淺析復雜場景下的濕地鳥類目標檢測
2021-02-01 14:01:54周鐵林
科學與信息化 2021年2期
周鐵林
沈陽理工大學 遼寧 沈陽 110000
1 YOLOv3目標檢測及原理
目標檢測是將圖像或視頻中的目標與感興趣區域分開,確定目標是否存在,以及是否存在目標,確定目標的位置。YOLO系列目標檢測網絡是單次目標檢測網絡中最具代表性的網絡結構,YOLOv3是YOLO系列的網絡之一,因為在檢測精度上可以與兩次目標檢測網絡相媲美,同時可以達到實時檢測速度,因此成為主要的,廣泛應用的目標檢測算法之一。
2 YOLOv3對于濕地鳥類檢測算法的改進
2.1 對于檢測框及網絡層的改進
針對拍攝采集的數據大多模糊不清,對于需要采集的目標容易造成采集模糊,無法識別,無法定位的這個問題,需要在算法的預測框方面改良,使其更好地檢測到實際需要采集的目標。一個目標的每個邊界框都要預測邊界框位置信息(x,y,w,h)和置信度(cinfidence),置信度的計算公式如公式1所示:
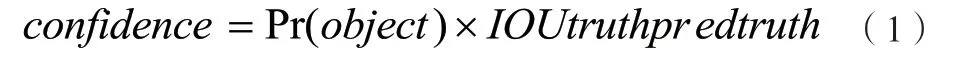
由于算法存在著高分類準確率和低定位準確率,我們需要將YOLOv3算法的預測框輸出信息中加入顯示預測框準確程度的指標,在網絡訓練過程中指導網絡學習預測更加準確的預測框,從而降低YOLOv3 算法的定位誤差[2]。可通過建立模型將顯示預測框的中心點坐標和概率輸入設定為x,輸出設定為y,為平均值,用來表示預測框相對位置,為方差,用來表示預測框相對的準確度。模型公式如公式2所示:
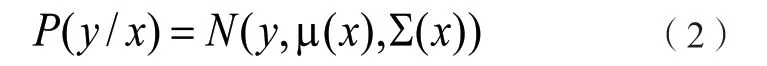
改進后每一個預測框輸出8個位置和尺寸信息,1個有無目標的置信度信息和多個類別信息。在網絡預測層加入對預測框的不確定性回歸使網絡整體性能提升了6.81個百分點,平均交并比提升了5.2%,這證明了加入預測框不確定性回歸減小了YOLOv3算法的定位誤差。為了獲得更高性能的訓練模型,在網絡訓練階段會使用多種有利于網絡訓練的方法。特征提取網絡是由高質量圖像分類的尺度架構截斷而成,主要用于提取圖像特征[3]。將Darknet53結構進行裁剪后,在數據集較少的情況下更加符合實際應用。借鑒上述思想,設計了全新的Darknet-Bird網絡結構。改進后的Darknet-Bird模型層數比原有的Darknet53模型層數少了11層,整體的運算量,網絡深度等都大幅下降。
2.2 YOLOv3改進后和已有的網絡對比
原始的YOLO v3網絡將輸入圖像拆分為SxS網格。如果將對象的中心坐標折疊到網格中,則該網格負責跟蹤對象。由于Darknet網絡引入residual結構,結構優勢遠遠超過傳統VGG-16網絡,優化了冗余的回歸金字塔結構,速度會快很多。增加了Libra R-CNN模型,包含候選區域生成與選擇、特征提取、類別分類和檢測框回歸等多個任務的訓練與收斂。與Faster-RCNN相比,COCO兩步目標檢測任務的LibraR-CNN模型精度超過2%,效果非常明顯。
3 結果展示
將數據集分別通過改進后的YOLOv3網絡和正常的YOLOv3網絡訓練后得出的結果如圖1所示:

圖1 數據集訓練結果對比圖
將本文算法與其他算法的實驗結果比較如下:Faster-RCNN的識別率為89.2%,YOLO v3的識別率為79.6%,本文算法識別率為86.6%。召回率分別為82.3%,80.7%,89.2%;FPS分別為14.7,30,37;用時分別為11.4s,8.3s,6.1s。
4 結束語
目前存在的檢測算法很多,論實用性來說本文經過改進的YOLOv3算法比較符合需求,但仍相差很大,距離實際應用仍有很大距離。由于實際應用的復雜性,還需根據實際應用情況來選擇符合條件的算法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
