基于單視圖3D重建的快遞紙箱體積測量算法①
2020-11-13 07:12:20馮相如
計算機系統(tǒng)應用 2020年10期
關鍵詞:測量
馮相如,朱 明
(中國科學技術大學 信息科學與技術學院,合肥 230027)
在2015年及其以前,國內的所有快遞的測量幾乎都是由快遞員人工測量完成的[1],耗費了大量的人力和時間,頻繁的手動操作對快遞員是一種極大的負擔,測量精度也很難得到保證,因此導致物流行業(yè)的效率非常低.為了提高物流效率,測量光幕和激光雷達等儀器設備被應用于快遞物流行業(yè)中,劉士興等人[2]利用測量光幕提出了基于線性回歸分析的邊緣擬合底面建模體積測量系統(tǒng),毛丹輝等人[3]詳細介紹了激光技術在體積測量中的應用現(xiàn)狀.但是該方法也存在著一定的不足,測量光幕除了對物品擺放有一定的要求,還對工作環(huán)境有所限制,而激光雷達等設備也比較昂貴,增加了物流行業(yè)的成本.
第一代基于圖像的3D 重建技術主要是基于幾何視角來理解重建3D 到2D 的投影關系,并建立有效地數(shù)學模型來解決這一問題.王玉偉等人[4]利用訓練好的RCF 網絡模型得到圖像中箱體的邊緣二值圖,并通過預處理獲取目標箱體的邊緣與頂點,最后通過雙目立體視覺獲得其體積,宓逸舟[5]同樣用了雙目立體視覺的算法對快遞包裹進行了體積測量.但是這類方法過程比較復雜,需要進行精準的相機標定和多張不同視角的圖像,這會大大限制多種環(huán)境下的應用.由于最近幾年深度學習的快速發(fā)展,基于圖像的深度學習構架出了第二代3D 重建技術,在大量數(shù)據(jù)的支撐下實現(xiàn)單視圖直接重建出物體的三維信息,而不需要復雜的標定和數(shù)學過程.
本文提出的基于第二代3D 重建的快遞紙箱體積測量算法,是讓快遞員用普通手機正對著快遞紙箱拍照并上傳到服務器,通過部署在服務器上體積測量算法計算出快遞紙箱的體積,最終將結果在手機上顯示.相對于前面幾種方法,該方法僅需要拍攝一張照片便可獲得其體積信息,并對工作環(huán)境沒有特殊的要求,成本低,適用性強.
本文第1 節(jié)闡述基于單視圖3D 重建的相關研究,并簡單介紹所設計的體積測量算法;第2 節(jié)詳細介紹整個體積測量算法的各個模塊;第3 節(jié)是實驗結果對比與分析,驗證該算法對快遞紙箱體積測量的有效性;第4 節(jié)對全文總結,并展望下一步工作.
1 概述
1.1 單視圖的3D 重建
3D 重建問題可以歸結為通過n張RGB 圖像預測出單個或多個目標X,并盡可能地縮小預測形狀與真實形狀之間的差異.在過去的數(shù)十年中,計算機視覺和計算機圖形學的專家對3D 重建進行了很多的研究.自2015年首次將卷積神經網絡用于基于圖像的3D 重建[6],并有著十分不錯的表現(xiàn)后,越來越多人專注于使用深度學習技術從單張或多張RGB 圖像來估計通用對象的3D 形狀.本文考慮到實際操作的簡單實用性,所以采用單視圖的3D 重建算法來進行快遞紙箱的體積測量.
3D-VAE-GAN[7]利用變分自編碼器和生成對抗網絡從概率空間生成三維對象,但是由于3D-VAE-GAN需要使用類別標簽進行重建.MarrNet[8]將3D 重建分解為兩個步驟,使用一個編碼器-解碼器網絡架構恢復2.5D 草圖(深度圖和法線貼圖),并借鑒3D-VAE-GAN網絡結構,以一張普通圖像和一張深度圖作為輸入來恢復3D 形狀.Choy 等[9]提出了3D-R2N2 網絡,采用標準的卷積神經網絡結構對原始的2D 圖像進行編碼,再利用一個反卷積網絡對其進行解碼,編碼器與解碼器中間用長短期記憶網絡(LSTM)進行連接,通過Encoder+3D LSTM+Decoder 的網絡結構來建立2D 圖像到3D 體素的映射,該網絡不需要任何的圖像注釋和類別標簽即可訓練測試,但是3D-R2N2 由于循環(huán)神經網絡的長期記憶損失,無法精確恢復物體3D 形狀,并且比較耗時.
黨的十九大勝利召開以來,西南政法大學始終把學習宣傳貫徹習近平新時代中國特色社會主義思想和黨的十九大精神作為首要的政治任務,按照中央、市委、市委教育工委的統(tǒng)一部署,遵循馬克思主義大眾化和大學生思想政治工作規(guī)律,結合學校思想政治工作實際,依托學校馬克思主義傳播人才培養(yǎng)專業(yè)群,探索建立了一支以學生骨干為核心主講團隊的習近平新時代中國特色社會主義思想大學生講習所(以下簡稱“講習所”)。
本文采用基于體素的Pix2Vox3D 重建網絡[10],Pix2Vox 對3D-R2N2 網絡存在的不足進行了改進,在速度和性能上都獲得了一定的提升.它同樣采用編碼器-解碼器的架構,輸入圖像經過VGG16[11]的編碼器生成特征圖,解碼器中將特征圖作為輸入,經過多次反卷積操作生成一個粗糙的3D 模型,通過上下文感知模塊來為物體的每個部分自適應的選擇高質量重建結果,最終經過具有跳躍結構的精煉化模塊生成最終的重建結果.但是對于體積測量來說精確度仍不滿足實際的需求,所以本文通過注意力機制進行信息的融合,并將網絡輸出分辨率提高,提升快遞紙箱重建的精度.
1.2 本文工作
本文提出的快遞紙箱的體積測量算法主要包含3 部分,如圖1所示:圖像預處理,3D 重建和后處理.圖像預處理是通過YOLOv3[12]級聯(lián)GrabCut[13]去除圖像中的背景,提取紙箱與快遞單標簽圖像,并獲得紙箱的實際長度,用于后續(xù)的計算.3D 重建部分是如何在不增加網絡參數(shù)的同時提高重建的精度,從而達到體積測量的需求,本文將網絡的輸出分辨率提高至643,并通過結合注意力機制PSA 模塊[14]降低網絡參數(shù).后處理是為了將網絡重建后模型中的一些重建錯誤的點進行剔除,精細化的重建結果,并集成在3D 重建網絡中.

圖1 算法流程圖
2 算法設計與實現(xiàn)
2.1 圖像預處理模塊
考慮到快遞員的工作環(huán)境,手機攝像頭獲取的圖像往往不能直接使用,如圖2(a).需要通過對圖像進行預處理,將紙箱和快遞單與背景圖像分割,該處理有助于提高三維重建算法的性能.
GrabCut 算法可以將圖像中的紙箱和快遞單標簽與背景分割,該算法利用了圖像的紋理顏色信息和邊界反差信息,通過輸入包含目標物體的矩形框,便可以得到良好的分割結果.由于快遞單標簽較小,考慮檢測的速度與小目標檢測的精確度,本文采用了YOLOv3目標檢測網絡獲取包含紙箱和快遞單標簽的矩形框.YOLOv3 采用了類似FPN 的上采樣和融合做法,相對于YOLOv2/v1 提升了小目標檢測的精確度,同時采用了DarkNet-53 網絡結構,相對于ResNet101/VGG16,速度更快.通過級聯(lián)YOLOv3 與GrabCut 可以快速精準的分割出快遞紙箱與快遞單標簽,快遞紙箱分割結果如圖2(b)所示.
將拍攝圖簡化如圖2(c),將紙箱和快遞單標簽與背景分割后,接著使用圖像處理可以在分割圖像中找到P3、P4、P7、P8 四點的像素坐標.假定P7 與P8 點的像素長度為l1,P3 與P4 點像素長度為l2,因為快遞單標簽的實際尺寸是不變并且是可知的,我們設為P7 與P8 的實際長度為l,那么P3 與P4 點的實際長度L便為:

經過預處理操作后,從原始圖像可以得到快遞紙箱P3、P4 點之間的實際長度以及去除背景干凈的快遞紙箱的圖像.

圖2 圖像處理樣例
2.2 三維重建算法模塊
Pix2Vox 網絡雖然針對3D R2N2 網絡存在的問題做了改進,但是網絡最終輸出的空間分辨率是323,對于精確地恢復快遞紙箱的長寬高的尺寸是不夠的.本文在Pix2Vox 的基礎上,做了如下兩點改進,網絡結構圖見圖3.
(1)重新設計解碼器,提高重建的分辨率.
(2)用PSA 模塊替換網絡中的兩個全連接層,降低網絡的參數(shù).
每一次的3D 反卷積可以將網絡的輸出分辨率提升8 倍,本文通過設計一個具有6 層3D 反卷積的解碼器來將網絡的輸出分辨率從323提升到643,如表1解碼器列所示,輸出分辨率的提升可以更好的恢復重建物體的細節(jié),提升重建性能.由于網絡中存在全連接層,提升分辨率會導致網絡中參數(shù)增加了8 倍,在實際應用中是不可行的.根據(jù)分析可以知道網絡中的全連接層主要作用是融合全局信息,以糾正3D 模型中錯誤恢復的部分,本文使用PSA 模塊替換全連接層,PSA 模塊具有局部和全局信息融合的效果,并且參數(shù)量會大大降低,參數(shù)量對比見后文分析.

圖3 3D 重建網絡結構圖

表1 編碼器-解碼器網絡結構
PSA 包括上下并行的兩個分支,如圖3中虛線部分,在實現(xiàn)上兩個分支是完全一樣的.在每個分支中,首先應用具有1×1 的卷積層減少輸入特征圖X的通道數(shù)以降低計算開銷,得到H×W×C的特征圖Xr.然后再應用一個1×1 的卷積層得到H×W×[(2H–1)×(2W–1)]的Xc,最后經過收集和分散操作獲得兩個具有全局融合信息的特征圖.收集或分散操作如圖4所示,圖4對應圖3中的CollectAttention 和DistributeAttention 具體操作.特征圖Xr上每個位置i,對應特征圖Xc的i位置1×1×[(2H–1)×(2W–1)] 的特征圖,將其轉換成(2H–1)×(2W–1)×1 的特征圖Xi,最后以i作為特征圖Xi中心點,如圖4中以虛線突出顯示的區(qū)域是用于特征的收集和分散,將該區(qū)域與Hr進行矩陣相乘得到具有全局融合信息的特征圖.上下兩層各得到這樣的一個分支特征圖,我們將該兩個分支特征圖進行通道數(shù)疊加并進行1×1 的卷積操作得到具有融合全局信息的特征圖,最后與具有局部信息的特征圖X 進行通道數(shù)疊加,完成全局信息的融合.

圖4 Collect / Distribute Attention
網絡采用的損失函數(shù)是體素交叉熵的平均值,公式如下:
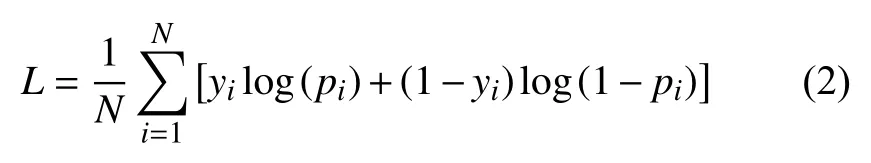
其中,N為標簽的數(shù)量,yi為真實概率,pi為預測概率,pi越接近yi,L值越小.
2.3 后處理模塊
3D 重建網絡輸出的3D 模型是一個三維矩陣,每個位置的值代表了是該點的置信度.Trimesh 是一個專門用來加載和使用三角網格的Python 庫,可以直接得到包圍該重建模型的最小外接立方體的歸一化的長寬高,但是因為在重建結果中會在邊界生成一些錯誤的點,如圖5中紅色圈標注所示,如果用Trimesh 庫來計算會有較大的誤差,所以本文設計了算法1 來剔除這些噪點.

?

4)假定符合x=0,z=0 所有點的集合為S2,假定S2 中點的個數(shù)為N2,在x=0 的yz 這個面上,統(tǒng)計z 從max 到0 每列點的個數(shù),若某列中點的個數(shù)大于 時,則此時z 值為快遞紙箱歸一化后的w.?N2(1?T1+T2)

圖5 三維重建結果圖
通過噪點剔除算法可以得到快遞紙箱精確地歸一化后的長寬高值,由2.1 節(jié)圖像預處理操作可以得到快遞紙箱實際的長度L,假定快遞紙箱實際的寬度為W,實際的高度為H,存在如下的比例關系:

通過式(3)我們可以求出快遞紙箱實際的長寬高,即能算出快遞紙箱的實際體積.
3 實驗分析
3.1 數(shù)據(jù)集
按照文獻[9] 實驗的數(shù)據(jù)集設置,我們也使用了ShapeNet[15]的子集,包含13 個類別,共43 783 個3D模型組成.由于目前的相關的3D 重建的開源數(shù)據(jù)集中沒有快遞紙箱的模型,所以為了驗證本文算法的有效性,我們使用Cinema 4D 軟件制作了與ShapeNet 相同格式的快遞紙箱數(shù)據(jù)集,總共150 個快遞紙箱的3D 模型,3600 張2 維圖片,這里簡稱該數(shù)據(jù)集為box-150.
3.2 評價指標
首先為了評估改進后的3D 重建網絡的性能,使用3D 體素重建與真實體素標簽之間的體素IoU作為相似性度量,其公式如下:

其中,p(i,j,k)和y(i,j,k)分別表示預測概率和真實標簽.I(·)是指示函數(shù),t表示體素化閾值.IoU越高,重建越好.
我們用體積的相對誤差衡量一個快遞紙箱體積測量結果的好壞,具體公式如下:

其中,Vp和Vy分別代表預測體積和真實體積,δ越小表示體積測量的越準確.
3.3 實驗結果
在實際訓練中,由于快遞紙箱數(shù)據(jù)集的限制,本文采用遷移學習的思想,網絡先用ShapeNet 子集進行預訓練150 個周期,接著在box-150 數(shù)據(jù)集上訓練150個周期.網絡采用224×224 RGB 圖像作為輸入,使用Adam 優(yōu)化器,β1為0.9,β2為0.999,預訓練時,批處理大小為64,初始學習率都設置為0.001,在box-150 訓練時,批處理大小為10,初始學習率都設置為0.0005.
本文選擇3 種3D 重建算法作為對比,第1 種是原始的Pix2Vox,第2 種是Pix2Vox 去除網絡中的全連接層,簡稱為Pix2Vox-NF32,第3 種是Pix2Vox 去除網絡中全連接層并將網絡輸出分辨率提高至643,這里簡稱為Pix2Vox-NF64.表2為4 個網絡在不同閾值下重建性能的對比,以IoU作為評價標準,實驗數(shù)據(jù)表明,直接去除全連接層會降低網絡的性能,但去除全連接層后提高網絡的輸出分辨率能夠提升網絡的模型,當同時采用提高分辨率與PSA,模型更優(yōu).圖6為4 種模型的參數(shù)量比較,通過比較可以發(fā)現(xiàn)我們的網絡比Pix2Vox 參數(shù)量更低.

表2 不同閾值下模型性能對比
體積測量的誤差主要來自兩個部分,第1 個是在圖像預處理階段,獲取快遞紙箱的長度時會存在誤差;第2 個誤差是3D 重建得到的歸一化長寬高的值,這一誤差可以歸結為后處理階段.我們對box-150 中25 組數(shù)據(jù)進行了第一個誤差的統(tǒng)計分析,具體如圖7所示,根據(jù)預處理獲取快遞紙箱的長度的誤差平均僅為0.6%,80%的數(shù)據(jù)的相對誤差都小于1%,證明了圖像預處理模塊對于計算快遞紙箱長度的有效性.第2 個誤差可以通過統(tǒng)計快遞紙箱的體積相對誤差來分析,并與用trimesh 庫來計算體積進行對比,通過圖8可以看出由后處理得出的平均體積相對誤差比用trimesh 庫的低了很多,證明了后處理模塊的有效性.

圖6 不同模型的參數(shù)量對比

圖7 25 組快遞紙箱長度相對誤差分析

圖8 基于trimesh 庫與后處理程序的體積誤差對比圖
考慮算法的實用性,本文還測試了6 組真實數(shù)據(jù),具體的誤差分析見表3,可以看出相對誤差基本在5%以內,滿足實際的需求.但相較于box-150 數(shù)據(jù)集效果差了一點,這是因為真實數(shù)據(jù)與模型訓練使用的數(shù)據(jù)還是存在著一些差異.

表3 手機拍照快遞紙箱體積測量誤差分析
4 總結展望
本文基于3D 重建網絡,設計了一個通過手機對快遞紙箱拍照就能獲得其體積的算法,通過實驗證明了圖像預處理模塊計算快遞紙箱長度的有效性以及提高網絡的重建分辨率并結合PSA 模塊有助于提高快遞紙箱的重建性能,此外后處理模塊能更精確的計算快遞紙箱的體積.最后考慮算法的實用性,本文還對真實數(shù)據(jù)做了測試.
下一步的研究工作在于如何讓該算法對拍攝快遞紙箱的角度更加魯棒性,保證在實際操作中更方便快捷地得到快遞紙箱的體積數(shù)據(jù).
猜你喜歡
小學科學(學生版)(2021年5期)2021-07-22 02:40:06
中學生數(shù)理化·八年級物理人教版(2019年9期)2019-11-25 07:33:02
中學生數(shù)理化·八年級物理人教版(2019年3期)2019-04-25 06:20:54
中學生數(shù)理化·八年級物理人教版(2018年3期)2018-05-31 08:52:45
數(shù)學小靈通(1-2年級)(2017年10期)2017-11-08 08:39:45
軍事文摘·科學少年(2017年4期)2017-06-20 23:25:16
軍事文摘·科學少年(2017年2期)2017-04-26 21:58:43
中學生數(shù)理化·八年級物理人教版(2016年3期)2016-04-07 04:49:32
少兒科學周刊·兒童版(2016年1期)2016-03-14 03:52:21
閱讀與作文(小學低年級版)(2015年4期)2015-04-29 00:00:00
