研究客戶聲音反映問題溯源分析效率提升的新方法
2021-01-21 09:27:46黎偉健葉天寬胡莉瓊朱凱亮
科技傳播 2020年24期
黎偉健,葉天寬,彭 濤,胡莉瓊,朱凱亮
1 研究背景
1.1 背景介紹
互聯(lián)網(wǎng)的高速發(fā)展引領(lǐng)我們進(jìn)入了一個(gè)信息量爆炸性增長(zhǎng)的大數(shù)據(jù)時(shí)代,特點(diǎn)是數(shù)據(jù)量大、速度快、類型多,一些已經(jīng)較為成熟的數(shù)據(jù)分析處理技術(shù)。運(yùn)用這些技術(shù)對(duì)行業(yè)數(shù)據(jù)進(jìn)行分析,實(shí)現(xiàn)海量的數(shù)據(jù)中,高效篩選和定位關(guān)鍵信息,并對(duì)此進(jìn)行深入分析,對(duì)提高行業(yè)的整體運(yùn)行效率以及增加行業(yè)利潤(rùn)都起到極大的推動(dòng)作用。
1.2 提出問題
1)數(shù)據(jù)源渠道單一。獲取客戶反饋的聲音主要是熱線客服渠道。
2)數(shù)據(jù)存在滯后性。客戶投訴由各子公司處理,處理后統(tǒng)一上傳至集團(tuán)客服系統(tǒng),客服系統(tǒng)T+1天再傳送至專業(yè)公司,因此數(shù)據(jù)存在滯后性。
3)依靠傳統(tǒng)的分析方法。目前對(duì)于客戶投訴的分析依靠傳統(tǒng)人工分析,耗時(shí)約7.6分鐘/件投訴。2019年1月—3月日均投訴量8 336件,按照30%對(duì)投訴分析有價(jià)值的有效單量計(jì)算,日均2 501件有效詳單,單憑人工分析需花費(fèi)19 006分鐘(相當(dāng)于40個(gè)人天工作量),通過逐一查看投訴詳單內(nèi)容,總結(jié)客戶投訴要點(diǎn)。如連續(xù)2~3天對(duì)于同一問題的客戶投訴量持續(xù)較高,才能觸發(fā)投訴預(yù)警,引起業(yè)務(wù)側(cè)關(guān)注并著手解決。
1.3 技術(shù)查新
目前在移動(dòng)通信行業(yè)通過客戶評(píng)論或投訴分析挖掘客戶關(guān)注熱點(diǎn)的應(yīng)用研究較少,客戶評(píng)論或投訴分析較多應(yīng)用在電商、新聞行業(yè),因此可借鑒其他行業(yè)的分析方法開展。
2 設(shè)定目標(biāo)
為滿足實(shí)際需要,將目標(biāo)定為:客戶聲音反映問題溯源分析效率提升至60分鐘/千件。
3 提出方案并確定最佳方案
3.1 提出可行方案
對(duì)歷史客戶聲音的內(nèi)容及分析環(huán)節(jié)進(jìn)行梳理,并將解決方法繪制成親和圖,如圖1所示:
方案一:基于正則表達(dá)式的分析方法。正則表達(dá)式是對(duì)字符串操作的一種邏輯公式,就是用事先定義好的一些特定字符、這些特定字符的組合,組成一個(gè)“規(guī)則字符串”,這個(gè)“規(guī)則字符串”用來表達(dá)對(duì)字符串的一種過濾邏輯。該方案通過預(yù)先準(zhǔn)備好的業(yè)務(wù)相關(guān)關(guān)鍵詞清單,利用正則表達(dá)式獲取相關(guān)客戶聲音信息,并結(jié)合業(yè)務(wù)特點(diǎn)得出原因分析結(jié)果。
方案二:基于關(guān)鍵詞模型的分析方法。在自然語言處理領(lǐng)域,處理海量的文本文件最關(guān)鍵的是要把用戶最關(guān)心的問題提取出來。不管是基于文本的推薦還是基于文本的搜索,對(duì)于文本關(guān)鍵詞的依賴也很大,關(guān)鍵詞提取的準(zhǔn)確程度直接關(guān)系到推薦系統(tǒng)或者搜索系統(tǒng)的最終效果。利用NLP技術(shù)構(gòu)建關(guān)鍵詞模型,并根據(jù)算法自動(dòng)提煉出客戶聲音的關(guān)鍵詞內(nèi)容,結(jié)合業(yè)務(wù)特點(diǎn)得出原因分析結(jié)果。
3.2 方案評(píng)估
從分析效果、維護(hù)成本方面進(jìn)行評(píng)估,最終選擇了關(guān)鍵詞模型方案。
3.2.1 分析效果
對(duì)于兩個(gè)方案的分析效果,對(duì)離線數(shù)據(jù)進(jìn)行模擬實(shí)驗(yàn)。
結(jié)果顯示,對(duì)同樣的客戶投訴內(nèi)容,方案二的分析效率更高(見表1)。
3.2.2 開發(fā)維護(hù)工作量
對(duì)于開發(fā)維護(hù)成本,對(duì)兩個(gè)方案進(jìn)行預(yù)估。
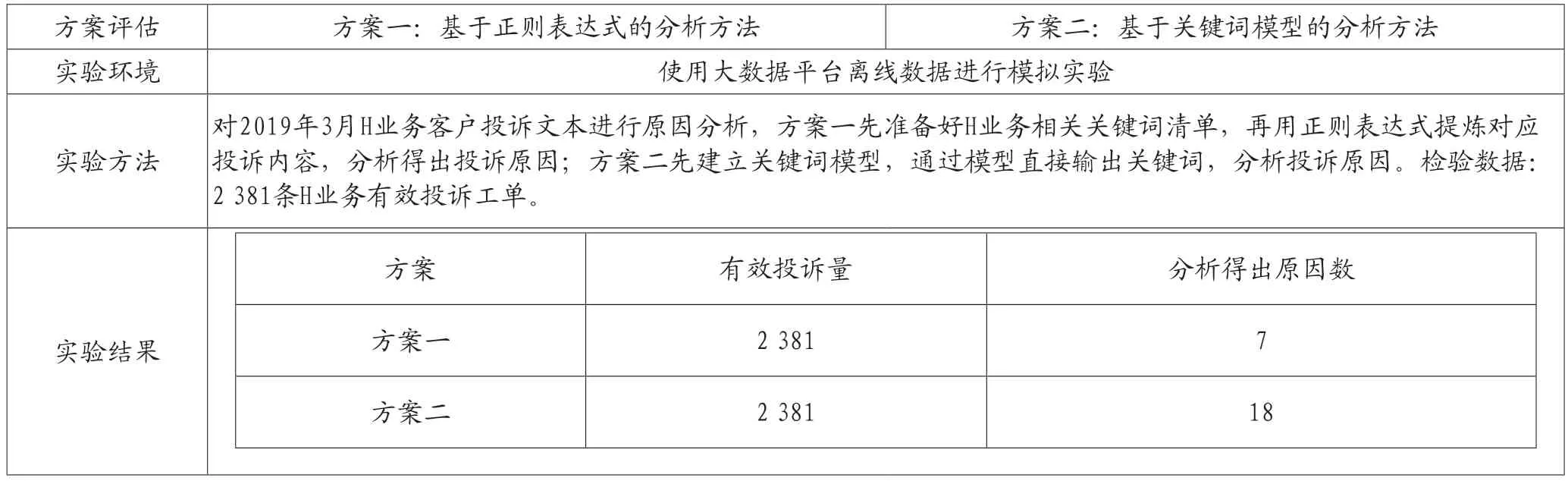
表1 兩方案的離線模擬實(shí)驗(yàn)

表2 兩方案的成本預(yù)估結(jié)果
根據(jù)成本預(yù)估結(jié)果(見表2),方案二開發(fā)維護(hù)工作量較小,對(duì)應(yīng)的人力成本較少。
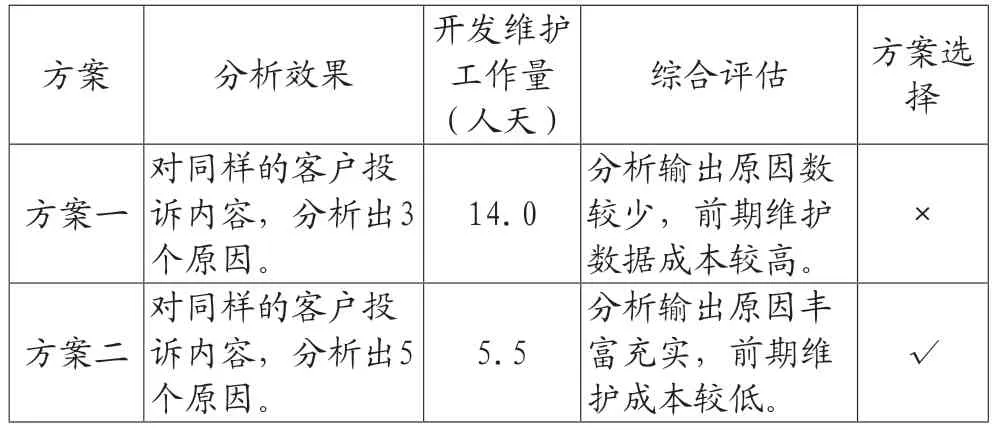
表3 可行性方案評(píng)估
由可行性方案評(píng)估表(見表3),客戶聲音分析效率提升的最佳方案是方案二:基于關(guān)鍵詞模型的分析方法。
3.3 方案選擇
3.3.1 分析數(shù)據(jù)源選擇
參評(píng)方案:
客戶在使用產(chǎn)品過程中,使用意見可以通過熱線傳統(tǒng)渠道反饋、互聯(lián)網(wǎng)渠道反饋,這些客戶聲音是客戶主動(dòng)參與,內(nèi)容真實(shí)度可靠、留言量大,評(píng)論涵蓋面更廣,既有負(fù)面批評(píng),也有正面肯定,甚至是改進(jìn)建議,對(duì)提升產(chǎn)品品質(zhì)和服務(wù)質(zhì)量具有較大參考意義。因此傳統(tǒng)渠道、網(wǎng)絡(luò)渠道是客戶聲音反饋的主要渠道,兩者應(yīng)同時(shí)納入分析源考慮范圍。
方案評(píng)比:
1)熱線傳統(tǒng)渠道:目前主要為全網(wǎng)投訴工單、在線交互文本、熱線語音(見表4)。
2)創(chuàng)新探索網(wǎng)絡(luò)渠道:主要有論壇、應(yīng)用商城、微博等渠道,這些渠道數(shù)據(jù)需主動(dòng)開發(fā)網(wǎng)絡(luò)檢索代碼獲取所有用戶評(píng)論(見表5)。
因此對(duì)比之下,傳統(tǒng)熱線渠道選擇全網(wǎng)投訴工單,互聯(lián)網(wǎng)渠道的客戶聲音選擇論壇。
3.3.2 數(shù)據(jù)庫類型選擇
參評(píng)方案:
當(dāng)前數(shù)據(jù)庫分為關(guān)系型數(shù)據(jù)庫和非關(guān)系型數(shù)據(jù)庫。
方案評(píng)比:

表4 傳統(tǒng)熱線渠道

表5 創(chuàng)新互聯(lián)網(wǎng)渠道
Microsoft SQL Server數(shù)據(jù)庫是關(guān)系型數(shù)據(jù)庫,它的二維表結(jié)構(gòu)是非常貼近邏輯世界的一個(gè)概念,關(guān)系模型相對(duì)網(wǎng)狀、層次等其他模型來說更容易理解,通用的SQL語言使得操作關(guān)系型數(shù)據(jù)庫非常方便,同時(shí)具備豐富的完整性大大減低了數(shù)據(jù)冗余和數(shù)據(jù)不一致的概率,易于維護(hù)。因此,選擇Microsoft SQL Server作為數(shù)據(jù)庫對(duì)象(見表6)。

表6 數(shù)據(jù)庫對(duì)比
3.3.3 分析算法選擇
參評(píng)方案:
文本分析算法有TextRank、TF-IDF等算法,使用不同方法對(duì)最后分析效率有直接的影響,衡量好壞的標(biāo)準(zhǔn)是關(guān)鍵詞重復(fù)率。為此,利用2種算法分析投訴工單、論壇評(píng)論,對(duì)比關(guān)鍵詞重復(fù)率。
方案評(píng)比:
分別對(duì)兩個(gè)算法進(jìn)行試驗(yàn)(見表7)。

表7 TextRank與TF-IDF算法對(duì)比
3.3.4 輸出形式選擇
參評(píng)方案:作為模型輸出結(jié)果,關(guān)鍵詞的輸出形式對(duì)分析原因有重要影響,針對(duì)詞云和關(guān)鍵詞清單這兩種輸出形式進(jìn)行對(duì)比(見表8)。
方案評(píng)比:
1)詞云:“詞云”就是通過形成“關(guān)鍵詞云層”,對(duì)系列文本中出現(xiàn)頻率較高的“關(guān)鍵詞”的視覺上的突出。
2)關(guān)鍵詞清單:這是一種將一系列關(guān)鍵詞按一定規(guī)則排序的詞匯列表,一般以電子表格形式呈現(xiàn)。

表8 詞云與關(guān)鍵詞清單對(duì)比
3.3.5 確定最佳方案
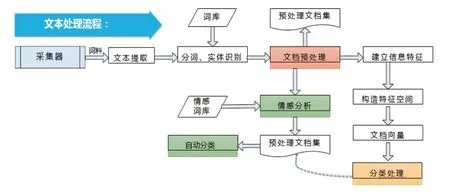
圖2 文本處理流程
4 實(shí)施對(duì)策
制定實(shí)施對(duì)策表,如表9。
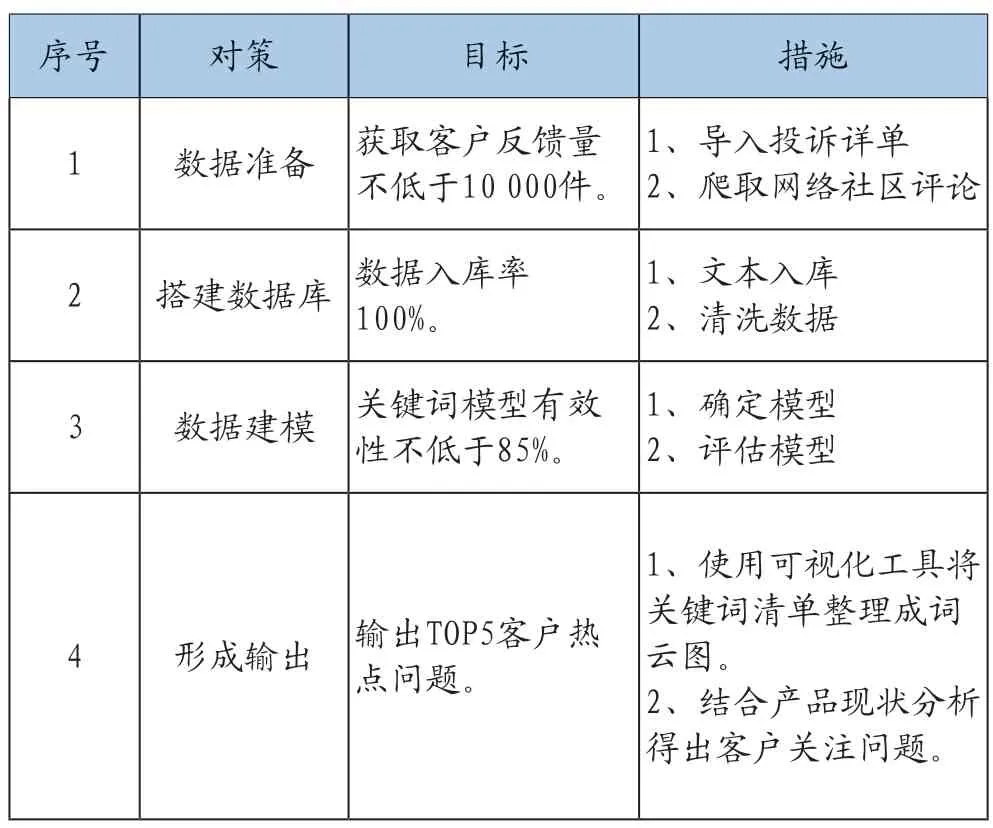
表9 制定實(shí)施對(duì)策表
5 按照對(duì)策表實(shí)施
5.1 實(shí)施一:數(shù)據(jù)準(zhǔn)備
實(shí)施項(xiàng)目:通過數(shù)據(jù)平臺(tái)下載客戶投訴詳單、編寫腳本檢索網(wǎng)絡(luò)社區(qū)用戶評(píng)論。
實(shí)施情況:
1)投訴詳單獲取。從數(shù)據(jù)平臺(tái)下載1-8月H業(yè)務(wù)投訴數(shù)據(jù),共768 292單。
2)論壇評(píng)論檢索。使用Python編寫H業(yè)務(wù)百度貼吧等網(wǎng)絡(luò)檢索腳本,對(duì)H產(chǎn)品1-8月客戶評(píng)論文本信息進(jìn)行批量檢索,共獲取1 214 467條評(píng)論。
目標(biāo)確認(rèn):
共獲取1 982 759件投訴詳單和網(wǎng)絡(luò)社區(qū)的評(píng)論,達(dá)成分目標(biāo)。
5.2 實(shí)施二:搭建數(shù)據(jù)庫
實(shí)施項(xiàng)目:將數(shù)據(jù)導(dǎo)入數(shù)據(jù)庫,實(shí)現(xiàn)100%入庫。
實(shí)施情況:
1)數(shù)據(jù)入庫。開啟Microsoft SQL Server服務(wù),創(chuàng)建數(shù)據(jù)庫YEW****_7002,并在數(shù)據(jù)庫下新建2張表,分別是客戶投訴表HL****XY91_DTL和網(wǎng)絡(luò)社區(qū)評(píng)論表H****XY3_comm,表結(jié)構(gòu)分別如下:為保證分析有效性,篩選有效投訴工單內(nèi)容(剔除空白值)和網(wǎng)絡(luò)社區(qū)客戶評(píng)論(剔除字符數(shù)<15的評(píng)論),使用SQL Server數(shù)據(jù)導(dǎo)入接口將兩張表導(dǎo)入到數(shù)據(jù)庫中,成功導(dǎo)入行數(shù)分別是498 821、912 034。
2)清洗數(shù)據(jù)。通過Python從SQL Server讀取兩張表文本,使用jieba工具包對(duì)中文文本自動(dòng)切詞,拆分成獨(dú)立詞匯,再使用停用詞表進(jìn)行無效詞過濾,實(shí)現(xiàn)文本清洗。
目標(biāo)確認(rèn):對(duì)兩張表入庫情況進(jìn)行統(tǒng)計(jì),情況如表10。
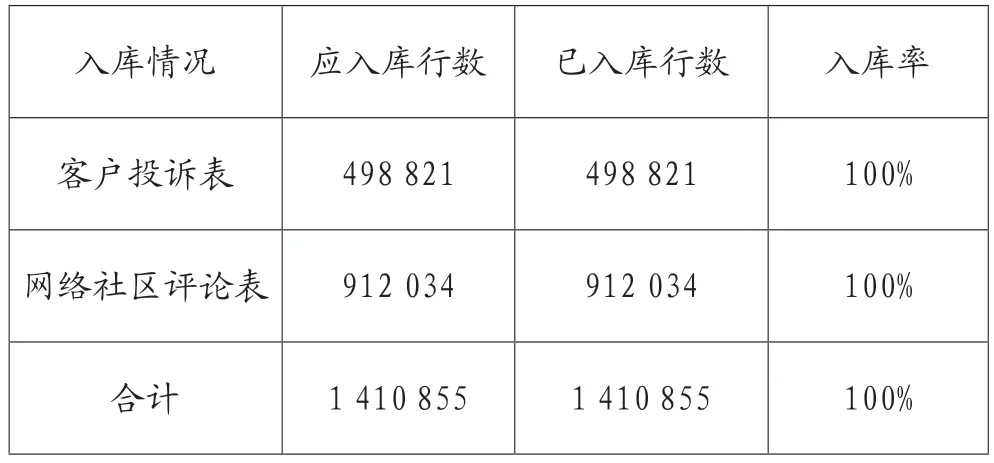
表10 入庫情況統(tǒng)計(jì)
本次客戶聲音數(shù)據(jù)入庫率達(dá)100%,達(dá)到目標(biāo)值,對(duì)策目標(biāo)達(dá)成。
5.3 實(shí)施三:進(jìn)行數(shù)據(jù)建模
實(shí)施項(xiàng)目:對(duì)清洗好的文本數(shù)據(jù)進(jìn)行關(guān)鍵詞模型訓(xùn)練,提煉出客戶聲音的關(guān)鍵詞。
實(shí)施情況:
1)訓(xùn)練模型。利用Python搭建關(guān)鍵詞模型,本次實(shí)施采用jieba工具包的TextRank算法,通過詞之間的相鄰關(guān)系構(gòu)建網(wǎng)絡(luò),迭代計(jì)算每個(gè)節(jié)點(diǎn)的rank值,排序rank值得到關(guān)鍵詞。
對(duì)每一條文本進(jìn)行上述操作,提取每一條文本的TOP5關(guān)鍵詞,直到遍歷全部文本數(shù)據(jù),輸出全部關(guān)鍵詞,保存為csv文檔。
2)評(píng)估模型。檢查每一條文本對(duì)應(yīng)的5個(gè)關(guān)鍵詞,如果發(fā)現(xiàn)關(guān)鍵詞不足5個(gè)的情況,屬于訓(xùn)練異常或樣本文本較短,可判斷為該條文本模型訓(xùn)練效果不佳。
經(jīng)統(tǒng)計(jì),本次共訓(xùn)練1 410 855條文本,其中1 219 259條文本所輸出的關(guān)鍵詞大于等于3個(gè)。
目標(biāo)確認(rèn):關(guān)鍵詞模型有效性為86.4%,對(duì)策目標(biāo)達(dá)成。
5.4 實(shí)施四:形成輸出
實(shí)施項(xiàng)目:使用可視化工具將關(guān)鍵詞清單整理成詞云圖,并結(jié)合產(chǎn)品現(xiàn)狀分析得出客戶投訴原因。
實(shí)施情況:
1)生成詞云圖。使用Python讀取關(guān)鍵詞csv文檔,準(zhǔn)備好數(shù)據(jù)源,用詞云工具包整理關(guān)鍵詞,并按關(guān)鍵詞出現(xiàn)頻次大小輸出凸顯效果不同的詞云效果,生成詞云圖,如圖3所示。

圖3 詞云圖
2)分析客戶關(guān)注焦點(diǎn)問題。從詞云圖選取最突出的關(guān)鍵詞,結(jié)合產(chǎn)品業(yè)務(wù)特點(diǎn)和現(xiàn)狀,以及實(shí)際客戶投訴內(nèi)容,分析總結(jié)出客戶關(guān)注焦點(diǎn)問題(見表11)。
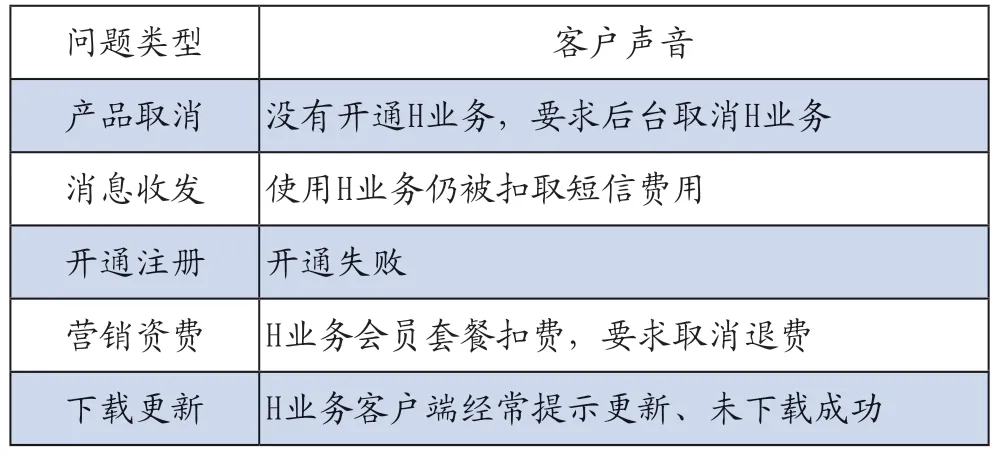
表11 客戶關(guān)注的焦點(diǎn)問題
目標(biāo)確認(rèn):輸出TOP5客戶熱點(diǎn)問題,達(dá)到目標(biāo)期望,對(duì)策目標(biāo)達(dá)成。
6 確認(rèn)效果
對(duì)策實(shí)施以后,客戶聲音分析效率平均值為55.2分鐘/千件,達(dá)到60分鐘/千件的目標(biāo)值。
猜你喜歡
民用飛機(jī)設(shè)計(jì)與研究(2020年4期)2021-01-21 09:15:02
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年18期)2018-11-14 01:48:06
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
山東工業(yè)技術(shù)(2016年15期)2016-12-01 05:31:22
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
