生成對抗網(wǎng)絡(luò)下小樣本語音情感識別方法
2020-12-28 06:38:22高英寧崔艷榮孫存威
計算機工程與設(shè)計 2020年12期
高英寧,崔艷榮+,孫存威
(1.長江大學 計算機科學學院,湖北 荊州 434023;2.電子科技大學 計算機科學與工程學院,四川 成都 611731)
0 引 言
語音情感識別(SER)是指從語音數(shù)據(jù)里辨別出人類的情緒狀態(tài)[1]。SER方法里,提取情緒特征的質(zhì)量大幅度上決定著情感識別精度。傳統(tǒng)的特征提取方法一般是針對整句語音數(shù)據(jù),提取語速、基音頻率等情緒特征[2]。這種方式提取的特征往往會丟失掉語音數(shù)據(jù)中的部分情感特征和時頻兩域的相關(guān)性信息,導(dǎo)致情感識別精度低。
隨著深度神經(jīng)網(wǎng)絡(luò)的出現(xiàn),卷積神經(jīng)網(wǎng)絡(luò)(CNN)在圖片處理領(lǐng)域[3]和長短時記憶網(wǎng)絡(luò)(LSTM)在語音處理方面[4]取得了顯著成功。近年來語音情感識別領(lǐng)域引入了CNN[5]和LSTM[6],解決了傳統(tǒng)SER方法所出現(xiàn)的問題。基于深度神經(jīng)網(wǎng)絡(luò)的語音情感識別模型通常需要大量的訓練數(shù)據(jù)才能獲得一個良好的識別率[7]。若僅用小樣本的語音數(shù)據(jù)作為訓練集訓練模型,容易出現(xiàn)過擬合現(xiàn)象,使得泛化能力差,從而導(dǎo)致識別率低。
經(jīng)典的數(shù)據(jù)增強是對原數(shù)據(jù)集應(yīng)用微小變換進行數(shù)據(jù)增強[8]。一些常見的圖像數(shù)據(jù)增強技術(shù),如移位和旋轉(zhuǎn),不適用于文本或語音處理。相比之下,生成對抗網(wǎng)絡(luò)(GAN)側(cè)重于實際數(shù)據(jù)的模擬[9]。因此,本文使用Wasse-rstein生成對抗網(wǎng)絡(luò)[10](WGAN)對抗訓練來自主學習原始樣本的分布規(guī)律,生成新的數(shù)據(jù)樣本進行數(shù)據(jù)增強。目前,很少有研究人員將生成對抗網(wǎng)絡(luò)應(yīng)用于小樣本語音情感識別去解決小樣本情感識別率低的問題。因此,本文提出一種生成對抗網(wǎng)絡(luò)模型下的小樣本語音情感識別方法。
1 小樣本語音情感識別算法
針對本文提出的生成對抗網(wǎng)絡(luò)模型下小樣本語音情感識別方法,其算法流程如圖1所示。
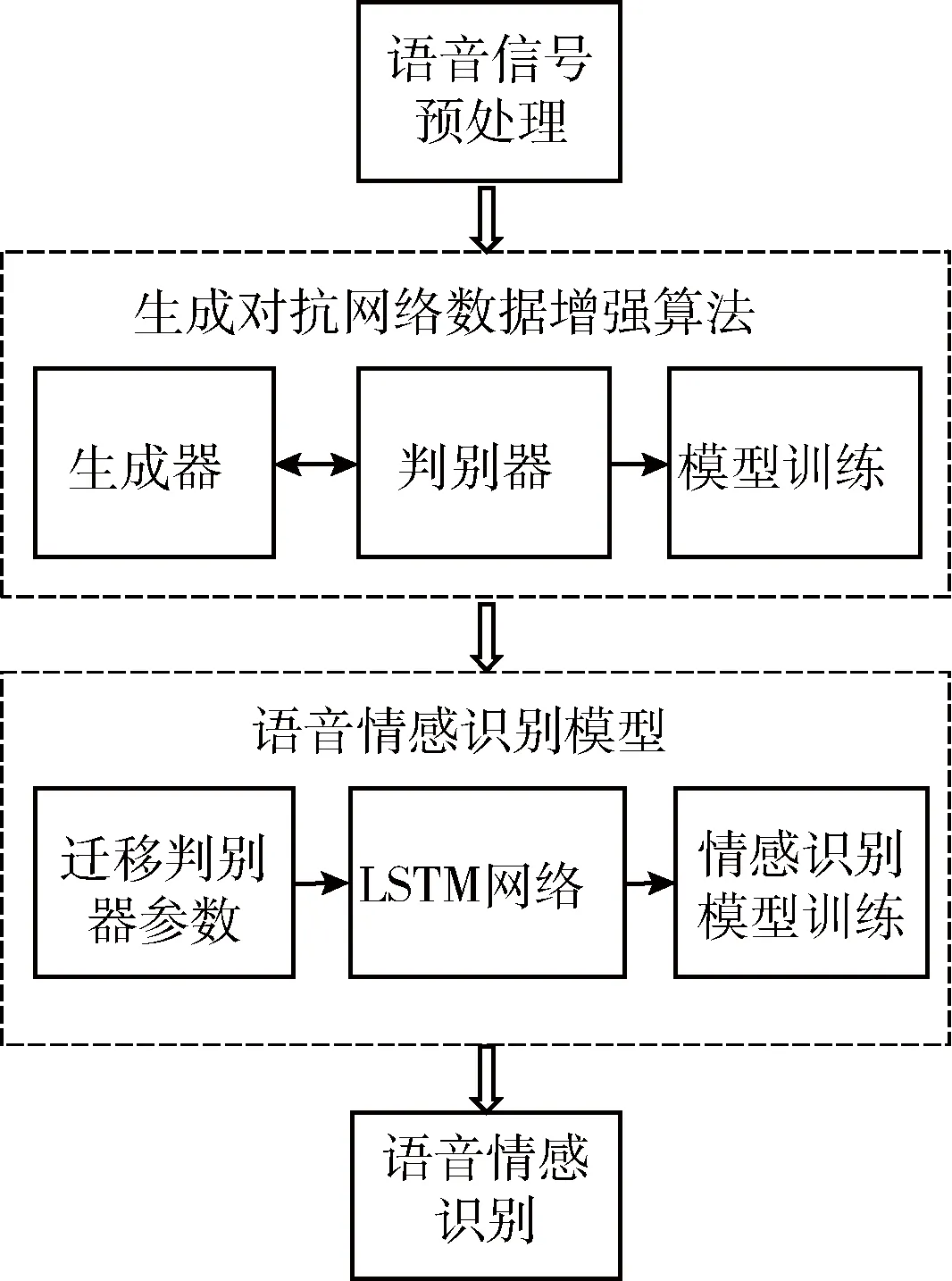
圖1 生成對抗網(wǎng)絡(luò)模型下小樣本語音情感識別流程
1.1 語音信號預(yù)處理
對語音情感數(shù)據(jù)進行預(yù)處理就是為了把語音的時域信號變成包括時域和頻域特征的語譜圖信號[11]。首先,對一段長的語音數(shù)據(jù)執(zhí)行分幀操作,把語音信號切割成大小相等的片段,其中的每一段為一幀,分別對每一個語音幀進行加窗處理,以減小信號中不連續(xù)部分的幅值,通過傅里葉變換計算出每幀語音數(shù)據(jù)的頻率譜,對其平方轉(zhuǎn)化得到對應(yīng)頻譜的能量譜,最后把所得到的結(jié)果按照時間維度拼接形成語譜圖,如圖2所示。
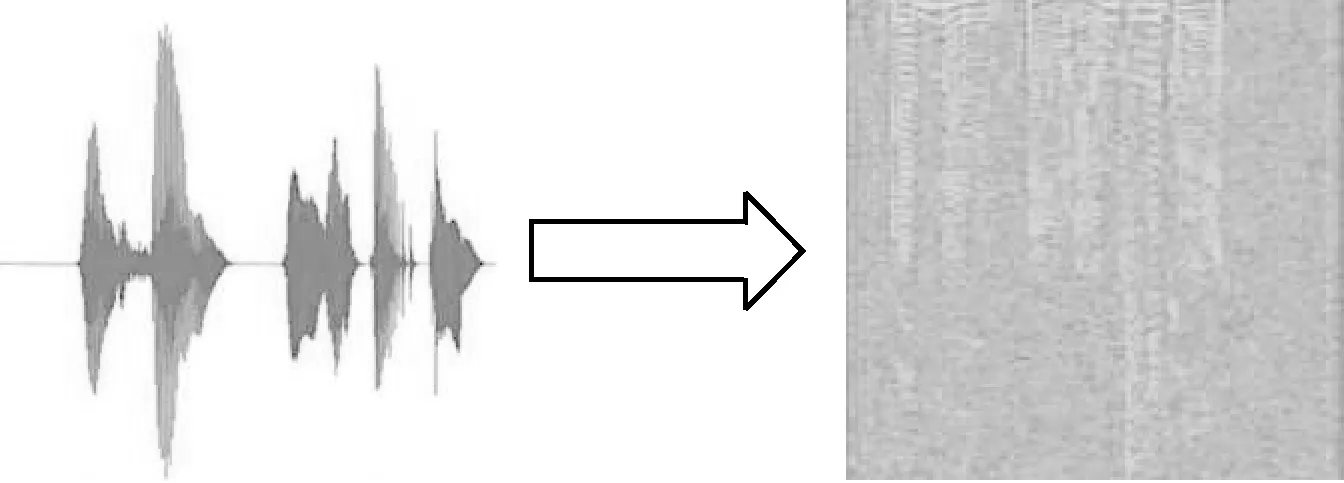
圖2 語譜圖
人們的情感變化可以清晰表現(xiàn)在語譜圖上。例如,人們傷心時,語速較慢,平均音調(diào)較低,語氣強度比較低,在語譜圖中深顏色部分的面積較小,相鄰條紋間隔較大。
1.2 生成對抗網(wǎng)絡(luò)數(shù)據(jù)增強算法
原始的GAN包含:生成器網(wǎng)絡(luò)(G)和判別器網(wǎng)絡(luò)(D)。G的任務(wù)就是通過輸入隨機分布噪聲z,產(chǎn)生盡可能擬合真實數(shù)據(jù)分布Pr的數(shù)據(jù)G(z),D的任務(wù)是盡可能辨別出輸入的樣本是來自數(shù)據(jù)集的樣本x還是模擬樣本數(shù)據(jù)G(z)。G的最終目的為最大化D判別錯誤的概率,D的最終目標是使得自己判斷正確的概率達到最大,即D(G(z))盡可能接近0,D(x)盡可能接近1,模型優(yōu)化函數(shù)如下式
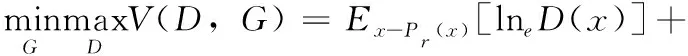
(1)
式中:Pr(x)為真實樣本的分布,Pg(z)表示隨機噪聲的分布。
GAN的訓練為G和D交替進行。理想的狀態(tài)下,該模型最終會找到一個全局最優(yōu)解,即D判斷不出輸入的數(shù)據(jù)是來自數(shù)據(jù)集的樣本x還是G產(chǎn)生的模擬樣本G(z)。
GAN的模型流程如圖3所示。
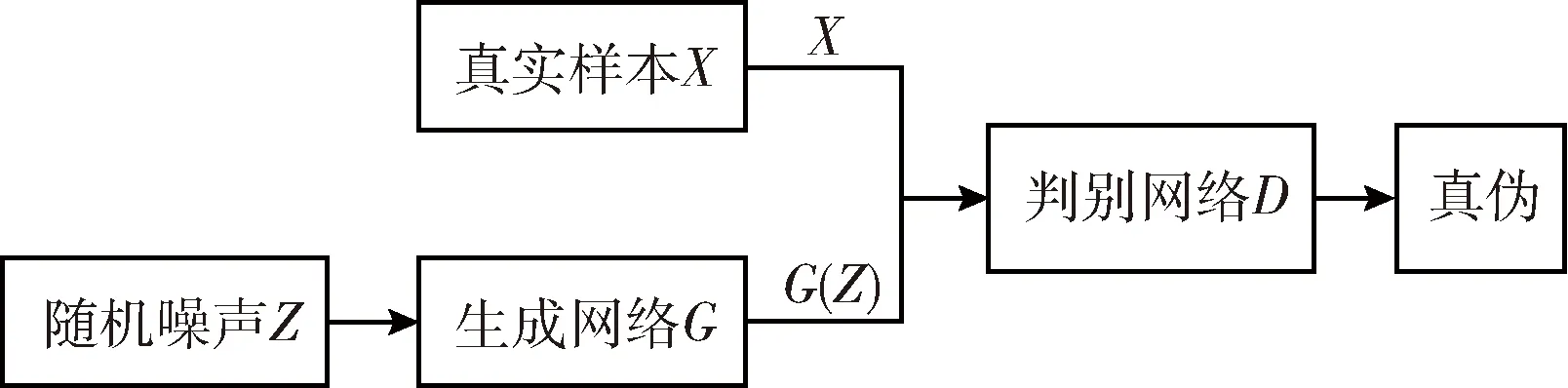
圖3 GAN的模型流程
由于原始的生成對抗網(wǎng)絡(luò)通過交叉熵(Jensen-Shannon divergence,JS)散度來衡量真實樣本數(shù)據(jù)和生成樣本之間的距離,會使得優(yōu)化目標函數(shù)式(1)出現(xiàn)梯度消失[12]。而WGAN是對GAN的一種改進,提出了使用Wasserstein距離來進行數(shù)據(jù)分布的比較,即使兩個數(shù)據(jù)分布之間沒有重合的部分,Wasserstein值也能很好地表示出兩個數(shù)據(jù)樣本距離的遠近,使得模型的訓練更加穩(wěn)定,基本解決了模型崩潰問題,優(yōu)化目標函數(shù)變?yōu)槭?2)
L=Ex~Pdata(x)[D(x)]-Ez~Pz(z)[D(G(z))]
(2)
根據(jù)式(2)可以得出生成器和判別器的損失函數(shù)如下式
Dloss=Ez~Pz(z)[D(G(z))]-Ex~Pdata(x)[D(x)]
(3)
Gloss=-Ez~Pz(z)[D(G(z))]
(4)
其中,x表示輸入的真實樣本,采樣于真實樣本Pdata(x),z表示輸入的正態(tài)分布噪聲,采樣于分布Pz(z)。
1.2.1 生成器
輸入的數(shù)據(jù)為100維的采樣于正態(tài)分布的噪聲,將輸入噪聲通過一個全連接層后維度轉(zhuǎn)換(Reshape)成(4,4,1024)的三維張量,經(jīng)過6層小步幅反卷積層進行上采樣,使得輸出特征圖大小逐漸擴大為前一層的兩倍,最終輸出一個維度為(256,256,3)的模擬樣本圖像,生成器模型如圖4所示。反卷積層的卷積核均為5×5像素,步幅大小為2,前5層反卷積層均使用ReLU非線性激活函數(shù),最后一層使用Tanh激活函數(shù)。同時在生成模型中添加批量歸一化方法,該方法避免了生成器模型把所有的樣本數(shù)據(jù)都收斂到同一個點,解決了初始化差的問題。
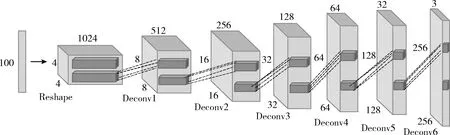
圖4 生成器模型
1.2.2 判別器
輸入數(shù)據(jù)為真實的樣本和生成的樣本,是一張維度為(256,256,3)的圖片,通過帶步長的卷積層進行下采樣,逐步學習輸入樣本的深層次特性,最后全連接層輸出判別器的判斷結(jié)果,判別器模型如圖5所示。卷積層的卷積核均為5×5像素,步幅大小為2,模型中所有層都需要使用Leaky ReLU激活函數(shù)。在判別器中添加批量歸一化方法降低初始化參數(shù)對訓練結(jié)果的影響,加快訓練速度。
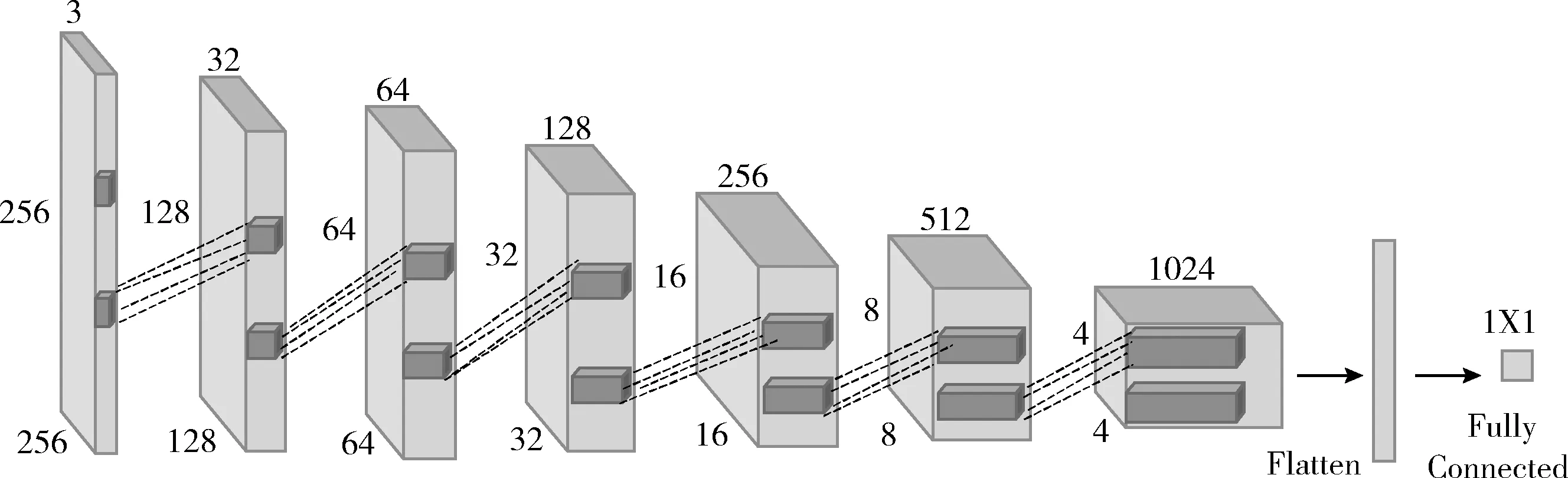
圖5 判別器模型
1.2.3 模型訓練
生成器模型的訓練需要先固定判別器的參數(shù)。輸入采樣于正態(tài)分布的噪聲z,對z進行一系列的小步幅反卷積操作和歸一化操作,輸出一批假的語譜圖,將它輸入到判別器模型。根據(jù)式(4)計算生成器模型的損失,依據(jù)判別器模型的判別結(jié)果以及數(shù)據(jù)集樣本和模擬樣本的Wasserstein距離,采用RMSProp算法調(diào)整模型的權(quán)重參數(shù),最小化Wasserstein距離。
判別器模型的優(yōu)化需要輸入真實樣本和生成器生成的樣本。根據(jù)式(3)來計算判別器模型的損失,判別器模型盡力去擬合出兩個輸入之間的Wassertein距離,采用RMSProp優(yōu)化算法調(diào)整權(quán)重參數(shù)。
訓練過程采用生成模型和判別模型交替訓練方法,為了防止過擬合的問題,加快收斂,在更新一次生成器參數(shù)之前,均需要更新判別器參數(shù)k次。
1.3 語音情感識別模型
1.3.1 遷移判別器參數(shù)
WGAN訓練完成時,G可以產(chǎn)生高質(zhì)量的模擬樣本,D學習到大量樣本特征。使用遷移學習,充分利用WGAN在訓練集上對抗訓練學習到的大量知識,將其用于解決語音情感識別率低的問題。本文遷移判別器模型包括除全連接層外的所有網(wǎng)絡(luò)層參數(shù),新的語音情感識別模型僅需要重新訓練最后的LSTM層和分類層,將G生成的模擬樣本作為訓練集訓練情感識別網(wǎng)絡(luò)。
1.3.2 LSTM網(wǎng)絡(luò)
由于循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)具有強大的記憶功能,適合使用上下文信息對序列數(shù)據(jù)進行建模,并得到相應(yīng)的輸出。然而RNN在學習長時序信息時,容易出現(xiàn)梯度消失。LSTM是對RNN的一種優(yōu)化,主要解決了訓練長序列信息時出現(xiàn)的梯度消失和梯度爆炸問題[13],圖6為LSTM的結(jié)構(gòu)單元。
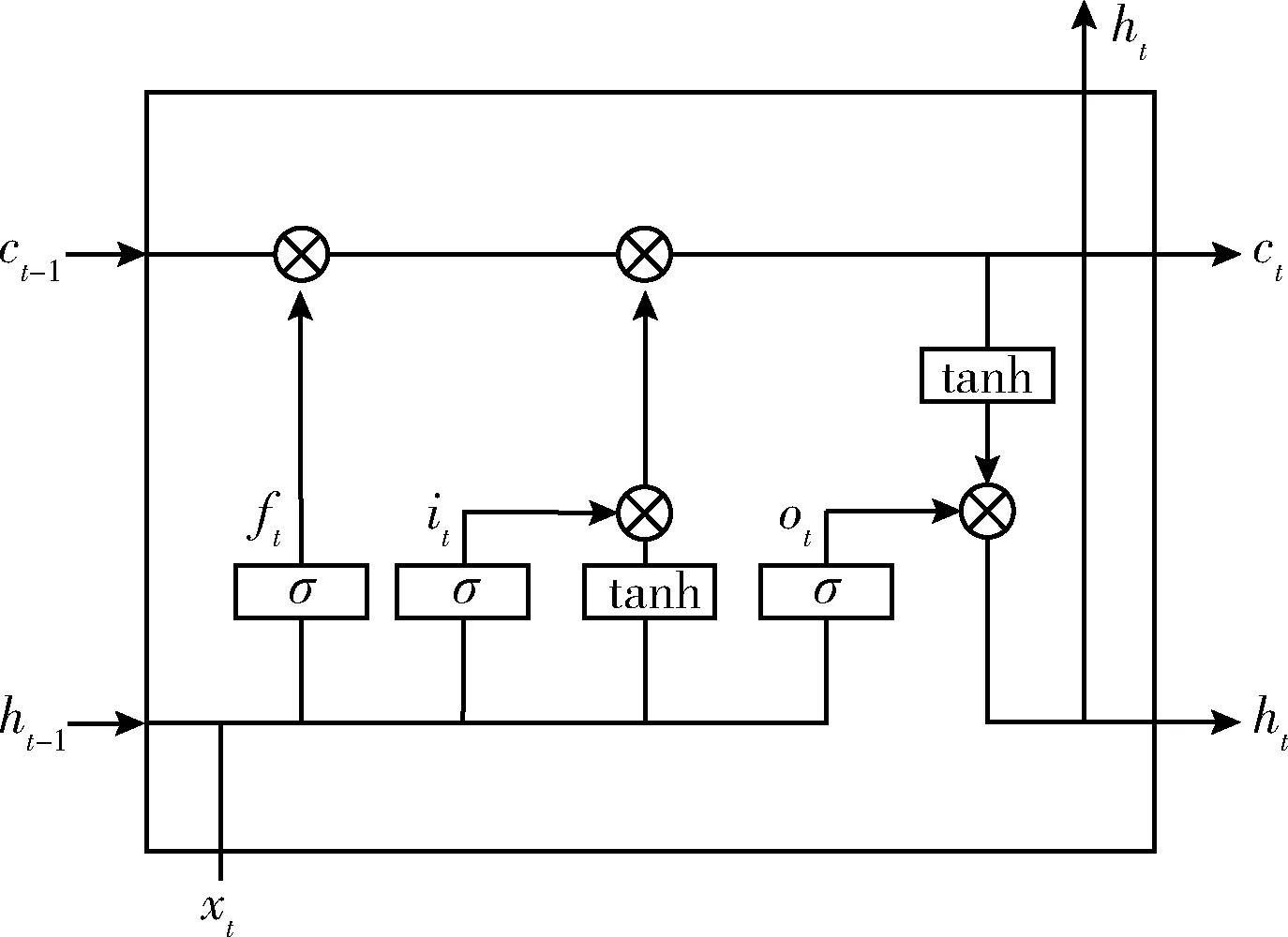
圖6 LSTM結(jié)構(gòu)單元
LSTM的計算公式可表示為
it=σ(Wixxt+Wihht-1+Wicct-1+bi)
(5)
ft=σ(Wfxxt+Wfhht-1+Wfcct-1+bf)
(6)
ot=σ(Woxxt+Wohht-1+Wocct+bo)
(7)
ct=ft·ct-1+it·tanh(Wcxxt+Wchht-1+bc)
(8)
ht=ot·tanh(ct)
(9)
其中,Wfx、Wfh、Wfc、bf為忘記門ft的權(quán)重參數(shù)和偏置項,Wcx、Wch、bc為記憶單元ct的權(quán)重參數(shù)和偏置項,Wox、Woh、Woc、bo為輸出門ot的權(quán)重參數(shù)和偏置項,Wix、Wih、Wic、bi為輸入門it的權(quán)重參數(shù)和偏置項,ht為LSTM網(wǎng)絡(luò)最后的輸出值。
利用LSTM網(wǎng)絡(luò)在時域上的建模能力,將語譜圖輸入卷積神經(jīng)網(wǎng)絡(luò)訓練后得到多張?zhí)卣鲌D。特征圖的橫坐標表示時域維度,縱坐標表示頻域維度,將其進行維度轉(zhuǎn)換,時域維度作為時間步長,特征圖數(shù)和頻域維度作為一個時間步的序列特征輸入,將其送到LSTM進一步提取特征。經(jīng)過對特征圖的維度重構(gòu)后,可以提取到語音樣本的深層次長時域上下文特征。
1.3.3 情感識別模型訓練
本文將訓練完成的生成對抗網(wǎng)絡(luò)的判別器模型和長短時記憶神經(jīng)網(wǎng)絡(luò)應(yīng)用到小樣本語音情感識別中。圖7為語音情感識別模型,對訓練完成的對抗網(wǎng)絡(luò)模型中的判別器網(wǎng)絡(luò)進行參數(shù)遷移,去掉最后的全連接分類層,在進行特征圖維度轉(zhuǎn)換,連接上兩層LSTM網(wǎng)絡(luò),隱藏節(jié)點數(shù)分別為1024、512,添加一層全連接層,通過softmax激活函數(shù)進行語音情感識別。在新的情感識別模型中進行參數(shù)微調(diào),損失函數(shù)采用交叉熵函數(shù),利用隨機梯度下降法調(diào)整權(quán)重參數(shù),使用生成樣本訓練語音情感識別網(wǎng)絡(luò)。
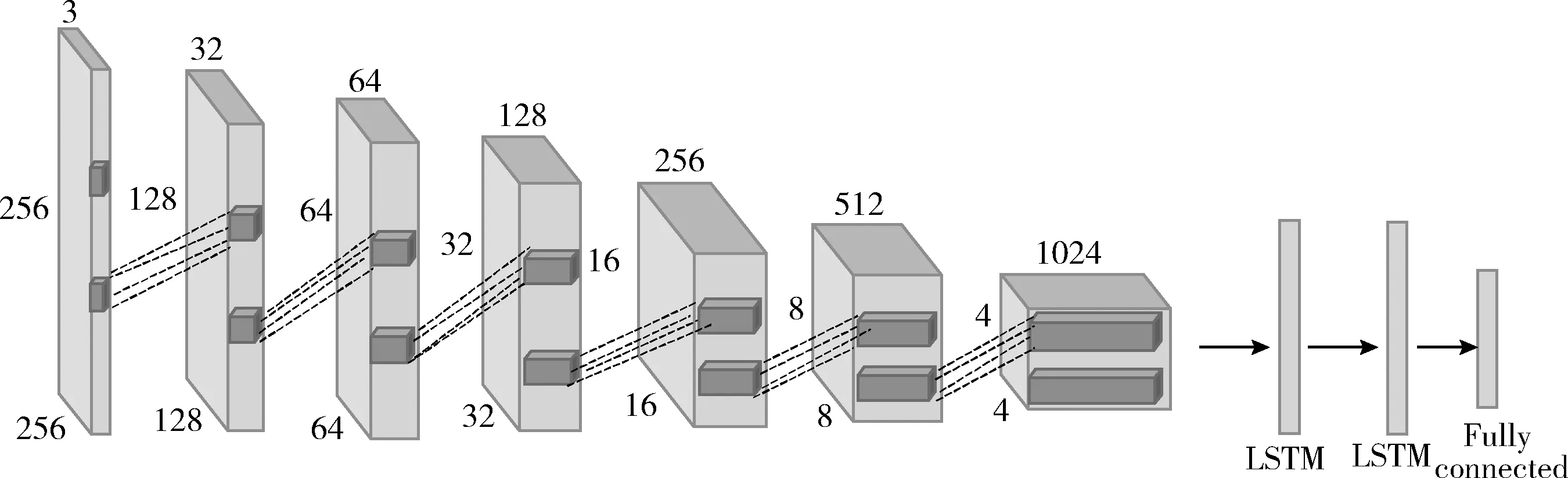
圖7 語音情感識別模型
1.4 語音情感識別
對于一個輸入的語音信號,經(jīng)過情感識別模型的特征提取得到Fi,將特征Fi輸入到全連接層,經(jīng)過softmax激活函數(shù)進行情感映射,即式(10)所示,所輸出的最大概率Si為情感識別結(jié)果
(10)
2 實驗結(jié)果與分析
2.1 實驗環(huán)境與數(shù)據(jù)集
本文實驗環(huán)境:操作系統(tǒng)為Windows10,深度學習框架為keras和Tensorflow,GPU為NVIDIA GEFORCE GTX 1060。選擇德語情感語料庫(EMODB)作為數(shù)據(jù)樣本。EMODB由10名專業(yè)錄音人對10句文本進行錄制,共535條數(shù)據(jù),包括7類情緒狀態(tài),分別為生氣、畏懼、開心、中性、傷心、驚訝、無聊。訓練集和測試集的比例設(shè)置為7∶1。
2.2 實驗設(shè)計
2.2.1 WGAN迭代次數(shù)對識別率的影響
本實驗使用訓練集對WGAN進行訓練,G和D的更新次數(shù)為1∶5。在WGAN不同迭代次數(shù)時,每條數(shù)據(jù)對應(yīng)生成50張語譜圖作為訓練集訓練本文語音情感識別模型,測試WGAN的迭代次數(shù)對語音情感識別準確度的影響。
圖8為語譜圖在經(jīng)過多次迭代后生成的模擬樣本圖片,圖9為WGAN的Wasserstein距離圖。由圖8和圖9可以看出,在模型訓練的開始階段,生成的語譜圖變化較為劇烈,Wasserstein距離較大。隨著實驗的不斷進行,產(chǎn)生的模擬樣本逐漸接近原始的數(shù)據(jù)樣本。當訓練迭代次數(shù)達到300時,發(fā)現(xiàn)圖9的Wasserstein距離趨于穩(wěn)定,說明模型訓練近似達到最優(yōu),得到了和原始樣本在視覺上具有高度相似性并且具有多樣性的圖像。

圖8 產(chǎn)生語譜圖效果
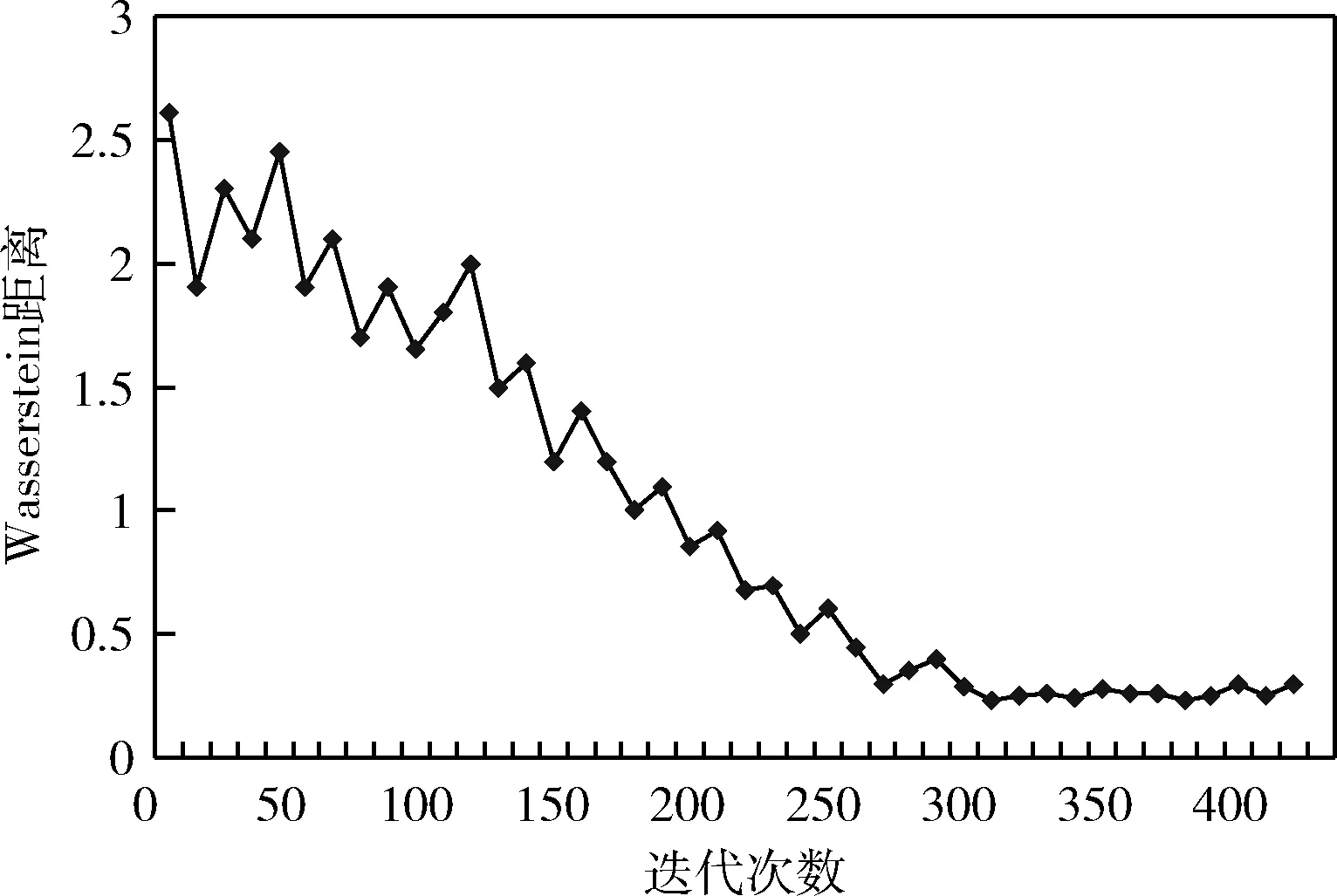
圖9 生成對抗網(wǎng)絡(luò)Wasserstein距離
圖10表示在本文語音情感識別網(wǎng)絡(luò)結(jié)構(gòu)下,使用生成器生成模擬樣本作為訓練集,測試生成對抗網(wǎng)絡(luò)在不同迭代次數(shù)下,對語音情感識別率的影響。
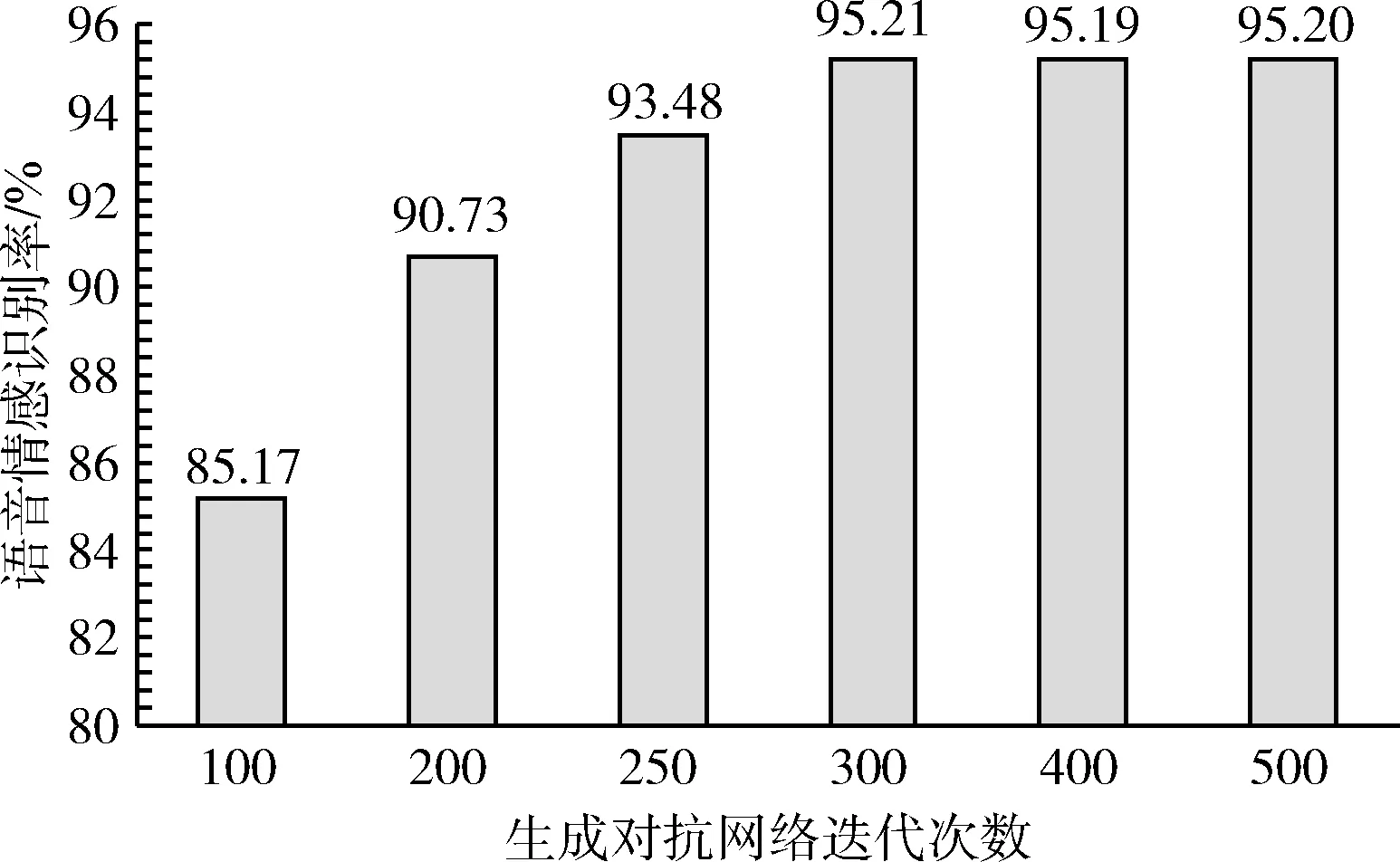
圖10 WGAN迭代次數(shù)對語音情感識別準確度的影響
由圖10可以看出,在WGAN訓練初期,由于對抗網(wǎng)絡(luò)變化劇烈,G生成的樣本質(zhì)量太差,對訓練集的擴充作用太小,導(dǎo)致識別率比較低。隨著實驗的不斷進行,生成的語譜圖逐漸接近原始數(shù)據(jù)樣本,生成的樣本對數(shù)據(jù)集有了較好的增強效果,使得語音情感識別率逐漸提高。然而實驗迭代次數(shù)到達300后,語音情感識別準確度趨于穩(wěn)定,這是因為隨著WGAN迭代次數(shù)增加,網(wǎng)絡(luò)逐漸處于收斂狀態(tài),G和D都達到了最優(yōu)狀態(tài)。
2.2.2 數(shù)據(jù)增強方法對比實驗
在相同條件下,使用本文語音情感識別模型,比較不同的數(shù)據(jù)增強方法,對情感識別準確度的影響。通過6組對比實驗來進行測試,實驗一使用原始訓練集訓練本文情感識別網(wǎng)絡(luò)。實驗二到實驗五分別采用對訓練集樣本等比例隨機轉(zhuǎn)動、隨機偏移、隨機縮放、隨機剪切方法將數(shù)據(jù)擴充50倍。實驗六采用WGAN來進行數(shù)據(jù)增強,在生成器和判別器對抗訓練300次時,使用生成器為訓練集中每條數(shù)據(jù)對應(yīng)生成50條模擬樣本作為訓練集。
由表1可知,實驗一采用不增強數(shù)據(jù)方式訓練語音情感識別網(wǎng)絡(luò),識別率為90.47%。實驗二和實驗三所使用的數(shù)據(jù)增強方法使得情感識別準確度有所下降,這是因為隨機轉(zhuǎn)動,隨機偏移改變了語譜圖的時序結(jié)構(gòu),導(dǎo)致丟失了很多情感時頻相關(guān)性信息,使得準確度下降。實驗四和實驗五所使用的數(shù)據(jù)增強方法使得情感識別準確度有略微提高,這是由于隨機縮放和隨機剪切保持了語譜圖中的時頻兩域信息的相關(guān)性,但是產(chǎn)生的增強數(shù)據(jù)缺少樣本多樣性,導(dǎo)致模型辨別能力沒有大幅度提高。而實驗六的準確度相比傳統(tǒng)方法有了很大的提高,這是因為WGAN使用語譜圖進行訓練時,不是簡單的對語譜圖進行擬合,而是通過G和D的對抗訓練對語譜圖進行特征學習,訓練完成后,G可以生成和原始圖像具有高相似度并且多樣性豐富的樣本圖像,使得模型識別能力有了顯著提高。
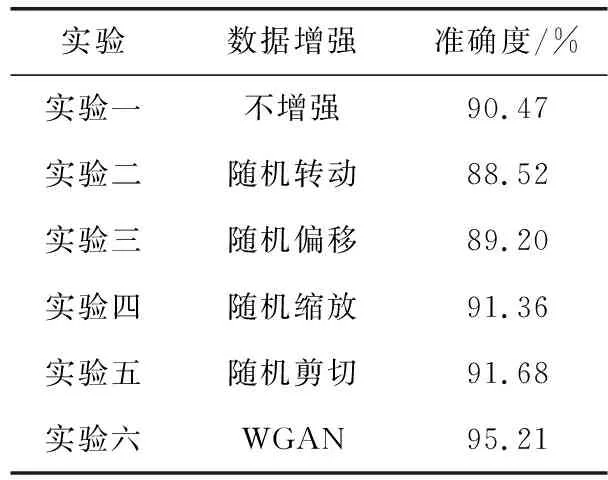
表1 數(shù)據(jù)增強對語音情感識別率的影響
2.2.3 參數(shù)遷移實驗
為了驗證本文中遷移訓練完成的WGAN的判別器參數(shù)的有效性,設(shè)計了兩組對比實驗。采用WGAN來進行數(shù)據(jù)增強,在生成器和判別器對抗訓練300次時,使用生成器為每條數(shù)據(jù)生成50條模擬樣本作為訓練集。
實驗一:使用訓練集訓練本文情感識別網(wǎng)絡(luò)。
實驗二:遷移訓練完成的WGAN的判別器參數(shù)到語音情感識別的模型,對其進行修改,去掉最后的全連接層,使用訓練集訓練本文語音情感識別模型。
由表2可以看出和不遷移模型相比,遷移WGAN判別器可以充分利用WGAN在訓練集上對抗訓練學習到的大量樣本特征知識,且只需要訓練情感識別網(wǎng)絡(luò)的最后LSTM層和分類層,提高了語音情感識別準確度,加快了網(wǎng)絡(luò)的訓練速度,減少了約3/5的模型訓練時間。
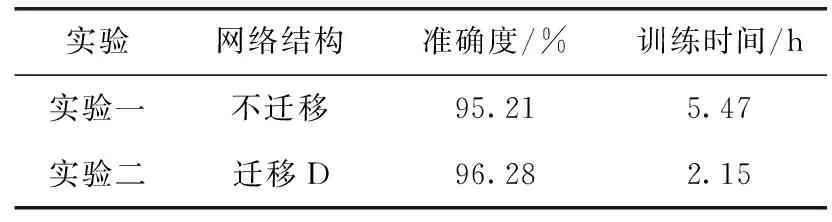
表2 遷移實驗下語音情感識別率和耗時的比較
2.2.4 語音情感識別方法對比實驗
為驗證本文方法的可行性,通過如下實驗來驗證。
實驗一:采用文獻[14]所使用的方法,通過手動提取語音中的基頻、共振峰等情感特征,使用SVM進行語音情感識別。
實驗二:采用文獻[15]提出的CNN模型,將小樣本語音數(shù)據(jù)預(yù)處理為梅爾頻譜圖,使用CNN對頻譜圖進行特征參數(shù)提取并識別。
實驗三:采用文獻[15]提出的CNN-LSTM模型,使用CNN提取頻譜圖特征參數(shù),把提取的特征圖進行維度轉(zhuǎn)換,將其輸入到LSTM層中進行語音情感識別。
實驗四:使用小樣本語音情感數(shù)據(jù)對WGAN網(wǎng)絡(luò)進行訓練,訓練完成后使用生成器生成模擬語譜圖樣本,并遷移判別器參數(shù),對其結(jié)構(gòu)進行調(diào)整,去掉全連接層,連接上LSTM層,對其參數(shù)精調(diào),使用生成模擬數(shù)據(jù)作為訓練集訓練情感識別網(wǎng)絡(luò)。
4種實驗下的語音情感識別率見表3。

表3 4種實驗下的語音情感識別率
由實驗一和實驗二可知,采用頻譜圖和CNN相結(jié)合的方法相比傳統(tǒng)的語音情感識別方法準確率更高。這是因為傳統(tǒng)的語音情感識別方法通過手工提取情感特征,會丟失部分時頻特征信息,而CNN通過強大的特征學習能力對頻譜圖進行自動提取特征,提取到了更深層次的情緒特征,從而準確度更高。實驗三使用CNN與LSTM相結(jié)合的網(wǎng)絡(luò)模型進行情感識別,利用CNN對頻譜圖進行自動提取特征,LSTM對特征圖進一步提取時序信息特征,相比單獨使用CNN模型提升了情感識別的準確度。然而由于前面的3組實驗的訓練樣本量偏小,模型收斂效果不好,導(dǎo)致準確度不高。而實驗四采用本文提出的模型,通過WGAN對抗訓練來增強數(shù)據(jù),遷移判別器的權(quán)重參數(shù)到情感識別模型,使得語音情感識別模型收斂速度更快,并且連接上LSTM網(wǎng)絡(luò)結(jié)構(gòu)后使得模型的識別能力更強,進一步提高識別準確度。
3 結(jié)束語
本文提出的一種生成對抗網(wǎng)絡(luò)模型下小樣本語音情感識別方法,使用小樣本語音數(shù)據(jù)對抗訓練WGAN,生成器和判別器對抗訓練學習樣本特征,生成器產(chǎn)生高質(zhì)量的模擬語譜圖樣本,解決了實際訓練過程中訓練數(shù)據(jù)不足的問題。遷移判別器網(wǎng)絡(luò)參數(shù)到語音情感識別模型,加快了網(wǎng)絡(luò)的收斂。對其進行參數(shù)微調(diào),去掉最后一層全連接層,連接上多層LSTM網(wǎng)絡(luò),充分提取語音信號的時頻兩域相關(guān)性信息,添加全連接網(wǎng)絡(luò)進行語音情感識別,進一步提高了語音情感識別準確度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中國生殖健康(2018年5期)2018-11-06 07:15:40
光學精密工程(2016年6期)2016-11-07 09:07:19
