以法統方結合機器學習探索中醫溫膽治法沿革
2020-11-19 07:26:32楊巍文小平郭晶磊
中國中醫藥信息雜志 2020年11期
楊巍,文小平,郭晶磊
論著·中醫藥信息學
以法統方結合機器學習探索中醫溫膽治法沿革
楊巍,文小平,郭晶磊
上海中醫藥大學基礎醫學院,上海 201203
以溫膽治法的清溫傾向沿革為例,探索以法統方結合機器學習的中醫治法研究方法。根據以法統方原理,將中醫治法比較轉化為方劑集合的比較,通過方劑藥物組成變化研究治法的變化。建立并應用隨機森林模型,量化比較2組或多組方劑集合的相似性,即不同治法之間的相似性。在《三因方》之前,溫膽治法與溫法的相似性為75%;在《三因方》之后,溫膽治法與溫法的相似性為19%。中醫溫膽治法在《三因方》之前以溫法為主,之后則傾向于清法。以法統方結合機器學習方法建立模型可用于中醫治法領域的量化研究。
方劑學;中醫治法;機器學習;隨機森林;溫膽治法
以往中醫治法研究多為回溯性研究,總結某個治法篩選出的方劑集合內部的規律;其更多作為一個分類工具,依附于其他研究對象如專病或特定醫家的組方用藥等。不同治法之間的關系一直是中醫方劑研究的盲點。
以法統方是對治法和方劑關系的高度概括,包括依法遣方、以法組方、以法釋方和以法類方四方面[1]。其數據挖掘領域的本質是對于治法與方劑組成關聯數據集的研究。通過以法統方,在給定樣本總體范圍內,可以將2種治法的比較問題轉化為其所代表的2個方劑集合的比較。隨機森林是機器學習中一種高級分類技術,通過隨機放回抽樣,削弱數據間的相關性,構建大量的規則樹,進而通過簡單投票判斷類別,實現對學習樣本集合規則的較優擬合[2]。與其他常見基于連續數據的算法比較,隨機森林有適用性廣泛的特點,尤其是對離散數據的擬合[3]。方劑集合的組成數據為離散型,適合運用隨機森林算法。
溫膽是針對膽寒病機的治法,源自《備急千金要方》“治大病后,虛煩不得眠,此膽寒故也,宜服溫膽湯方”[4],學術界對于溫膽治法是溫膽還是清膽有諸多討論[5-8]。本研究基于以法統方理論,將治法的比較轉化為方劑集合的比較,再通過機器學習模型對方劑集合進行量化比較,從而量化“溫膽治法”與溫法、清法的相似程度,厘清溫膽治法清溫傾向的沿革,以更好地繼承和理解歷代醫家的認識。
1 研究對象
針對溫膽治法的溫清傾向,“溫膽治法”與“溫法”的比較可以轉化為溫膽治法的方劑集合與溫法方劑集合的比較(V溫膽/V溫法),“溫膽治法”與“清法”的比較可以轉化為溫膽治法的方劑集合與清法方劑集合的比較(V溫膽/V清法)。在給定樣本總體范圍內比較2個方劑集合的問題,可通過隨機森林算法轉化為以一個方劑集合建模,另一方劑集合應用模型的形式,量化比較2個方劑集合的相似性。以“溫膽治法”方劑集合(V溫膽)與“溫法”方劑集合(V溫法)比較為例:先由V溫法和“清法”方劑集合(V清法)生成研究范圍內的溫法辨別模型(F溫法),則V溫膽/V溫法=F溫法(V溫膽)/F溫法(V溫法)=F溫法(V溫膽)。也就是近似地建立一個含有幾百個方劑學專家的辨別模型系統,通過投票來量化V溫膽與V溫法的相似性,即“溫膽治法”與“溫法”的相似性(見圖1)。同理,V溫膽與V清法的比較即F清法(V溫膽)。

圖1 溫膽治法與溫法相似性辨別基本邏輯圖
2 方法與結果
2.1 模型建立
采用《中醫方劑大辭典》(第一版)[9]的清法和溫法方劑組成數據,基于隨機森林算法構建溫法辨別模型F溫法(見圖2),運用模型判別溫膽治法對應方劑是否屬于溫法,通過其被判別為溫法的比例F溫法(V溫膽)分析溫膽治法與溫法的相似性(見圖3)。同理可獲得溫膽治法與清法的相似性。

圖2 溫法辨別模型訓練圖
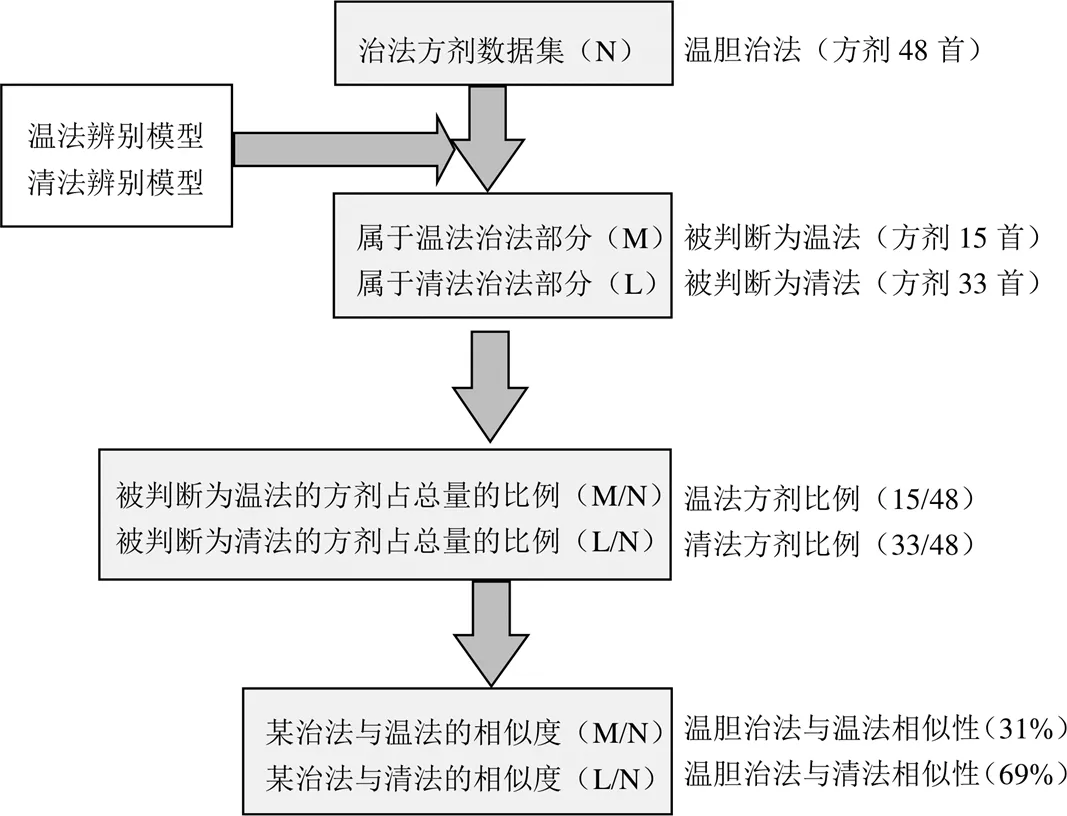
圖3 溫法辨別模型應用圖
2.2 數據錄入
將《中醫方劑大辭典》(第一版)共15 163首具有功用字段的方劑導入數據庫。以“清熱”等50個治法關鍵詞檢索獲得清法方劑2110首,以“散寒”等39個治法關鍵詞檢索獲得溫法方劑968首,兩者構成學習集;以“膽寒”“膽冷”“膽虛冷”“溫膽”為關鍵詞檢索獲得溫膽治法方劑48首,構成應用集。
2.3 數據清洗
排除清溫并用的方劑25首、與膽有關的治法方劑1首。提取方劑組成字段的中藥,剔除劑量、炮制和服法等信息,根據《中華人民共和國藥典》[10]、《中華本草》[11]、《中藥大辭典》[12]、《中藥學》[13]、《中藥別名速查大辭典》[14]對藥名進行規范。
2.4 模型訓練
從隨機森林調參效率角度,將學習集中出現30次以上的中藥(共192味)作為隨機森林的構成參數。
袋外錯誤率是一種取代測試集的誤差泛估計[15]。使用R語言,調用randomForest包,通過不斷人工調整參數,以較低袋外錯誤、較高學習集正確率,選定參數try=19、nodesizes=15、ntree=1500,其他參數使用默認值。通過set.seed保證隨機模型的可重復性,不斷人工調整參數,以袋外錯誤率0.09、學習集正確率0.96,選擇為“溫法辨別模型”。同理獲得相同袋外錯誤率和學習集正確率的清法辨別模型。
2.5 模型應用
使用溫法辨別模型對應用集(溫膽治法方劑集)進行判斷,獲得溫膽治法的總體溫法相似性為31%。同理獲得溫膽治法的總體清法相似性為69%。
在溫法辨別模型、清法辨別模型判斷應用產生的數據結果基礎上,以《中醫方劑大辭典》(第一版)為數據來源,補充方劑出處(方書)的成書年代,作為該方劑的出現時間。歷代溫膽治法方劑增長趨勢圖見圖4。在1174年以前,即《三因方》出現之前,新增加的溫膽治法方劑多傾向于溫法,溫膽治法與溫法的相似性為75%,與清法的相似性為25%,組方多為含有肉桂、附子、烏頭的溫補之劑,可見溫膽治法早期主要為溫法;在1174年及以后,即《三因方》出現后,溫膽治法方劑多傾向于清法,與溫法的相似性為19%,與清法的相似性為81%,尤其在明代方書整理過程中,溫膽的清法特性被加強,甚至將溫膽默認為清法,其源頭為《千金》溫膽湯[16],可見溫膽治法后期傾向于清法。
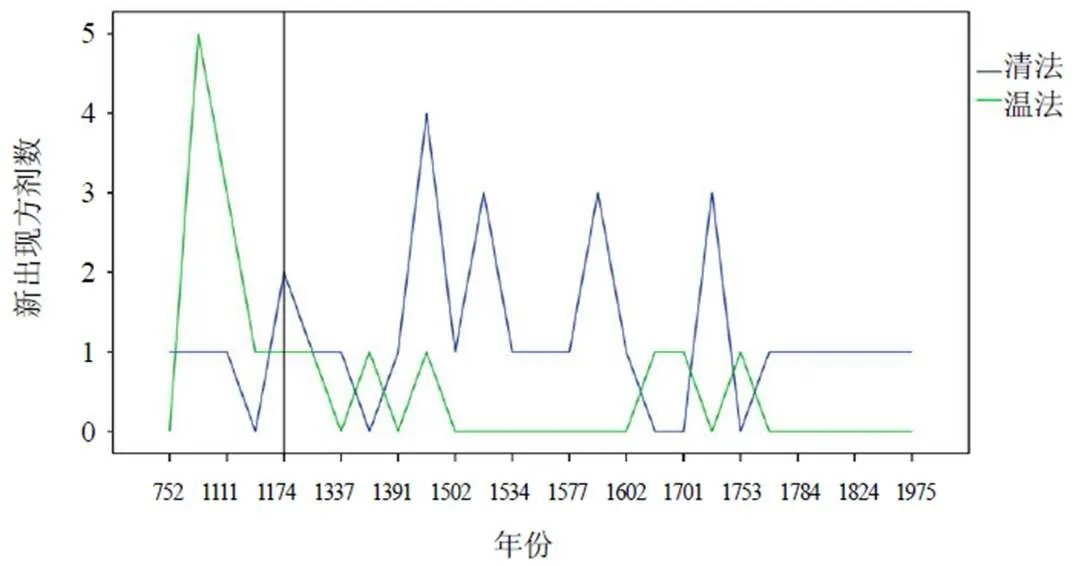
圖4 歷代溫膽治法方劑增長趨勢圖
3 討論
隨機森林相對其他簡單分類方法難以解釋,只能從結果進行逆向推測,且調參困難,對失衡分布學習集效果不佳,故本研究在構建學習集時,盡量平衡數據,采用樣本加倍的方式構建清法學習集。隨機森林結果具有隨機性,本研究通過set.seed保證可重復性。針對不同模型結果不穩定問題,改進為建立5個同參數不同隨機數(不同seed)的模型,各模型結果基本與原模型結果分析無差異。
對于單個方劑,劑量、味數、炮制和服法都是影響其清溫傾向的重要屬性。但對于方劑集合來說,其中某個方劑的特殊劑量等信息對整體屬性影響有限。從大數據角度,個別偏差會被排除,藥物組成是方劑集合最主要的屬性特點,因此,本研究雖然僅采用藥物組成建模進行研究,仍可大致反映方劑集合的整體屬性。如將藥物劑量、味數、炮制和服法也納入分析,數據模型分析結果會更加全面和準確。
本研究建立的方法可運用于各種治法相似性研究,以及基于治法相似性的古方、古法的傳承脈絡探索研究。經過一定變化,可以運用于中醫疾病的異名準確性研究(如消渴各種異名的相對準確性),以及現代病名與古代病名的對應關系研究(如骨質疏松癥對應的古代病名)。本方法變換后可應用于基于對應方劑的各種中醫基本概念量化比較,如以五臟方劑集構成學習集,三焦方劑集構成應用集,可以從方劑組成角度量化判斷三焦與各臟的相關性。
綜上所述,本研究以探索溫膽治法的清溫傾向歷史沿革為例,結合以法統方和機器學習,將方劑集合量化比較問題轉換為隨機森林的建模和應用,進而反映與方劑集合關聯的中醫治法間的量化關系,提供了一種新的中醫治法量化研究方法。本方法尚不十分成熟,對于將中醫各種治法轉化為方劑集合、方劑集合變換為隨機森林模型的過程中,如何更好地進行數據信息的取舍,最終結果的參數評估,以及在不同研究范圍內的有效性,尚需通過大量實踐進一步積累經驗。
[1] 鄧中甲.方劑學[M].北京:中國中醫藥出版社,2003:11.
[2] BREIMAN L. Random forests[J]. Machine Learning,2001,45(1):5-32.
[3] 洪燕珠,周昌樂,張志楓,等.基于隨機森林法的慢性疲勞證候要素特征癥狀的選擇[J].中醫雜志,2010,51(7):634-638.
[4] 孫思邈.備急千金要方[M].北京:中醫古籍出版社,1997:371.
[5] 侯志明,王艷榮.膽寒癥淺析[J].內蒙古中醫藥,2008,27(3):21-22.
[6] 于東林,丁然.溫膽湯“清膽”質疑[J].河北中醫,2013,35(7):1013- 1014.
[7] 張春曉,丁春明,桑希生.膽寒證與溫膽湯解析[J].中醫藥學報,2016, 44(3):113-115.
[8] 施國善,王有鵬.溫膽湯源流及方名探析[J].遼寧中醫雜志,2016, 43(8):1635-1637.
[9] 彭懷仁.中醫方劑大辭典[M].北京:人民衛生出版社,1993.
[10] 國家藥典委員會.中華人民共和國藥典:一部[M].北京:中國醫藥科技出版社,2015.
[11] 國家中醫藥管理局《中華本草》編委會.中華本草[M].上海:上海科學技術出版社,1999.
[12] 南京中醫藥大學.中藥大辭典[M].上海:上海科學技術出版社,2006.
[13] 高學敏.中藥學[M].北京:中國中醫藥出版社,2002.
[14] 李順保.中藥別名速查大辭典[M].北京:學苑出版社,1997.
[15] JAMES G, WITTEN D, HASTIE T, et al. An introduction to statistical learning[M]. Berlin:Springer,2013:316-321.
[16] 吳元潔,王正.溫膽湯源流及歷代應用考略[J].中成藥,2012,34(1):130-132.
Exploration of Evolution of Gallbladder Warming Therapy Through Therapy Guiding Prescription Combined with Machine Learning
YANG Wei, WEN Xiaoping, GUO Jinglei
To explore a research method of TCM treatment based on therapy guiding prescription combined with machine learning by taking the evolution of gallbladder warming therapy as an example.According to therapy guiding prescription, a comparative study was conducted by transforming TCM treatment into composition of prescriptions. The changes in treatment were studied through changes in the composition of prescriptions. Through the establishment and application of a random forest model, the similarity of two or more sets of prescriptions was quantified and compared, that was, the similarity between different treatments.Prior to, gallbladder warming therapy had 75% similarity with warming therapy; while it had 19% similarity with warming therapy after.Gallbladder warming therapy was mainly warming therapy before, and became clearing therapy after that. This research method which combines therapy guiding prescription with machine learning method to establish models can be applied to the quantitative research in the fields of TCM therapy.
prescription science; TCM treatment; machine learning; random forest; gallbladder warming therapy

R243;R2-05
A
1005-5304(2020)11-0096-03
10.19879/j.cnki.1005-5304.201909317
上海市衛生和計劃生育委員會中醫藥科技創新項目(ZYKC201601003)
郭晶磊,E-mail:guojinglei@aliyun.com
(2019-09-23)
(2019-11-07;編輯:陳靜)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
光學精密工程(2016年6期)2016-11-07 09:07:19
