基于自編碼器和改進K均值聚類的光伏組件故障診斷
2021-01-23 07:59:42周皖奎
通信電源技術 2020年19期
楊 君,林 翀,周皖奎
(杭州華電下沙熱電有限公司,浙江 杭州 310018)
0 引 言
光伏發電光伏組件多部署于地勢復雜、環境惡劣的場所,依靠人工巡檢的方式排查和診斷故障時效性差,難以檢出故障,影響電池壽命和發電效率,甚至會引發事故。因此,需采用有效的光伏故障診斷方法,以提高故障檢出的時效性和檢出率,降低人工成本。
目前,光伏組件的故障診斷主要有傳統巡檢和智能算法等方式。人工巡檢診斷方式主要有熱成像法、對地電容測量法以及經驗觀察法等。由于它的時效性差、巡檢周期長以及成本高,光伏組件的故障診斷正逐漸地被智能分析法取代。陶彩霞針對光伏陣列的常見故障類型,提出基于深度信念網絡,通過故障數據的樣本積累度模型進行訓練,從而診斷光伏的常規故障。但是,采用深度網絡對少量的光伏故障數據進行處理,容易出現模型欠擬合和難以收斂的問題[1]。Kang B K利用環境溫度、光伏組件電流以及電壓,提出了基于卡爾曼濾波器的故障檢測模型,但模型無法穩定數據的明顯擾動,導致無法檢出故障類型[2]。Ding H提出了一種決策樹模型檢測故障和識別故障類型,其監督學習方式針對小樣本的效果并不明顯,且忽視了環境擾動對模型帶來的影響[3]。YI Z基于模式識別方法和模糊推理系統確定光伏是否發生故障,其模糊系統的建立依靠個人經驗需反復試湊,主觀性較大[4]。
針對以上問題,提出了基于AE和K-Means++的光伏組件故障診斷方法,利用AE表征學習少量樣本的連續參數,進行去線性化,降低參數內部的耦合性,然后通過AE壓縮降維后,采用K-Means++對AE生成的降維特征進行聚類。該方法能明顯降低故障類別的混淆,有效分類故障模式。
1 基礎理論
1.1 自編碼器
自編碼器是一種能夠通過無監督學習學到輸入數據并高效表示的人工神經網絡。自編碼器包含編碼器(Encoder)和解碼器(Decoder)兩部分,如圖1所示。自編碼器隱含層神經元個數小于輸入層神經網絡個數即可進行數據壓縮和降維,通過對已有無標簽的數據學習數據之間的關鍵表征,舍棄一些數據間共有的無關緊要的特征,從而降低在高維空間下不同類型數據特征之間的混淆。

圖1 自編碼器結構
1.2 改進K均值聚類
K-Means算法是解決聚類問題的經典算法,簡單快速。當結構集是密集的,簇與簇之間區別明顯時,聚類算法的結果較好。在處理大量數據時,該算法具有較高的可伸縮性和高效性。
傳統的K-Means算法擁有許多優勢,同時存在K值需要事先指定、對初始聚類中心敏感、對噪聲敏感以及只能發現球狀簇的缺陷。其中,初始聚類中心敏感的特性對模型影響最大。若聚類中心選取不合理,聚類會出現偏差、空簇甚至計算失敗的情況,影響聚類的穩定性。合理選擇初始聚類中心可以加快算法的收斂,避免聚類陷入局部最優。多次K-Means聚類取平均的方法能夠在一定程度上降低其影響。但是,對于多次聚類差異較大的聚類中心,其平均值會受較大的影響。因此,考慮采用K-Means++的方式進行聚類,改進傳統K-Means算法隨機選取K個點作為初始聚類中心的問題,實現步驟如下。第一步,隨機選取一個點P1作為聚類中心。第二步,求樣本中每個點與前n(1<n<K)個聚類中心距離的和。第三步,選擇距離最遠的樣本點作為下一個簇的初始聚類中心。第四步,重復第二步和第三步,直到找出K個初始聚類中心。
2 光伏組件故障診斷分析
2.1 光伏故障診斷步驟
基于AE和K-Means++的光伏故障診斷方法需要獲取故障樣本數據,通過AE降維和K-Means++聚類分析獲取聚類中心及對應類別,最后利用新的故障數據診斷故障。具體步驟如下:第一,獲取光伏組件原始故障數據;第二,根據原始數據集訓練AE,當AE模型收斂并評估達到要求后,保存AE模型、結構以及權重;第三,獲取AE編碼器部分層,通過保存的模型權重將數據降維為2維,以便聚類和可視化分析;第四,利用K-Means++聚類分析AE降維后的數據集,保存聚類中心,并將聚類中心與光伏故障類別相對應;第五,獲取新的故障數據,通過AE進行降維后計算降維后的數據與保存的聚類中心的距離,距離最近的聚類中心對應的故障類別即為光伏當前故障類別;第六,通過新的數據集重新更新聚類中心,使模型不斷地自省和完善,提升模型故障診斷的準確率。
2.2 數據樣本選取
光伏組件內部特性的改變會引起如最大功率電壓、電流以及輸出功率等指標的改變。理論上,光伏組件發電量的計算式為:

式中,L為發電總量;Q為斜面總輻照量;S為光伏總面積;η為光電轉換效率。由于輻照、溫度、積灰、蒸發量以及氣壓等各種外部因素的影響,光伏發電量往往沒有那么多。因此,為準確分析光伏組件的故障,需綜合考慮光伏組件的內外影響因素。選取最主要的輸出電流、輸出電壓、環境溫度、凈輻射瞬時值、蒸發量、氣壓以及輸出功率等內外部參數作為輸入,重點分析常見的短路、開路、老化以及遮擋故障類型。選取遼寧某光伏廠家SSM235P-60型多晶硅組件,分別采集不同季節、不同輻照以及不同溫度條件下的組件故障數據。每種故障數據100條,共400條故障數據,其中320條數據用于自編碼器訓練,80條數據用于自編碼器驗證和分類測試,如表1所示。
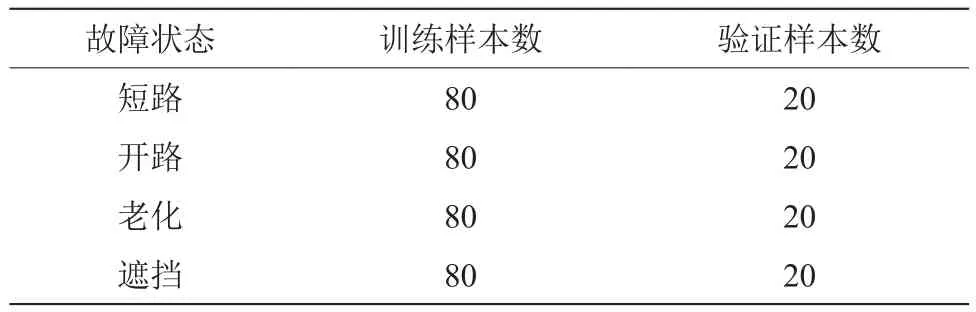
表1 光伏組件故障數據分布
2.3 自編碼器訓練集數據降維
光伏樣本數據特征數為7。對于特征維度較小的數據樣本,為防止過擬合,選取僅含一個隱含層的自編碼器。為便于數據可視化和聚類分析,隱含維度為2作為數據壓縮的維度。自編碼器結構如表2所示。

表2 自編碼器網絡結構
為避免網絡過擬合,提升網絡的穩定性,在原始數據上增加隨機擾動作為輸入,原始數據作為輸出,并增加L2正則化項,模型batch_size=8,epoch=100。經過100輪迭代后,網絡訓練結果如圖2(a)所示。可見,在23輪前,模型訓練損失急劇下降,隨后趨于平穩。模型精度如圖2(b)所示,由于添加了正則化項,驗證集模型精度比訓練集模型精度稍高,模型在訓練集和驗證集上模型精度均超過95%,驗證集精度更是超過98%。由此可知,該自編碼器滿足對光伏組件數據特征的提取及降維要求。
2.4 故障聚類及結果分析
通過K-Menas++聚類分析主成分分析(Principle Component Analysis,PCA)降維后的數據,并利用輪廓圖分析聚類的性能。如圖3(a)所示,聚類分析在相應的數據集上,強行將數據分析指定對應的類別。由圖3(b)可知,聚類輪廓系數遠低于1,且平均輪廓系數不到0.43,說明聚類類別存在明顯的重疊。
采用訓練好的AE降維數據,將輸入的7維數據降維為2維,利用K-Means++進行聚類,聚類結果如圖4(a)所示。由圖4(b)可知,它的分類內聚度總體較好,僅類別4分類內聚度較低,單聚類平均輪廓系數達到0.63,總體聚類效果較好。
取數據集中用于驗證AE模型的80條故障數據驗證模型,通過AE降維后求最近的聚類中心判斷故障類別,其故障診斷具體信息如表2所示。除少量的開路和遮擋故障類別被分到其他類別外,該模型準確分類了短路和老化故障類別。由此可知,AE能夠準確地提取故障特征,并且利用K-Means++進行聚類獲取聚類中心,在光伏組件故障診斷應用中效果良好,結果如表3所示。
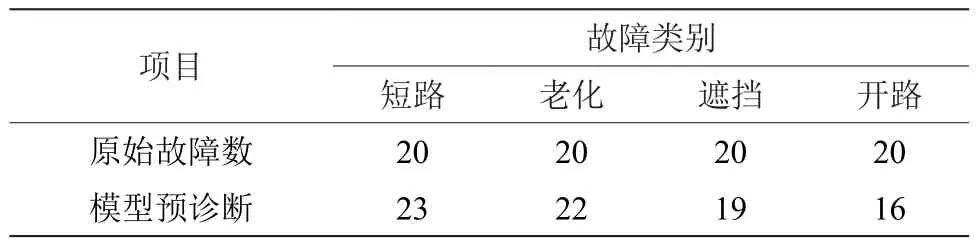
表3 模型故障診斷結果
3 結 論
本文基于AE和K-Means++算法診斷光伏組件的短路、老化、遮擋以及開路故障,分別采用AE對光伏組件這種非線性系統進行特征提取和數據降維,通過聚類可視化分析分類識別降維后的數據特征,以達到故障診斷的目的。通過數據試驗和對比分析可知,AE對復雜的數據特征降維的表現明顯優于PCA。通過AE降維,將電壓、電流等連續呈條狀的數據分布形式進行解耦和離散化,以充分滿足K-Means++聚類的需求。利用改進的K-Means++,優化初始聚類中心的選取,進一步降低了不同類別之間的混淆,提升了故障診斷的準確率。
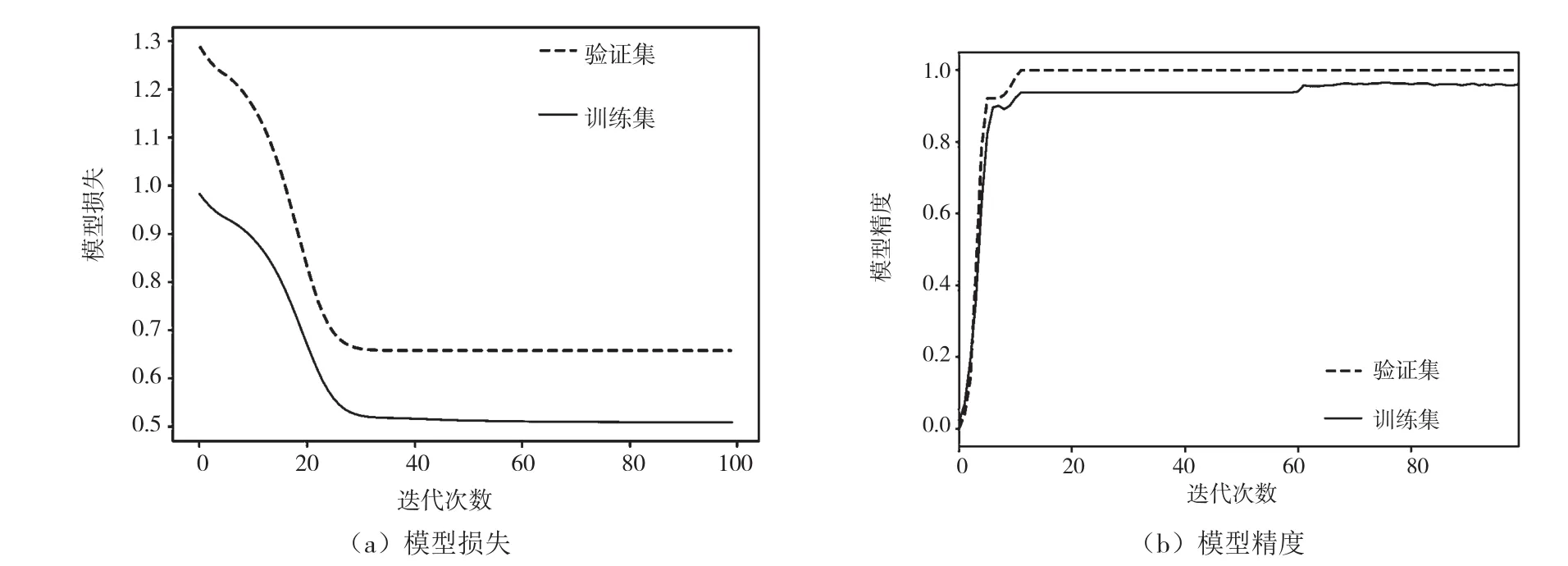
圖2 自編碼器訓練結果
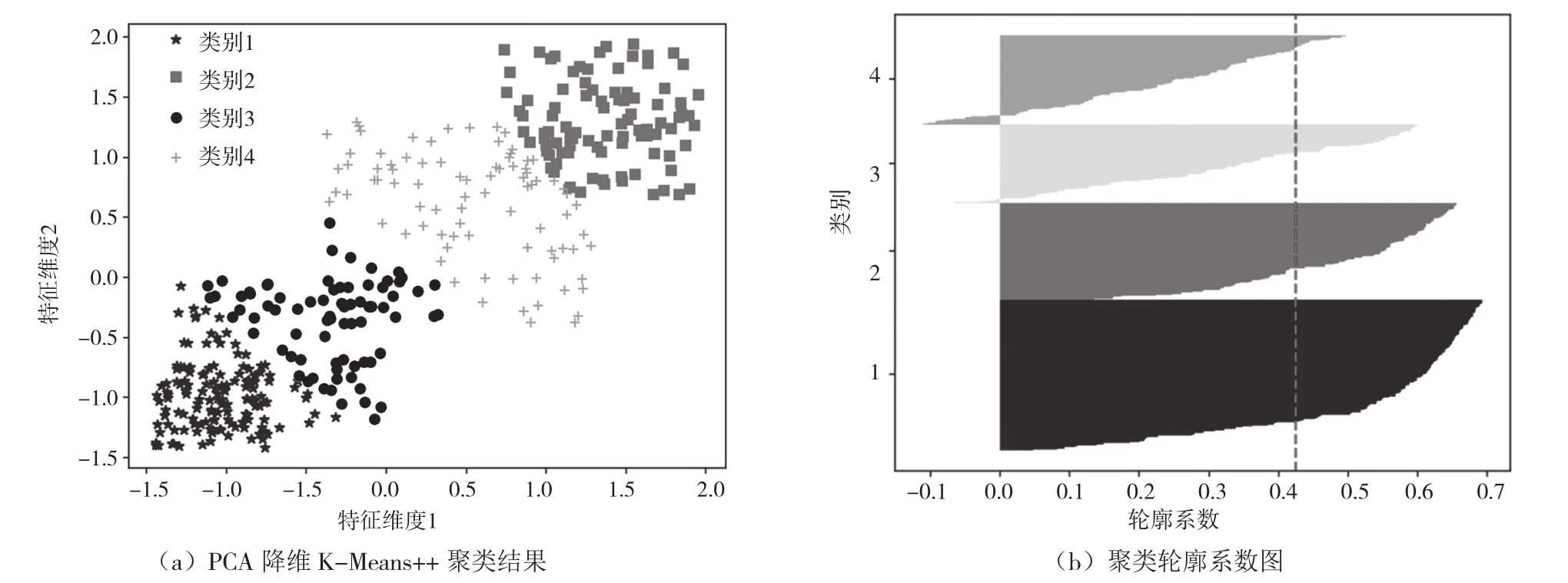
圖3 數據PCA降維K-Means++聚類可視化
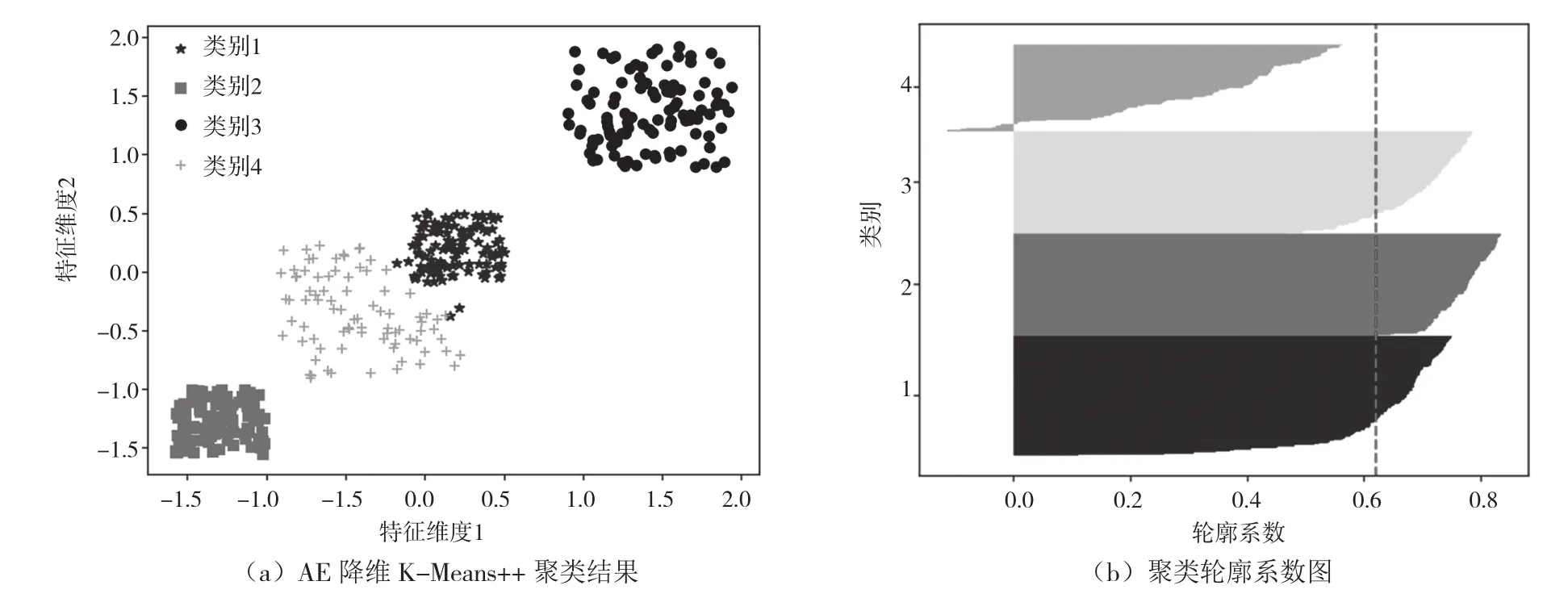
圖4 數據AE降維K-Means++聚類可視化
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
