基于DA-Elman的鐵路貨運量預測
2020-12-26 08:22:30宋偉張楊
微型電腦應用 2020年12期
宋偉, 張楊
(1.陜西廣播電視大學 開放教育學院, 陜西 西安 710068; 2.國際商業機器公司, 陜西 西安 710100)
0 引言
鐵路貨運量預測對國家和區域經濟發展規劃具有至關重要的參考作用,高精度的鐵路貨運量預測為鐵路發展規劃的制定和運輸企業的運營決策提供科學決策的依據和參考[1]。目前,鐵路貨運量預測方法主要有灰色理論[2]、廣義回歸神經網絡[3]、BP神經網絡[4]、徑向基神經網絡[5]、Rough Set理論[6]、分形理論[7]、支持向量機[8]以及Elman神經網絡[9-11]等,但這些方法普遍具有預測精度低和滯后性明顯的缺點,需要進行定性分析和修正。
蜻蜓算法[12](dragonfly algorithm,DA)是受蜻蜓兩個聚集群體(遷徙群體和覓食群體)啟發所提出的群搜索智能算法。該算法具有控制參數少、復雜度低和計算速度快等優點,被廣泛地應用于模式識別、參數優化、工程優化設計等問題。針對極限學習機(extreme learning machine,ELM)模型性能受其初始權值和偏置的影響,文獻[13]將DA算法應用于ELM模型參數優化,實現小麥發芽粒和小麥蟲蛀粒檢測。為提高概率神經網絡(probabilistic neural networks,PNN)湖庫營養狀態識別精度,文獻[14]應用DA優化PNN模型的平滑因子,結果表明,DA可以有效提高PNN模型識別精度。為實現PID控制器最優化控制,文獻[15]選擇誤差性能指標ITAE為DA算法的適應度函數,運用DA算法優化PID控制器,實現PID控制器最優控制。與粒子群算法、布谷鳥算法和人工蜂群算法相比,DA優化PID控制器參數具有更優的控制性能。
針對Elman神經網絡(elman neural network,ENN)模型性能受權值和閾值選擇的影響,為提高鐵路貨運量預測的精度,運用蜻蜓算法優化選擇ENN模型的權值和閾值,提出一種DA優化Elman神經網絡的鐵路貨運量預測方法。實證結果表明,與PSO-Elman和Elman相比,DA-Elman的鐵路貨運量預測精度最高,為鐵路貨運量預測提供了新的方法和科學決策的依據。
1 蜻蜓算法
在DA算法中,蜻蜓個體在避撞、結對、聚集、覓食和避敵等行為綜合作用下進行覓食和尋優,不同行為描述如下[16-17]。對于第i個蜻蜓,其避撞、結對、聚集、覓食和避敵等行為的位置更新,如式(1)—式(5)。
(1)

(2)

(3)
Fi=X+-X
(4)
Ei=X-+X
(5)
式中,X為當前蜻蜓個體的位置;N為相鄰蜻蜓個體的數量;Xj和Vj分別為第j個鄰近蜻蜓個體位置和速度;X+和X-分別為食物源位置和天敵位置。
在5種蜻蜓群體行為綜合作用下,蜻蜓個體的步長向量更新策略,如式(6)。
ΔXt+1=(sSi+aAi+cCi+fFi+eEi)+wΔXt
(6)
式中,w為慣性權重;s、a、c、f、e分別為不同行為的權重;t為當前迭代次數。
蜻蜓個體的位置更新數學模型,如式(7)。
Xt+1=Xt+ΔXt+1
(7)
2 Elman神經網絡
ENN由輸入層(Input Layer)、隱含層(Hidden Layer)、關聯層(Association Layer)和輸出層(Output Layer)組成,其為局部反饋連接的前向神經網絡。其結構示意圖,如圖1所示。

圖1 Elman神經結構示意圖
與傳統的靜態前向神經網絡相比,ENN網絡增加了一個關聯層,也叫連接層,該層從隱含層接受反饋信號,隱含層節點數與關聯層節點數相等,兩者一一對應進行連接。圖1中,W1為輸入層到隱含層的權值矩陣;W2為關聯層到隱含層的權值矩陣;W3為隱含層到輸出層的權值矩陣;U(k-1)、X(k)、Y(k)和Xc(k)分別為ENN的輸入向量、隱含層輸出向量、ENN的輸出向量和關聯層的輸出向量,其數學模型[18],如式(8)。

(8)
式中,b1為隱含層的閾值;f(x) 和g(x)分別為隱含層和輸出層的傳遞函數;b2為輸出層的閾值。
3 基于DA-Elman的鐵路貨運量預測
3.1 適應度函數
針對ENN預測精度受其權值和閾值的影響,本文運用DA對ENN網絡的權值和閾值進行優化選擇,DA-Elman模型的適應度函數,如式(9)。
s.t.W1∈[W1min,W1max]
W2∈[W2min,W2max]
W3∈[W3min,W3max]
b1∈[b1min,b1max]
b2∈[b2min,b2max]
(9)
式中,n為訓練集個數;x(i)和y(i)分別為第i個樣本的實際貨運量和預測貨運量。[W1min,W1max]、[W2min,W2max]、[W3min,W3max]、[b1min,b1max]、[b2min,b2max]分別為W1、W2、W3、b1、b2的取值范圍。
3.2 算法步驟
基于DA-Elman的鐵路貨運量預測算法步驟如下。
Step1:讀取鐵路貨運量數據,劃分訓練集和測試集,并歸一化處理,如式(10)。

(10)
式中,x′為歸一化之后的數據;x,xmax,xmin分別為原始數據、原始數據中的最大值和最小值;a、b為歸一化之后的最小值和最大值,文中a=-1,b=1;
Step2:初始化DA參數:當前迭代次數t、最大迭代次數T、種群規模N和優化變量的上下限[W1min,W1max]、[W2min,W2max]、[W3min,W3max]、[b1min,b1max]、[b2min,b2max];
Step3:隨機初始化初始位置X和步長ΔX;
Step4:令t=1,將訓練集帶入Elman模型,運用式(9)計算蜻蜓個體的適應度并排序,記錄和保存當前最優解;
Step5:更新食物源位置X+、天敵位置X-以及s、a、c、f、e和慣性權重w;
Step6:按式(1)~(5)更新S、A、C、E和F;
Step7:按式(6)~(7)更新步長和位置;
Step8:若t>T,輸出和保存ENN模型的最優權值和閾值;否則,t=t+1,返回Step4;
Step9:將ENN模型的最優權值和閾值代入Elman進行鐵路貨運量預測。
4 實證分析
4.1 數據來源
為了說明DA-Elman鐵路貨運量預測模型的有效性和可靠性,選擇我國2000-2018年鐵路貨運量數據為研究對象,數據來源于國家數據網http://data.stats.gov.cn/,2000-2018年我國鐵路貨運量序列,如圖2所示。

圖2 2000-2018年我國鐵路貨運量圖
由于影響鐵路貨運量的因素很多,將鐵路貨運量作為DA-Elman的輸出,國內生產總值、鐵路貨運量、公路貨運量、公路運營路程、鐵路運營路程、鐵路復線比例、鐵路貨物周轉量和鐵路運輸從業人員等影響貨運量的因素作為DA-Elman的輸入。2000~2012年鐵路貨運量數據作為訓練集,2013~2018年鐵路貨運量數據作為測試集,前者建立DA-Elman鐵路貨運量預測模型,后者驗證DA-Elman鐵路貨運量預測模型的精度。
4.2 評價指標
選擇相關系數R和均方根誤差(root mean square error,RMSE)作為鐵路貨運量預測效果的評價指標[19-21],如式(11)、式(12)。
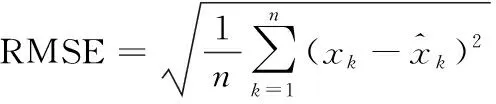
(11)

(12)
4.3 結果分析
Elman網絡參數為:N1=8,N2=16,N3=1;DA參數:最大迭代次數T=100,種群規模N=10,DA-Elman模型預測結果,如圖3所示。

圖3 DA-Elman鐵路貨運量預測結果
RMSE與種群規模關系圖可知,隨著種群規模的增加,預測誤差呈現增大趨勢,因此文中種群規模統一設定為10,如圖4所示。

圖4 RMSE與種群規模關系圖
將DA-Elman與PSO-Elman和Elman進行對比,粒子群算法(Particle Swarm Optimization Algorithm,PSO):最大迭代次數T=100,學習因子c1=c2=2,種群規模N=10。預測結果對比,如圖5和表1所示。
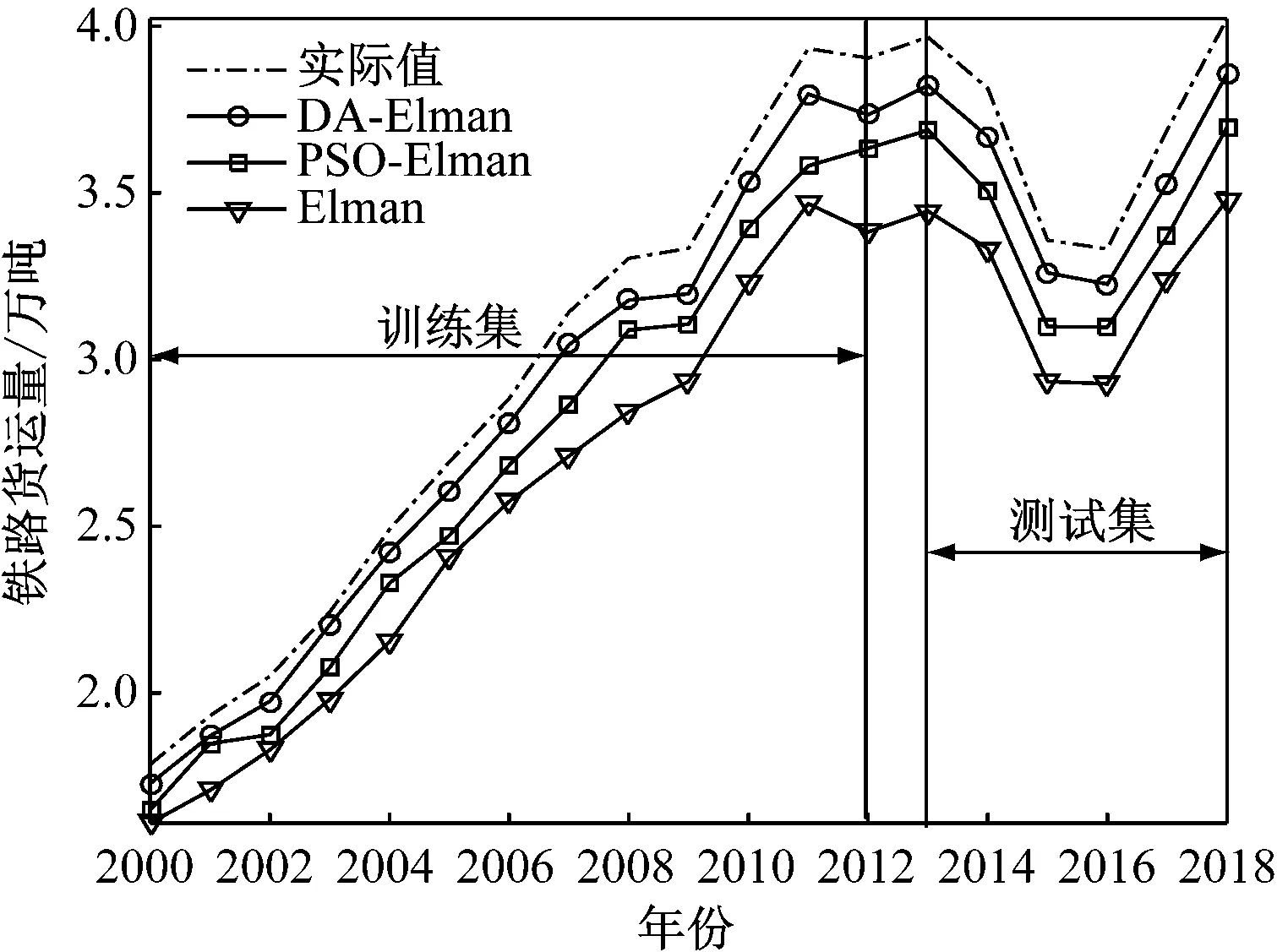
圖5 預測對比圖

表1 預測結果對比
由圖5和表1可知:(1) 從鐵路貨運量整體預測結果角度來看,在訓練集和測試集上,DA-Elman的RMSE最小且R達到最大,說明DA-Elman的鐵路貨運量預測值和鐵路貨運量實際值關聯程度最高,預測效果最好,DA-Elman優于PSO-Elman和Elman;(2) DA-Elman和PSO-Elman預測精度優于Elman,主要原因在于DA和PSO優化選擇了Elman模型參數,從而提高了Elman模型的預測精度。為了給鐵路部門和運輸企業提供科學決策的依據,運用DA-Elman鐵路貨運量預測模型對我國2019年~2021年的鐵路貨運量進行預測,如圖6所示。

圖6 鐵路貨運量2019~2021年預測結果
2019年~2021年我國鐵路貨運量預測結果分別為404 212萬噸、406 103萬噸和407 138萬噸。綜合分析可知,與PSO-Elman和Elman相比,DA-Elman的鐵路貨運量預測精度最高,為鐵路貨運量預測提供了新的方法和科學決策的依據。
5 總結
為提高鐵路貨運量預測精度,針對ENN預測精度受其權值和閾值的影響,提出一種基于DA-Elman的鐵路貨運量預測方法。選擇我國2000-2018年鐵路貨運量數據為研究對象,研究結果表明,與PSO-Elman和Elman相比,DA-Elman的鐵路貨運量預測精度最高,為鐵路貨運量預測提供了新的方法和科學決策的依據。
猜你喜歡
天天愛科學·科學啟蒙(2025年3期)2025-03-27 00:00:00
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
云南畫報(2021年12期)2021-03-08 00:50:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
鐵道通信信號(2018年7期)2018-08-29 01:17:04
光學精密工程(2016年6期)2016-11-07 09:07:19
通信電源技術(2016年4期)2016-04-04 02:58:04
工程建設與設計(2016年3期)2016-02-27 10:50:46
核科學與工程(2015年4期)2015-09-26 11:59:03
