基于BERT的不完全數據情感分類
2021-01-21 03:23:12陳黎飛
計算機應用 2021年1期
羅 俊,陳黎飛
(1.福建師范大學數學與信息學院,福州 350117;2.數字福建環境監測物聯網實驗室(福建師范大學),福州 350117)
0 引言
人工智能的第三次浪潮正改變著人們的生活方式,給人們的生活和學習帶來極大便利的同時,也使得互聯網用戶的信息呈爆發式增長。其中用戶輿論的情感信息備受企業、政府重視,比如微博上對熱點事件的評論,互聯網電影數據庫(Internet Movie Database,IMDb)對電影的評價等。對用戶數據進行情感分類挖掘對企業和政府的發展和運營具有重要的應用價值。
早期的自然語言處理任務中詞的特征表示方法主要有詞袋(Bag-of-Words)模型[1]和獨熱編碼(One-Hot Encoding)技術,其目的旨在將輸入的句子轉化為稀疏向量。顯然,這種特征表示方法沒有考慮單詞之間的相關性,且其高維性會耗費大量的計算機內存資源[2]。為了避免高維性問題,以Word2Vec[3]為代表的分布式向量表示(Distributed Representation)[4]技術得以發展,通過將輸入的句子表示為詞嵌入(Word Embedding)形式,就能利用向量之間的點積衡量句子間語義的相似性程度。
傳統的機器學習算法如支持向量機(Support Vector Machine,SVM)[5]、決策樹(Decision Tree)[5]常用于情感分類挖掘任務,但這些算法僅適用于樣本量少的情況并且容易產生過擬合的問題。隨著神經網絡[6]的發展,情感分類任務中相繼出現平移不變特點的卷積神經網絡(Convolutional Neural Networks,CNN)[7]、節點按鏈式連接的循環神經網絡(Recurrent Neural Network,RNN)[8]和有選擇性記憶信息的長短期記憶(Long Short-Term Memory,LSTM)[9]等模型。還有一些相關變體,比如結合條件隨機場(Conditional Random Field,CRF)的雙向LSTM模型[10]、CNN與LSTM結合的多通道策略神經網絡模型[11],以及添加注意力機制的雙向LSTM 模型[12]等,這些模型增強了情感分類任務中語義信息的相關性,有利于情感極性的判斷。
然而,現有的方法大多未考慮不完全數據對情感分類性能的影響。不完全數據常產生于人為的書寫表達錯誤等[13],以微博為例,人們希望用簡短的句子來傳達信息,并不計較句子中的語法錯誤或單詞拼寫錯誤等,而這些錯誤信息卻容易導致機器無法識別其中的重要信息,進而影響情感分類的效果。針對文本中出現的不完全數據問題,文獻[14]提出利用棧式降噪自編碼器(Stacked Denoising AutoEncoder,SDAE)對加噪的輸入數據進行壓縮-解壓縮訓練來重新構建“干凈”完整的數據,在含噪數據的情感分類任務中取得了優于隨機森林(Random Forest)等傳統機器學習模型的性能。也有研究提出將降噪自編碼器網絡與詞向量結合[15],用于提高分類的準確率;本文也將降噪自編碼器運用于提出的模型中以達到對不完全數據去噪的效果。
近年來,情感分類模型的性能得以有效提高得益于預訓練模型的發展[16]。預訓練模型通過在大規模語料庫上進行無監督訓練來提取下游任務所需的共有信息,然后對下游任務做基于梯度優化的有監督訓練。主流的預訓練模型BERT(Bidirectional Encoder Representations from Transformers)[17]是一種能夠進行并行計算的注意力機制模型,在自然語言處理的多個數據集上都取得了最佳的結果。由于這些數據集都是預先花費大量時間處理好的“干凈”完整的數據集,所以在處理不完整數據集的情感分類時的性能有所下降。在現實生活中不完全數據隨處可見,而人為處理大量噪聲數據費時費力,有必要對模型加以改進以提高其對不完全數據的分類性能。
基于上述分析,本文提出稱為棧式降噪BERT(Stacked Denoising AutoEncoder-BERT,SDAE-BERT)的新模型。新模型通過棧式降噪自編碼器對經詞嵌入后的原始數據進行去噪訓練,為不完整的原始數據重構生成相對完整的數據,接著將其輸入到預訓練的BERT 模型中進一步改進特征的表示,最終完成不完全數據的情感分類任務。
1 相關基礎
1.1 棧式降噪自編碼器
自編碼器(AutoEncoder,AE)是主成分分析(Principal Component Analysis,PCA)在神經網絡中的一種拓展,二者都是通過數據降維來提取重要特征,與PCA 不同的是,自編碼器具有非線性變換特點,能夠有選擇性地提取信息,對于有噪聲的數據可以使用降噪自編碼器(Denoising AutoEncoder,DAE)進行去噪處理。如果高維數據直接從高維度降至低維度只進行一次非線性變換,可能無法提取某些重要特征,于是可以采用文獻[14]提出的棧式降噪自編碼器來處理高維度噪聲數據問題。如圖1 所示,其中帶有“×”的數據表示噪聲數據,對輸入的數據每次編碼(解碼)都做一次非線性變換,相較于直接從高維到低維能提取和重組更深層的關鍵特征。
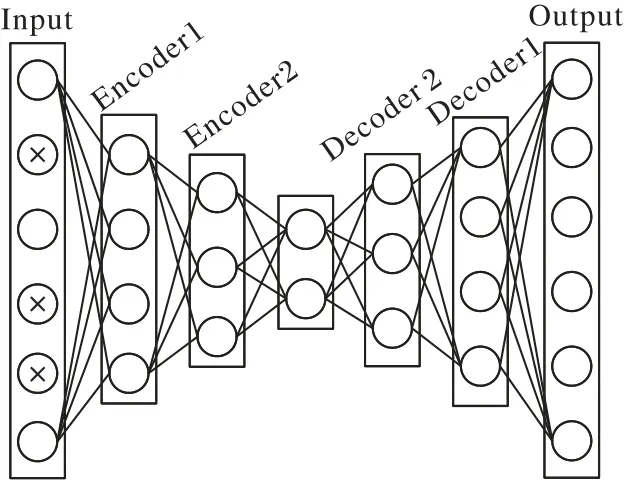
圖1 棧式降噪自編碼器Fig.1 Stacked denoising autoencoder
1.2 BERT模型
文獻[18]提出利用Word2Vec構建神經網絡語言模型,使得深度學習在自然語言處理領域變得可行。然而靜態的Word2Vec無法解決一詞多義問題[19],動態的詞向量模型便應運而生,如循環神經網絡[8]、長短期記憶網絡[9]等。循環神經網絡(RNN)的鏈式結構使得其擅長處理時間序列問題。但實驗證明,RNN 長距離記憶能力差,不適合處理長文本的分類問題,同時還存在誤差反向傳播時的梯度消失和梯度爆炸等問題。為了處理RNN 的短記憶問題,文獻[9]提出利用門控方法來解決記憶丟失問題的LSTM 模型。為了提取更深層次的特征表示,文獻[17]提出具有雙向Transformer 的預訓練模型BERT,并且該模型預先編碼了大量的語言信息。本文提出的模型將圍繞預訓練模型BERT 做進一步改進以處理不完全數據的情感分類問題。
1.2.1 輸入表示
BERT 模型的輸入特征表示由標記詞嵌入(Token Embedding)、片段詞嵌入(Segment Embedding)、位置詞嵌入(Position Embedding)三部分組成,最終輸入模型的向量表示由它們的對應位置相加,其中:Token Embedding 是固定維度大小的詞向量表示,它的第一個位置[CLS]編碼全句的信息可用于分類;Segment Embedding 用0 和1 編碼來區分一段話中不同的兩個句子;Position Embedding 編碼相應詞的位置信息。
1.2.2 Transformer編碼層
該層是對輸入的詞向量進行特征提取,使用的是Transformer[20]的編碼器端,如圖2 所示,其核心部分是多頭自注意力模塊。注意力機制能計算每一詞與句子中的其他詞的相關性程度,計算過程中每個詞不依賴于前面詞的輸出,因此注意力機制模型能并行運算。“多頭”允許模型在不同的表示子空間學到相關的信息,可以防止過擬合。對注意力模塊的輸出進行殘差連接可避免當前網絡層學習的較差,接著進行歸一化來提高算法的收斂速度。最后,將多頭注意力模塊的輸出經過全連接后再進行殘差連接和歸一化。BERT 模型由12 個相同的Transformer 編碼層串接而成,以增強網絡學習的深度。
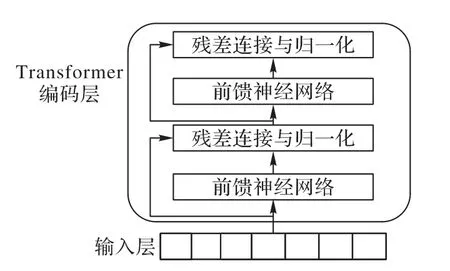
圖2 Transformer編碼層Fig.2 Transformer coding layer
1.2.3 掩蓋語言模型
常見的語言模型如ELMo(Embeddings from Language Models)[21]是基于馬爾可夫假設對單詞組成的句子做概率乘積,選擇概率最大的句子作為模型的輸出。而BERT 模型是在兩個無監督預測任務上對模型訓練,分別是掩蓋語言模型(Masked Language Model,MLM)和下一句預測(Next Sentence Prediction,NSP)。MLM 類似于英語中的完形填空任務,給出詞的上下文來預測被遮擋的單詞;NSP 是一個簡單的二分類訓練任務,用于判斷前后兩個句子是否連續。
掩蓋語言模型用特殊標記隨機替換掉句子中15%的單詞,被替換的15%單詞中有80%的幾率用[MASK]代替,10%的幾率用隨機的單詞替換,10%的幾率保持不變。從理論上講掩蓋模型引入了噪聲,模型對掩蓋的單詞重新編碼再來預測被掩蓋的單詞,因此,掩蓋語言模型本質上也是一種降噪的自編碼語言模型[22]。但是這種自編碼語言模型僅僅用于預訓練階段,而本文所使用的棧式降噪自編碼器用于下游任務中特定的數據集以實現對不完全數據去噪。
2 SDAE-BERT模型
不完全數據是相對于完全數據而言的,也稱不完整數據。不完整數據的句子中通常有單詞的拼寫、句子的語法等錯誤,從而導致句子的語義或語法出現結構混亂。表1 列舉了第3.1 節所用數據集中的常見錯誤類型,其中括號內為正確表示。在大多數非正式場合,人們為了方便交流,往往忽視句子結構的完整性,導致機器無法和人一樣識別某些重要信息,從而影響情感極性的判斷。

表1 兩種數據集常見錯誤類型Tab.1 Common error types of two datasets
2.1 棧式降噪BERT模型(SDAE-BERT)情感分類
在大語料庫中訓練的模型BERT,可以加入目標數據微調后進行情感分類。在此之前,還可以對原始數據的輸入特征向量表示進行棧式降噪自編碼訓練得到目標數據的特征表示,接著再用預訓練模型BERT 對目標數據進行情感分類。SDAE-BERT 的情感分類過程如圖3 所示。其中原始數據表示不完全數據,目標數據表示經棧式降噪自編碼器訓練后的相對“干凈”完整的數據。

圖3 SDAE-BERT的情感分類流程Fig.3 Sentiment classification flowchart of SADE-BERT
與BERT 模型后串接降噪BERT 的不完全數據情感分類[23]不同的是,本文提出棧式降噪BERT(SDAE-BERT)模型,用棧式降噪自編碼器直接對經詞嵌入后的原始數據訓練,再使用預訓練模型BERT 進行情感分類。模型的結構如圖4 所示,由4 層結構組成:輸入層、棧式降噪自編碼器(SDAE)層、BERT 層、分類層。在2.2 節將介紹SDAE-BERT 模型的4 個層次。
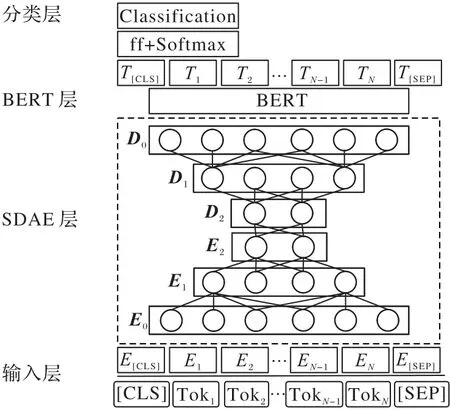
圖4 SDAE-BERT模型結構Fig.4 SDAE-BERT model structure
2.2 SDAE-BERT模型結構
2.2.1 輸入層
將原始的句子轉化為大小為(Nbs,128,768)的詞嵌入表示,其中:128 為句子的最大長度,768 為隱藏層單元個數,Nbs為批量處理數據的大小。
2.2.2 棧式降噪自編碼器層
棧式降噪自編碼器層由3 個分別含有兩個隱藏層的降噪自編碼器堆疊而成,編碼和解碼過程如式(1)、(2)。
編碼過程:
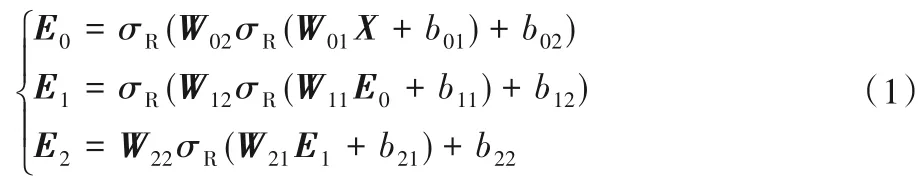
解碼過程:
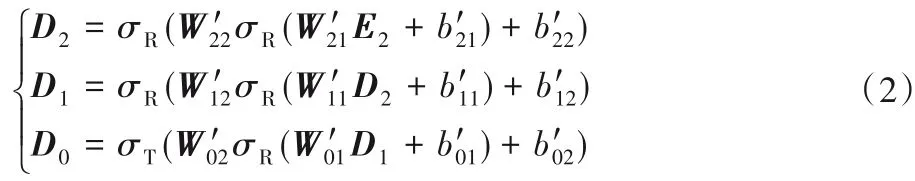
其中:X為不完全數據經過輸入層后的向量表示;E0、E1、E2,D2、D1為編碼,解碼過程中的中間變量;W、b,W′、b′為編碼,解碼過程中的權重和偏置。例如,W01表示第一個編碼器的第一個隱藏層的權重,b01為對應的偏置,為最后一個解碼器的第一個隱藏層的權重為對應的偏置,依此類推;σR為修正線性單元(Rectified Linear Unit,ReLU)激活函數,σT為雙曲正切(Tanh)激活函數。
把同樣的數據(即不完全數據)經眾包平臺的糾正處理后也即將不完全數據轉化為相對“干凈”完整的數據,糾正后的數據經過輸入層得到的X0作為棧式自編碼器的訓練目標,將SDAE 層的輸出D0與完整數據X0用均方誤差(Mean Squared Error,MSE)函數計算誤差并對誤差反向傳遞,使訓練數據D0接近于干凈完整的數據X0,誤差計算如式(3),其中Nbs為批量大小,表示每隔一個批量計算一次誤差大小,一個批量的誤差為整個批量的平均誤差。用Adam 優化器更新網絡參數直至損失在預期范圍內,保存此時的網絡參數用于下一層的BERT模塊。
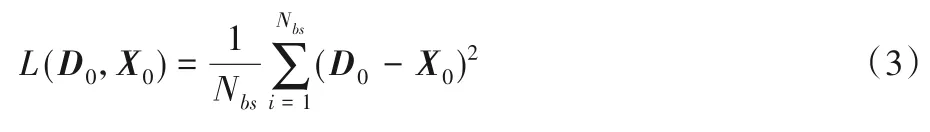
2.2.3 BERT層
將上一層棧式降噪自編碼器的輸出D0作為BERT 的輸入,用預訓練模型BERT 對輸入的特征向量微調。微調過程中使用二分類交叉熵損失函數,計算公式如式(4)所示。BERT 模型由12 個Transformer 串接而成,取最后一層的第一個特殊標記[CLS]用于情感分類。

其中:y表示真實的標簽值表示經過BERT 層后模型預測為正類的概率值。
2.2.4 分類層
把第一個特殊標記[CLS]經前饋神經網絡變換后用softmax 函數將線性變換的結果O(i)轉化為概率分布P(i),其中i∈1,2,分別表示正負類情感極性,計算公式如式(5),最后用arg max進行分類,取概率值大的對應標簽Y作為分類的結果,計算公式如式(6):

3 實驗結果及分析
為檢驗提出的模型與對比算法在情感分類中的性能,本文選取自然語言處理領域的兩個主流數據集Sentiment140 和IMDB 進行實驗。所提模型是在預訓練模型BERT 上進一步改進,預訓練的BERT 已經編碼了大量語言信息,所以在少量樣本上訓練即可得到理想的效果。
3.1 數據集
表2 為實驗的數據統計情況,Sentiment140 是斯坦福大學收集用戶情感信息的數據集,IMDB是有明顯情感傾向性的二分類影評數據集。從Sentiment140 和IMDB 中選取有明顯結構不完整性的句子分別6 000 個和3 600 個,其中訓練集占80%,測試集占20%,取訓練集中10%作為驗證集。同時復制一份同樣的數據,借助眾包平臺糾正這些不完整的數據,以獲得完整數據作為棧式降噪自編碼器的訓練目標,使得不完整數據經過堆棧自編碼器訓練后得到相對完整數據。
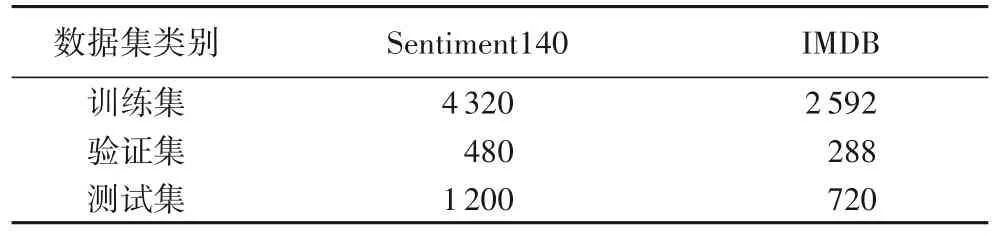
表2 實驗數據統計Tab.2 Statistics of experimental data
針對不同數據含有的不同錯誤類型,表3 中為對應的樣本數量統計,由表可知不完全數據中的錯誤類型主要是拼寫、語法、縮寫、發音、擬聲,因此有必要對不完全數據進行去噪處理,來提高不完全數據的情感分類準確率。
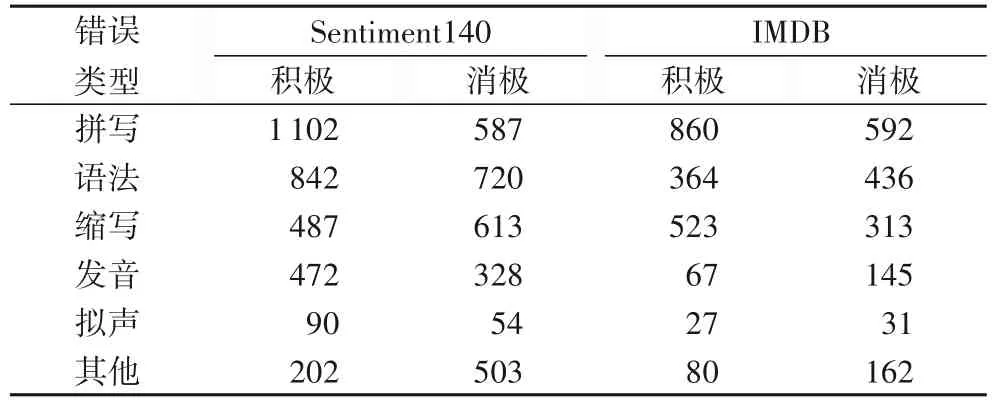
表3 不完全數據的錯誤類型統計Tab.3 Statistics of incomplete data error types
3.2 評價指標
本文分類器的主要評價指標有準確率(Accuracy)、精確率(Precision)、召回率(Recall),實驗采用準確率和調和平均值F1(F1-Score)值作為分類器的評價指標,由于實驗所選取的數據均為有明顯不完全數據特征的句子,因此采用宏平均(Macro-average)即macroF1 值代替調和平均值,以防止因數據標簽分布不平衡對實驗結果的影響,準確率的計算公式如式(7),macroF1值的推導如式(8)~(11):
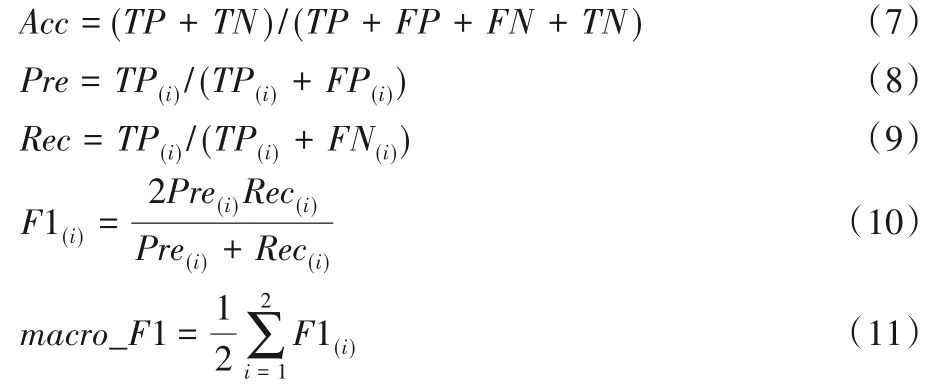
其中:Acc為準確率;Pre為精確率;Rec為召回率;macro_F1 為宏平均值;TP(True Positive)表示正類情感標簽被模型預測為正類的樣本數量;FP(False Positive)表示負類情感標簽被模型預測為負類的樣本數量;FN(False Negative)表示正類情感標簽被模型預測為負類的樣本數量;i表示第i個情感標簽(i取1、2)。
3.3 超參數設置
棧式降噪自編碼器層 輸入句子的最大長度為128,輸入的隱層節點數為768,在編碼器中隱層節點數分別為384、128、32,在解碼器的隱層節點個數分別為32,128,384,輸出的隱層節點數為768,訓練的epoch 值設為50,使用均方誤差函數計算損失、Adam優化器更新網絡參數,學習率為2E -3。
BERT 層 使用預訓練好的BERT-base 模型,模型由12個Transformer 模塊串接而成,12 個注意力頭,768 個隱層節點數,輸入句子的最大長度為128,模型的總參數大小為110 MB。在谷歌Colab 實驗平臺的GPU 上對棧式降噪自編碼器的輸出進行微調,訓練epoch 值設為10,使用Adam 優化器更新網絡參數,學習率為2E -5,批大小設為8。權重衰減系數設為0.001 以調節模型復雜度對損失函數的影響,為防止過擬合,dropout值設為0.1。
3.4 實驗結果對比
為了避免由于實驗過程中epoch 值的選定對實驗結果的影響,對SDAE-BERT 模型在兩個不完全數據集上進行實驗,在模型的批大小、學習率、樣本數量相同的情況下,改變epoch值,記錄不同epoch 值下的分類準確率和F1 值。實驗結果如圖5 所示,X軸為epoch 值的大小,Y軸為分類的性能百分比(Percentage)。不同線段類型分別代表準確率和F1。實驗結果表明,對于Sentiment140 在epoch 值為10 時,分類的準確率和F1 值達到最高分別為86.32%、85.55%,對于IMDB 在epoch 值為16 時,分類的分類的準確率和F1 值達到最高分別為84.86%、84.13%。隨著迭代次數的增加,模型逐漸擬合并且趨于平穩。綜合考慮分類性能和訓練時間復雜度,選取epoch值為10進行實驗。
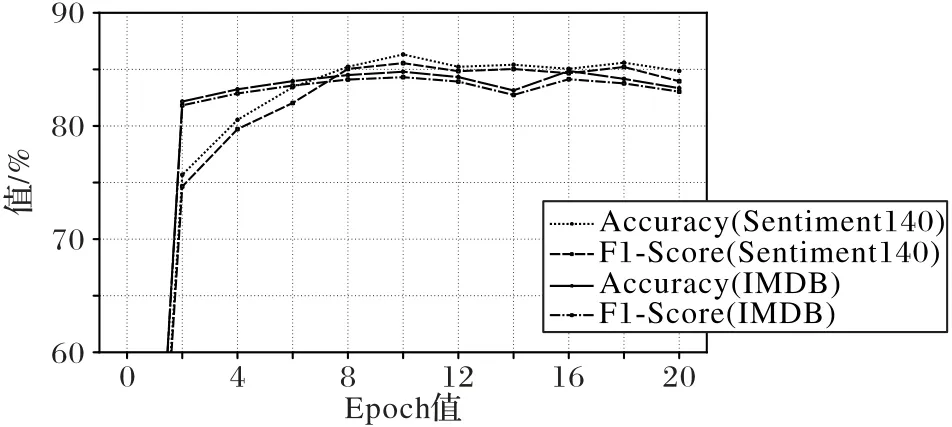
圖5 不同epoch值的SDAE-BERT模型結果Fig.5 SDAE-BERT model results with different epoch values
表4 為不同模型在兩個不完整數據集上的實驗結果。其中,SVM 是使用徑向基(Radial Basis Function,RBF)高斯核函數的支持向量機;LSTM是對文獻[6]的復現,在一定程度上能解決RNN 的記憶衰退問題。BiLSTM-ATT 是引入注意力機制的雙向LSTM 模型,其實驗結果是來自對文獻[8]的復現。BERT 是在兩個數據集下微調的結果,SDAE-BERT 為本文提出的模型。
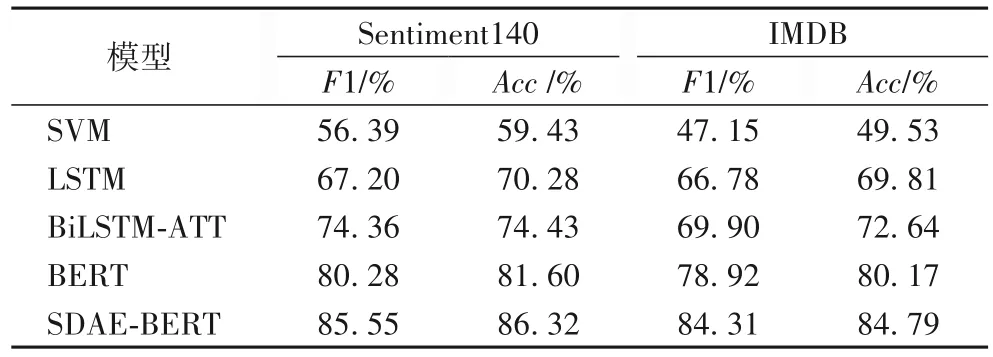
表4 不同算法在兩個不完整數據集上的結果Tab.4 Results of different algorithms on two incomplete datasets
表5 為不同模型在兩個完整數據集上的實驗結果,用來與不完整數據的實驗結果做對比,其所有參數設置與不完整數據集上的保持一致。
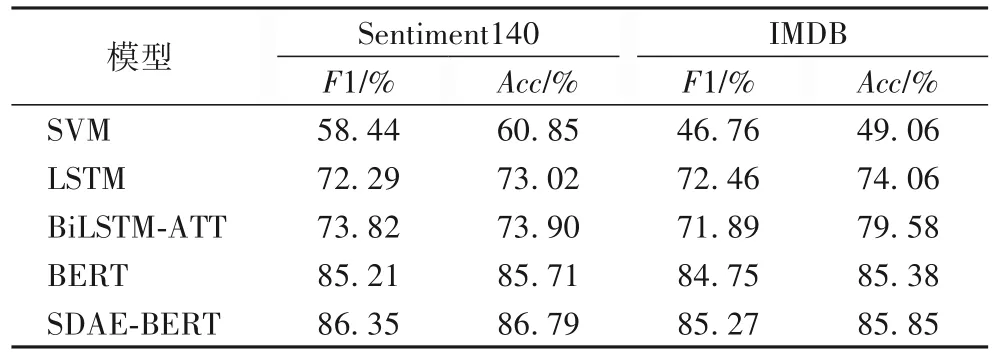
表5 不同算法在兩個完整數據集上的結果Tab.5 Results of different algorithms on two complete datasets
實驗結果表明,在訓練數據較小的情況下。預訓練模型BERT在不完整數據和完整數據上的F1值和分類準確率均高于支持向量機、LSTM 和有注意的LSTM 模型;對于不完整數據,LSTM 加入注意力機制比不加注意力機制的F1 值提高4%~10%,而對于完整數據則無明顯效果,猜測注意力機制可能對不完整數據更有效,注意力機制能根據上下文語境預測當前最適合的單詞;由表4 和表5 可知,在不完整數據集下的BERT 的分類效果比完整數據集下的BERT 低6%~7%,因此有必要對系統做進一步改進使其對不完整數據有同樣的分類效果。本文提出的模型SDAE-BERT 在不完整數據上的F1 值和分類正確率均高于BERT 及其他模型,與BERT 模型相比在F1 值和正確率上分別提高約6%和5%(向上取整),從而驗證SDAE-BERT 能有效地處理噪聲問題。表5 完整數據集上的分類效果相比表4 的不完整數據都有一定提高,表明完整數據更有利于情感分類。表5中SDAE-BERT 與BERT 模型的實驗結果無明顯區別,表明提出的模型能夠有效地對不完全數據進行情感分類。
基于上述實驗,選擇SDAE-BERT模型對比不同的訓練數據規模對實驗分類效果的影響,在保持模型結構和初始超參數不變的情況下,只改變數據集的規模。實驗結果如表6所示。

表6 不同樣本數量下的SDAE-BERT模型分類結果Tab.6 Classification results of SDAE-BERT model under different sample sizes
由表6 可得,訓練數據的規模對SDAE-BERT 的分類效果有較大影響,因此在對SDAE-BERT 進行訓練時,適當增加訓練數據模型能夠學習到更多的特征表示,從而能提高不完全數據的情感分類性能。
4 結語
針對BERT 未考慮不完整數據給情感分類性能帶來的影響,本文提出棧式降噪BERT(SDAE-BERT)模型。首先分析了棧式降噪自編碼器能夠對含有噪聲的數據去噪;其次對預訓練模型BERT 的輸入表示、Transformer 編碼層和掩蓋語言訓練方式進行描述;最后,提出將棧式降噪自編碼器與預訓練模型BERT 結合來處理不完全數據的情感分類模型。在不完全數據上的實驗結果有所提升,從而驗證了SDAE-BERT模型的有效性。
本文的不足在于所采用的數據集并非公共的不完全數據集,在對比方面存在一定的局限性;同時實驗的數據較少,對上下文信息的捕捉不充足。下一步工作準備在兩個方面進行展開:1)融合多個不完全數據集使得訓練的模型更具有普遍性;2)增大訓練數據的規模使模型充分提取上下文的信息。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
