移動應用評論挖掘研究綜述
2021-01-23 21:27:45張季康樂樂李博
知識管理論壇 2021年6期
張季 康樂樂 李博


摘要:[目的/意義]用戶評論有助于開發者實現移動應用創新,通過對移動應用評論挖掘相關文獻進行歸納總結,為移動應用開發和評論挖掘提供借鑒。[方法/過程]利用文本分析方法,將移動應用評論挖掘相關研究歸納為評論分類、評論聚類和評論特征抽取3個關鍵主題,并基于此框架闡述該領域的發展狀況。[結果/結論]研究得出:評論分類方法已開始從機器學習向深度學習演變;評論聚類主要使用K-Means和DBSCAN;特征抽取仍以評論的顯式特征為主。未來,移動應用評論挖掘仍有3個問題值得探究,分別是領域依賴性、多源信息融合以及評論價值評估。
關鍵詞:移動應用? ? 評論挖掘? ? 評論分類? ? 評論聚類? ?特征抽取
分類號:TP391.1
引用格式:張季, 康樂樂, 李博. 移動應用評論挖掘研究綜述[J/OL]. 知識管理論壇, 2021, 6(6): 339-350[引用日期]. http://www.kmf.ac.cn/p/266/.
1? 引言
隨著移動互聯網的發展和移動設備的普及,移動應用(簡稱APP)已經成為日常生活中不可或缺的一部分。自蘋果公司2008年7月份發布App Store、谷歌公司2008年10月份推出Android Market(2012年更名為Google Play Store)之后,移動應用如雨后春筍般涌現出來。經過10多年的發展,Google Play Store已有超過345萬款應用,Apple App Store也有近220萬款應用[1],這些應用從社交媒體到新聞資訊、從商務辦公到娛樂消遣、從醫療健康到學習教育、從在線購物到金融理財,涵蓋了人們生活中的眾多場景。2020年,受新冠肺炎疫情的影響,人們使用移動設備的習慣向前推進了2-3年,移動應用下載量達到了2 180億次,每個用戶日均使用移動設備的時長超過了4小時[2]。
移動應用的巨大需求量給APP開發者帶來無限機遇的同時,也給開發者帶來了巨大的挑戰。第一,移動應用商店具有明顯的開放性特征[3]。在商店中,關于某一應用的功能描述、用戶評論、更新文檔等都是公開可見的。這意味著應用一旦發布,就面臨著被模仿甚至被抄襲的風險。第二,需求分析具有典型的階段性特征。應用程序都是針對當時的需求開發的,但在與移動應用交互的過程中,用戶會不斷產生新的需求。第三,市場競爭異常激烈。在特定的細分市場上,功能高度相似的應用少則數款、多則數十款,用戶可以輕易地從一款APP轉移到另一款APP[4]。
對于移動應用而言,創新一直以來都被認為是獲得競爭優勢的關鍵來源[5-6]。根據新穎程度,創新可分為突破式創新和漸進式創新[7]。突破式創新是設計一個全新的產品或提出產品設計的新方法,是從0到1的過程;漸進式創新是對現有產品進行持續不斷的迭代優化,是從1到N的過程。移動應用創新更多的是從1到N的過程,即對APP進行長期的維護和改進。不同于實體產品的創新,移動應用創新迭代非常快,如Google Play中的應用平均13天更新一次[8]。要在如此頻繁更新的情況下獲得不錯的市場績效,開發者需要及時地從用戶那里收集反饋。用戶創新理論最先由希普爾發現并提出,該理論認為在某些行業或領域往往是用戶而不是生產商提出具有創意的產品或服務[9]。所以,這些生產商要從傳統的以自己為中心的創新轉向以用戶為中心的創新,要為用戶提供平臺以激發他們的創造力[10]。
移動應用商店的出現不僅為用戶打造了一個絕佳的反饋平臺,而且為開發者提供一個汲取知識的創新平臺。應用商店允許用戶以數字星級(從1星到5星)和開放式文本的形式發表評論[11],其中文本通常由標題和正文組成。在開發應用新版本時,開發者平均會使用50%的信息性評論[12]。所謂信息性評論,是對提高APP質量或用戶體驗有潛在幫助的評論。然而,對開發者來說,從評論中快速篩選出信息性評論并不容易,主要原因有:①評論數量大,增長速度快。評論數量隨著時間的推移會越積越多,Google Play Store中一些熱門應用每天會收到500多條評論[13],人工審閱耗時耗力。②信息性評論大約只占總評論數的三分之一[14]。也就是說,評論中包含大量的虛假評論、不相關的評論以及非評論等垃圾評論[15]。③評論文本是有噪聲的。用戶撰寫的文本常常不符合語法,存在拼寫錯誤、縮寫、表情包,缺少或亂加標點符號[16]。④不同于其他評論(如新聞評論、圖書評論、影視評論),移動應用評論具有強時效性和高價值性,用戶針對某一版本發表的功能錯誤、程序崩潰等評論,若開發者及時響應,將極大地增強用戶的身份認同和使用體驗。因此,諸多學者致力于探索如何自動從海量的、非結構化的、非正式的評論文本中挖掘有價值的信息,然后將其納入軟件開發環節,以促進移動應用的迭代創新。
學界圍繞移動應用評論挖掘取得了眾多的研究成果,已有學者對此進行了系統性綜述。N. Genc-Nayebi和A. Abran[17]從評論挖掘技術、領域依賴、評論有用性、垃圾評論識別和軟件特征提取5個方面展開敘述,揭示了評論挖掘的主要研究問題。但是,該綜述的分類體系較為分散,并且由于文獻量不足難以對評論有用性和垃圾評論識別進行全面客觀的述評。M. Tavakoli等[18]針對評論挖掘技術和工具進行綜述,將評論挖掘技術分為有監督的機器學習技術、自然語言處理技術和特征提取技術,并羅列了當時的評論挖掘工具。然而,其缺乏對評論挖掘技術更有深度和廣度的分析和歸納。鑒于評論挖掘在移動應用創新領域具有重要的意義,且近幾年APP評論挖掘方法已經有了新的進展,所以有必要重新梳理相關文獻。
本文主要貢獻如下:①篩選出利用用戶評論驅動APP創新的相關文獻;②利用文本分析方法,將相關研究歸納為評論分類、評論聚類和特征抽取三大類,以期明確該領域的發展現狀;③從領域依賴性、多源信息融合以及評論價值評估3個方面進行展望,為未來的研究提供參考。
2? 數據來源和研究框架
2.1? 數據來源
本研究英文論文選取Web of Science核心數據集中的SCI-E、SSCI、CPCI作為數據來源。在增加每個術語可能的同義詞以及對檢索結果分析的基礎上,確定的檢索式為(TS=(“user reviews$” or “consumer review$” or “user feedback” or “user comment$”) and TS= (“mobile app$” or “mobile application$” or “app store$” or “app market$”)) or (TS = (“app review$” or “application review$”)),語言類型為English,時間跨度為2009-2020年,文獻類型選擇article、review和proceedings paper。然后,篩選出與移動應用創新相關的評論挖掘文章共54篇文獻作為研究樣本。中文論文選擇中國知網全文數據庫中的核心期刊作為數據來源,檢索式為(su=(‘用戶評論 + ‘用戶反饋+用戶評價) and (‘移動應用+應用程序+應用商店+應用市場+app)) or (su=app評論 + ‘應用評論),時間跨度為2009-2020年。同樣,篩選出與移動應用創新相關的評論挖掘文章,整理得到13篇文獻。綜合67篇中英文文獻,對用戶評論驅動APP創新的研究進行系統總結。
2.2? 研究框架
能夠表達論文核心內容的關鍵詞或主題詞的詞頻分布可用來研究某一領域的發展現狀[19]。筆者利用CiteSpace V[20]從54篇英文文獻的標題、摘要、關鍵詞、補充關鍵詞中提取名詞性短語,一共抽取了226個名詞性短語。作者對統計結果作進一步處理:①刪除檢索詞以及與檢索詞表達相同含義的短語(如mobile app reviews);②把表達相同主題的短語進行歸并;③保留頻次大于3的主題,并將主題按頻次由大到小排列,如表1所示:
3? 評論挖掘
3.1? 評論分類
評論分類的目的不僅是要識別出有價值的評論,而且要對評論類型進行更細致的劃分。通過對Apple應用商店中528條評論的人工分析,D. Pagano和W. Maalej將其分為17個類別[22],其中大約一半的類別被認為與移動應用創新相關[23-24],如錯誤報告、功能請求和功能缺陷等。H. Khalid更加關注負面評論,從20個iOS應用的6 390條一星或兩星的評論中人工區分出12種類型的用戶抱怨,其中功能錯誤、附加功能請求和程序崩潰等類型對開發者優化APP至關重要[25]。基于機器學習和深度學習的評論分類能夠從評論中迅速識別出對開發者有用的評論類型,克服了人工分類耗時長、主觀性強等缺陷。
3.1.1? 基于機器學習的評論分類
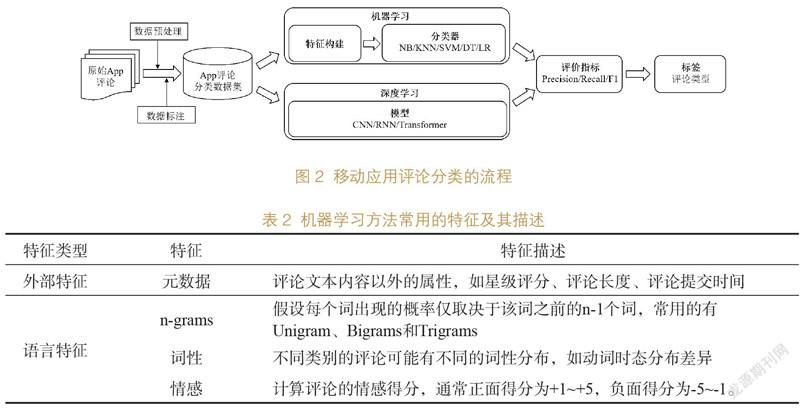
移動應用評論分類的關鍵流程如圖2所示。從圖中可以看出,機器學習需要人為構建特征,有意義的特征會顯著提高分類算法的性能。移動應用評論的特征可以分為語言特征和外部特征(見表2)。外部特征是指評論文本內容以外的屬性,而語言特征主要包括n-grams、詞性、情感。在進行評論分類時,主要利用語言特征,輔以評論元數據。常用的評論分類算法包括樸素貝葉斯(Na?ve Bayes,NB)、K-近鄰(K-Nearest Neighbor,KNN)、支持向量機(Support Vector Machine,SVM)、決策樹(Decision Tree,DT)、邏輯回歸(Logistic Regression,LR)。
與單獨使用文本分析、自然語言處理、情感分析和評論元數據相比,結合它們會取得更好的結果[24, 26]。W. Maalej和H. Nabil[27]進行了一系列實驗來比較簡單字符串匹配、詞袋模型、自然語言處理(去除停用詞和詞形還原)、評論元數據和情感分析技術的準確率。研究發現,僅靠元數據會導致分類準確率很低,當與自然語言處理技術相結合時,分類準確率在70%-95%之間,召回率在80%-90%之間。在所有的實驗中,多個二類分類器比多類分類器更準確地預測評論類型。次年,W. Maalej等[28]進一步探索,將元數據與詞袋模型、自然語言處理(尤其是二元語法和詞形還原)結合時,所有評論分類的準確率可達88%-92%,召回率高達90-99%。
由于有監督的方法需要人工標注訓練數據,這個過程會花費大量的時間。所以在不影響準確性的情況下,主動學習和半監督學習也受到相關學者的關注。雖然主動學習和半監督學習都用到了未標注的數據,但二者的學習方式不同。主動學習是從未標注的數據中選擇最易判斷錯誤的樣本交由專家標注,從而最小化訓練評論分類器所需的人力,與隨機選擇的訓練數據集相比,主動學習在多個場景下顯著提高了預測的準確率[29]。然而,半監督學習是選擇最不易判斷錯誤的樣本加入已標注數據。胡天媛等[30]綜合分析用戶評論的內容和句式結構的特點,采用半監督自學習的方式,基于有限數量和類型的評論種子,通過循環的方式自動挖掘出體現使用反饋的APP軟件用戶評論。為了有效控制用于貶低目標應用或操縱應用排名的虛假評論,D. J. He等[31]提出了一種基于PU學習(Positive-unlabeled learning)和行為密度(behavior density)的方法來檢測虛假評論。
還有學者采用集成學習方法,以期通過聚合多個弱監督模型得到一個強監督模型。集成學習算法主要有兩種:Bagging和Boosting。通過將樸素貝葉斯、決策樹、支持向量機、邏輯回歸、神經網絡等不同的算法以不同的集成學習算法集成起來,大多數情況下,集成學習的性能優于單個模型[23, 32]。
上述研究依賴于評論的文本屬性,這通常會產生高維模型,并可能導致過擬合問題。因此,N. Jha和A. Mahmoud[33]使用語義框架將用戶評論分類為用戶需求、錯誤報告和其他,結果表明,語義框架有助于生成更低維、更準確的模型。但是,在評論摘要任務中,基于文本生成的摘要比基于框架生成的摘要更全面[34]。
3.1.2? 基于深度學習的評論分類
深度學習相較于機器學習沒有顯式的特征構建過程,目前已經被廣泛應用于自然語言處理問題,并在文本分類任務中取得了很好的效果。王瑩等[35]從功能性需求與非功能性需求兩個維度出發,對用戶評論進行軟件需求挖掘,采用TextCNN、TextRNN和Transformer3種深度學習方法,實驗結果顯著優于傳統的機器學習方法。同樣,A. Li等[36]提出一種基于圖卷積網絡的大規模反垃圾評論模型,該模型集成了同構圖和異構圖來描述局部上下文和全局上下文,線上評估和線下性能都驗證了該方法優于利用評論信息、用戶特征和商品特征的基線模型。通常來說,深度學習在大量訓練數據的情況下會有更好的表現,但在小規模的訓練數據上可能并不能取得預期的效果。例如,C. Stanik等[37]使用傳統的機器學習方法就獲得了與卷積神經網絡相當的結果。當然,更復雜的模型也意味著更高的時間成本。
最后,移動應用評論分類往往牽涉訓練數據類別分布不平衡的問題,這會造成分類器決策邊界偏移,從而在實際應用中效果不佳。現有文獻主要采用兩種方式:①用代價敏感的學習方法來緩解不平衡數據的影響[38-39],即對不同類型的誤分類設置不同的代價;②使用重采樣技術來處理不平衡的類[40-41],即對數量多的類進行欠采樣(也稱為“下采樣”)、數量少的類進行過采樣(也稱為“上采樣”)。
3.2? 評論聚類
評論分類是根據預定義的類別給評論分配標簽,而評論聚類是將相似且沒有預先劃定類別的評論聚在一起。典型的聚類算法有K-Means和DBSCAN,其中K-Means是基于形心的聚類,而DBSCAN是基于密度的聚類。張莉曼等[42]在Word2vec詞向量模型的基礎上,結合Canopy和K-Means對評論聚類,即通過Canopy得到聚類簇數,再運用K-Means得到聚類結果,該方法有效識別并聚合了用戶需求。不同于廣泛使用的K-Means,DBSCAN可以自動確定聚類簇的個數,而不需要預先指定。因此,這種方法也受到了學者的關注。L. Villarroel等[4]采用DBSCAN算法對錯誤報告、新功能建議兩種類型的評論進行聚類,并分別針對這兩種類型的聚類簇執行優先級排序。在此基礎上,S. Scalabrino等[43]對評論進行了更細粒度的分類,增加了4類非功能性需求:安全問題報告、性能問題報告、過度能耗報告和可用性改進請求。不過,K-Means和DBSCAN在移動應用評論數據集上的優劣有待進一步研究。
3.3? 特征抽取
雖然評論分類或評論聚類可以從大量的評論文本中挖掘高價值的評論,但后續仍需開發者人工分析才能知道用戶喜歡或討厭的具體是哪些特征。為了解決這個問題,學者們提出了多種方法以高效地抽取APP特征,進而可以分析用戶對這些APP特征的情感。筆者結合APP評論中特征抽取的研究現狀,參照B. Liu對屬性抽取方法的分類[44],將相關文獻劃分為4類:基于頻率、基于句法分析、基于監督學習和基于主題模型的特征抽取。
3.3.1? 基于頻率的特征抽取
基于頻率的特征抽取通常先利用ICTCLAS、jieba、Standford Parser等自然語言處理工具進行詞性標注,然后從標注好的語料中提取出名詞、動詞等,最后保留大于設定閾值的詞作為候選特征[44]。P. M. Vu等[45]從原始評論中提取所有的名詞和動詞作為關鍵詞,根據評論星級和出現頻率對關鍵詞進行排序,以便開發者查找與所需關鍵詞最相關的評論。不過,單個詞語只能淺顯、零散地表達用戶觀點,而短語可以提供更完整的信息。于是,P. M. Vu等[46]使用詞性組合來提取用戶評論中的短語,根據短語之間的相似性度量對短語進行分組,排序并監測這些分組的動態變化,從而幫助開發者獲取主要的用戶觀點。
為了從評論中挖掘出用戶高頻反饋的特征,不少學者使用關聯分析。這一方法的基本假設是:用戶在評價APP特征時,用詞是比較一致的[47]。因此,那些頻繁出現的名詞或動詞很可能就是APP特征。為了提高特征挖掘的效果,呂宏玉等[48]先利用基于句式匹配和情感傾向識別出特征請求評論,然后通過Apriori關聯規則挖掘算法提取軟件特征。與之不同,文濤等[49]利用Apriori算法提取特征后,針對每一條評論語句需要進一步識別出其中包含的<特征詞, 觀點詞>對。鑒于傳統的頻繁項集挖掘算法(如Apriori)計算量大且難以擴展,C. Gao等[50]采用Eclat算法快速獲得所有頻率大于支持度閾值的候選短語。
3.3.2? 基于句法分析的特征抽取
觀點詞和觀點評價對象之間的評價或修飾關系往往能夠通過句法關系來表征,而句法分析可以識別這些關系[44],從而實現特征的抽取。句法分析從語法的角度分析詞語之間的關系,包括句法結構分析和依存關系分析。Z. Peng等[51]使用Stanford Parser從評論的依存關系分析中提取動名詞短語(動詞—名詞)和名詞短語(名詞—名詞或形容詞—名詞),然后基于短語與主題之間的相關性,確定作為功能請求的短語。考慮到APP評論描述的內容總是與場景相關,D. Sun等[52]利用評論的短語結構樹和依存關系提取核心關注(kernel concern),并為每個核心關注構建聚合場景模型,幫助需求分析人員更完整、更準確地理解用戶的真實意圖。
3.3.3? 基于監督學習的特征抽取
特征抽取任務可以轉化為序列標注任務,當前主要的序列標注算法有隱馬爾可夫模型(Hidden Markov Model,HMM)和條件隨機場(Conditional random field,CRF)。CRF對HMM進行了改進,打破了HMM與實際問題不符的兩個基本假設——齊次馬爾可夫性假設和觀測獨立性假設。因此,CRF在特征抽取任務中的表現更為出色,也更為常用[53]。崔建苓等[54]提出基于本體和CRF融合的特征提取方法,并將深度學習Recursive Autoencoder應用于情感分析,最后形成<特征,話題,情感詞,句子,極性>的五元組,結果表明RERM(Requirement Elicitation method based on Review Mining)對潛在軟件需求類型分類的效果良好,比ASUM(Aspect and Sentiment Unification Model) [55]提供了更多有價值的信息。
3.3.4? 基于主題模型的特征抽取
主題模型是一種生成概率模型,其目標是從文檔集合中挖掘出其潛藏的主題[56]。當前APP評論挖掘中應用最廣泛的主題模型是由D. M. Blei提出的潛在狄利克雷分配(Latent Dirichlet Allocation,LDA)。LDA主題模型利用不同文檔中觀測到的詞來推斷文檔的主題分布及主題中詞的分布[57]。王欣研等[58]通過LDA獲取用戶評論主題詞并運用Glove詞向量相似性得到主題語義關聯,然后構建出語義關聯主題圖譜,從而為開發者高效獲取用戶需求提供了新的思路和方法。近年來,學者們也提出了許多LDA的變體模型用于評論挖掘,如動態LDA[59]、自適應在線LDA[60]、E-LDA[61]等。
除了普遍使用的LDA及其變體模型外,ASUM[55]、非負矩陣分解[62]等主題模型也會被采用。另外,還有部分學者對比了不同主題模型的效果。E. Suprayogi等[63]比較了LDA和非負矩陣分解,從主題連貫性來看,非負矩陣分解的表現更好。C. Gao等[64]比較了潛在語義索引、LDA、隨機投影、非負矩陣分解和基于吉布斯抽樣的LDA模型,最終基于吉布斯抽樣的LDA模型取得了與AR-Miner(App Review Miner)[14]相當的命中率,并實現了動態跟蹤排名靠前的評論所反映的主要主題。
現有的主題模型大多基于LDA和概率潛在語義分析,但是這些主題模型對短文本的表現不佳,因為短文本會造成數據稀疏、難以識別歧義詞含義等問題[65]。為此,M. A. Hadi和F. H. Frad[66]提出了自適應在線Biterm主題模型,有效緩解了詞語共現模式稀疏的問題,可以從APP評論中抽取出更連貫、更高區分度的主題。
4? 總結與展望
移動應用商店匯集了大量用戶對APP的使用體驗和建議,而這些反饋是開發者取得競爭優勢的重要抓手,因為用戶評論中包含功能缺陷、功能請求等有利于開發者優化APP、提升用戶體驗的信息。筆者從評論分類、評論挖掘、特征抽取3個方面對相關的文獻進行系統性梳理。首先,基于監督學習的評論分類仍是主流,但評論分類方法已經開始從機器學習向深度學習演變,深度學習方法在評論分類任務中的效果往往優于機器學習方法。其次,評論聚類通常作為評論分類的后續步驟,因為特定類別中的評論數量可能有數百條,通過聚類可以進一步降低開發者獲取信息所付出的時間和精力。聚類算法有很多,但現有研究還沒有比較不同聚類算法或算法的不同設置在移動應用評論數據集上的性能優劣。最后,有關特征抽取的文獻主要集中在移動應用評論顯式特征的挖掘,主題模型能夠在一定程度上解決隱式特征抽取問題,但還需要專門針對APP評論隱式特征抽取進行研究。
未來,移動應用評論挖掘還需要深入研究的問題主要有:
(1)領域依賴性。在不同類別的應用中,詞語會呈現出不同的含義,語言模式也有所不同,這使得大多數研究僅適用于特定的實驗環境。例如,T. Johann等[67]提出的特征提取方法SAFE(a Simple Approach for Feature Extraction),通過人工分析應用頁面和評論,確定了18個詞性模式和5種句子模式,并用這些模式來提取應用頁面和評論的特征。該方法對于頁面維護良好的Google Drive,精度為87%;對于評估的10個應用程序,平均精度為56%。然而,F. A. Shah等[68]將SAFE用于8個不同的數據集(6個APP評論數據集、1個筆記本電腦評論數據集和1個餐廳評論數據集)獲得的平均精度遠低于論文中報告的性能。因而,APP評論挖掘中如何實現領域遷移是一個具有挑戰的研究方向。
(2)多源信息融合。一方面,不同應用商店的管理策略和用戶群體存在顯著的差異,使得即使是同一APP在不同應用商店中的用戶反饋也會有所不同[69];另一方面,開發者不僅需要了解自身應用的優點和缺點,還要時刻關注競爭應用的長處和不足。因此,需要整合不同應用商店的用戶反饋以及競爭應用的評論、產品描述和更新文檔。除了從應用商店挖掘信息外,還可以收集APP運行時的數據。將應用商店數據和APP運行數據融合在一起,可以更全面地反映移動應用的狀態,更準確地把握用戶的需求。
(3)評論價值評估。移動應用評論的質量參差不齊,有用評論少、低價值評論多。因此,高效的評論價值評估對于APP開發具有積極的現實意義。當前大多數研究尚未考慮到,APP評論價值的評估不僅僅是一個技術性問題,更是一個理論性問題。需要構建合適的價值評估體系,從多個角度對移動應用評論進行分析。具體而言,可以從評論的信息價值、時間價值、創新價值等多個維度,對移動應用評論進行恰當的評估,以最大限度地挖掘評論的價值,更好地推動APP評論挖掘的演化。
參考文獻:
