基于雙向長短時記憶網絡的系統異常檢測方法
2020-12-14 10:22:04張林棟劉培玉
計算機應用與軟件 2020年12期
張林棟 魯 燃 劉培玉
(山東師范大學信息科學與工程學院 山東 濟南 250014)(山東省分布式計算機軟件新技術重點實驗室 山東 濟南 250014)
0 引 言
系統日志異常檢測是計算機系統必不可少的任務。系統日志記錄了系統狀態和不同臨界點上的事件,可以用來幫助技術人員調試機器性能和檢測系統故障等問題,也是檢測系統是否異常的重要數據。系統日志異常檢測最早開始于人工檢測,但是人工檢測僅限于日志數據較少的環境,很難應用于大數據的環境下。
Xu等[1]提出了一種統計分析的方法,捕獲單一類型消息的發生頻率來進行異常檢測,但是異常行為通常由復雜的若干個軟件組成,只進行單一類型的異常檢測是遠遠不夠的。Yamanishi等[2]提出了一種基于機器學習的方法來檢測日志消息之間的相關性,解決了基于統計分析方法中不能對復雜系統異常檢測的問題。但是隨著系統的變化,該方法并不能很好地適應新的日志模式。因此越來越多的學者開始利用神經網絡進行系統異常檢測。
Brown等[3]運用自然語言處理的知識,提出了一種基于遞歸神經網絡(RNN)語言模型,將注意力機制納入到RNN語言模型中。但是RNN所能存取的上下文信息范圍有限,由于其本身的激活函數,在模型訓練過程中會產生梯度消失和爆炸的問題,使得隱藏層的輸入對于網絡輸出的影響隨著網絡環路的不斷遞歸而衰退。為了克服RNN的缺點,Du等[4]提出了一種基于深度學習的系統日志異常檢測框架Deeplog,利用長短時記憶網絡(LSTM)對系統日志進行異常檢測。與基于機器學習的方法[5-7]相比,該方法克服了RNN網絡的不足,而且具有很高的準確率,但是由于LSTM網絡的結構特性,在進行異常檢測時只考慮了日志的前序事件對當前事件的影響而忽略了后序事件對當前事件的影響,使得結果很難具有說服性。
因此,本文提出基于雙向長短時記憶網絡的日志路徑異常檢測模型。該模型有效地彌補了LSTM的不足,充分考慮前后事件對當前事件的影響。與之前的方法相比,該模型在HDFS和OpenStack數據集上準確率和F-measure都有顯著的提高。
1 相關工作
1.1 遞歸神經網絡(RNN)
RNN[8]是最早應用在時序序列預測的算法之一,是唯一具有內部存儲器的神經網絡算法,能夠廣泛地適用于時間序列、語音、文本、財務數據、音頻、視頻、天氣等時序數據的處理。
RNN具有獨特的循環機制,因此能夠在輸入和輸出序列之間的映射過程中充分利用上下文相關信息,綜合考慮前序事件和后序事件對當前事件的影響。在RNN中,信息只在一個方向上移動。當它作出決定時,會考慮當前的輸入以及它從之前收到的輸入獲得想要的內容。但是RNN也存在著顯著的缺點,在訓練時會產生梯度爆炸等問題,并且RNN所能存取的上下文信息范圍非常有限,使得隱藏層的輸入對于網絡輸出的影響隨著網絡環路的不斷遞歸而衰退。
1.2 長短時記憶網絡(LSTM)
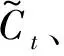
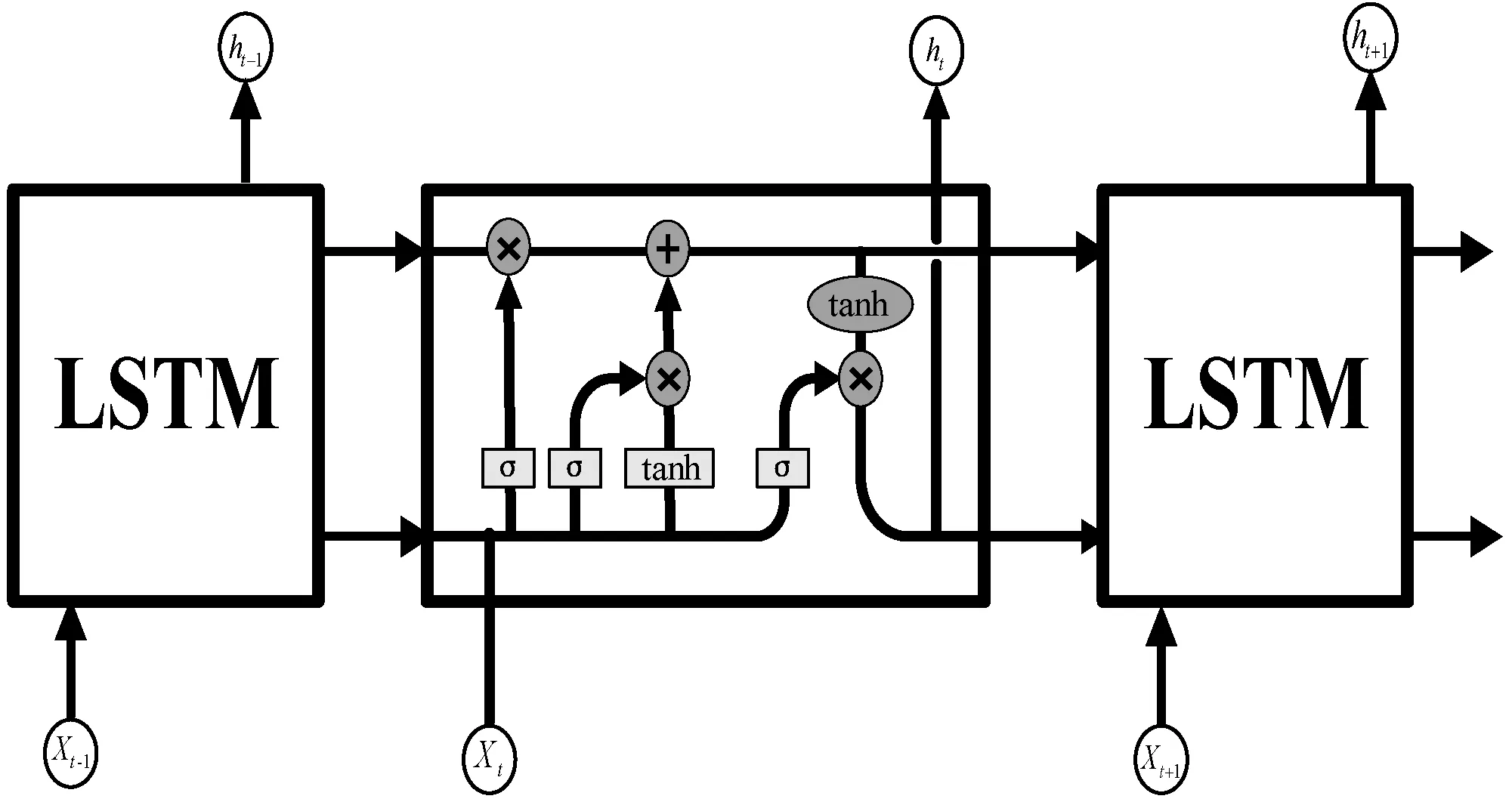
圖1 LSTM框架圖
1.3 雙向長短時記憶網絡(Bi-LSTM)
雙向長短時記憶網絡(Bi-LSTM)[10]模型如圖2所示,由前向傳播和后向傳播的LSTM網絡組成。該網絡結合了RNN和LSTM的優點,既克服了RNN衰退的問題,又能夠利用LSTM網絡的優勢,通過前向推算和后向推算,有效地結合前后事件對當前事件的影響。
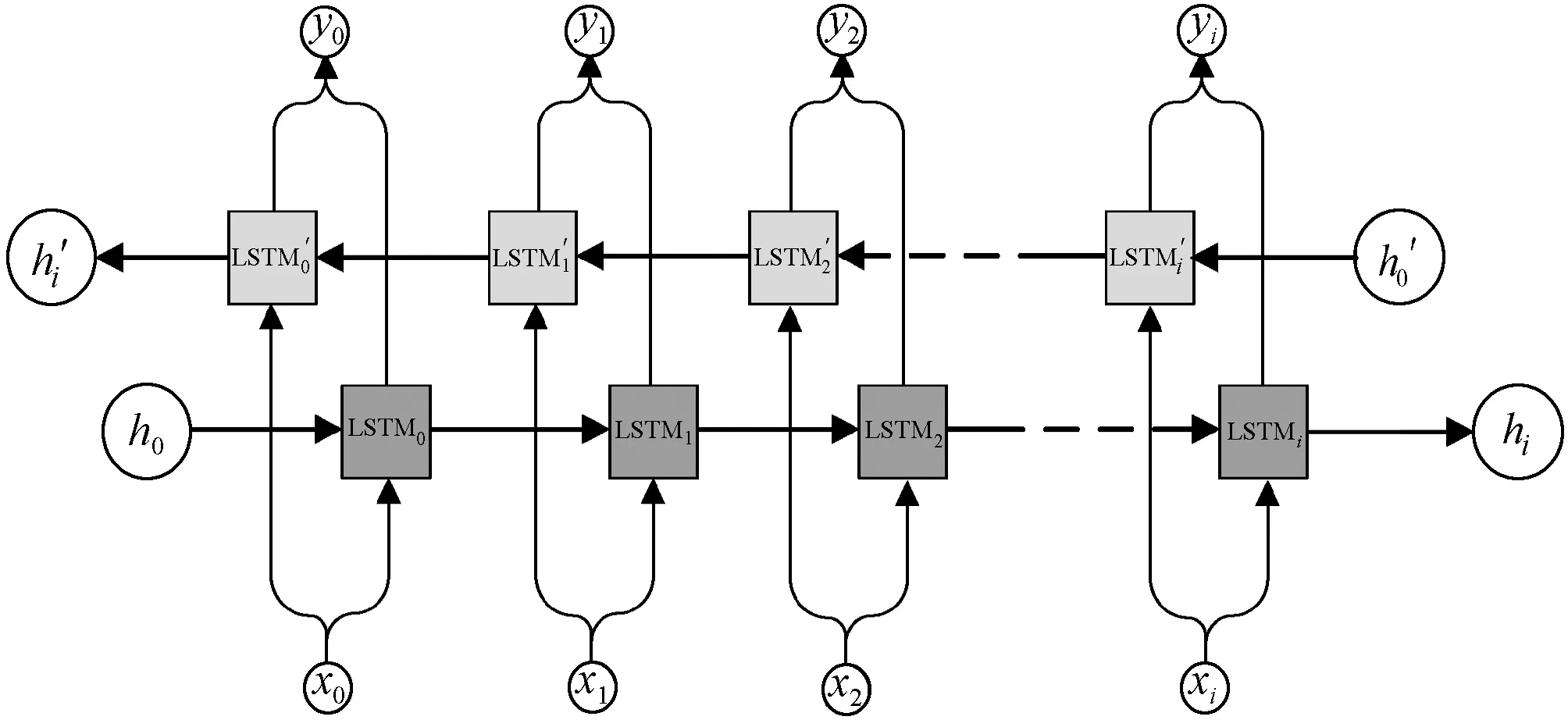
圖2 Bi-LSTM網絡模型
2 模型構建
2.1 異常檢測框架
日志路徑異常檢測的框架如圖3所示。首先把正常執行的日志文件通過日志解析器提取出對應的日志鍵,并將一系列日志鍵建模成為一個時間序列。其次通過Bi-LSTM模型進行訓練,使模型充分學習日志鍵序列執行模式。在進行檢測時,將新的日志文件使用日志解析器構造日志鍵序列,通過Bi-LSTM模型進行檢測。若未發現異常則模型將序列標記為正常;若檢測出異常,則將根據用戶的反饋來判斷是否發生誤判。如果發生誤判則通過在線更新優化模型參數的機制,再次通過模型進行異常檢測;如果沒有發生誤判,模型將輸出日志序列標記為異常。
圖3 日志路徑異常檢測框架圖
2.2 日志解析器
日志解析器[11-13]的目的是將結構不統一的日志數據進行歸一化處理。通過解析日志文件提取日志鍵構造時序序列的方法,將不同結構的日志數據轉化為具有相同格式時序化日志鍵序列。首先逐行讀取日志數據,每個日志行都使用一個簡單的正則表達式進行預處理。其次提取該日志的關鍵特征構造成一個日志鍵,并將每行解析的日志鍵構建成一個時序序列。例如,一個日志條目為“Adding an already existing block(10)”,則可以用一個日志鍵k1來代替它,即k1=Adding an already existing block(.*)。其中日志鍵中參數被抽象為*號。如表1所示,通過日志解析器的日志文件將被解析為一個時序序列,例如{k1,k2,…}。

表1 日志解析實例
2.3 日志路徑異常檢測
將通過日志解析器獲得的日志鍵序列進行系統日志異常檢測。假設K={k1,k2,…,kn}是一個日志塊所轉換的日志鍵序列,每一個日志鍵代表某一時刻日志執行的路徑命令,整個日志鍵序列反映了日志的順序執行路徑。對整個序列進行檢測,需要依次檢測每個日志鍵是否為異常。令ki為K序列n個中的某一個,代表著即將檢測的日志鍵。
如圖3所示,采用Bi-LSTM網絡來進行系統日志異常檢測,該網絡由前向LSTM和反向LSTM網絡組成,充分考慮了后序事件對前序事件的影響。輸入是幾個連續的日志鍵,輸出是下一個日志鍵ki的概率。ki的概率由前向傳播和反向傳播得到的概率共同決定的。前向或反向傳播都由一層LSTM網絡組成。每一塊LSTM都有隱藏狀態ht-i和細胞狀態Ct-i,兩者都被傳遞到下一個塊以初始化其狀態。目的是通過模型得出當前日志鍵ki的概率,然后設定一個概率界限(參數g)來判斷當前日志鍵是否發生了異常。通過各個門控的計算最終得出ki的條件概率,與通過訓練得出的g進行比較,把低于g的日志鍵標記為異常。
其前向傳播推算的公式為:
輸入門:
(1)
(2)
遺忘門:
(3)
(4)
輸出門:
(5)
(6)

反向傳播推算的公式為:
輸入門:
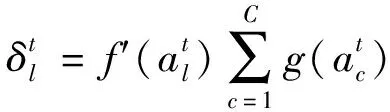
(7)
遺忘門:
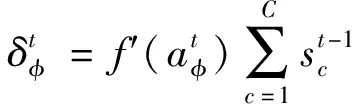
(8)
輸出門:
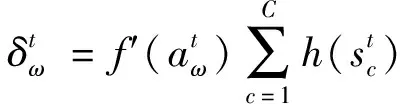
(9)
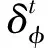
訓練階段:在訓練階段中使用正常執行的日志條目作為數據集來訓練模型,目的是讓模型充分學習到系統日志正常的執行模式,盡可能避免出現誤判的情形。通過日志解析器得到一個日志鍵序列,然后給定一個窗口大小h,將日志鍵按窗口的大小、執行順序組合成一個時序序列,該序列記為w,例如w={ki-h,ki-h+1,…,ki-1},將w輸入到模型Bi-LSTM網絡中。例如,假設一個日志鍵序列為{k11,k23,k5,k9,k12,k25,k3}。給定窗口大小h=4,則用于訓練模型的輸入序列和輸出標簽為:{k11,k23,k5,k9→k12},{k23,k5,k9,k12→k25},{k5,k9,k12,k25→k3}。通過Bi-LSTM模型得出下一日志鍵ki的條件概率,根據ki概率分布的范圍,設置g的參數大小。
檢測階段:基本方法跟訓練階段相同,對于新加入的日志條目首先通過日志解析器構造成日志鍵序列w。將w輸入到Bi-LSTM模型中得出當前日志鍵的條件概率,通過與設置的參數g進行對比,把高于設置的g值的ki標記為正常;若得到的ki概率值低于g值,那么模型將把該結果反饋給用戶,用戶判斷是否發生了誤判,如果發生了誤判,則通過在線更新機制調整模型參數,將得出的日志鍵與實際的日志鍵設為相同的概率,如果沒有發生誤判則直接將該序列標記為異常。
異常檢測模型如圖4所示。為了檢測一個新的日志鍵ki是正常還是異常的,把窗口大小為h的日志鍵序列w作為輸入,輸出是給定輸入日志鍵序列的下一個日志鍵ki的條件概率。通過將得出的條件概率Pr與參數g進行比較,判斷日志執行路徑是否發生了異常。
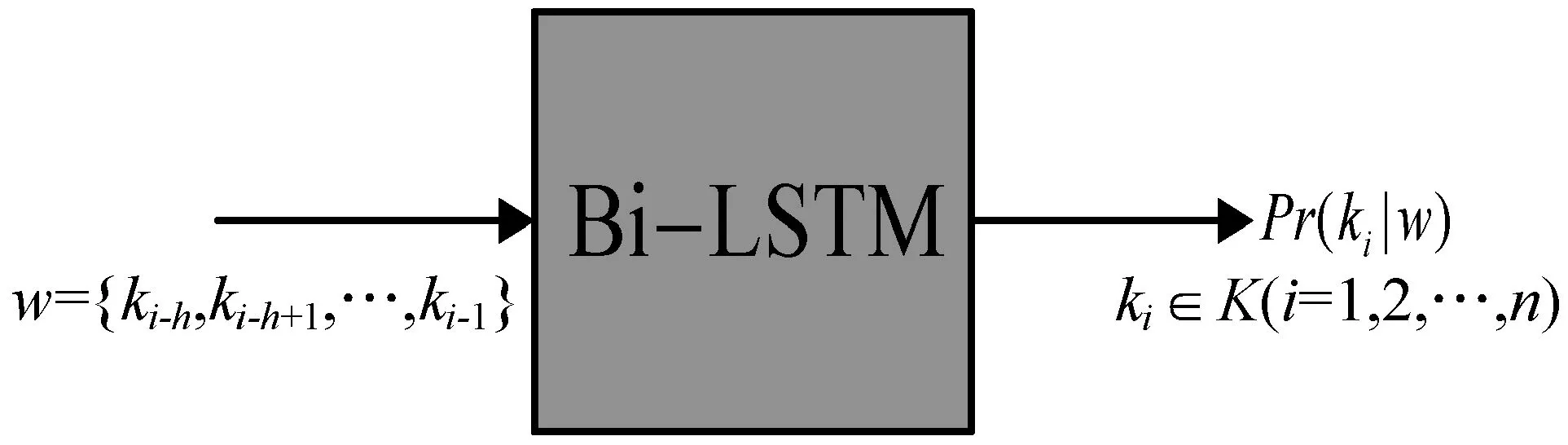
圖4 異常檢測模型圖
語言模型:把日志執行路徑作為時序序列處理,其原理是應用自然語言處理的語言模型。在訓練模型時,把每個日志鍵都可以看作是從詞匯表K中提取的一個單詞,應用自然語言處理的語言模型來計算該詞出現的概率,從而判斷系統是否發生異常。近年來,使用神經網絡的神經概率語言模型(NPLM)[14]已被證明在自然語言處理任務中非常有效。因此在Bi-LSTM中使用了NPLM語言模型來對日志鍵序列進行異常檢測。NPLM語言模型沿用了傳統的N-gram模型[15]中的思路,認為目標詞wt的條件概率與其之前的n-1個詞有關。但與N-gram模型區別是在計算P(wt|w1,w2,…,wt-1)時,其使用了機器學習的方法,很好地解決了給定一個日志鍵序列如何最大化地計算日志鍵ki概率的問題。NPLM語言模型的計算公式為:
p(w|context(w))=k(iw,Vcontext)
(10)
式中:k表示神經網絡;iw為w在詞匯表中的序號;context(w)為w的上下文;Vcontext為上下文構成的特征向量。
2.4 在線更新機制
如何保證檢測模型的時效性、如何解決日志新的執行模式等,是系統異常檢測必須要解決的問題,因此在模型中加入了用戶反饋在線更新的機制。隨著工作量以及工作方式的變化,用戶可以在線優化模型的參數。例如:檢測時可能會出現誤報的情況,假設一個窗口大小h=4日志鍵序列為{k22,k16,k5,k6},已知訓練后,模型已經將概率為1的下一個日志鍵預測是k7,而實際序列中的日志鍵是k3,那么模型將把k3標記為異常。如果用戶反饋這是誤報(實際情況下k7和k3都是正常的日志鍵),模型就可以根據用戶的反饋優化新的權重來學習這個新序列。當再次輸入該序列時,檢測到的k7和k3都將會得到相同的概率且被標記為正常。
3 實 驗
3.1 傳統異常檢測方法
主成分分析法(PCA)[16]是一種基于降維的統計方法。在進行異常檢測的時候,PCA根據每個日志事件的標識符進行分組,然后記錄每組中每個日志事件出現的次數。PCA的基本思想是將高維數據投影到由k個維度組成的新坐標系中,通過測量坐標系的子空間上的投影長度來檢測異常。因此,PCA可以保留原始高維數據的主要特征。
Xu等[17]首先將PCA應用在的異常檢測中。在Xu等的方法中,每個日志序列被轉化為日志事件的計數向量,使用PCA構造成兩個子空間,正常空間Sn和Sm異常空間。然后,計算事件計數向量y到Sm的投影,如果超過閾值,則對應的日志事件將被標記為異常。
Lou等[18]最先將不變量挖掘(IM)的方法應用到系統日志異常檢測中。IM根據日志參數之間的關系將日志消息進行分組,從日志消息組中自動地獲取程序不變量。程序不變量在系統運行期間始終保持線性關系,其輸入是從日志序列生成的事件計數矩陣,其中每一行是事件計數向量。首先,使用奇異值分解來估計不變空間的不變量r;其次,通過強力搜索算法找出不變量;最后,通過與設定的閾值進行比較來驗證挖掘的不變量。重復執行以上步驟,直至獲得r個獨立不變量。在檢測時,對新的日志序列進行判斷是否符合不變量,如果至少有一個不符合,則日志序列將被報告為異常。
3.2 數據集
實驗采用系統日志異常檢測中通用的權威數據集,一是Xu等[17]所公開的HDFS日志數據集,另一個是Du等[4]在Deeplog中公開的OpenStack數據集。
HDFS數據集是基于PCA的主要數據集,并在在線PCA和基于IM的異常檢測方法中廣泛應用。該數據集包含了11 197 954個日志條目,其中約3%是異常的。通過標識符字段將日志條目分組到不同會話中,HDFS的標識符為block_id,每組會話對應著一個日志塊。
OpenStack數據集包含1 333 318個日志條目,約7%是異常的。主要的進程包括VM的創建/刪除、停止/啟動、暫停/恢復等。OpenStack數據集的標識符為instance_id。分別將每個日志條目通過解析器轉化為日志鍵,然后通過Bi-LSTM網絡來訓練其權重,進行異常檢測。
3.3 實驗評估標準
為了評估模型的有效性,本文采用Precision(召回率)、Recall(準確率)和F-measure作為評價標準。Precision為所有檢測到的異常與真正異常的百分比[19]。Recall反映了被正確判定的正常樣本占總的正常樣本的百分比。設置參數g決定了得到下一日志鍵概率判斷為異常的最低概率值。F-measure的值同時受到Precision、Recall的影響。設置默認輸入窗口h的大小為10,一個LSTM網絡塊的存儲單元α的個數為64。為了檢測模型的性能,做了三組對比實驗:首先比較該模型與之前的基于機器學習的方法的性能;其次通過調整參數g、h、α、Pr的大小來對模型參數進行實驗分析;最后進行模型有在線更新機制與無在線更新機制的對比實驗。
(11)
(12)
(13)
式中:TP為將正常樣本預測為正常類數;FN為將正常樣本預測為異常類數;FP為將異常樣本預測為正常類數;TN為將異常樣本預測為異常類數。
表2為HDFS數據上每種方法的假陽性和假陰性的數目。PCA實現了最少的假陽性,但是具有很高的假陰性。IM假陽性和假陰性都很高;Bi-LSTM的假陰性和假陽性都具有較低的水平。
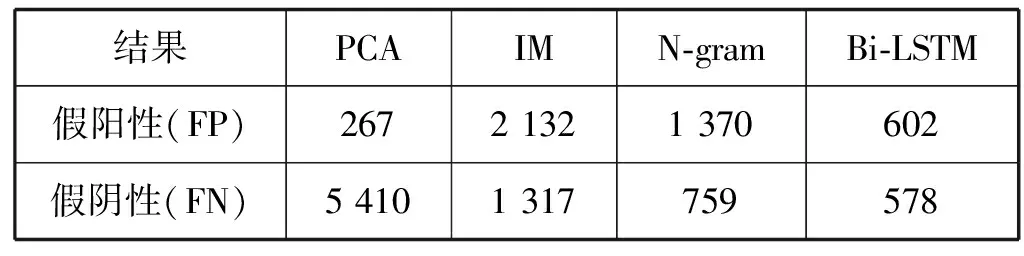
表2 HDFS數據集FP和FN的數量
3.4 結果分析
3.4.1方法對比分析
圖5和圖6分別為HDFS和OpenStack數據集上不同方法對比實驗結果。雖然傳統的PCA在HDFS數據集上的準確率為0.98,但是F-measure值僅有0.79,OpenStack數據集上也并未表現出突出的性能。而IM盡管在HDFS數據集上表現出良好的性能,而在OpenStack數據集上準確率和F-measure分別為0.02和0.04。由此可以得出:傳統的基于機器學習的檢測方法并不具有很好的適用性,不能有效地應用到不同系統之間的異常檢測。使用LSTM的檢測方法的Deeplog模型準確率和F-measure都高達0.95以上。基于Bi-LSTM的方法在兩個數據集上都表現出良好的性能,準確率和F-measure分別為0.98和0.98。這是由于Bi-LSTM綜合考慮前后事件對當前事件的影響,因此實驗結果高于Deeplog模型。通過對比實驗可以得出:Bi-LSTM模型不僅能夠適用于隨機生成的數據集而且在大規模的數據上也表現出優越的性能,能夠適用于不同系統日志路徑的異常檢測。

圖5 HDFS數據集性能對比結果圖
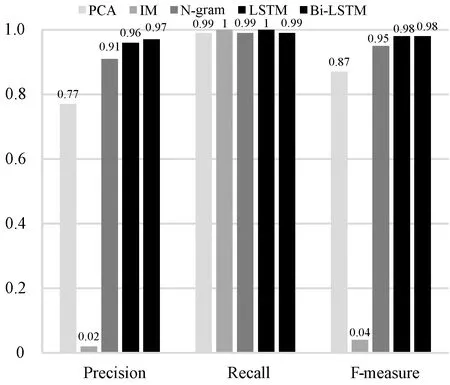
圖6 OpenStack數據集性能對比結果圖
3.4.2Bi-LSTM模型參數分析
通過調整Bi-LSTM網絡中各種參數來測試模型的性能,其中調整的參數包括:g,h,α,Pr。在每個實驗中只改變一個參數的值,其余參數保持默認值。圖7為改變參數α,其他參數不變的情況下的模型性能隨著LSTM單元個數的變化趨勢,實驗表明當內存單元數為192時,模型的準確率和F-measure都明顯優于其他內存單元數。圖8反映了改變參數g后模型的性能變化,當設置的g閾值偏低時,雖然模型具有很高的準確率但是其F-measure卻很低。圖9為改變參數h模型的性能變化,由于LSTM網絡需要長依賴性,所以當選擇的窗口越大時,其表現的性能越明顯。圖10反映了改變參數Pr后模型的性能變化,Pr的大小決定著前向推算和后向推算各自對預測的概率所占的比重。綜合所有的實驗結果,發現Bi-LSTM網絡的性能在調整各個參數時表現得非常穩定,單一改變參數或者是組合調整對模型的性能影響不大。
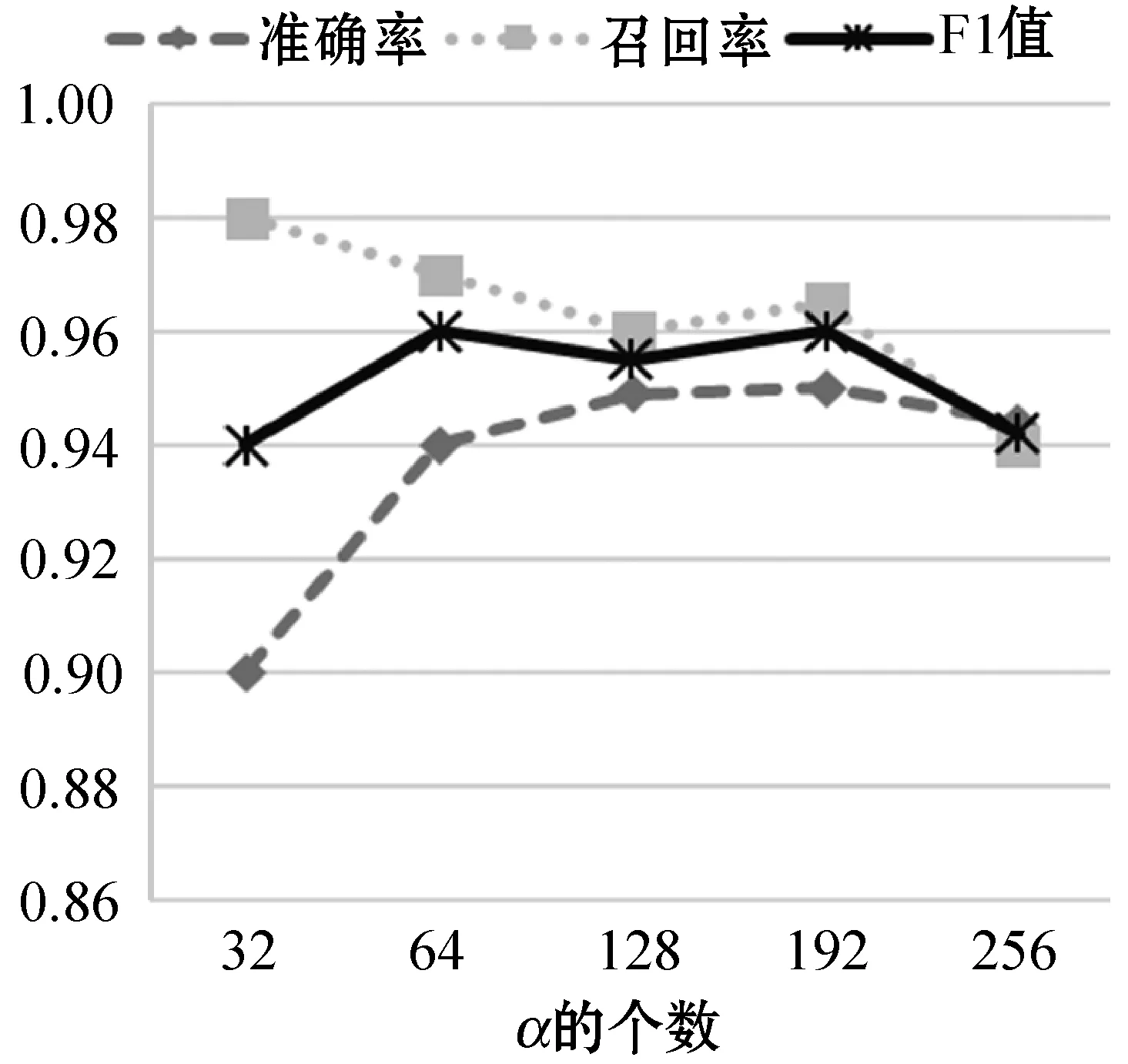
圖7 改變參數α性能對比結果圖
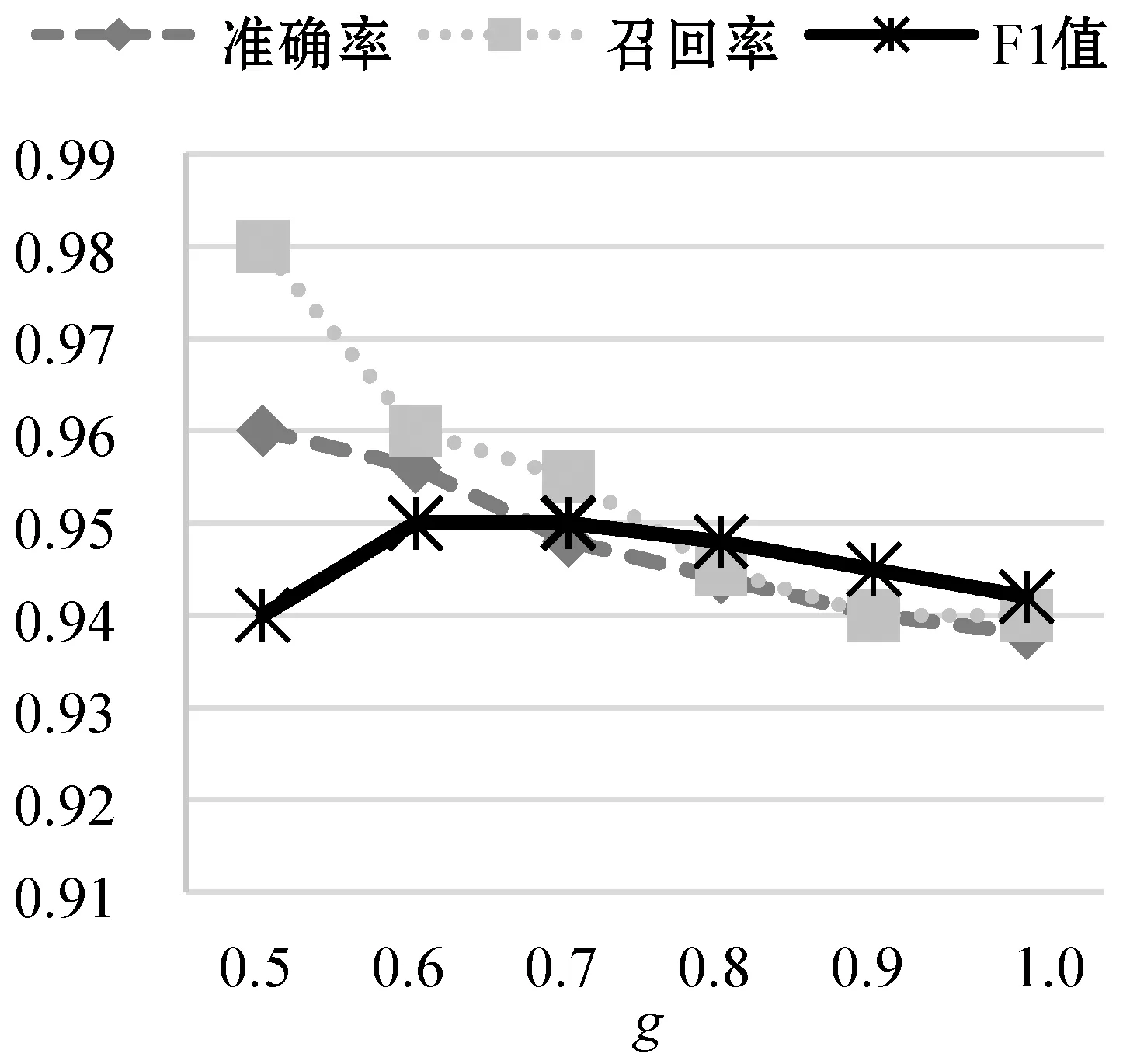
圖8 改變參數g性能對比結果圖
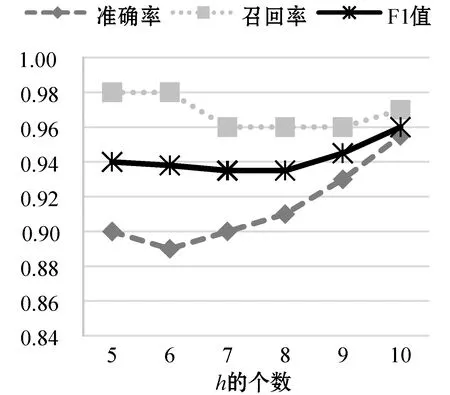
圖9 改變參數h性能對比結果圖
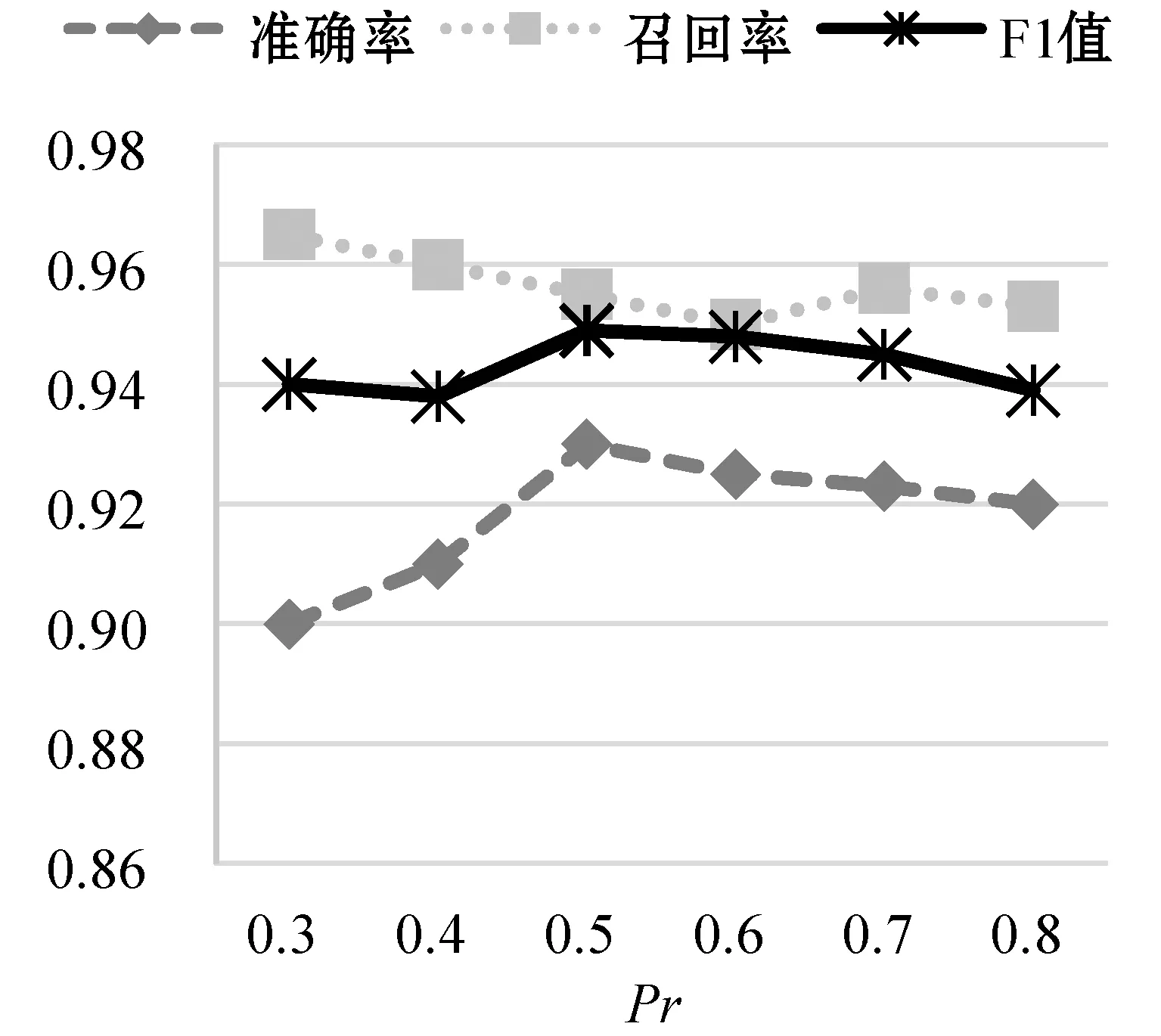
圖10 改變參數Pr性能對比結果圖
3.4.3在線更新對模型性能的分析
在HDFS和OpenStack兩個數據集中,許多日志鍵僅在特定時間段內出現,因此訓練數據集可能不包含所有正常日志鍵,具有很好的未知性。首先,用數據集的前10%作為訓練數據,其余的作為測試數據。然后,設置各個參數α=64、g=0.8、h=10、Pr=0.5,并保證參數不改變。對于有在線更新的模型,假設有用戶報告檢測到的異常為誤報,Bi-LSTM使用該標記來更新其模型以學習這種新模式。圖11是模型在HDFS數據集下的性能,無在線更新的模型準確率僅為0.30,F-measure為0.46,而有在線更新的模型準確率和F-measure分別為0.90和0.95。圖12是模型在OpenStack數據集下的性能,無在線更新的模型準確率僅為0.35,F-measure為0.52,而有在線更新的模型準確率和F-measure分別為0.93和0.96。結果表明,有在線更新的異常檢測模型在準確率和F-measure都明顯高于無在線更新模型,在線更新的機制可以提高模型在檢測新執行模式時的性能。
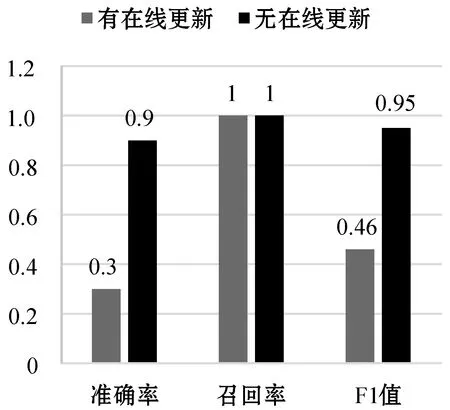
圖11 HDFS數據集有無在線更新性能比較圖
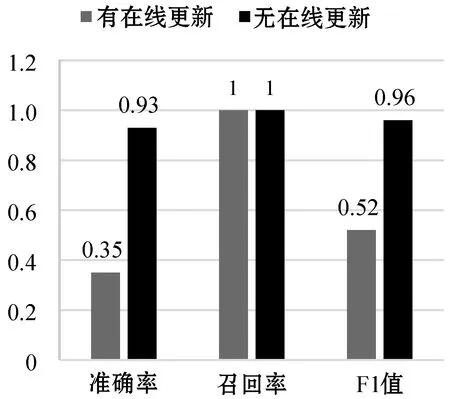
圖12 OpenStack數據集有無在線更新性能比較圖
4 結 語
本文提出一種基于雙向長短時記憶網絡的系統異常檢測模型。首先在每個日志條目的級別上,通過日志解析器實現從日志文件中分離出不同類別的任務,從而構成時序化的日志鍵序列,有效地解決傳統異常檢測方法中日志結構不統一的問題。其次使用雙向長短時記憶網絡對時序化的日志序列進行建模和預測,并且增加在線更新優化模型參數的機制,提高模型檢測新執行模式的性能。實驗結果表明,與傳統的基于機器學習異常檢測的方法相比,本文模型在HDFS和OpenStack數據集上準確率分別提升了0.11和0.2,召回率提升了0.29,F-measure分別提升了0.19和0.11。基于雙向長短時記憶網絡的系統異常檢測模型在系統日志異常檢測上具有顯著的性能,對系統異常檢測和優化模型參數等方面具有重要的意義。
在未來工作中,將改進模型使其不僅能適用于系統日志執行模式的異常檢測,還能夠對日志中的各個參數進行異常檢測。同時改進模型的輸出最大化概率的最優路徑來提升模型的效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
