
基于多級全局信息傳遞模型的視覺顯著性檢測
2021-01-21 03:23:28宋建偉
計算機應用 2021年1期
溫 靜,宋建偉
(山西大學計算機與信息技術學院,太原 030006)
0 引言
視覺顯著性源于認知學中的視覺注意模型,旨在模擬人類視覺系統自動檢測出圖片中最與眾不同和吸引人眼球的目標區域。顯著性檢測在很多視覺任務(例如目標跟蹤[1]、圖像語義分割[2]、行人重識別[3]以及基于內容感知的圖像編輯[4]等)的預處理階段起著至關重要的作用。
早期的顯著性檢測方法[5-6]主要采用一些計算模型和基于手工特征的傳統方法來預測顯著性區域。隨著深度學習的興起,較早階段采用的深度方法都是利用卷積神經網絡(Convolutional Neural Networks,CNN)提取特征的能力來預測像素點是否為顯著性區域。例如:Wang 等[7]提出一種將局部估計和全局搜索相結合的顯著性檢測算法;Li 等[8]提出了一種利用每個超像素的上下文CNN 特征來預測像素的顯著性值的顯著性檢測算法。雖然上述方法可以完成顯著性檢測任務,但是CNN 結構中的完全連接層會大幅地增加檢測的時間,降低計算效率,并且影響空間位置信息的捕獲。
針對這個問題,近幾年提出了基于全卷積神經網絡(Fully Convolutional neural Network,FCN)[1]來逐像素點地預測顯著性值。Lee等[9]提出將低層空間特征嵌入特征圖中,然后將其與CNN 特征組合以預測顯著性圖;Liu 等[10]提出了一個兩階段的網絡,該網絡首先產生粗略的顯著性圖,然后整合局部上下文信息對于顯著性細節分層優化,完善最終結果;Wang等[11]使用低級線索生成顯著性圖,并利用它以循環方式定位顯著性區域,從而完成顯著性預測任務。
但是這些工作主要利用了FCN 里單獨特定層的特征信息,沒有充分地考慮各級特征之間的信息互補作用。由于缺乏底層空間細節,使得顯著性圖無法保留比較精細的對象邊界。Luo 等[12]針對以上的問題,改進U 型結構的同時,又利用了多層次的上下文信息來準確檢測出顯著物體;Zhang 等[13]使用雙向結構在CNN 提取的多級特征之間傳遞消息,以更好地預測顯著性圖。
但上述的這些方法依然無法準確地檢測具有各種比例大小、形狀和位置各異的顯著性對象。而造成這些問題的原因主要有以下兩點:
1)以前大多數的基于FCN 的顯著性檢測模型依次堆疊單尺度卷積層和最大池化層以生成深度特征。由于感受野有限,因此通過這種網絡學習到的特征可能不包含豐富的多尺度全局信息。
2)在自上而下的網絡傳遞中獲得的豐富高級語義信息在反卷積的過程中,又被逐漸傳送到較淺的層,因此,較深層捕獲的信息在傳遞的同時逐漸被稀釋。
因此,解決上述問題的方法轉化為如何全局化多尺度地提取較高級語義信息,并且更有效地將全局高級語義信息和底層細節特征協同利用的研究。基于此,本文算法在多級特征分層處理的同時,充分地考慮高層特征空間的全局信息,通過引入多尺度全局池化特征聚合模塊(Multi-scale Global Feature Aggregation Module,MGFAM)集成網絡高級特征空間的不同尺度信息,全局化地提取到高層次特征圖層帶來的豐富語義信息。除此之外,為了將具有全局性的高級語義信息和底層細節特征有效協同利用,在本文中進一步將MGFAM提取到的特征信息進行特征融合操作,并且將融合的信息分別傳遞至較淺的層次;然后,將較淺層次中包含的底層空間細節信息和通過MGFAM 產生的全局高級語義信息進行融合,這樣可以有效地解決自上而下傳遞過程中的信息被稀釋,以及缺乏全局信息等問題。這些設計使得整體網絡輸出的特征信息包含全局高級語義概念和底層空間細節。
1 多級全局信息傳遞模型
在本章中,1.1 節具體描述了本文提出的模型整體結構;接著,在1.2 節中介紹了多尺度全局特征聚合模塊;最后,針對于不同級別的特征圖層,進一步設計了一種有效的特征融合方式以及多層次傳遞組合方式,這會在1.3 節中較為詳細地闡述。
1.1 模型整體網絡結構
在本文中,基于FCN 來構建模型的體系結構,并以VGG-16 Net 作為預訓練模型。總體構架如圖1 所示。本文模型使用的VGG-16 是以視覺顯著性檢測任務為驅動,從而做出修改的基干網絡。首先將VGG-16 網絡中的全連接層去掉,用于逐像素點預測;然后,將VGG-16 中最后的最大池化層去掉,從而使得最終輸出的信息保留更多細節。
在基本骨架VGG-16 信息傳遞的同時,對每層輸出的特征圖分別進行分層處理。為了增大感受野,學習更為豐富的上下文信息,在VGG-16的5個層次的輸出后都分別添加空洞卷積模塊;除此之外,為了多級上下文特征信息得到充分利用,隨后添加了門控雙向消息傳遞模塊。在此模塊中,高層級中的語義信息和低層級中的空間細節雙向傳遞,較深的層級將語義信息逐步傳遞至低級更好地實現顯著區域定位,而較淺的層將更多的空間細節傳遞給較深層次。因此,通過這種不同于骨干網絡的多層級信息相互傳遞配合以產生更準確的結果,最終經過融合得到輸入圖像初步的顯著性預測結果。
為了關注更多全局性的高級語義信息,本文引入了多尺度全局特征聚合模塊。此外,本文模型選擇合適的層級插入MGFAM,提取到不同層級的全局高級語義信息進行特征融合操作。為了包含更多的底層細節信息,本文模型還將提取出的有判別性的特征信息有指向性地進行特征傳遞操作。最后,將來自MGFAM 的指導信息和較低層次的初步預測結果進行融合得到最終的預測結果。
在圖1 中展示了模型所有的功能模塊。模型以256×256圖像大小作為輸入,先使用VGG-16 分層提取多級特征(第一行),利用MCFEM(Multi-scale Context-aware Feature Extraction Module)捕獲不同級別的上下文信息,然后經由門控雙向消息傳遞模塊(Gated Bi-directional Message Passing Module,GBMPM)后獲得初步的預測結果。在Conv4-3和Conv5-3后面添加了MGFAM,降維后進行特征融合操作。最終多層次多尺度信息融合,利用集成特征Prev1進行顯著性預測。
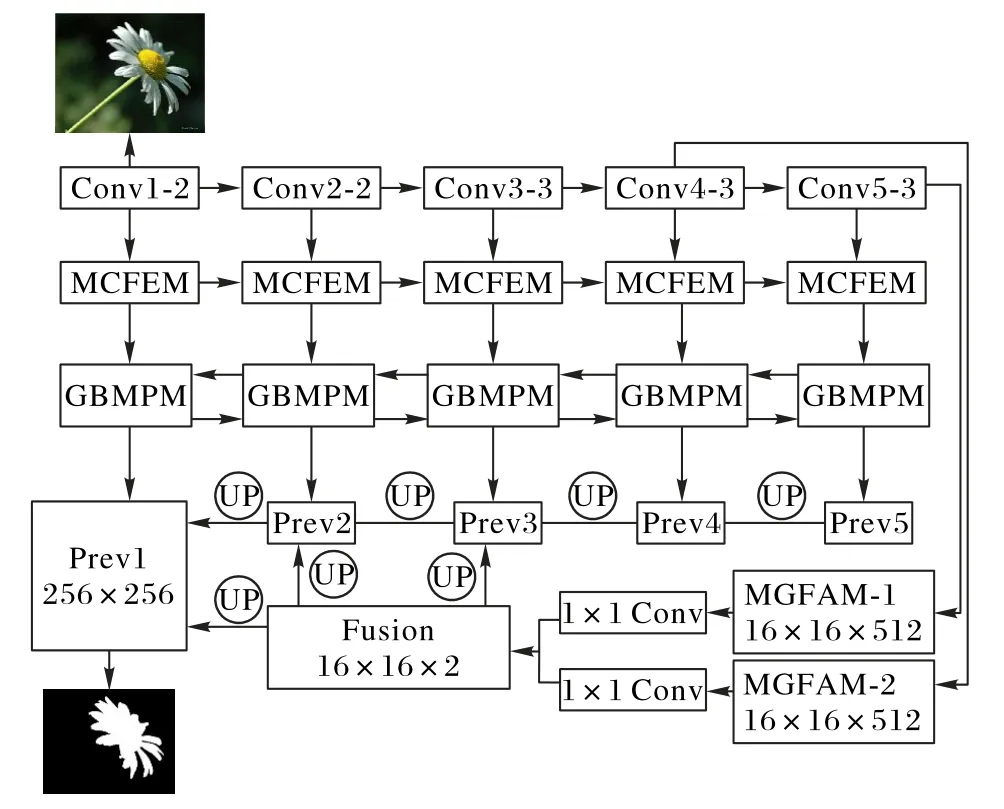
圖1 本文提出的模型的總體框架Fig.1 Overall framework of the proposed model
1.2 多尺度全局特征聚合模塊
在文獻[14-15]中都表明,FCN 的感受野比理論上要小很多,尤其是對于比較深的層次,感受野無法全局地捕獲或提取整張輸入特征圖像的全局信息。因此,檢測結果總是僅發現了顯著對象的局部信息,有嚴重的信息丟失現象。
目前,金字塔池化已經成功應用于圖像分割[14]等領域,并且針對以上問題獲得了不錯的解決效果。金字塔池化通過融合不同感受野大小的子區域的信息,可以提取出更豐富的全局特征。為此,根據顯著性檢測的任務特點,對其進行了調整和改進,引入了多尺度全局特征聚合模塊來解決這類問題。
圖2 顯示了MGFAM 的具體結構。本文模型在構建時摒棄了模塊傳統的嵌入方式,分別在Conv4層和Conv5層后添加MGFAM,雙分支并行提取出不同層級的全局信息。在尺度方面,根據顯著性檢測任務特點,本研究構建了4 種尺度的平均池化操作,將特征圖分別平均池化至1×1、2×2、4×4、8×8 的尺寸大小。圖中尺度最小的為最粗略的層級,是使用全局池化生成的單個bin 輸出。剩下的3 個層級將輸入特征圖劃分成若干個不同的子區域,并對每個子區域進行池化。為了保持全局特征的權重,4 個尺度池化后的特征圖分別都降維至1/4。

圖2 MGFAM的詳細圖示Fig.2 Schematic diagram of MGFAM
為了更好地表示第n個級別尺度的全局平均池化操作以及降維操作,其統一表示如(1)所示:
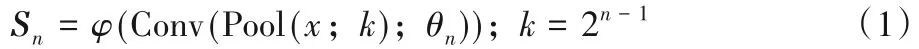
Sn表示經過不同級別全局平均池化再降維后的特征圖結果。接著將Sn分別上采樣至與輸入特征圖相同的尺寸。不同尺度特征圖從低分辨率上采樣至高分辨率的過程由以下方式執行:

其中:n表示尺度等級,n∈{1,2,3,4};x代表輸入的特征圖;k代表每一尺度等級池化后的分辨率大小;Conv(*;θ)是參數θ={W,b}的卷積層;Up(·)是上采樣操作,旨在將特征圖分尺度上采樣;φ(·)是ReLU(Rectified Linear Unit)激活函數。
最后,將不同尺度等級池化后的最終結果Gn和輸入的特征圖x拼接為最終的全局特征。為了保持通道維數不變,降維至原來的1/2。特征合并及降維的過程表示如式(3)所示:
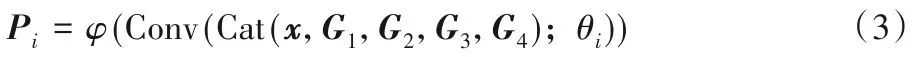
其中:Cat(·)是通道軸之間的串聯操作,Pi(i=4、5)為Conv4-3和Conv5-3 后輸出特征圖分別經過MGFAM 處理后的最終結果。
特征聚合的過程就是融合目標特征的過程,聚合過程中給予了原本的輸出特征圖較大的權重,用于提供VGG-16 網絡的原始層次信息。并且通過4 種尺度的池化,獲得了全局池化生成的單個bin 帶來的全局信息,以及其他3個尺度等級下的平均池化操作所提供的不同子區域之間的不同尺度信息。因此,特征聚合之后提供了本層級最為有效的全局上下文信息特征。
圖2 展示了多尺度全局特征聚合模塊的具體操作,每一層都分別池化至2n-1(n表示尺度等級)4 種尺度大小。上采樣后,將4種尺度池化分支拼接聚合后輸出。
1.3 特征融合及多層次特征傳遞
本文的基礎模型基于VGG-16 網絡構建。然而,VGG-16整體的結構是自上而下的單方向傳遞的,在特征提取的過程中特征圖逐漸減小。因此,在顯著性檢測任務中,經過VGG-16 網絡的輸出需要通過上采樣操作將特征圖調整到和輸入圖像一樣的大小。這一操作就使得高級特征在傳輸到較低層時將逐漸被稀釋。
為了解決這一問題,本文將通過MGFAM 提取出的全局上下文信息進行特征融合操作,并且設計了一種有效的多層次傳遞方式。
1.3.1 基于MGFAM的深層次特征融合
在深層次特征融合方式地設計上,不再保留MGFAM 作為每層的固有部分,只在VGG-16 的Conv4 層和Conv5 層后分別添加該模塊。
Conv5層作為VGG-16骨干網絡的最后一個block,具有最強的語義信息。但是輸出的特征圖分辨率較低,無法獲取更多的細節信息,對于細節的感知能力比較差。因此,在Conv4層后也獨立加入了MGFAM。Conv4 層輸出的特征圖分辨率是Conv5層的4倍,相比最后一個block來說,具有更多的位置以及細節信息,并且在全局池化的過程中對于信息的損失相對較少。
接著將Conv4 層和Conv5 層分別經過MGFAM 提取后的多尺度信息進行特征融合操作,多層級全局信息進行融合互補后,獲得更加具有判別力的特征。在后續2.2.2 節的模型簡化實驗中也詳細地闡述了這種特征融合方式的設計緣由以及有效性。
1.3.2 多層次特征傳遞
基于MGFAM 的深層次特征融合之后,為了保證其產生的指導信息可以與自上而下路徑中的不同級別的特征圖信息融合在一起。本文通過多層次特征傳遞的方式將指導信息傳遞到不同級別的特征圖層。在本文中,選擇將指導信息傳遞至前三層,充分地考慮到淺層特征更需要全局性的高級語義信息,本文算法采用的這種局部傳遞(Local propagation)方式減少了冗余信息。如圖3 所示,局部傳遞這種方法,比全局傳遞(Global propagation)方式(即,將指導信息自上而下傳遞到每個級別特征圖的方式)可以避免重復的全局高級語義特征堆積,減少冗余信息干擾。

圖3 多層次特征傳遞方式結果對比Fig.3 Result comparison of multi-level feature propagation schemes
例如圖3(d)既獲得了顯著性目標蝴蝶,同時也避免了與蝴蝶目標相連的黃色鮮花區域的干擾。最終傳遞的引導信息如式(4)所示:

其中F為Conv4-3 和Conv5-3 經過MGFAM 提取信息后,特征融合后所得的信息。
1.4 計算顯著性特征圖
在計算最終的顯著性預測結果的過程中,每層級的預測模塊Previ將特征圖hi和高層次預測信息Previ+1以及通過MGFAM 提取的多級全局信息的融合結果M作為輸入進行融合。每層級預測模塊的融合過程如下:
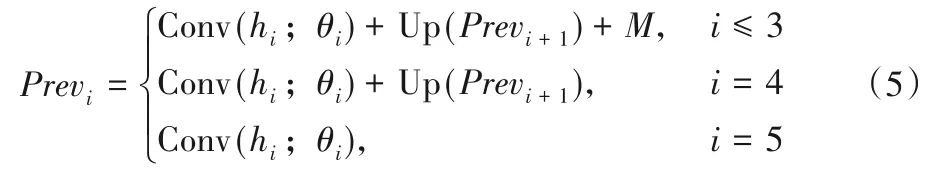
其中Conv(*;θi)是卷積操作,用1×1的卷積核來進行卷積降維處理。
模型的參數是通過最小化ground truth 和顯著性圖之間的交叉熵損失來優化的。Prev1是模型的最終顯著性圖預測結果。網絡通過最小化softmax 的交叉熵損失函數來端到端訓練提出的模型。式(6)給出了損失函數的定義:
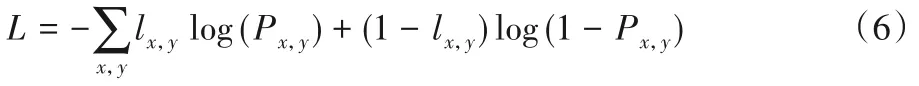
其中:lx,y∈{0,1}是像素(x,y)的標簽,Px,y是像素(x,y)屬于前景的概率。
2 實驗設計與結果分析
2.1 實驗環境與數據設置
實驗設置 本文的模型是基于TensorFlow 框架而實現的。網絡的骨干參數使用在ImageNet 數據集上預訓練的VGG-16模型進行初始化。對于除骨干網絡之外的卷積層,使用截斷法線法初始化權重。在后面提到的模型簡化測試中,默認情況,使用ECSSD 數據集進行測試對比。本文所有實驗均使用Adam優化器進行,初始學習率為1E -6。
數據集 為了驗證本文方法的有效性,本文在幾個主流的公共數據集上面評估算法性能。本文實驗選擇使用數據集有:DUTS[16]、PASCAL-S[17]、ECSSD[18]、SOD[19]和HKU-IS[20]。DUTS是一個大規模的數據集,其中包含10 553張用于訓練的圖像。這些圖像具有不同位置和不同比例以及復雜的背景,檢測這些圖像具有一定的挑戰性。在本文實驗中主要將該數據集作為訓練數據集。PASCAL-S數據集主要包含自然圖像。ECSSD 有各種復雜場景的圖像,包含許多語義上有意義但結構復雜的圖像用于評估。SOD 是基于伯克利分割數據集(Berkeley Segmentation Dataset,BSD)的顯著對象邊界的集合。HKU-IS 包括4 447 個具有挑戰性的圖像,在本文實驗中將該數據集的3 000幅圖像用于訓練,1 447幅作為測試圖像。
評估準則 在本文中,使用了在顯著性任務中廣泛使用的指標來評估本文方法的性能并且與其他方法進行對比,評估指標分別為準確率(Precision)、召回率(Recall)、平均絕對誤差(Mean Absolute Error,MAE)和F度量值(F-measure)。
除此之外,為了使實驗數據結果更加形象地展現,本文繪制了PR(Precision-Recall)曲線。PR 曲線對不同概率閾值(范圍從0到1)下的顯著性圖進行二值化并與ground truth進行比較,從而計算出最終結果。
為了更全面地對本文的模型進行評估,本文使用F 度量值(F-measure)來對整體性能做綜合度量,F-measure是查全率和查準率在非負權重β下的加權調和平均值,定義如下:
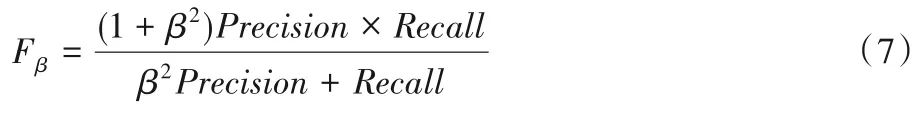
如文獻[21]所述,將β2設置為0.3 的權重精度要比召回率高。MAE是直接計算模型輸出的顯著性圖與ground truth之間的平均絕對誤差,首先將兩者進行二值化,然后通過式(8)進行計算:

其中:P和G分別顯著性圖預測結果和ground truth;W和H分別表示P的寬度和高度。
2.2 模型簡化測試
為了證明MGFAM 和深層次特征融合的有效性,進行了模型簡化測試。除了MGFAM 和融合方式的不同組合之外,所有其他配置都相同。圖4展示了不同組合的視覺效果。
2.2.1 MGFAM的有效性
為了捕獲圖像豐富的全局上下文信息,本文引入了MGFAM。本文在選擇插入MGFAM 的VGG-16 網絡層次上做了更多考慮。如果輸入MGFAM 的特征圖分辨率太大,那么在進行分尺度池化的過程中,對于分辨率大的特征圖來說因為直接將其全局池化至1×1、2×2 等很小的尺度,在獲取全局信息的同時會丟失更多信息。按照設想,分別在VGG-16 每層都添加MGFAM,最后因為損失太大很難完成顯著性檢測任務。
除此之外,本文通過實驗做了更多的嘗試,比如只在Conv1 后加MGFAM,只在Conv2 后加MGFAM,分別在Conv1、Conv2、Conv3 后加MGFAM 等,實驗證明在VGG-16 網絡的較淺層添加MGFAM,反而會因為損失太大而嚴重干擾檢測結果。
因此,在前期實驗中只在分辨率最低的Conv5 后添加MGFAM。如表1,MGFAM 使得檢測結果在ECSSD 數據集上的F-measure 和MAE 均得到了提升。MGFAM 多尺度多區域的池化操作,更突出了顯著物體在全局上的完整性。如圖4(c),是不加MGFAM 的基礎結果,對于感受野比較有限的模型,總是錯誤地將背景估計為顯著物體。而圖4(e),是在Conv5 后添加MGFAM 之后的檢測結果。可以明顯地觀察到,引入的MGFAM在顯著性檢測任務中起到了較好的效果。
為了進一步證明MGFAM 的有效性,本文選擇結構和MGFAM 相似,具有代表性的多平行分支提取特征的模塊ASPP(Atrous Spatial Pyramid Pooling)[22]來做比較。圖4(d)展示了引入ASPP模塊后的最終檢測結果。可以明顯地觀察到,雖然ASPP模塊因為集成了不同感受野下的多尺度信息,起到了一些作用,但是ASPP因為是一種稀疏的操作會造成棋盤偽影效應,并且因為缺乏全局信息的提取,很易受到復雜背景干擾。
2.2.2 特征融合的有效性
在提取特征信息的過程中,既想要得到對細節感知能力較強的信息,又不想因為分辨率太大,使得在多尺度全局池化時讓信息損失太多,所以在融合方法的設計上本文放棄了在較底層上做處理。Conv3 層作為承上啟下的中間層,往往無法捕獲有判別力的特征信息。通過實驗表明,Conv3 對結果沒有決定性的影響,為了避免信息的冗余利用,放棄了選擇連同Conv3 層做融合操作,只在Conv4 層和Conv5 層加入多尺度全局池化特征聚合模塊。
而針對融合和多尺度全局池化的先后順序,本文通過實驗又做了進一步的探討。表1 第1 行第4~6 列數據為先將Conv4層和Conv5層輸出的特征信息融合后再使用MGFAM進行多尺度全局池化(MFa)的F-measure(Max F)及MAE 結果,由表1可以看出,相較于只在Conv5層后添加MGFAM(表1中MGFAM)效果又有進一步提升。接著改變策略進行實驗,在Conv4 層和Conv5 層后先分別加入MGFAM,將其分別經過MGFAM 提取后的多尺度全局信息再進行特征融合操作(MFp),實驗結果(第2 行第4~6 列數據)表明,這種操作因分層處理有更好的表現。
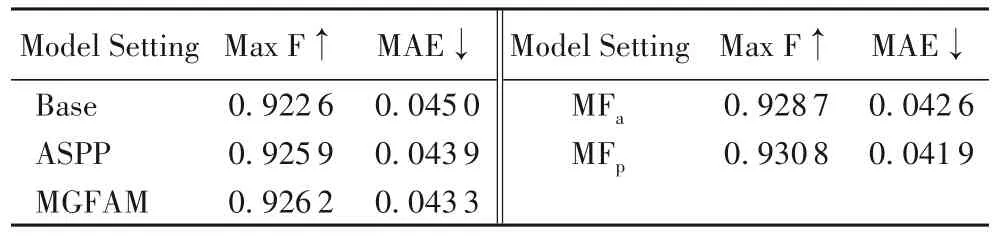
表1 ECSSD數據集上模型簡化測試結果Tab.1 Model simplification test results on ECSSD dataset
由表1 ECSSD 數據集上進行模型簡化測試結果可以看出,模型中的MGFAM 以及融合操作都至關重要,并且都為檢測性能做出了一定的貢獻。
由圖4 可以看出,在Conv4 和Conv5 分層添加MGFAM 后再進行特征融合的操作,既得到了對細節的感知能力較強的信息(第1 行),又獲得了豐富的全局信息,使得顯著性檢測結果對前景和背景的分辨能力更強(第2~3行)。

圖4 模型簡化測試結果Fig.4 Model simplification test results
2.3 性能與比較
將本文提出的顯著性目標檢測模型與較先進的7 種算法進行了對比。其中HS(Hierarchical Saliency detection)[23]、wCtr(saliency optimization from robust background detection)[24]是傳統的顯著性檢測算法,而PFAN(Pyramid Feature Attention Network for saliency detection)[25]、BDMP(Bi-Directional Message Passing model for salient object detection)[13]、DGRL(Detect Globally,Refine Locally)[15]、NLDF(Non-Local Deep Features for salient object detection)[12]和DSS(Deeply Supervised Salient object detection with short connections)[26]是基于深度學習的顯著性目標檢測算法。為了保證對比實驗的公平性,NLDF、BDMP、DGRL 等主流的深度學習算法結果是使用原文作者提供的開源代碼以及模型來進行訓練、測試及評價獲得的。對于PFAN 算法本文按照原文作者所提供的圖像結果進行評價,獲取最終的指標評價結果。
2.3.1 定量評估
本文的算法在4 個基準數據集上與7 種主流的顯著性檢測算法進行了比較。從表2 可以看出,本文的算法在ECSSD數據集上相較于HS、wCtr 等傳統顯著性檢測算法在Fmeasure 值上提高了0.25 左右,MAE 也分別降低了0.18 和0.12。除此之外,相較于NLDF以及BDMP等較先進的基于深度的顯著性檢測算法,F-measure 值分別提高0.028 和0.008;其中相較于NLDF 算法,MAE 值也降低了0.023。除此之外,該算法在其他數據集下的F-measure 和MAE 均有較好的表現,這有力地證明了本文所改進的模型的有效性。圖5 列出了4 個數據集上不同算法的PR 曲線。由圖5 可以看出,本文算法的PR(Precision-Recall)曲線在4 個數據集上的表現總體優于其他算法。
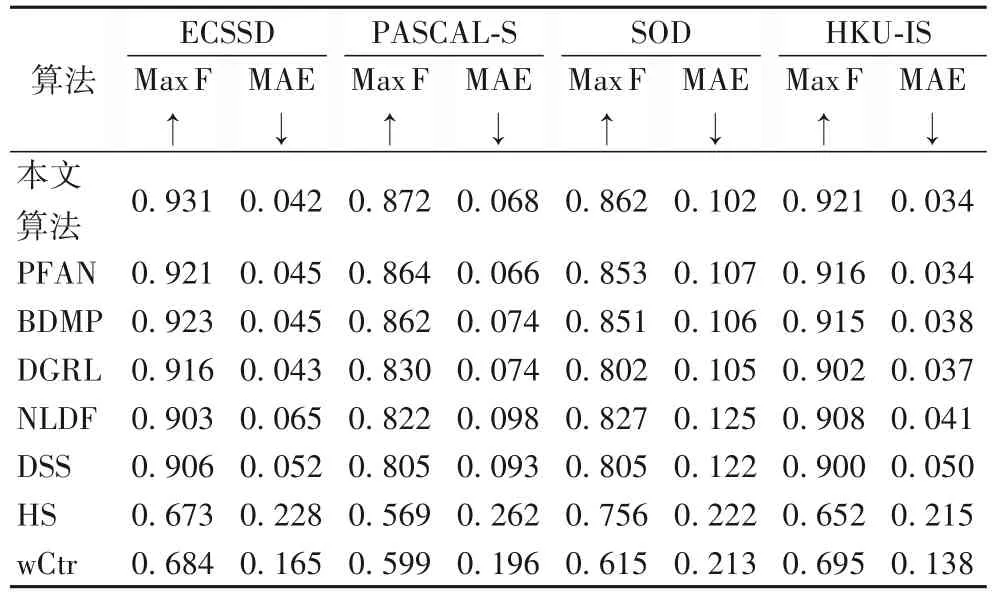
表2 本文算法與7種顯著性目標檢測算法在4個廣泛使用的數據集上的定量比較Tab.2 Qualitative comparison of the proposed algorithm with 7 saliency object detection methods on 4 widely used datasets
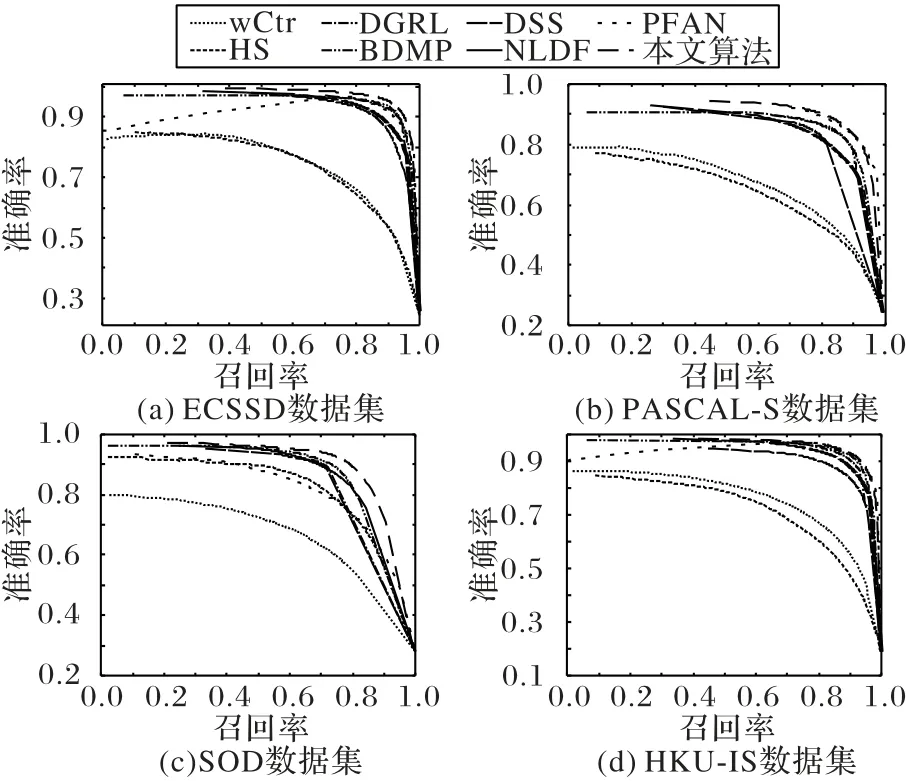
圖5 8種算法在4個流行的顯著性目標檢測數據集上的PR曲線對比Fig.5 Precision-Recall curves comparison of eight algorithms on 4 popular salient object detection datasets
表3 列出本文在NVIDIA 1080Ti GPU 的硬件設備條件下測試一張輸入圖像的平均消耗時間。由表可以看出,本文的全卷積網絡模型,與大多數先前的顯著目標檢測算法相比,也達到了較高的運算速度。
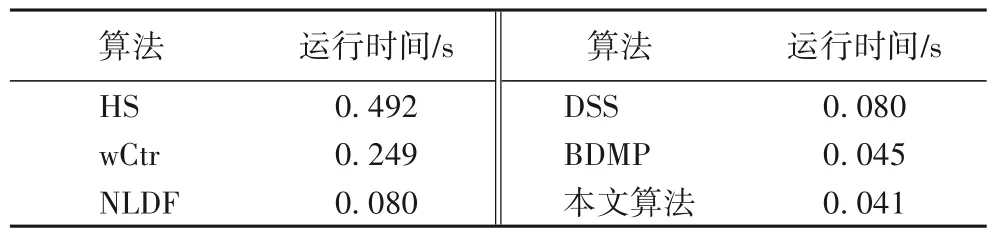
表3 各算法平均運行時間比較Tab.3 Average running time comparison of different methods
2.3.2 定性評估
為了進一步證明本文算法的優勢所在,圖6展示了本文算法最終顯著性預測結果,從而定性地分析模型優越性。圖6列出了本文模型和7種經典算法生成的顯著圖的視覺效果對比。

圖6 本文算法與7種顯著性目標檢測算法結果的定性比較Fig.6 Quantitative comparison of the results of the proposed algorithm and 7 salient object detection methods
從圖6中(第1行)可以清晰地看出,本文的算法針對前景和背景不明顯的圖片依然有較好的檢測效果。不論是對于有復雜場景(第2、3行),還是多對象(4、5行)、小對象(6、7行)以及大對象(8、9 行)的圖片均有不錯的檢測效果。除此之外,因為同時也集成上下文信息,分層提取特征,所以本文的算法不僅在全局方面能更可靠地檢測,在邊緣細節上也有較好的表現,如圖6(第8、9行)。
但是在多尺度全局池化的過程中,不可避免地會造成一定的信息丟失;同時,在傳遞方式上的選擇也不夠優雅,雖然給底層提供了更有判別力的全局信息,但是因其多倍的上采樣,使得結果在邊緣和細節的處理上仍然不夠樂觀。
3 結語
本文提出了一種基于多級全局信息傳遞模型的顯著性檢測算法,算法引入了多尺度全局特征聚合模塊,并且提出了有效的深層次特征融合算法,最終采用多層次特征傳遞的方式將較低層的特征信息和較高層全局特征信息組合,從而獲得顯著性目標區域。通過定性與定量實驗比較驗證了本文提出的算法不論是在性能上還是在速度上均有較好的表現。
針對多層級多尺度池化和上采樣帶來的信息損失問題,在未來的工作中,將考慮在充分利用全局信息的同時,增強邊緣和細節上的處理;此外,將進一步優化網絡結構,探索新的信息傳遞方法來減少信息損失。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
