基于大數據架構的輿情數據中心分析與設計
2020-11-18 14:00:34周奇印鑒張良均
現代計算機 2020年28期
周奇,印鑒,張良均
(1.廣東開放大學信息與工程學院,廣州510630;2.中山大學數據科學與計算機學院,廣州510630;3.廣州泰迪智能科技有限公司,廣州510630)
1 建設背景
自習近平主席在2013 年9 月和10 月分別提出共建“絲綢之路經濟帶”和“21 世紀海上絲綢之路”(簡稱“一帶一路”)的重大倡議以來,絲路沿線國家及國際社會反響強烈。從國際輿論情況的來源看,既有來自政界、學界、商界、媒體的聲音,也有來自民間公眾的評價。從其性質看,既有積極和充滿期待的一面,也有謹慎和疑慮的一面,還有反對、詆毀的雜音。從其認知內容看,既存在合作互信現象,又存在知之甚少現象,甚至不乏錯誤解讀現象。準確把握相關國家的絲路觀、了解它們的利益與訴求,有助于我們科學研判與決策,講好絲路故事,克服認知風險,營造積極的國際輿論氛圍,順利推進與絲路經濟帶國家的務實合作,實現共同發展、共同繁榮、合作共贏之目標。
目前“一帶一路”已經設計包括亞洲43 國、中東歐16 國、獨聯體4 國、非洲1 國在內的共64 國。由于域內民族眾多,教派林立,更有眾多歷史遺留問題,了解相關國家政府、民眾對“一帶一路”的態度,解讀相關地區和國家對“一帶一路”倡議的公共話語與基本認知,才能更加有針對性地摸索對外傳播“一帶一路”倡議的重點,逐步降低和打消相關國家的疑慮;同時提升中國國際輿論話語權,力避中國在全球輿論場中的失語問題。
2016 年10 月29 日,首屆中國國際輿論學年會在廣東外語外貿大學召開,華南首個新聞大數據聯合實驗室落戶廣外。在中國走出去融入國際社會的過程當中,國際輿論以及通過國際輿情了解中國在國際的身份,中國怎么樣以更好的姿態更有效地走出去,如何更好地做好輿情分析的研究支持工作成為義不容辭的責任。
2 現狀及需求分析
2.1 現狀
(1)信息獲取過于分散收集效率低
互聯網日益發達的今天,我們獲取信息的途徑也變得越來越豐富,足不出戶就能掌握全球資訊。資源越多意味著我們要收集這些信息需要花費的時間就越多,如“一帶一路”有來自各國政界、學界、商界、媒體的聲音,也有來自民間公眾的評價,而這些信息分布在國內外各大主流網站、論壇、博客、貼吧、微信,等等,要進行這些信息的收集需要發大量的人力物力,同時信息完整度和時間得不到保證。
(2)獲取大量相關信息后無法進行處理和判斷
大量的各類信息收集完成后,需要根據需求進行信息處理,去除垃圾信息,并作出相應判斷。面對這類重復性多且任務煩重的工作,少量人力短時間內無法完成,同時得出來的數據偏向于個人情感。
(3)各信息間難以歸類分析
要準確掌握資訊最新動向,需要結合前期資訊作出歸類分析,結合經驗得出事件趨向,達到先知先斷的效果。而要做到信息歸類分析,需要作很多相應工作,同樣費時費力。若這些工作不能按時完成,歸類出來的結果也失去了意義。
2.2 機遇
習近平總書記指出,互聯網是我們這個時代最具發展活力的領域。互聯網快速發展,給人類生產生活帶來深刻變化,也給人類社會帶來一系列新機遇新挑戰。新大型數據新聞節目——《數說命運共同體》,節目挖掘超過1 億GB 的數據,分析發現“一帶一路”沿線國家40 多億百姓休戚相關的密切聯系。讓沉默的數據說話,它們呈現出來的,是“一帶一路”國家間前所未見的聯系圖景。
2017 年8 月24 日,中國電子信息產業發展研究院在工業和信息化部信軟司指導下發布了《中國大數據產業發展水平評估報告(2017 年)》(以下簡稱《評估報告》)。作為《大數據產業發展規劃(2016-2020 年)》頒布后的第一個年度大數據產業評估報告,為我國大數據產業健康發展和相關產業管理工作提供了有力支撐。
2.3 需求分析
隨著互聯網的發展大數據不斷地向社會各行各業滲透,為每一個領域帶來變革性影響,并且正在成為各行業創新的原動力和助推器。互聯網社交互動技術的不斷發展創新,人們越來越習慣于通過微博、微信、博客、論壇等社交平臺去分享各種信息數據、表達訴求、建言獻策,每天傳播于這些平臺上的數據量高達幾百億甚至上千億條,這些數量巨大的社交數據構成了大數據的一個重要部分,這些數據對于政府收集民意動態、企業了解產品口碑、公司開發市場需求等發揮重要作用。
輿情資訊信息涵蓋的內容很多,對這些內容分析需要一個專門的分析平臺做處理,以減輕人員工作量及數據準確度,以極度的時間分析掌握各事件動態,及發展趨勢為進一步推理提供數據基礎。
需要一個分析平臺去把事件歸類,以應對不同的分析場景,如政策、經濟、旅游、文化等為類分析,讓結果更有針對性,方便針對性的解析問題。
通過平臺實現對世界各國和地區宏觀經濟、投融資環境、項目需求、項目進展、風險評估等信息采集、解析和數據挖掘,直觀顯示信息變化。
3 總體流程
圖1 展示了平臺基本建設流程。
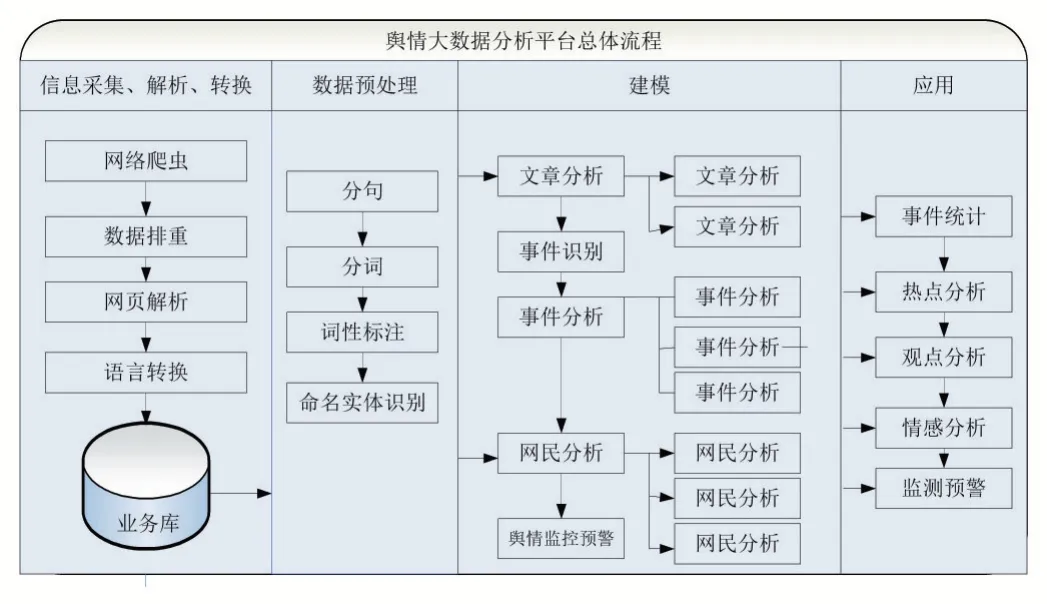
圖1 平臺基本建設流程
信息采集、解析與轉換:進行網絡爬蟲,并解析網頁得到所需信息,通過語言轉換過程將解析后數據統一翻譯為中文,并存儲至業務庫;
數據預處理:針對每一個文章記錄,進行分詞、詞性標識、實體識別等預處理過程,為后續的數據挖掘建模提供基礎;
挖掘建模:針對不同的應用場景,建立不同的模型,如文章分析、事件識別、事件分析、網民分析、輿情監控預警等;
應用:將模型預測的結果進行展示,為最終用戶提供可視化,包括事件統計、熱點分析、觀點分析、情感分析、監測預警。
4 總體建設規劃
輿情大數據分析平臺的建設規劃是基于一網、二化、三庫、五應用四個方面展開的。
(1)一網
即我們的輿情大數據分析平臺,利用數據采集、云計算、數據挖掘等技術,構造的一個應用平臺,它通過一個入口,用戶通過瀏覽器即可訪問有權限的數據及分析結果。
(2)二化
即標準化和可控化。標準化即數據格式要標準化、處理流程標準化、分析過程標準化。可控化即平臺將采集的數據從不同維度、不同密度進行分析,預測并發現熱點事件與負面輿情,對公共政策提供基于大數據的評估和建議。
(3)三庫
三庫即業務數據庫、媒體事件庫、主題分析庫。業務數據庫即從不同的網頁爬取“一帶一路”相關網頁信息,并通過排重、解析、翻譯等一系列過程將結果數據匯集而已。媒體事件庫即將業務數據進行預處理后,分解聚合為網民、評論數據、媒體事件等可供分析的數據庫。主題分析庫即將媒體事件庫數據從不同維度、不同密度進行分析挖掘形成的數據庫。通過建立關聯耦合的數據庫,因虛而實,形成持續數據,實現超融合、超預期的工作支撐。
(4)五應用
應用即為展示給最終用戶的分析結果。包括事件統計、熱點分析、觀點分析、情感分析、監測預警。
5 項目部署網絡拓撲圖
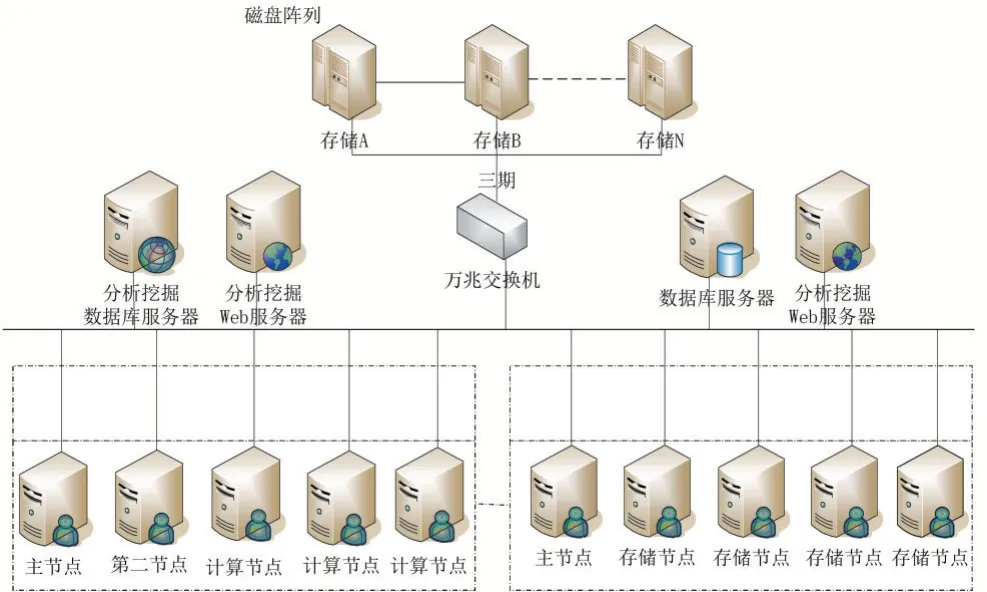
圖2 平臺網絡拓撲結構
6 總體應用架構
輿情大數據分析平臺在充分考慮業務的平穩運行、滿足性能要求的前提下,從數據采集、支撐框架、大數據中心和綜合應用等方面提供可行的應用方案,其應用架構如圖3 所示。
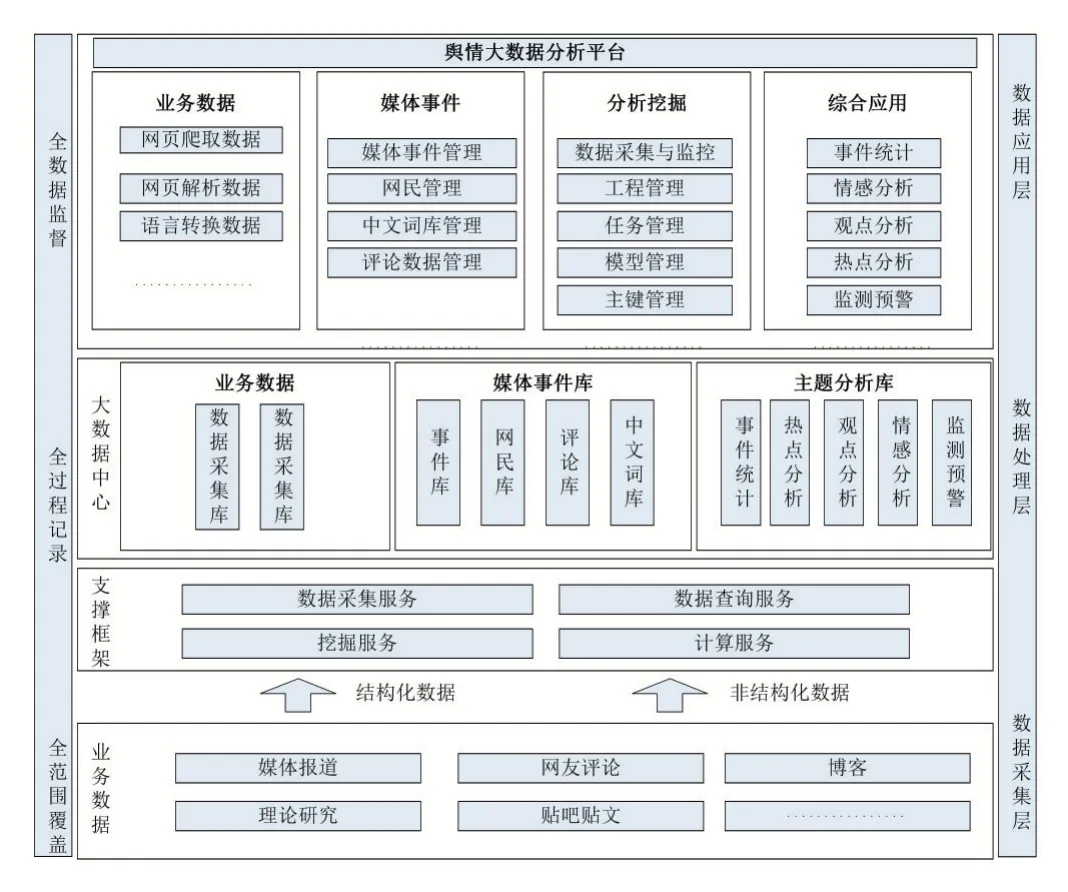
圖3 平臺應用架構
(1)數據采集層
整個平臺通過數據采集層實現從不同網頁、不同終端數據的抓取及匯聚,形成集中統一的數據資源。這些數據資源是整個平臺所有功能模塊運行的核心基礎,因此數據采集層也是整個平臺架構中的基礎。輿情大數據分析平臺通過數據采集層和不同系統進行對接,獲取上層數據處理應用所需的各種數據,如媒體報道、網友評論、貼文等;也能夠支持不同數據類型的獲取,如各種主流數據庫、非結構化數據文件(如網頁數據等等)。
(2)數據處理層
在數據匯聚到融合平臺上以后,通過數據處理層實現對平臺數據的底層處理工作,為上層功能模塊提供有力的工具保障。可以說,數據處理層是整個大數據平臺的核心所在。應該將完成業務信息庫、媒體數據庫和主題數據庫的整理,完成數據中心、綜合應用中心、分析挖掘平臺所支撐的計算及分析處理。通過這層數據處理實現數據在整個生命周期內的所有管理功能,并提供了完善的數據模型和開發接口,為上層應用系統的功能模塊封裝了必要的、完善的實現手段。
(3)數據應用層
數據應用層是根據輿情大數據分析平臺的具體項目需求設計的具體功能模塊和展現效果,利用數據處理層提供的資源和接口,對數據采集層匯聚過來的數據,按照不同的業務邏輯進行處理和展示,是整個數據綜合平臺的核心價值所在。本項目的目標在于利用大數據的手段,通過對多源數據的融合和在分析平臺上進行配置及定制化開發。為更好的實現這一目標,在分析平臺上利用融合匯聚的各系統數據,重新定義了新的業務系統。區別于傳統應用系統各自獨立的設計方式,在綜合平臺中,我們將業務系統的上層展現與底層的功能模塊進行分離,通過對不同應用子系統業務邏輯的深度分析和挖掘,開發出不同類型的功能子模塊,便于各個業務系統根據需要選擇接入點,應用之間通過服務總線進行有效交互,以適應未來業務發展的需求,實現信息、資源的共享和重用,提供數據共享及服務共享能力。
7 系統技術架構
輿情大數據分析平臺主要從軟件層面提供平臺級的應用支撐能力,基于最底層的Linux 集群基礎設施,提供PaaS 層的平臺服務,在其之上提供SaaS 層應用。
在PaaS 層提供數據采集服務、分布式文件存儲服務、分布式數據庫服務、數據搜索服務、分布式離線計算服務、實時計算服務、數據挖掘服務、分布式消息隊列服務、分布式協調服務、開放式監控服務以及集群管理。
在DaaS 層構建數據庫群,包括業務數據庫、媒體事件庫、主題數據庫。
在SaaS 層提供應用級別的服務:情感分析、觀點分析、熱點分析、監測預警和事件統計。平臺技術架構如圖4 所示。
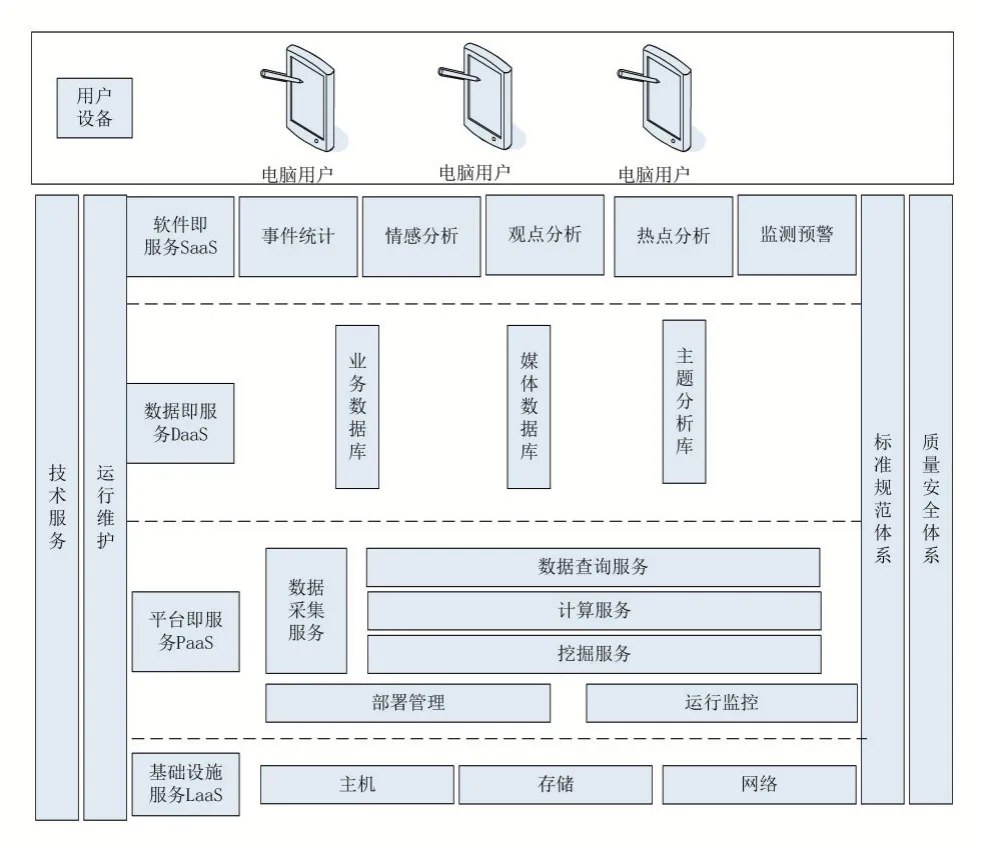
圖4 平臺技術架構
8 結語
本文對輿情數據中心的基本建設流程、部署網絡拓撲圖、總體應用架構和系統技術架構進行分析與設計,能對大量的輿情資訊信息進行科學有效處理,以減輕人員工作量及數據準確度,以極短的時間分析掌握各事件動態,及發展趨勢為進一步推理提供數據基礎。
通過對分析與設計平臺把事件歸類,以應對不同的分析場景,如政策、經濟、旅游、文化等歸類分析,讓結果更有針對性,方便針對性地解析問題,能對信息采集、解析和數據挖掘,直觀顯示信息變化。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
山東工業技術(2016年15期)2016-12-01 05:31:22
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
