改進樞軸特征選擇的跨領(lǐng)域情感分類
2020-11-17 06:28:26梁俊葛張周彬邵黨國
計算機工程與設計 2020年11期
梁俊葛,相 艷,張周彬,熊 馨,邵黨國,馬 磊
(昆明理工大學 信息工程與自動化學院,云南 昆明 650504)
0 引 言
在無標簽數(shù)據(jù)領(lǐng)域中進行情感預測是一個值得研究的問題,跨領(lǐng)域情感分類是解決這一問題的方法之一[1-5]。近年來,深度學習方在各領(lǐng)域有著良好的實際表現(xiàn)已經(jīng)逐漸取代傳統(tǒng)的機器學習方法成為跨領(lǐng)域情感分類的主流[6-11]。Ziser等[12]提出了神經(jīng)結(jié)構(gòu)對應模型,他們的模型可以捕捉到不同領(lǐng)域間有著相同表征的特征,并解決不同領(lǐng)域間特征分布問題。Yu等[13]提出了一種基于神經(jīng)網(wǎng)絡的跨領(lǐng)域情感分類模型,可對文本進行多重分類。雖然跨領(lǐng)域情感分類的研究已經(jīng)取得了諸多成果,但仍存在一定問題:①傳統(tǒng)的跨領(lǐng)域情感分類中,在文本向量化工作中使用詞袋模型把文本轉(zhuǎn)換為向量形式,這種方法從根本上不可避免會導致特征冗余的情況。②現(xiàn)有工作中,樞軸特征選擇方法并不完備。例如,傳統(tǒng)的跨領(lǐng)域情感分類主要采用互信息算法來選擇樞軸特征,該方法更多只考慮了特征與情感標簽直接的關(guān)系,并未考慮特征出現(xiàn)在文本中的頻次。而樞軸特征選擇的好壞,直接影響到最終的跨領(lǐng)域情感分類結(jié)果。
為解決上述問題,本文提出了改進樞軸特征選擇的跨領(lǐng)域情感分類模型:IPFS(improved pivot feature selection for cross domain sentiment classification)。該模型通過詞形還原構(gòu)建更稠密的文本特征,融合卡方檢驗算法選擇出更高質(zhì)量的樞軸特征,結(jié)合神經(jīng)網(wǎng)絡,得到更好的遷移特征。在亞馬遜數(shù)據(jù)集上的實驗結(jié)果表明,本模型相較現(xiàn)有傳統(tǒng)跨領(lǐng)域情感分類模型具有更好的分類效果。驗證了本文模型在跨領(lǐng)域情感分類任務中的有效性。
1 相關(guān)工作
已有的跨領(lǐng)域情感分類方法主要有基于跨領(lǐng)域詞嵌入的方法、基于樞軸特征選擇的方法以及基于自編碼器的方法。
跨領(lǐng)域詞嵌入的方法主要思想是約束樞軸特征在不同領(lǐng)域中有著相似的詞嵌入表示。Bollegala等[14]提出了跨領(lǐng)域詞嵌入表示模型,通過約束樞軸特征在不同領(lǐng)域之間有著相似的詞嵌入表示,來解決跨領(lǐng)域任務中樞軸特征的詞嵌入分布問題。Yang等[15]將word2vec模型的損失函數(shù)加入了新的約束項,結(jié)合源域詞向量來生成目標域的詞向量,實現(xiàn)跨領(lǐng)域情感分析。另一類跨領(lǐng)域情感分類方法是基于樞軸特征選擇的模型。Li等[16]利用注意力機制網(wǎng)絡模型自動選擇出樞軸特征,通過聯(lián)合訓練兩個參數(shù)共享的內(nèi)存網(wǎng)絡來選擇出更適合情感分類的樞軸特征并完成情感分類。Ziser等[12]提出神經(jīng)結(jié)構(gòu)對應學習模型,利用神經(jīng)網(wǎng)絡的優(yōu)勢來得到非樞軸特征和樞軸特征之間的映射關(guān)系。另一類基于自動編碼器的方法主要通過提取出對跨域變化具有魯棒性的特征,來減少不同領(lǐng)域間的域間差。Chen等[17]提出平均深度對抗網(wǎng)絡,通過對抗神經(jīng)網(wǎng)絡來將分類器從源域標簽數(shù)據(jù)中學習到的知識遷移到無標簽的目標領(lǐng)域中來學習跨領(lǐng)域中不變的特征。Ganin等[18]提出了DANN模型,利用領(lǐng)域?qū)褂柧毞椒▉硎股窠?jīng)網(wǎng)絡產(chǎn)生混淆分類器的表示。Qu等[19]提出了類別對齊對抗網(wǎng)絡,通過增強源域和目標域的類別一致性來完成跨領(lǐng)域情感分類任務。
2 本文方法
2.1 問題描述
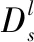
2.2 改進特征選擇的神經(jīng)結(jié)構(gòu)對應學習模型
本文提出的改進特征選擇的神經(jīng)結(jié)構(gòu)對應學習模型主要分為3個模塊:樞軸特征選擇模塊、特征遷移模塊、跨領(lǐng)域情感分類模塊。
2.2.1 樞軸特征選擇模塊
樞軸特征是在不同領(lǐng)域中有著相同的表征的特征,在不同領(lǐng)域中充當橋梁的作用。本文提出的樞軸特征選擇如圖1所示。

圖1 樞軸特征選擇
具體步驟為:
(1)預處理
提取出源域和目標域中的文本內(nèi)容,并對文本內(nèi)容進行去標點符號、去停用詞等預處理操作。
(2)詞形還原
詞形還原可以把詞語轉(zhuǎn)換為能夠表達完整語義的一般形式,可以減少冗余特征,為文本向量化做準備。
例如“l(fā)ikes”和“l(fā)ike”都是“l(fā)ike”的不同詞形,它們有著相同的情感極性,在樞軸特征選擇中應該把它們作為同一個特征對待。
WordNet詞典中對不同詞性的特征有著不同的詞形還原結(jié)果,因此在詞形還原之前需要對文本中的每個特征進行詞性標注。本文采用NLTK包中提供的詞性標注器pos_tag來對詞性進行標記,將對應的詞性轉(zhuǎn)換成WordNet詞典的名形動副4種詞性符號。將NN(名詞)、NNS(名詞復數(shù))、NNP(名詞單數(shù))、NNPS(名詞復數(shù))轉(zhuǎn)換為n(名詞);將JJ(形容詞),JJR(形容詞比較級),JJS(形容詞最高級)轉(zhuǎn)換為a(形容詞)。詞性標注后,再使用NLTK庫中基于WordNet的詞形還原工具WordNLemmatizer對特征進行詞形還原。
(3)文本向量化
利用Ds和Dt建立詞袋模型,在此基礎(chǔ)上進行文本向量化。文本向量的值為特征在該文本中出現(xiàn)的頻次。步驟(2)中的詞形還原可以起到文本向量特征降維的作用。例如在進行Amazon數(shù)據(jù)集Kitchen到Electronic跨領(lǐng)域情感分類任務時,詞形還原任務前,總的特征數(shù)目為12 961,共有25 233個句子,因此總的文本向量矩陣的維度為25 233*12 961。經(jīng)過詞形還原后,維度降低到了25 233*12 383。
(4)選擇具有最大卡方值的特征
卡方值表征了特征和標簽之間的關(guān)聯(lián)度,為卡方檢驗得到的統(tǒng)計值,其計算公式如下
(1)

(5)樞軸特征生成
在有著最大卡方值的特征中,選擇在源域和目標域中詞頻均高于m的特征作為最終的樞軸特征,得到樞軸特征集合fp。
2.2.2 特征遷移模塊
在特征遷移模塊,通過映射矩陣將非樞軸特征降維到低維度的隱層特征,用該隱層特征來預測樞軸特征的存在。本文的特征映射如圖2所示。具體過程如下。

圖2 特征映射
(1)總的特征集合為f=fp∪fnp,其中fp為前文步驟得到的樞軸特征集合,fnp為非樞軸特征集合,fp∩fnp=φ。
(2)對于給定的輸入文本,其樞軸特征向量表示為xp,非樞軸特征向量為xnp。為了學習到具有魯棒性以及緊密的文本特征表示,需要學習到從非樞軸特征到樞軸特征間的非線性映射。采用神經(jīng)網(wǎng)絡結(jié)構(gòu),xnp作為神經(jīng)網(wǎng)絡的輸入,通過編碼得到低維度、共享的中間隱層特征表示,其計算公式為
hwh(xnp)=σ(whxnp)
(2)
其中,wh為特征映射矩陣,σ(·) 表示sigmoid非線性激活函數(shù)。
(3)之后用隱層特征hwh(xnp) 預測樞軸特征xp,計算公式為
o=σ(wrhwh(xnp))
(3)
這樣得到的模型輸出o是一個概率向量,其取值是[0,1]之間的數(shù)值,維度與xp維度一致,其值預測了對應樞軸特征在該輸入文本中出現(xiàn)的概率。
(4)對于步驟(3)樞軸特征預測的結(jié)果,采用交叉熵函數(shù)作為損失函數(shù),如式(4)所示
(4)
式中:|fp| 是樞軸特征的個數(shù),xp是一個取值為0或1的向量,其第i個數(shù)值反映了所對應的第i個特征是否是輸入文本的樞軸特征。數(shù)值為1表示該特征是輸入文本的樞軸特征,為0則不是。這樣,上一步正確預測的概率越高,損失函數(shù)就會越小。通過最小化總的損失函數(shù),可以得到最優(yōu)的wh和wr。
在特征遷移模塊中,神經(jīng)網(wǎng)絡模型將高維度的非樞軸特征遷移到低維度、共享的隱層特征空間,在該低維的隱層空間下,源領(lǐng)域數(shù)據(jù)與目標域領(lǐng)域數(shù)據(jù)擁有相似的分布,故可以減小特征在不同領(lǐng)域間的域間差。
2.2.3 跨領(lǐng)域情感分類模塊
跨領(lǐng)域情感分類器訓練過程如圖3所示。具體過程如下。

圖3 IPFS的跨領(lǐng)域分類器
(1)利用源域和目標域標記數(shù)據(jù),獲得源域和目標域的初始文本特征。
(2)利用特征遷移模塊得到映射矩陣,將源域非樞軸特征乘以特征映射矩陣得到源域的遷移特征。目標域非樞軸特征乘以特征映射矩陣得到目標域域文本向量的遷移特征。
(3)將源域標記數(shù)據(jù)的初始特征和遷移特征拼接,送入logistics分類器,訓練分類器參數(shù)。
(4)將目標域的初始特征和遷移特征拼接,送入到訓練好的logistics情感分類器,即可得到目標域情感分類預測結(jié)果。利用目標域標記數(shù)據(jù)進行測試,可以得到跨領(lǐng)域情感分類的準確率。
3 實驗設置
3.1 數(shù)據(jù)集
為了驗證模型的實驗效果,我們進行了跨領(lǐng)域情感分類。采用Amazon產(chǎn)品評論數(shù)據(jù)的4個數(shù)據(jù)集:Books(B)、DVD(D)、Kitchen(K)、Electronics(E),每個領(lǐng)域包含1000條正向和1000條負向的產(chǎn)品評論,并且這4個數(shù)據(jù)集各有6000(B)、37471(D)、13 153(E)、16 785(K)條無標簽數(shù)據(jù)。實驗數(shù)據(jù)見表1。

表1 實驗數(shù)據(jù)
3.2 實驗對比模型
(1)No-DA:在源域訓練好分類器,不做任何領(lǐng)域適應操作,直接進行跨領(lǐng)域情感分類。
(2)SCL-MI模型:該模型采用互信息篩選出樞軸特征,然后通過SVD分解將樞軸特征與非樞軸特征關(guān)聯(lián)起來,為源域和目標域間提供一個橋梁,來完成跨領(lǐng)域情感分類。
(3)DANN模型:該模型利用對抗神經(jīng)網(wǎng)絡來完成跨領(lǐng)域情感分類任務。
(4)MSDA模型:該模型利用邊緣化的去噪自編碼器模型來完成跨領(lǐng)域情感分類任務。
(5)AE-SCL-SR模型:該模型在篩選出樞軸特征后,通過神經(jīng)網(wǎng)絡結(jié)構(gòu)將樞軸特征和非樞軸特征關(guān)聯(lián)起來,得到遷移特征,在此基礎(chǔ)上,完成跨領(lǐng)域情感分類任務。
(6)IPFS-Chi2模型:是指本文所提出的樞軸特征改進方法中,只基于卡方檢驗選擇樞軸特征的模型。
4 實驗結(jié)果與分析
4.1 評價指標
本文采用準確率來評估跨領(lǐng)域情感分類的效果,定義如下
(5)
其中,num_correct為目標域情感分類正確的樣本數(shù),num_all為目標域數(shù)據(jù)集樣本總數(shù)。
4.2 改進樞軸特征的實驗
為了驗證卡方檢驗和詞形還原的有效性,本文在Amazon這4個不同領(lǐng)域數(shù)據(jù)集上對AE-SCL-SR、IPFS-Chi2和IPFS這3種模型進行了12組對比實驗,結(jié)果如圖4所示。
由圖4可看出,相比AE-SCL-SR模型,IPFS-Chi2模型在12組實驗中有9組取得了更好的結(jié)果,2組持平。在DVD到Book,以及Kitchen到Electronics的跨領(lǐng)域情感分類實驗中,IPFS-Chi2模型的準確率分別高出AE-SCL-SR模型約0.8%和1.3%,驗證了卡方檢驗對于選擇樞軸特征的 有效性。進一步比較IPFS-Chi2和IPFS模型可以看到,在12組實驗中IPFS模型有9組取得了高于IPFS-Chi2約0.3%的準確率,2組持平。在DVD到Kitchen的跨領(lǐng)域情感分類實驗中,IPFS模型的準確率高出IPFS-Chi2模型約0.7%。以上結(jié)果進一步證實了詞形還原的作用。

圖4 改進樞軸特征選擇方法的實驗結(jié)果
4.3 與基線模型的比較
表2是本文方法與各基線模型的分類準確率對比結(jié)果。

表2 IPFS模型與其它模型的實驗結(jié)果比較
可以看出本文提出的IPFS模型在各個情感分析任務中均取得了較好的實驗結(jié)果,平均準確率達到了78.7%,優(yōu)于所有的基線模型。對于跨領(lǐng)域情感分類任務,本文模型在12組實驗全部優(yōu)于SCL-MI模型,說明本文樞軸選擇的質(zhì)量影響著最終的實驗分類準確率以及神經(jīng)網(wǎng)絡的優(yōu)勢性。與DANN模型相比,本文模型由11組優(yōu)于DANN模型,1組持平,驗證了本文模型的有效性,通過提高選擇的樞軸特征質(zhì)量并結(jié)合神經(jīng)網(wǎng)絡可以達到更好的分類準確率。IPFS在12組實驗中有10組實驗性能明顯優(yōu)于MSDA模型,1組實驗性能與MSDA持平。與AE-SCL-SR模型相比,IPFS模型有10組實驗性能優(yōu)于AE-SCL-SR模型,1組實驗性能與AE-SCL-SR持平,驗證了本文模型可以更好選擇高質(zhì)量的樞軸特征,更好完成跨領(lǐng)域情感分類任務,達到更高的分類準確率。此外,IPFS模型相對AE-SCL-SR、DANN、MSDA、SCL-MI、No-DA跨領(lǐng)域情感分類的準確率在12組實驗上平均提高了0.6%、2.7%、3.9%、4.4%和5.7%。實驗結(jié)果表明,IPFS模型能夠很好解決跨領(lǐng)域情感分類問題。
從表2的對比結(jié)果還可以看出,跨領(lǐng)域情感分類任務中,所有模型都在Kitchen和Electronic這一對遷移任務中取得了最好的結(jié)果,這說明Kitchen和Electronic領(lǐng)域的特征分布最相似,域間差最小,領(lǐng)域適應效果更佳。同時,從各個方法的平均準確率可以看出,特征遷移的模型均優(yōu)于沒有進行遷移的情況,這說明跨領(lǐng)域情感分類學習可以有效地提高分類準確率。
5 結(jié)束語
針對跨領(lǐng)域情感分類任務,本文提出的IFPS模型融合了詞形還原和卡方檢驗來選擇樞軸特征,在特征映射過程中結(jié)合神經(jīng)結(jié)構(gòu)對應學習來構(gòu)建樞軸特征和非樞軸特征間的映射關(guān)系。通過詞形還原來減少文本特征數(shù)目,得到更加稠密的文本向量化表示,通過卡方檢驗讓模型能夠更好得到和情感標簽關(guān)聯(lián)更緊密的特征作為樞軸特征,并結(jié)合神經(jīng)網(wǎng)絡完成跨領(lǐng)域情感分類任務。在Amazon數(shù)據(jù)集上的12組不同跨領(lǐng)域情感分類任務的對比實驗結(jié)果表明,本文提出模型的準確率比幾種較先進的跨領(lǐng)域情感分類模型有著進一步的提升,能夠很好解決跨領(lǐng)域情感分類任務。
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
