自適應(yīng)分箱特征選擇的快速網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)
2021-01-29 04:30:46劉景美高源伯
西安電子科技大學(xué)學(xué)報(bào) 2021年1期
劉景美,高源伯
(西安電子科技大學(xué) 綜合業(yè)務(wù)網(wǎng)理論及關(guān)鍵技術(shù)國(guó)家重點(diǎn)實(shí)驗(yàn)室,陜西 西安 710071)
近來年,隨著大數(shù)據(jù)、工業(yè)互聯(lián)網(wǎng)、物聯(lián)網(wǎng)等新型技術(shù)的發(fā)展,安全威脅和網(wǎng)絡(luò)攻擊也隨之增多,網(wǎng)絡(luò)安全面臨著新的挑戰(zhàn),安全形勢(shì)嚴(yán)峻[1]。因此,設(shè)計(jì)一套能夠準(zhǔn)確高效識(shí)別各種網(wǎng)絡(luò)攻擊的網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng),已成為現(xiàn)如今亟待解決的一個(gè)問題。
為提高網(wǎng)絡(luò)入侵檢測(cè)的準(zhǔn)確率,研究者們?cè)跈C(jī)器學(xué)習(xí)、深度學(xué)習(xí)中探索新的算法并將其應(yīng)用于此[2-6]。然而,這些算法普遍存在訓(xùn)練時(shí)間和檢測(cè)時(shí)間較長(zhǎng)的問題,針對(duì)這一問題,很多研究者利用特征選擇[7-14],將原始高維數(shù)據(jù)降為低維數(shù)據(jù),從而減少訓(xùn)練和檢測(cè)的時(shí)間。
文獻(xiàn)[15]設(shè)計(jì)了一種基于多目標(biāo)優(yōu)化與logistic回歸的封裝器,有效提高了準(zhǔn)確率,然而,這種算法以logistic回歸模型的預(yù)測(cè)結(jié)果為優(yōu)化目標(biāo),每一輪都需要重新訓(xùn)練模型,算法時(shí)間復(fù)雜度較高,時(shí)間較長(zhǎng)。文獻(xiàn)[16]利用基于信息增益的過濾器與深度學(xué)習(xí)模型設(shè)計(jì)的入侵檢測(cè)系統(tǒng),準(zhǔn)確率相對(duì)較高,但是,在特征選擇方面,由于入侵檢測(cè)數(shù)據(jù)集同時(shí)存在連續(xù)型和離散型數(shù)據(jù),且數(shù)據(jù)分布不均勻,采用基于信息增益的過濾器算法運(yùn)行時(shí)間相對(duì)較長(zhǎng)。針對(duì)這一問題,筆者提出了一種基于信息增益的自適應(yīng)分箱特征選擇算法,對(duì)入侵檢測(cè)數(shù)據(jù)集中的連續(xù)型數(shù)據(jù)進(jìn)行自適應(yīng)分箱處理,從而降低計(jì)算復(fù)雜度,提高特征選擇階段的效率。
將提出的自適應(yīng)分箱特征選擇算法與LightGBM集成學(xué)習(xí)模型相結(jié)合,設(shè)計(jì)了一種快速網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng),在保證較高準(zhǔn)確率的條件下大大降低了模型訓(xùn)練和入侵檢測(cè)的時(shí)間。通過在網(wǎng)絡(luò)入侵檢測(cè)領(lǐng)域常用數(shù)據(jù)集NSL-KDD上測(cè)試,表明文中算法在準(zhǔn)確率和訓(xùn)練時(shí)間上均優(yōu)于隨機(jī)森林、AdaBoost等現(xiàn)有算法。
1 基于信息增益的自適應(yīng)分箱特征選擇
信息增益是衡量通過得知特征X的信息從而對(duì)所要預(yù)測(cè)類別Y的信息的不確定性減少的程度;通過計(jì)算數(shù)據(jù)集中每個(gè)特征相對(duì)于類別標(biāo)簽的信息增益,從而得到各特征對(duì)預(yù)測(cè)類別的貢獻(xiàn)程度,之后通過選取信息增益較大的特征生成新的特征子集,達(dá)到數(shù)據(jù)降維的目的,進(jìn)而保證系統(tǒng)在較高準(zhǔn)確率的條件下降低訓(xùn)練和檢測(cè)時(shí)間。信息增益的計(jì)算公式為
IG(Y|X)=H(Y)-H(Y|X) ,
(1)
其中,H(Y)為數(shù)據(jù)集中類別Y的信息熵,對(duì)于含有n個(gè)類別的數(shù)據(jù)集,Y={y1,y2,…,yn},其計(jì)算公式為
(2)
其中,P(yi)為在數(shù)據(jù)集的所有類別中yi的出現(xiàn)的概率。H(Y|X)的計(jì)算為
(3)
其中,m為特征X中的取值個(gè)數(shù),P(xj)是特征X為xj的概率,P(yi|xj)是在特征X為xj的條件下類別Y為yi的概率。
對(duì)于傳統(tǒng)的基于信息增益的特征選擇,在計(jì)算P(yi|xj)時(shí),要計(jì)算特征X取特征值時(shí)的條件概率。在入侵檢測(cè)系統(tǒng)的數(shù)據(jù)中,同時(shí)存在連續(xù)型數(shù)據(jù)和離散型數(shù)據(jù),對(duì)于取值較少的離散型數(shù)據(jù)來說,這種計(jì)算量并不大,但是對(duì)于連續(xù)型數(shù)據(jù)和取值較多的離散型數(shù)據(jù)來說,這無疑是一個(gè)巨大的計(jì)算開銷。對(duì)于一個(gè)有m種取值的特征,其時(shí)間復(fù)雜度為O(m),以NSL-KDD數(shù)據(jù)集為例,該數(shù)據(jù)集中的特征“dst_bytes”共有9 326種取值;如果直接對(duì)其進(jìn)行信息增益的計(jì)算,那么計(jì)算量是很大的,因此,對(duì)該特征不同取值進(jìn)行分組成為了一個(gè)必然趨勢(shì)。然而,由于網(wǎng)絡(luò)入侵檢測(cè)數(shù)據(jù)集中數(shù)據(jù)分布不平衡的特點(diǎn),如果直接按數(shù)值或樣本個(gè)數(shù)來平均分組,那么分組后的特征無法很好地表示原始特征的分布情況。為此,設(shè)計(jì)了一種基于信息增益的自適應(yīng)分箱特征選擇算法。
以含有n個(gè)樣本點(diǎn)的特征X為例,該算法過程如下:


(3)按分箱后的結(jié)果將同一箱子中的樣本記為同一特征值,計(jì)算各特征的信息增益。
這種算法與傳統(tǒng)的基于信息增益的特征選擇算法結(jié)果相近,但運(yùn)算效率大大提高。這里的時(shí)間復(fù)雜度由原來的O(m)降至O(mbox),m為特征取值的數(shù)量,隨訓(xùn)練集中特征取值的變化而變化;mbox是預(yù)先設(shè)置的分箱數(shù)量,為常數(shù)。因此,本算法將時(shí)間復(fù)雜度從傳統(tǒng)算法的線性階降低為常數(shù)階。對(duì)于連續(xù)值特征,mbox?m,以分箱數(shù)為20的特征選擇算法為例,對(duì)于NSL-KDD數(shù)據(jù)集中的“dst_bytes”特征,時(shí)間復(fù)雜度從原來的O(9 326)降至為O(20),有效降低了運(yùn)行時(shí)間,提高了程序的效率。
2 基于自適應(yīng)分箱特征選擇與LightGBM的快速網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)框架
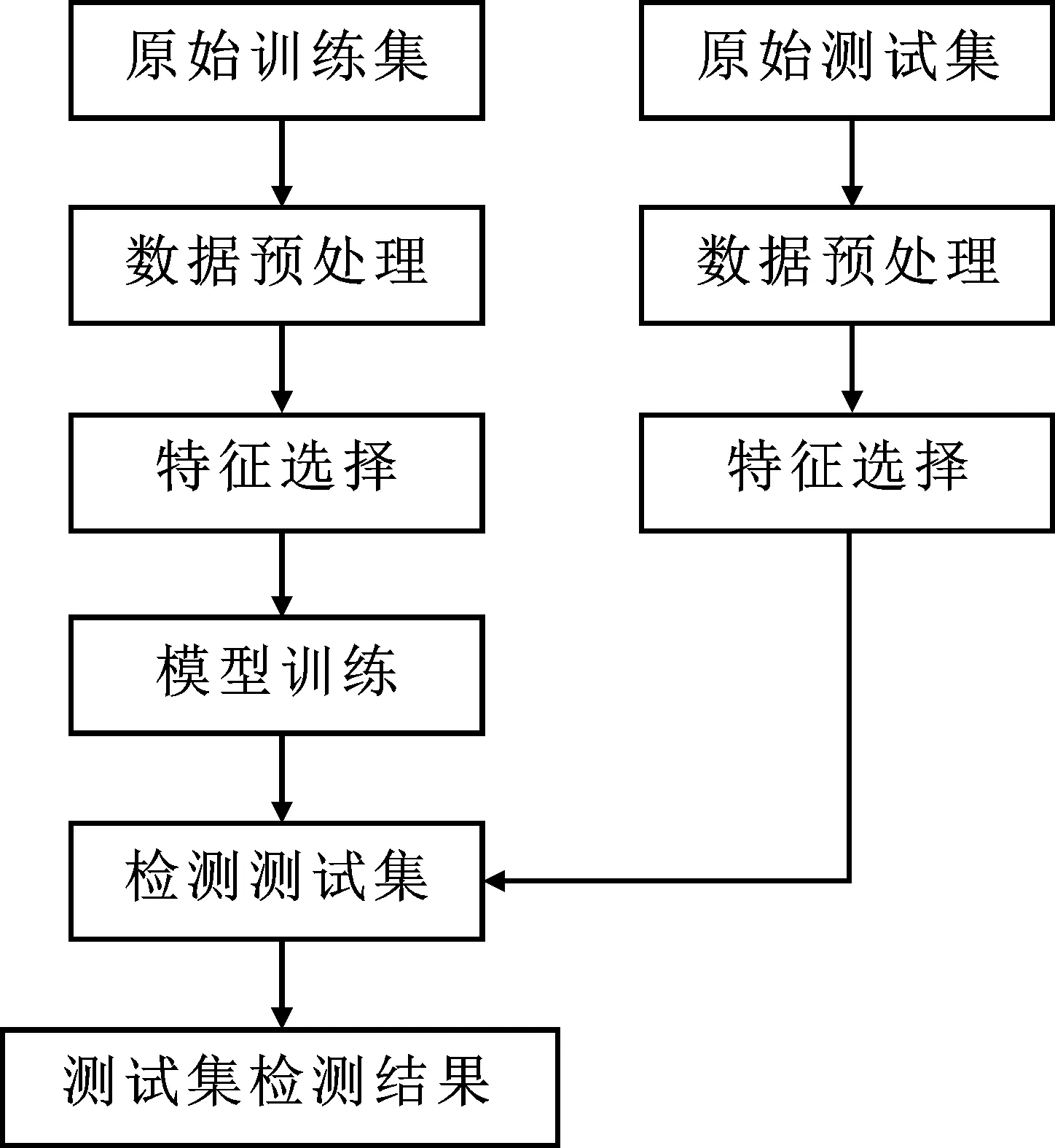
圖1 入侵檢測(cè)系統(tǒng)框架圖
設(shè)計(jì)的基于自適應(yīng)分箱特征選擇與LightGBM的快速網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)整體框圖如圖1所示。對(duì)于原始訓(xùn)練集,首先進(jìn)行數(shù)據(jù)預(yù)處理,將原始數(shù)據(jù)集標(biāo)準(zhǔn)化處理并去除無效特征;再通過基于信息增益的自適應(yīng)分箱特征選擇算法,對(duì)原始數(shù)據(jù)集的所有特征按照各特征的信息增益進(jìn)行排序,選取信息增益較大的n個(gè)特征生成維度較低的數(shù)據(jù)子集;之后利用LightGBM集成學(xué)習(xí)對(duì)特征選擇后的訓(xùn)練集進(jìn)行訓(xùn)練,訓(xùn)練出所需的網(wǎng)絡(luò)入侵檢測(cè)模型。在系統(tǒng)性能驗(yàn)證階段,將對(duì)測(cè)試集按照之前訓(xùn)練集中相同的預(yù)處理和特征選擇方法進(jìn)行操作;之后通過文中的入侵檢測(cè)系統(tǒng)進(jìn)行檢測(cè);將檢測(cè)結(jié)果與真實(shí)結(jié)果相對(duì)比,從而計(jì)算出本系統(tǒng)檢測(cè)的準(zhǔn)確率等性能指標(biāo),全面評(píng)估本系統(tǒng)綜合性能。
2.1 數(shù)據(jù)預(yù)處理
對(duì)于原始數(shù)據(jù)的數(shù)據(jù)預(yù)處理,主要采用了零均值標(biāo)準(zhǔn)化和去除無效特征的方法。
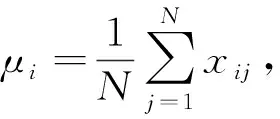
(4)
在去除無效特征階段,將遍歷所有特征,去除特征值惟一的特征。在NSL-KDD數(shù)據(jù)集中,由于特征“num_outbound_cmds”中所有的特征值均為0,因此該特征無法起到有效預(yù)測(cè)作用,所以刪除該特征。
2.2 基于LightGBM的集成學(xué)習(xí)模型
LightGBM是一種基于梯度單邊采樣(Gradient-based One-Side Sampling ,GOSS)與互斥特征捆綁(Exclusive Feature Bundling ,EFB)的梯度提升決策樹(Gradient Boosting Decision Tree ,GBDT)模型。針對(duì)之前的GBDT模型訓(xùn)練時(shí)間較長(zhǎng),且時(shí)間消耗主要在于最佳分割點(diǎn)確定上這一問題,LightGBM在決策樹的特征選擇與分割點(diǎn)確定方面,采用了直方圖算法。這種算法將原來連續(xù)的特征值進(jìn)行分箱處理,在之后的訓(xùn)練模型時(shí)使用這些分箱結(jié)果構(gòu)建直方圖,大大減少了對(duì)分裂點(diǎn)選擇的時(shí)間,提高了訓(xùn)練和檢測(cè)的效率[17]。
為減少每次迭代過程中樣本的數(shù)量,并對(duì)預(yù)測(cè)效果不好的樣本加強(qiáng)訓(xùn)練,LightGBM引入了GOSS算法。對(duì)于經(jīng)過上一輪訓(xùn)練過后的樣本,計(jì)算每個(gè)樣本的梯度。每個(gè)樣本的梯度可以表示該樣本預(yù)測(cè)的錯(cuò)誤程度。為此,通過GOSS算法保留所有梯度較大的實(shí)例,對(duì)于梯度較小的實(shí)例則采取按照一定比例隨機(jī)采樣的策略。
在計(jì)算每個(gè)樣本的梯度方面,設(shè)O為決策樹中某個(gè)固定節(jié)點(diǎn)上的訓(xùn)練數(shù)據(jù)集。定義該節(jié)點(diǎn)在點(diǎn)d處分割特征j的方差增益為
(5)


(6)
其中,Al={xi∈A:Xij≤d},Ar={xi∈A:Xij>d},Bl={xi∈B:Xij≤d},Br={xi∈B:Xij>d}。
在網(wǎng)絡(luò)入侵檢測(cè)領(lǐng)域,通常情況下數(shù)據(jù)集是相對(duì)稀疏的,因此有些特征會(huì)存在互斥特性,即不同時(shí)取非零的情況。針對(duì)這一情況,LightGBM還引入了EFB對(duì)數(shù)據(jù)中的互斥特征進(jìn)行捆綁,從而進(jìn)一步降低模型的計(jì)算復(fù)雜度。通過EFB可以將多個(gè)特征捆綁為一個(gè)束bundle,這樣就將計(jì)算復(fù)雜度從原來的O(#data×#feature)降為O(#data×#bundle),從而進(jìn)一步降低模型在訓(xùn)練和檢測(cè)階段的時(shí)間復(fù)雜度,提高運(yùn)行效率。
3 實(shí)驗(yàn)仿真結(jié)果與分析
本實(shí)驗(yàn)操作系統(tǒng)環(huán)境為Windows 10,電腦硬件cup為i7-5 500 U,8 GB內(nèi)存,在Python 3.7軟件環(huán)境中編程實(shí)現(xiàn)。設(shè)置了特征選擇的結(jié)果比較實(shí)驗(yàn)和整體系統(tǒng)模型的性能比較實(shí)驗(yàn)。
3.1 數(shù)據(jù)集介紹與分析
為有效驗(yàn)證網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)的性能,采用網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)領(lǐng)域常用的數(shù)據(jù)集NSL-KDD[18]。NSL-KDD數(shù)據(jù)集分為訓(xùn)練集和測(cè)試集,訓(xùn)練集共包括125 973條有效數(shù)據(jù),測(cè)試集共包括22 544條有效數(shù)據(jù)。由于本數(shù)據(jù)集在不同類別樣本之間的數(shù)量存在不平衡現(xiàn)象,在訓(xùn)練集中對(duì)部分少數(shù)類別攻擊樣本進(jìn)行了隨機(jī)過采樣;之后,隨機(jī)選取訓(xùn)練集中的90%作為訓(xùn)練數(shù)據(jù),10%的數(shù)據(jù)作為驗(yàn)證數(shù)據(jù)從而訓(xùn)練模型。最后通過在測(cè)試集的檢測(cè)結(jié)果驗(yàn)證本系統(tǒng)的性能。
在特征方面,NSL-KDD數(shù)據(jù)集中共包括41維特征和1維結(jié)果標(biāo)簽,在41維特征中,僅7維特征是離散型數(shù)據(jù),其他34維特征均為連續(xù)型數(shù)據(jù),該數(shù)據(jù)集數(shù)據(jù)數(shù)值的分布特點(diǎn)符合大多數(shù)網(wǎng)絡(luò)入侵檢測(cè)領(lǐng)域數(shù)據(jù)的特點(diǎn),因此,如果直接對(duì)數(shù)據(jù)集進(jìn)行基于信息增益的特征選擇,則時(shí)間復(fù)雜度將會(huì)很大,嚴(yán)重影響了程序運(yùn)行效率;而使用文中提出的基于信息增益的自適應(yīng)分箱特征選擇,時(shí)間復(fù)雜度將大大降低,在保證達(dá)到所需特征選擇需求的條件下,有效提高程序的運(yùn)行效率。
3.2 特征選擇的結(jié)果比較實(shí)驗(yàn)
在特征選擇性能比較實(shí)驗(yàn)方面,首先對(duì)提出的特征選擇算法與傳統(tǒng)基于信息增益特征選擇算法進(jìn)行對(duì)比,在NSL-KDD的訓(xùn)練集上進(jìn)行實(shí)驗(yàn)。利用傳統(tǒng)的基于信息增益的特征選擇算法與分箱數(shù)量設(shè)置為20的文中算法,在NSL-KDD的訓(xùn)練集上信息增益排名前8的特征及結(jié)果如表1所示。結(jié)果表明,在信息增益排名前8的特征中,雖然有個(gè)別幾個(gè)特征的順序不是完全一致,但在排名前8的特征中,所選擇的體征種類完全相同,僅存在部分信息增益差距較小的特征出現(xiàn)順序不一致的現(xiàn)象。這種信息增益大體一致的結(jié)果,能夠滿足選擇特征的需求。在運(yùn)行時(shí)間方面,基于信息增益的特征選擇運(yùn)行時(shí)間為824.43 s,而筆者提出的基于信息增益的自適應(yīng)分箱特征選擇算法僅用時(shí)27.35 s,相比于傳統(tǒng)的特征選擇算法,所用時(shí)間減少了約96.68%,大大提高了程序的效率。

表1 兩種特征選擇算法結(jié)果比較
3.3 入侵檢測(cè)系統(tǒng)性能比較實(shí)驗(yàn)
對(duì)于網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)方面的比較實(shí)驗(yàn),首先對(duì)基于自適應(yīng)分箱特征選擇算法與LightGBM的入侵檢測(cè)系統(tǒng)進(jìn)行仿真實(shí)驗(yàn)。在設(shè)計(jì)的基于特征選擇與LightGBM的網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)中,首先需要確定特征選擇的數(shù)量。由基于自適應(yīng)分箱特征選擇算法計(jì)算的信息增益排名結(jié)果可以看出,前3個(gè)特征的信息增益均在0.28以上,遠(yuǎn)高于其他特征,且前8個(gè)特征的信息增益均大于0.1。為此,將主要研究選取前3個(gè)特征和前8個(gè)特征的特征子集。為全面研究不同特征的預(yù)測(cè)結(jié)果,并驗(yàn)證選取3個(gè)特征和8個(gè)特征的準(zhǔn)確率情況,在利用自適應(yīng)分箱算法計(jì)算的信息增益的排序結(jié)果中,按照排序順序依次選取不同數(shù)量的特征進(jìn)行實(shí)驗(yàn)。不同的特征選擇在LightGBM分類器下的準(zhǔn)確率如圖2所示。由圖可知,當(dāng)選擇特征數(shù)量大于3時(shí),在驗(yàn)證集的準(zhǔn)確率已經(jīng)很高且趨于平穩(wěn)。在測(cè)試集中,選用3個(gè)特征時(shí)準(zhǔn)確率也相對(duì)較高;在選擇特征數(shù)量為8時(shí),驗(yàn)證集中已經(jīng)處于較高的平穩(wěn)水平,在訓(xùn)練集中準(zhǔn)確率也相對(duì)較高。可以看出,選用3個(gè)特征和8個(gè)特征兩種情況性能表現(xiàn)相對(duì)較好。
為進(jìn)一步研究不同迭代次數(shù)時(shí),選取的3個(gè)特征和8個(gè)特征的數(shù)據(jù)子集與原始數(shù)據(jù)集的性能情況,分別在驗(yàn)證集和測(cè)試集中對(duì)文中算法進(jìn)行仿真驗(yàn)證。在驗(yàn)證集和訓(xùn)練集中,不同迭代數(shù)量的準(zhǔn)確率結(jié)果分別如圖3和圖4所示。由圖3可知,迭代次數(shù)在100到200之間,在驗(yàn)證集中的準(zhǔn)確率大幅提升,當(dāng)?shù)螖?shù)大于200時(shí),3種情況的準(zhǔn)確率均提升緩慢,特別是當(dāng)?shù)螖?shù)大于500時(shí),準(zhǔn)確率曲線趨于平穩(wěn)。為保證系統(tǒng)能夠在保證較高準(zhǔn)確率的條件下實(shí)現(xiàn)快速網(wǎng)絡(luò)入侵檢測(cè),選取迭代次數(shù)為650。3種情況的詳細(xì)性能比較如表2所示。
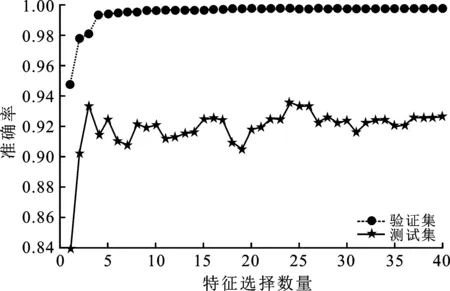
圖2 不同特征準(zhǔn)確率折線圖
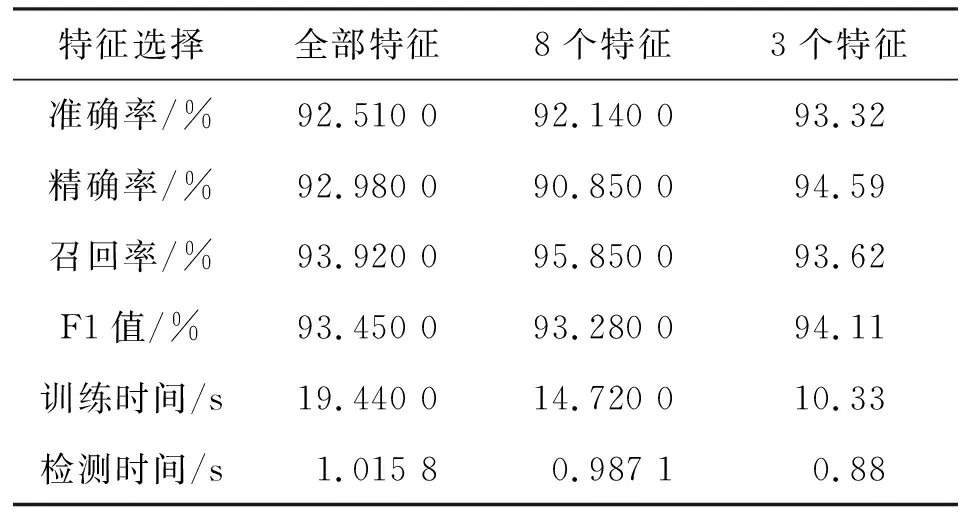
表2 不同特征性能對(duì)照表
在圖3的驗(yàn)證集中,雖然原始數(shù)據(jù)集的準(zhǔn)確率始終保持高于其他兩種情況,但是在圖4的測(cè)試集中,通過特征選擇的3特征數(shù)據(jù)子集準(zhǔn)確率整體高于其他兩種情況,這與3個(gè)特征集中的特征有關(guān)。原始數(shù)據(jù)集存在大量的冗余和噪聲,在驗(yàn)證集中,通過多次迭代優(yōu)化,會(huì)引導(dǎo)模型趨于有效區(qū)分驗(yàn)證集中攻擊和正常樣本的方向訓(xùn)練。然而,此時(shí)所選取特征和特征值的劃分點(diǎn)很有可能只滿足驗(yàn)證集的數(shù)據(jù)分布特點(diǎn)而不滿足整體數(shù)據(jù)集,這將導(dǎo)致模型過擬合;雖然在驗(yàn)證集上的準(zhǔn)確率很高,但泛化能力不強(qiáng)。而選用的3特征數(shù)據(jù)子集,三個(gè)特征的信息增益遠(yuǎn)高于其他特征。這三個(gè)特征與類別標(biāo)簽的相關(guān)性較強(qiáng),能夠?yàn)闄z測(cè)類別提供可靠依據(jù),以及為入侵檢測(cè)系統(tǒng)有效區(qū)分攻擊和正常流量提供可靠保證。

圖3 驗(yàn)證集準(zhǔn)確率迭代曲線圖
通過表2中對(duì)三種情況的詳細(xì)性能指標(biāo)對(duì)比,選用3種特征的數(shù)據(jù)子集在準(zhǔn)確率和F1(精確率和召回率的調(diào)和函數(shù))值這兩個(gè)核心指標(biāo)上均優(yōu)于其他兩種情況。特別是在訓(xùn)練和檢測(cè)時(shí)間上,選用3種特征的數(shù)據(jù)子集的訓(xùn)練時(shí)間僅約為原始數(shù)據(jù)集時(shí)間的一半,大大提高了模型訓(xùn)練效率,且測(cè)試時(shí)間也均少于其他兩種情況,縮短了模型訓(xùn)練和入侵檢測(cè)的時(shí)間。
為進(jìn)一步評(píng)估文中設(shè)計(jì)的網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)的綜合性能,還設(shè)置了多種預(yù)測(cè)模型的綜合對(duì)比實(shí)驗(yàn)。引入了現(xiàn)有網(wǎng)絡(luò)入侵檢測(cè)的主流算法K近鄰(K-Nearest Neighbor,KNN)、決策樹(Decision Tree ,DT)、Adaboost、隨機(jī)森林(Random Forest ,RF)、支持向量機(jī)(Support Vector Machine ,SVM)、GBDT和XGBoost。將上一組實(shí)驗(yàn)中表現(xiàn)性能最好的選用3個(gè)特征的LightGBM模型與這些算法進(jìn)行詳細(xì)的對(duì)比分析,各算法詳細(xì)的性能表現(xiàn)如表3所示。
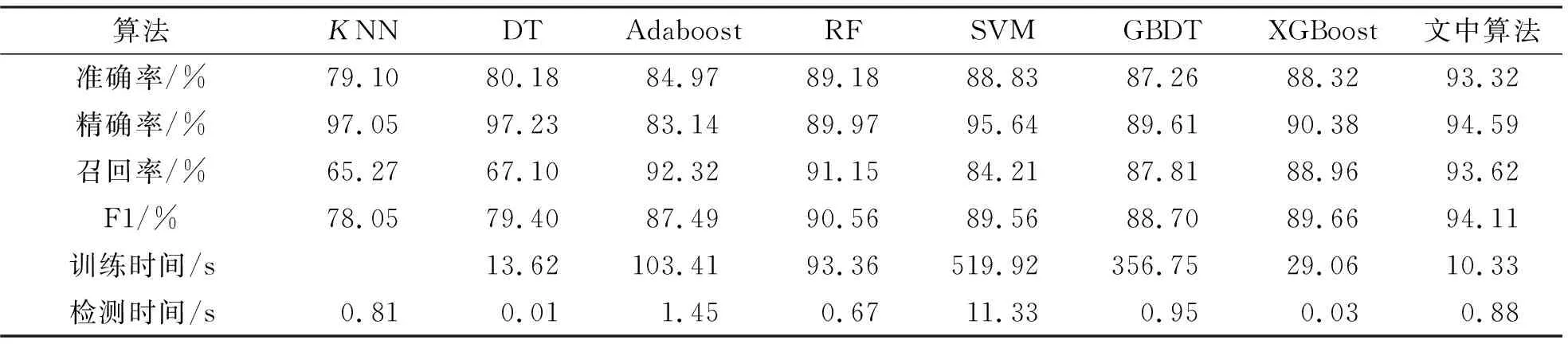
表3 不同入侵檢測(cè)模型性能對(duì)比表
對(duì)于網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)來說,準(zhǔn)確率和F1值是評(píng)判系統(tǒng)整體性能優(yōu)劣的主要標(biāo)準(zhǔn)。在這兩個(gè)指標(biāo)的比較中,筆者提出的基于特征選擇與LightGBM的入侵檢測(cè)系統(tǒng)均優(yōu)于其他算法。在精確率方面,KNN和DT兩個(gè)算法相對(duì)較高,但是其召回率較低,如果將其應(yīng)用于實(shí)際網(wǎng)絡(luò)入侵檢測(cè)環(huán)境中,將會(huì)對(duì)網(wǎng)絡(luò)系統(tǒng)造成很大的損失。在訓(xùn)練時(shí)間方面,筆者設(shè)計(jì)的入侵檢測(cè)系統(tǒng)的訓(xùn)練時(shí)間均小于除KNN外的其他算法(KNN無需學(xué)習(xí)新的模型),能夠?qū)崿F(xiàn)模型的快速訓(xùn)練。對(duì)于利用多種單一模型的集成學(xué)習(xí)來說,在提高準(zhǔn)確率的同時(shí)會(huì)延長(zhǎng)模型訓(xùn)練和檢測(cè)時(shí)間。Adaboost和隨機(jī)森林雖然在準(zhǔn)確率方面較單一模型有所提高,但是其訓(xùn)練時(shí)間過長(zhǎng)。對(duì)于SVM來說,由于其計(jì)算的復(fù)雜度較高,雖然準(zhǔn)確率相對(duì)較高,但是其訓(xùn)練和檢測(cè)時(shí)間過長(zhǎng),難以部署在實(shí)際場(chǎng)景中。通過以上性能對(duì)比分析,無論是在檢測(cè)的準(zhǔn)確率還是模型的訓(xùn)練時(shí)間方面,文中所述算法整體性能優(yōu)于其他現(xiàn)有算法。
4 結(jié)束語
與傳統(tǒng)基于信息增益的特征選擇算法相比,筆者提出的基于信息增益的自適應(yīng)分箱特征選擇算法在保證結(jié)果與之前算法相近的條件下,大大降低了時(shí)間復(fù)雜度,速度更快。在NSL-KDD訓(xùn)練集的實(shí)驗(yàn)中,與傳統(tǒng)算法相比,本算法時(shí)間縮短了約96.68%。筆者設(shè)計(jì)的基于自適應(yīng)分箱特征選擇與LightGBM的快速網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng),準(zhǔn)確率更高且模型訓(xùn)練速度相對(duì)較快。通過在NSL-KDD數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果可知,該系統(tǒng)的準(zhǔn)確率高達(dá)93.32%,且訓(xùn)練時(shí)間僅為10.33 s,對(duì)于22 544條的測(cè)試集樣本,檢測(cè)時(shí)間僅0.88 s,可用于網(wǎng)絡(luò)入侵檢測(cè)場(chǎng)景。未來,將進(jìn)一步探索入侵檢測(cè)領(lǐng)域各特征之間的潛在關(guān)系,研究更好的降維方式,在較快速度的同時(shí),進(jìn)一步提高入侵檢測(cè)系統(tǒng)的準(zhǔn)確率。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
