基于鄰居信息聚合的子圖同構(gòu)匹配算法
2021-01-21 03:22:50徐周波劉華東
計(jì)算機(jī)應(yīng)用 2021年1期
關(guān)鍵詞:信息
徐周波,李 珍,劉華東,李 萍
(廣西可信軟件重點(diǎn)實(shí)驗(yàn)室(桂林電子科技大學(xué)),廣西桂林 541004)
0 引言
圖匹配技術(shù)被廣泛地應(yīng)用于社交網(wǎng)絡(luò)、網(wǎng)絡(luò)安全、計(jì)算生物學(xué)和化學(xué)等領(lǐng)域[1]中。子圖同構(gòu)問題是圖匹配問題中的一種,屬于NP 完全問題[2]。研究者們從不同的角度進(jìn)行研究,致力于提高子圖同構(gòu)問題的求解效率,并擴(kuò)大求解規(guī)模。因此,子圖同構(gòu)問題成為圖匹配問題中研究的熱點(diǎn)。
求解子圖同構(gòu)問題的方法一般分為3類[3]:基于樹搜索的求解方法、基于索引的求解方法和基于約束滿足問題(Constraint Satisfaction Problem,CSP)的求解方法。Ullmann[4]首次提出了基于回溯的樹搜索算法(以下簡稱Ullmann 算法),該算法基于全局搜索剪枝策略,一一枚舉目標(biāo)圖與模式圖中的節(jié)點(diǎn)對應(yīng)的子圖,由于該算法沒有運(yùn)用剪枝策略來對候選節(jié)點(diǎn)進(jìn)行過濾,因此隨著圖數(shù)據(jù)量的增加其搜索復(fù)雜程度將呈指數(shù)增長。Cordella 等針對已匹配節(jié)點(diǎn)的鄰接點(diǎn)啟發(fā)式信息,給出了VF[5]及VF2[6]算法。VF2 算法基于Ullmann 算法按照節(jié)點(diǎn)度的大小依次選取模式圖節(jié)點(diǎn),以深度優(yōu)先匹配順序,結(jié)合匹配節(jié)點(diǎn)的1步和2步鄰居信息來縮小值域范圍以提高求解效率,是目前主流的子圖同構(gòu)算法。但VF2 算法并沒有定義匹配順序,針對這一問題,Carletti 等[3]提出了基于VF2 算法的VF3 算法。VF3 算法通過為模式圖的節(jié)點(diǎn)計(jì)算選擇概率來決定匹配順序,引入分類概念將節(jié)點(diǎn)進(jìn)行分類,并在搜索過程中引入向前看策略,更進(jìn)一步修剪了搜索空間。但正因?yàn)橐敫怕蔬x擇和分類,具有較長的預(yù)處理時(shí)間。McGregor[2]首次給出了子圖同構(gòu)問題的基于節(jié)點(diǎn)的CSP 模型,并利用子圖同構(gòu)的路徑一致性技術(shù),求解子圖同構(gòu)問題。在此基礎(chǔ)上,Larrosa 等[7]引入相鄰約束,通過同態(tài)傳播來刪除各變量的不可行解。在將圖匹配問題轉(zhuǎn)化為二元CSP 過程中,會(huì)造成全局語義的丟失現(xiàn)象,為此Solnon[8]引入了一種全不同約束,通過此約束構(gòu)建的CSP 模型相較于傳統(tǒng)的CP 的過濾算法,具有更高的求解效率。Audemard 等[9]在Solnon[8]方法的基礎(chǔ)上,增加相鄰變量域的評估值進(jìn)一步縮小值域范圍。總體上,基于CSP 的求解方法,利用圖中的屬性和結(jié)構(gòu)信息,結(jié)合傳播約束、弧一致性等技術(shù),迭代地在所有可能的節(jié)點(diǎn)對中過濾掉一定不是解的節(jié)點(diǎn)對,算法的優(yōu)點(diǎn)是求解速度快,但是需要保留不滿足約束的節(jié)點(diǎn)以避免重新搜索,因此對內(nèi)存的需求大。基于索引的求解方法,這類方法通常以包含圖的結(jié)構(gòu)和語義信息的向量或特征樹建立索引。Shasha、He 和Zou 等以路徑、樹結(jié)構(gòu)作為過濾特征,給出了GraphGrep[10]、Closure-Tree[11]和Gcod-ing[12]等算法。算法首先查詢模式圖是否存在于目標(biāo)圖中,并建立相對應(yīng)的索引,并在最后進(jìn)行子圖同構(gòu)檢測。索引信息越豐富,其檢索的效率越高,但隨之而來的問題是需要花費(fèi)大量的時(shí)間來進(jìn)行索引的建立。
對于如何提高子圖同構(gòu)的求解效率,現(xiàn)有的研究主要是從兩方面入手:一是優(yōu)化匹配順序[13],以減少搜索次數(shù);二是使用更多的鄰居關(guān)系來構(gòu)建約束,過濾不可行的解,以減小搜索空間。對于匹配順序的優(yōu)化,本文通過考慮模式圖和目標(biāo)圖中的節(jié)點(diǎn)的度和標(biāo)簽等屬性,計(jì)算出匹配節(jié)點(diǎn)的Rank 值,并對Rank 值進(jìn)行排序,得出優(yōu)化后的匹配順序,以此來為變量序進(jìn)行賦值。現(xiàn)如今采用鄰居關(guān)系來構(gòu)建的約束,大多數(shù)是基于單個(gè)節(jié)點(diǎn)和單個(gè)鄰居之間的約束關(guān)系,很少有考慮到節(jié)點(diǎn)局部鄰域之間的信息。隨著圖卷積神經(jīng)網(wǎng)絡(luò)(Graph Convolutional Network,GCN)[14-15]的出現(xiàn),可以很好地對圖結(jié)構(gòu)的空間信息進(jìn)行特征的提取,將節(jié)點(diǎn)的局部鄰域信息轉(zhuǎn)化為節(jié)點(diǎn)的特征向量來進(jìn)行表示學(xué)習(xí)。本文通過引入圖卷積神經(jīng)網(wǎng)絡(luò)技術(shù)對模式圖和目標(biāo)圖的節(jié)點(diǎn)的結(jié)構(gòu)、屬性特征進(jìn)行鄰居信息的聚合,使節(jié)點(diǎn)帶有局部鄰域的信息。
本文將采用樹搜索方法并結(jié)合CSP求解技術(shù)對子圖同構(gòu)問題進(jìn)行求解,利用優(yōu)化后的匹配順序?qū)ψ兞啃蜻M(jìn)行賦值,并將節(jié)點(diǎn)局部鄰域關(guān)系轉(zhuǎn)化成約束,來提高子圖同構(gòu)求解的效率。通過一些公開數(shù)據(jù)集的實(shí)驗(yàn)分析表明,與經(jīng)典的樹搜索算法和約束求解算法相比,本文算法有效地提高了子圖同構(gòu)的求解效率。
1 相關(guān)定義
定義1圖。是一個(gè)圖,V是頂點(diǎn)集,E?V×V是邊集,L=是一個(gè)標(biāo)簽集,V中每個(gè)節(jié)點(diǎn)都有一個(gè)頂點(diǎn)標(biāo)簽vlabel,且vlabel∈lv。E中的邊都有一個(gè)邊標(biāo)簽elabel,且elabel∈le。
定義2子圖同構(gòu)。給定目標(biāo)圖Gt=和模式圖以及映射R?Vt×Vp,若存在單射函數(shù)f:Vp→Vt滿足:
1)?u∈Vp,存在f(u) ∈Vt,使得且lv(u)=lv(f(u))。
2)?u,v∈Vp,u≠v?f(u) ≠f(v)。
3)?(u,v) ∈Ep,存在 (f(u),f(v)) ∈Et,且le(u,v)=le(f(u),f(v))。
那么稱Gt的子圖sub(Gt)與Gp是子圖同構(gòu)關(guān)系,記做sub(Gt)?Gp。
子圖同構(gòu)問題是指在目標(biāo)圖Gt中找到一個(gè)或所有與模式圖Gp同構(gòu)的子圖。本文的算法是求解所有同構(gòu)的子圖。定義3CSP。約束滿足問題定義為三元組其中:
1)X={x1,x2,…,xn}為包含n個(gè)變量的有限集合;
2)D={D(x1),D(x2),…,D(xn)}為n個(gè)變量的值域;
3)C={c1,c2,…,cm}為約束集合,約束ci的變量范圍var(ci)={xi1,xi2,…,xij},且對應(yīng)的值域val(ci)?Dil×Di2×…×Dij(i=1,2,…,m,1 ≤j≤n),其中xil∈X(l=1,2,…,j),Dil為變量xil的值域,稱ci為定義在變量集{xi1,xi2,…,xij}上的j元約束。
CSP 的解指的是對變量集X中的所有變量找到完全實(shí)例化,并滿足約束集C中的所有約束。解決CSP 主要有三種算法:回溯搜索、局部搜素和動(dòng)態(tài)編程,其中回溯算法為應(yīng)用最廣的算法。
2 基于節(jié)點(diǎn)鄰居信息聚合子圖同構(gòu)匹配算法
首先,利用圖卷積神經(jīng)網(wǎng)絡(luò)技術(shù)進(jìn)行特征表示學(xué)習(xí),得出包含節(jié)點(diǎn)局部鄰域信息的特征向量;其次,根據(jù)模式圖與目標(biāo)圖節(jié)點(diǎn)的標(biāo)簽、度等屬性對匹配順序進(jìn)行優(yōu)化;最后,構(gòu)建子圖同構(gòu)的CSP求解模型并采用回溯算法對其進(jìn)行求解。
2.1 鄰居信息聚合
鄰居信息聚合將對圖的節(jié)點(diǎn)進(jìn)行鄰居信息的聚合,使只有自身屬性特征的節(jié)點(diǎn)帶有局部鄰域信息,并以向量的形式表示出來。文獻(xiàn)[15]所提供的聚合方法主要是針對節(jié)點(diǎn)分類,面對子圖同構(gòu)問題時(shí),不能將提取的空間特征信息很好地轉(zhuǎn)換為匹配時(shí)所需要的權(quán)值。鑒于此,本文對文獻(xiàn)[15]的聚合方法進(jìn)行了改進(jìn)。
已知模式圖Gp和目標(biāo)圖Gt,首先,利用模式圖和目標(biāo)圖的結(jié)構(gòu)屬性特征,分別構(gòu)建模式圖Gp和目標(biāo)圖Gt的特征矩陣,并根據(jù)式(1)進(jìn)行節(jié)點(diǎn)信息的傳播和匯聚:

其中:N(i)為節(jié)點(diǎn)i的所有鄰居節(jié)點(diǎn)集合,deg(i)為節(jié)點(diǎn)i的度,Θ是權(quán)重矩陣即機(jī)器學(xué)習(xí)中要更新的參數(shù)矩陣,為節(jié)點(diǎn)i第k次迭代的特征向量。
如圖1所示,圖1(a)為k=1時(shí)黑色節(jié)點(diǎn)的鄰居信息聚合示意圖,圖1(b)為k=2 時(shí)黑色節(jié)點(diǎn)的鄰居信息聚合示意圖。在圖1(a)中,黑色節(jié)點(diǎn)經(jīng)過圖卷積神經(jīng)網(wǎng)絡(luò),對一步鄰居信息進(jìn)行匯聚,并得到新的節(jié)點(diǎn)特征向量。與圖1(a)類似,圖1(b)是兩步鄰居信息的聚合。在圖卷積神經(jīng)網(wǎng)絡(luò)中是對每個(gè)節(jié)點(diǎn)進(jìn)行聚合。

圖1 不同k值時(shí)的鄰居信息聚合示意圖Fig.1 Neighbor information aggregation with different k value
其次,計(jì)算節(jié)點(diǎn)的權(quán)重值Weight。將得到的節(jié)點(diǎn)的特征向量進(jìn)行降維操作,并對其取模,即可得到每個(gè)節(jié)點(diǎn)的權(quán)值。
2.2 優(yōu)化節(jié)點(diǎn)匹配順序
文獻(xiàn)[9]指出節(jié)點(diǎn)的匹配順序的不同會(huì)造成查詢次數(shù)的不同,如圖2 所示。針對模式圖p給定兩個(gè)匹配順序O1={u1,u2,u3}和O2={u1,u3,u2},若采用O1的匹配順序與目標(biāo)圖g1進(jìn)行匹配時(shí):第1 步將u1與v1進(jìn)行匹配;第2 步將u2與v2進(jìn)行匹配;第3步將u3與v2的剩余的鄰居v3進(jìn)行匹配,發(fā)現(xiàn)標(biāo)簽不同不是同構(gòu)子圖,所以只需要匹配3 次就可以知道不是所需要的解。若采用O2的匹配順序,第1 步將u1與v1進(jìn)行匹配;第2 步將u3與v4進(jìn)行匹配;第3 步將u2與v4的鏈接的鄰居v5進(jìn)行匹配,不滿足匹配條件,但v4還有剩余鄰居,則繼續(xù)匹配,發(fā)現(xiàn)直到匹配到節(jié)點(diǎn)v1004還是不滿足匹配條件,針對O2的匹配順序則需要匹配1 003 次才能發(fā)現(xiàn)沒有解;同理,若采用O1的匹配順序與目標(biāo)圖g2進(jìn)行匹配需要匹配1 003 次,若采用O2的匹配順序,則只需要匹配3 次。由此可以看出不同的匹配順序?qū)λ阉鞯拇螖?shù)是有很大的影響的。
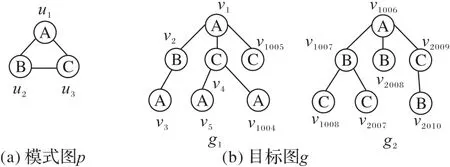
圖2 模式圖p和目標(biāo)圖gFig.2 Pattern graph p and target graph g
針對此問題,考慮到模式圖中節(jié)點(diǎn)的標(biāo)簽屬性出現(xiàn)次數(shù)少的應(yīng)該優(yōu)先匹配,并且節(jié)點(diǎn)的度數(shù)越大,節(jié)點(diǎn)就更具有特殊性。根據(jù)這一特性,給出式(2)對模式圖節(jié)點(diǎn)進(jìn)行排序,進(jìn)行匹配順序優(yōu)化:

其中:freq(G,L(u))表示在目標(biāo)圖G中所有與節(jié)點(diǎn)u標(biāo)簽一致的節(jié)點(diǎn)總數(shù)量,deg(u)表示節(jié)點(diǎn)u的度。如圖2所示,模式圖p中節(jié)點(diǎn)u1在目標(biāo)圖g2中的freq(G,L(u1))=1,deg(u1)=2,則Rank(u1)=1/2。計(jì)算出模式圖上每個(gè)節(jié)點(diǎn)的排序值,按照排序值的大小從小到大對模式圖節(jié)點(diǎn)進(jìn)行排序。若排序值相同,則隨機(jī)排列,由此求出模式圖節(jié)點(diǎn)的匹配順序。
2.3 子圖同構(gòu)的CSP模型
1)變量集:X=Vp。
2)值域:?xi∈X,D(xi)=Vt。
3)約束集C={c1,c2,c3,c4}:
a)邊約束c1:?xi,xi∈X,xi≠xj
b)節(jié)點(diǎn)標(biāo)簽約束c2:?xi∈X,若xi=di,di∈D(xi),則lv(xi)=lv(di)。
c)邊標(biāo)簽約束c3:Ep,若xi=di,xj=dj,di∈D(xi),dj∈D(xj),則∈Et且le(xi,xj)=le(di,dj)。
d)全 不 同alldiff約 束c4:alldiff(x1,x2,…,xn)={(d1,d2,…,dn)|?di∈D(xi),?i≠j,di≠dj,i=1,2,…,n}。
為了進(jìn)一步對值域進(jìn)行縮減,根據(jù)子圖同構(gòu)問題節(jié)點(diǎn)度的特性,在匹配時(shí)要求目標(biāo)圖Gt中節(jié)點(diǎn)的度數(shù)應(yīng)當(dāng)大于或等于模式圖Gp中的節(jié)點(diǎn),所以可將初始化值域Di更新為:
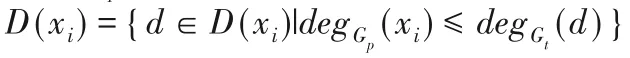
其中:degGp(xi)表示模式圖Gp中節(jié)點(diǎn)xi的度,degGt(d)表示目標(biāo)圖Gt中與節(jié)點(diǎn)xi的映射節(jié)點(diǎn)的度。
在子圖同構(gòu)約束求解過程中,有效地構(gòu)建約束是減小解空間、提高算法的時(shí)間效率的重要手段,基于2.1 節(jié)提出的鄰居信息聚合方法,將得到的權(quán)重值Weight轉(zhuǎn)化為聚合權(quán)值約束,在匹配時(shí)提供局部鄰域信息,可進(jìn)一步地縮減值域,提高算法的效率。進(jìn)一步,在原約束集中加入鄰域約束NDC,此時(shí)將CSP中的約束集更新為C={c1,c2,c3,c4,c5,c6}。
e)聚合權(quán)值約束c5:?xi∈X,若xi=di,di∈D(xi),則Weight(xi)≤Weight(di)。
f)鄰域約束(Neighborhood Dominance Constraint,NDC)[9]c6:?xi,xi∈X,若xi=di,xj=dj,則S(xi,xj)≤S(di,dj) 且(xi,di)∈N(xi)×N(di),其中N(xi)是模式圖節(jié)點(diǎn)xi的鄰居節(jié)點(diǎn),S(xi,xj)=MkGp[xi][xj]表示在模式圖中節(jié)點(diǎn)xi到節(jié)點(diǎn)xj步長為k的路徑數(shù),S(di,dj)=[di][dj]表示在目標(biāo)圖中節(jié)點(diǎn)di到節(jié)點(diǎn)dj步長為k的路徑數(shù)。
2.4 VFGCN算法
在VF2 搜索算法的基礎(chǔ)上結(jié)合2.3 節(jié)給出的CSP 模型,并結(jié)合CSP求解技術(shù)給出基于圖神經(jīng)網(wǎng)絡(luò)技術(shù)的子圖同構(gòu)算法(VF2 algorithm based on Graph Convolutional Network,VFGCN)。算法主要分為4 個(gè)步驟:第1 步為各個(gè)變量初始值域,根據(jù)度約束和節(jié)點(diǎn)標(biāo)簽約束對值域進(jìn)行預(yù)處理;第2 步為鄰居信息聚合,利用圖卷積神經(jīng)網(wǎng)絡(luò)對節(jié)點(diǎn)進(jìn)行信息聚合;第3 步為求解匹配順序,為后續(xù)優(yōu)化變量匹配順序做準(zhǔn)備;第4步為約束求解,對于不滿足約束條件的解進(jìn)行回溯。給出偽代碼如下。
算法1 VFGCN。
輸入 模式圖Gp=(Vp,Ep,Lp)和目標(biāo)圖Gt=(Vt,Et,Lt);
輸出 所有的子圖同構(gòu)結(jié)果solutions。

算法第1)行函數(shù)Ri根據(jù)模式圖和目標(biāo)圖節(jié)點(diǎn)的度和節(jié)點(diǎn)的標(biāo)簽屬性為每個(gè)變量返回初始值域,對值域進(jìn)行預(yù)處理,對于不滿足條件的值從各個(gè)變量的值域中進(jìn)行剔除。第2)行函數(shù)Neighbor函數(shù)用于對模式圖和目標(biāo)圖的節(jié)點(diǎn)進(jìn)行鄰居信息聚合,根據(jù)式(1)將節(jié)點(diǎn)的局部鄰域信息提取為節(jié)點(diǎn)特征向量并進(jìn)行降維、取模等操作將向量轉(zhuǎn)化為權(quán)值,并返回每個(gè)節(jié)點(diǎn)的權(quán)值,每個(gè)頂點(diǎn)的權(quán)值將作為后續(xù)回溯過程的約束條件。第3)行函數(shù)Rank 用于對模式圖節(jié)點(diǎn)的匹配順序進(jìn)行優(yōu)化,根據(jù)式(2)對模式圖節(jié)點(diǎn)節(jié)點(diǎn)進(jìn)行計(jì)算和排序,返回排序后的模式圖節(jié)點(diǎn)匹配順序S,返回后的順序S即為求解時(shí)變量的匹配順序,以優(yōu)化后的順序來為變量進(jìn)行賦值。算法第4)~15)行為算法的搜索回溯過程,依次從返回的排序的節(jié)點(diǎn)序列S中選取變量,結(jié)合CSP 基于回溯的求解方法,若當(dāng)前的值域滿足Weight權(quán)值約束c5、NDC 鄰域約束c6、邊約束c1和邊標(biāo)簽約束c3,則通過alldiff約束c4更新剩余待匹配變量的值域,保持單射關(guān)系,并將該變量從當(dāng)前變量域中移除。若變量域中的變量并未完全實(shí)例化就引起值域的空值化,則說明當(dāng)前搜索分支無法找到可行解,則算法向上回溯重新進(jìn)行賦值;若變量完全實(shí)例化,即當(dāng)前變量域?yàn)榭眨覍?yīng)的變量賦值滿足所有約束條件,則說明找到一個(gè)可行解,并將可行解加入到最終解集中。
3 實(shí)驗(yàn)結(jié)果及分析
在Core-i5-6500@3.2 Hz,16 GB 內(nèi)存的實(shí)驗(yàn)環(huán)境下,操作系統(tǒng)是Windows 10,64 位,編譯環(huán)境是pycharm,編譯語言是python。實(shí)驗(yàn)使用了公開數(shù)據(jù)集AIDS(http://jenalib.leibnizfli.de)和PDBSV2(http://www.rcsb.org)兩個(gè)數(shù)據(jù)集,其中AIDS 為抗艾滋病毒數(shù)據(jù)集,包含大量的稀疏無向圖,節(jié)點(diǎn)數(shù)量從4 到245 不等,每個(gè)圖表示化合物的拓?fù)浣Y(jié)構(gòu),并包含節(jié)點(diǎn)標(biāo)簽和邊標(biāo)簽。目標(biāo)圖數(shù)據(jù)集中含有10 000幅圖。模式圖按邊的數(shù)量分為Q4、Q8、Q12、Q16、Q20、Q24 六組,每組包含1 000 幅小圖。PDBSV2 數(shù)據(jù)集為蛋白質(zhì)骨架數(shù)據(jù)集,該數(shù)據(jù)集包含40 種蛋白質(zhì),為中等稀疏圖,節(jié)點(diǎn)數(shù)量從4 000 到12 000 不等。目標(biāo)圖為40 幅大圖,模式圖按邊的數(shù)量分為Q4、Q8、Q16、Q32、Q64、Q128六組,每組包含40幅小圖。模式圖均為按照邊數(shù)從相應(yīng)的目標(biāo)圖中隨機(jī)抽取。實(shí)驗(yàn)過程中將使用本文算法與VF2 算法[6]、迭代標(biāo)記過濾(Iterative Labeling Filtering,ILF)算法[16]、基于路徑的局部全不同(Path of Local All Different,PathLAD)算法[17]、VF3 算法[3]相比較。實(shí)驗(yàn)結(jié)果中的平均時(shí)間通過式(3)計(jì)算得出:

其中:timeall為各個(gè)分組求解的總時(shí)間,Numpattern為每個(gè)分組中模式圖的數(shù)量。平均時(shí)間更能體現(xiàn)求解單個(gè)模式圖與所有目標(biāo)圖的子圖同構(gòu)全部解的時(shí)間效率,并統(tǒng)計(jì)出兩個(gè)數(shù)據(jù)集進(jìn)行鄰居信息聚合時(shí)所花費(fèi)的時(shí)間,計(jì)算公式與式(3)一致,timeall為模式圖各個(gè)分組或目標(biāo)圖聚合總時(shí)間,Numpattern為各個(gè)分組中模式圖的數(shù)量或目標(biāo)圖的數(shù)量。
基于上述所述,本文算法利用圖卷積神經(jīng)網(wǎng)絡(luò),對模式圖和目標(biāo)圖節(jié)點(diǎn)的鄰域特征信息進(jìn)行了提取,并對匹配順序進(jìn)行了優(yōu)化,減少了搜索次數(shù),結(jié)合CSP 求解技術(shù),提高了子圖同構(gòu)問題的求解效率。
1)首先在AIDS數(shù)據(jù)集上進(jìn)行對比實(shí)驗(yàn),按照模式圖的規(guī)模將實(shí)驗(yàn)分為6 組。實(shí)驗(yàn)結(jié)果如表1 所示,由表1 中的數(shù)據(jù)可知在6 組實(shí)驗(yàn)中,VFGCN 算法均優(yōu)于VF2 算法、PathLAD 算法、ILF算法和VF3算法;并且隨著模式圖規(guī)模的增大,求解的平均時(shí)間總體呈上升趨勢。由此可以看出,模式圖的大小對于求解時(shí)間的影響;但當(dāng)模式圖規(guī)模為Q24 時(shí),時(shí)間卻不是6組中最慢的,但解的個(gè)數(shù)是6 組中最少的。原因在于:在搜索的過程中,已提前對不可行的解進(jìn)行了剪枝,避免了對無效的分支進(jìn)行搜索,所以盡管模式圖的規(guī)模是最大的,但是時(shí)間并非最慢的,因此模式圖的規(guī)模大小對求解時(shí)間還是有很大的影響。
AIDS 數(shù)據(jù)集的鄰居信息聚合時(shí)間如表2 所示,對于不同規(guī)模的下的模式圖和目標(biāo)圖,聚合的時(shí)間大約都在0.001 4 s左右,由此可以看出聚合步驟所消耗的時(shí)間是非常少的,并且不受模式圖規(guī)模的影響。因?yàn)椴恍枰貜?fù)遍歷圖的所有節(jié)點(diǎn),只需要遍歷節(jié)點(diǎn)的有限鄰居,所以能夠在極短的時(shí)間內(nèi)有對節(jié)點(diǎn)的局部鄰域信息進(jìn)行聚合,并給出其特征向量,并且在聚合時(shí)所選的k值(k步鄰居)影響著后續(xù)的求解效率,在實(shí)驗(yàn)過程中發(fā)現(xiàn),并不是聚合的鄰居信息越多,即k取值越大,求解效率就越高;反而當(dāng)k的取值超過一定范圍,將降低求解效率。其原因在于,當(dāng)k取值過大時(shí),會(huì)使得聚合后的特征向量趨于一致,即所有節(jié)點(diǎn)的鄰域信息過于相似,導(dǎo)致在后續(xù)的匹配過程中不能夠很好地對不可行的解進(jìn)行剪枝,反而影響了求解的效率。經(jīng)實(shí)驗(yàn)測試,對AIDS 和PDBSV2 數(shù)據(jù)集來說,由于模式圖的最大規(guī)模分別為Q24 和Q128,節(jié)點(diǎn)的鄰居大多數(shù)是在3 步之內(nèi),所以將k取1 時(shí)效率是最高的,因此在后續(xù)的實(shí)驗(yàn)過程中k取值為1。
2)本組將在PDBSV2 數(shù)據(jù)集上進(jìn)行對比實(shí)驗(yàn),實(shí)驗(yàn)將按照模式圖的規(guī)模分為6組。其鄰居信息聚合時(shí)間如表2所示,對比表2 兩個(gè)數(shù)據(jù)集聚合的平均時(shí)間可以看出,在不同的規(guī)模下,PDBSV2數(shù)據(jù)集的平均聚合時(shí)間均比AIDS數(shù)據(jù)集要長,其原因在于節(jié)點(diǎn)的鄰居個(gè)數(shù)。PDBSV2 數(shù)據(jù)集整體的圖密度要比AIDS 數(shù)據(jù)集要高,就是相對于AIDS 數(shù)據(jù)集,PDBSV2 數(shù)據(jù)集中的一個(gè)節(jié)點(diǎn)可能擁有著更多的鄰居,因此在聚合過程中將花費(fèi)更多的時(shí)間。
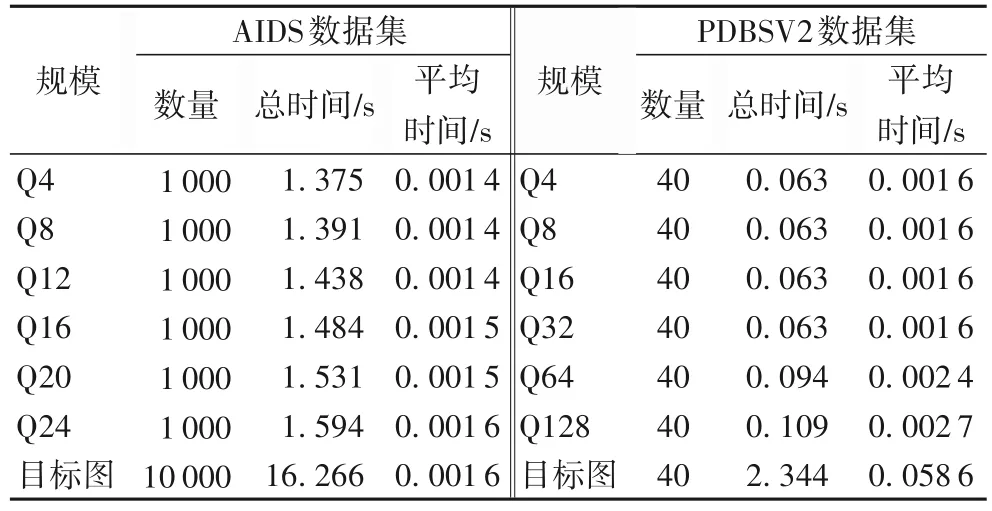
表2 鄰居信息聚合時(shí)間Tab.2 Neighbor information aggregation time
與其他算法的對比實(shí)驗(yàn)結(jié)果如表3 所示。從表3 中的數(shù)據(jù)可以看出,隨著模式圖規(guī)模的增大,求解的平均時(shí)間總體呈上升趨勢。VFGCN 算法求解的平均時(shí)間對比VF2 算法、ILF 算法和PathLAD 算法在6 組實(shí)驗(yàn)中均是最短的,對比VF3 算法在規(guī)模為Q64 和Q128 時(shí)VF3 算法略有優(yōu)勢。其原因在于,VFGCN 算法對節(jié)點(diǎn)的匹配順序進(jìn)行了優(yōu)化,降低了搜索次數(shù),并提取了節(jié)點(diǎn)的局部鄰域信息,對于不可行解更有效地進(jìn)行了剪枝。但是在規(guī)模為Q64 和Q128 時(shí),VF3 算法首先對模式圖中的節(jié)點(diǎn)計(jì)算匹配概率以此來確定匹配順序,并對節(jié)點(diǎn)進(jìn)行分類,不屬于同一個(gè)類別的節(jié)點(diǎn)不能夠進(jìn)行匹配,在面對規(guī)模更大模式圖的時(shí)候比VFGCN 算法更能對值域進(jìn)行修剪。但是同樣,VF3 算法在計(jì)算規(guī)模偏大的模式圖節(jié)點(diǎn)的選擇概率和對節(jié)點(diǎn)進(jìn)行分類時(shí),所耗費(fèi)的預(yù)處理時(shí)間也更長了。

表3 PDBSV2數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果Tab.3 Experimental results on PDBSV2 dataset
4 結(jié)語
為了進(jìn)一步提高子圖同構(gòu)問題的求解效率,本文提出了一種基于鄰居信息聚合的子圖同構(gòu)匹配算法,能夠有效地縮減值域。該算法結(jié)合圖卷積神經(jīng)網(wǎng)絡(luò)技術(shù),利用改進(jìn)后的聚合公式,對模式圖和目標(biāo)圖的節(jié)點(diǎn)進(jìn)行局部鄰域信息的提取及聚合,并且基于圖的標(biāo)簽、度等特征提供了一種優(yōu)化后的匹配順序,建立子圖同構(gòu)的CSP 求解模型并進(jìn)行回溯求解。實(shí)驗(yàn)結(jié)果表明,該算法與經(jīng)典算法相比較,有效地減少了子圖同構(gòu)的求解時(shí)間,在小規(guī)模以及中等規(guī)模的圖匹配中有較高的求解效率。在未來的工作中,將研究動(dòng)態(tài)圖匹配算法,并結(jié)合CSP技術(shù)中的動(dòng)態(tài)CSP求解技術(shù)對其進(jìn)行求解。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會(huì)展(2014年4期)2014-11-27 07:46:46
大眾創(chuàng)業(yè)(2009年10期)2009-10-08 04:52:00
數(shù)字社區(qū)&智能家居(2009年7期)2009-09-29 08:16:48
數(shù)字社區(qū)&智能家居(2009年11期)2009-06-25 04:30:34
數(shù)字社區(qū)&智能家居(2009年3期)2009-04-21 03:09:04
數(shù)字社區(qū)&智能家居(2009年2期)2009-03-27 04:33:44
數(shù)字社區(qū)&智能家居(2009年12期)2009-02-03 07:50:48
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
