基于HAWQ的電力企業數據質量管理應用研究與建設
2020-12-17 12:45:06楊秋勇
自動化儀表 2020年12期
楊秋勇
(廣東電網有限責任公司,廣東 廣州 510000)
0 引言
在大型電力企業或組織中,存在多地區、多產品、多業務、多系統的環境,在數據信息、報表統計、業務分析和業務元定義上存在諸多數據質量問題。其主要包括數據不一致、不完整、不統一、不真實和不及時等。由此會導致管理者、業務人員和信息使用者的誤解,使數據利用出現錯誤、企業決策出現偏差。同時,低劣數據質量往往造成開發出來的系統與用戶預期大相徑庭,并且導致運行維護成本過高、工作量過大,系統難以擴展。諸如此類的問題迫切需要加強對于數據本身質量的研究和管理。數據質量管理是研究數據質量問題的標準和指導方案。數據就是資產的理念已被普遍認識,但要從根本上提高對數據質量重要性的認識,并潛化為工作方式和習慣,就必須立足于對數據及其質量本質的解析,從而推動實踐,把握進程[1]。
數據作為信息化應用的主體,具有多重屬性。其基本質量特性主要包括適用性、準確性、完整性、及時性、有效性這五個方面。要對數據質量進行較好的控制[2],需杜絕數據質量問題的出現,使數據監控工作能夠真正達到控制數據質量的目的[3]。
1 傳統的數據質量系統
傳統的數據質量管理系統實現了校驗規則配置、規則執行、數據質量報告等功能,一定程度提高了傳統關系型數據庫的數據管理水平,能滿足百萬級別以下的單表數據質量校驗需求。
傳統數據質量平臺功能描述如下。
①規則配置:提供基于單表的數據質量校驗腳本配置。
②規則執行:基于數據庫映射技術(dblink等),通過數據庫存儲過程執行校驗腳本,并保存校驗結果(問題數據總數和被校驗記錄總數)。
③數據質量報告:基于固定的格式,生成數據質量得分圖表,經人工調整補充形成報告。
傳統數據質量管理系統采用關系型數據庫作為被校驗庫和校驗結果存儲庫。但受限于關系型數據庫的部署架構和處理方式,其無法應對千萬級存量數據及指數式增長的大數據的數據質量校驗,也無法開展數據質量探查、分析、治理工作。
2 管理應用研究與建設
針對傳統數據質量管理系統的問題,本文研究并借鑒了國內外對數據質量結合大數據的解決方案,提出了基于帶查詢功能的分布式系統基礎架構(HADOOP with query,HAWQ)的數據質量管理應用解決方案。利用HAWQ集群,在多臺HADOOP服務器上分散存儲被校驗業務數據和校驗出的問題數據。得益于HAWQ的大規模并行處理(massively parallel processing,MPP)架構,可有效提高數據質量系統的校驗、探查、分析能力[4]。基于HAWQ的數據質量系統有以下優點。
①基于HADOOP平臺,技術成熟、保證平臺有良好的可擴展性。
②基于MPP架構,任務并行的分散到多個服務器和節點上計算完成后再匯總,避免產生CPU、I/O瓶頸。
③支持SQL過程化編程,以及SQL語言控制結構,并具有所有PostgreSQL的數據類型(包括用戶自定義類型)、函數和操作符[5]。
3 電力企業數據質量管理與創新點
3.1 應用設計
基于HAWQ的電力企業數據質量管理應用,采用J2EE結合Spring Clould框架開發,邏輯上劃分為主體應用、規則執行引擎組件、評價執行引擎組件、問題數據導出引擎組件。基于HAWQ的電力企業數據質量管理應用架構如圖1所示。
3.1.1 主體應用功能
(1)元數據管理:適配大數據平臺元數據,提供數據庫元數據、業務對象元數據的管理服務,解析說明表、字段的業務含義,用于生成、配置校驗規則[6]。
(2)規則管理:提供規則配置、版本管理、規則參數配置等功能,同時系統針對校驗腳本,自動給出HAWQ的語法適配建議。
(3)副本監控:針對待校驗庫數據副本的數據量、元數據進行監控,可避免因為數據量偏差較大,元數據的基本信息(如庫表、字段、數據類型等)出現差異,影響數據質量校驗結果,導致校驗結果出錯。
(4)問題數據下載:配置導出規則、問題數據枚舉值映射,提供單位-對象的問題數據下載。
(5)整改指引:業務人員、廠家在解決數據質量問題后,歸納解決方法,形成規范、高效的解決方案,固化到系統中,通過系統共享,促進數據質量問題整改。
(6)操作規范分析:通過制定規范規則,發現由于業務系統未能及時按數據質量考核進行整改,導致業務人員誤操作形成數據質量問題的規律。指導業務人員在操作業務系統過程中的動作,避免部分簡單的數據質量問題。
(7)報告管理:基于報告模板,結合評價結果,生成質量報告、企業信用報告。
(8)評價管理。
①提供評價靈活配置,可為不同的考核單位配置不同的規則、調整權重,并為每個規則設置目標值、目標值得分。
②豁免功能:細化組織單位顆粒度,將豁免功能細化到縣級和供電所層級,解決業務系統數據質量、實用化模塊無法實現豁免至縣局和供電所層級的問題。在細化豁免顆粒度的同時,可提升豁免功能效率、有效性和準確性。
③系統算分功能:利用在月、周整體評價中拆分出的個性化評價結果,組成新的評價,完成結果匯總和算分統計。
④評價申訴:針對考核中的特殊情況,地市局用戶可以向省公司提出豁免申請。系統以時間軸的方式展示每個申訴的始末。同時,統計每個地市局的申訴總量、有效申訴等信息。
(9)對比分析:通過單位得分排名、業務域得分、問題數據分布、指標得分、得分趨勢、指標通過率、問題數據,環比跟蹤問題數據的處理情況。
3.1.2 規則執行引擎組件
實現多線程規則執行,并通過執行腳本緩存,最大限度提升數據質量校驗的效率[7]。
3.1.3 評價執行引擎組件
基于HAWQ集群,對海量的問題數據進行去重、統計,根據指標森林對不同的指標樹進行匯總并加以權重,得出最后的總分。
3.1.4 問題數據導出引擎組件
問題數據的導出得益于HAWQ的MPP架構,支持問題數據主鍵與問題數據關聯多線程讀取,實現了千萬級問題數據的快速、全量讀取,并按配置的格式生成EXCEL文件[8]。
3.2 主要創新點
3.2.1 高并發智能化的規則執行引擎
傳統數據質量系統的問題是:單線程執行,數據質量校驗整體過程效率低[9]。
本文創新點如下。
①任務調度,按優先級管理執行的線程和并發度。
②智能策略緩存,避免規則重復執行。
③基于大數據技術的問題數據多線程寫入。
高并發智能化的規則執行引擎如圖2所示。

圖2 高并發智能化的規則執行引擎示意圖
3.2.2 彈性的問題數據存儲架構
傳統數據質量系統的問題是:問題數據無法快速存儲。
本文創新點如下。
①高容錯性,數據自動保存多個副本,副本丟失后自動恢復。
②適合批處理,數據分散在多臺服務器上,可并行處理數據,加快問題數據的分析和歸納[10]。
③一次寫入多次讀取,以流式文件訪問,數據讀取更高效。這種特性很適用于存儲問題數據。
④易于水平擴展,存儲節點可按需擴展。
⑤性能開銷小,通過HADOOP分布式文件系統HADOOP distributed file system,HDFS的接口寫入問題數據,可避免數據庫事務、回滾日志等性能開銷。
彈性的問題數據存儲架構如圖3所示。

圖3 彈性的問題數據存儲架構
3.2.3 基于HADOOP技術的問題數據分析架構
傳統數據質量系統的問題是:數據分析效率低。
本文創新點如下。
①快速響應:利用數據倉庫工具(Hive)作后期數據分析,可以更快地響應需求的變更。
②數據獨立存儲:每條規則都會生成一個文件,用于存儲當次的問題數據。
基于HADOOP技術的問題數據分析架構如圖4所示。
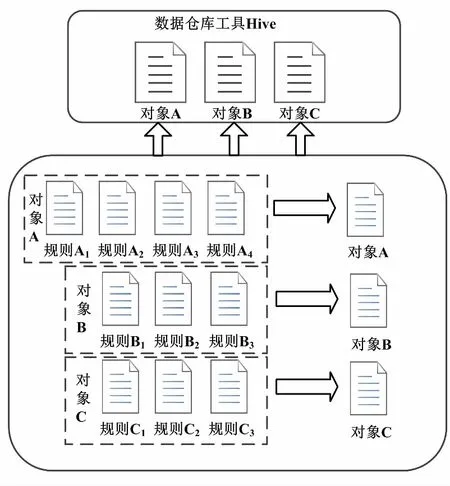
圖4 基于HADOOP技術的問題數據分析架構
3.2.4 基于HAWQ的準實時評價引擎
傳統數據質量系統的問題是:評價計算過程耗時長、豁免速度慢。
本文創新點如下。
①問題數據去重:對評價中的所有問題數據進行分析,按對象整合重復的問題數據,同時標記出問題數據各個字段存在的問題,為后面的問題數據下載和對比分析提供基礎數據。
②算分:可自動適配不同的評價指標樹,結合規則的豁免和排除,動態計算各個指標的數據。
③對比分析:基于兩個評價的執行結果,對比各評價指標的得分和問題數據,得出已整改、未整改、新增問題等維度的數據。
3.2.5 采用多線程切片技術問題數據導出組件
傳統數據質量系統的問題是:問題數據導出慢,且無法全量下載。
本文創新點如下。
①一次讀取(HAWQ),多處寫入(ORACLE/FTP)。
②導出引擎可獨立部署,實現高效的橫向擴展。
采用多線程切片技術的問題數據導出組件如圖5所示。

圖5 采用多線程切片技術的問題數據導出組件示意圖
4 系統實踐
目前基于HAWQ數據質量管理應用已完成開發,并在廣東電網公司運行。經實踐驗證,通過基于HAWQ數據質量管理應用,最高可實現數據質量校驗效率比原傳統數據質量系統提升17倍左右。服務器配置信息如表1所示。

表1 服務器配置信息
為驗證基于HAWQ數據質量管理應用性能的有效性,與傳統數據質量平臺進行比較,并在總記錄數242億5千萬、問題數1千萬,執行規則4 180條的試驗環境下進行對比。
傳統數據質量平臺與基于HAWQ數據質量管理應用的性能對比如圖6所示。

圖6 傳統數據質量平臺與基于HAWQ數據質量管理應用的性能對比
基于HAWQ數據質量管理應用的性能與傳統數據質量系統相比,有顯著的提升。其中,對多表關聯的數據一致性校驗的提升高達40倍。
5 結論
本研究針對企業海量數據的數據質量管理現狀和難點,提出了基于HAWQ的電力企業數據質量管理應用解決方案。通過開展高并發智能化的規則執行引擎、彈性的問題數據存儲架構、基于HADOOP技術的問題數據分析架構、基于HAWQ的準實時評價引擎、采用多線程切片技術問題數據導出等關鍵技術研究,初步搭建基于HAWQ的電力企業數據質量管理應用系統。該系統在廣東電網有限責任公司進行試點應用,質量校驗效率提升明顯。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
石油瀝青(2021年4期)2021-10-14 08:50:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
Coco薇(2017年11期)2018-01-03 20:59:57
商周刊(2017年22期)2017-11-09 05:08:31
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
河南電力(2015年5期)2015-06-08 06:01:46
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
皖西學院學報(2015年5期)2015-02-28 17:52:46
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
