
面向群組用戶時序行為的動態推薦算法
2021-01-21 03:22:54蔡瑞初郝志峰
計算機應用 2021年1期
溫 雯,劉 芳*,蔡瑞初,郝志峰,2
(1.廣東工業大學計算機學院,廣州 510000;2.佛山科學技術學院數學與大數據學院,廣東佛山 528000)
0 引言
近年來,互聯網上的信息資源不斷豐富,人們對線上信息的依賴程度越來越高。在這種時代背景下,用戶在面對大量信息時也越來越難以獲得自己真正感興趣的部分,如何定位用戶感興趣的信息、并將其展示(曝光)給用戶也成為信息系統所需面臨的一個挑戰。因此,通過對用戶的歷史行為數據建模,從而主動為用戶推薦偏好內容的個性化推薦系統[1]具有重要且現實的應用意義。近年來,推薦系統已經成功應用到了諸多領域,最常見的應用落地場景有:在線視頻[2]、社交網絡[3-5]、在線音樂[6]、電子商務[7]等。
傳統的推薦系統通過分析用戶的歷史時序行為,挖掘用戶的個性化需求,從而將一些商品個性化推薦給相應的用戶,幫助用戶找到自己想要但難以被發現的商品[8],目前應用最廣泛的是基于協同過濾(Collaborative Filtering,CF)算法[9-11]的推薦系統。然而,在現實生活中,用戶的歷史行為往往是復雜多變的。譬如,對于互聯網在線購物數據而言,用戶的行為記錄包括購買、瀏覽、收藏等,這些行為數據構成了用戶的曝光數據,即用戶已經了解或看到了這些商品;而用戶購買過的物品可以表明用戶的個人喜好,因此構成用戶點擊數據。即通過用戶對商品的購買行為可以分析用戶是否喜愛該商品或該商品是否只是曝光給了用戶,但對于用戶未瀏覽或購買的商品,并不能直接表明用戶不喜歡這些商品,有可能是因為用戶從未聽說過這些商品[12-13]。而僅基于用戶歷史點擊行為數據建模的推薦算法并未考慮到這一點,且用戶的興趣往往是隨著時間動態變化的,因此推薦結果往往會產生偏差。
此外,對于互聯網在線電視節目點播系統和網上購物系統來說,一個用戶ID所產生的觀看/購買歷史記錄背后可能隱含了多個家庭成員的觀看/購買記錄,而往往家庭成員之間的喜好不盡相同,即系統所采集的數據是用戶群組的數據,且每個成員的喜好也會隨時間而動態變化,但目前的推薦算法并未考慮這一情況。
本文針對以上問題提出一種面向群組用戶時序行為的動態偏好推薦方法,由于經典的推薦算法直接對用戶的點擊數據建模,這種建模方法會使得系統側重于推薦用戶經常點擊的物品而忽視了曝光數據對系統結果造成的偏差影響。因此本文利用因果推斷(Causal Inference,CI)[14]中的逆傾向加權方法(Inverse Propensity Weighting,IPW),將數據以其流行度的倒數輸入模型進行加權訓練,使得訓練時所有物品相當于處于一個以同等概率曝光的公平狀態,盡可能減小經常對用戶曝光的物品對推薦系統產生的偏差。
本文的主要工作和貢獻如下:
1)本文提出了一種面向群組用戶時序行為的動態偏好推薦方法,通過融合數據集中時間序列的特性和隱含群組的信息,為用戶作動態時序推薦;
2)構建出某一時刻下群組角色的多項式分布概率矩陣,得到該時刻下的用戶角色,按時間為用戶作精準推薦;
3)針對曝光模型設計了兩種計算流行度的方法,并采用逆傾向加權思想將流行度融入訓練過程中,使得流行度較高的物品不會產生太大的權重,平衡樣本狀態;
4)在網絡電視節目IPTV 數據集和阿里巴巴網上購物云主題(Cloud theme)兩個真實數據集上進行了實驗,結果表明,本文提出的時序推薦算法可以切實有效地為群組用戶做出推薦。
1 相關工作
與本文相關的工作主要包括以下2 個方面:1)基于矩陣分解的推薦算法;2)面向時間序列的推薦算法。
1.1 基于矩陣分解的推薦算法
傳統矩陣分解[15-16]的基本思想是將推薦系統中所有用戶和物品映射到一個共享的潛在因子空間(Latent Factor Space),然后分別使用用戶潛在偏好特征向量(User Latent Feature Vector)和物品潛在屬性特征向量(Item Latent Feature Vector)代表對應的用戶和物品,因此用戶-物品之間的關聯矩陣可被建模成兩個潛在特征向量的內積。早期基于矩陣分解的算法[17-18]主要針對用戶的顯式反饋信息建模,即直接利用用戶對物品的評分來預測用戶的偏好,然而這種只關注可觀測到的正向反饋信息的做法在真實的Top-K推薦場景下會導致比較差的效果,且應用場景受限。
此外,Salakhutdinov 等[19]在2007 年提出的概率矩陣分解(Probabilistic Matrix Factorization,PMF)模型中假設用戶評分矩陣中的元素是由用戶潛在偏好向量和節目潛在屬性向量的內積決定的,并服從正態分布,該算法能有效解決大型數據集中用戶行為稀疏的問題。文獻[11]中針對隱式反饋數據提出加權矩陣分解(Weighted Matrix Factorization,WMF)模型,通過對樣本引入置信度來確定用戶喜好該物品的程度,實驗表明該模型尤其在數字電視數據集上效果顯著。Lee 等[16]1999年在Nature上提出了一種新的矩陣分解思想——非負矩陣分解(Non-negative Matrix Factorization,NMF)算法,它假設用戶評分矩陣分解出來的小矩陣應該滿足非負約束,使得分解出來的結果更能符合現實世界的解釋,譬如圖像數據中不可能存在負數的像素值,在文檔統計中,詞頻為負也無法解釋。文獻[20]中提出一種DBPMF(Deep Bias Probabilistic Matrix Factorization)模型,利用深度卷積網絡提取用戶/物品的特征并將其融入PMF 中,以此來跟進用戶的評分行為和物品的流行度變化,建立在線協同過濾系統。文獻[21]中采用一種非采樣的方法提出了 ENMF(Efficient Neural Matrix Factorization)模型,通過推導的三種優化方法來有效學習數據中的模型參數,減小了計算復雜度,改善了由于采用負采樣方法的傳統模型而產生的計算消耗和魯棒性問題。另外,Liang 等[13]在傳統矩陣分解的基礎上就用戶是否對物品曝光這一問題進行建模,將曝光因子建模成一個隱變量,根據用戶行為數據推斷其值,并利用不同數據中的附加信息(如文檔主題、街道位置)建模,提出了一種ExpoMF(Exposure Matrix Factorization)模型。同時,Liang 等[12]提出IPW-MF(Inverse Propensity Weighted Matrix Factorization)模型,它對用戶的曝光數據和點擊數據分別建模成曝光模型和點擊模型,其中曝光模型又分別根據物品流行度和用戶搜索情況具體化為流行度模型和泊松模型,并在模型訓練中引入因果推斷中的逆傾向評分加權方法,消除由于曝光數據產生的推薦偏差。該算法最接近本文的工作,不同的是本文在曝光模型部分采用的是流行度模型,并根據問題設計了兩種計算流行度的方式,最后依據時序數據的特性按時間為用戶做出Top-K推薦。
傳統的矩陣分解推薦算法雖基于用戶的歷史點擊行為數據可以預測特定用戶對某物品的喜好,但其面臨著用戶數據稀疏、冷啟動等問題。而改進的矩陣分解模型雖然可以解決數據稀疏、縮短訓練時間等問題,但其在設計時沒有主動地考慮到用戶興趣是隨時間變化的,針對這一不足之處,本文探究了在時間序列上應用矩陣分解方法為用戶做動態推薦的問題。
1.2 面向時間序列的推薦算法
近年來,工業界和學者們逐漸將目光投向了時間序列上的推薦算法研究。如Koren[18]在矩陣分解的基礎上對時間進行建模,提出將SVD++模型與時間參數聯合起來建模成TimeSVD++,該方法能有效挖掘用戶喜好的局部變化,并準確地預測電影評分。文獻[22]中提出一種在線進化協同過濾方法來捕捉用戶興趣隨時間的動態變化,達到實時推薦的效果。此外,文獻[23]基于用戶評分的時序信息同時構建用戶和物品的近鄰關系,并將兩者融入到PMF 中,提出基于用戶時序行為的推薦算法(SequentialMF)。文獻[24]提出一種ISLF(Interest Shift and Latent Factors combination model),將用戶興趣轉移(Interest Shift)與潛在因子方法結合起來,通過考慮用戶長短期興趣變化從而捕捉用戶真正的偏好。Liu 等[25]為給用戶作時序推薦引入了馬爾可夫模型(Markov Model)來找出用戶評分行為的周期性特征,提升了計算效率。文獻[26]首次將泊松分解框架和泊松過程聯系起來提出一種RPF(Recurrent Poisson Factorization)框架,通過推斷用戶隨時間動態變化的興趣愛好從而在合適的時間為其推薦合適的物品,并針對不同的問題場景提出了三個RPF的變體框架。以上基于時間序列的推薦算法雖然考慮到了用戶興趣是隨時間動態變化的這一問題,但它們都是針對用戶行為由單一角色產生這一場景下的,沒有考慮到在現實場景中,一個用戶ID 所呈現的行為記錄可能是由一個家庭的多個成員所產生的。
同時隨著深度學習[27-28]的興起,眾多時間序列的研究都逐漸偏向使用深度神經網絡來預測用戶行為[29-32],并能取得不錯的效果,但是對于本文研究的問題來說,單一時間片的單用戶數據具有較大的稀疏性,而深度學習的方法對于數據量要求很高,因此不能獲得較好的學習效果,其次深度學習的過程缺乏一定的可解釋性。
據了解,目前的研究工作中,還沒有關注到個體用戶背后的隱變量,即用戶背后存在的群組角色不定,可能會在不同的時刻產生不同的興趣,本文工作正是考慮到了以上問題并結合時間序列的特點針對此類群組用戶為其做出合適的物品推薦。
2 問題描述
本章首先給出問題定義,然后對群組用戶下的推薦問題進行形式化描述并約定相關符號。
2.1 問題定義
本文的目標是利用曝光數據判別出隱藏在用戶背后的群組角色,然后研究用戶在一天24 個時刻下的時序行為,最后按時間為用戶做出推薦。相關術語和問題定義如下。
定義1定義用戶行為是隨時間t變化的,本文研究用戶一天24 個時刻下的行為,因此本文中所用到的時刻均是指間隔1 h 的時間段,例如t=0 時刻表示0:00—1:00(包括0:00 時刻)的時間段。
定義2定義第d天、第t時刻下用戶u的行為觀測數據集D(u,t)包括曝光數據aui(t)和點擊數據yui(t),即D(u,t)={aui(t),yui(t)},其中曝光數據aui(t)表示用戶u看過或了解物品i,yui(t)表示用戶u點擊了物品i。且用戶u只能在物品i已曝光的條件下點擊它,即p(yui(t)=1|aui(t)=0)=0。
定義3定義用戶背后隱藏了多個群組角色uw(u,t),(w=1,2,…),w為角色類型,譬如可以是家庭中常見的角色類型:兒童、青少年、成年人、老人等。本文依據實驗數據集特性,按照不同物品訪問的群體(群組角色)不同對物品進行劃分,且為符合現實情況和便于說明,將群組角色定義為三類并給定對應的標簽:兒童、成年人、老人。在不同時刻下,產生用戶點擊行為的角色類型是隨時間變化的。
問題定義給定任意用戶u∈{1,2,…,U}以及用戶在前m天不同時刻下的行為觀測數據集D(u,t)、用戶角色uw(u,t),本文的任務是通過構建學習模型獲得用戶隨時間變化的偏好預測函數,從而能夠對m+1 天之后的用戶行為進行Top-K推薦。
2.2 相關符號
為了能更好地闡述本算法的模型,本節給出本文中所用的相關符號及其含義,如表1所示。

表1 相關符號及含義Tab.1 Related symbols and their definitions
3 面向群組用戶時序行為的動態偏好推薦
3.1 模型描述
本文主要研究用戶群組角色隨時間而變化的情況下,如何結合用戶的曝光數據及點擊行為記錄對用戶偏好進行準確預測,即不同時刻下用戶背后的群組角色是隨時間變化的隱變量,本文將用戶每天的行為記錄看成一天24 個時刻下的周期行為。首先根據用戶的曝光行為數據構造出曝光模型,這里本文采用的是流行度模型,得到當前時刻下的群組角色,然后在物品已曝光的條件下,用戶偏好由傳統的矩陣分解模型推測得出。
矩陣分解是假設在一個推薦系統中存在用戶u∈{1,2,…,U}和物品i∈{1,2,…,I},對于給定的用戶點擊行為矩陣Yui∈RU×I,yui表示用戶u對物品i的點擊,θu表示用戶u的潛在偏好向量θu∈Rk,βi表示物品i的潛在屬性向量βi∈Rk,其中k為向量維度,求解出用戶潛在偏好特征矩陣Θu和物品潛在屬性特征矩陣Bi,使得兩者之積盡可能擬合Yui。一般可利用隨機梯度下降(Stochastic Gradient Descent,SGD)法迭代計算式(1)的局部最優解θu和βi:

其中:D表示用戶的所有觀測數據,即用戶的歷史行為記錄,表示模型的正則化項,λ為超參,用于控制模型的正則化程度。yui>0 表示用戶u對物品i的真實喜好程度表示系統預測的用戶u對物品i的喜好程度。
和經典的矩陣分解方法[19]一樣,假設隨時間變化的用戶潛在偏好向量θu(t)和物品潛在屬性向量βi(t)、用戶是否點擊已曝光物品yui|aui=1 的情況均服從正態分布,物品i是否對用戶u曝光服從伯努利分布,具體如下:
雷貝拉唑為苯并咪唑類化合物,是第二代質子泵抑制劑,通過特異性地抑制胃壁細胞H+、K+‐ATP酶系統而阻斷胃酸分泌的最后步驟。臨床上注射用雷貝拉唑鈉主要用于口服療法不適用的胃、十二指腸潰瘍出血,并可使基礎胃酸分泌和刺激狀態下的胃酸分泌均受抑制[1]。注射用雷貝拉唑鈉的臨床前藥理學的研究報道較少,有關臨床應用以及檢測方法的居多。本研究主要考察注射用雷貝拉唑鈉對不同潰瘍模型大鼠的抑制作用,包括對吲哚美辛引起的胃潰瘍、醋酸性胃潰瘍、大鼠反流性食管炎以及半胱胺型十二指腸潰瘍的影響。

其中:δ0表示t時刻下未對用戶u曝光的物品i,被用戶點擊了的概率為0或未被用戶點擊的概率為1,即p(yui(t)=1|aui(t)=0)=0 或p(yui(t)=0|aui(t)=0)=1。(λθ,λβ,λy)為引入的超參,μui(t)為物品i在用戶中的流行度,結合本文的實際研究問題,本文將討論兩種方式來構建物品的流行度模型。
對于偏好預測的點擊模型,由于此時用戶的觀測數據集并不是直接來自于點擊數據,因此利用傳統的貝葉斯后驗推斷會由于曝光模型所決定的數據分布導致系統的推斷結果產生偏差,即經常對用戶曝光的物品會產生太大的權重,而較少對用戶曝光的物品甚至沒有權重,最后可能導致用戶只能看到自己已經看過的東西,而未看過的東西一直不會被看到,久而久之,用戶就會陷入一個“信息繭房”,看不到自己真正感興趣的信息。
為了解決以上問題,本文借鑒了因果推斷[14]中的逆傾向評分加權思想,從觀測集中采樣物品并以其流行度的倒數對其進行加權訓練,使得在推斷用戶偏好時流行度高的物品權重減小,流行度低的物品權重增大,所有物品處于一個相對公平的環境里被均衡采樣,從而實現為用戶精準推薦的目的。
3.2 流行度模型
首先根據用戶的可觀測數據構造曝光模型,本文采用的是流行度模型。對于式(2)中的定義aui(t)~Bernoulli(μui(t)),一般做法是通過統計每個物品i被多少個用戶看見的比例來獲得最大似然估計即傾向評分值的計算為:

但本文中所要解決的問題是隱含多個群組角色的用戶興趣隨時間變化的動態推薦問題,因此結合問題本文具體設計了以下兩種求解傾向評分值的思路。
思路1 (Ours.v1)。物品i對用戶u的曝光是隨時間變化的。由于隱含在用戶背后的群組角色是隨時間變化的,例如對于電視點播數據集來說,早上7:00 可能是老年人在看早間新聞,晚上19:00 可能是兒童在看動畫節目。因此物品在不同時刻對于不同的群組角色曝光情況肯定是不同的,此時傾向評分值的計算為:


其中:Uw(u,t)的計算方法與式(4)中一樣,μi_w為當前t時刻下的物品在所屬物品集中的流行度矩陣,求得為|U|×24×|I|大小的矩陣。
3.3 用戶偏好推斷
在曝光的條件下,利用傳統的矩陣分解方法構造點擊模型去得到用戶隨時間變化的潛在偏好因子θu(t)和物品潛在屬性因子βi(t),從而根據推斷出用戶的偏好。
具體來說,利用逆傾向評分加權方法的矩陣分解模型的目標函數為:

首先計算用戶潛在偏好因子θu(t)。假設物品潛在屬性矩陣是一個隨時間變化的大小為|I|×k的矩陣β(t),其中k為向量維度,|I|為物品數目;對于每個用戶u定義一個隨時間變化的大小為|I|×|I|的對角矩陣Pu(t),其中Pu(t)=y(u)=yui表示用戶u的所有喜好,即用戶的點擊項。通過最小化損失函數(6)可得:

同樣地,假設用戶潛在偏好矩陣是一個隨時間變化的大小為|U|×k的矩陣θ(t),對于每個物品i定義一個隨時間變化的大小為|U|×|U|的對角矩陣Pi(t),其中Pi(t)=yui表示用戶u的所有喜好。同樣可得物品潛在屬性因子為:
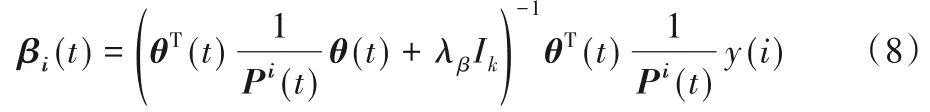
通過不斷迭代模型得到θu(t)、βi(t)的值后,取的值按從大到小排在前K位對應的物品為用戶做出推薦。
3.4 學習算法及時間復雜度分析
本節給出目標函數優化的完整算法流程,并分析該優化算法的時間復雜度,其中該算法的復雜度主要在目標函數參數更新的計算過程中。算法流程如算法1所示。
算法1 目標函數優化算法。
輸入 每個時刻下的點擊矩陣{Yui(t):?(u,i) ∈D(u,t)},潛在向量維度k,正則化參數λθ、λβ,利用式(4)或(5)計算出的傾向評分值。
輸出 隨時間變化的用戶潛在偏好因子θ1:U(t)和物品潛在屬性因子β1:I(t)。

在等式(7)中,βT(t)的計算對于每個用戶的時間復雜度為O(k2× |I|),將會耗費大量的計算時間。為了加速優化過程,本文采用WMF 中的方法,利用βT(t)βT(t)β(t) +βT(t)(1/Pu(t) -I)β(t),因此βT(t)β(t)的計算將獨立于用戶可以預先計算出來,而第二項βT(t)(1/Pu(t) -I)β(t)中的(1/Pu(t) -I)將只涉及到yui=1的項,因此時間復雜度與數據集中的用戶已點擊物品數成正比。式(7)中的y(u)同樣只與數據集中的用戶已點擊物品數相關。因此,式(7)中對于每個用戶的時間復雜度為O(k2|I|yui=1+k3+k|I|yui=1)=O(k2|I|yui=1+k3),其中O(k3)假設為式(7)中βT(t)β(t) +λθIk)-1的逆運算復雜度。則對于數據集中的所有用戶數|U|的總的復雜度為O(k2|I|+k3|U|),其中可知,該算法的時間復雜度與輸入的用戶數和物品數成正比,其中向量維度k的值在本文實驗中設置為50。同樣可知式(8)中物品潛在因子參數βi(t)的總的計算時間復雜度為
4 實驗結果與分析
4.1 度量標準
本文采用推薦系統中普遍適用的Recall、MAP(Mean Average Precision)、NDCG(Normalized Discounted Cumulative Gain)來評判模型性能。Recall衡量的是用戶推薦列表中的喜好物品數占測試集中用戶所有喜好的物品數比例;MAP 計算的是每個用戶的平均精度均值(Average Precision,AP),它考慮了推薦物品的位置,位置越靠前,MAP 值越高,推薦越精準;NDCG 是一個位置敏感型指標,推薦列表中用戶喜歡的物品位置越靠前,獲得的增益越大,推薦效果越好。假設Ru表示用戶u的Top-K推薦物品列表,Tu表示測試集中用戶u所有偏好的物品列表,d對應推薦列表中的物品。計算公式如下:

其中:I(x)是一個指示函數,當x>0 時,I(x)=1,反之為0。表示用戶u的推薦列表中的第n個位置的物品。Pu(n)表示用戶u在前n個物品上的準確度。Z是常數,其值為理想狀態下的DCG@K。
4.2 數據集
為了驗證不同類型的數據對算法性能的影響,本文將在IPTV和Cloud theme[34]2個真實數據集上進行實驗和對比分析。下面從數據集大小和數據特點等方面分別介紹這2個數據集。
IPTV 數據集為國內某運營商網絡電視節目點播數據集,其結構為用戶從2015 年10 月7 日到2015 年11 月9 日的歷史播放節目記錄,原始的數據中總共包含了18 萬多個用戶的5 398多萬條觀看記錄,篩選出每天都有播放記錄的活躍用戶并進一步定義用戶觀看時長小于1 min 的播放記錄為曝光但未點擊的情況即(yui(t)=0|aui(t)=1),最終得到了2 920 個用戶,32 341個節目,2 227 811個曝光項的數據集。
Cloud theme 數據集為淘寶app 中云主題產品的用戶點擊數據,數據集包含了70 多萬個用戶在大促期間6 天的140 多萬條用戶點擊日志,涵蓋355 個不同場景,同時提供了商品與主題的對應關系、用戶在大促前1 個月的購買日志。同樣地,通過設置每個物品至少被10 個用戶點擊過,每個用戶至少點擊了3 個物品的篩選條件后,得到3 812 個用戶、25 382 個商品、52 282個曝光項。兩個數據集的具體統計信息如表2。

表2 數據集統計信息Tab.2 Statistics of datasets
其中,在構造流行度模型的思路2 中針對所有物品按照所屬的群組角色對應劃分成3 個不同的物品子集問題中,對于IPTV 數據集而言,由于原數據集給出了每個節目的類型標簽,因此可按照不同的節目類型訪問的群體(群組角色)不同對節目進行劃分,為了便于區分、說明,本文統一將節目劃分為三類并給定對應的標簽:兒童、成人、老人。劃分后的結果如表3。

表3 IPTV數據集的子集統計Tab.3 Subset statistics of IPTV dataset
對于Cloud theme 數據集,因為原數據集提供了每個物品所屬的主題標簽,因此可以依據給出的主題標簽聚合劃分成只有三類主題的物品子集,為了便于區分,同樣對三類主題給定兒童、成人、老人的標簽。劃分后的結果如表4。
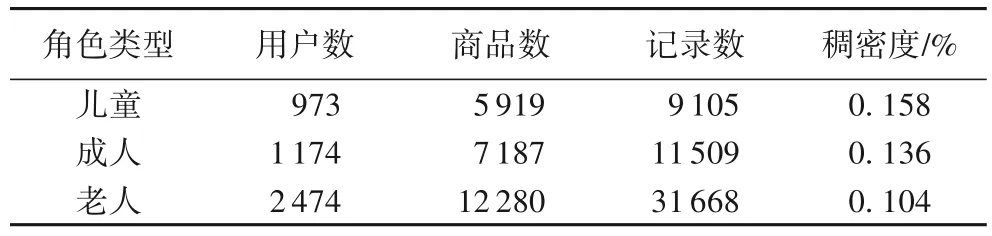
表4 Cloud theme數據集的子集統計Tab.4 Subset statistics of Cloud theme dataset
4.3 實驗和結果
4.3.1 實驗設置
本文使用以上兩個數據集來驗證提出的模型的可行性。對于每個數據集,將用戶的觀看/購買行為記錄按日期順序從小到大排列并以8∶2 的比例劃分訓練集和測試集,然后從訓練集中隨機抽取10%的數據作為驗證集,并確保測試集中的用戶和節目/物品為訓練集和驗證集中出現過的項。在所有的實驗中,潛在向量的維度設為50,在模型訓練的過程中,使用交替最小二乘法來訓練模型參數,正則化參數(λθ,λβ)通過網格化搜索依次從[e-5,e-4,…,e4,e5]中組合確定。
4.3.2 對比方法
本文采用了以下相關方法進行對比。
1)MF[15]。經典的矩陣分解方法,將用戶沒有的行為當作缺失值,并基于相似度矩陣填充缺失值。
2)NMF[16]。一種約定分解的小矩陣中所有元素均為非負數的矩陣分解方法。
3)IPW-MF[12]。本文進行改進的原對比方法,該方法在構造曝光模型中計算的是物品在整個數據集所有用戶中的流行度。
4.3.3 結果及分析
本節給出模型在兩個數據集上按一天24 個時刻進行Top-K推薦的實驗結果。為符合日常推薦情景,本文取Recall@20、NDCG@20、MAP@20 作為最后的性能評價。結果如圖1~2所示。

圖1 5種矩陣分解方法在IPTV數據集上的性能比較Fig.1 Performance comparison of five matrix factorization methods on IPTV dataset

圖2 5種矩陣分解方法在Cloud theme數據集上的性能比較Fig.2 Performance comparison of five matrix factorization methods on Cloud theme dataset
根據圖1 中的結果可以分析出:對于稀疏程度不高的IPTV 數據集來說,本文所提的模型(Ours.v1 & Ours.v2)在NDCG@20(圖1(c))和MAP@20(圖1(b))評價指標上明顯優于其他3 個模型;在Recall@20(圖1(a))上,Ours.v1 效果依然明顯優于其他方法,Ours.v2在前8個時刻召回率略低于IPWMF,但在后16個時刻上高于IPW-MF;同時對于MF和NMF來說,本文的兩個模型在3 個指標上遠遠高于MF 和NMF,說明在MF 基礎上對數據采用逆傾向評分加權值的方法去訓練的方案是可行的,且整體上Ours.v1的效果要優于Ours.v2。
在Cloud theme 數據集上,由于該數據集稀疏度較高,因此各模型的性能指標相對較低。在召回率Recall@20(圖2(a))的指標上,本文的方法優勝的時刻占大多數(Our.v1 有14 個時刻上的效果優于3 種對比方法,Ours.v2 有16 個時刻上的效果優于對比方法);在NDCG@20(圖2(c))上,本文的兩種方法明顯優于IPW-MF 和MF,但有3 個時刻(t=9,14,18)兩種方法的指標略低于NMF;在準確度MAP@20(圖2(b))上,Ours.v2 與Ours.v1 的效果不相上下,且Ours.v2 有8 個時刻上的效果都要明顯優于另外的4 種方法,同時NMF 有3 個時刻(t=9,14,18)準確度略高于本文的方法,可能是因為這3個時刻下的用戶行為數據相對較多,導致了NMF 模型效果的提升。整體上看,模型效果的優先級為:Ours.v2 >Ours.v1>NMF>MF>IPW-MF。
另外本研究也在WMF[11]和ENMF[21]上做了一系列對比實驗,結果顯示在IPTV 數據集上,兩個模型效果略高于本文的兩個模型;但在Cloud theme 數據集中,本文的模型效果優于WMF 和ENMF,經猜想可能是因為這兩個模型不太適合處理稀疏程度高的數據。
5 結語
本文提出了一種面向群組用戶時序行為的動態偏好推薦方法,通過考慮用戶行為的時序信息,針對隱含多個類型角色行為的用戶采用基于矩陣分解的算法思想,設計兩種計算物品流行度的思路,并利用因果推斷中的逆傾向加權方法將基于流行度的曝光模型與矩陣分解模型結合起來,使得經常對用戶曝光的物品權重減小,讓所有訓練數據處于一個平衡的狀態。同時本文構建的推薦系統可以捕捉到用戶的興趣行為隨時間的動態變化,實現了推薦的動態性,通過在兩個真實數據集上的實驗結果表明本文的模型在召回率和時間效率上優于其他對比方法,因此本文的方法是切實可行的。
此外,本文對于基于用戶行為的時序推薦工作提供了一個新的思路,即可以探索隱藏在用戶背后的群組角色問題,因此未來的研究將關注模型自動學習群組用戶中各類型角色的權重方向上,并利用數據中的用戶行為周期和觀看時長等附加信息構造一個更加精準高效的推薦系統。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
意林原創版(2016年10期)2016-11-25 10:28:30
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
