NVIDIA GeForce RTX 3080全球首發評測
2020-11-16 07:13:41《微型計算機》評測室
微型計算機 2020年19期
《微型計算機》評測室

RTX 30系列產品綜合概述
RTX30系列首發產品有三款,也就是前文介紹的GeForceRTX3090、GeForceRTX3080和GeForceRTX3070。其中最先上市的是RTX3080,國內上市時間為9月17日,價格為5499元起。隨后是RTX3090,上市時間為9月24日,國內定價11999元起。最晚上市的是RTX3070,上市時間是10月15日,國內定價僅為3899元起。從參數對比來看,RTX30系列最顯著的變化便是換用了三星的8nm工藝,同時CUDA核心的數量大幅度增長,單精度計算性能、張量核心性能暴增。另外,RTX30系列的功耗也顯著增加,頂級的RTX3090和高端的RTX3080在TDP功耗上均突破了300W,難怪NVIDIA建議玩家為RTX3090、RTX3080配備750W以上的電源。
RTX30系列在工藝上采用的是三星的8nm工藝。和之前NVIDIA在頂級產品上偏愛臺積電的工藝不同的是,Ampere顯卡所使用的制程工藝的確有點出乎大眾預料。三星8nm工藝在實際的工藝代次上是屬于10nm工藝的改進版本,屬于典型的半代工藝。其存在兩個版本,分別是8nmLPP和8nmLPU。但是三星沒有給出更多有關8nmLPU的數據,可能和三星之前宣布的高密度庫有關。NVIDIA本次RTX30系列顯卡,有可能選擇的是三星8nm工藝的LPU版本,但是目前沒有更多消息可供證明。
在采用了三星8nm工藝后,相比上代同為面向圖形的TU102核心,GA102核心的晶體管數量增加了大約50%,但是整體芯片面積卻降低了17%。RTX30系列GPU所使用的8nm工藝的晶體管密度為4458萬/mm2,之前RTX20系列使用12nmFFN工藝的晶體管密度為2467萬/mm2,新工藝的晶體管密度是之前工藝的1.8倍。
性能飛躍式增長,RTX30系列GPU架構解讀
RTX30系列GPU在架構上最大的變化是改用了全新的安培(Ampere)架構。有關安培架構的內容,本刊在之前的《來自540億晶體管的力量—全新NVIDIA安培架構和A100GPU深入解讀》一文中已經做出了比較詳細的解讀。不過,之前NVIDIA在發布A100GPU的時候,無論是GPU本身還是架構設計都更偏向于計算,在面向圖形應用時,偏向計算的架構顯然是無法適應圖形計算的需求的,因此NVIDIA在同為安培架構、面向不同計算場合的芯片設計上,采用了針對性的改進。可以這樣理解,目前我們看到的RTX30系列顯卡,采用的是面向圖形的安培架構,它和面向計算的安培架構有一定的相似之處,但是側重點完全不同。
GA102和GA104的宏觀架構
NVIDIA給出了完整版本GA102芯片的信息。根據這些內容顯示,GA102芯片前端設計PCIe4.0總線控制器和常見的極線程分發器(GigaThreadEngine),數據通過這兩個端口進入GPC中。GA102內部一共包含了7個GPC,每個GPC內部包含6個TPC,一共擁有42個TPC。每個TPC包含2個SM模塊和一個PolyMorphEngine(幾何處理引擎,用于曲面細分計算),也就是84個SM模塊和42個PolyMorphEngine。在安培架構上,NVIDIA定義一個SM模塊內擁有等效128個CUDA核心或者流處理器,那么完整版本的GA102就包含了等效10752個CUDA核心。顯存控制器方面,GA102擁有12組顯存控制器,每組32bit,組成了384bit的規格,后端還包括用于全局連接的高速Hub和4通道NVLink總線。
值得注意的是,GA102內部還有168個FP64單元(每個SM內有2個),但是在宏觀架構圖中并未顯示。FP64的計算性能是FP32單元的1/64。在這里加入少量FP64單元的目的主要是考慮到部分程序中有少量FP64計算任務,以及張量核心也有部分FP64數據需要計算。當然,相比A100GPU中龐大的FP64規模,這里的FP64單元僅僅是為滿足基本計算需求而設定。
繼續向下深入探討的話,安培核心的SM,除了包含等效128個CUDA核心外,還包含4個第三代Tensor Core張量核心、256KB的寄存器、4個紋理單元、1個第二代光線追蹤核心以及128KB的L1/共享緩存。另外核心內部還為每個顯存控制器配備了512KB的L2緩存,總計6144KB。
再來看GA10 4。RT X 3070使用的芯片代號是GA10 4-300- A1,按照慣例,NVIDIA會使用GXXX- 400作為比較接近完整版芯片的產品代號。根據NVIDIA數據,GA104的完整版本有6個GPC、24個TCP和48個SM,等效6144個CUDA核心。GA104-300-A1則屏蔽了1個TPC,最終只包含了6個GPC、23個TCP和46個SM,以及等效5888個CUDA核心,所以RTX 3070SUPER或RTX 3070 Ti理論上應該是有空間的。
總的來說,從宏觀架構來看,安培架構和之前的圖靈架構存在非常相似的地方,這也是NVIDIA使用多年的、GPC-TPC- SMCUDA核心四級層級的繼承和發展。今天我們看到的面向圖形的安培架構和面向計算的安培架構其差別之大甚至接近兩代GPU的架構差異,雖然部分技術可能來源相同,但由于最終目標不同,因此兩者的差異鮮明。
SM模塊解析
SM(Streaming Multi- processer,流式多處理器模塊)模塊一直是NVIDIA GPU的計算核心。在之前面向計算的A100上,SM模塊的基本配置情況是1個完整的SM模塊包含了64個INT 32單元、64個FP32單元(也就是CUDA核心)以及32個FP64單元、4個第三代張量核心,分別針對傳統的數據處理、雙精度計算和AI計算三種任務。不過,在新的GA10X核心的安培架構上,由于計算任務的變化,和A100的SM模塊相比,GA10X的SM模塊也有了巨大的變化。
NVIDIA從RTX 20系列開始,就將圖形計算部分劃分為三個類型,那就是傳統圖形數據計算、光線追蹤計算和AI計算。在圖靈架構上,這三個部分使用的分別是圖靈架構SM、第一代RTCore以及第二代Tensor Core,后兩者都是NVIDIA的獨家方案。在新的面向圖形計算的安培架構中,這三個計算任務依舊被完整地保留了下來,并共同組成了全新的安培SM模塊。
面向圖形的安培SM模塊的基本配置和之前的圖靈架構在宏觀結構上是基本相同的。整個SM中都包含了4個計算單元,128KB的L1緩存和共享內存以及4個紋理單元、RT核心等。其主要變化發生在計算單元內部。
在之前的圖靈SM模塊的單個計算單元配置上(4個SM計算單元組成一個SM模塊),每個SM模塊中的計算單元擁有1個warp調度單元和1個派遣單元,16384×32bit寄存器、16個FP32內核和16個INT32內核,2個張量核心以及后端的LD/ST單元、特殊功能單元(Special Function Unit,簡稱SFU)等。
在新的GA10X安培SM的計算單元內部,依舊配置了1個warp調度單元和1個派遣單元、16384×32bit寄存器和后端LD/ST、SFU單元,但是在計算的部分卻包含了1組16個可自由執行FP32和INT32計算的雙功能計算單元(ALU)—它們既可以完成FP32計算,又可以完成INT32計算,另外還包含了1組16個FP32計算單元和1個新的第三代張量核心。
由于SM設計的變化,因此安培架構相比圖靈架構顯示出巨大的功能性和性能導向差異。最典型的就是CUDA核心的數量方面,NVIDIA一直以來都將1個FP32單元作為1個CUDA核心來計數和宣傳,但是在本次使用了INT32和FP32雙功能設計、并額外增加了FP32單元后,可宣傳的CUDA核心數量就大大增加了。比如同為4個SM計算單元組成的SM模塊,GA10X安培架構擁有等效128個CUDA核心、面向計算的A1xx安培架構擁有64個CUDA核心,圖靈架構也擁有64個CUDA核心,這也是NVIDIA宣傳GA10X安培架構SM模塊2倍于圖靈架構的數字計量來源。
但是,這并不意味著安培架構在FP32計算性能上隨時都能保證達到圖靈架構的2倍,畢竟安培架構的每個SM模塊中只有64個“純粹”的FP32單元,其余64個是雙功能單元。這意味著當計算任務的數據格式以混合INT和FP格式占據這些單元時,安培架構的SM模塊每周期所呈現的FP計算能力就會根據計算任務而變化,最極端情況下會降低至和圖靈架構相同(假設INT32占據了所有64個雙功能單元),或者呈現圖靈架構的2倍(全部都是FP32計算)。
考慮到目前復雜的圖形計算任務,采用FP32+INT32混組核心的設計的優勢是能夠帶來每晶體管性能的顯著提升。畢竟計算任務并不會老老實實地按照設計規范出現。舉例來說,一個計算任務中包含了20個INT計算和80個FP計算時,在圖靈架構下,20個INT計算任務在1個時鐘周期內就可以完成,但是80個FP計算就需要2個時鐘周期才能完成。其中部分INT32核心在此時就會被閑置,每晶體管性能就會降低。換到安培架構,20個INT計算任務會分配20個雙功能核心的INT32功能完成(剩余48個雙功能核心),其余80個計算任務中的64個可以交給固定FP32核心,另外16個可以交給雙功能核心的FP32功能完成。那么,1個時鐘周期就可以完成所有的計算任務,效率自然能得到大幅度提升。
總的來看,在計算任務全部都是FP32的情況下,新的安培架構的1個SM可以視同擁有128個FP32計算單元、4個第三代張量核心和1個RT核心。因此,NVIDIA特別提到,現代游戲工作負載具有廣泛的處理需求,許多工作負載混合使用FP32算術指令(例如FFMA、浮點加法FADD、浮點乘法FMUL等),以及許多更簡單的整數指令,例如用于尋址和獲取數據算法,或者用于處理結果等。因此,在圖靈架構上,NVIDIA增加了新的計算路徑后,大幅度提升了這類算法的自由度和工作效能,從而帶來了不錯的性能優勢。在安培架構上,這樣的設計被強化了,浮點計算可以根據需求選擇任何一組計算單元(計算路徑),根據Shader指令和應用程序設計的不同,性能將有所變化,具體取決于指令的應用方式。比如光線追蹤降噪計算全部都是FP指令,能夠充分利用新的雙功能計算單元和傳統的FP32單元,顯著提升性能。
此外,在L1緩存部分,安培架構的SM L1共享緩存應用下的帶寬相比圖靈架構翻倍,安培架構的SM共享緩存帶寬為每時鐘周期128bytes,而圖靈架構為每時鐘周期64bytes。這樣一來,RTX 3080的總L1帶寬為219GB/s,RTX 2080 SUPER僅有116GB/s。
在緩存方面,安培架構的SM緩存容量從之前的96KB提升到了128KB,容量增大了33%,這有助于存放更多的數據在L1緩存中,減少數據不斷地從外部存儲調用的頻率,能提高性能并降低功耗。完整的GA102包含10752KB的L1緩存,對比TU102為6912KB。此外,NVIDIA還給出了L1和共享緩存的容量配置表,L1和共享緩存的可配置方案如下:
128KB L1 + 0 KB共享內存
120KB L1 + 8 KB共享內存
112KB L1 + 16 KB共享內存
96KB L1 + 32 KB共享內存
64KB L1 + 64 KB共享內存
28KB L1 + 100 KB共享內存
NVIDIA特別提到,對于圖形工作負載和異步計算,GA102將分配6 4KB L1數據紋理緩存(相比之下圖靈架構僅能分配32KB)、48KB共享內存和16 KB保留用于各種圖形管線操作。
光線追蹤模塊
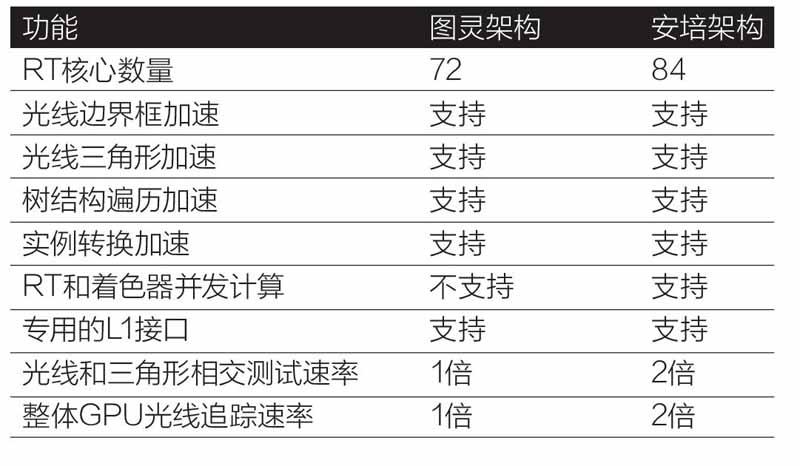
在之前的圖靈架構上,NVIDIA引入了光線追蹤模塊(下簡稱為“RT模塊”)。RT模塊的主要作用是針對光線追蹤計算中最耗費時間的加速邊界體積層次(BVH)遍歷和光線/三角形(基元)交叉測試(光線投射)過程進行加速,將整個光線追蹤計算的時間降低至可接受的范圍內。
有關光線追蹤計算的基本情況,我們在2018年的《生而為光—NVIDIA“圖靈”架構解析》一文中有非常詳細的介紹,因此本文僅作簡單回顧性介紹,有需要的讀者可以翻看之前的內容。
光線追蹤計算的過程,是通過圖像平面中的每個像素從相機(觀察者的眼睛)射出一條或者多條光線,然后測試光線是否和場景中的任何基元相交。由于光線和基元在場景中的碰撞檢測非常重要,因此一種流行的算法就是使用基于樹的加速結構,其中包含了多個分層排列的邊界框,邊界框包圍或者圍繞著不同數量的場景幾何體,大的邊界框可能包含了較小的邊界框,較小的邊界框內再包含實際的場景物體。這種分層排列的邊界框被稱為邊界體積層次結構,或者BVH。BVH通常被列成具有多個級別的樹形結構,每個級別都有一個或者多個節點,從頂層的單根節點開始,向下流入不同級別的多個后代節點。
光線追蹤計算更適合多指令多數據流形式的計算,因此需要專門的MIMD執行單元。此外,在硬件計算上最好也能夠為其進行優化。在這種情況下,NVIDIA設計了專門的BVH遍歷計算器以及三角形交叉測試單元,能夠以極高的效率完成整個場景的光線追蹤計算,這就是圖靈核心上開始出現的RT模塊中包含的RTCore。而在新的安培架構上,NVIDIA又對RT模塊的性能進行了增強。面向圖形的安培架構GPU加入了新的增強異步計算效能的功能,該功能允許在每個安培架構GPU的SM中同時處理光線追蹤計算和圖形計算,或光線追蹤計算和數學計算工作負載。在這種情況下,安培架構的SM可以同時處理兩個計算工作負載,并且不限于像以前的GPU那樣只能同時進行數學計算和圖形處理(光線追蹤計算需要等待),從而使基于計算的降噪算法等方案可以與光線追蹤計算可以同時運行,極大地提高了代碼執行效能。
除了上述性能提升外,NVIDIA在安培架構的光線追蹤模塊中還帶來了比較重要的技術創新,那就是光線追蹤動態模糊加速。動態模糊是一種非常流行且重要的計算機圖形效果,可用于電影、游戲和許多不同類型的專業渲染應用程序中。動態模糊的本質和膠片攝影相關,因為膠片攝影時,圖像不是立即創建的,而是通過將膠片在有限的時間段內曝光來創建的。這意味著目標物體在膠片快門時間內的高速移動將帶來模糊的曝光效果。對GPU來說,要創建類似效果,必須模擬相機和膠片工作流程。動態模糊對于電影是非常重要的,它能夠避免畫面出現斷續卡頓的效果,對游戲來說亦是如此。
現代GPU動態模糊實現上有多種手段,這些技術既可以用于電影中的離線高質量渲染,也可以用于游戲等實時應用。高質量的模糊效果通常需要在某個時間間隔內渲染和混合多個幀,還需要后處理進一步改善結果,因此對算力要求極高。人們需要使用更為真實的模擬來實現動態模糊,比如光線追蹤。在使用了光線追蹤之后,動態模糊可以看起來更準確和逼真,而不會出現不需要的偽影,但是在GPU上渲染也可能需要很長時間,因此需要硬件加速來快速實現這個結果。
目前有多種算法可以結合光線追蹤實現動態模糊。一種流行的算法是將許多帶有時間戳的光線隨機發射到場景中。具有動態模糊功能的BVH會針對在一段時間內移動的幾何圖形返回光線的命中信息,該幾何圖形的采樣點是光線相關的時間函數。然后將這些樣本著色并合并以創建最終的模糊效果。NVIDIA自2017年推出OptiX 5.0以來,就已經能夠支持這項技術。
在動態模糊計算方面,之前的圖靈架構可以很好地加速運動相機類型的運動模糊,它能夠在一定時間間隔內將多束光線射入場景,光線追蹤核心可以加速BVH遍歷,執行光線和三角形相交測試并返回結果以創建模糊效果。但是,圖靈架構在遇到BVH信息隨對象移動而變化的情況下,就很難在給定的時間間隔內對移動的幾何體執行運動模糊計算了。現在,新的安培架構的光線追蹤核心通過加入新的加速功能,和經過修改的BVH配合使用,可以顯著加速運動的幾何形狀的動態模糊計算。
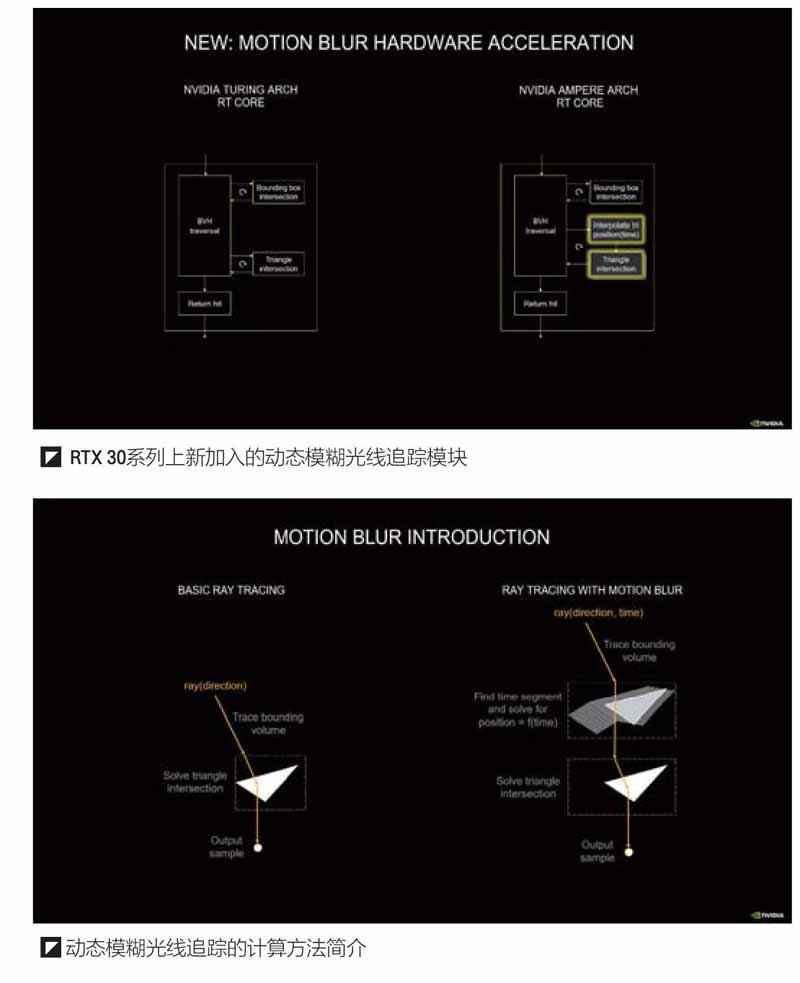
NVIDIA給出了2個對比圖用于解釋這個過程。首先來看單個光線的計算過程。在單光線的基礎的光線追蹤計算中,光線只是方向的函數,通過跟蹤給定的目標體積邊界,解決了三角形相交問題,從而能夠輸出光線的追蹤采樣值。在加入了動態模糊后,單個光線的計算將擁有2個變量,分別是方向和時間,同樣是通過跟蹤給定的目標體積邊界,然后查找此時物體運動的時間,求解位置有關的時間函數f(time)后,得到物體在此時的位置,再解決三角形相交問題,最終再輸出光線的追蹤采樣值。
在實際的計算中,光線計算會以多方向的形式進行輸出,在沒有動態模糊的情況下,不同光線匹配不同的方向,通過和單光線計算一樣的方式,輸出多個結果,碰撞測試,返回結果,完成光線追蹤采樣。在加入了動態模糊后,每個入射光線將被分配一個時間戳,這樣一來多光線、多方向和多個時間組成了復雜的計算陣列,此時需要同時計算物體在不同時間戳f(time)的位置后,再進行后續計算。比如圖中橙色光線嘗試在不同的時間點與橙色三角形相交,綠色和藍色光線分別嘗試與綠色和藍色三角形相交,如果命中則報告位置和結果。根據NVIDIA的介紹,安培架構中加入的全新“Interpolate Triangle Position unit(內插三角形位置單元)”能夠在BVH過程中,基于對象運動現有位置和動態方向插入新的三角形,以便光線可以在時間戳指定的時間內,在對象空間中的期望位置處與插入的三角形相交。這個新單元可以進行精確的光線追蹤運動模糊渲染,其渲染速度比圖靈架構的光線追蹤單元快8倍。當然,最終的結果輸出將采用濾波計算后的結果,結果是一個模糊的狀態,正如圖中顯示的那樣。
