基于YOLOv3的軍事目標檢測算法改進
2021-01-15 09:22:04張奔賈婧王偉
網絡安全技術與應用 2021年1期
◆張奔 賈婧 王偉
基于YOLOv3的軍事目標檢測算法改進
◆張奔 賈婧 王偉
(北方自動控制技術研究所 山西 030006)
YOLOv3目標檢測模型預設的anchor boxes是在VOC數據集上采用K-means聚類算法得到,并不適用于本文研究的巡飛彈對地目標偵察的使用場景。同時,K-means聚類算法在訓練數據集上無法得到穩定的最優解。本文通過改進聚類算法,并對軍事目標數據集重聚類后,更新anchor boxes數據。訓練模型后的avg-IOU和loss曲線表明,改進算法使模型更快速地收斂,同時能夠獲得更高質量的目標檢測結果。
YOLOv3;k-means;軍事目標;重聚類
巡飛彈在執行作戰任務的過程中,對地目標偵察是非常重要的一個環節[1],而YOLO系列目標檢測模型在實時目標檢測領域具有優秀的性能[2]。基于特征描述子的方法設計局部紋理特征,然后進行全局特征目標檢測[3]。后續基于深度神經網絡的方法有R- CNN,在此基礎上又發展出了Fast R-CNN、Faster R-CNN等[4]。本文通過對均值聚類算法的研究,改進K-means算法,從而提高聚類結果穩定性,改善模型訓練過程和目標檢測效果。
1 YOLOv3目標檢測算法
YOLOv3算法首先通過特征提取網絡Darknet53對輸入圖像提取特征[5],得到圖像對應的特征圖,大小比如13×13,然后輸入圖像可以被認為分成了13×13個grid cells,接著如果真實圖像中某個目標的中心坐標落在哪個grid cell中,那么就由該grid cell來預測該目標。每個grid cell都會預測3個邊界框,并給出相應的objectness score。最后通過非極大值抑制算法排除冗余的預測候選框,完成對圖像中目標的檢測。如圖1所示,網絡在每個Cell上會預測3個邊界框,其中每個邊界框會用5個預測值表示,分別是:,tx,ty,th,tw,to,其中前四個是邊界框坐標的offset值,最后一個是置信度。如果預測邊框的中心點距離對應Cell左上角的邊距為(cx,cy),而采用k均值算法得到的邊界框先驗維度(Bounding Box Prior)的高與寬分別為(ph,pw),則預測邊框的實際值見下圖1:
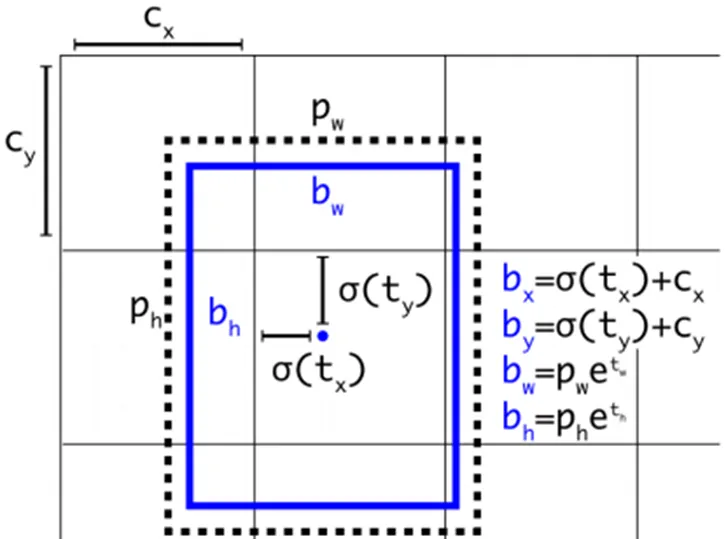
圖1 YOLOv3預測框計算
YOLOv3的損失函數為:

損失函數分別表示定位損失、置信度損失和分類損失,從函數的定位損失部分可以看出:在訓練的過程中,實際求得的是網絡預測值與聚類得到的anchor boxes值之間的偏移值。因此,改善聚類算法,使之得到穩定的最優解并且針對特定訓練數據集做重聚類,能夠改善模型的收斂狀況,獲得更佳的識別效果。
2 K-means聚類算法
YOLOv3目標檢測模型使用K均值聚類算法對voc數據集進行維度聚類,得到9個不同長寬比的anchor boxes ,以此代替配置文件中采用的原Faster R CNN中人為設定的anchor值[6]。
K-means聚類分析是利用數據的相似性,對聚類數據集進行劃分[7]。其數據類別相似性指標一般采用歐式距離。對數據集劃分成k個預先設定的類別,使每個類別所包含的數據點最為相似且不同類別之間的數據差異盡可能最大化。假設數據集X包含n個m維的數據點,相似性指標采用歐式距離分成K個類別,則各類包含數據點的聚類平方和最小時,達到聚類目標:

K-means通過多次迭代得到最終的k個聚類中心,算法流程如下:
(1)隨機產生k個分別代表一個聚類中心的初始質心;
(2)對每個數據點對象都計算與各個初始質心的歐式距離,以最小距離為標準進行歸類;
(3)對每個類別中所有屬于該類的數據點位置統計計算,得到新的質心;
(4)重復2、3步驟,直到各個類別的質心不再改變,從而得到最終的聚類結果。
K-means這種采用貪心算法的聚類思路,前提是需要人為指定k值。從相關的仿真實驗中可以看出,采用K-means算法對數據集多次聚類,聚類結果有較大差異性,很難得到穩定的最優解。
3 K-means聚類算法改進
針對上述問題,對K-means聚類算法的改進集中在選擇相互衡量指標盡可能大的點作為初始質心,改進算法的流程如下:
(1)隨機選擇數據集中的一個數據點作為第一個聚類中心;
(2)計算每個數據點與其最近的聚類中心之間的距離d(x),統計得到距離累加結果sum(d(x));
(3)隨機采用一個閾值,若累加后的種子點距離高于閾值,則設為下一個種子點,然后嘗試更新選擇作為聚類中心的數據點,選擇包含數據較多的點,被選中作為新的聚類中心的概率應較大;
(4)重復2、3步驟,直至選出k個初始質心;
(5)執行K-means算法,得到最終聚類結果。
目標檢測的圖像數據集,采用矩形框來人工標注圖像中的目標。大小不同的矩形框做聚類時,若采用歐式距離,會產生較多的損失誤差。聚類的目的是要獲得相對于所有矩形框而言更高的交并比得分,而這個分數實際上是與矩形框的大小沒有關系,所以改進算法所采用的聚類標準為IoU距離公式:

4 實驗
4.1 實驗數據集
實驗圖像數據采用模擬器生成,以巡飛彈對地偵察目標為應用背景,采集空中俯視角度下的自行火炮、軍用卡車、軍用吉普車3種軍事目標圖像資料。模擬圖像的尺寸為1920×1080,其中目標所占像素點分布在50×50到300×300之間。整個軍事目標數據集包含2191張圖片,其中包含目標:自行火炮6436輛,軍用卡車1998輛,軍用吉普車3009輛。數據集按照4:1的比例分為訓練集和驗證集。使用標圖軟件對上述3種類別的目標全部進行標記,生成2191個xml文件。
4.2 實驗環境
實驗環境:操作系統為ubuntu16.04;中央處理器為;GPU為GTX2080TI;GPU加速庫:CUDA10.1、CUDNNv7.5.6、OPENCV-3.4.4;編程語言為Python2.7、C++語言。深度神經網絡的配置參數如表1所示。

表1 訓練配置文件主要參數設置
4.3 實驗方法
按照K-means算法和改進聚類算法的流程,分別編寫兩個python腳本文件,將聚類K值設定為9,在ubuntu系統的終端下分別運行,得到聚類結果。由于YOLOv3的特征提取網絡對輸入圖像進行32倍下采樣,故聚類得到的9對高寬比需要乘32后寫入到訓練配置文件中才能正確應用。
K-means算法和改進聚類算法分別對軍事目標數據集聚類得到anchor boxes,保持模型的其他參數一致的情況下,分別采用兩種聚類方法得到的anchor boxes對模型進行訓練,對比實驗結果。
4.4 實驗結果
如圖2所示,黑色矩形圖標表示VOC數據集下聚類得到的anchor boxes,紅色圖標表示采用K-means算法對軍事目標數據集進行10次聚類后的結果,可以看到,聚類的結果并不穩定。
采用改進聚類算法對軍事目標數據集進行10次聚類,結果穩定,最后的聚類結果為:0.43、1.11、0.71、0.79、2.07、1.10、1.18、1.33、3.23、1.75、1.78、1.94、5.24、2.75、2.76、3.79、4.57;平均IoU為0.733485。隨機選取K-means算法的一組聚類結果:0.49、0.87、0.67、1.75、0.94、0.92、1.11、2.59、1.57、4.15、1.61、1.63、2.35、5.63、2.62、2.59、3.83、4.18;平均IoU為0.729859,分別乘32后寫入配置文件進行訓練,實驗結果如圖3、4、5所示。
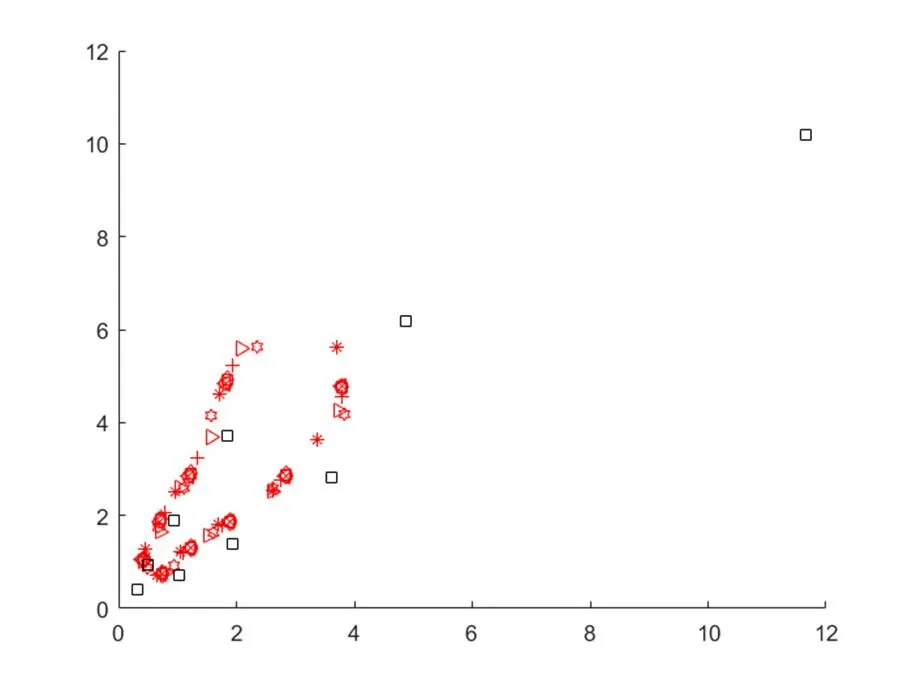
圖2 聚類結果對比
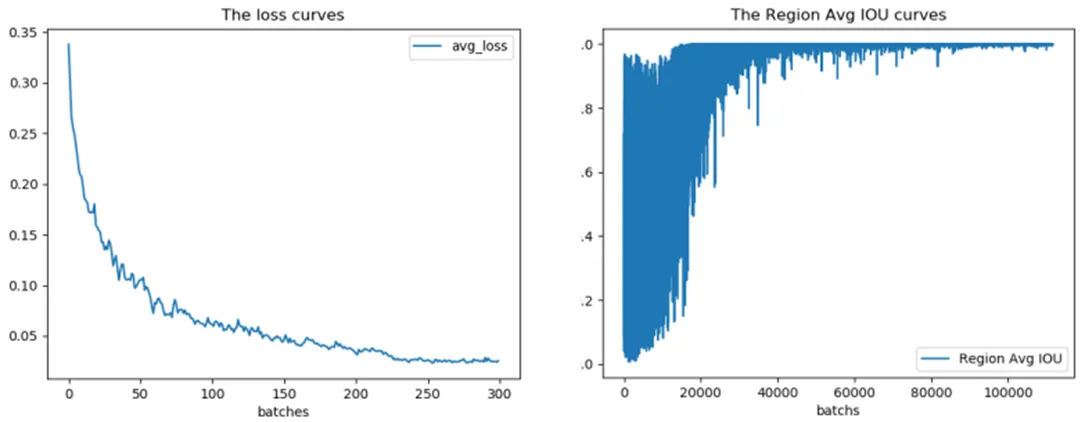
圖3 K-means算法訓練loss和Avg IOU曲線

圖4 改進算法訓練loss和Avg IOU曲線

圖5 采用改進算法(右)聚類結果的識別效果對比
采用改進聚類算法結果的模型相比K-means算法,在反映模型訓練過程的loss和Avg IOU曲線圖中都有更好的表現,識別效果圖中也可以看出對目標的標記更加精準。
5 結語
本文研究了YOLOv3算法中對訓練數據集進行聚類分析的算法,針對聚類得到的anchor boxes對模型神經網絡訓練的影響作用,做了針對性的改進。對比實驗結果表明改進算法能夠得到穩定的聚類結果,并且對網絡訓練的收斂情況有明顯的提升,同時最后模型的目標檢測效果也有所改善。
[1]郭美芳,范寧軍,袁志華.巡飛彈戰場應用策略[J].兵工學報,2006,27(5):944-947.
[2]Redmon J,Divvala S, Girshick R, et al.You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2016:779-788.
[3]Dalal N,Triggs B. Histograms of oriented gradients for human detection[C]. Computer Vision and Pattern Recognition.2005:886-893.
[4]邢志祥,顧凰琳,錢輝,等.基于卷積神經網絡的行人檢測方法研究新進展[J].安全與環境工程,2018,25(6): 100-105.
[5]Redmon J,Farhadi A. Yolov3:An incremental improvement[J]. arXiv preprint arXiv:1804.02767,2018.
[6]蘇飛.高維數據的聚類分析研究與應用[D].華北水利水電大學,2017.
[7]田瀟瀟.基于多分類的主動學習改進算法[D].河北大學,2017.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
