基于分布式計算模型的施工工序關聯分析
2021-01-18 08:17:18唐朝國鄒文露
高速鐵路技術 2020年6期
楊 科 唐朝國 袁 焦 伏 坤 鄒文露
(中鐵二院工程集團有限責任公司, 成都 610031)
在鐵路工程建設期間,施工質量問題時有發生,分析這類問題發現,其中相當一部分問題是由施工工序安排不當造成的。其原因在于施工安排在很大程度上依賴于現場管理人員的知識和經驗,人為因素影響較大,在進度壓力下,往往易忽視施工工序的規律性。
施工工序為鐵路工程風險管理提供了基礎支撐,是定位風險事件的最小單位,尋找工序之間的邏輯關系,再根據現場實際選擇合理的工序安排,能幫助現場施工人員緩解和預防風險的發生[1]。
施工工序的安排具備客觀性,若能通過分析現場施工數據,找到工序之間的規律,勢必能夠改善風險控制、成本監控、進度管理等過程。隨著鐵路工程電子施工日志在全國鐵路建設項目中的普及,施工現場數據逐漸被統一、規范,為上述問題的解決提供了數據基礎。本文將利用分布式計算框架,借助鐵路工程實體分解結構(EBS)[2],從海量施工日志數據中尋找鐵路工程施工工序之間的規律。
1 現狀分析
1.1 電子施工日志和EBS
電子施工日志系統利用信息化的方式將以往紙質的施工日志統一規劃,將施工現場的技術情況、安全檢查情況、質量檢查情況等管理起來,以桌面應用、移動應用的方式呈現,方便現場用戶進行填報。
EBS是鐵路工程實體分解結構的縮寫,由中國鐵路BIM聯盟于2014年發布。不同于基于工作分解結構(WBS)[3],EBS結構按照專業將工程系統分解為樹形結構,更滿足工程系統的特點,更利于鐵路工程管理。電子施工日志提供的數據采集功能就是以EBS為紐帶串聯起來。橋涵專業的部分EBS項如表1所示。

表1 橋涵專業部分EBS項列表
1.2 分布式系統
作為一款采集現場數據的信息系統,施工日志具備面向事務系統(OLTP)的所有特征,其數據通過關系型數據庫進行存儲,根據業務的不同,將數據分散到不同的數據表中。采集端在確認用戶信息后,在本地將用戶每日填報的現場環境、施工進度、材料使用情況、人員投入情況等打包上傳,通過互聯網集中傳輸到應用服務器,并最終進入到數據庫中。這樣的方式可使業務系統快速響應各個增刪查改的需求,但面對耗時、海量查詢的統計分析需求時,就顯得力不從心,強行在OLTP系統上執行統計分析,反而會使業務的處理率下降,甚至造成數據丟失,嚴重影響系統的推廣使用。
目前,已有很多研究對鐵路工程的“大數據”統計分析進行了實施和應用[4]。隨著分布式系統逐步成為大數據的核心技術,以Hadoop生態圈為代表的平臺將為工程的建設業務提供解決方案,為項目的成功落地提供技術保障[5]。
1.3 關聯分析和R語言
關聯分析是數據挖掘的一種主要方法,用于查找隱藏在數據集合中的頻繁模式,即集合中各項之間存在的關聯規則。利用支持度和置信度兩個指標來保證找到有意義的規則,避免某些偶爾出現規則對于整個模型的影響。Apriori算法是關聯分析的常用算法,解決了很多潛在頻繁模式的挖掘問題(如經典的“啤酒尿布”案例等)。
R語言是一門用于統計分析的編程語言和開發環境,包括了豐富的統計算法和制圖函數,更加貼近統計學家的使用習慣,在大數據前沿科學的研究中使用更加廣泛。如RHadoop[6]利用MapRecude[7]API集成了常用的R函數,使數據分析人員能夠利用R語言進行HDFS、HBase的連接和訪問,再配合R語言強大的數據分析能力,快速實現分析目標。但這類軟件也存在缺點,如RHadoop對于數據庫的支持就較弱,沒有API直接訪問Hive,通過RJDBC訪問需對數據進行轉換,比較耗能。
1.4 施工工序的關聯分析
施工工序是項目管理的基礎,要實施施工組織管理信息系統,就需建立可靠的施工工序活動。傳統常利用需求工程方法,從現場環境、人員、設備、材料到場情況等維度,向項目管理人員、施工技術人員收集原始信息,依靠他們的豐富經驗和知識來保證系統的可靠性。但從信息系統的角度來看,領域知識的獲取最為困難,易導致后期模型的不確定性。另一個方法是依賴現場數據,從實際工作中尋找客觀規律。施工日志為我們提供了數據來源,但面對海量的數據,傳統的分析方法在時間耗費、資源占用上都已滿足不了實際需要。面對用戶需求和分析方法的矛盾,采用分布式架構,解決數據的大容量可靠存儲以及分析的并行計算,勢必會成為施工日志數據向應用轉換的唯一途徑。
2 關聯模式分析
2.1 數據及數據模式
要構建海量數據基礎上的關聯分析,必須首先分析現有數據的內在關系,構建穩定、成熟的數據模式。在施工日志中,工序相關的數據分散在多張數據表中,具備典型的多維數據特點。為便于分析,且保證分析過程不影響業務系統的正常運行,需對多維數據進行抽取、轉換和加載(ETL過程),最終進入分布式存儲系統之中。
具體而言就是將多源數據平面化,這些平面化數據稱為“現場數據”(如表2所示),數量已達到億級,需要借助Sqoop工具,用命令行的方式執行相關SQL并導入HDFS。根據不同的分析維度(如每天、每周、每月等),靈活地執行不同的SQL語句,抽取相應的數據結果。

表2 數據分析原始數據表
2.2 關聯分析的分布式設計
R語言在Hadoop上已有成熟的應用,統計分析人員也更習慣于采用RHadoop進行數據分析,雖然已有其他編程語言(平臺)實現甚至改進了分布式系統上的關聯分析算法[8],但可惜的是R語言提供的arule包的對應算法并不支持分布式計算,在面對海量數據時,無法保證處理效率。因此需尋求一種基于MapReduce模型的算法來支持大數據的分析計算。
2.2.1購物籃化過程
Apriori所需的事務數據集以某一屬性為維度,聚合該維度下的數據。現場數據是每日施工情況的流水賬,應當以“工點”+“日期”為維度,聚合多道工序,該過程可稱為“購物籃化”。其數據結構如表3所示,分布式流程如圖1所示。
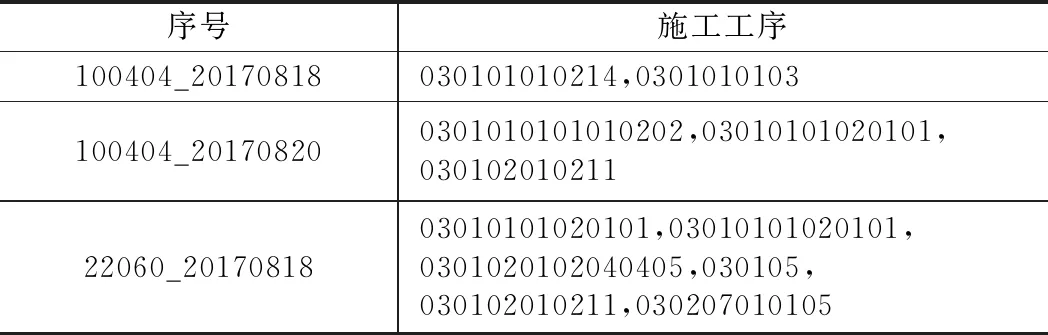
表3 事務數據集(購物籃化)表
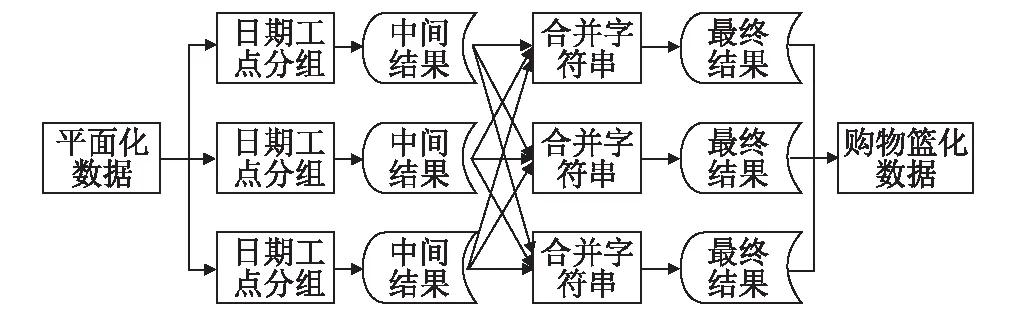
圖1 購物籃化現場數據MapReduce流程圖
輸入數據是平面化的數據,每一行包含一組施工信息,處理邏輯可分為兩個子流程。首先是將同一天、同一工點的數據找出來的分組邏輯,然后是將同一分組內的工序(EBS編碼)拼接并以逗號分隔的合并邏輯,最終輸出到HDFS之中。對應到RHadoop的相關開發包,需在Map任務實現第一個子流程,在Reduce任務實現第二個子流程。鑒于第一個子流程產生的中間結果比較龐大,利用RHadoop提供的Combine任務,可對結果進行合并,只需實現和Reduce的相同邏輯,即可減輕網絡負載,減小Reduce任務執行期壓力。Reduce任務還可過濾聚合后只有一道工序的記錄,降低下一過程的計算量。
2.2.2初始化頻繁1-項集過程
頻繁1-項集是從購物籃化的數據中,抽取只包含1條EBS編碼的作為項。該過程需從購物籃化后的數據中生成,由于數據量預期都會很大,因此還需借助MapReduce來實現。其具體流程如圖2所示。
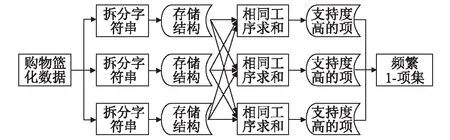
圖2 生成頻繁1-項集MapReduce流程圖
2.2.3生成候選k-項集過程
該過程在一個循環體中。候選項集的生成有很多種算法,主流的算法是對頻繁(k-1)-項集自身做組合,生成候選k-項集。一個專業的EBS編碼大概在 1 000~20 000區間內,組合以后滿足支持度閾值的更少,因此該過程可在內存中進行計算,以提高整體分析的速度。候選集的算法過程如圖3所示。
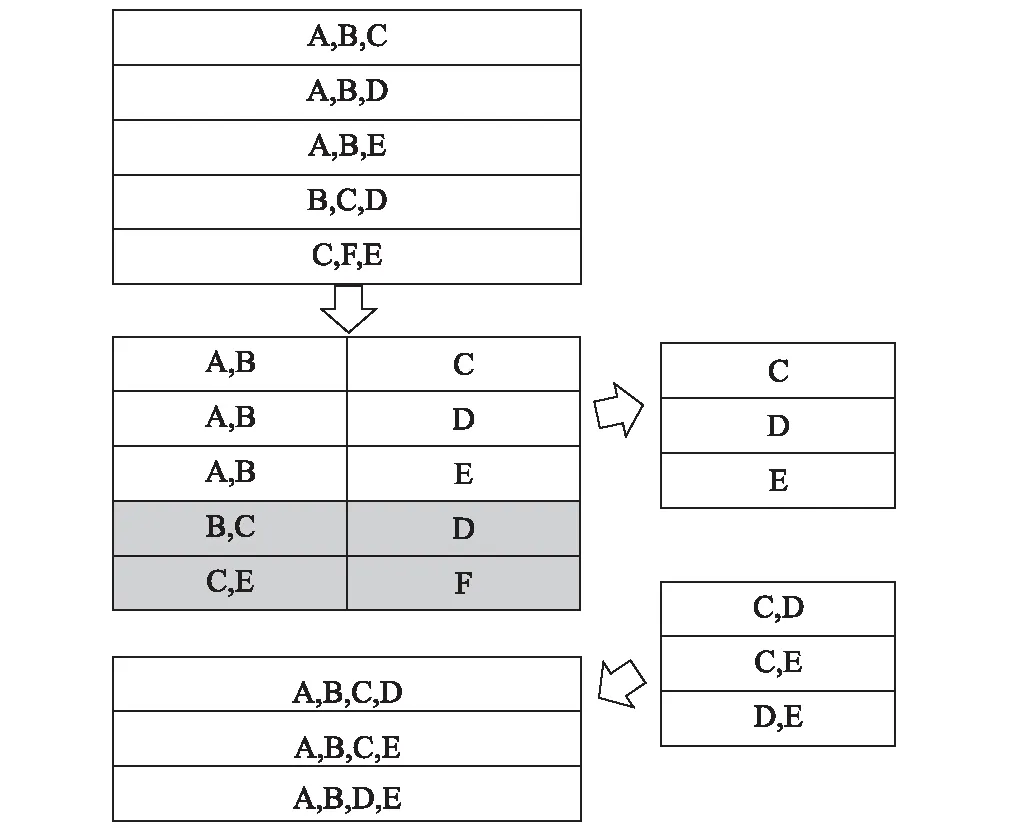
圖3 生成候選k-項集流程圖
圖3是一個頻繁3-項集生成候選4-項集的過程,A-E代表了1條EBS編碼,由于BC、CE開頭的只有一項,根據Apriori定理,不會產生頻繁項,因此直接淘汰,從ABC、ABD、ABE中生成。
2.2.4生成頻繁k-項集過程
該過程和上一個過程在同一個循環體內,利用上一過程產生的候選k-項集,在購物籃中遍歷查找是否存在這樣的項,找到1次計數加1。當數據量較大時,在購物籃中遍歷查找也是一個非常消耗性能的操作,必須把該過程放到Map中,實現數據的分而治之,隨著Map計算節點的增加,遍歷的時間會得到有效的控制。其具體流程如圖4所示。
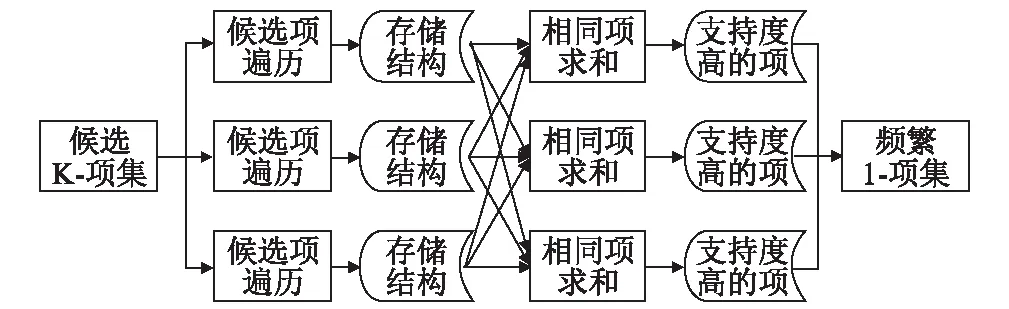
圖4 生成頻繁k-項集MapReduce流程圖
每次循環產生的頻繁k-項集加入到頻繁項集集合F中,若沒有產生頻繁k-項集,則終止循環體。
2.2.5從頻繁項集生成關聯規則
從尋找工序間的關聯關系而言,頻繁項集F已經夠用,但從尋找工序的規則而言,還需對頻繁項集F進一步加工,該過程在內存中進行計算。
規則的生成依賴于置信度,以頻繁項集t:{0301010101010108,03030101010102,030301010211}為例,其有6個規則,如{0301010101010108}→{03030101010102,030301010211}、{03030101010102}→{0301010101010108,030301010211}、{03030101010102,030301010211} → {0301010101010108}等作為候選,表示為{Left}→{Right},通過在頻繁項集集合F中計算該頻繁項集支持度δ(t)與箭頭左邊的項集支持度δ(Left)的商,即得到confidence(Left→Right)。無論{Left}還是t肯定存在于F中,支持度已知,整個計算過程并不會消耗太多資源。
3 分析結果
3.1 模型好壞的評價指標的制定
從上述的設計、實現過程可知,施工工序的關聯分析依賴于“支持度閾值”的制定。“支持度閾值”是整個分析的關鍵指標,該指標決定了模型的好壞以及計算的時間、空間復雜度。因此,采用均衡計算量+用戶評價的方式,先實驗一個較低的支持度閾值(如0.55),將獲取到的規則交給現場施工人員、技術專家評價,再增大或降低支持度閾值[9],力求達到計算量與可信模型之間的平衡。
3.2 實驗結果
本文通過分析百萬級橋涵專業施工日志的數據,得到實驗結果如表4所示。

表4 橋涵專業工序頻繁集表(百萬級)
根據EBS代碼反查工序名稱,發現橋墩地基承臺的“混凝土”和“鋼筋”頻繁出現在施工工序安排中,這與施工現場的實際情況相吻合。利用同樣的算法,再選取施工日志填報優秀的橋涵工點進行分析,獲取更加精準的實驗結果,如表5所示。

表5 橋涵專業工序頻繁集表(十萬級)
根據EBS代碼反查可知,“預應力混凝土簡支箱梁架設”與“球型鋼支座”的關聯程度較高,在日常工作安排中,可考慮兩者先后施工。
4 結束語
在調用傳統的R函數進行關聯分析時,內存占用會明顯增長,易導致整個分析系統崩潰。采用分布式的Apriori算法,在處理施工日志的海量數據時,內存消耗低,且并行的處理方式也降低了分析時間。在此基礎上,本文分析了鐵路工程施工工序,獲得了現場工序安排的規律,為管理人員把握施工進度、合理安排現場工作提供了一種智能化的解決方式。可以預見,隨著電子施工日志的逐步普及,越來越多的項目會采用電子日志進行填報,未來的數據質量、數量會進一步增加,最終提高分析結果的精度和覆蓋范圍。
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
建材發展導向(2021年9期)2021-07-16 07:11:36
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
山東工業技術(2016年15期)2016-12-01 05:31:22
中國房地產業(2016年2期)2016-03-01 01:25:48
河南電力(2016年5期)2016-02-06 02:11:34
西安建筑科技大學學報(自然科學版)(2014年2期)2014-11-12 13:04:54
