然而,不同的并行計算平臺的硬件、所適用的并行模型和運行時環境都各不相同,這對程序的可移植性提出了嚴峻的挑戰.
串行程序并行化的工具或系統可以分為兩類:一類是采用專用編譯器等自動并行化工具直接將串行程序自動并行化,編譯器開發成本較高,而并行效率不高.比如斯坦福大學的SUIF 編譯器[1]和Mathews 的ACP編譯器[2],為了保持原有串行程序語義,導致編譯器的策略非常保守,實際效果不太理想.其他工具例如Cetus[3]、Par4all[4]、Pluto[5]僅可實現循環級別的并行,不支持任務并行.S2P[6]雖然提供了任務級并行,但其并行粒度沒有優化.現有自動并行化工具支持的并行平臺較少,僅僅包括共享存儲平臺的少數系統和少量異構平臺.另一類是采用加編譯制導的編譯器或并行編程框架,對串行程序進行輔助標記來實現并行化.
常見的并行編程平臺主要有共享存儲和分布式存儲兩類.共享存儲平臺下,OpenMP 采用在串行程序中添加并行標記語句的方法來實現并行化,這種方法會產生較好的并行效果但需要一定的標記工作量,系統好壞取決標記方法和工作量的大小.Blumofe 提出的Cilk/Cilk++[7,8]是一種基于C/C++的多線程并行編程模型,是在原有C/C++的基礎上提供和并行相關的制導標記,實現任務分解和并行.Habel 等[9]實現了一種基于標記的分布式并行編程框架的設計,該框架提供了數據來源和分布的標記,通過源到源編譯器將標記解析為并行程序,但該框架僅支持矩陣密集型的科學計算.分布式存儲平臺下,MPI 并行編程模型采用消息傳遞機制完成并行計算和同步通信;以FORTRAN90 為基礎的HPF[10]并行編程模型,通過制導語句實現數據并行制導和數據映射制導.Sourouri 提出的Panda[11]異構并行編程框架可將帶標記的串行代碼轉化為MPI或MPI+CUDA 并行代碼,但該框架缺少運行時系統.
同時支持共享存儲和分布式存儲的并行編程框架不多見,這些系統和框架往往與應用任務特性相關或一些特定并行編程模型相關,實現或生成的并行程序效率也是一個問題.Liu 等[12,13]提出了一個基于任務和管道(TNC)模型的并行編程框架.應用程序分為主程序層和任務實現層.主程序層與平臺無關,框架提供定義和啟動任務和管道的接口;任務實現層與平臺相關,具體各類型任務和管道由平臺相關編程方法實現,框架再將任務和管道封裝,管道負責各任務間的通信.應用程序主程序層可以保持不變,任務實現層根據不同目標平臺調整,從而提高并行程序的維護和可移植性,但該方法在分布式環境下通信開銷較大.Kutil[14]提出了基于面向對象的C++的編程框架,支持共享存儲平臺和分布式存儲平臺.該方法將矩陣運算分解為無通信的子運算,由框架負責具體的數據通信,但該方法的并行化設計僅針對矩陣運算領域,無法擴展到其他計算任務.
為了解決上述問題,本文提出了一種基于標記語言的三層并行編程框架.我們對共享和分布式存儲編程平臺的基本并行特性進行抽象,提取各并行編程平臺并行程序的基本結構和共同點形成跨平臺的標記語言.實現了二個層間轉換過程,一個是串行程序層到并行中間代碼層轉換,采用對串行程序進行并行標記得到有并行語義的程序代碼;另一個是并行中間代碼層到目標并行編程語言程序層轉換,采用對并行中間代碼進行解析映射的方法,輔助并行編程框架實現目標并行平臺的并行程序轉換.
1 框架總體結構
1.1 框架的層次模型
為了使框架結構清晰,設計了一個跨平臺的分層并行編程模型,共有3 層,分別是:上層、中層、和下層.如圖1所示.

圖1 編程框架的層次模型
上層是用戶的串行程序層,是平臺無關的.中層是與串行程序對應的、帶有制導標記的中間代碼,有并行語義但與平臺無關.下層是目標并行編程語言程序層,可在并行計算執行模型上運行,與平臺相關.
并行計算執行模型主要包括:成熟的通用并行計算執行模型,例如Pthread、OpenMP、MPI 和CUDA、OpenACC 等;特殊應用并行編程模型,例如Vxworks下多任務并行編程模型.
底層硬件平臺主要包括共享存儲多核CPU 平臺、分布式存儲Cluster、異構GPU 三種類型.
1.2 框架處理流程
利用框架將一個串行程序實現并行化的流程如圖2所示.首先輸入選擇待轉化的串行程序文件,進入第一個層間轉換階段:在串行程序定義的位置添加并行標記或者在需要并行參數尋優和同步控制等功能的位置添加相應的標記,得到有并行語義的程序代碼.然后進入第二個層間轉換階段:并行編程框架將逐一解析各并行標記,結合用戶界面輸入的目標平臺參數,經過一系列映射過程后得到目標并行編程語言程序.

圖2 編程框架的處理流程模型
2 跨平臺并行化實現
對串行程序進行簡單標記,再經過解析映射得到能夠并行地在共享存儲平臺、分布存儲平臺和GPU平臺等多種平臺上正常運行的目標并行編程語言程序.主要研究基于標記的串行API 跨平臺并行化方法,包括兩個層間轉換過程:(1)并行中間代碼生成;(2)基于標記信息的解析映射.
2.1 并行中間代碼生成
標記語言用于輔助并行編程框架實現目標并行平臺的并行程序轉換,是并行編程框架的重要組成部分.我們對多種并行平臺語言的基本并行特性進行抽象,因此標記語言是一種可表示并行語義的跨平臺標記語言,命名為Sigma 標記語言(以下簡稱標記語言).以簡潔易用、功能齊備的指導原則,設計了類似OpenMP的三段式標記語言.標記語言的指令結構如圖3所示.

圖3 標記語言結構
標記語言共有5 類19 條,包括并行、輔助并行、性能、平臺等類型的標記,標記語言與平臺無關.
本文研究的工程背景是雷達數據處理.以雷達數據為代表的此類工業數據有以下幾個特點:
(1)數據規整.每個數據包都有固定的大小,包含多批固定長度和類型的數據.
(2)數據獨立性.各個數據包彼此獨立不相關,可以單獨處理,對有的處理過程,數據包的各批次數據可以被單獨處理.
(3)周期性.每個數據包按固定周期到達.
針對上述數據特點,并行方式采用數據并行.并行標記設計為#sigma parallel_task [標記子句].
并行標記提供了數據并行所需要的信息,有4 個標記子句:
(1)src_data:提供串行API 輸入數據源、數據類型和數據長度;
(2)dst_data:提供串行API 輸出數據源、數據類型和數據長度;
(3)group:提供分組(批)數,即數據源可以劃分為若干批或組來相對獨立的處理;
(4)varlist:串行API 的其他參數.
采用對串行程序進行并行標記得到有并行語義的程序代碼,即第一層間轉換階段.
在一個需要并行化的數據處理串行API 的定義位置添加并行標記得到并行中間代碼,如圖4所示.

圖4 并行中間代碼
2.2 基于標記信息的解析映射
采用對并行中間代碼進行解析映射得到目標并行編程語言程序,即第二層間轉換階段.
用戶在并行編程框架界面選擇目標平臺參數(硬件平臺、操作系統和并行計算執行模型等)后,框架將2.1 中的并行中間代碼進行解析映射可以得到目標平臺并行語言編程程序.具體步驟如下:
(1)標記解析.并行編程框架將并行中間代碼進行解析,得到標記提供的數據并行參數,如輸入數據源srcname、輸入數據源大小srcsize、輸出數據源dstname、輸出數據源大小dstsize、分批數num 和其他參數;
(2)標記映射.并行編程框架將并行中間代碼映射為基于數據并行的目標平臺并行語言編程程序,
框架對多種并行平臺語言的基本并行特性進行抽象.以Pthread 多線程線程池并行編程模型和MPI 并行編程模型為例,展示共享存儲平臺和分布式平臺的并行程序架構對比如表1所示.

表1 共享存儲平臺和分布存儲平臺并行程序結構對比
由表1可知,并行程序的主要結構包括數據劃分和分發、調用原串行API、數據收集等部分.其他可用于數據并行的OpenMP 模型和Vxworks 系統并行模型等并行編程也滿足類似結構.
因此,并行編程框架根據這個主體結構封裝了多個目標平臺下的基礎并行代碼段,主要用于并行初始化、數據分發和收集、并行計算執行等.這些代碼段將使用上述(1)標記解析得到的并行參數.標記映射過程,即目標并行平臺代碼生成過程如算法1 所示.

算法1.并行標記映射算法輸入:數據并行參數srcname、srcsize、dstname、dstsize、num 等,串行API 名稱,numprocs 為并行處理單元數(共享存儲平臺的計算單元是線程,分布式存儲平臺的計算單元是節點進程);目標平臺參數(硬件平臺、操作系統和并行計算執行模型等).輸出:并行代碼.1)寫初始化部分代碼.主要實現并行初始化和臨時變量定義,變量空間申請,框架根據不同的目標平臺使用不同的并行初始化代碼段.2)寫數據劃分部分代碼.主要實現將num 批數據劃分為numprocs份;劃分方式有靜態和動態劃分兩種,框架根據用戶選擇的劃分方式調用不同的函數實現,函數參數將使用num 和numprocs.3)寫數據分發部分代碼.主要實現將數據分發到每個并行處理單元.共享存儲平臺使用自定義函數Data_trans,以傳遞存儲地址實現,分布式存儲平臺的數據分發使用MPI 自帶消息傳遞函數,以傳消息實現.框架根據不同的目標平臺調用不同的數據分發代碼段,代碼段將使用srcname 和srcsize 參數.

4)寫數據處理部分代碼.主要實現數據的并行處理.共享存儲平臺以線程方式調用串行API,分布式存儲平臺以進程方式調用串行API.框架根據不同的目標平臺調用不同的并行計算執行代碼段.5)寫數據收集部分代碼.方法與3)類似,主要實現收集各并行計算單元結果.框架提供的代碼段將使用dstname 和dstsize 參數.6)寫結束收尾部分代碼.主要實現變量空間回收和并行環境結束工作.
算法1 的第2)步中的數據劃分方式有靜態劃分和動態劃分.靜態劃分是均勻劃分,數據劃分的塊數與并行處理單元數相等.動態劃分指的是根據并行參數自動尋優的結果來進行劃分,并行參數尋優的方法見3.2.假設有4 個并行處理單元(共享存儲平臺的計算單元是線程,分布式存儲平臺的計算單元是節點進程)來處理一個數據集,兩種劃分方式如圖5所示.

圖5 數據劃分方式示意圖
劃分后的數據是相對獨立的,在數據處理過程中各并行處理單元之間沒有數據交換和同步,不會出現數據競爭.對于某些有數據交換和同步需求的程序,參考fork/join 模型,將源程序中數據交換和同步部分保持不變,仍然采用串行執行,將剩余部分封裝為一個或多個新的API,再對新API 進行并行化.原串行程序的可并行部分通過并行化提高了運行效率,不可并行部分實現了數據交換和同步功能,在保證原程序的總體功能實現的前提下實現了原串行API 的并行化.第4節中的副瓣對消計算實例即按此方法實現.
算法1 的第4)步中共享存儲平臺的多線程實現所涉及的并行計算執行代碼段包括:Pthread 模型、OpenMP模型和VxWorks 系統并行模型,分別使用Pthread 線程池、OpenMP 多線程制導和VxWorks 多任務實現.
算法1 的第1)和6)步在全部并行計算完成前僅需執行一次,為了提高易用性,將算法1 的2)到5)封裝為并行API 以供多次調用,同時保持并行API 和串行API保持參數列表的一致,增加了可讀性.
針對GPU 平臺并行程序的特殊程序結構,即host/device 混合編程模型,并行框架增加了面向GPU 平臺的kernel 標記手段,可將kernel 標記解析映射為CUDA API 并行實現.
3 并行參數自動尋優
并行參數自動尋優的目的是幫助用戶選擇最優的并行參數,優化并行效果.并行參數包括線程數、節點數和數據劃分比例等,綜合影響因素和優化效果,共享存儲平臺和分布式存儲平臺分別挑選線程數和數據劃分比例作為優化對象.使用并行參數自動尋優標記后,框架將會生成目標并行平臺下的并行參數自動尋優程序.
(1)共享存儲平臺
框架可自動計算不同的線程數下程序的耗時,并擇優確定最佳線程數.具體過程見算法2.

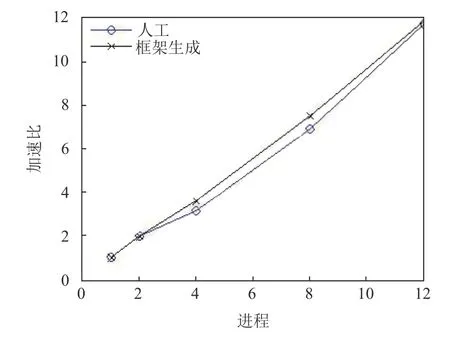
算法2.共享存儲平臺并行參數自動選優算法輸入:線程數集合P=2:N,N 為物理核數,最小耗時初始值Tmin 初始化為最大值;輸出:最佳線程數Popt;1)for each 線程p 屬于P 2)統計多次并行函數運行平均耗時t;3)if t 標記使用方法:將標記#sigma auto_optization_SM_start 和#sigma auto_optization_SM_end 分別加在并行域的開始和結束位置即可. (2)分布式存儲平臺: 框架可自動收集同一個算例在不同的節點運行耗時后確定最佳數據分配比例,實現負載均衡.具體過程見算法3. 由節點耗時計算任務分配比例的公式如下所示: 其中,Ti是多次標準算例運行平均耗時,N是分布式存儲平臺的節點數,Li是節點i的任務分配比例. 由任務分配比例計算任務量的公式如下所示: 其中,W是待分配的任務總量,Wi是節點i所分配得到的任務量. 算法3.分布式存儲平臺并行參數自動選優算法輸入:分布式存儲集群有N 個節點,待分配的任務總量W,標準算例;輸出:各節點的任務量w;1)for each node i 2)統計多次標準算例運行平均耗時Ti;3)收集其他節點的耗時Tj,j∈{1:N }但j≠i;4)通過式(1)計算節點i 的任務分配比例;5)通過式(2)計算節點i 的任務量;6)end for 7)return 各節點的任務量w; 標記使用方法:將標記#sigma auto_optization_DM 加在并行域的開始位置即可. 雷達信號處理是典型的工程應用,涉及大量的數學變換和矩陣運算,我們選取脈沖壓縮、副瓣對消、雷達圖像處理3 個處理過程來測試我們的并行框架. 首先,對并行框架的功能性進行測試,即考察并行框架是否能正確實現跨平臺并行化. 以副瓣對消串行API 程序并行化為例.首先,對副瓣對消串行API 程序添加并行標記,選擇目標并行平臺為“共享存儲多核平臺-Linux-Pthread”和“分布式存儲平臺-Linux-MPI”后,并行框架對標記進行解析映射后,可以生成共享存儲多核平臺(Linux)上的線程池的并行程序和分布式存儲平臺(Linux)上的基于MPI 的并行程序.兩個并行程序的運行結果和原串行程序一致,證明本文的并行框架具備跨平臺并行能力. 其次,對框架生成的并行編程語言程序的性能也進行了測試. (1)共享存儲平臺 以脈沖壓縮串行程序為例,對于框架產生的Pthread脈沖壓縮并行程序,將并行度分別取2、4、8、12 時,即線程數分別取為上述值時,統計程序運行耗時.并行程序運行的硬件條件為:共享存儲平臺Intel(R)Core(TM)i7-8700K CPU @ 3.40 GHz,CPU 6 核12 線程,Linux. 由程序運行耗時計算的加速比如圖6所示,由圖可知,兩種方式產生的并行程序均取得了較好的加速比,由于框架自動生成的并行程序的冗余代碼較少,代碼規范且執行高效,其加速比要略優于人工實現的并行程序. 圖6 脈沖壓縮并行程序取不同并行度時并行化加速比 (2)分布式存儲平臺 以雷達圖像處理串行程序的并行化為例,對于框架產生的分布式圖像處理并行程序,將并行度分別取1、8、16、24 時,即進程數分別取為上述值時,統計程序運行耗時.并行程序運行的硬件條件為:雙AMD(R)Opteron 6168 處理器,每個處理器有12 個計算核心,Linux 操作系統. 由程序運行耗時計算的加速比如圖7所示,由圖可知,由并行框架生成的并行程序的加速比與人工實現的并行程序相當. 圖7 圖像處理并行程序取不同并行度時并行化加速比 我們設計了一種基于標記語言的上層(串行程序層)、中層(并行中間代碼層)和下層(目標并行編程語言程序層)的三層并行編程框架.我們對多種并行平臺語言的基本并行特性進行抽象,形成了一種可表示并行語義的跨平臺標記語言.標記語言輔助并行編程框架完成了二個層間轉換過程,實現了目標并行平臺的并行程序轉換,解決了串行代碼自動跨平臺并行化的問題,僅需一次標記,即可得到多個平臺的并行程序.將框架應用于雷達數據處理程序并行化改造,實驗結果表明,該框架可以生成目標并行編程平臺的并行代碼,且經過系統參數優化的并行代碼加速比相當或優于人工實現的并行代碼.


4 實驗分析

5 結論與展望
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛生(2015年3期)2015-11-19 02:53:32
核科學與工程(2015年4期)2015-09-26 11:59:03
