基于BLSTM-Attention神經網絡模型的化工事故分類①
2020-11-13 07:12:22鄭利杰杜軍威
計算機系統應用 2020年10期
葛 艷,鄭利杰,杜軍威,陳 卓
(青島科技大學 信息科學技術學院,青島 266061)
隨著化工領域的迅速發展,由于化工生產品中易燃易爆、有腐蝕性、有毒的物質比較多,化工事故也在頻頻發生[1].因此,有必要對發生的化工事故進行分析,知道是哪些行為、哪些物品或者哪些事件造成了化工事故的發生.這對化工事故的監管,預警以及處理等方面有著重要意義.
文本自動分類是信息處理的重要研究方向[2].目前分類方法有很多,常用的有樸素貝葉斯Naive-Bayes、卷積神經網絡CNN、循環神經網絡RNN 等分類方法.
羅慧欽針對樸素貝葉斯模型屬性間條件獨立假設不完全符合實際的問題,提出只考慮屬性間的依賴關系的基于隱樸素貝葉斯模型的商品情感分類方法[3].但樸素貝葉斯模型無法根據文本上下文的語義信息做出有效的特征提取.
CNN 在很多自然語言處理任務中得到較好的結果.Kim Y 等人用CNN 完成文本分類任務,具有很少的超參數調整和靜態向量,在多個基準測試中獲得較好的結果[4].Zhang X 等人使用字符級卷積網絡(ConvNets)進行文本分類,并取得了較好的結果[5].但由于CNN模型需要固定卷積核窗口的大小,導致其無法建立更長的序列信息[6].
Auli 等人提出了基于循環神經網絡的聯合語言和翻譯模型[7].邵良杉等人基于LSTM改進的RNN 模型實現互聯網中在線評論文本的情感傾向分類任務.RNN 能夠解決人工神經網絡無法解決的文本序列前后關聯問題,但無法解決長時依賴問題[8],并且存在梯度消失問題,對上下文的處理受到限制[9].
長短期記憶網絡(Long Short-Term Memory,LSTM)[10]是一種時間遞歸神經網絡[3],也是一種特定形式的RNN (Recurrent Neural Network,循環神經網絡).可以解決RNN 無法處理的長距離依賴問題,但容易造成前面的信息缺失以及不同時刻信息的重要度得不到體現[11].萬勝賢等人提出局部雙向LSTM 模型,對高效的提取一些局部文本特征有重要意義[12].LSTM 和雙向LSTM是典型的序列模型,能夠學習詞語之間的依賴信息但不能區分不同詞語對文本分類任務的貢獻程度[13],有效的表達文本語義特征[14].
Attention 機制[15]的一大優點就是方便分析每個輸入對結果的影響,可以自動關注對分類具有決定性影響的詞,捕獲句子中最重要的語義信息,而無需使用額外的知識和NLP 系統[16].另外,Attention 機制[15]在關系抽取任務上也有相關的應用[17].
針對以上分析,本文提出一種基于Attention 機制的BLSTM (BLSTM-Attention)神經網絡模型對化工新聞文本進行特征提取,實現事故文本分類.模型的BLSTM 層實現對文本上下文語義信息的高級特征提取;在BLSTM 層后引用Attention 機制實現對不同詞和句子分配不同權重,合并成更高級的特征向量.
化工事故新聞數據包含新聞內容,標題信息以及新聞來源等多個方面的信息,其中,新聞內容的文本對上下文具有較強的依賴性.另外,事故新聞數據集有其獨有的一些特征,有些分類算法在化工領域數據集上并不完全適用.本文選取清洗完成的化工事故新聞標題、內容作為分類的依據,新聞來源作為新聞的可靠性分析依據.將本文的模型分類方法與Naive-Bayes、CNN、RNN、BLSTM 方法在相同的化工事故新聞數據集上進行實驗對比.實驗結果表明,本文提出的BLSTM-Attention 神經網絡模型在化工事故新聞數據集上的效果要更優于其他方法模型.
1 BLSTM-Attention 神經網絡模型
本文將Attention 機制與雙向LSTM 神經網絡相結合,構成BLSTM-Attention 模型,該模型由4 個部分組成:(1)輸入層:輸入訓練好的詞向量;(2)BLSTM 層:根據輸入層的信息獲取高級特征;(3)Attention 層:產生權重向量,并通過乘以權重向量,將每個時間步長的詞級特征合并為句子級特征向量;(4)輸出層:根據從Attention 層獲得的輸出信息完成分類任務并輸出結果.模型結構如圖1所示.

圖1 BLSTM-Attention 神經網絡模型
1.1 輸入層
給定一個由t個句子組成的訓練文本d,即d={S1,S2,···,St},每個句子S又由n個詞語組成,則Si={w1,w2,···,wt}.本文利用Word2Vec 對數據進行向量化,得到向量化表示的詞語xt作為BLSTM 層的輸入,稱為詞向量w∈?d,通過輸入層實現文本向量化.
1.2 BLSTM 層
LSTM 網絡信息的更新和保留是由輸入門、遺忘門、輸出門和一個cell 單元來實現的.長短時記憶網絡的基本思想是在原始的RNN 隱藏層只有一個對短期輸入非常敏感的狀態,即隱藏層h基礎上再增加一個狀態單元c(cell state)來保存長期狀態.
輸入門(input gate)決定了當前時刻網絡的輸入xt有多少保存到單元狀態ct,可以避免當前無關緊要的內容進入記憶.表示為:

其中,Wxi,Whi,Wci表示輸入門it所對應的權重矩陣;xt表示輸入的詞向量;ht?1表示LSTM 層上一時刻的輸出結果;ct?1表示上一時刻的狀態;bi表示一個常數向量.
遺忘門(forget gate)決定了上一時刻的單元狀態ct?1有多少保留到當前時刻ct,可以保存很久很久之前的信息.表示為:

其中,Wxf,Whf,Wcf表示遺忘門ft所對應的權重矩陣;bf表示一個常數向量.
輸出門(output gate)控制單元狀態ct有多少輸出到 LSTM 的當前輸出值ht,可以控制長期記憶對當前輸出的影響.表示為:

其中,Wxo,Who,Wco表示遺忘門ot所對應的權重矩陣;bo表示一個常數向量.
當前時刻狀態單元的狀態值由ct來表示:

其中,cm表示候選狀態單元值,公式表示為:

其中,Wxc,Whc,Wcc表示選狀態單元值cm所對應的權重矩陣.

本文采用的BLSTM 神經網絡包含了兩個隱藏層,這兩個隱藏層之間的鏈接是以相反的時間順序流動的,所以它是分別按前向與后向傳遞的.自前向后循環神經網絡層的公式表示為:

自后向前循環神經網絡層的公式表示為:

BLSTM 層疊加后輸入隱藏層公式表示為:
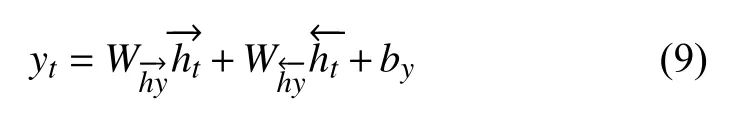
1.3 Attention 層
考慮到不同詞對文本的貢獻不大相同,本文采用能夠通過分配不同的注意力來獲得較高的權重的Attention 機制來對重要詞語和句子進行特征提取.Attention 機制結合BLSTM 模型將利用每個時刻下狀態和最終狀態,計算得到每個時刻狀態的注意力概率分配,以此來對最終狀態進行更進一步的優化,得到最終的文本特征,并將Attention 機制接入全連接進行分類.首先對BLSTM 層的輸出信息yt通過非線性變換得到隱含表示uit;然后,經過隨機初始化注意力機制矩陣uw與uit進行點乘運算得到Attention 層的詞級別權重系數 αit,并最終得到句子特征向量sit,表示為:

其中,Ww為權重矩陣,bw為偏置量.
同樣,采用與詞級別相同的方式對文章貢獻不同的句子賦予不同的權重參數,通過句子級的Attention機制得到文章的特征向量.具體表示為:

1.4 輸出層
本文采用計算簡單,效果顯著的Softmax 分類器對經過Attention 機制得到的文章特征向量vt進行歸一化得到預測分類.表示為:

另外,本文采用正則化的方法來提高模型的泛化能力,防止出現過擬合的情況.目標函數用帶有L2 正則化的類別標簽y的負對數似然函數,表示為:

其中,ti是獨熱編碼(one-hot represented)表示的基礎值;yi∈?m是每個類的估計概率,m是類別的個數;λ是L2正則化超參數.
2 實驗
2.1 實驗數據
本文采用Python 程序爬取各大網站得到的4 萬多條事故新聞作為語料庫.語料庫中包括事故標題、事故內容以及新聞來源等信息,本文選取事故標題、事故內容作為事故類型分類的依據.由于網站信息雜亂,新聞的重復報道以及與化工事故相關性不大等原因使得評論中存在較多的噪聲數據,為保證實驗質量對數據進行了清洗.通過相似度計算,打標簽等方法對數據進行預處理,清洗去掉重復以及非化工事故新聞3 萬4 千多條噪聲數據,選取10 314 條數據進行實驗.數據統計如圖2所示.
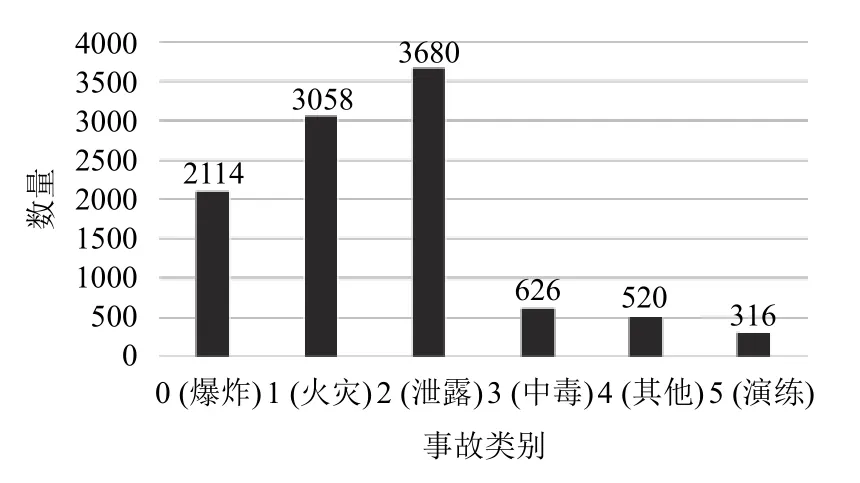
圖2 數據統計
圖2橫坐標表示事故類別,縱坐標表示每一類別的個數.化工事故的類別基本分為5 大類:爆炸,火災,泄露,中毒以及其他.根據化工領域常舉行化工事故演練來加強官兵快速反應能力和實戰能力,新增了演練這一類別,能夠訓練模型將事故與演練區分開,防止因為事故演練而做出錯誤事故的分析.這樣大大提升了我們對事故分析的準確性和有效性,同時也提高了分類的準確性.表1對數據做了進一步說明.
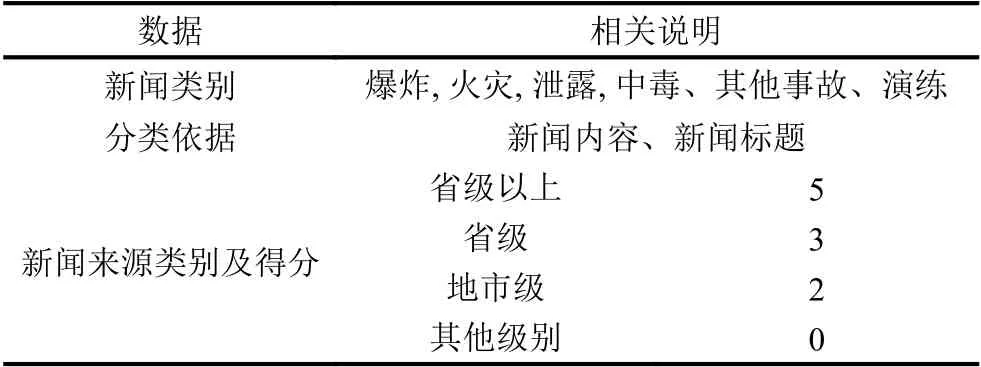
表1 數據說明
本文將新聞標題以及新聞內容作為模型的輸入,考慮到標題所包含的信息量比較少,將獲得的分類結果按照2:8 的比重進行計算作為分類的最終結果.另外,由于新聞來源雜亂繁多,通過打標簽的方式將其分為4 類:省級以上、省級、地市級以及其他類別,并對其進行打分.新聞來源的可靠性通過其得分來判斷,化工事故新聞數據文本的得分情況如圖3所示.

圖3 新聞數據得分
圖3的橫坐標表示新聞的得分,縱坐標表示獲得相應分數的新聞個數.從圖3看出,新聞得分為0 的新聞數并不是很多,大多數的新聞都有可靠的來源,具有較強的可靠性.
2.2 參數設置
本文采用Adam 優化方法,其學習率設為0.001;經過多次實驗后選取結果最優參數設置:迭代次數設為20;詞嵌入維度設為200;神經元個數為[256,128].為了防止過擬合現象,目標函數加入L2 正則化項,正則化的因子取值設為10–5;另外,還加入dropout 策略,并把它應用在輸入層和BLSTM 層,經過多輪試驗,當dropout rate 為0.5 的時候,模型能夠達到比較好的性能.根據實驗過程中的最佳實驗效果選取各個模型的參數,具體參數設置如表2所示.
本文采用jieba 分詞工具對數據做分詞處理,Word2Vec 訓練數據產生所需要的詞向量.網絡模型設置好之后,不需要借助GPU 在自己的電腦上就能夠實現,實現成本低,運算復雜度并不高.另外,本文采用準確率和F1 值來評估模型效果.

表2 模型參數設置
2.3 實驗結果
圖4、圖5分別表示BLSTM 和BLSTM-Attention神經網絡模型在模型訓練時損失值隨迭代次數的變化圖.

圖4 BLSTM 模型訓練損失變化圖(10314)
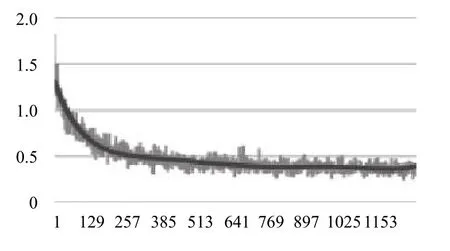
圖5 BLSTM-Attention 模型訓練損失變化圖(10314)
從圖4和圖5中可以看出函數損失值是逐漸下降的,并且最終趨于穩定收斂狀態.BLSTM-Attention 模型與BLSTM 模型相比,起始的損失值相差不大,但收斂速度明顯增加,也更加穩定,并且最終收斂的損失值較小.
為了驗證BLSTM-Attention 神經網絡模型的有效性,與Naive-Bayes、CNN、RNN 以及BLSTM 方法模型在相同的數據集上做對比實驗,實驗結果如表3所示.
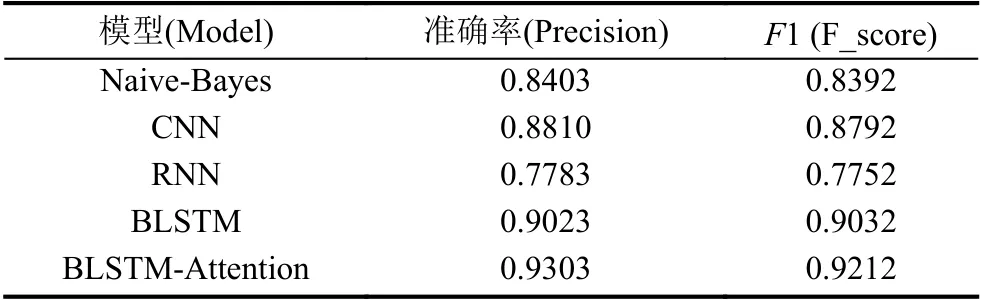
表3 不同分類模型的平均分類結果比較
2.4 實驗分析
從表3的各個模型的對比實驗結果能夠看出,在相同的數據集上,除了RNN 的實驗效果較差,以Word2Vec 訓練的詞向量作為文本特征的其他分類實驗結果的效果都不錯.能夠說明Word2Vec 訓練的詞向量可以很好地描述文本特征.
BLSTM 神經網絡模型相較于其他分類模型的分類效果更好,這也說明BLSTM 模型在學習詞語之間的依賴信息和反映文本上下文語義信息上有著重要作用.
BLSTM-Attention 模型與BLSTM 模型相比,實驗結果表明Attention 機制對不同詞語和句子所分配的權重對文本的特征提取有一定的意義,提升了文本分類的準確度.
3 結束語
為了解決化工新聞文本的語義特征提取及對上下文的依賴問題,本文提出一種應用于化工事故領域的基于雙向LSTM-Attention 機制的神經網絡模型.BLSTM-Attention 模型能夠實現對詞語之間以及句子之間的特征學習和提取,并且通過Attention 機制對不同的詞語和句子分配不同的權重.
本文采用Word2Vec 對清洗好的數據訓練得到詞向量;將BLSTM-Attention 神經網絡模型與 Naive-Bayes、CNN、RNN 以及不加Attention 機制的BLSTM方法模型在相同的化工數據集上做對比實驗.實驗結果表明,Word2Vec 訓練的詞向量可以很好地描述文本特征.另外,相較于Naive-Bayes、CNN、RNN 以及不加Attention 機制的BLSTM 方法模型,BLSTMAttention 模型能夠實現對詞語之間以及句子之間的特征學習和提取,并且通過Attention 機制對不同的詞語和句子給予不同的關注度,對提高分類性能有一定作用.本文提出的BLSTM-Attention 模型能夠更有效地提取出文本特征,對于文本分類效果有一定的提升.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
