英漢雙語者二語口語產生中音韻編碼過程的同化機制*
2020-12-15 08:32:42蘭天一張清芳
心理學報 2020年12期
關鍵詞:效應
辛 昕 蘭天一 張清芳
(中國人民大學心理學系,北京 100872)
1 前言
雙語者指掌握并能使用兩種語言的個體(Fabbro,1999)。雙語者的第二語言加工過程是否會受到母語的影響,是研究者們重點關注的問題之一。Perfetti 等(2007)根據雙語者母語和第二語言加工的神經機制是否相同,提出了有關二語加工模式的同化與順應假設(assimilation and accommodation hypothesis),認為二語加工過程中存在同化和順應兩種不同的機制。同化機制指雙語者采用母語策略(overlapping system)加工二語,被試表現為二語加工和加工母語的神經模式類似; 順應機制指雙語者采用二語的加工系統(additional system)加工二語,表現為二語加工與二語這門語言為母語時的加工模式類似。
1.1 雙語加工中的同化與順應機制
雙語者加工二語時表現出同化還是順應機制,所比較的對象是兩種語言作為母語時的認知神經機制。研究發現,語言的正字法透明度影響了母語者語言加工的腦激活模式。正字法透明度指的是從字素到音素的形音匹配程度的規則性(Liberman et al.,1980)。正字法透明度高指語言中的一個字素與一個音素匹配(如意大利語),正字法透明度低指語言中一個字素與多個音素匹配,或者是一個音素對應多個字素(如英語)(Katz & Frost,1992)。研究發現在閱讀和命名任務中,意大利母語者比英語母語者更多的激活左側顳頂區,該區域主要涉及音素加工。英語母語者則表現出更多的激活于左側后顳下回和左側額下前回,而該區域主要涉及詞匯檢索(Paulesu et al.,2000)。
雙語者加工二語的腦激活模式是與自己的母語相似還是與二語(作為母語時)類似,這與兩種語言正字法透明度的相對高低有密切關系。印地語的正字法透明度高于英語,Das 等(2011)發現印地語-英語雙語者在印地語閱讀過程中左側頂下小葉表現出更高的激活,而在英語閱讀中左側顳下回的激活程度更高。Jamal 等(2012)在西班牙語-英語雙語者(前者的正字法透明度高于后者) 研究中發現,當被試閱讀西班牙詞匯時左側顳中回和顳上溝的激活更強,這兩個腦區涉及語義加工,在閱讀英語詞匯時左側額中回和額上回的激活更強,這兩個腦區在語音加工中起著重要作用。Nelson 等(2009)在英語-漢語雙語者(英語的正字法透明度高于漢語)研究中發現,被試在閱讀英語詞匯時激活了大量的左側梭狀回區域,這一區域可能涉及語義加工,但在閱讀漢語時則發現了雙側梭狀回區域的激活。Liu 和Cao (2016)采用元分析發現在雙語加工中,如果雙語者的二語比一語的正字法透明度高,則更多激活了雙側聽覺區和中央前區,這些區域主要負責視聽感覺和語音編碼,表明雙語者加工二語時采用了同化機制。如果一語比二語正字法的透明度高,則更多激活了左前額葉區域,表明對二語的形音匹配加工需要付出更大的努力,說明雙語者加工二語時采用了順應機制。
盡管如此,雙語者二語語音加工任務中有關同化與順應機制的研究結論并不一致。采用雙耳分聽聲調判斷任務,Wang 等(2001)發現具有聲調經驗的漢語被試在漢語任務中表現出左腦優勢,而無聲調經驗的英語被試則表現出雙側激活的模式。在后續的訓練任務中,Wang 等(2003)進一步要求英語母語者學習漢語的聲調,結果發現左側顳上回顯著激活,且激活水平與聲調學習成績正相關。研究者推測英語母語者采用漢語模式加工漢語,采用了順應機制。與此結果不同,Tian 等(2019)考察了母語為英語或印度尼西亞語,第二語言為漢語的被試在出聲閱讀中形音規則加工過程的神經基礎。漢字形音規則指漢字的發音是否與聲旁發音相同,相同為規則漢字,不同則為不規則漢字。結果發現,雙語者在命名規則漢字的條件下,激活了左側輔助運動區以及左側中央前回,而漢語母語者則激活了與正字法加工相關的左側額下回。根據這一結果,Tian 等(2019)認為雙語者是利用音素相關區域和運動區域促進規則漢字的語音加工,表明第二語言為漢語的雙語者使用了同化機制加工漢字語音。
同化與順應機制并不是非此即彼的,有研究比較腦區激活的模式發現雙語者的二語加工過程同時采用了同化與順應機制。Zhao 等(2012)采用不出聲命名任務,發現在漢語加工任務中英漢雙語者比漢語母語者的雙側枕葉激活更強,表明雙語者對漢字進行視覺詞形分析,采用了順應機制加工漢語。不同的是漢語被試的左側頂下小葉表現出更多背側區域的激活,而英漢雙語被試在漢語任務中左側頂下小葉表現出更多腹側區域的激活。已有研究發現左側頂下小葉背側的激活與語音存儲有關,而腹側化與精確的字素-音素轉換加工(graphemephoneme route)有關(Tan et al.,2010)。研究者認為雙語者的腹側激活表明人們把不規則漢字的學習看作是部件-發音對應(Radical-Sound)的規則,類似于英語字素-音素的習得策略。加工策略上的相似性表明英漢雙語者采用同化機制加工漢語,二語加工中同時存在同化與順應機制。
近期有一些研究者采用高時間分辨率的事件相關電位(event-related potential,ERP)技術比較了雙語者加工二語的時間進程模式。Timmer 和Shiller(2012)采用出聲閱讀任務,通過啟動范式設置啟動詞和目標詞之間的正字法-語音相關條件。發現荷蘭語-英語雙語者和英語母語者腦電模式基本相似,雙語者和英語母語者都在120~180 ms 發現了正字法效應,180~280 ms 發現了語音效應。因此,這一結果表明荷蘭語-英語雙語者在二語加工時表現出了與英語母語類似的加工模式,支持了順應的觀點。王星星(2013)采用圖片命名和語義判斷任務考察了藏漢雙語者漢語產生的語音效應。結果發現,藏漢雙語者在漢語字詞口語產生過程中信息激活的時間進程為形-音-義,且在時間上存在重疊。研究者認為藏漢雙語者的漢語產生特征與藏語母語相似,表明漢語作為二語的產生受到了母語背景的影響,表現出母語同化的認知機制。
綜上,已有雙語者二語加工的研究主要是采用功能磁共振成像(functional magnetic resonance imaging,fMRI) 技術從認知神經的層面上對此問題進行考察,研究主要發現是二語加工中采用同化抑或是順應機制受到母語和第二語言特點的影響。很少有研究關注雙語者二語詞匯產生過程中的加工機制,而詞匯產生是從概念通達開始,最后輸出語音或者文字的過程,其加工過程與詞匯理解不同(陳寶國 等,2006; Ferrand et al.,1996; 張清芳,楊玉芳,2005)。本研究是從詞匯產生過程的角度來考察雙語者二語加工的認知神經機制。
1.2 口語詞匯產生中音韻編碼的單元
口語產生過程包含了概念準備、詞條選擇、音韻編碼、語音編碼和發聲5 個主要階段(Dell,1986;Levelt et al.,1999)。在音韻編碼過程,講話者根據詞素選擇音段和節律結構,并進行音節化(syllabification),將音段與節律結構中的音節節點聯系起來。在語音編碼過程選擇音節程序節點為發音做好準備。音韻編碼的加工單元一直是言語產生研究的爭論焦點之一。
在印歐語言的口語產生中,大多數研究支持音素是音韻編碼的加工單元。在英語語誤中,絕大部分的語音片段插入、遺漏、替代或者置換等錯誤都來源于音素的變換(例如york library→lork yibrary,reading list→leading rist),而較少發現音節變換導致的言語錯誤(例如napkin→kinnap)(Dell,1986)。采用圖畫-詞匯干擾任務(Damian & Martin,1999;Meyer & Schriefers,1991)、掩蔽啟動范式(Forster &Davis,1991; Kinoshita & Woollams,2002; Malouf &Kinoshita,2007; Schiller,2008)和內隱啟動范式(Damian & Bowers,2003),研究者發現與音素不同相比,音素相同時都會產生顯著的反應時加快,表明音素是音韻編碼的單元。
研究者對漢語口語詞匯產生的音韻編碼過程中音節和音素的作用存在不同看法。漢語作為一種聲調語言與字母語言存在很大的不同。首先,相比英語、荷蘭語,漢語的音節數量很少,不計聲調有400 個音節左右,計聲調也只有1200 個左右,而荷蘭語中大約有12000 個音節(Levelt et al.,1999; 張清芳,楊玉芳,2005)。其次,漢語中的音節邊界十分清晰,不存在重新音節化現象,而在拼音語言的口語產生中,會出現大量跨越音節邊界重新組合成音節的現象。根據Levelt 等(1999)的觀點,重新音節化現象是心理詞典中不存儲音節的主要原因,而在漢語中更為經濟的方式是將所有音節存儲起來,并在音韻編碼過程中直接提取。因此漢語的語音特點決定了漢語的主要音韻編碼單元更可能是音節,而非音素。
語誤分析發現在漢語中只有極少量的音素錯誤,大部分語誤都是音節和韻導致的出錯(Chen,2000)。Chen 等(2002)采用內隱啟動范式探索漢語雙音節詞匯產生中的音韻編碼階段,發現了音節相同條件下的啟動效應,但音素相同條件下無任何效應,張清芳和楊玉芳(2005)利用圖畫詞匯干擾范式,Chen 等(2003)以及Chen (2016)采用掩蔽啟動范式發現了相似的結果,這表明無聲調的音節在音韻水平上能作為一個獨立的計劃單元。You 等(2012)利用圖畫命名和單詞命名兩種任務均發現了音節啟動效應,為漢語口語中音節是音韻編碼單元提供了更強的證據。岳源和張清芳(2015)采用圖畫-詞匯干擾范式,通過比較即時命名、延遲命名以及延遲命名與發音抑制任務的結合,考察了漢語口語產生中音節和音段(segments)1音段(segmental units)在漢語中指的是亞音節語音表征單元(sub-syllabic units) (Bakovic,2014)。例如,對于一個CVG (G 表示glide) 結構的漢語音節/qing/,可以劃分為兩個音段,首CV結構的/qi/和尾音段VG 結構的/ing/(多個音素結合形成的一個單元,其音素個數少于音節)在單詞形式編碼的不同階段所產生的效應,結果表明音節的促進效應發生在音韻編碼階段,證明了音節是音韻編碼過程的合適單元,音段可能在隨后的語音編碼階段起作用。Roelofs (2015)認為漢語產生音韻編碼階段是先提取音節再分解為較小單元的音素(或者音段),最終在語音編碼階段按照運動指令組合發音。
與上述結果不同,有些研究發現了粵語口語產生中音段的促進效應。Wong 和Chen (2008,2009)采用圖畫-詞匯干擾范式,在粵語中發現當干擾詞與目標詞的韻母和聲調相同時,圖畫命名顯著快于無關條件,因此他們認為粵語口語產生中的主要音韻編碼單元可能是音段(同見Wong et al.,2012)。最近Wang 及其同事的研究同樣發現了音段促進效應,但更重要的是發現音節是在音段提取之前加工,支持音節是粵語口語產生中的音韻編碼單元(Wang,Wong & Chen,2017; Wong et al.,2018)。Wong 等(2012)選取的粵語被試是來自香港的大學生,具有較高的英語水平,研究者認為對于英語這種字母語言的過早暴露,可能是導致被試的粵語加工模式更接近英語母語的原因,從而能夠更加敏感的操作亞音節水平作為音韻編碼的計劃單元。
也有事件相關電位的研究發現了音素效應。Qu等(2012)采用音素重復任務(如首音素重復的“黃盒子”和首音素不重復的“綠盒子”),在圖畫呈現后的200~300 ms 之間發現了首音素重復效應,表明音素信息在音韻編碼階段也會被激活(同見Yu et al.,2014)。O’Seaghdha 等(2013)等指出Qu 等發現的ERP 波形的差異可能僅僅反映了顏色詞和目標詞在首音素相同時的聯結,并不能表明音素是音韻編碼的單元。Wang,Wong,Wang 等(2017)的研究在關鍵試次中先后呈現兩幅圖片,兩幅圖片存在音節相關、音段相關或無關關系。要求被試在看到第一幅圖片和第二幅圖片(目標圖)時均先不要命名,當提示線索出現時才對圖片進行口語命名(即延遲命名任務)。研究在目標圖畫呈現后的200~400 ms 與400~600 ms 發現了音節相關效應,卻未發現任何音段相關效應。Zhang 和Damian (2019)采用掩蔽啟動范式,首次在漢語普通話的口語詞匯產生過程中同時探測到了音節效應(300~400 ms)和音段效應(500~600 ms),基于元分析中各個階段對應的時間進程(Indefrey,2011),研究者認為這兩個效應可能分別發生在音韻編碼階段和語音編碼階段,表明漢語口語音韻編碼的單元可能是音節而不是音素(類似的加工模式見Cai et al.,2020; Feng et al.,2019;張清芳,王雪嬌,2020)。
1.3 英漢雙語者漢語口語詞匯產生中的音韻編碼單元
綜上,多數研究者認為漢語口語詞匯產生中音韻編碼過程最先激活的單元是音節。與此同時,研究發現雙語者的音韻編碼過程會受到雙語者語言的影響,尤其是第一語言的經驗可能對第二語言的加工過程產生影響(Qu et al.,2012; Wang,Wong,&Chen,2017; Wong et al.,2018; Verdonschot et al.,2013; Nakayama et al.,2016)。Verdonschot 等(2013)選取熟練英漢雙語者完成英語和漢語兩種語言的啟動任務,發現了漢語任務中的啟動詞與目標詞音節結構相同時的首音素啟動效應,表明母語可能影響了二語的加工過程。Nakayama 等(2016)選取二語熟練度不同的日英雙語者,在掩蔽啟動范式下要求被試出聲朗讀英語單詞。啟動詞和目標詞只有起始音素重疊(e.g.,bark-BENCH),或者輔音元音(CV)重疊為日語中的莫拉單元(e.g.,bell-BENCH)。結果發現低熟練度的日英雙語者表現出CV 啟動效應,但未發現音素啟動效應,即他們產生第二語言英語詞匯時使用音節為音韻編碼單元,這可能是由于第一語言日語中的音韻編碼單元對第二語言的音韻編碼單元造成影響,雙語者音韻編碼的單元受到了二語水平的調節。
現有關于漢語口語詞匯產生中音韻編碼單元的研究僅關注了漢語作為母語的加工過程,而對于漢語作為第二語言產生時這一過程的認知機制尚未有研究進行探索。在二語習得認知神經機制的研究中,主要關注了漢語作為第二語言時的詞匯理解過程(Timmer & Shiller,2012; Liu & Cao,2016;Zhao et al.,2012),通過比較腦區激活模式的相似性考察二語理解的同化與順應機制,從詞匯產生過程角度進行探索的研究很少。而且,已有有關同化與順應機制的研究多采用fMRI 技術比較腦區激活模式,很少有研究從時間進程的模式上進行考察。
本研究采用圖畫詞匯干擾范式,利用事件相關電位技術,考察漢語作為第二語言時的音韻編碼單元及其時間進程。實驗中選取了兩組被試,包括母語為字母語言的英漢雙語者和漢語普通話為母語的中國被試,變化干擾詞與目標圖片名稱的關系,包括音節相關、音素相關和無關三種條件。與漢語相比,英語的形音匹配規則較為一致,正字法透明度較高; 而漢語中字形與語音之間的匹配是不透明的,兩類語言形成了較為鮮明的對比。另一方面,已有研究一致地表明英語和漢語的音韻編碼分別為音素(Damian & Bowers,2003; Schiller,2008)和音節(Feng et al.,2019; Zhang & Damian,2019),采用這兩種語言可以考察母語對第二語言音韻編碼單元的影響。實驗中要求英漢雙語者完成英語和漢語口語詞匯產生任務,漢語被試僅完成漢語口語詞匯產生任務。我們通過比較漢語作為二語產生時的行為模式和腦電模式(詳見數據分析部分)類似于漢語母語者還是英語母語者考察詞匯產生過程的同化與順應機制。如果英漢雙語者的漢語詞匯產生模式與漢語母語者的模式更為相似,則支持順應機制,如果與英語的詞匯產生模式更為相似,則支持同化機制。
2 方法
2.1 被試
漢語母語被試22 人(13 名男性,9 名女性,平均年齡21.9 歲),英漢雙語被試18 人(13 名男性,5 名女性,平均年齡22.9 歲),兩組被試在年齡上無顯著差異(t=1.35,p=0.19),均為在校大學生。英語母語被試為外籍留學生,是晚期英漢雙語者,學習漢語至少3 年以上,平均學習漢語年齡18 歲開始,均具有1 年以上的中國留學經歷,通過漢語水平考試(HSK)5 級及以上。所有被試無腦部疾病史,視力或矯正視力正常,在實驗前閱讀知情同意書并簽字,實驗后獲得一定報酬。
2.2 材料
漢語命名材料。32 幅黑白線條圖片,選自張清芳和楊玉芳(2003)建立的漢語圖片命名的圖片庫,正式實驗圖片為25 幅,練習圖片7 幅,名稱均為單音節詞,每幅圖片匹配3 種類型的干擾字。例如,圖片名稱為“船”(/chuan2/),分別匹配3 種干擾詞:1) 音節相關詞與目標圖片名稱音節完全相同而聲調不同,如“穿” (/chuan1/); 2) 音素相關詞與目標圖片名稱的首音段或者首音素組合相同,聲調不同,即與目標圖片名稱的頭兩個音素相同(CV 相關),如“吃”(/chi1/); 3) 無關詞與目標圖的名稱無語音相關,如“杯”(/bei1/)。3 種條件下的干擾詞與目標詞之間均無任何語義和正字法上的聯系,且干擾詞的詞頻(王還等,1986)和筆畫數匹配,統計結果無顯著差異,字頻:F(2,72)=1.21,p=0.31; 筆畫數:F(2,72)=0.51,p=0.60。
英語命名材料。32 幅黑白線條圖片選自Snodgrass 和Vanderwart (1980)標準化的英語圖片命名的圖片庫,正式實驗圖片為25 幅,練習圖片7幅,名稱均為雙音節詞,音節結構為CV 或CCV (C表示輔音,V 表示元音)。例如,圖片名稱為“penguin(/?pe?gw?n/)”分別匹配3 種干擾詞1) 音節相關詞與目標圖片名稱首音節相同,例如“pencil (/?pensl/)”;2) 音素相關詞與目標圖片名稱的首音素相同,例如“pilot (/?pa?l?t/)”; 3) 無關詞與目標圖的名稱無語音相關,例如“orbit (/??:b?t/)”。3 種條件下干擾詞的詞頻和音節長度匹配,統計結果無顯著差異,詞頻:F(2,72)=0.93,p=0.40; 音節長度:F(2,72)=0.35,p=0.71。
2.3 設計
研究中要比較英漢雙語者漢語圖畫命名的過程與英語圖畫命名過程類似,還是與漢語母語者的圖畫命名過程類似,兩組被試共獲得3 組數據,分別為漢語母語者用漢語命名圖片(簡稱為“漢漢組”),英語母語者用英語(簡稱為“英英組”)和漢語(簡稱為“英漢組”)命名圖片。根據數據分析的思路,研究中包括了兩類實驗設計。第一類是兩因素混合設計,包括了漢語是作為母語還是二語(簡稱為“漢語類別”,包括漢漢組和英漢組)和干擾詞與圖片名稱之間的語音相關類型(音節相關,音素相關,無關)兩個自變量,第一個自變量為被試間因素,第二個自變量為被試內因素。第二類是兩因素被試內設計,包括了英漢雙語者的目標語言(英英組和英漢組)和干擾詞與圖片名稱之間的語音相關類型(音節相關,音素相關,無關)兩個自變量,均為被試內因素。
25 幅實驗圖片和7 幅練習圖片都與3 種不同的干擾字搭配后形成了75 個實驗配對和21 個練習配對,因此,每組包括21 次練習試次和75 次實驗試次。為了得到足夠多的疊加次數,每組測試重復了3 次,圖畫呈現的順序是偽隨機的:同一幅圖畫至少間隔5 幅其它圖畫后再次呈現,圖畫名稱聲母相同或者聲旁相同的不會連續出現,各個條件下相同的干擾詞不會連續呈現。每個被試3 組中測試的試次序列是不同的,每組之間有休息。英漢雙語被試一半先完成母語命名任務,一半先完成漢語二語命名任務。
2.4 儀器
實驗由E-prime 2.0 心理學實驗程序編寫,被試出聲命名,設置麥克風接收語音信號,通過PST-SRBOX 反應盒記錄聲音信息,錄音筆記錄被試反應。收集腦電數據時,被試需配佩戴腦電帽(Quick Cap),通過Neuroscan 軟件及硬件設備記錄數據。
2.5 程序
被試端坐在距離電腦屏幕70 cm 處進行實驗。正式實驗開始之前,在屏幕中央依次呈現每幅圖片及其對應名稱(漢語或英語名稱),呈現時間為2 秒,共50 幅。告知被試正式實驗會呈現這些圖片,要求被試盡可能記住圖片對應的名稱。如若被試對某一圖片的名稱錯誤命名,則對其進行糾正,并強調記住相應名稱。一般來說,因為這些圖片都是日常生活中常見的命名一致性很好的圖片,被試對圖片的命名與程序中給出的名稱是一致的。
正式實驗中每一個試次的流程如下:首先屏幕中央呈現注視點“+”800 ms,再呈現500 ms 空屏,然后同時呈現圖和詞(詞在圖中央),要求被試忽略出現的詞,準確而迅速地說出圖畫的名稱,被試做出反應的同時圖片與干擾詞消失,再間隔 800~1000 ms 的空屏,主試控制按鍵進入下一個試次。每組被試完成實驗試次數和實驗時間有差別。漢語母語被試僅完成漢語材料。英漢雙語被試需要完成英語命名和漢語命名,語言種類的材料順序在被試間平衡,一半被試先做英語命名再做漢語命名,一半被試先做漢語命名再做英語命名。英漢雙語被試需要完成492 個試次,時長約42 分鐘,每完成一組(約7 分鐘)休息一次。
2.6 EEG 記錄與分析
腦電信號由Neuroscan 系統進行采集,64 導銀、氯化銀電極以國際通用的10-20 方式固定于電極帽上。左側乳突作為參考電極,額頭中央連接接地電極。位于左眼上下眶的電記錄垂直眼電(VEOG),位于左右眼角外 1 cm 處的電極記錄水平眼電(HEOG)。電極與頭皮之間的阻抗小于5 kΩ。信號經放大器放大,濾波帶通為0.05~70 Hz,采樣頻率為500 Hz。
記錄的EEG 數據導入MATLAB (MathWorks),利用EEGLAB 軟件包(Delorme & Makeig,2004)進行離線處理。首先對腦電數據進行雙側乳突的重新參考(Wang et al.,2011; Zhang & Zhu,2011)。分別對數據進行30 Hz (24 dB/oct)的低通濾波以及0.1 Hz的高通濾波,再按照目標圖呈現前100 ms 和呈現后600 ms 對腦電數據進行分段,前100 ms 作為基線進行基線校正,在偽跡校正中將波幅超過±100 μV 去除,以排除無關偽跡的影響。
選取半球(前和后)和偏側化(左、中、右) 6 個興趣區進行分析,其中每個興趣區(region of interest,ROI)波幅值是3 個電極點的平均波幅:左前(F3,FC3,C3),中前(Fz,FCz,Cz),右前(F4,FC4,C4); 左后(CP3,P3,PO3),中后(CPz,Pz,POz),右后(CP4,P4,PO4)區域。將每個時間窗口的平均波幅根據兩種實驗設計分別進行分析。(1) 2(漢語類別:漢漢組、英漢組)×2(語音相關類型:音節相關、音素相關、無關)×2(半球:前、后)×3(偏側化:左、中、右)的重復測量方差分析; (2) 2(目標語言:英英組、英漢組)×2(語音相關類型:音節相關、音素相關、無關)×2(半球:前、后)×3(偏側化:左、中、右)的重復測量方差分析。重復測量方差分析中球形性假設不成立時,使用 Greenhouse-Geiss 法校正。利用R 軟件中的fdrtool 安裝包,在多重比較中采用控制錯誤發現率校正法對p值進行校正(false discovery rate,FDR,Yekutieli & Benjamini,1999)。
采用Cartool 軟件(Brunet et al.,2011)進行時空微態分割分析,使用了漢漢組、英漢組與英英組內音節相關條件、音素相關條件以及語音無關條件下被試的總平均數據。這一分析方法是利用層次聚類分析(modified hierarchical clustering analysis)和聚合層次聚類法(agglomerative hierarchical clustering)來確定對不同條件之間的總平均數據解釋力度最大的地形圖成分。結合交叉驗證(cross-validation)和Krzanovski-Lai 準則(Michel et al.,2001; Murray et al.,2008)來確定不同條件下能夠最好的解釋總平均數據的最優地形圖數量。然后采用統計平滑去除解釋力較低、時間孤立的地形圖。兩個地形圖之間的相關性達到90%以上即融合為一個地形圖,持續時間小于10 ms 則拒絕該地形圖。再利用Ragu軟件包(Koenig et al.,2011)對在Cartool 軟件中分割得到的微態地形圖數據進行非參數置換檢驗(Koenig et al.,2014)。首先,將每個被試在每個條件下的ERP 數據進行條件間以及被試組間的重新隨機分配,組合成新的總平均的數據,再對新的總平均數據進行微態擬合,并提取微態特征(持續時間等參數)。隨后經過5000 次的重新組合與計算,可以建立零假設條件下的微態特征的差異分布。最后,將真實情況下各個條件間的總平均數據與零假設分布進行比較,從而直接得到p值,不需要進一步的統計分析。
3 結果
4 名漢語被試由于無關偽跡太多而被剔除。最終分析18 名漢語母語被試(11 名男性,7 名女性),18名英漢雙語被試(13 名男性,5 名女性)。
3.1 行為數據
兩組被試共獲得3 組數據,刪除反應時快于300 ms 或者慢于2000 ms 的數據,以及偏離各條件下平均值3 個標準差以外的試次,漢漢組、英英組和英漢組分別刪除了2.5%,3.0%。和3.3%的數據。圖1 中表示了3 組數據的平均反應時。
使用R 軟件(R Development Core Team,2009)中lme4 安裝包的lmer 程序(Bates et al.,2015)進行固定和隨機效應的分析。使用限制最大似然估計法查找對觀測數據實現最佳擬合模型的最優參數估計。模型擬合主要包括3 個步驟:首先,指定一個只包含隨機因素(被試和項目)的零模型; 第二,通過添加固定因子來豐富零模型。在已有模型的基礎上,逐步增加兩個自變量及其交互作用。第三,使用卡方檢驗將新建立的模型與之前的模型進行比較。若在已有模型中加入固定因子或兩個因素的交互作用對方差估計的改善不顯著,則當前模型是最佳擬合模型。

表1 三組混合效應模型的固定效應
首先進行漢漢組和英英組的方差分析,將母語類別(漢漢組、英英組)和語音相關類型(音節相關、音素相關、語音無關)作為固定效應,被試和項目作為隨機效應對反應時進行線性混合效應模型分析。最優模型(見表1 最左欄)包括語音相關類型主效應。增加目標語言未顯著提高模型的擬合度,χ2(1,7877)=3.25,p=0.07; 增加語音相關類型顯著地提高了模型的擬合度,χ2(1,7877)=126.33,p<0.001; 增加目標語言和語音相關類型的交互作用未提高模型的擬合度,χ2(1,7877)=0.0021,p=0.96。
第二,進行漢漢組和英漢組的方差分析,將漢語類別(漢漢組、英漢組)和語音相關類型(音節相關、音素相關、語音無關)作為固定效應,被試和項目作為隨機效應對反應時進行線性混合效應模型分析。最優模型包括目標語言、語音相關類型主效應以及目標語言和語音相關類型的交互作用(見表1 中間欄)。增加目標語言顯著地提高了模型的擬合度,χ2(1,7859)=4.96,p=0.025; 增加語音相關類型顯著地提高了模型的擬合度,χ2(1,7859)=4.94,p=0.020; 增加目標語言和語音相關類型的交互作用顯著地提高了模型的擬合度,χ2(1,7859)=7.08,p=0.007。
最后進行英英組和英漢組的方差分析,將目標語言(英英組、英漢組)和語音相關類型(音節相關、音素相關、語音無關)作為固定效應,被試和項目作為隨機效應對反應時進行線性混合效應模型分析。最優模型包括語音相關類型主效應以及目標語言和語音相關類型的交互作用(見表1 最右欄)。增加目標語言并未顯著提高模型的擬合度,χ2(1,7842)=0.46,p=0.49; 添加語音相關類型顯著地提高了模型的擬合度,χ2(1,7842)=64.39,p<0.001; 增加目標語言和語音相關類型的交互作用顯著地提高了模型的擬合度,χ2(1,7842)=7.63,p=0.006。
事后多重比較發現,漢漢組發現音節效應顯著,β=-43.06,p<0.001,音素效應不顯著,β=-5.52,p=0.53; 英漢組音節效應顯著,β=-20.60,p<0.001,音素效應不顯著,β=-7.18,p=0.34; 英英組音節效應顯著,β=-20.65,p<0.001,音素效應不顯著,β=-7.98,p=0.22。
3.2 ERP 分析
兩組被試共收集3 組腦電數據,刪除偽跡較多的試次,漢漢組、英英組和英漢組分別刪除了3.8%,6.6%。和7.8%的數據。每名被試每個條件下有效疊加試次數均超過50 次。
元分析研究表明圖畫呈現后的250~450 ms 為詞匯產生中的詞匯選擇和音韻編碼階段(Indefrey &Levelt,2004),我們重點關注了200~500 ms 時間窗。為了考察英漢雙語者二語加工的音韻編碼單元起作用的時間進程,從刺激出現之后的200 ms 開始,以50 ms 為時間窗口遞增,對3 組數據在各個時間窗口下進行了語音相關類型(音節相關、音素相關與語音無關),半球(前、后)和偏側化(左、中、右)的方差分析(結果見表2)。
多重比較結果(均經過FDR 校正)發現,漢漢組在250~300 ms 時間窗口,前半球右側音節效應顯著F(1,17)=9.57,p=0.021,=0.36,f2根據方差分析效應量Cohen’s f 的評價標準,0.10 為的低效應,0.25 為中等效應,0.40 為高的效應(Cohen,1988)=0.75; 前半球中央區域音節效應邊緣顯著F(1,17)=4.82,p=0.08,=0.22,f=0.53; 后半球右側音節效應顯著,F(1,17)=12.19,p=0.018,=0.42,f=0.84。300~350 ms 時間窗口,后半球右側音節效應顯著,F(1,17)=10.21,p=0.03,=0.38,f=0.77。
英英組200~250 ms 時間窗口,后半球中右音素效應邊緣顯著,F(1,17)=8.81,p=0.05,=0.34,f=0.72;F(1,17)=5.76,p=0.06,=0.25,f=0.58。前半球左中音素效應邊緣顯著,F(1,17)=4.89,p=0.06,=0.22,f=0.54;F(1,17)=4.50,p=0.06,=0.21,f=0.51。
英漢組200~250 ms 時間窗口發現,前半球左側和后半球左側音素效應邊緣顯著,F(1,17)=4.89,p=0.07,=0.24,f=0.56;F(1,17)=5.54,p=0.07,=0.25,f=0.57。在250~ 300 ms 時間窗口,前半球左中和右側音素效應邊緣顯著,F(1,17)=6.83,p=0.067,=0.29,f=0.64;F(1,17)=6.007,p=0.07,=0.26,f=0.59;F(1,17)=5.38,p=0.07,=0.24,f=0.56。圖2 從左至右分別表示了漢漢組(左)、英英組(中)和英漢組(右)在不同時間窗口內3種條件下在Cz 電極點上的平均波形圖,以及相應的時間窗口內的地形分布圖。
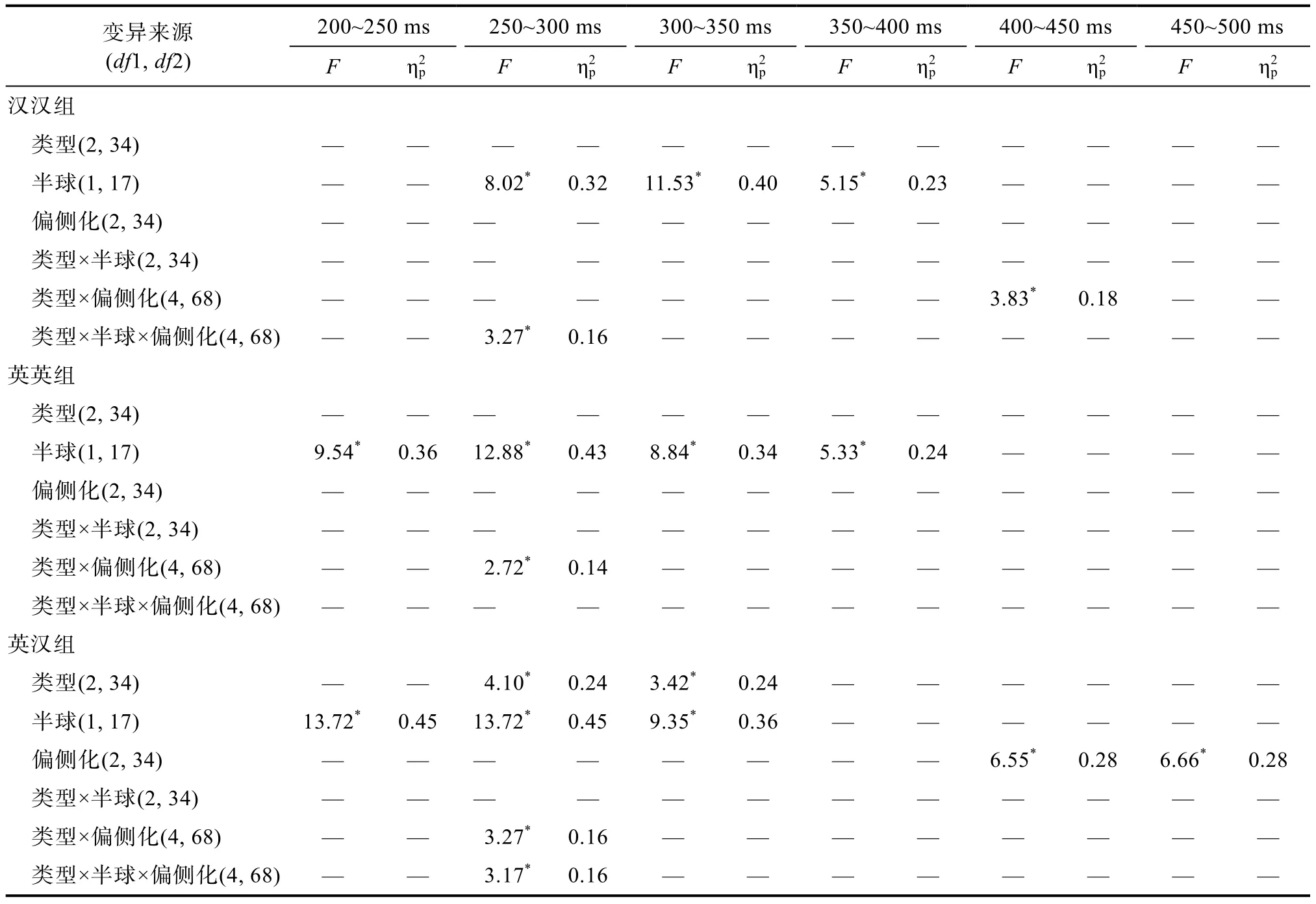
表2 目標語言在各時間窗口下不同干擾詞語音相關類型,半球和偏側化的方差分析
3.3 整體地形圖ERP 模式分析(時空微態分割)
研究認為刺激相關的ERP 信號之間整體電場并不是隨機變化的,而是在轉換為另一種形態穩定的地形之前,能夠保持幾十毫秒的穩定(Lehmann& Skrandies,1984),每一種時間空間地形分布圖反映了某一個加工階段或過程。這一方法是通過對比不同條件和組別之間一定時間內穩定的整體電場,對特定時間進程內相應的心理信息加工過程進行分析(Koukkou & Lehmann,1987; Lehmann et al.,1998; Laganaro,2014,2017)。在確定不同條件下解釋力最優的地形圖數量過程中,利用整體解釋變異(global explained variance,GEV)和持續時間(duration)進行統計分析。
首先對漢漢組與英英組做組間分析,進而對漢漢組和英漢組做組間分析,最后對英英組和英漢組做組內分析。比較漢漢組和英英組在不同語音相關條件之間的整體地形圖差異時,我們利用了漢漢組和英英組內音節相關條件、音素相關條件以及語音無關共6 個條件的總平均數據,根據以往研究表明,250~450 ms 為音韻編碼階段(Schriefers et al.,1990),對圖片呈現后的200~500 ms 進行地形圖分析,結果可以解釋總變異的91.5%。圖3A 呈現的是能夠解釋總平均ERPs 最大變異的4 個地形圖成分,圖3B 為每個條件下總平均ERPs 的整體場能量軌跡(global field power traces,GFP),表明每個條件下每個地形圖的位置和持續時間。分析表明漢漢組和英英組相比,具有不同的微態成分2 和微態成分3,表明漢語母語和英語母語者在音韻編碼階段具有不同的腦加工模式。
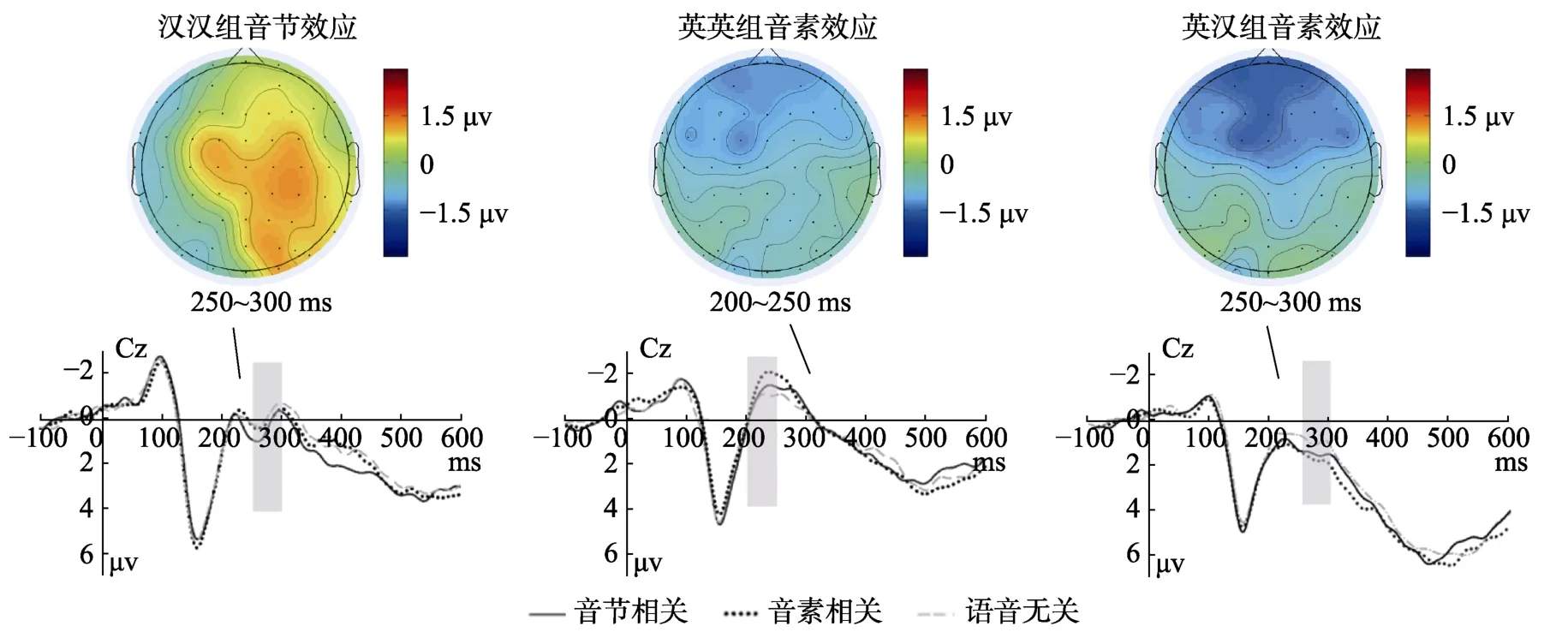
圖2 漢漢組(左)、英英組(中)和英漢組(右)在不同時間窗口內3 種條件下在Cz 電極點上的平均波形圖以及相應的時間窗口內的地形分布圖
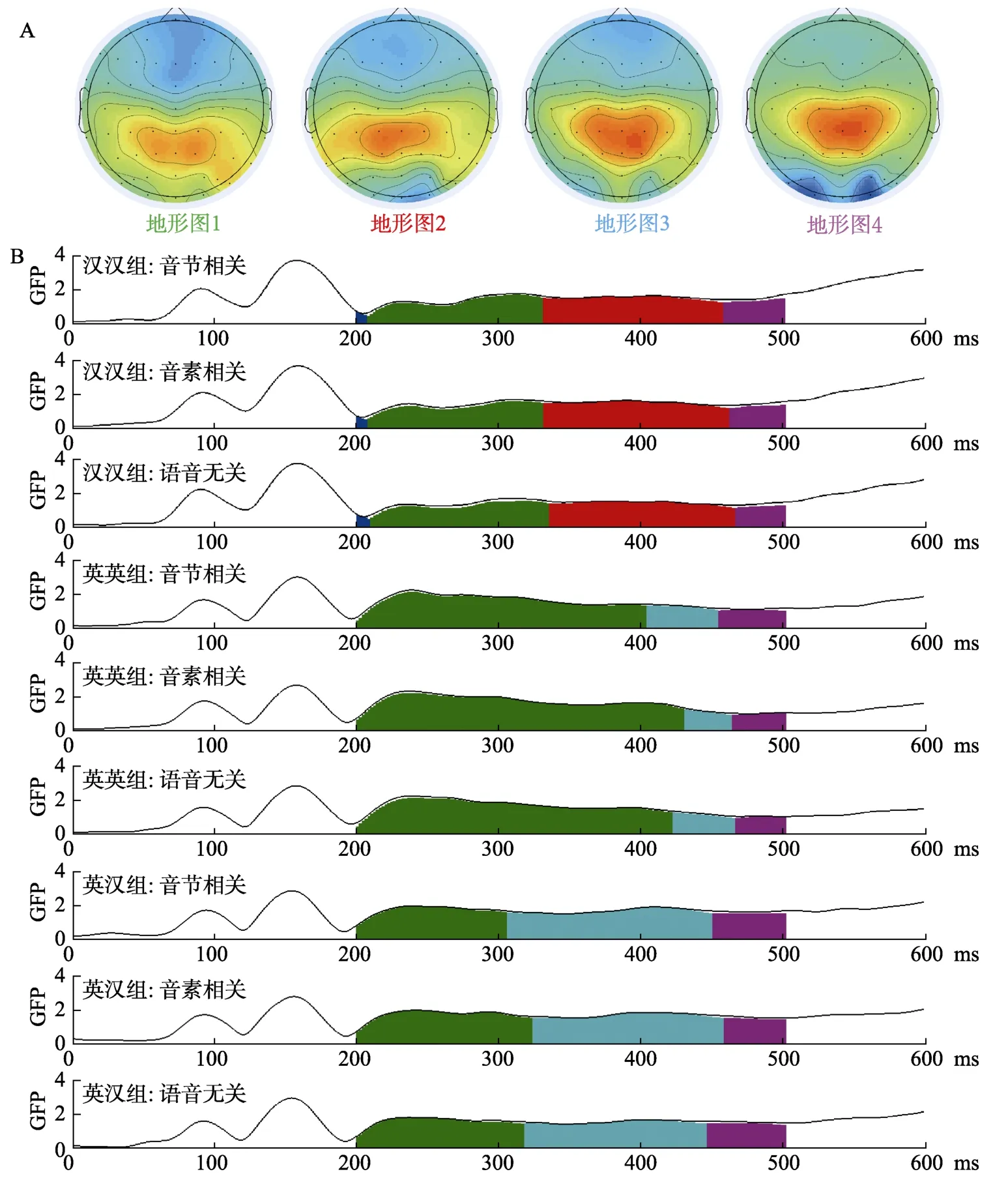
圖3 漢漢組、英英組與英漢組各個條件下總平均ERPs 的GFP 和微態分割圖
利用漢漢組和英漢組共6 個條件的總平均數據,同樣從圖片呈現后200 ms 到500 ms 進行時空微態分割分析,結果可以解釋總變異的93.2%。分析表明英漢組與漢漢組相比,相同微態成分1 和4 組間主效應差異不顯著(allps≥0.84),語音相關類型主效應和組間與語音相關類型交互作用都不顯著(allps≥0.99)。漢漢組在334~460 ms 出現了與英漢組不同的微態成分2,顯著區別于英漢組的腦微態成分。
比較英漢組和英英組的腦地形圖差異時,我們利用了英漢組和英英組共6 個條件的總平均數據,同樣從圖片呈現后200 ms 到500 ms 進行時空微態分割分析,結果發現英英組與英漢組具有3 個相同的微態成分,僅在成分1 和3 的開始時間和持續時間上存在差異,可以解釋總變異的93.2%。地形圖1、3 上組間主效應差異顯著(p<0.001;p<0.001),語音相關類型主效應和組間與語音相關類型交互作用都不顯著(allps≥0.99)。在地形圖1 上英漢組都表現出比英英組更短的持續時間(音節相關106 ms vs.204 ms; 音素相關124 ms vs.230 ms)。地形圖3 上英漢組都表現出比英英組更長的持續時間(音節相關144 ms vs.50 ms; 音素相關134 ms vs.34 ms)。
綜合時空微態分割結果可知,英漢組與英英組具有相同的微態成分,僅在成分持續時間上存在差異; 英漢組與漢漢組既有相同也有不同的微態成分。這些結果說明英漢雙語者在產生漢語時的腦功能激活狀態更類似于英語母語者,而區別于漢語母語者,因此認為英漢雙語者在加工漢語時表現出同化機制。
4 討論
采用圖詞干擾范式,結合ERP 技術以及時空微態分割分析法,我們考察了英漢雙語者漢語作為第二語言的口語詞匯產生中音韻編碼過程的同化與順應機制。反應時結果發現漢漢組、英漢組與英英組都出現顯著的音節效應,未出現音素效應。ERP 結果發現,漢漢組表現出音節效應,英英組表現出音素效應,英漢組表現出音素效應(200~250 ms),英漢組音素效應的模式與英英組更相似;時空微態分割分析發現英漢組與英英組微態成分完全相同(地形圖1,地形圖3,地形圖4),僅在持續時間上存在差異,相比而言,英漢組與漢漢組具有不同的微態成分(地形圖2)。總體來說,英漢雙語者二語產生的音韻編碼過程中表現出的音素效應模式與英語母語者更為相似,與漢語母語者的神經模式存在顯著不同,研究結果首次清晰地表明英漢雙語者在二語口語產生的音韻編碼過程中表現出母語同化機制。
在反應時上,漢語作為母語的口語詞匯產生過程表現出音節效應,以及英語作為母語的口語詞匯產生過程表現出音素效應,這與已有漢語和英語的研究結論一致(You et al.,2012; Zhang & Damian,2019)。O’Seaghdha 等(2010)提出了合適單元假設(proximate units principle)來解釋跨語言間音韻編碼單元的不同。合適編碼單元(proximate units)指的是激活詞匯的詞素之后首先被激活的音韻編碼單元,這一假設認為音韻編碼單元中最先選擇的單元存在語言上的差異,印歐語系如英語或荷蘭語中最先選擇的單元是音素,而在漢語中則為音節。在印歐語系中,講話者在選擇音素后,結合節律信息進行音節化過程,從心理音節表中提取音節準備發音運動程序。漢語口語產生中講話者則在選擇音節后進一步分解為音素或音段信息(音韻編碼階段),準備發音運動程序(語音編碼過程),最后進行發音輸出口語產生的結果(發音階段)。Roelofs (2014)利用計算機模擬的方法將合適單元假設加入到了口語詞匯產生的WEAVER 模型的參數設定中,驗證了合適單元假說。我們通過跨語言比較的結果,為合適單元假說提供了支持證據。
英英組在反應時的結果上未表現出音素效應,這與已有發現不一致。我們猜測可能的原因有:第一,實驗設計中同時包括了音節相關、音素相關和無關,因為音節相關中語音重疊的程度大于音素相關,所產生的促進效應較大,而音素相關所產生的促進效應較小,這在一定程度上掩蔽了音素相關所引起的效應,使得相對較為微弱的音素效應不能達到顯著水平。同時,本研究發現英英組的反應時長于漢漢組,潛伏期變長也有可能使得音素效應消失。第二,這可能是由于英漢雙語者的外部語言環境是漢語所導致的。以往就有研究在行為結果上發現,第一語言的加工過程會受到第二語言學習遷移的影響。在考察粵語口語產生中音韻編碼單元的研究,有研究者指出發現粵語中的亞音節啟動效應可能是受到了被試英語二語經驗的影響,導致粵語被試能夠更加敏感的操作亞音節水平作為語音計劃單元(Wong et al.,2012)。在以漢英雙語者為被試的研究中同樣發現在產生漢語過程中的亞音節啟動效應(Verdonschot et al.,2013),表明二語可能對母語音韻編碼單元產生影響。Nakayama 等(2016)也指出,產生二語過程中利用母語或二語模式啟動效應的大小與在二語國家停留的時間長短有關。本研究中參加實驗的被試均在中國停留至少一年以上,日常語言環境均為漢語,因此在語言產生的行為反應時結果上發現了更類似漢語母語者的音節效應。
重要的是,我們首次同時采用ERP 波形分析和時空微態分割分析,兩類分析一致地表明英漢組的漢語音韻編碼過程中表現出音素效應模式,其模式更多地與英英組相似,并非與漢漢組相似,表現出二語加工中的同化機制。具體地說,ERP 波形分析發現漢漢組的音節效應出現在250~350 ms 之間,位于右側半球,時間進程與音節效應出現的時間相當(Wong et al.,2018; You et al.,2012; Zhang &Damian,2019)。英漢組的音素效應出現在 200~300 ms 之間,位于左側半球前部區域,英英組的音素效應出現在200~250 ms 之間,位于左側半球前部區域,這與印歐語系中發現的音素效應出現的時間一致(Timmer & Schiller,2012; Timmer et al.,2014)。因此,我們認為時間進程和波形分布的結果表明,英漢雙語者產生漢語過程中的音韻編碼單元模式更類似于母語英語的音韻編碼單元模式,支持同化機制。
已有研究認為每一個空間地形分布圖反映了特定的加工過程,不同的微態成分對應于不同的加工過程(Koukkou & Lehmann,1987; Lehmann et al.,1998; Laganaro,2014,2017)。我們的研究發現英漢組和漢漢組微態成分1 的持續時間不存在顯著差異,而英漢組與英英組微態成分1 的持續時間存在顯著差異,在地形圖1 上英漢組表現出比英英組更短的持續時間。根據元分析中各個階段對應的時間進程(Indefrey,2011),微態成分1 可能對應的是詞匯選擇階段。由于英漢組和漢漢組產出的詞匯均為漢語,因此詞匯選擇階段持續時間上沒有顯著差異,而英漢雙語者在產生漢語與英語過程中需要檢索不同的詞匯因此需要不同的持續時間。英漢雙語者檢索母語詞匯反而比檢索二語漢語詞匯需要更長的時間。為什么?根據抑制控制模型(Inhibitory Control,Green,1998),我們猜測是由于周圍的語言環境為漢語,雙語者在這種環境下需要對母語進行抑制從而產生二語,由于母語產出比二語更為流暢,因而對母語需要更強的抑制,也就導致再次進行母語的口語產生時需要消耗更大的認知資源解除抑制,因此導致英語母語者檢索母語詞匯反而需要更長的時間(Gollan et al.,2011; Misra et al.,2012)。
在英漢組與英英組中具有相同的微態成分3,均出現在圖畫呈現后的300 ms 之后,這一時間窗口對應于口語詞匯產生中的音韻編碼階段(Indefrey,2011),而這一微態成分在漢漢組中未出現,這一成分可能與音素提取有關,音韻編碼過程在英漢組和英英組具備相似的時空模式,表明英漢雙語者在二語加工過程中采用了與母語相似的加工機制,表現出同化加工機制。在微態成分3 的持續時間上,英漢組都表現出比英英組更長的持續時間。對于雙語者來說,在二語音韻編碼過程中仍然要比一語音韻編碼消耗更大的認知努力,表現出二語加工中需要更長的持續時間進行音韻編碼過程。
在漢漢組中,出現了一個特異的微態成分 2,其時間進程大約在圖畫出現后的350 ms 左右,而這一微態在英漢組與英英組中都未出現。根據這一對比,我們猜測這一成分與漢漢組中的音節提取有關。這一時間窗口與已有有關漢語口語詞匯產生中音節提取的時間進程基本一致。Zhang 和Damian(2019)發現的音節效應位于圖畫呈現后的 300~450 ms 之間(類似的時間窗口見Wang et al.,2018)。因為此類分析在已有同類研究中很少使用,上述研究發現還需要更多的實驗進行驗證。
綜上,本研究的發現一致地表明英漢雙語者在作為二語的漢語口語詞匯產生過程中采取了與母語類似的加工模式,表現出同化加工機制。這與已有的一些發現一致。研究者發現藏漢雙語者的漢語產生在反應時結果上的模式與藏語更為相似,同樣表現出同化機制(王星星,2013)。同樣在印尼語-漢語者出聲閱讀漢字的fMRI 研究(Tian et al.,2019)中發現作為二語的漢語表現出與母語相似的腦區激活模式。
我們的發現與詞匯識別中的結果不一致。元分析的結果(Liu & Cao,2016)發現在詞匯理解任務中,如果二語的正字法透明度低于一語,則表現為順應的機制。為什么在詞匯產生過程中出現了完全不同的加工機制?一個可能的原因是任務不同導致加工機制不同。在圖畫詞匯干擾任務中,被試主要的任務是口語命名圖片,同時忽略干擾字。在圖片命名任務中,人們可以不用通達目標字的正字法信息(Zhang et al.,2007; Damian & Bowers,2003),而單詞的閱讀過程從視覺正字法信息加工開始,也涉及到單詞語音和語義的提取(陳寶國 等,2006)。漢語作為表意文字,側重形音對應的音節發音記憶,重視字形分析的作用(Zhao et al.,2012),視覺呈現的漢字識別過程必然受到正字法信息的影響。已有研究發現漢語作為第二語言進行加工時更多表現出與母語不同的加工模式,表現出順應機制。由于實驗任務中對正字法信息依賴的要求不同,英漢雙語者對于詞匯產生和詞匯理解過程可能采用了不同的加工機制。
其次,也有研究運用口語產生的任務,得到結論認為雙語者在二語熟練度較高的情況下,能夠采用順應機制加工二語(Nakayama et al.,2016)。從雙語者掌握的語言類型來看,Nakayama 等(2016)選取的是日英雙語者,日語中存在一定數量的印歐語系外來語,通常用片假名書寫。雖然在語音上經過了日本語化,但是仍然與英語具有一定的相似性。這種母語中的英語外來語所帶來的影響,可能導致日語被試在學習英語過程中更加容易地采用英語的加工機制。而在以英漢雙語者為被試的產生任務研究中(Zhao et al.,2012)發現,被試在加工漢語過程中,更多的運用母語的加工策略同化二語加工,這比順應二語本身的加工機制需要更少的認知努力。在產生漢語口語詞匯產生的過程中,我們也發現英漢雙語者選取了消耗認知資源更低的類似于母語英語的加工方式,即同化機制。
另一個可能影響的因素是二語的熟練度。Nakayama 等(2016)在研究中發現二語熟練度低的被試在產生二語詞匯過程中傾向于使用一語的音韻編碼單元,而熟練度高的被試更傾向于采用二語音韻單元的加工模式。即二語熟練度低的被試傾向于采用同化機制,而熟練度高的被試傾向于采用順應機制。結合本研究進行對比,參加本實驗的被試為通過漢語水平考試(Hanyu Shuiping Kaoshi,HSK)成績為5 級及以上,一般認為達到HSK 5 級以上的被試其漢語熟練度較高(張凱,2004)。我們在行為結果上發現了英語母語被試的表現類似于漢語母語者的加工模式,這不同于腦機制上發現的同化加工模式。HSK 分為聽力、閱讀和寫作三個部分,主要考察的是對漢語的理解和運用能力,并未系統地考察口語表達能力。這種行為和腦機制上的差異表現,也更進一步說明,根據被試的HSK 成績評價為語言理解熟練度較高,不能保證口語產出能力也較高。而隨著被試留學經驗的豐富,沉浸在二語環境中的時間增長,漢語口語產生的熟練度增加,被試可能在未來的腦機制上呈現出順應的機制。目前從腦機制上得到的結果來看,我們更傾向于認為支持同化機制。這也提示研究者需要從產生和理解兩個方面考察留學生學習漢語的情況,后續研究中需要區分被試口語產生能力的熟練度高低對音韻編碼單元同化順應機制的影響。
需要注意的是,第一,本研究中出現了行為和腦電結果的不一致:英漢組在行為上在對母語英語的加工中表現出音節效應,而腦電結果表現出音素效應。反應時是最終輸出的結果反映,會受到一系列加工過程的影響,而腦電指標反映了實時的加工。基于已有研究的結果和本研究的分析,我們傾向于認為英漢雙語者在英語的加工中,其神經層次上仍然保留了對英語音素的敏感性。而行為上未表現出音素效應的原因比較復雜,比如同時呈現的語音相關條件,以及作為二語的漢語對母語英語的影響,需要在下一步的研究中進行考察。第二,本研究中英漢組和英英組是同一組被試,但所用實驗材料不同,而英漢組和漢漢組為不同組被試,所用實驗材料相同。在行為數據分析中我們采用混合線性模型同時納入了被試隨機變量和項目隨機變量,在考慮被試差異和項目差異影響的基礎上考察了語言和語音相關類型對英漢組、英英組和漢漢組口語詞匯產生過程的影響。本研究的實驗設計遵循了已有對于雙語者二語加工同化與順應機制的研究邏輯,與已有研究設計類似(例如Tian et al.,2019;Timmer & Shiller,2012; Sun et al.,2015)。Sun 等(2015)利用fMRI 技術考察英漢雙語者和漢英雙語者在閱讀母語與二語詞匯過程中的腦區激活差異。其中將英漢雙語者進行二語漢語詞匯判斷任務組(英漢組)與英漢雙語者進行英語詞匯判斷任務(英英組)和漢英雙語者進行漢語詞匯判斷組(漢漢組)分別進行組內和組間對比。結果表明,與英英組相比,英漢組更多的激活右側額下回區域,該腦區的激活與漢語加工相關。也就是說,英漢雙語者在詞匯識別任務中采用了與二語類似的加工方式,即表現出順應機制,這一結果與Liu 和Cao (2016)元分析中的結果相一致,因此我們認為該機制受到組內或組間比較的影響較小。盡管如此,由于雙語者的兩種語言之間存在相互影響的可能,在考察二語加工同化與順應的機制時,更為理想的情況是3 組被試分別為漢語單語組、英語單語組和英漢雙語組,比較英漢組與其他兩組的加工機制是否相同。
5 結論
基于二語學習者在認知神經機制上的同化與順應假設,我們利用圖詞干擾范式,要求被試進行外顯的口語詞匯產生任務,ERP 波形分析和時空微態分割分析一致地表明英漢雙語者二語漢語加工過程中采用了類似于英語母語的同化機制,且發生在音韻編碼加工階段的早期,為英漢雙語者產生二語的加工機制提供了時間進程以及時空微態分割上的證據。
猜你喜歡
核科學與工程(2021年4期)2022-01-12 06:30:26
今日農業(2020年19期)2020-12-14 14:16:52
小學生必讀(中年級版)(2020年9期)2020-12-04 02:07:22
科學大眾(2020年17期)2020-10-27 02:49:10
紅土地(2018年11期)2018-12-19 05:10:56
意林·全彩Color(2018年9期)2018-11-13 22:49:38
中學物理·高中(2016年12期)2017-04-22 11:53:03
中國衛生(2016年4期)2016-11-12 13:24:14
中國衛生(2014年4期)2014-12-06 05:57:14
小櫻桃·童年閱讀(2014年11期)2014-12-01 22:21:30
