基于卷積神經(jīng)網(wǎng)絡(luò)的短文本情感分類(lèi)①
2021-01-22 05:43:22樊粵湘
計(jì)算機(jī)系統(tǒng)應(yīng)用 2021年1期
代 麗,樊粵湘,陳 思
(浙江理工大學(xué) 經(jīng)濟(jì)管理學(xué)院,杭州 310018)
隨著Web2.0 和移動(dòng)設(shè)備通訊地不斷發(fā)展,越來(lái)越多的人喜歡在微博、購(gòu)物網(wǎng)站等社交平臺(tái)上參與互動(dòng)與交流,互聯(lián)網(wǎng)上的文本信息也因此呈現(xiàn)出迅猛增長(zhǎng)的趨勢(shì).大量文本信息通常體現(xiàn)了個(gè)人的觀點(diǎn)和情感的表達(dá),若能夠利用分析技術(shù)準(zhǔn)確挖掘出其中所包含的信息價(jià)值并充分利用,無(wú)論是對(duì)國(guó)家在輿情控制方面還是對(duì)企業(yè)在決策制定方面都有著巨大的作用.因此,在當(dāng)前充斥著海量文本數(shù)據(jù)的網(wǎng)絡(luò)環(huán)境下,文本情感分析是一項(xiàng)十分重要的工作.
面對(duì)文本情感分析問(wèn)題,很多學(xué)者都提出了十分有效的方法.根據(jù)研究的思路不同,主要可以分為基于情感詞典的方法和基于機(jī)器學(xué)習(xí)的方法[1,2].基于情感詞典的方法需要構(gòu)造一個(gè)較為完善的詞典對(duì)文本特征詞進(jìn)行情感色彩地判斷,比較適合應(yīng)用于傳統(tǒng)的規(guī)范性文本,而對(duì)于網(wǎng)絡(luò)上的頻現(xiàn)新詞和縮略詞的短文本分析效果則不夠理想,需要耗費(fèi)大量的人力、時(shí)間以及財(cái)力等諸多成本去更新、維護(hù)詞典;而基于機(jī)器學(xué)習(xí)的方法則需要人工構(gòu)造特征,無(wú)法得到文本包含的句法和語(yǔ)義信息,是一種較為淺層的研究方法,無(wú)法學(xué)習(xí)復(fù)雜的函數(shù),泛化能力較弱[3,4].隨著互聯(lián)網(wǎng)中的海量文本信息和語(yǔ)言多樣化的表達(dá)的變化,以上這兩種方法已經(jīng)難以有效地解決企業(yè)決策的需求了.在2006年Hinton 等人提出了深度學(xué)習(xí)方法經(jīng)過(guò)改進(jìn)以后能夠較好地彌補(bǔ)上述方法的缺陷,它是一種端到端的技術(shù),無(wú)需人工參與便能夠以大腦處理信號(hào)的機(jī)制自發(fā)的從原始數(shù)據(jù)中學(xué)習(xí)到特征信息,從而從更高層面上對(duì)文本進(jìn)行抽象表達(dá)[5].深度學(xué)習(xí)還被廣泛地運(yùn)用到中文分詞[6]、機(jī)器翻譯[7]等NLP 領(lǐng)域中.Kim 首次運(yùn)用深度學(xué)習(xí)中的卷積神經(jīng)網(wǎng)絡(luò)模型(Convolutional Neural Network,CNN)實(shí)現(xiàn)了英文文本的情感分類(lèi),實(shí)驗(yàn)的最終效果要明顯優(yōu)于傳統(tǒng)的機(jī)器學(xué)習(xí)算法[8].文獻(xiàn)[9]在普通CNN基礎(chǔ)上提出了動(dòng)態(tài)池化,構(gòu)建了DCNN 模型來(lái)學(xué)習(xí)句子結(jié)構(gòu)以?xún)?yōu)化情感分類(lèi)器的性能.文獻(xiàn)[10]在CNN 模型中引入注意力機(jī)制(Attention Mechanism)構(gòu)建WACNN模型,在MR5K 和CR 數(shù)據(jù)集上證明了此方法可提高模型的情感分類(lèi)準(zhǔn)確率.文獻(xiàn)[11]將CNN 模型同長(zhǎng)短期記憶神經(jīng)網(wǎng)絡(luò)模型(LSTM)進(jìn)行結(jié)合,采用了聯(lián)合深度學(xué)習(xí)方法對(duì)影視評(píng)論進(jìn)行情感分類(lèi),此方法對(duì)訓(xùn)練語(yǔ)料存在著極大的依賴(lài)性.文獻(xiàn)[12]研究了不同表達(dá)方式的文本對(duì)CNN 模型情感分類(lèi)性能的影響.
基于以上分析發(fā)現(xiàn),很多學(xué)者在基于CNN 模型進(jìn)行改進(jìn)后對(duì)文本進(jìn)行情感分類(lèi)研究時(shí)只考慮了特征詞語(yǔ)語(yǔ)義信息對(duì)文本情感分類(lèi)的作用,而忽略了詞語(yǔ)本身所具備的與情感信息緊密相關(guān)的特征影響,如詞語(yǔ)本身的情感色彩、詞性等.此外,對(duì)于中文文本數(shù)據(jù)的研究都需要經(jīng)過(guò)分詞操作,不同于英文文本中各詞語(yǔ)以空格形式隔開(kāi),中文文本中各詞語(yǔ)是連接在一起的,這就導(dǎo)致對(duì)中文文本分詞時(shí)存在著分詞錯(cuò)誤的問(wèn)題,從而進(jìn)一步影響詞向量的訓(xùn)練質(zhì)量.因此,本文將在經(jīng)典CNN模型的基礎(chǔ)上,提出了一種融合情感特征的雙通道卷積神經(jīng)網(wǎng)絡(luò)模型SFD-CNN (Double channel Convolutional Neural Network model fused with Sentiment Feature),在設(shè)置實(shí)驗(yàn)文本數(shù)據(jù)的向量化的同時(shí)考慮了文本特征詞本身的情感信息和分詞錯(cuò)分的影響,從而獲取更多的情感信息,以期在情感分類(lèi)任務(wù)中達(dá)到更好的分析效果.
1 詞向量模型
在使用相關(guān)算法對(duì)文本數(shù)據(jù)進(jìn)行情感分類(lèi)時(shí)需要先把文本轉(zhuǎn)換成數(shù)值型使其能被工具識(shí)別.在進(jìn)行文本數(shù)值化表示時(shí)應(yīng)當(dāng)滿(mǎn)足以下要求:該表示方法既可以很好地表示文本語(yǔ)義內(nèi)容又可以將各文本內(nèi)容區(qū)別開(kāi)來(lái).目前,常用的文本表示模型有布爾模型、向量空間模型(Vector Space Model,VSM)以及詞向量模型等[13].布爾模型較為簡(jiǎn)單,也容易讓人理解,但是其只關(guān)注某項(xiàng)特征是否在文本中出現(xiàn)過(guò),而忽視了其與上下文詞語(yǔ)之間的相關(guān)性;向量空間模型在一定程度上表達(dá)了特征詞項(xiàng)間的語(yǔ)義信息,但其維度大小同文本特征集個(gè)數(shù)線(xiàn)性相關(guān)很容易造成維度災(zāi)難.Hinton 提出的Word Embedding (詞向量)方法正好彌補(bǔ)了上述方法的不足.
詞向量主要思想就是將詞語(yǔ)從高維稀疏的空間中映射至低維空間,并在這一過(guò)程中充分考慮詞語(yǔ)的語(yǔ)義信息,非常適合用來(lái)表示文本的抽象特征[14].2013年,Google 工程師Mikolov 等人將詞向量訓(xùn)練工具Word2Vec進(jìn)行了開(kāi)源,由此詞向量逐漸為人們熟知.Word2Vec中主要包含了兩種訓(xùn)練詞向量的模型:CBOW 模型與Skip-Gram 模型,這兩種模型都是基于Bengio 的3 層神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型NNML 而提出的.相比于NNML,Word2Vec 對(duì)詞向量的訓(xùn)練結(jié)果進(jìn)行了一定的優(yōu)化,同時(shí)還通過(guò)采用Negative Sampling 或Hierarchical Softmax等方法使得模型的計(jì)算復(fù)雜度在一定程度上得以降低[15].CBOW 模型與Skip-Gram 模型都是由3 層結(jié)構(gòu)構(gòu)成:輸入層、映射層和輸出層,其模型結(jié)構(gòu)如圖1所示.

圖1 CBOW 和Skip-Gram 模型
從圖1可以看出,CBOW 模型是以輸入某一詞語(yǔ)的上下文詞向量來(lái)計(jì)算詞向量的.而Skip-Gram 模型的思想則與CBOW 模型相反,其是通過(guò)輸入某一詞語(yǔ)向量來(lái)計(jì)算出其上下文詞語(yǔ)的詞向量.但它們總體上的思想相同,即上下文相似,其目標(biāo)詞匯也會(huì)相似[16].
2 融合情感特征的雙通道卷積神經(jīng)網(wǎng)絡(luò)情感分類(lèi)模型
綜合考慮現(xiàn)有的情感分類(lèi)研究常常忽略特征詞本身所攜帶情感信息和中文分詞總存在著被錯(cuò)分兩方面問(wèn)題,本文對(duì)經(jīng)典CNN 模型加以改進(jìn),構(gòu)造了一個(gè)融合情感特征的雙通道卷積神經(jīng)網(wǎng)絡(luò)情感分類(lèi)模型,以期在情感分類(lèi)任務(wù)中達(dá)到更好的效果.具體的改進(jìn)措施如下:首先在預(yù)先訓(xùn)練好的語(yǔ)義詞向量上加入該特征詞語(yǔ)自身所攜帶的情感信息特征,使得融合后的特征詞向量更能準(zhǔn)確表達(dá)其所含有的情感信息;然后在原有的CNN 模型基礎(chǔ)上構(gòu)造出另一條輸入通道,并把相應(yīng)的以中文文本中最小單位字為基礎(chǔ)訓(xùn)練出來(lái)的字向量為輸入源,以使模型能夠在解決分詞錯(cuò)誤問(wèn)題的同時(shí)又能進(jìn)一步地從不同方面提取到更多的有用信息特征.
2.1 融合情感特征的詞向量
以詞向量表示的文本所包含的原始文本信息是CNN模型進(jìn)行情感分類(lèi)的基礎(chǔ),為了進(jìn)一步豐富詞向量所攜帶的文本情感信息,本文將在詞語(yǔ)的語(yǔ)義向量 上引入會(huì)對(duì)文本情感類(lèi)別判定產(chǎn)生一定影響的諸如詞語(yǔ)的情感極性、詞性等相關(guān)情感特征,形成融合情感特征(sentiment feature)的詞向量.對(duì)于額外的情感特征信息本文將使用一個(gè) 維的向量 來(lái)表示,各維度分別代表著某一情感特征屬性,而且只有0、1 兩個(gè)取值,0 表示該詞語(yǔ)沒(méi)有該維度相對(duì)應(yīng)的特征,1 代表的含義則與0 相反.其中,各情感特征設(shè)計(jì)方法如下.
1)詞語(yǔ)情感極性特征.詞語(yǔ)情感極性特征是針對(duì)那些本身就能夠表達(dá)某些情感的詞匯.因?yàn)樵~匯所攜帶的情感信息在一定程度上會(huì)影響句子的情感傾向性.對(duì)于詞語(yǔ)這一情感特征的提取,本文主要是依據(jù)情感詞典.而情感詞典的形成主要是以現(xiàn)有情感詞典資源為基礎(chǔ),然后向其中加入一些未包含在內(nèi)而在網(wǎng)絡(luò)中進(jìn)行商品評(píng)論時(shí)又常用的情感詞語(yǔ),具體形成過(guò)程如圖2所示.
2)詞語(yǔ)詞性特征.在無(wú)監(jiān)督的情感識(shí)別或抽取的任務(wù)中,許多學(xué)者通常都是以形容詞、動(dòng)詞、副詞、名詞及其相應(yīng)的短語(yǔ)作為特征來(lái)展開(kāi)研究的.涂海麗也指出上述詞性的詞語(yǔ)在對(duì)中文文本進(jìn)行情感分析時(shí)發(fā)揮著十分重要的作用[17].所以本文也將以上談及的詞性納入詞語(yǔ)的情感信息特征當(dāng)中,并借助jieba 分詞中的詞性標(biāo)注功能對(duì)實(shí)驗(yàn)文本數(shù)據(jù)在進(jìn)行分詞的同時(shí)也進(jìn)行詞性的標(biāo)注,然后在構(gòu)造情感特征向量時(shí)對(duì)詞語(yǔ)的這些特征進(jìn)行數(shù)值化表示.
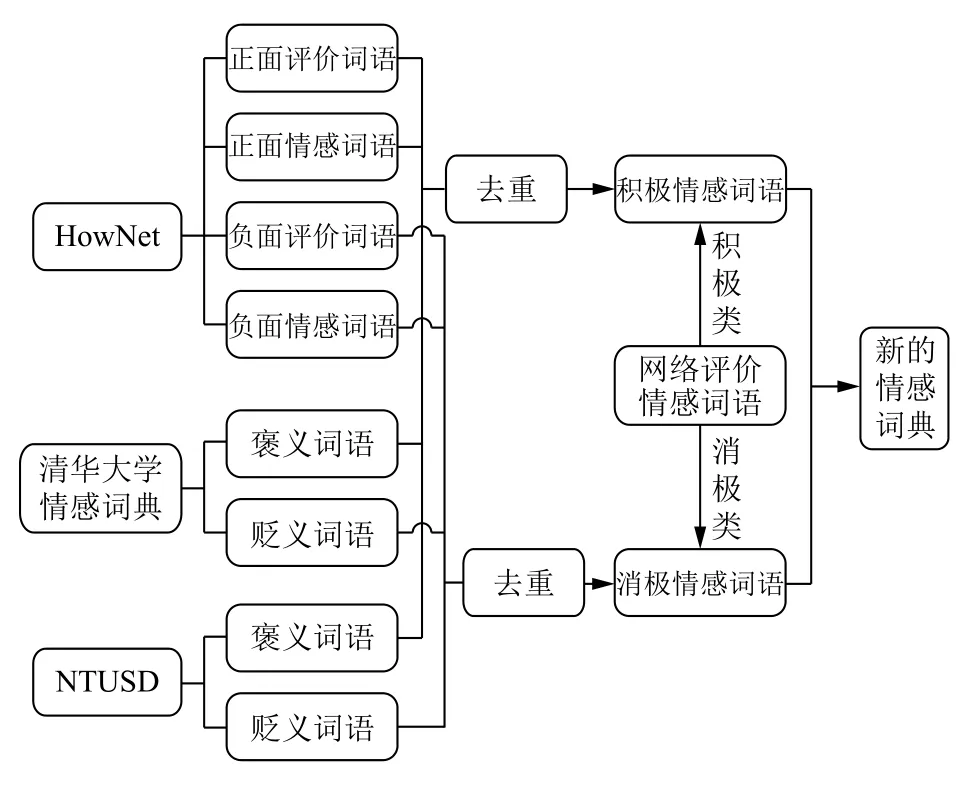
圖2 新情感詞典形成過(guò)程
3)否定詞特征.否定詞語(yǔ)在情感分析任務(wù)中發(fā)揮著十分重要的作用,它的使用甚至能使文本情感傾向發(fā)生徹底轉(zhuǎn)變.對(duì)于否定詞的判別,本文將借助HowNet情感詞典中的否定詞表.
4)轉(zhuǎn)折詞特征.包含有轉(zhuǎn)折詞的評(píng)論文本語(yǔ)句通常表達(dá)的情感信息都是不單一的.轉(zhuǎn)折詞將文本分成了前后兩個(gè)部分,它們所要表達(dá)的含義往往是相對(duì)或者相反的,而且后部分分句一般才是表達(dá)者的重心.邸鵬等也通過(guò)實(shí)驗(yàn)證明了對(duì)轉(zhuǎn)折句式的考慮提高了基于NB 算法的情感分類(lèi)器的精度[18].因此本文將轉(zhuǎn)折詞也作為詞語(yǔ)的情感屬性特征,并結(jié)合文本語(yǔ)料整理出常用的轉(zhuǎn)折詞表.
經(jīng)過(guò)前文內(nèi)容的分析,代表特征詞項(xiàng) 額外的情感特征信息向量可以簡(jiǎn)單地被表示成一個(gè)8 維的向量:[積極情感詞,消極情感詞,形容詞,副詞,動(dòng)詞,否定詞,轉(zhuǎn)折詞,名詞],而各維度下的具體取值則分別代表著該特征詞項(xiàng)x是否擁有此情感屬性:取值為1 說(shuō)明其本身具備有此屬性,取值為0 則相應(yīng)地表示其不含有此屬性.詞語(yǔ)情感特征向量xsen的示例如圖3所示.

圖3 詞語(yǔ)情感特征向量示例圖
得到詞語(yǔ)的情感特征向量后,便需要將其與相應(yīng)的詞語(yǔ)語(yǔ)義向量進(jìn)行融合.本文采取前后串接操作將兩者融合,得到拓展后的詞向量xexpand.具體的表達(dá)式如式(1)所示.

其中,x可通過(guò)詞向量模型訓(xùn)練文本語(yǔ)料庫(kù)后獲得.
2.2 字向量
對(duì)于字向量xunigram的獲取,同樣采用詞向量模型對(duì)分詞后的評(píng)論文本數(shù)據(jù)進(jìn)行訓(xùn)練,不同的是此處的分詞操作不是將評(píng)論文本劃分為由若干詞語(yǔ)構(gòu)成的序列,而是將它們劃分成了由一個(gè)個(gè)單獨(dú)的漢字構(gòu)成的序列.經(jīng)模型訓(xùn)練后便可得到這些單字詞匯相對(duì)應(yīng)的字向量,其中字向量的維度大小與相對(duì)應(yīng)文本的詞向量維度保持一致.
2.3 模型結(jié)構(gòu)
在前面兩小節(jié)的介紹下,本文基于卷積神經(jīng)網(wǎng)絡(luò)算法所設(shè)計(jì)的情感分類(lèi)模型結(jié)構(gòu)如圖4所示.模型由輸入層、卷積層、池化層以及輸出層構(gòu)成.

圖4 SFD-CNN 模型結(jié)構(gòu)
1)輸入層:此層的作用主要是將評(píng)論文本數(shù)據(jù)用Word2Vec 訓(xùn)練出來(lái)的向量數(shù)值化,在本文所提出模型中主要表現(xiàn)為將評(píng)論文本分別轉(zhuǎn)換成融合情感特征的詞向量矩陣xexpand和字向量矩陣xunigram,并把它們分別作為模型兩個(gè)通道的輸入.在此次研究中,由于評(píng)論文本集經(jīng)過(guò)預(yù)處理后最大的文本詞序列長(zhǎng)度為215,轉(zhuǎn)換為單個(gè)字序列的最大長(zhǎng)度為446,因此設(shè)置n=215,N=446,v的具體取值則依據(jù)文本向量化后的維度而定.若假設(shè)文本向量化后的維度取值為100,則設(shè)置v=100.對(duì)于文本長(zhǎng)度低于設(shè)定數(shù)值的其他文本序列,本文將進(jìn)行后向補(bǔ)零操作,使其等于規(guī)定的長(zhǎng)度.
2)卷積層:卷積層的作用就是通過(guò)對(duì)輸入的文本矩陣進(jìn)行卷積運(yùn)算獲取能夠代表文本信息的特征,降低向量的維度.在經(jīng)典的CNN 結(jié)構(gòu)中,該層一般只含有一種類(lèi)型的卷積核,由于本文研究的是文本數(shù)據(jù),前后的特征詞語(yǔ)都存在著一定的聯(lián)系,為了能夠同時(shí)獲取不同粒度下文本所表現(xiàn)的特征,本文將在模型各通道下的文本矩陣上使用窗口大小不同的卷積核組合.如在圖4所示的模型中采用的是窗口大小分別為3、4、5 的卷積核組合對(duì)評(píng)論文本進(jìn)行卷積操作.
3)池化層:池化層是以卷積層輸出的特征圖為輸入的,本文在該層分別對(duì)兩個(gè)通道下的特征圖進(jìn)行最大池化處理,得到更低維度的文本特征,然后將兩個(gè)通道下池化后的文本特征進(jìn)行拼接形成最能代表文本的最終特征向量.
4)輸出層:輸出層的功能則是根據(jù)池化層輸出的最終特征向量對(duì)文本進(jìn)行情感類(lèi)別的劃分,本文在此層主要是將池化層后得到的特征圖以全連接的形式進(jìn)行連接然后輸入到Softmax 分類(lèi)器中,將文本分別劃分為積極情感和消極情感兩種類(lèi)別.
此模型分類(lèi)結(jié)構(gòu)在預(yù)先訓(xùn)練好的語(yǔ)義詞向量中融入了情感信息特征,從特征詞本身所攜帶的情感信息和正確識(shí)別中文分詞方面出發(fā)進(jìn)行了改進(jìn)和綜合分析,即在原有的CNN 模型基礎(chǔ)上構(gòu)造了另一條輸入通道,并把相應(yīng)的以中文文本中最小單位字為基礎(chǔ)訓(xùn)練出來(lái)的字向量為輸入源,以使模型能夠在解決分詞錯(cuò)誤問(wèn)題的同時(shí)又能進(jìn)一步地從不同方面提取到更多的有用信息特征,從而得到了在情感分類(lèi)任務(wù)中更好的預(yù)期效果.
3 實(shí)驗(yàn)及分析
3.1 實(shí)驗(yàn)環(huán)境
本文在進(jìn)行情感分類(lèi)實(shí)驗(yàn)時(shí)的環(huán)境主要如下:操作系統(tǒng)是64 位的Windows 10 家庭中文版,CPU 為Intel core i5-8250U,RAM 為8 GB,使用的編程語(yǔ)言為Python3.6,主要涉及到的類(lèi)庫(kù)有Tensorflow、sklearn、numpy 等,開(kāi)發(fā)工具為Pycharm.
3.2 實(shí)驗(yàn)數(shù)據(jù)
在本文此次研究中,所使用到的數(shù)據(jù)可分成兩部分:一部分是用來(lái)訓(xùn)練和測(cè)試情感分類(lèi)器模型的評(píng)論文本數(shù)據(jù),并且?guī)в星楦猩蕵?biāo)注.另一部分則是用來(lái)訓(xùn)練詞語(yǔ)語(yǔ)義向量的大規(guī)模無(wú)標(biāo)記的Wiki 中文數(shù)據(jù)集.其中,評(píng)論文本數(shù)據(jù)是通過(guò)Python 語(yǔ)言編寫(xiě)相應(yīng)爬蟲(chóng)程序從京東商城的官網(wǎng)上獲取的,主要包括了手機(jī)、筆記本電腦、水果、書(shū)籍、服裝、洗發(fā)水6 個(gè)領(lǐng)域的評(píng)論文本,共有12 000 條,并且各領(lǐng)域下積極評(píng)論和消極評(píng)論都為1000 條;而Wiki 中文數(shù)據(jù)集是從Wiki官網(wǎng)上下載的中文壓縮包,大小為1.64 GB.文獻(xiàn)[19]指出使用大規(guī)模的文本語(yǔ)料集訓(xùn)練出來(lái)的詞向量較符合中文語(yǔ)言模型;文獻(xiàn)[20]也表明通過(guò)此種方法訓(xùn)練出來(lái)的詞向量可以使模型的性能得到有效改善.因此,本文將使用Word2Vec 工具中的Skip-Gram 模型訓(xùn)練Wiki 中文數(shù)據(jù)集以獲得高質(zhì)量的詞向量,然后以此對(duì)評(píng)論文本中的特征詞項(xiàng)初始化.
經(jīng)過(guò)對(duì)語(yǔ)料庫(kù)的訓(xùn)練后,便可以得到相應(yīng)維度下的詞語(yǔ)特征語(yǔ)義向量,各詞向量間在語(yǔ)義上具有一定的關(guān)聯(lián)性.如在維度為100 的情況下,根據(jù)訓(xùn)練后的詞向量模型,可獲取到詞語(yǔ)“購(gòu)買(mǎi)”的語(yǔ)義相似詞列表和對(duì)應(yīng)的相似度,具體如表1所示,該詞語(yǔ)的向量表達(dá)如圖5所示.接下來(lái),則在語(yǔ)義向量的基礎(chǔ)上根據(jù)2.1 小節(jié)介紹的方法構(gòu)造融合情感特征的詞向量,同時(shí)根據(jù)2.2 小節(jié)的介紹使用Skip-Gram 模型訓(xùn)練評(píng)論文本的字向量.
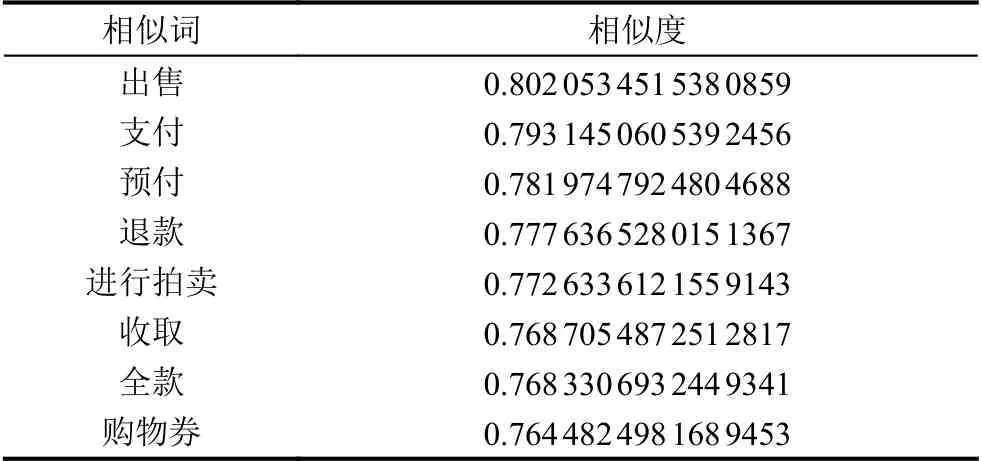
表1 “購(gòu)買(mǎi)”語(yǔ)義相似詞列表
圖5 “購(gòu)買(mǎi)”詞向量表達(dá)式
3.3 實(shí)驗(yàn)參數(shù)
實(shí)驗(yàn)時(shí)對(duì)模型中各個(gè)參數(shù)值的設(shè)定直接影響著實(shí)驗(yàn)結(jié)果,為了使模型達(dá)到較好的性能,就需要對(duì)模型中的各個(gè)參數(shù)進(jìn)行不斷地調(diào)整與優(yōu)化.表2展示了本文在進(jìn)行調(diào)優(yōu)時(shí)的各參數(shù)取值范圍和最終的取值.其中,參數(shù)取值范圍表示在研究卷積神經(jīng)網(wǎng)絡(luò)模型不同參數(shù)對(duì)中文文本情感分類(lèi)效果的影響時(shí)所取的數(shù)值,模型參數(shù)值則是依據(jù)網(wǎng)格搜索的調(diào)參方法得到的本文所提出模型分類(lèi)準(zhǔn)確率最高時(shí)的取值.各參數(shù)在本文實(shí)驗(yàn)數(shù)據(jù)集中的表現(xiàn)具體如圖6所示.
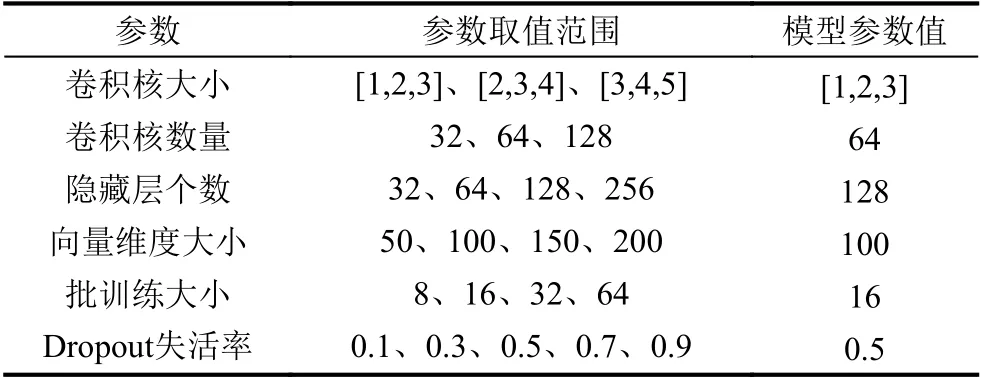
表2 模型參數(shù)
3.4 實(shí)驗(yàn)設(shè)置及結(jié)果分析
為了驗(yàn)證本文所提出模型的有效性,本小節(jié)將依據(jù)傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)模型、融合情感特征信息的卷積神經(jīng)網(wǎng)絡(luò)模型、雙通道卷積神經(jīng)網(wǎng)絡(luò)模型以及本文所提出模型在相同的評(píng)論數(shù)據(jù)集上進(jìn)行文本情感分類(lèi)實(shí)驗(yàn),而且各模型的參數(shù)值設(shè)定一致,如表2所示.此外還會(huì)將經(jīng)典傳統(tǒng)機(jī)器學(xué)習(xí)方法支持向量機(jī)的實(shí)驗(yàn)結(jié)果納入對(duì)比分析范圍中.其中,各模型的實(shí)驗(yàn)介紹如下所示:
1)支持向量機(jī)模型:記為SVM.此模型的輸入文本以預(yù)先訓(xùn)練好的詞向量初始化.
2)傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)網(wǎng)絡(luò)模型:記為CNN.此模型為典型的CNN 模型,只有一個(gè)輸入通道,并使用本預(yù)先訓(xùn)練好的詞向量對(duì)實(shí)驗(yàn)文本數(shù)據(jù)初始化.
3)融合情感特征信息的卷積神經(jīng)網(wǎng)絡(luò)網(wǎng)絡(luò)模型:記為SF-CNN.此模型結(jié)構(gòu)同典型CNN 一致,但在對(duì)實(shí)驗(yàn)文本數(shù)據(jù)進(jìn)行初始化時(shí)會(huì)加入文本特征的情感信息.
4)雙通道卷積神經(jīng)網(wǎng)絡(luò)模型:記為D-CNN.此模型具有兩個(gè)輸入通道,其中一個(gè)輸入通道初始化文本數(shù)據(jù)的方式同CNN 模型,另外一個(gè)則以預(yù)先訓(xùn)練好的字向量來(lái)初始化文本數(shù)據(jù).
5)本文所提出模型:記為SFD-CNN.此模型結(jié)構(gòu)與D-CNN 相同,其中一個(gè)輸入通道的文本初始化方式同SF-CNN 模型,另一個(gè)通道則是以預(yù)先訓(xùn)練的字向量來(lái)初始化文本.
上述模型在同一評(píng)論文本數(shù)據(jù)集上進(jìn)行十折交叉驗(yàn)證,并以10 次實(shí)驗(yàn)結(jié)果的平均值來(lái)衡量模型的情感分類(lèi)性能,最終的實(shí)驗(yàn)結(jié)果如表3所示.

圖6 模型參數(shù)取值對(duì)準(zhǔn)確率的影響

表3 不同模型情感分類(lèi)實(shí)驗(yàn)結(jié)果
為了更為清晰地表達(dá)各實(shí)驗(yàn)結(jié)果的對(duì)比情況,將表3中的數(shù)據(jù)圖形化,具體情況如圖7所示.其中,Precision+代表積極類(lèi)文本的精準(zhǔn)率,Recall+代表積極類(lèi)文本的召回率,F1+代表積極類(lèi)文本的F1 值;Precision?代表消極類(lèi)文本的精準(zhǔn)率,Recall?代表消極類(lèi)文本的召回率,F1?代表消極類(lèi)文本的F1 值;Accuracy 代表文本的整體準(zhǔn)確率.
結(jié)合表3和圖7的實(shí)驗(yàn)結(jié)果可知,常用的傳統(tǒng)機(jī)器學(xué)習(xí)方法中基于詞向量的SVM 模型情感分類(lèi)性能最差,而且比同樣基于詞向量的CNN 模型準(zhǔn)確率低了2.15%.這是因?yàn)镃NN 模型比SVM 模型具有更高的學(xué)習(xí)能力,可從詞向量中提取到更為抽象的深層次語(yǔ)義信息.可見(jiàn),本文提出使用卷積神經(jīng)網(wǎng)絡(luò)模型對(duì)中文短文本進(jìn)行情感分析是有效可行的.對(duì)比CNN 和SF-CNN 兩個(gè)模型的結(jié)果易知,融入特征詞語(yǔ)情感信息的SF-CNN 模型性能相較于CNN 模型有所提升,其在F1+、F1?和準(zhǔn)確率上的取值分別高于CNN 模型的1.14%、0.67%、0.45%.這表明在文本特征詞語(yǔ)的語(yǔ)義向量中融入的情感信息在模型進(jìn)行情感分類(lèi)時(shí)為其提供了額外的有效信息,使模型能夠提取到更為有用的、辨別情感類(lèi)別的文本特征.對(duì)于雙通道輸入的D-CNN 模型來(lái)說(shuō),其F1+、F1?和準(zhǔn)確率分別為92.54%、92.38%、92.47%,所達(dá)到的情感分類(lèi)效果也要優(yōu)于CNN 模型,主要是由于該模型從字向量方面在一定程度上彌補(bǔ)了中文分詞錯(cuò)誤對(duì)模型帶來(lái)的不利影響,而且以雙通道的形式輸入文本信息,可以提取到更為全面的敏感信息.進(jìn)一步,從圖7中易知,SFD-CNN 模型的情感分類(lèi)性能最為優(yōu)越,無(wú)論是在F1+、F1?的值上還是準(zhǔn)確率上,其值都要比其他模型大.這說(shuō)明綜合考慮SF-CNN 模型和D-CNN 模型的改進(jìn)之處可進(jìn)一步提升情感分類(lèi)效果.與最初的CNN 模型相比,其F1+值提高了2.07%,F1?值提高了2.32%,準(zhǔn)確率提高了2.19%.

圖7 各CNN 模型實(shí)驗(yàn)結(jié)果對(duì)比圖
4 結(jié)論
本文針對(duì)在情感分類(lèi)研究中傳統(tǒng)機(jī)器學(xué)習(xí)模型的缺陷,提出使用深度學(xué)習(xí)中的卷積神經(jīng)網(wǎng)絡(luò)模型來(lái)實(shí)現(xiàn)對(duì)短文本的情感分類(lèi),同時(shí)也針對(duì)以往研究中文本情感特征提取的不足以及忽視分詞錯(cuò)誤對(duì)情感分類(lèi)的影響,對(duì)經(jīng)典的卷積神經(jīng)網(wǎng)絡(luò)模型進(jìn)行改進(jìn),提出一種融合情感特征的雙通道卷積神經(jīng)網(wǎng)絡(luò)模型SFD-CNN,并設(shè)置對(duì)比試驗(yàn),將其與CNN、SF-CNN、D-CNN 以及SVM 模型進(jìn)行比較.最終的實(shí)驗(yàn)結(jié)果表明SFDCNN 模型的情感分類(lèi)性能最優(yōu),無(wú)論是準(zhǔn)確率還是F1+、F1?值都要高于其他模型.由于本文所使用的CNN 模型都是單層結(jié)構(gòu),無(wú)論是卷積層還是池化層都只有一層,所以接下來(lái)可以進(jìn)一步研究多層結(jié)構(gòu)的CNN 模型對(duì)文本情感分類(lèi)的效果.
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
