概率線性判別分析在語音命令詞置信度判決中的應(yīng)用①
2021-01-22 05:41:18閆宏宸
計算機系統(tǒng)應(yīng)用 2021年1期
閆宏宸,肖 熙
(清華大學(xué) 電子工程系,北京 100084)
計算機技術(shù)的發(fā)展為人類生活帶來了極大便利,基于語音的人機交互已經(jīng)以命令詞識別系統(tǒng)的形式在智能家居、可穿戴設(shè)備等平臺得到了應(yīng)用.命令詞識別系統(tǒng)是一種“N選1”的識別系統(tǒng),將輸入語音識別為預(yù)先設(shè)定的命令詞之一,系統(tǒng)的錯誤主要來自對集內(nèi)命令詞的錯識和對集外語音或噪聲的誤識.有鑒于此類系統(tǒng)使用環(huán)境的多樣性,通過某種手段拒絕錯誤的識別結(jié)果,特別是拒絕環(huán)境噪聲和集外語音引發(fā)的錯誤識別結(jié)果,對提高命令詞系統(tǒng)的可靠性極為重要.
對語音識別結(jié)果的置信程度加以檢驗和判決是一種比較理想的做法.在數(shù)理統(tǒng)計中,置信度分析是分析一個隨機變量落在某個區(qū)間的概率,而在語音識別中,置信度分析通常用于衡量模型與數(shù)據(jù)之間匹配的可信程度.置信度分析方法大致可以分為基于預(yù)測特征的組合、基于后驗概率和基于似然值比值(似然比)等3 大類方法[1].其中基于似然比的置信度分析方法將置信度問題轉(zhuǎn)化為統(tǒng)計假設(shè)檢驗問題,設(shè)定數(shù)據(jù)由某一模型產(chǎn)生(零假設(shè))和數(shù)據(jù)非由該模型產(chǎn)生(對立假設(shè))兩種假設(shè),通過兩種假設(shè)上的似然比檢驗以及閾值判斷是否接受零假設(shè).已有的置信度分析方法包括基于詞網(wǎng)格生成后驗概率的置信度[2]、基于逆模型建模對立假設(shè)計算似然比的置信度[3]等.
本文提出了一種無需聲學(xué)模型、語言模型支撐的命令詞置信度分析方法.調(diào)研發(fā)現(xiàn),身份矢量(identity vector,i-vector)特征[4]和概率線性判別分析(Probabilistic Linear Discriminant Analysis,PLDA)方法[5]已經(jīng)在說話人識別中得到了廣泛應(yīng)用,但是將i-vector 特征與PLDA應(yīng)用于命令詞語音識別的置信度分析中尚未有文獻(xiàn)報導(dǎo).i-vector 的原理是通過對所有語音數(shù)據(jù)訓(xùn)練,建立通用背景模型(Universal Background Model,UBM)[6],將語音表示為高維的均值超矢量(supervector),然后通過因子分析將其投影為低維、定長的矢量表示,其特點在于它能在較大的粒度范圍內(nèi)提取語音特征,可以作為一段語音信號的整體描述,這使得i-vector 作為無需語言模型支持的置信度判決的輸入特征成為了可能.另一方面,PLDA 方法最早發(fā)源于圖像領(lǐng)域的人臉識別應(yīng)用,通過增大類間差異,達(dá)到補償識別過程中無關(guān)因素的作用.由于在判決階段,PLDA 通過計算假設(shè)檢驗的比值(也即似然比)打分,因此其可以自然地作為一種置信度分析手段.
本文首先對漢語的1254 個全音節(jié)孤立字以及連接詞進(jìn)行了置信度實驗,考察了基于i-vector 和PLDA方法在置信度判決中的有效性.在連接詞實驗中分析發(fā)現(xiàn),i-vector 特征對語音在全局層面上的刻畫能力較強,但是對于語音中的時序特征的辨識,例如音節(jié)發(fā)音順序辨識,其存在一定的模糊性,而時序信息是語音語義的重要成分,這在命令詞識別中是不可回避的問題.針對此缺陷,本文在實驗驗證的基礎(chǔ)上,嘗試提出了改進(jìn)方法,較好地解決了此問題.
1 置信度與基線系統(tǒng)概述
1.1 置信度及其評價方法
語音識別系統(tǒng)的性能在過去幾十年中取得了長足的進(jìn)步,但環(huán)境噪聲、非對話內(nèi)容等干擾因素依然是語音控制這類系統(tǒng)在實際應(yīng)用中面臨的一大挑戰(zhàn).引入置信度模型,通過后處理排除識別結(jié)果中的無關(guān)內(nèi)容,是提高系統(tǒng)可靠性的一個有效思路.
在語音識別中,置信度代表某一語音X來自模型W的可信程度.文獻(xiàn)[1]中對置信度予以綜述,其中將置信度估計方法大致分為3 類:1)基于預(yù)測特征的組合,即收集解碼過程中各環(huán)節(jié)的相關(guān)特征并融合為判據(jù);2)基于后驗概率,即使用識別過程中的后驗概率;3)基于似然值比值(似然比):將置信度轉(zhuǎn)換為一個假設(shè)檢驗問題處理,零假設(shè) H0表示語音X來自模型W,對立假設(shè) H1反之.根據(jù)Neyman-Pearson 準(zhǔn)則,對上述假設(shè)的最優(yōu)檢驗為似然比檢驗:
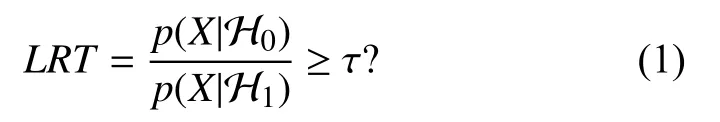
其中,τ為與虛警概率相關(guān)的閾值.
在置信度估計中一般會遇到兩類錯誤:第1 類錯誤(漏報),即實際情況符合零假設(shè) H0時,檢驗結(jié)果拒絕H0;第2 類錯誤(虛警),即實際情況不符合零假設(shè)H0時,檢驗結(jié)果接受 H0.兩類錯誤以及它們衍生出的接收者操作特征(Receiver Operating Characteristic,ROC)曲線、檢測錯誤權(quán)衡(Detection Error Tradeoff,DET)曲線、等錯誤率(Equal Error Rate,EER)等均為評價置信度的統(tǒng)計手段.根據(jù)置信度在語音識別中的應(yīng)用場景,可以在幀搜索階段就融入置信度得分信息,達(dá)到實時剪枝提高識別率的作用,也可以作為后處理方法,對識別結(jié)果的正確性進(jìn)行檢驗.對于后者,在實際應(yīng)用中更關(guān)注根據(jù)置信度進(jìn)行拒識后對系統(tǒng)性能的影響,可以采用拒絕率(Rejection Rate,RR)和拒絕后的識別準(zhǔn)確率(Accuracy after Rejection,AR)來考察置信度在語音命令識別中的作用:

1.2 基線系統(tǒng)
在基于GMM-HMM 的語音識別系統(tǒng)的識別過程中,語音識別器對每次輸出能給出N-best 候選的似然值得分.在基線系統(tǒng)中我們采用首選輸出的似然值得分與次優(yōu)候選的似然值得分之比來作為置信度判斷的依據(jù),對識別結(jié)果進(jìn)行后處理,簡單易行且應(yīng)用廣泛.

其中,p(X|w1) 為首選似然值,p(X|w2)為次優(yōu)候選的似然值,二者均已根據(jù)幀長度做歸一化.似然比LR≥τ則接受w1作為首選識別結(jié)果.
2 基于i-vector 和PLDA 的置信度判決方法
2.1 通用背景模型
傳統(tǒng)的語音識別系統(tǒng)常常是通過訓(xùn)練一個高斯混合模型(Gaussian Mixture Model,GMM),對其語音特征的分布進(jìn)行建模,通過求取并比較測試語音在不同GMM 上的似然值確認(rèn)其相似程度,完成識別.但是實際應(yīng)用中,用于訓(xùn)練特定GMM 的語音往往長度較短或語料較少,導(dǎo)致訓(xùn)練數(shù)據(jù)不足,無法訓(xùn)練出高質(zhì)量的GMM 模型;另一方面也存在大量未標(biāo)注的語料,其中的信息無法被利用.Reynolds 等人提出的通用背景模型(Universal Background Model,UBM)[6]利用所有數(shù)據(jù)訓(xùn)練得到一個混合分量數(shù)較高的GMM 模型,其代表了全局語音特征的分布情況.訓(xùn)練得到UBM 模型之后,通過自適應(yīng)算法適應(yīng)特定語句的數(shù)據(jù),可以得到各語句的GMM 模型,其特征分布隨語句內(nèi)容而不同,可用于識別確認(rèn).
UBM 的訓(xùn)練采用傳統(tǒng)的EM 算法,反復(fù)迭代更新UBM 各分量的權(quán)重wi、均值μi、方差 Σi.在自適應(yīng)階段,對于給定語音數(shù)據(jù)x=x1,x2,···,xt,···,xT,實際應(yīng)用中一般采用最大后驗概率(Maximum A Posteriori,MAP)算法,且只更新UBM 的均值.首先計算數(shù)據(jù)xt與UBM中第i個分量的相似度:

然后計算充分統(tǒng)計量:

最后計算新均值Ei(x),并與原均值μi加權(quán)融合:

其中,αi稱作自適應(yīng)系數(shù),用于控制新舊參數(shù)對UBM的影響.在特征空間中,xt的分布只能覆蓋到UBM 的部分分量,這些分量的Ni較 高,相應(yīng)地 αi也較高,更新的均值傾向于在數(shù)據(jù)x上 訓(xùn)練得到的Ei(x);類似地,未被覆蓋到(數(shù)據(jù)量不足)的分量,其傾向于UBM 中經(jīng)充分背景數(shù)據(jù)訓(xùn)練得到的μi.通過根據(jù)數(shù)據(jù)分布情況有選擇地調(diào)整UBM 參數(shù),能夠獲得與數(shù)據(jù)相匹配且高質(zhì)量的GMM 模型.
2.2 i-vector 模型
前述GMM-UBM 方法得到的特定GMM 模型可以用于常規(guī)的GMM 似然值得分確認(rèn),但考慮到各GMM 的均值足以代表特征的分布情況,因此可以將均值拼接起來,稱為均值超矢量,作為反映變長語音特性的一種定長特征,其同樣包含了說話內(nèi)容等信息.常見的利用此超矢量的方式包括將其送入支持向量機(Support Vector Machine,SVM)等分類器中訓(xùn)練判別[7],或通過聯(lián)合因子分析(Joint Factor Analysis,JFA)[8]對超矢量建模并進(jìn)行分解:

其中,M為語音的超矢量,m一般取UBM 的均值超矢量;V為本征語音(eigenvoice)矩陣,y為語音因子;U為本征信道矩陣,x為信道因子;D為殘差矩陣(對角陣),z為殘差因子.y、x、z均服從標(biāo)準(zhǔn)高斯分布.通過訓(xùn)練V、U、D矩陣,對語音和信道空間分別建模并求解,理論上可以得到僅包含有用信息的因子y作為新的語音特征.
然而在文獻(xiàn)[9]中,Dehak 等人通過實驗發(fā)現(xiàn)上述分離方法較為理想化,在信道因子中同樣存在語音信息,并在文獻(xiàn)[4]中提出了i-vector 模型:

其中,T表示的全局差異空間(total variability space)包含了說話內(nèi)容、信道等各方面的信息,w為全局因子,服從標(biāo)準(zhǔn)高斯分布,又稱為身份矢量(identity vector,ivector).i-vector 模型可以看做JFA 的簡化,不再試圖完全分離無關(guān)信息,而是使用全局差異空間同時予以刻畫.i-vector 主要起對均值超矢量的降維作用,與均值超矢量同樣包含說話內(nèi)容相關(guān)的信息,文獻(xiàn)[10]等已有研究中通過實驗證明其確實對內(nèi)容具有一定的鑒別能力;另一方面,由于均值超矢量代表語句整體的特征分布,未包含語句中音節(jié)內(nèi)容的時間順序信息,因此基于UBM 均值超矢量產(chǎn)生的i-vector 特征類似地具備對語音片段的全局刻畫能力,而對內(nèi)容的時序信息缺乏更精確的描述.
使用EM 算法訓(xùn)練T矩陣[11].對于給定語音數(shù)據(jù)x=x1,x2,···,xt,···,xT,由式(5)中的充分統(tǒng)計量Ni、Fi得到中心化一階統(tǒng)計量:

將x在各分量i上 的統(tǒng)計量拼接為N(x)、(x).
令UBM 的均值超矢量、方差為m、Σ,并隨機初始化矩陣T.E 步驟中,更新隱變量w的后驗分布:

M 步驟中,更新矩陣T:

反復(fù)迭代更新得到矩陣T后,語音x的i-vector 為:

2.3 概率線性判別分析模型
概率線性判別分析(Probabilistic Linear Discriminant Analysis,PLDA)最早由Prince 等在文獻(xiàn)[5]中提出,應(yīng)用于圖像識別中的人臉識別任務(wù).PLDA 的原始形式如下:

其中,wij為第i個人的第j次采樣特征,μ為全局均值,V表示類間差異空間,U表示類內(nèi)差異空間,zij為殘差.μ+Vyi是wij的信號分量(只與i相關(guān)),Uxij+zij是噪聲分量.
與此前常用的線性判別分析(Linear Discriminant Analysis,LDA)[12]相比,PLDA 同樣試圖尋找數(shù)據(jù)的某種低維投影,使得投影后類間差異最大,但PLDA 是一種生成式(generative)模型,考慮了圖像由信號與噪聲兩部分組成并予以顯式建模,噪聲模型更為完備,因而取得了更好的效果.
在原始PLDA 模型的基礎(chǔ)上,由于在語音相關(guān)任務(wù)中無需求解類內(nèi)差異,文獻(xiàn)[13]中引入了簡化的PLDA模型:
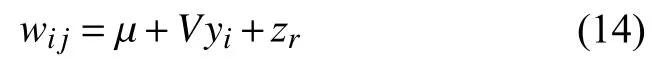
其中,隱變量yi服從標(biāo)準(zhǔn)高斯分布,類內(nèi)差異被合并為zr,其協(xié)方差為Σ.
使用EM 算法訓(xùn)練PLDA 模型,迭代優(yōu)化完全數(shù)據(jù)的對數(shù)似然函數(shù)的期望Q得到最合理的參數(shù)θ={μ,V,Σ}:

隨機初始化矩陣V、Σ.E 步驟中,更新隱變量y的后驗分布只需估計其均值和方差:
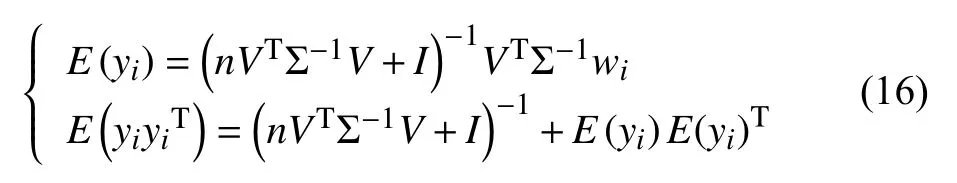
M 步驟中,更新矩陣V、Σ:

其中,N為訓(xùn)練i-vector 總數(shù),n為yi所屬的語句對應(yīng)的i-vector 總數(shù).
測試階段,給定兩條待比對的i-vectorw1、w2,假設(shè) Hs表示二者由相同的因子y生成,Hd表示二者由不同的因子y生成,PLDA 模型通過計算兩種假設(shè)的似然值得分給出w1、w2之間的相似度:

其中,Σtot=VVT+Σ,Σac=VVT.
與1.1 節(jié)中基于似然比的置信度對比可以發(fā)現(xiàn),PLDA 可以比較自然地作為一種置信度計算方法,以語音整體的i-vector 作為輸入,不依賴聲學(xué)模型和語言模型即可完成似然比檢驗.
2.4 孤立字語音識別置信度檢驗實驗
音節(jié)是漢語發(fā)音的基本單元,因此考察i-vector 特征對音節(jié)的置信度的檢測能力,是該方法能否成功應(yīng)用于連接詞識別置信度檢驗的基礎(chǔ).本實驗采用IsoWord孤立字?jǐn)?shù)據(jù)集,其包含了50 名男性、50 名女性、每人1254 個有調(diào)音節(jié),覆蓋了漢語的全部具有實義的音節(jié),采樣率16 kHz.隨機選取1 名男性的語音樣本作為測試集,其余作為訓(xùn)練集.使用1.1 節(jié)中的拒絕率和拒絕后的識別準(zhǔn)確率評價系統(tǒng)的性能.
本文采用45 維MFCC 特征,對輸入的單幀語音信號,去除直流,預(yù)加重(系數(shù)取0.98),加漢明窗(幀長20 ms、幀移10 ms)后,提取14 維Mel 倒譜系數(shù),對相鄰幀計算一階、二階差分系數(shù),并加入三者的歸一化能量系數(shù).
為了確定理想的模型參數(shù),本文首先在識別率有代表性的數(shù)據(jù)樣本上進(jìn)行了調(diào)參實驗,調(diào)整的參數(shù)包括UBM 混合分量數(shù)和i-vector 維度.可以觀察到不同參數(shù)的組合對性能有微小的影響.以第25 號孤立字男聲樣本為例,實驗結(jié)果見表1和表2.
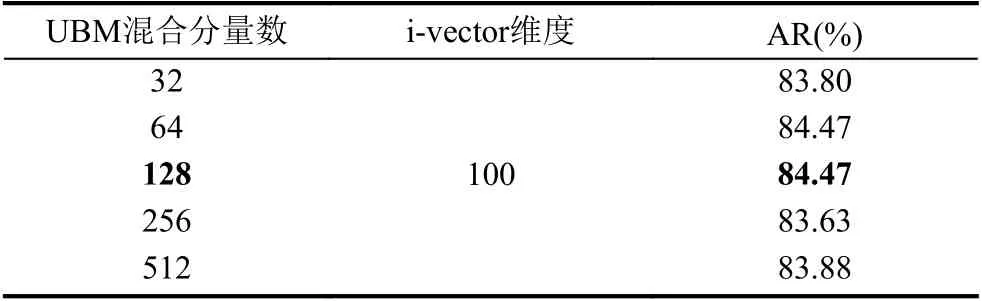
表1 UBM 混合分量數(shù)對性能的影響

表2 i-vector 維度對性能的影響
根據(jù)調(diào)參實驗結(jié)果,本文在孤立字的置信度判決實驗中,UBM 模型混合數(shù)取128,i-vector 維數(shù)取100.
在確定了模型參數(shù)后,在訓(xùn)練階段,首先訓(xùn)練UBM模型,對每條語音計算所需的充分統(tǒng)計量,然后訓(xùn)練ivector 模型的T矩陣.參照文獻(xiàn)[14]中的建議,使用已知的語音對應(yīng)的說話內(nèi)容作為訓(xùn)練標(biāo)簽,對i-vector 預(yù)先做LDA 降維,從而初步補償類間差異.由于文獻(xiàn)[13]中發(fā)現(xiàn)i-vector 具有較強的非高斯性,為使其符合前述基于高斯假設(shè)的PLDA 模型,參照文中建議對i-vector做白化與長度規(guī)整后,再訓(xùn)練PLDA 模型,PLDA 因子維度與LDA 維度相同(不再做進(jìn)一步降維).每條語音的代表i-vector 取該語音所有說話人語音樣本對應(yīng)的i-vector 的均值.測試階段,將測試語音通過訓(xùn)練集上訓(xùn)練好的UBM 模型、T矩陣、LDA 矩陣,得到測試ivector,在PLDA 模型上與每條語音的代表i-vector 逐對計算似然值得分.部分實驗流程使用MSR Identity Toolbox[15]完成.
圖1、圖2為采用基線系統(tǒng)和i-vector+PLDA 對隨機兩組男聲孤立字各1254 個發(fā)音樣本置信度檢測的RR-AR 曲線.可以看出,不論是對于原本識別率較低還是較高的男性語音樣本,i-vector+PLDA 都能通過拒識提高其性能,且效果較基線系統(tǒng)有一定的提升.

圖1 第17 號孤立字男性語音樣本上的RR-AR 曲線

圖2 第50 號孤立字男性語音樣本上的RR-AR 曲線
表3為將RR固定為5%時,各系統(tǒng)在所有男聲樣本上輪流訓(xùn)練測試的平均性能,其中原始無置信度輔助的GMM-HMM 孤立字識別系統(tǒng)的平均識別率是89.81%.可以看出置信度的拒識使系統(tǒng)輸出的正確率絕對提高約2%,且i-vector+PLDA 相比基線系統(tǒng)再絕對提高約0.3%.

表3 置信度輔助的系統(tǒng)在IsoWord 數(shù)據(jù)集上的性能
2.5 連接詞短語置信度檢驗與拒識實驗
連接詞實驗采用的SbPhrase 短語語料數(shù)據(jù)庫包含了699 條四字短語,較為均衡地覆蓋了所有的漢語音節(jié)及音節(jié)間的連接關(guān)系,可以較為客觀地評測命令詞系統(tǒng)的一般性能.該數(shù)據(jù)庫包含了50 名男性、50 名女性的錄音樣本,采樣率16 kHz,每條短語時長約1 s.
置信度檢驗實驗中,以前25 名男性的所有短語語音作為訓(xùn)練集,訓(xùn)練GMM-HMM 系統(tǒng),其余男性語音作為測試集,并使用置信度對識別結(jié)果做后處理.MFCC特征提取與2.4 節(jié)相同,根據(jù)實驗調(diào)整i-vector 提取參數(shù)為512 分量UBM、200 維i-vector.
圖3、圖4為隨機兩個男聲連接詞短語樣本置信度檢測的RR-AR 曲線.
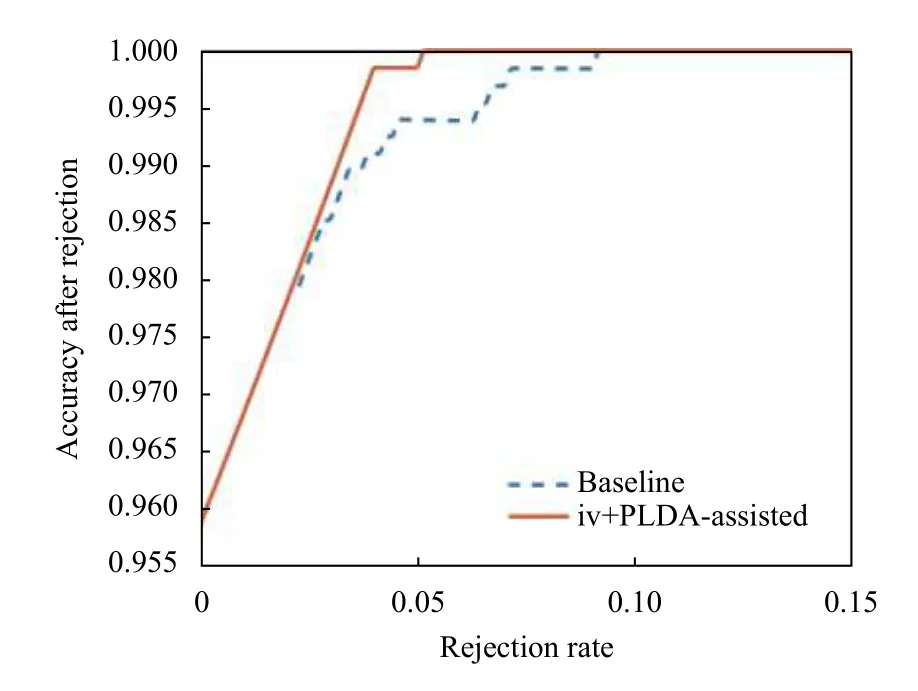
圖3 第30 號男性連接詞語音樣本上的RR-AR 曲線

圖4 第41 男性連接詞語音樣本上的RR-AR 曲線
表4為將RR 固定為5%時,各系統(tǒng)在所有樣本上的平均性能,其中原始GMM-HMM 連接詞識別系統(tǒng)的平均識別率是95.97%.與孤立字類似地,置信度的引入提高了系統(tǒng)的識別性能,而i-vector+PLDA 的效果更佳.

表4 置信度輔助的系統(tǒng)在SbPhrase 數(shù)據(jù)集上的性能
在命令詞識別系統(tǒng)中,對集外詞或噪聲的有效拒識至關(guān)重要,我們通過實驗單獨測試了系統(tǒng)的拒識性能.仍然使用SbPhrase 數(shù)據(jù)庫的男聲部分,取數(shù)據(jù)庫中的前300 條短語作為集內(nèi)詞訓(xùn)練PLDA 模型并確定其閾值,其余作為集外詞進(jìn)行實驗.除此之外,采用從CMU NoiseX-92 數(shù)據(jù)集[16]中截取的噪聲片段考察系統(tǒng)對噪聲的抵抗能力,該數(shù)據(jù)集包含了白噪聲、工廠噪聲、背景說話聲等常見噪聲類型.使用虛警率評價系統(tǒng)的性能.
表5中的結(jié)果表明,i-vector+PLDA 系統(tǒng)性能良好,不論對語音類的集外詞還是非語音類的干擾噪聲都具有較高抗性,保證了系統(tǒng)的穩(wěn)健性.

表5 i-vector+PLDA 系統(tǒng)的集外詞、噪聲拒識性能
3 融合DTW 的置信度判決方法
3.1 i-vector 時序鑒別能力分析
在2.1 節(jié)中已經(jīng)指出,GMM-UBM 模型通過自適應(yīng)得到每條語音對應(yīng)的GMM 模型,這種建模方式的一個缺陷是不包含時序信息:對于僅字序、詞序不同的語音,由于使用了相同或相近的音素,全局上看,各自的特征集內(nèi)其特征分布彼此相似,因而在這類系統(tǒng)上會體現(xiàn)為相似度較高.換言之,雖然i-vector 的全局描述能力較好,但缺乏對其中時序信息的描述,理論上,若單獨使用i-vector 特征,對于較長的命令詞導(dǎo)致鑒別力下降的可能性會增大.在實際應(yīng)用中,這會導(dǎo)致部分與命令詞在字序、詞序上相似的集外詞無法被系統(tǒng)有效拒識,引發(fā)不必要的虛警.
有鑒于i-vector 的上述特點,一種解決方法是利用命令詞識別系統(tǒng)在識別時給出的最佳音節(jié)分割點,對組成命令詞的每個音節(jié)或是單詞分別進(jìn)行確認(rèn),如在漢語系統(tǒng)中可以檢驗組成命令詞的單字,此時系統(tǒng)對這些單元的分辨能力則至關(guān)重要,這點在2.4 節(jié)中已經(jīng)予以驗證.然而,此種實現(xiàn)依賴于上游的分割結(jié)果,為系統(tǒng)帶來了新的困難.除此之外,另一種思路則是嘗試增強系統(tǒng)本身的時序鑒別能力.
例如,在i-vector 框架下,一般通過隱馬爾科夫模型(Hidden Markov Model,HMM)、長短期記憶網(wǎng)絡(luò)(Long Short-term Memory,LSTM)等時序相關(guān)的模型建模時序特征,產(chǎn)生新的i-vector 或作為已有i-vector的補充.文獻(xiàn)[10]對比了i-vector、d-vector、s-vector三種特征對不同語音特性(如說話人身份、說話速度等)的刻畫能力.其中對于詞序特性,該文通過在兩段拼接順序不同的語音上的分類任務(wù)予以驗證,在此實驗中i-vector 的鑒別效果較差,接近隨機猜測,說明其幾乎沒有時序鑒別能力,而基于LSTM 的s-vector 效果突出,因此該文通過拼接二者得到所謂i-s-vector,在包括詞序區(qū)分的大部分任務(wù)上均取得了最優(yōu)結(jié)果.Hossein 等[17]則提出使用HMM 代替GMM 作為UBM模型的基礎(chǔ),通過對每個音素訓(xùn)練HMM 并拼接,得到特定語句的HMM模型,由此模型產(chǎn)生的i-vector 與語句的相關(guān)性更強.
上述方法通過引入其它時序相關(guān)的模型增強ivector 的時序鑒別性能,其共同局限性在于需要與語句相關(guān)的信息,如每段語句的音素標(biāo)簽,用于訓(xùn)練對應(yīng)的HMM 或神經(jīng)網(wǎng)絡(luò)模型,而實際應(yīng)用中我們希望在僅具備錄入語音,沒有關(guān)于語音內(nèi)容知識的情況下,完成系統(tǒng)的訓(xùn)練.動態(tài)時間規(guī)整(Dynamic Time Warping,DTW)算法[18]是語音領(lǐng)域的經(jīng)典方法之一,其通過對語音序列進(jìn)行非線性扭曲實現(xiàn)序列間對齊,從而求取相似度,算法直觀且易于實現(xiàn),其約束條件決定其適于衡量時序差異,且不依賴語音以外的信息.因此,本文提出將DTW 與原有i-vector+PLDA 系統(tǒng)融合,期望二者融合而成的系統(tǒng)可以兼顧i-vector+PLDA 的低錯誤率和DTW 的時序鑒別能力.
3.2 得分計算、似然比校準(zhǔn)與系統(tǒng)融合
DTW 算法產(chǎn)生兩段序列之間的相似度得分,而在很多命令詞系統(tǒng)中,單個詞語對應(yīng)存在多個模板(訓(xùn)練語音片段).本文中將目標(biāo)語音在某詞語下所有模板上的DTW 得分的平均值作為該語音與此詞語的相似度.
盡管上述得分與對數(shù)似然比同為相似度的體現(xiàn),但由于計算方式、統(tǒng)計特性上的差異,數(shù)學(xué)上二者并不相容.本文采用文獻(xiàn)[19]中的邏輯回歸校準(zhǔn)方法,通過在同源、不同源得分上訓(xùn)練二元邏輯回歸模型得到模型系數(shù),并校準(zhǔn)原始得分s,使其等價于對數(shù)似然比:

系統(tǒng)融合采用兩系統(tǒng)似然比的連乘,即對數(shù)似然比的簡單相加:

3.3 逆序短語拒識實驗
第2.5 節(jié)實驗中使用的SbPhrase 數(shù)據(jù)集不含有實驗所需的音素相近但字序不同的短語對,因此為SbPhrase 中前50 條短語重新采集語音,構(gòu)建小型子數(shù)據(jù)集SbPhrase-T.對于每條短語,除其正序(如“曼徹斯特”)外,另行采集部分逆序(如“斯特曼徹”) 和完全逆序(如“特斯徹曼”)兩份語音.將SbPhrase 中前50 條短語作為集內(nèi)詞訓(xùn)練i-vector+PLDA 系統(tǒng),將兩種逆序語音作為集外詞進(jìn)行拒識實驗.
圖5為短語的3 種字序在原系統(tǒng)上對數(shù)似然比得分的混淆矩陣(confusion matrix),展示了所有語音在所有正序短語的PLDA 模型上的相似度情況.其中,為方便橫向比較,橫軸每3 列對應(yīng)一條短語,其下三列依次對應(yīng)正序、部分逆序、完全逆序語音的得分.觀察對角線可以發(fā)現(xiàn),兩種逆序語音在其對應(yīng)序號正序模型上的得分總體較高,說明系統(tǒng)不能將其有效拒識,再次確認(rèn)了前述i-vector 在時序鑒別能力方面的弱點.

圖5 原系統(tǒng)的混淆矩陣(部分)
圖6為DTW 與i-vector+PLDA 系統(tǒng)融合后,新系統(tǒng)上得分的混淆矩陣,經(jīng)DTW 修正后,混淆矩陣的對角線更加清晰,兩種逆序語音的得分明顯降低,接近背景(短語不匹配情況)水平.
表6為兩種系統(tǒng)對逆序語音拒識的量化實驗結(jié)果.數(shù)據(jù)表明,相比單i-vector+PLDA 系統(tǒng),融合系統(tǒng)有效降低了系統(tǒng)在逆序語音上的虛警,說明DTW 得分的引入提高了系統(tǒng)的時序鑒別能力.
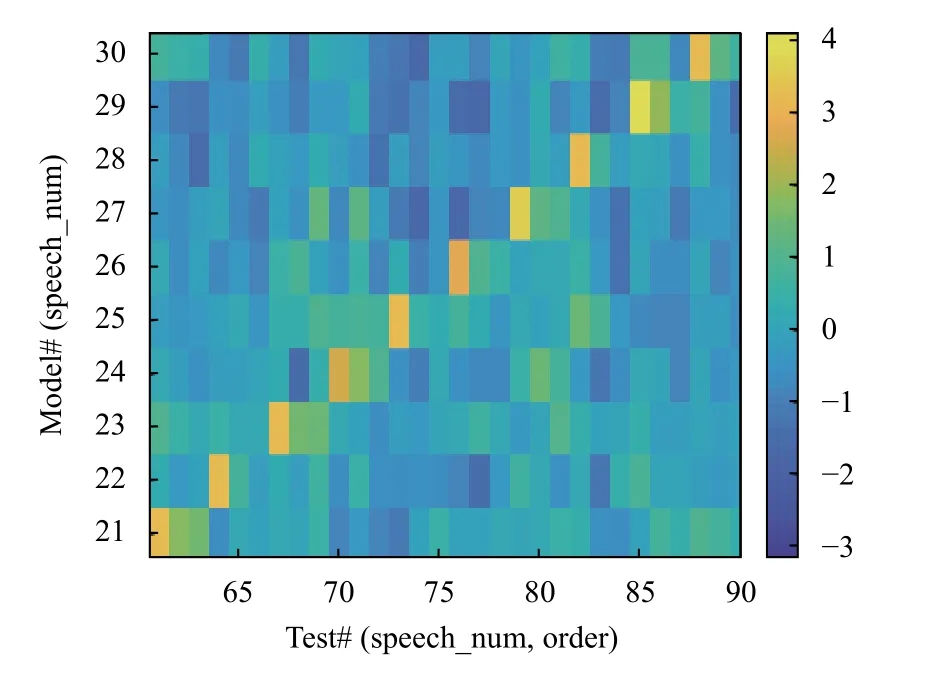
圖6 新系統(tǒng)的混淆矩陣(部分)

表6 不同系統(tǒng)在SbPhrase-T 數(shù)據(jù)集上的拒識性能
4 i-vector+PLDA 置信度應(yīng)用意義分析
相比傳統(tǒng)的置信度估計方法,上文提出的基于ivector 和PLDA 以及融合DTW 的方法具有兩點優(yōu)勢:
其一,無需訓(xùn)練聲學(xué)模型及語言模型.傳統(tǒng)方法,特別是基于后驗概率的置信度判決方法,依賴基本語音識別單元(如音素或音節(jié))聲學(xué)模型的似然值得分和相應(yīng)的聲學(xué)模型.這些信息常常與特定系統(tǒng)及其使用的聲學(xué)模型、語言模型相關(guān),遷移至傳統(tǒng)語音識別系統(tǒng)的諸多變種以及未來更新穎的語音識別框架中存在困難.本文方法訓(xùn)練過程則僅需語音及對應(yīng)的類別標(biāo)簽,外部系統(tǒng)不額外提供其他先驗的聲學(xué)和語言模型信息,一方面使得系統(tǒng)結(jié)構(gòu)直觀、易于實現(xiàn),另一方面因為無需考慮前端系統(tǒng)的實現(xiàn)細(xì)節(jié),可以獨立測試與部署,達(dá)成一定程度的模塊化,使用更加靈活廣泛.
其二,無需提供語句內(nèi)容相關(guān)信息.實際應(yīng)用中,很多命令詞系統(tǒng)通過非確定性的命令詞加強安全性或保證用戶體驗.例如,用戶可以根據(jù)個人喜好為智能音箱、手環(huán)等智能設(shè)備錄入自選的喚醒詞,后續(xù)通過該詞喚醒設(shè)備進(jìn)入工作狀態(tài).此類場景中,設(shè)備在錄入階段無法獲知命令詞的內(nèi)容,因此文獻(xiàn)[10,17]中的方法缺乏訓(xùn)練所需的標(biāo)簽.本文方法通過DTW 完成時序信息的補充,避免了對此類“標(biāo)簽”的依賴,可以應(yīng)對較為復(fù)雜多變的命令詞.在電話銀行、智能家居等應(yīng)用中,通過本文方法對語音識別系統(tǒng)的結(jié)果進(jìn)行驗證,既有助于降低錯誤,提升用戶體驗,同時仍不失原系統(tǒng)交互過程中的靈活性,對命令詞系統(tǒng)的改進(jìn)具有實際價值.
此外,第2 節(jié)的置信度檢驗實驗結(jié)果中,本文方法輔助語音識別系統(tǒng)對連接詞識別率的提升相比孤立字更為顯著.越長的語音片段,其中包含的語音內(nèi)容信息越豐富,通過相應(yīng)增加UBM 混合數(shù)和i-vector 維度,得到的i-vector 能夠充分包含此信息,而特征信息量的增加也有益于PLDA 對有用信息的分離與鑒別.因此,相比孤立字,本文方法更適合用于詞語、短句等較長的語音.
5 結(jié)束語
本文提出將i-vector 以及PLDA 模型用于置信度判決.i-vector 語音特征包含了包括說話內(nèi)容在內(nèi)的各種差異信息,利用PLDA 可以中和其他信息的影響,有效鑒別說話內(nèi)容,且其形式上符合基于似然比的置信度分析,在孤立字、連接詞實驗中體現(xiàn)出了良好潛力.通過與DTW 融合,補充缺失的時序信息,得到不依賴聲學(xué)、語言模型以及語句標(biāo)簽的置信度分析方法,在應(yīng)用中較傳統(tǒng)的置信度分析方法有其獨特優(yōu)勢.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業(yè)設(shè)計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
