卷積神經網絡的聚焦均方損失函數設計①
2020-11-13 07:12:04徐銳,馮瑞
計算機系統應用 2020年10期
徐 銳,馮 瑞
1(復旦大學 計算機科學與技術學院,上海 201203)
2(上海視頻技術與系統工程研究中心,上海 201203)
從圖片中進行2D 人體姿勢估計是許多計算機視覺高階任務的基礎,例如動作捕捉,手勢識別和活動識別等.在神經網絡出現之前就有很多基于圖結構模型(pictorial structure model)的方法[1–7]試圖去解決這個問題.但是隨著卷積神經網絡和大規模數據集的出現,可以讓網絡模型即使在苛刻的場景中也表示出良好的預測效果,而無視人體姿勢的約束和大的外觀的變換.DeepPose[8]首先將卷積神經網絡帶入人體姿勢估計領域,就優于所有的傳統方法.之后Tompson[9]使用回歸熱點圖方法來取代直接回歸坐標值,目前大部分網絡都是直接使用均方損失函數回歸熱點圖的方式來進行學習,并未考慮到熱點圖中前景和背景之間像素點不均衡問題,會導致網絡傾向學習背景,影響網絡的性能.
所以本文提出了一個改進的損失函數去解決熱點圖中前景和背景之間樣本不均衡問題,并命名為聚焦均方損失函數,通過對前景賦予高權重,背景賦予低權重,使得網絡學習的重心放在前景部分,減少背景對網絡性能的影響.
本文組織如下:在第1 節簡要介紹人體姿勢估計領域經典網絡.第2 節介紹所提出的聚焦均方損失函數,并于均方損失函數對比,以分析其優點.第3 節為實驗部分,通過實驗驗證我們所提出的聚焦損失函數在公開數據集MPII[10]和MSCOCO[11]上的性能.最后在第4 節我們對全文工作做了總結與展望.
1 相關工作
深度學習出現之前人體姿勢估計的主流模型一直是基于樹形結構的圖模型,通常是基于Felzenszwalb和Huttenlocher 所提出的高效的圖結構方法[12].但是隨著卷積神經網絡和大規模數據集的出現,深度學習方法主要占據主流.DeepPose 首先將卷積神經網絡應用于人體姿勢估計領域,DeepPose 網絡是基于AlexNet[13]結構,直接回歸坐標點.之后Tompson 等提出使用網絡回歸熱點圖的方法來替代直接回歸坐標點值.回歸熱點圖的優勢在于:可以讓網絡全卷積,減少參數量,并捕捉關鍵點之間的相關關系以及前景與背景之間的對比關系.CPM[14]網絡使用級聯網絡去逐級精化網絡的預測效果,同時生成center map 來約束網絡,把響應歸攏到圖像中心.HourglassNet[15]網絡由多個Hourglass Block 串聯而成,每個block 之間加入損失函數,進行中間監督,防止因為網絡過深導致的梯度消失.低分辨率的特征圖擁有較大的感受野,捕捉圖像的全局特征,高分辨率的特征圖擁有較小的感受野,捕捉圖像的局部特征,進行信息交融.微軟提出了基于Hourglass 改進的Pose_Resnet[16],將反卷積層替換原網絡的上采樣層,并剔除shortcut 支路,并只使用一個block 就得到SOTA (State Of The Art)效果.之后微軟又提出了全新的網絡HRNet[17],其主干網絡保持高分辨特征圖不變,此時高分辨特征圖不是從低分辨特征圖上采樣或者反卷積得到的,這樣可以保留更多細節信息,以獲得更豐富的局部特征信息,分支網絡進行降采樣以獲取全局特征,之后再將分支網絡的特征圖上采樣后與主干網絡進行信息交互,因此預測的熱點圖更加準確.OpenPose[18]使用向量(Part Affinity Field,PAF)對關鍵點進行建模,其網絡分成兩支,同時預測熱點圖和PAF,根據回歸得到的PAF 對關鍵點進行聚類.
2 聚焦均方損失函數
目前人體姿勢估計領域的網絡都是通過回歸熱點圖來完成訓練的,將各關鍵點的空間位置標識為前景,其他像素點即為背景.每張熱點圖對應一個關鍵點,數據集圖片中標識多少關鍵點,則網絡需回歸相應的熱點圖數.所回歸的熱點圖中前景部分一般使用高斯函數來計算像素點值,如式(1)所示:

其中,x0,y0是高斯核中心坐標,x,y是當前坐標,δ是高斯核方差,高斯核寬度為 2 δ+1.我們取δ=6,x0,y0設置為熱點圖的中心坐標,生成的熱點圖如圖1所示.

圖1 熱點圖
圖1形象地展示了一個標準的熱點圖,高斯核(中心亮斑部分)只占據熱點圖全部像素的很小一部分.而當前大部分網絡算法都直接使用均方損失函數直接計算預測的特征圖與所標注的熱點圖像素值之間的歐式距離,并沒有考慮到高斯核與背景像素點不均衡問題.假設網絡所回歸的熱點圖大小為64×64 像素大小,高斯核的大小設置為13×13 像素大小,這樣前景與背景的比例為169:3927 (0.00430),故背景占據了熱點圖的絕大部分的像素點,而當前網絡直接使用均方損失函數,計算標注熱點圖與網絡預測熱點圖的歐式距離,使得網絡平等地對待前景與背景,可能導致網絡更加傾向于回歸背景而非前景,降低了網絡的識別率.
而在目標檢測領域同樣存在著類似的不均衡問題.在檢測網絡的起始階段,需要通過SS (Selective Search)或卷積網絡生成一系列的候選框(Proposal),在后續階段根據一些規則,對這些候選框執行保留,合并或拋棄等操作,最后得到網絡的檢測結果.但是所生成的候選框大部分都是被合并或拋棄的,對最終檢測結果沒有貢獻,即是負樣本.例如在Faster-R-CNN[19]網絡的起始階段會生成約2000 個候選框,但是正樣本候選框可能只有幾個,正負樣本比例嚴重失衡.為解決這個問題,有學者在交叉熵損失函數(如式(2)所示)的基礎上,提出了focal loss[20],根據標注標簽對損失函數賦予權重,使得降低了大量簡單負樣本在訓練中的所占比重,數學形式如式(3)所示.

式(3)是focal loss 的數學形式,其中α是平衡因子,以平衡正負樣本不均衡問題,y是標注標簽數據,y′是網絡所預測的數據,γ是調節簡單樣本權重降低的速率,當γ為0 時focal loss 退化為交叉熵損失函數,當γ增加時,調整因子的影響也在增加.
本文亦受目標檢測領域中focal loss 所啟發,在均方損失函數的基礎上進行修改,增加前置權重,根據熱點圖中各像素點值對損失函數賦予不同的權重,使得網絡更傾向于學習高斯核的位置,對于回歸背景位置則施予更大的懲罰.
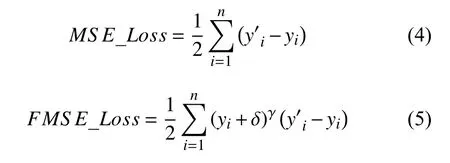
均方損失函數和聚焦均方損失函數的數學形式分別如式(4)和式(5)所示,而各自函數圖像如圖2所示.

圖2 均方損失函數與聚焦均方損失函數圖像
在式(4)中,yi為標注標簽,y′i是網絡所預測的標簽,n是每個mini batch 所含的樣本數.
在式(5)中,我們在均方損失函數的基礎上加入了(yi+δ)γ前置權重,使的它對前景與背景賦予不同的權重.yi為標注標簽,y′i是網絡所預測的標簽,n是每個mini batch 所含的樣本數,δ是極小值,因為背景中像素點yi為0,會導致損失函數為0,使得網絡無法學習,本文中 σ取1e?3.γ是平衡因子,調整標注標簽對損失函數的貢獻大小.當yi處于熱點圖的高斯核中,yi值較大,此時對loss 賦予較高的權重.當yi處于背景位置時,yi值較小,此時對loss 賦予較低的權重.當γ為0 時,則聚焦均方損失函數退化為普通均方損失函數.當γ增加時,像素點yi的值對loss 權重的影響也在增加.
為探究本文所提出的聚焦均方損失函數的γ值對網絡性能的影響影響,我們在MPII 公開數據集上使用HouglassNet 作為實驗網絡,設置不同的聚焦均方損失函數γ值,并固定其他實驗條件,得到最終實驗結果如圖3所示.
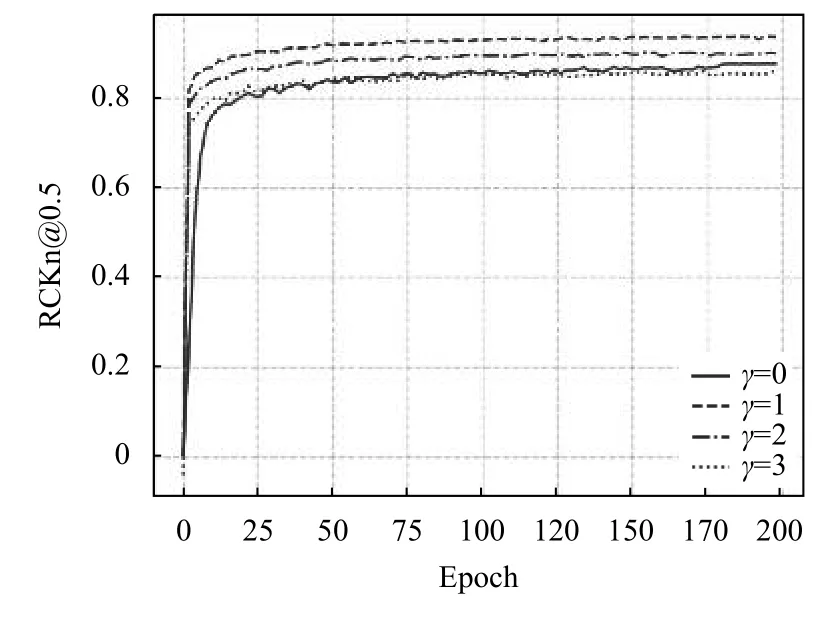
圖3 聚焦均方損失函數的γ 值影響
觀察實驗結果圖3可以得到,當γ=0 時,此時聚焦均方損失函數退化為普通的均方損失函數,在訓練200 輪后,網絡在驗證集上的成績為88.6.而γ=1 時,所提出的損失函數加速了網絡的收斂速度,并比使用均方損失函數的成績提高了4.6 的成績,達到了93.2.當γ值繼續增加,網絡的性能反而下降,這說明背景信息同樣可以幫助網絡定位關鍵點位置,而此時聚焦損失函數把過多的權重分配給前景,背景在損失函數中所占過低,網絡丟失了背景信息,導致關鍵點定位精度,因此一個合適的γ值是非常重要的.
所以在本文的后續實驗部分,我們設置聚集均方損失函數的γ為1.
3 實驗及分析
本節詳細介紹實驗結果以及分析,首先簡單介紹實驗所使用的網絡,之后在介紹實驗配置,展示實驗結果并做出相應的分析.
3.1 實驗所選用的網絡
本文實驗使用沙漏網絡(HourglassNet)和高分辨率網絡(HRNet)作為基準網絡,來測試我們所提出的聚焦均方損失函數的有效性.
沙漏沙漏網絡(HourglassNet)是一種新穎的卷積網絡架構,利用多尺度特征來捕捉人體各個關鍵點的空間位置信息,網絡結構形似沙漏狀,重復使用top-down到bottom-up 來推斷人體的關節點位置.每一個top-down到bottom-up 的結構都是一個stacked hourglass 模塊(Hourglass Block),并在每個Block 之間都加入loss 進行中間監督,以防止網絡過深導致梯度消失.考慮到參數問題,本文中我們使用含有8 個沙漏模塊的沙漏網絡,結構如圖4所示.

圖4 沙漏網絡結構
沙漏網絡主要由卷積層,Batch Normaliztion,上采樣層和skip connection,激活函數選取ReLU.
而在HRNet 網絡的預處理階段對圖像進行提取特征,之后逐步將高到低分辨率子網逐個添加以形成更多的階段,并將多分辨率子網并行連接.網絡進行了反復的多尺度融合,以便每個高到低分辨率表示不斷地從其他并行表示中接收信息,從而獲得豐富的高分辨率表示.網絡的高分辨率特征圖不再是由低分辨率特征圖上采樣或反卷積得到,而是在主干網上保持,這樣可以保留更多的細節信息,網絡所預測的關鍵點熱點圖在空間上的位置更加精確.其網絡結構如圖5所示.

圖5 高分辨率網絡結構
HRNet 結構分為縱向Depth 和橫向Scale 兩個維度,橫向上不同分辨率子網絡并行,縱向上進行多分辨率信息融合,從上到下,每個stages 分辨率減半,通道數加倍.
3.2 MPII 和MSCOCO 數據集
本文實驗中我們選用MPII 和MSCOCO 為實驗數據集,并分別在各自評價指標下(PCKh@0.5 和OKS)報告我們所提出的聚焦損失函數在應用在HourglassNet和HRNet 網絡的性能.
3.3 訓練與測試信息
訓練階段我們使用Faster-R-CNN 作為人體檢測網,并將人體檢測框的高度或者寬度拓展到固定寬高比為4:3,然后從圖片中裁剪人體檢測框,并調整圖片到固定大小256×256 像素大小.對圖片使用數據增強技術,包括隨機旋轉([?30°,30°]),隨機比例大小([0.65,1.35]),和隨機左右翻轉(p=0.5).我們選用Adam 優化算法,在前10 輪訓練中使用較小的學習率(1e?6)對網絡進行預熱,并在10 輪之后學習率設定為1e?3,之后分別在100 輪訓練后下降到1e?5 和在150 輪訓練后下降到1e?6.在200 輪后訓練過程結束.
測試階段我們與訓練階段一致,使用Faster-RCNN 作為人體檢測網,從圖片中裁剪人體檢測框,并調整圖片到固定大小和左右翻轉,輸入到關鍵點檢測網絡中,回歸熱點圖.我們通過平均原始圖片及其翻轉圖片的網絡回歸的熱點圖來作為最終預測的熱點圖.
3.4 實驗環境
硬件信息:4 塊Titan Xp 12 GB 顯卡,CPU:Intel Xeon E5-2620,RAM:128 GB,DISK:4 TB.
軟件信息:操作系統是Linux Ubuntu16.04,cuda 環境是cuda9.0+cudnn7,深度學習框架是Pytorch 1.0.0.
3.5 實驗結果及分析
根據前文設置的實驗環境,訓練與測試信息等,我們在表1報告在MPII 數據集上的聚焦均方損失函數應用于HourglassNet 和HRNet 網絡的實驗成績,并在圖5展示詳細的訓練與測試信息.
從表1可看出,在MPII 數據集上的PCKh@0.5 評價標準下,使用所提出的聚焦均方損失函數的HourglassNet比使用均方損失函數的在難以預測的關鍵點(Wrist 和Ankle)分別提升了1.3 和1.9 的成績,而在易于預測的關鍵點上,我們同樣也提升了網絡的性能,平均成績達到了88.0,高于原有成績87.5.對于HRNet,聚焦均方損失函數表現出相似的結果.這充分說明了我們所提出的聚焦均方損失函數可以有效地幫助網絡去學習那些困難的關鍵點,提升了網絡的性能.

表1 MPII 數據集上實驗結果
通過圖6可以看到,在MPII 數據集上使用聚焦均方損失函數的網絡(HourglassNet 和HRNet)在訓練集和驗證集上的準確率均比使用均方損失函數的網絡的更高,其在訓練集上的準確率提升了1.2%,驗證集上提升了0.9%,而且其loss 的收斂的速度更快,說明了聚焦均方損失函數可以有效地提升網絡的性能.我們又分別在表2和圖4分別報告在MSCOCO 數據集上的實驗成績和詳細信息.
在MSCOCO 數據集上的OKS 評價標準下,我們使用所提出的聚焦均方損失函數的HourglassNet 相比比于直接使用均方損失函數的精準率(AP)和召回率(AR)分別提升了0.021 和0.020 的成績,并可以看出聚焦均方損失函數提升了AP(M)和AR(M)成績,說明網絡有助于學習那些小的人體關鍵點.對于HRNet,聚焦均方損失函數分別提升了0.09 的AP 成績和0.07 的AR 成績.
通過圖7可以得到,在MSCOCO 數據集上使用聚焦均方損失函數的HourglassNet 和HRNet 網絡模型在訓練集和驗證集上的準確率均比均方損失函數的更高,準確率分別提升了2.1%和0.8%,召回率分別提升了3.4%和1.2%,而且其loss 的收斂的速度更快且值更小.使用聚焦均方損失函數的loss 震蕩也比使用均方損失函數要小.本文所提出的聚焦均方損失函數可以有效地提升網絡在MSCOCO 數據集上的預測精度.圖8是關鍵點檢測結果示例.
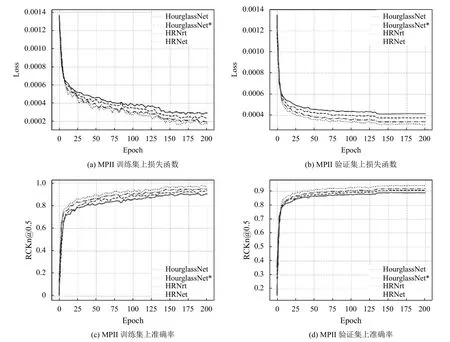
圖6 MSCOCO 數據集上訓練與驗證信息

表2 MSCOCO 數據集上實驗結果


圖7 MSCOCO 數據集上訓練與驗證信息

圖8 關鍵點檢測結果示例
4 總結與展望
文中提出的方法并不像大多數方法那樣對網絡結構進行修改來提升準確率,而是重新設計損失函數來解決熱點圖中前景和背景之間不均衡問題,讓網絡學習的重點放在前景中高斯核部分,減少背景噪聲對網絡性能的干擾.之后將所提出的聚焦損失函數應用在經典網絡(HourglassNet 和HRNet),展示了在公開數據集(MPII 和MSCOCO)下的實驗結果,從各個角度對實驗結果進行了分析,證明了本文提出的聚焦損失函數具有較高的精度和魯棒性.
在未來的研究工作中,我們將會在其他的網絡模型上進行實驗,用于驗證聚焦均方損失函數的實用性和魯棒性.同時,針對如何對網絡結構本身進行設計和改進來提升性能,也需要在未來的科研中更加深入的研究.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
汽車工程師(2021年12期)2022-01-17 02:29:54
今日農業(2021年8期)2021-11-28 05:07:50
當代陜西(2020年14期)2021-01-08 09:30:42
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中國衛生(2014年2期)2014-11-12 13:00:16
