面向分布式AI的智能網(wǎng)卡低延遲Fabric技術
2020-11-20 07:40:58熊先奎XIONGXiankui袁進輝YUANJinhui宋慶春SONGQingchun
中興通訊技術 2020年5期
關鍵詞:模型
熊先奎/XIONG Xiankui, 袁進輝/YUAN Jinhui, 宋慶春/SONG Qingchun
(1. 中興通訊股份有限公司,中國 深圳 518057;2. 北京一流科技有限公司,中國 北京 100083;3. 國際高性能計算和人工智能咨詢委員會,美國 森尼韋爾 94085)
(1. ZTE Corporation, Shenzhen 518057, China;2. Beijing Oneflow Technology Co., Ltd., Beijing 100083, China;3. HPC-AI Advisory Council, Sunnyvale 94085, USA)
2012年,AlexNet深度神經(jīng)網(wǎng)絡獲得ImageNet圖像識別測試的歷史性突破。隨后,基于深度學習的人工智能(AI)研究和應用再度爆發(fā)[1-2]。深度學習使用多層卷積或循環(huán)神經(jīng)網(wǎng)絡和反向傳播算法,通過標簽數(shù)據(jù)集訓練特定模型,在推理階段提供語音識別、圖像識別等AI應用。算法、數(shù)據(jù)集、算力是本輪AI成功騰飛的3個要素,三者缺一不可。其中,以圖形處理單元(GPU)多指令多數(shù)據(jù)流(MIMD)計算架構提供的高性能算力訓練平臺成為深度學習實現(xiàn)工程化的基礎。
在機器學習領域[3],隱含狄利克雷分布(LDA)主題模型對文本表征降維后,生成聚類統(tǒng)計模型,以支持互聯(lián)網(wǎng)實現(xiàn)文本分類、頭條推薦等。由大規(guī)模邏輯回歸(LR)生成的預測模型所支撐的金融違約分析應用等機器學習方法,也同樣需要大規(guī)模算力部署。
大規(guī)模機器學習本質上是一種特殊的高性能計算(HPC),因此,要實現(xiàn)計算的分布式和并發(fā)性,除算力本身外,還離不開計算范式的定制化設計和計算通信的網(wǎng)絡優(yōu)化。
最新深度學習模型的訓練需要消耗更多的算力。鑒于深度學習模型計算主要是稠密型計算,業(yè)界廣泛采用GPU等協(xié)處理器進行并行加速,但單個協(xié)處理器的算力仍無法滿足日益增長的算力需求。通過高速互聯(lián)技術把更多協(xié)處理器連接起來,能夠協(xié)同輸出大規(guī)模算力,可實現(xiàn)點對點數(shù)十至上百吉比特的傳輸帶寬,例如節(jié)點內可以使用外設部件互連標準(PCIe)或NvLink等技術。當單個節(jié)點仍無法滿足需求時,可通過高速網(wǎng)絡實現(xiàn)多節(jié)點分布式計算。此時,由于傳輸帶寬過低,普通以太網(wǎng)絡(千兆網(wǎng)或萬兆網(wǎng))會出現(xiàn)多節(jié)點擴展效率極低、計算資源嚴重浪費的現(xiàn)象。因此,在分布式深度學習訓練場景中,基于遠程直接內存訪問(RDMA)的網(wǎng)絡通信成為最佳選擇。
分布式深度學習訓練任務必須使用RDMA技術,這是因為:(1)深度學習訓練任務普遍使用隨機梯度下降算法。每處理一小片數(shù)據(jù)就需要更新模型參數(shù),計算粒度很細,對網(wǎng)絡傳輸?shù)难舆t容忍度非常低。(2)深度學習普遍使用的GPU加速卡,吞吐率非常高。如果數(shù)據(jù)搬運速度跟不上計算速度,就容易造成計算資源浪費。(3)在深度學習訓練中,系統(tǒng)調度、數(shù)據(jù)加載和預處理均需要使用CPU資源,而基于傳統(tǒng)以太網(wǎng)的網(wǎng)絡傳輸也需要消耗很多CPU計算資源,這會影響整個系統(tǒng)的效率。RDMA的內核旁路技術可降低CPU利用率,提高整個系統(tǒng)的效率。
因此,分布式AI訓練平臺需要特殊的硬件設計、低延遲的通信網(wǎng)絡、抽象化的通信原語庫和定制化的計算范式。其中,低延遲的通信網(wǎng)絡和通信原語庫是本文關注的重點。
1 RDMA低延遲特性和技術背景
RDMA技術是由無限帶寬貿易協(xié)會(IBTA)定義的面向高性能、大規(guī)模、軟件定義及易管理等的先進網(wǎng)絡通信技術[4],最初被用于InfiniBand網(wǎng)絡,后來被廣泛應用在以太網(wǎng)中。基于融合以太網(wǎng)的RDMA(RoCE)更是被全球各大數(shù)據(jù)中心用戶廣泛地部署。RDMA已成為目前提升網(wǎng)絡應用性能的關鍵技術之一。
RDMA技術提供了一個可以將RDMA硬件對外進行高效通信的抽象層(verbs)。用戶可以利用各種方式來調用verbs,以實現(xiàn)對于RDMA硬件的調用[5]。一般而言,雖然直接調用verbs可以獲得最佳性能,但是仍然需要對應用的通信接口進行修改。當然,也可以直接使用現(xiàn)有的通信中間件來調用RDMA,而無須對應用做任何修改,如信息傳遞接口(MPI)[6]、英偉達多GPU通信庫(NCCL)[7]、Internet小型計算機系統(tǒng)接口(iSCSI)、基于Fabric的非易失性存儲(NVMeoF)、Lustre等。 這是因為這些中間件已經(jīng)將RDMA通信庫包含在自己的通信庫里,對應用而言是完全透明的。
在通信過程中,RDMA可以繞開操作系統(tǒng),直接實現(xiàn)不同機器內存之間的數(shù)據(jù)傳遞。如圖1所示,與傳輸控制協(xié)議(TCP)相比,RDMA不需要從內存到操作系統(tǒng)、再到網(wǎng)卡硬件的層層拷貝,也不需要等待CPU中斷來層層拷貝數(shù)據(jù)。這既降低了CPU在通信上的利用率,又減少了對CPU中斷的消耗。將CPU或者GPU的計算資源完全供給應用有助于應用性能的提升。此外,隨著網(wǎng)絡速度的提升,傳統(tǒng)的TCP通信對CPU在通信上消耗的資源也越來越多,這導致應用得不到足夠的CPU資源來運行。當數(shù)據(jù)中心規(guī)模達到一定程度時,可能會出現(xiàn)性能下降的現(xiàn)象,這也是為什么大規(guī)模數(shù)據(jù)中心都最先關注RDMA的原因之一。
在通信中,RDMA是如何做到不消耗CPU呢?在網(wǎng)絡傳輸層,IBTA規(guī)范首先做了嚴格的定義,即將傳輸層的各種操作都直接定義到了硬件實現(xiàn)上,例如將應用的message在發(fā)送端傳輸時的分割打包操作。由于應用的信息往往都很大(最大達到2 GB),網(wǎng)絡無法將一個這么大的信息直接傳出去,需要將它分割成多個小于網(wǎng)絡最大傳輸單元(MTU)的數(shù)據(jù)包,然后給每個數(shù)據(jù)包做Checksum和加header等。所有這些操作原來都是CPU在做,現(xiàn)在RDMA網(wǎng)卡可以直接將它們卸載過來,無須再依賴于CPU。同樣地,在接收端也可以將一系列反向操作以卸載到網(wǎng)卡的硬件上來。此外,IBTA還根據(jù)網(wǎng)絡面向數(shù)據(jù)或是面向連接等特性定義了不同的數(shù)據(jù)傳輸方式,如可靠連接(RC)、不可靠連接(UC)和不可靠數(shù)據(jù)報(UD)等。利用各種數(shù)據(jù)傳輸方式的特點,應用之間可以使用不同的RDMA通信方式,如rdma_send、rdma_write、rdma_read、rdma_atomic等,如圖2所示。
rdma_send是一種雙邊操作,需要在發(fā)送端和接收端都執(zhí)行后處理請求操作。當數(shù)據(jù)到達接收端時,需要向遠端服務器查詢數(shù)據(jù)的終點,這時可以使用RC、UC和UD來進行數(shù)據(jù)傳輸。
rdma_write、rdma_read和 rdma_atomic都是單邊操作。使用rdma_write時,遠端CPU在數(shù)據(jù)寫入的過程中不參與任何操作,可以使用RC或UC來傳輸;使用rdma_read時,在從遠端存儲中讀取數(shù)據(jù)的過程中不需要通知遠端CPU,可以使用RC來傳輸;rdma_atomic是rdma_read和rdma_write的組合操作,應用可以首先從遠端服務器中讀取數(shù)據(jù)、改寫數(shù)據(jù),然后再寫回遠端內存,中間不需要和遠端CPU有任何溝通,可以使用RC來傳輸。

▲圖1 RDMA和TCP的比較
通過在傳輸層的卸載,RDMA實現(xiàn)了應用之間的高效通信,但這同時給RDMA網(wǎng)絡的端到端連接帶來了挑戰(zhàn):如何能保障在數(shù)據(jù)傳輸?shù)倪^程中不會因網(wǎng)絡問題而導致數(shù)據(jù)的丟失。為了應對這一挑戰(zhàn),在InfiniBand網(wǎng)絡中,采用了基于credit的鏈路層流控機制。高性能的動態(tài)路由和擁塞控制機制有效地控制了網(wǎng)絡中的丟包問題。在以太網(wǎng)上,顯示擁塞通知(ECN)+擁塞通知包(CNP)和基于優(yōu)先級的流量控制(PFC)等機制被用于減少網(wǎng)絡中的丟包,但如何將以太網(wǎng)的流控做到像InfiniBand網(wǎng)絡那樣高效和可靠,還需要很長的路要走。
目前,基于以太網(wǎng)的RDMA主要標準為RoCE,包括RoCE V1和RoCE V2兩個版本。其中,RoCE V1主要是面向同一個以太網(wǎng)子網(wǎng)內的RDMA通信,使用較少,只在早些時候的計算和存儲應用中使用過;RoCE V2實現(xiàn)了RDMA協(xié)議在以太網(wǎng)上的跨子網(wǎng)通信,可以進行大規(guī)模部署和遠距離傳輸。目前主流的RoCE應用都是基于RoCE V2的,并且都是先將InfiniBand的完整數(shù)據(jù)包作為RoCE的Payload,然后再通過用戶數(shù)據(jù)報協(xié)議(UDP)header和傳統(tǒng)的以太網(wǎng)header對接,實現(xiàn)RDMA包在傳統(tǒng)以太網(wǎng)絡上的傳輸。
圖3給出了RoCE的數(shù)據(jù)格式。RoCE作為一種高效的以太網(wǎng)通信方式,可以應用在不同場景:(1)在無損(Lossless)以太網(wǎng)絡中,需要使能ECN、PFC和端到端服務質量(QoS),需要的配置雖然相對復雜,但是有助于提升網(wǎng)絡性能。(2)在有損(Lossy)以太網(wǎng)絡中,不使能PFC,可選使能ECN,配置簡單,但需要更先進的數(shù)據(jù)完整性控制機制[8-9]。

▲圖2 RDMA傳輸方式舉例

▲圖3 基于融合以太網(wǎng)的遠程直接內存訪問數(shù)據(jù)格式
RDMA和RoCE技術已經(jīng)被廣泛地應用于HPC、存儲、深度學習、機器學習、數(shù)據(jù)庫、大數(shù)據(jù)等應用場合中。與此同時,RDMA技術也為未來技術的發(fā)展帶來更加廣闊的研究空間,成為現(xiàn)代以數(shù)據(jù)為中心的系統(tǒng)架構的核心。
2 分布式AI訓練平臺的定制化硬件
如圖4所示,分布式AI訓練服務器采用定制化硬件設計。其中每個服務器節(jié)點由2個XEON CPU與8塊GPU模塊提供主要算力。該系統(tǒng)被分割成兩個通信域:節(jié)點內部通信和分布式節(jié)點間通信:
(1)節(jié)點內部通信。GPU間采用NVlink構成超立方體拓撲連接,可通過GPU Direct共享內存技術和NCCL通信原語,支持模型數(shù)據(jù)和暫存數(shù)據(jù)在HBM內存中進行低延遲交換和傳遞。GPU和CPU間、GPU和網(wǎng)卡(NIC)間可以通過PCIe 對等網(wǎng)絡(P2P)通信支持數(shù)據(jù)的直接內存訪問(DMA)搬移和共享。
(2)節(jié)點間通信。AI訓練平臺由大量的GPU服務器節(jié)點組成的分布式系統(tǒng)構成。分布式節(jié)點間通過RDMA低延遲Fabric網(wǎng)絡連接。分布式系統(tǒng)通信方式可以是MPI、NCCL或者遠程過程調用(RPC)通信,但一般采用效率更高的基于RDMA原生Verbs的通信原語庫。
3 分布式AI計算范式
分布式AI計算范式從計算類型上大致可分為兩種類型:模型并行和數(shù)據(jù)并行。
(1)模型并行。當模型比較大時,GPU自帶的HBM高帶寬內存難以全部容納放入,這時可以把模型數(shù)據(jù)按神經(jīng)網(wǎng)絡層次或者參數(shù)分區(qū)進行拆分,并分布到不同的GPU上進行獨立計算,然后再統(tǒng)一匯聚進行迭代。
(2)數(shù)據(jù)并行。不同GPU分配同樣的模型參數(shù),并將待訓練的迭代數(shù)據(jù)分批次加載到不同GPU進行訓練。不同批次數(shù)據(jù)訓練結果以某種規(guī)則合并迭代后完成訓練。
模型并行需要拆分模型參數(shù),因此,GPU間存在著較強的計算圖依賴性,往往難以彈性伸縮;而數(shù)據(jù)并行則要好得多,更適合大規(guī)模的分布式AI訓練。
在實際應用時,往往采用數(shù)據(jù)并行+模型并行的混合模式。大型模型參數(shù)可以先按照模型并行拆分形成獨立計算簇,再通過數(shù)據(jù)并行模型對計算簇進行并行化擴展。
在并行化方面,分布式AI平臺也存在兩種主流類型:參數(shù)服務器(PS)模型和環(huán)形拓撲模型。
如圖5所示,PS模型是當前重要的分布式AI訓練平臺計算范式。本質上,PS是一種類似于Hadoop分布式文件系統(tǒng)的半集中計算架構,采用了類似Map-Reduce的計算范式。其中,PS服務器和控制器起到中央調度器的作用,各個GPU節(jié)點充當任務對象并負責計算各自的梯度更新。PS服務器負載Broadcast模型參數(shù)給所有任務對象,并負責在PS服務器上匯聚所有梯度更新,以完成一個批次數(shù)據(jù)的迭代。顯而易見,PS服務器是整個系統(tǒng)的瓶頸點,并且高度依賴通信網(wǎng)絡的低延遲和高帶寬。
如圖6所示,環(huán)形分布式計算范式具有GPU節(jié)點邏輯成環(huán)的特點,沒有PS計算范式的聚合服務器半集中點。每個GPU 任務對象接收上個節(jié)點批次計算產(chǎn)生的梯度數(shù)據(jù)更新,并計算本節(jié)點的梯度再傳遞給下一個任務對象節(jié)點。從調度上看,環(huán)形計算充分利用了深度學習訓練過程反向傳播(BP)鏈式求導從后向前過程的特點:后級網(wǎng)絡層先計算,逐步推到前級網(wǎng)絡層。因此,梯度計算和梯度傳遞交替進行,這充分利用了通信帶寬和計算流水性。環(huán)形計算范式一般使用 Reduce-Scatter和 All-Gather MPI通信過程。
在分布式并行計算范式中,還同時存在著同步通信和異步通信的差異。傳統(tǒng)分布式系統(tǒng),例如大數(shù)據(jù)排序(Sorting操作),大多采用塊同步并行模型(BSP)同步通信,即在一次迭代中設置Barrier以等待系統(tǒng)最慢的節(jié)點完成此次計算。然而在神經(jīng)網(wǎng)絡和機器學習中,模型參數(shù)的更新具有一定魯棒性,因此,可以接受延遲同步并行計算模型(SSP)異步方式更新模型數(shù)據(jù)。在SSP模式下,允許計算快的節(jié)點領先最慢的節(jié)點若干個迭代步長,而不是僅僅等待慢節(jié)點追趕進度。

▲圖4 GPU服務器節(jié)點通信框圖

▲圖5 參數(shù)服務器計算范式
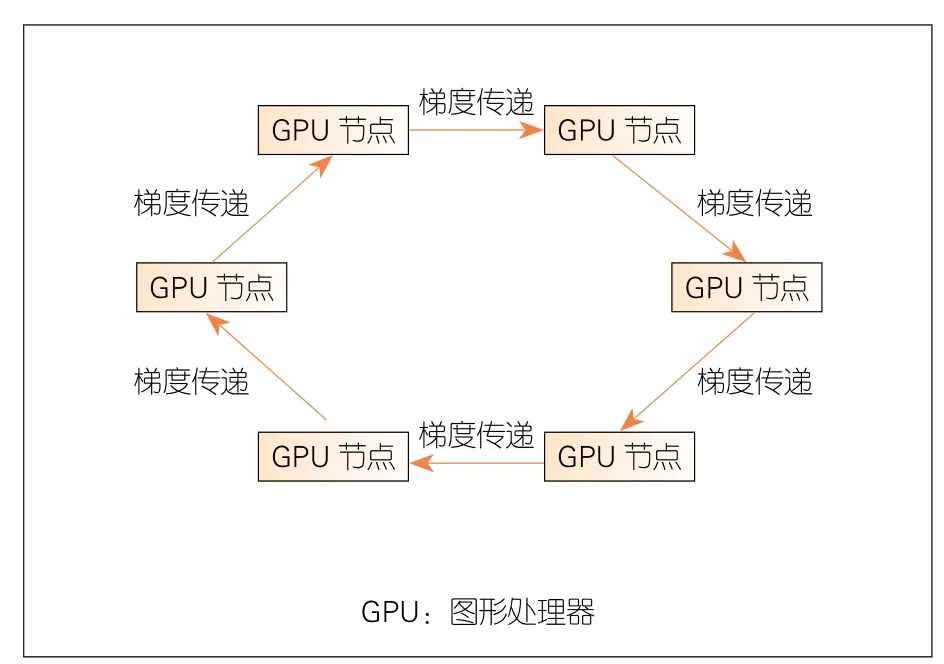
▲圖6 環(huán)形分布式計算范式
4 分布式AI中使用低延遲Fabric的一些問題
4.1 RDMA固有問題
如前文所述,RDMA是建立在旁路內核、通過硬件維護內存區(qū)和隊列管理獲取低延遲的低延遲Fabric技術,因此,RDMA會不可避免地存在以下問題:
(1)硬件低級別的通信原語過于抽象,導致現(xiàn)代數(shù)據(jù)中心應用軟件難以適配。一方面,低級別的通信庫和協(xié)議棧使得應用軟件需要關注硬件級別的buffer管理問題,因此,一般都需要在原生RDMA驅動和庫上進行一層封裝抽象,這導致RDMA性能不能充分發(fā)揮;另一方面,在現(xiàn)代數(shù)據(jù)中心云基礎設施里,網(wǎng)絡普遍通過軟件定義網(wǎng)絡(SDN)Overlay網(wǎng)絡和vSwitch框架實現(xiàn)虛擬化隔離和租戶安全,而原生RDMA技術在穿越隧道和分段網(wǎng)絡時,難以維持緩沖和隊列管理。因此,業(yè)內多妥協(xié)采用裸金屬物理服務器和原生網(wǎng)絡部署以換取原生RDMA性能。
(2)目前,RDMA技術緩沖資源管理是在網(wǎng)卡專用集成電路(ASIC)芯片內實現(xiàn)的,用戶態(tài)應用旁路內核直接操作網(wǎng)卡硬件。從商業(yè)角度看,CPU和NIC芯片分離、互相解耦有利于建立生態(tài)系統(tǒng),然而,無論是在資源保護和硬件性能可擴展性上,還是在應用間共享資源(零拷貝技術、fd.IO包向量處理技術)等方面,ASIC化的網(wǎng)卡都欠缺靈活性。
(3)基于以太網(wǎng)的RDMA技術有RoCE和iWarp,其中比較流行的是RoCE(V2版本)。如前文所述,在有損或無損以太網(wǎng)環(huán)境下,由于以太網(wǎng)Best-effort問題和組網(wǎng)部署特點,RoCE網(wǎng)絡存在著規(guī)模擴展性問題[10]。采用PFC流控技術顯得過于“粗暴”,并且在In-Cast和擁塞環(huán)境下,節(jié)點數(shù)目很難擴展到實用級別規(guī)模。采用數(shù)據(jù)中心量化擁塞通知(DCQCN)和TIMELY(Delay)等技術方案仍不能解決參數(shù)收斂慢、全系統(tǒng)調優(yōu)困難等規(guī)模擴展性問題。關于這一點,阿里巴巴高精度擁塞控制(HPCC)算法已給出詳細論述[11],此處不再贅述。
4.2 分布式AI中使用RDMA面臨的問題
現(xiàn)有深度學習框架極少直接基于RDMA技術開發(fā)網(wǎng)絡通信庫,通常都是通過Nvidia NCCL來間接使用RDMA, 例 如 TensorFlow、PyTorch、PaddlePaddle、MxNet等主流深度學習框架。這可能導致兩個潛在的問題:一方面,非Nvidia通用圖形處理器(GPGPU)的加速器廠商如果想要實現(xiàn)分布式深度學習訓練功能,就必須自己開發(fā)類似于Nvidia NCCL的通信庫來使用RDMA;另一方面,深度學習框架與底層通信庫相隔離,無法進行一體優(yōu)化[12-13]。
對于基于RDMA技術實現(xiàn)底層網(wǎng)絡通信,最主要的挑戰(zhàn)是內存管理。RDMA傳輸需要使用注冊內存(鎖頁內存),如果每一次網(wǎng)絡傳輸都根據(jù)傳輸量的實際需求當場申請并注冊,則會導致開銷顯著,還會增加網(wǎng)絡傳輸?shù)难舆t。如果提前申請并注冊好內存塊,則可能因無法準確預知程序運行時每次的實際傳輸需求而過多申請內存,這會造成內存資源的浪費。
針對這一問題,一般有如下幾個解決方法:(1)提前申請并注冊大塊內存,在實際傳輸時使用內存池技術,并從已注冊好的大塊內存上分配需要的內存;(2)提前申請并注冊一些固定大小的內存塊,每次在進行數(shù)據(jù)傳輸時,首先把需要傳輸?shù)臄?shù)據(jù)拷貝到這些已注冊內存塊上,然后再通過RDMA進行傳輸;(3)對于靜態(tài)結構的神經(jīng)網(wǎng)絡,每一次迭代網(wǎng)絡傳輸量是固定不變且可提前預知的,在系統(tǒng)運行前申請并注冊內存,然后重復使用這些注冊內存塊。
OneFlow軟件是目前唯一一個內部原生集成RDMA網(wǎng)絡傳輸功能的深度學習框架。用戶既可通過Nvidia NCCL使用RDMA傳輸,也可直接使用OneFlow基于RDMA自研網(wǎng)絡通信庫去實現(xiàn)分布式訓練。針對動態(tài)形狀和靜態(tài)形狀的網(wǎng)絡傳輸,可分別使用上文描述的第2、3種技術解決方案。動態(tài)形狀的網(wǎng)絡傳輸須引入一次額外的拷貝,而靜態(tài)形狀的網(wǎng)絡傳輸則實現(xiàn)了真正的零拷貝,達到了同時兼顧內存利用率和運行效率需求的目的。
OneFlow軟件還充分發(fā)揮了RDMA的優(yōu)點,采用Actor軟件機制實現(xiàn)了一個簡潔的去中心化調度系統(tǒng)框架。該軟件先在編譯階段生成靜態(tài)計算圖,然后生成包含Actor實例的分布式環(huán)境描述信息的計劃。分布式系統(tǒng)最終根據(jù)計劃生成Actor實例運行態(tài)(各Actor間的生產(chǎn)、消費數(shù)據(jù)會被存儲在Register中),通過RDMA低延遲網(wǎng)絡消息傳遞協(xié)作來完成計算流水。
5 中興通訊對低延遲Fabric技術的探索
中興通訊在智能網(wǎng)卡領域有較強的技術積累,相關技術已被廣泛使用在5G用戶面功能(UPF)下沉實現(xiàn)的低延遲2B業(yè)務、5G核心網(wǎng)L3虛擬專用網(wǎng)絡(VPN)IPsec加解密連接、數(shù)據(jù)中心輸入輸出(IO)虛擬化等各種產(chǎn)品應用和方案中。
智能網(wǎng)卡實現(xiàn)低延遲Fabric的優(yōu)勢包括:(1)比商用網(wǎng)卡更為強大的性能和資源保證,如更大的最長前綴匹配(LPM)精確匹配查找表和更快的三態(tài)內容尋址存儲器(TCAM)模糊匹配資源;(2)高度靈活性和可編程性,即根據(jù)應用需要調整數(shù)據(jù)流和資源抽象化;(3)軟硬協(xié)同一體化設計,如可與分布式AI框架協(xié)同優(yōu)化甚至定制;(4)模塊化,即利用已有模塊實現(xiàn)快速的系統(tǒng)集成;(5)基于現(xiàn)場可編程門陣列(FPGA)實現(xiàn)智能網(wǎng)卡,以便于未來實現(xiàn)批量芯片化。
基于智能網(wǎng)卡技術,中興通訊做了一些低延遲Fabric框架上的技術探索,以嘗試解決前文所述相關問題。首先,將RDMA網(wǎng)卡設備原型下沉進入FPGA,并基于VirtIO前后端技術實現(xiàn)了IO虛擬化。將VirtIO后端和vSwitch、Vxlan隧道端點(VTEP)卸載至FPGA中,以適配數(shù)據(jù)中心虛擬化網(wǎng)絡支持問題。其次,基于TCP減負引擎(ToE),將TCP狀態(tài)機下沉進入FPGA,以支持低延遲用戶態(tài)TCP協(xié)議棧(基于FStack原型)。此外,通過通信原語庫封裝抽象和智能網(wǎng)卡硬件先入先出(FIFO)橋接技術,對底層RDMA通信原語進行虛擬Socket封裝,可對應用實現(xiàn)近似伯克利套接字(BSD Socket)的封裝調用。
針對低延遲Fabric框架技術,中興通訊下一步的研究方向包括:
(1)基于P4框架實現(xiàn)網(wǎng)卡擁塞控制相關算法,通過增加帶內網(wǎng)絡遙測(INT)的遙測能力來減少對往返時延(RTT)和確認字符(ACK)丟失的依賴,并嘗試通過控制面獲取網(wǎng)絡轉發(fā)設備的Buffer水線信息,以獲得更精確的調度能力;
(2)除已支持對通信原語庫中的廣播機制進行硬件加速外,后續(xù)將在通信原語庫抽象化封裝中增加實現(xiàn)應用層感知接口,支持可配置選項(如帶寬、時延、突發(fā)、抖動、擁塞優(yōu)先級等參數(shù))提供給網(wǎng)卡設備層以配合控制算法實現(xiàn)網(wǎng)絡規(guī)模擴展;
(3)針對有損環(huán)境和偶發(fā)In-Cast丟包環(huán)境,通過采用類似低密度奇偶校驗碼(LDPC)、前向糾錯碼(FEC)等交叉交織冗余編碼算法,減少和平滑重傳所導致的網(wǎng)絡延遲問題;
(4)針對邊緣計算區(qū)塊鏈、聯(lián)邦學習等廣域分布式AI應用,對同態(tài)加密等強計算需求進行加速。
6 結束語
由于受限于智能網(wǎng)卡FPGA資源,低延時Fabric技術的相關探索仍停留在原型階段,離商用化還有不小的距離。謹以此文拋磚引玉,共同探索低延遲Fabric技術的落地。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
