主題網(wǎng)絡(luò)爬蟲在校園網(wǎng)絡(luò)平臺監(jiān)測中的應(yīng)用研究
2021-01-20 06:21:14周林重慶大學(xué)城市科技學(xué)院
數(shù)碼世界 2020年12期
周林 重慶大學(xué)城市科技學(xué)院
1 引言
校園網(wǎng)絡(luò)平臺主要包括校園論壇、校園貼吧、博客、微博、公眾平臺等,是學(xué)生最活躍的信息交流平臺。大學(xué)生的互聯(lián)網(wǎng)參與行為表現(xiàn)出參與意識強、知識層次高、個性化鮮明、好奇心重等特點,他們在“互聯(lián)網(wǎng)世界”里非常活躍。從新媒體研究的視角來看,學(xué)生既是網(wǎng)絡(luò)信息的接受者,也是網(wǎng)絡(luò)信息的制造者與傳播者,對校園網(wǎng)平臺信息進(jìn)行有效的監(jiān)測,對督促學(xué)生良好的網(wǎng)絡(luò)行為引導(dǎo)、正確價值觀的構(gòu)建等具有積極的意義和價值。校園網(wǎng)平臺信息的主題相關(guān)性較強,因此選擇主題爬蟲“面向特定主題”的信息進(jìn)行抓取,能夠有效實現(xiàn)校園網(wǎng)平臺信息的監(jiān)測。
2 面向校園網(wǎng)平臺的主題爬蟲關(guān)鍵技術(shù)
2.1 采取策略
在爬蟲技術(shù)應(yīng)用中,針對不同類型的網(wǎng)絡(luò)平臺,所采用的爬蟲關(guān)鍵技術(shù)有所區(qū)別,比如對于傳統(tǒng)網(wǎng)頁信息的采集,采用傳統(tǒng)爬蟲爬取更多頁面,對于博客、微博、個人主頁等類型的網(wǎng)絡(luò)平臺,考慮到其自行管理特征和實時更新特征,需要盡可能的縮短爬行周期,與信息更新的速度相匹配。在以往的應(yīng)用中,簡單咨詢聚合(RSS)被廣泛應(yīng)用,但隨著信息技術(shù)的不斷發(fā)展,在不利用RSS的情況下,需要在爬行策略上進(jìn)行思考,采取更多的、更有效的策略。從高校學(xué)生活躍度較高的網(wǎng)絡(luò)平臺情況來看,微博、博客、個人主頁等是最受歡迎的,因此在具體的應(yīng)用中,需要先對各網(wǎng)絡(luò)鏈接類型進(jìn)行區(qū)分,然后依據(jù)鏈接類型與鏈接結(jié)構(gòu)爬取信息,縮短爬行周期,獲得更好的效果。
2.2 主題相關(guān)性判斷
在進(jìn)行主題相關(guān)性分析時,先確定分析的流程,即網(wǎng)站結(jié)構(gòu)分析→鏈接類型分析→網(wǎng)頁內(nèi)容獲取→主題相似度計算。在具體實踐中,先對學(xué)生主要參與的網(wǎng)絡(luò)平臺進(jìn)行分析分類,明確每個網(wǎng)站的特定結(jié)構(gòu),然后針對性的對爬蟲做統(tǒng)一的設(shè)置,以避免和排除不相干鏈接的干擾。比如新浪微博網(wǎng)址均以https://weibo.com/開頭,那么在在爬蟲設(shè)計時只要滿足前綴為這個格式的即可,這樣可以有效濾過其他網(wǎng)站的廣告URL。在個人往來平臺的的信息爬取中,以目錄頁為種子,以列表中所有鏈接地址為爬取內(nèi)容,則可爬取該主頁所信息。
當(dāng)獲得全部網(wǎng)絡(luò)頁面鏈接之后,為避免“主題漂移”,還需通過獲取網(wǎng)頁內(nèi)容來評價主題相關(guān)性。為了提高網(wǎng)絡(luò)信息爬取效率,需要先對網(wǎng)絡(luò)內(nèi)容進(jìn)行判斷,然后進(jìn)行主題相似度分析,以避免主題無關(guān)性信息下載。在實踐中,選擇樸素貝葉斯算法,其概率公式為:

其中,B為信息網(wǎng)頁,C為關(guān)鍵詞信息類別,通過這個公式可對比出“是/非”的概率,然后在根據(jù)關(guān)鍵詞w及權(quán)重t,對T個網(wǎng)頁或T篇文章進(jìn)行爬取,最終依據(jù)以下兩個公式判斷網(wǎng)頁信息是否主題相關(guān)。
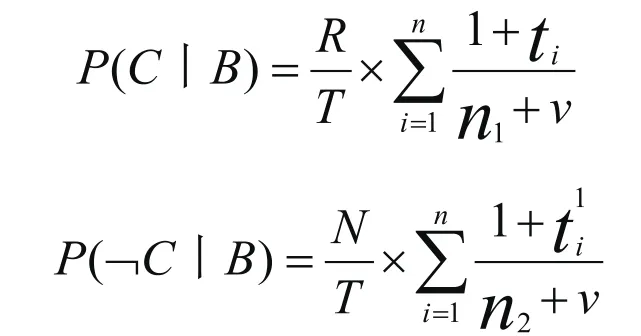
其中,R是主題相關(guān)的數(shù)量,N是主題不相關(guān)的數(shù)量,v是不同詞數(shù)量。
3 校園網(wǎng)絡(luò)平臺監(jiān)測主題爬蟲架構(gòu)設(shè)計
3.1 爬取流程
在主題爬蟲系統(tǒng)框架設(shè)計時,先對爬蟲進(jìn)行初始化設(shè)計,包括種子管理與爬蟲定時器設(shè)置,然后實施網(wǎng)頁抓取,采用多線程技術(shù),實現(xiàn)增量爬取,減少網(wǎng)絡(luò)信息的重復(fù)爬取。針對校園網(wǎng)絡(luò)平臺的信息監(jiān)測要求,主題爬蟲系統(tǒng)在工作時需要實現(xiàn)四個爬取過程的內(nèi)容,包括頁面抓取、頁面解析、去重、任務(wù)調(diào)度。
3.2 頁面爬取與內(nèi)容抽取
針對校園網(wǎng)絡(luò)平臺中學(xué)生個人主頁地址集中的特征,可在深度優(yōu)先爬取的基礎(chǔ)上,采用多線程技術(shù)實現(xiàn)多個頁面爬取任務(wù)并發(fā)執(zhí)行,可以同時爬取多個個人網(wǎng)絡(luò)主頁,最大限度提升爬取效率。考慮到校園網(wǎng)絡(luò)平臺上的信息是不斷更新的,而且原有信息多是保留的,這時為了盡可能減少重復(fù)爬取,可采用增強爬取的方法,在爬蟲定時器的控制下,按照設(shè)定好的爬取周期進(jìn)行二次爬取或多次爬取。在一次爬取時,所有檢索信息按照URL和sha-1值以extractor表的方式存儲數(shù)據(jù)庫,當(dāng)二次爬取時,為避免重復(fù),系統(tǒng)先在數(shù)據(jù)庫中查詢前一次爬取的數(shù)據(jù),查看URL是否存在,以及文章內(nèi)容sha-1值是否變化,若URL存在且sha-1值無變化,則無需再次爬取;若sha-1值有變化,則在數(shù)據(jù)庫信息表中更新文章信息。
在主題相似度計算時,中文分詞是基礎(chǔ),這就需要選擇合適的分詞器,而且分詞器的效果直接影響主題相似度計算的準(zhǔn)確性。分詞器的選擇中,要充分考慮系統(tǒng)要求、面向網(wǎng)頁的特征、網(wǎng)頁信息的文字特征等因素,同時還需要注重單擊分詞速度、分詞精度等指標(biāo),而且還要滿足“支持自定義詞典”的功能。分詞器選定后,在相應(yīng)的校園網(wǎng)絡(luò)平臺選取微博、博客、論壇、個人主頁等平臺上的文章進(jìn)行訓(xùn)練,用選定的分詞系統(tǒng)進(jìn)行分詞處理。在樸素貝葉斯算法函數(shù)下,分別計算出網(wǎng)頁文章信息屬于和不屬于相關(guān)主題的概率。最后,對于滿足爬行條件的網(wǎng)頁信息,將HTML文件下載到本地,然后在數(shù)據(jù)庫中建立一一對應(yīng)額文件夾進(jìn)行保存。
頁面爬取流程完成后,對信息內(nèi)容的抽取將成為主要任務(wù)。首先對網(wǎng)頁信息進(jìn)行抽取,比如微博內(nèi)容、博客文章、網(wǎng)頁文章等,抽取內(nèi)容主要包括標(biāo)題、發(fā)布時間、內(nèi)容。當(dāng)網(wǎng)頁信息中包含圖片內(nèi)容時,可借助圖片轉(zhuǎn)換文字的軟件工具提取文字信息,然后對文字進(jìn)行比對處理,最后存儲于數(shù)據(jù)庫。由于校園網(wǎng)絡(luò)平臺中的信息內(nèi)容是不定時更新的,而且學(xué)生對網(wǎng)絡(luò)的參與熱情較高,在互聯(lián)網(wǎng)上十分活躍,發(fā)布信息較為頻繁,因此針對這些信息的監(jiān)測,需要系統(tǒng)對網(wǎng)頁信息的爬取周期更短,需要更大頻率的監(jiān)測。從目前最常用的方法來看,主要采取抽取定時器、爬蟲定時器等功能。爬取定時器設(shè)置一定的爬取周期,然后以自動的方式在周期內(nèi)實現(xiàn)網(wǎng)頁信息爬取。
3.3 去重與任務(wù)調(diào)度
系統(tǒng)正常運行中,雖然可以通過數(shù)據(jù)庫存儲的原始文件進(jìn)行比對,最大限度避免網(wǎng)頁信息的重復(fù)爬取與解析,但實際上這樣會大大降低程序的效率。而且校園網(wǎng)絡(luò)平臺不僅僅局限于博客、微博、論壇、個人主頁等作者發(fā)布的“主貼”,還會涉及到很多的“回復(fù)”信息,而這些信息同樣需要進(jìn)行監(jiān)測。分析可知,在校園網(wǎng)絡(luò)平臺上用戶發(fā)布的言論都是按照時間順序排序的,因此針對這些信息則可以選用爬過的言論發(fā)表時間中最大值作為標(biāo)準(zhǔn),對網(wǎng)頁上這類信息進(jìn)行判斷其是否已經(jīng)被爬取過。基于這種考慮,可以在數(shù)據(jù)庫建立一個“歷史時間表”,借助存儲的時間信息完成去重任務(wù)。在任務(wù)調(diào)度中,首先需要對各類校園網(wǎng)絡(luò)平臺上的用戶賬號進(jìn)行匯總統(tǒng)計,然后在多線程爬取方式下,依據(jù)賬號書目確定開啟線程的個數(shù),以確保各線程間無重復(fù)競爭的問題。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫(yī)苑(2022年1期)2022-08-30 08:39:14
裝備制造技術(shù)(2021年1期)2021-05-21 07:55:08
福建基礎(chǔ)教育研究(2019年6期)2019-05-28 17:48:32
人大建設(shè)(2017年11期)2017-04-20 08:22:46
財經(jīng)(2017年2期)2017-03-10 14:35:35
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
新疆醫(yī)科大學(xué)學(xué)報(2015年10期)2015-12-26 12:33:32
