基于統計建模的HEVC 快速率失真估計算法
2021-02-01 11:56:20孟翔殷海兵黃曉峰
電信科學 2021年1期
關鍵詞:模型
孟翔,殷海兵,黃曉峰
(杭州電子科技大學通信工程學院,浙江 杭州 310018)
1 引言
隨著各種對高清視頻的需求,JCT-VC 提出了新一代高效視頻編碼(HEVC)標準[1],其采用高級編碼工具,包括基于四叉樹的編碼單元(coding unit,CU)、變換單元(transform unit,TU)以及預測單元(prediction unit,PU)。與H.264[2]相比,在相同圖像質量情況下,HEVC 可以節省高達50%的比特率。
CU/PU/TU 的組合方案可以大大提高編碼效率,但是基于率失真優化(rate distortion optimization,RDO)[3]的模式決策都需要為大量候選模式進行RDO 成本計算,其中涉及前向變換、量化、逆量化、逆變換和熵編碼,這會造成極大的計算復雜度,阻礙了有效并行技術,導致硬件實現效率降低。
一些學者針對如何減少碼率和失真的計算復雜度問題展開研究,Zhao 等[4]提出廣義高斯分布模型來估計碼率,使用在量化中丟掉的比特來估計失真;Tu 等[5]和Wang 等[6]采用量化系數之和與其對應系數坐標來估計碼率;Liu等[7]提出一種基于二元分類的線性模型來估計碼率。Sun 等[8]嘗試簡化RDO 過程,使用變換系數來估計碼率和失真,Chen 等[9]和Sharabayko等[10]采用信息熵來估計碼率。考慮到硬件資源,一些學者提出了有利于硬件實現的快速RDO 算法[11-14],雖然節省了大量的硬件資源,但是算法過于簡單造成了嚴重的性能損失。現有工作并未充分探索熵編碼特性,這會導致壓縮質量顯著下降[15]。
本文的主要貢獻如下:對每個語法元素進行碼率分析,并根據結果建立碼率模型;提出一種加權量化系數,能夠較好地反映碼率信息;采用建模的方式估計頭信息碼率;從變換域建模估計失真,避免多余的重構過程;避免了上下文概率狀態的實時更新,有利于硬件實現。
2 碼率與失真估計算法
HEVC 原始的碼率與失真計算流程如圖1 所示,其中熵編碼技術會涉及上下文狀態的實時更新,系數之間產生較強的依賴性,這不利于硬件并發的實現并會產生很大的編碼復雜度,失真計算會經過冗長的重構過程,進一步加劇了編碼的復雜性。
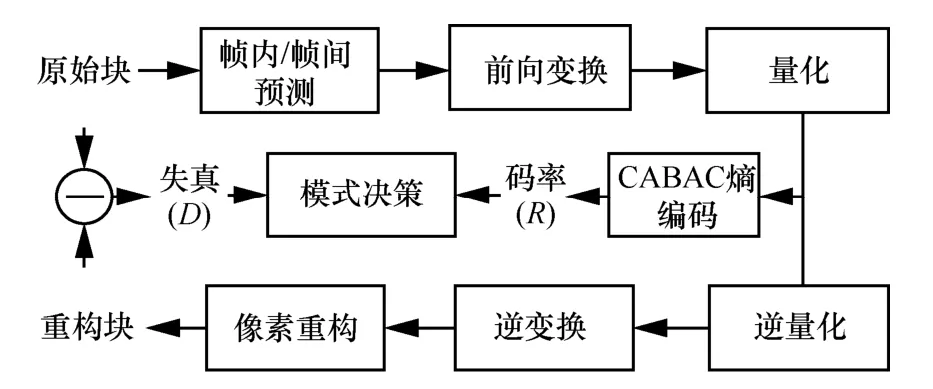
圖1 HEVC 原始碼率失真計算流程
為了簡化編碼的復雜度,采用碼率與失真預估的方式來替代原有的計算過程。引入碼率失真算法后的計算過程如圖2 所示,可以看出碼率失真預估算法大大簡化了原始HEVC 算法的流程,同時避免了上下文概率狀態的實時更新和冗長的重構過程,更有利于硬件并發與流水線技術的實施。

圖2 引入碼率失真算法后的計算過程
在RDO 過程中,碼率一般由兩部分組成:

其中,Rhead表示編碼頭信息所需碼率,Rres代表編碼量化系數所需碼率。在編碼量化系數時,需要編碼多個語法元素。
首先,變換單元會被分為若干個4×4 大小的系數塊組(coefficient group,CG),按反向掃描順序首先掃描到的非零系數為最后一個非零系數位置(last coefficient position,LCP),編碼器需要對LCP 信息進行編碼,然后對每個CG 進行判斷,代碼子塊標志(code sub block flag,CSBF)表示該 CG 內是否存在非零系數,有效系數標志(significant coefficient flag,SCF)表示當前系數是否非零,系數符號標志(coefficient sign flag,CSF)表示當前系數是否為正,前8 個非零系數中,系數大于1(greater than 1,G1)表示當前系數絕對值是否大于1,對于第一個大于1 的系數,系數大于2(greater than 2,G2)表示該系數絕對值是否大于2,最后系數剩余部分(remaining,RM)會被編碼。
為了更加直觀地分析碼率,本文統計了在不同TU 大小和不同量化參數(quantization parameter,QP)下,各個語法元素所占的碼率比重,如圖3 所示,編碼模式為隨機訪問(random access,RA)模式,可以看出,在TU 4×4 和TU 8×8 大小下,LCP 語法元素占有較大比重,分別為32.2%與25.8%,G1 與CSF 語法元素碼率占比較為均勻,SCF 碼率綜合占比最大,因此如何著重分析碼率占比較大的語法元素非常關鍵。
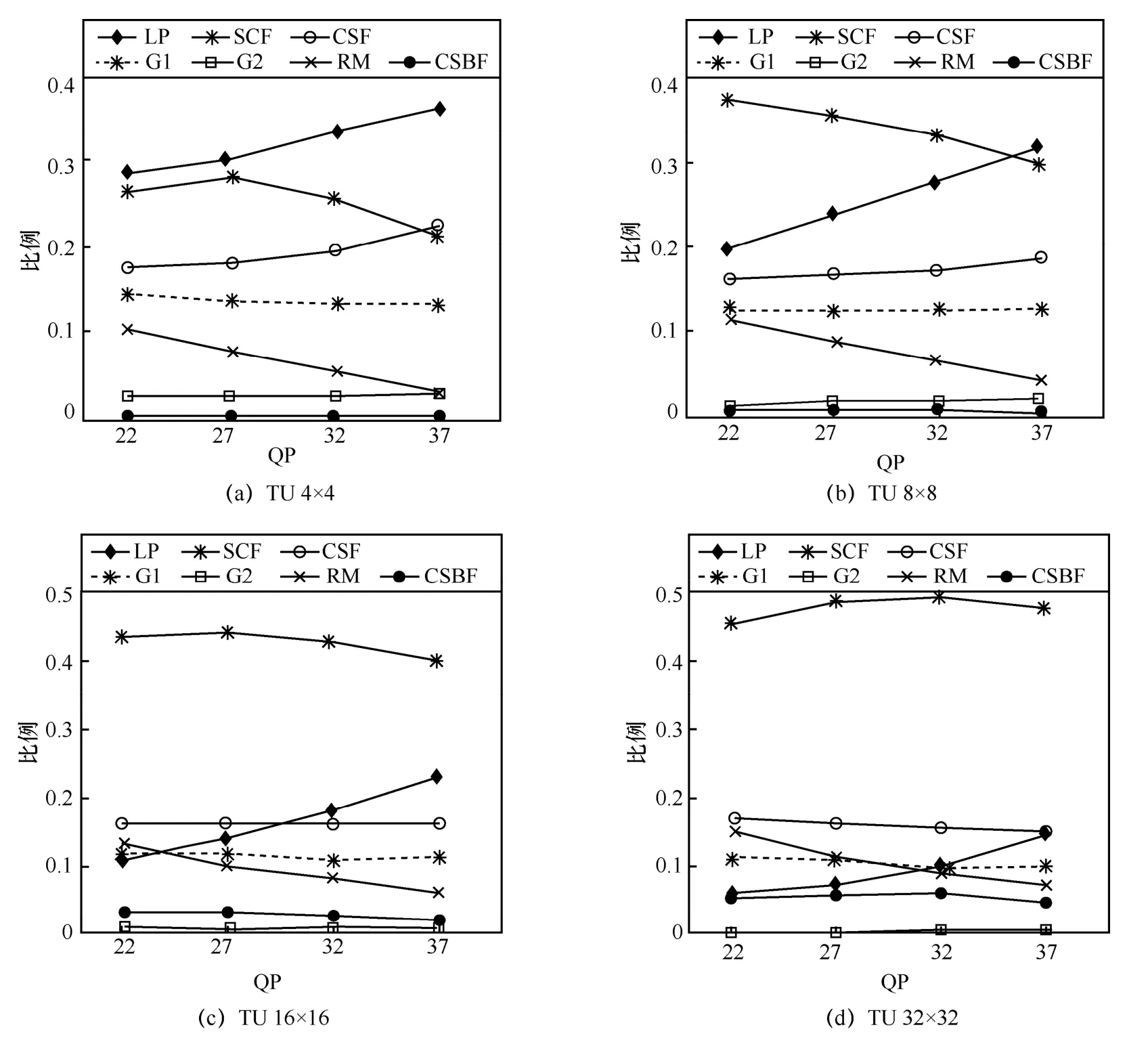
圖3 TU 級別下各語法元素碼率比重
3 頭信息碼率預估
3.1 幀間預測跳過標志的碼率估計
跳過模式是合并模式的一種特殊情況,其CU 內不包含任何殘差信息。對于每個單元,CU跳過標志被用來表示該CU 是否為跳過模式。其根據相鄰CU 跳過標志的不同會使用3 種上下文模型。本文實驗發現跳過標志所消耗的碼率均值在不同QP 下有著較強的線性關系。當相鄰單元均為非跳過模式時,碼率與QP 之間的關系如圖4 所示。

圖4 跳過標志碼率與QP 的關系
其中,R_0 和R_1 分別表示編碼0(非跳過模式)和1(跳過模式)所消耗的碼率。實驗測試環境為RA 編碼模式,測試序列為BasketballPass,測試幀數為30。圖4 中的×表示各QP 下碼率消耗的平均值。事實上,隨著QP 的增加,CU 更有可能被編碼為跳過模式。因此,編碼1 消耗的比特逐漸減少,編碼0 消耗的比特逐漸增加。
因此可以根據QP 進行建模,式(2)中定義了跳過標志的碼率估計模型。
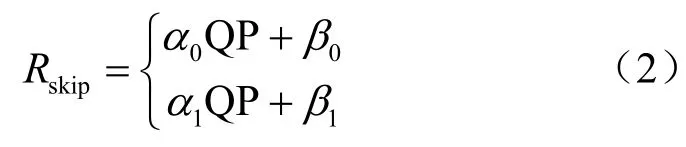
其中,0α與0β表示編碼0 時的模型系數,1α與1β表示編碼1 時的模型系數,在相鄰單元都為非跳過模式時,0α=0.016 89,0β=0.183 3,1α=?0.107 3,1β=5.814。當相鄰單元只有一個為跳過模式或都為跳過模式時,其碼率模型可以采用相同的方法分析。
3.2 預測模式的碼率估計
在頭文件碼率中,編碼預測模式所消耗碼率占有較大比例,對亮度塊來說,最優預測模式從兩類中選出,一類是來自相鄰單元的3 種高概率模式(most probability mode,MPM),另一類為低概率模式(low probability mode,LPM)。prev_intra_luma 會被用來描述該模式是否為MPM模式,與跳過標志建模類似,QP 與碼率關系如圖5所示。
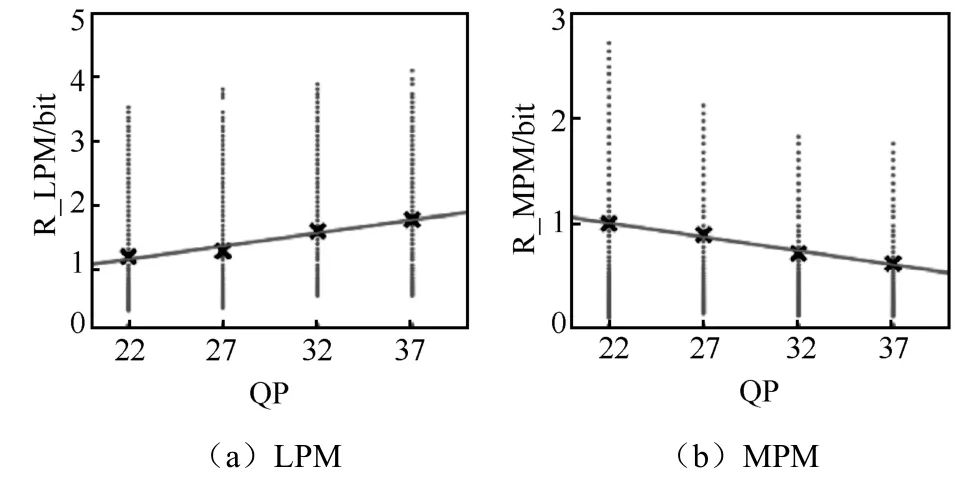
圖5 預測模式QP 與碼率的關系
最后該部分模型如式(3)所示:
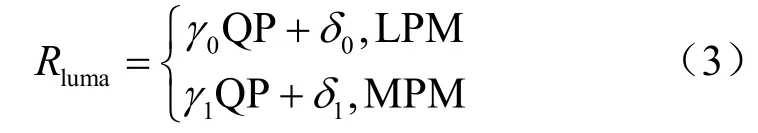
其中,0γ=0.041 73,0δ=0.138 4,1γ=?0.026 8,1δ=1.578。
對于色度塊,從5 個候選模式中選擇最佳模式。intra_chroma_pred_mode 用于描述最佳模式是否與最佳亮度模式相同,該部分建模類似于prev_intra_luma。
4 殘差系數碼率估計
4.1 基于加權量化系數的量化系數和
在現有工作中,Sheng[16]采用量化系數總和(sum quantized coefficient,SQC)作為系數部分碼率估計的特征。但是,當TU 的SQC 相同時,其碼率消耗會有較大的差異。造成這一誤差的原因之一是:在編碼過程中,上下文概率模型轉換會導致嚴重的系數間串行依賴。為解決此問題,本文提出加權量化系數總和(sum weighted quantized coefficient,SWQC)。
在圖3 中,SCF 語法元素總體比其他語法元素占據更大的比例。因此,本文重點分析因編碼SCF 語法元素而產生的系數依賴性。實際上,SCF的上下文模型選擇受許多因素影響,包括當前塊是否為亮度塊、下方和右側的CSBF 值等。因此,本文將CG 分為7 類,如圖6 所示。

圖6 加權量化系數的分類方法
在圖6 中,CSBF(0,0)代表下方和右方CG的CSBF 值均為0。TU 4×4 為第1 類。對于第一個CG,存在DC 系數并且為低頻區域,非零系數多于其他CG,因此將第一個CG 分為第2 類。最后一個非零CG 具有LP 語法元素,分為第3 類。根據下方和右方CSBF 取值分為第4、5、6、7 類。
本文使用線性回歸方法確定權重,使用CG級別碼率進行訓練。不同組將獲得不同的權重,加權量化系數總和累積作為TU 級碼率估計的特征。第3 類中有一個特殊情況,最后一個非零CG具有LP 語法元素,其碼率消耗主要來自LP 信息,為了簡化算法,將第3 類的權重設置為1。該部分碼率模型如式(4)所示:

其中,W kj代表權重系數,k表示由圖6 確定的CG 類別,Lij代表量化系數,N為TU 塊大小。在QP 為32時,各TU 大小下Rwqc與碼率之間關系如圖7 所示。

圖7 TU 級別加權量化系數總和與碼率的關系
權重系數從序列BasketballPass 獲得。將其應用于序列BQsquare,其與TU 級別碼率的相關系數(R2)與均方差(MSE)見表1,其中擬合方式均為線性擬合,擬合公式為y=ax+b,其中a、b為模型參數。可以看到SWQC 比SQC具有更小的均方差和更高的相關系數。這證明了使用SWQC 在碼率估計方面將獲得更高的精準度。

表1 均方差與相關系數
4.2 位置參數以及其他特征參數
在熵編碼中,高概率事件將消耗較少的比特,而低概率事件將消耗較多的比特。經過變換、量化等步驟后,非零系數出現在低頻區域的概率要大于高頻區域。因此,碼率消耗將隨著系數分布的不同而有著較大的變化。本文定義ηc為CG 級別最后一個非零系數的正向掃描位置。當ηc較小時,表示非零系數分布在低頻區域。ηz表示CG內第一個與最后一個非零系數之間的零系數個數。當ηz較小時,表示非零系數分布更加集中。這兩個特征可以很好地描述系數的分布,該部分碼率定義如下:

QP 為32 時,其與碼率的關系如圖8 所示。
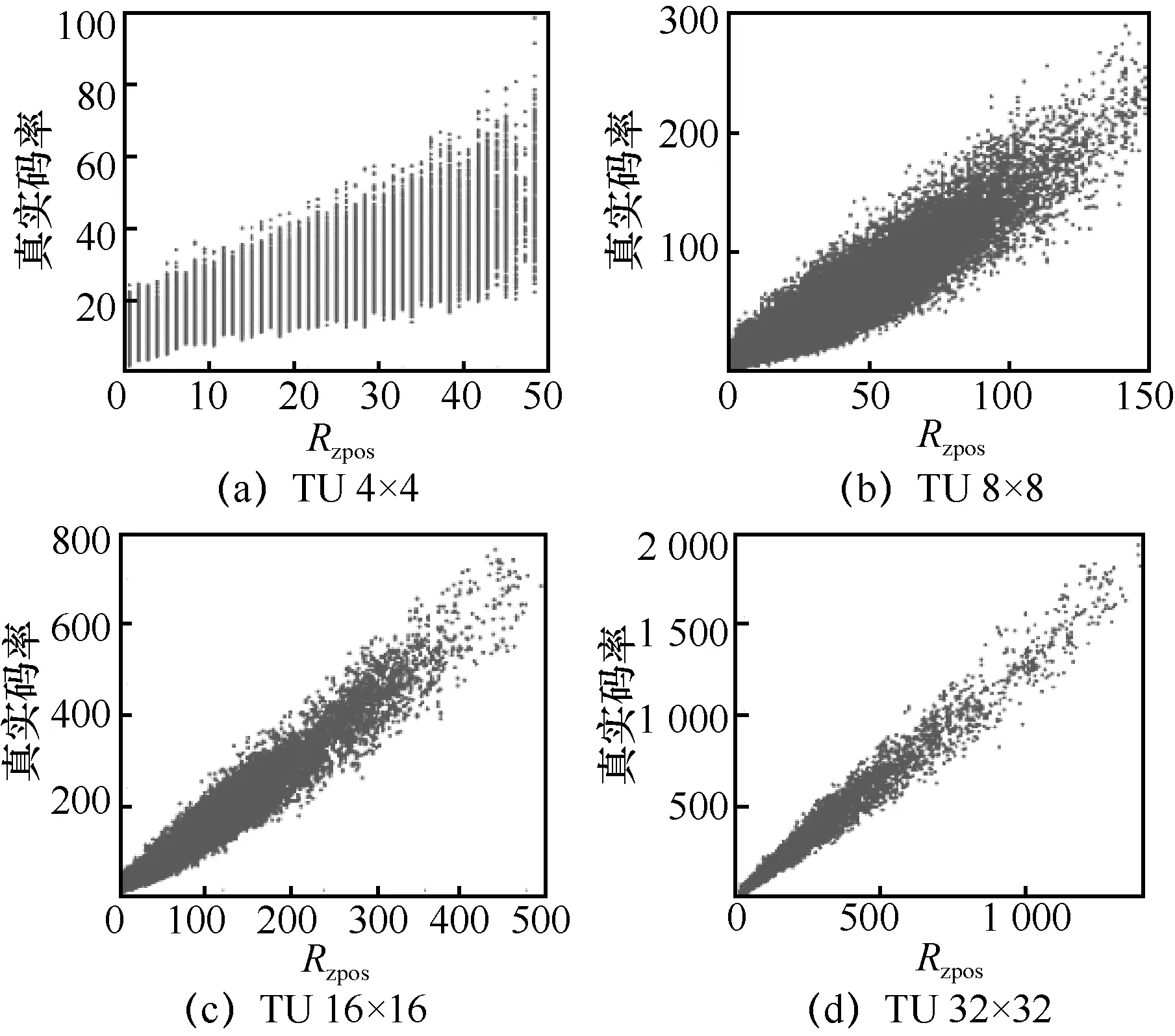
圖8 TU 級別位置信息與碼率的關系
在TU 4×4 與TU 8×8 兩種情況下,編碼LCP位置信息時,其碼率占比較大,由圖3 可知其占比分別達到32.2%與25.8%,但是TU 16×16 與TU 32×32情況下,其碼率占比只有16.7%與9.1%。在考慮到模型復雜度與硬件資源的情況下,本文只針對TU 4×4 與TU 8×8 情況考慮LCP 位置信息,LCP 語法元素碼率組成如下:

其中,Rpre表示前綴碼,采用常規編碼模式;Rsuf為后綴碼,采用等概率編碼模式;本文定義特征bη為前綴碼和后綴碼的總碼元個數,并使用它來估計編碼LCP 信息所消耗的碼率。
此外,在不同TU 大小下,各個語法元素碼率占比波動較大,但CSF 語法元素卻很平穩,占比平均為17.1%,因為該語法元素采用等概率編碼方式,因此本文定義特征nη為非零系數個數并納入考慮范圍。
4.3 最終碼率模型以及碼率估計算法實現過程
最終模型如下:

其中,bη只有在TU 大小為4×4 與8×8 的情況下才會使用;0θ~4θ為模型參數,由線性回歸訓練所得到。圖9 為QP 等于32 時,REst與真實碼率之間的關系,測試序列為BasketballPass。可以看出,兩者之間有著很強的線性關系。
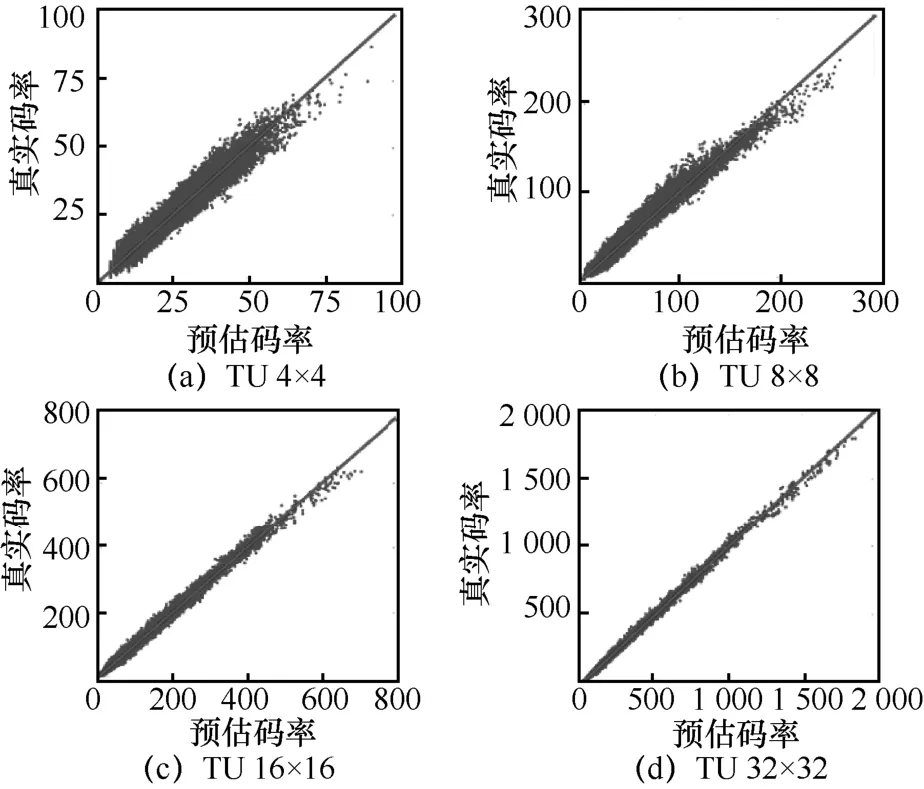
圖9 預估碼率與真實碼率的關系
碼率估計算法流程如下。
輸入量化系數矩陣L,4×4 權重矩陣kW 。
輸出預估碼率REst。
說明量化系數矩陣L尺寸取決于當前TU塊尺寸,取值范圍為4×4、8×8、16×16、32×32。K取值范圍為1~7,由圖6 所示方法決定。步驟3中C為系數組矩陣,大小為4×4。
步驟1根據式(2)、式(3)計算頭信息碼率。
步驟2遍歷系數矩陣L,確定LCP 位置并計算bη參數。
步驟3當前TU 大小為4×4,計算Rwqc=否則計算
步驟4統計cη參數,同時記錄零系數的個數zη,根據式(5)計算出Rzpos。
步驟5統計非零系數個數nη,遍歷L結束。
步驟6如果TU 尺寸為4×4、8×8,根據式(7)得出REst;否則令ηb= 0,代入式(7)得出REst。
碼率估計算法流程如圖10 所示。
5 失真預估
在HEVC 中,計算量化過程如下:

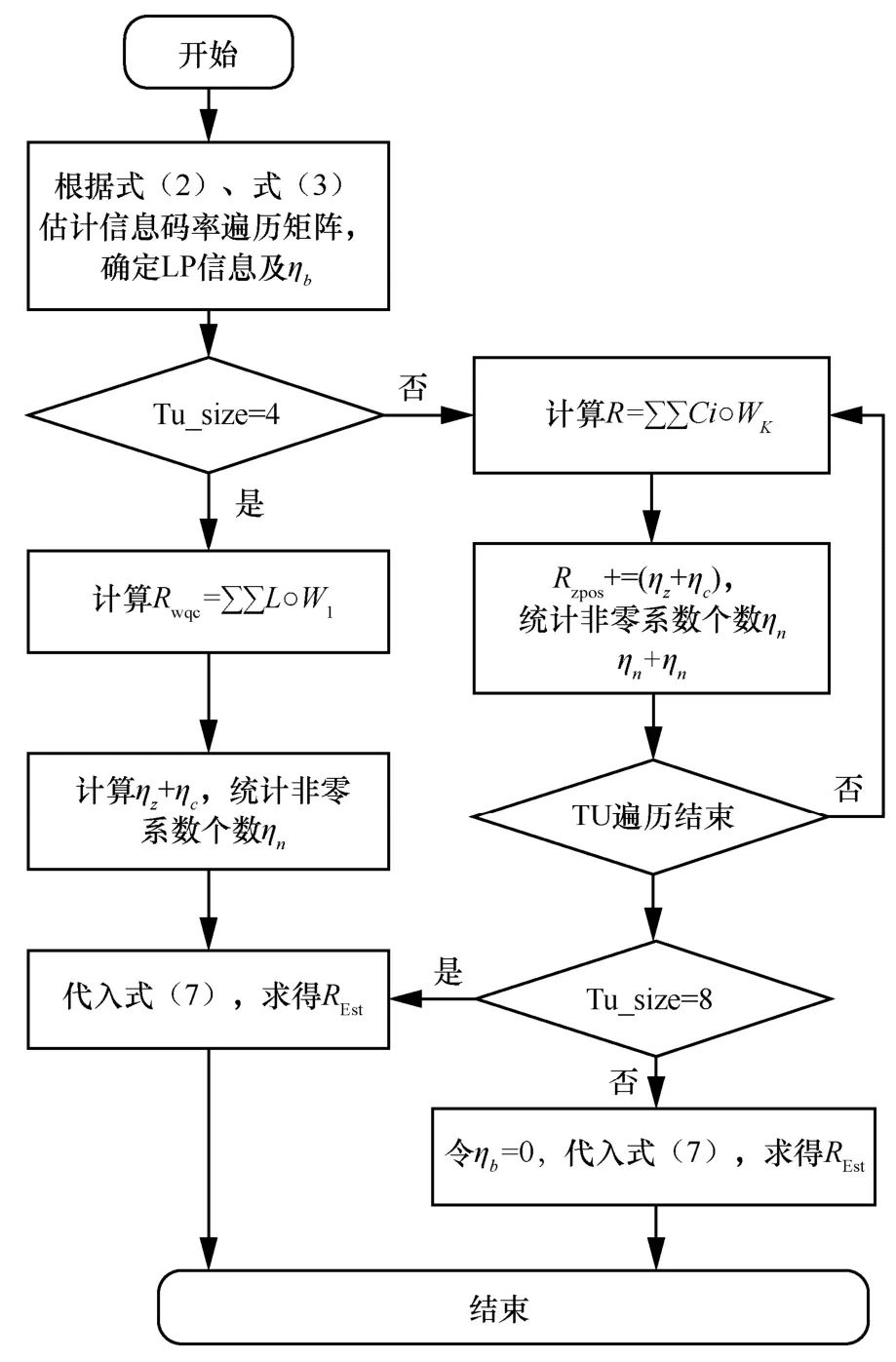
圖10 碼率估計算法流程
其中,Q ij為量化值,y ij為變換系數,Sc =2qbits/Qstep是和QP 有關的縮放系數。在變換域中,失真可以由式(9)統計:

其中,y為變換系數,yi為重構后的變換系數。為了簡化重構過程,本文分別定義了原始縮放后系數Pi j=yij×Sc 和近似重構后的變換系數Ti j=Qij?iQBits,并統計了兩者間的差異,定義如下:

因此被縮放后失真近似為:

將式(11)代入式(9):
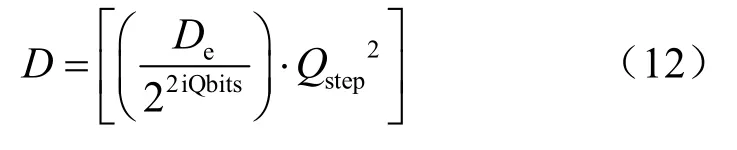
其中,iQbits=qbits+shift,化簡后有:

其中,shift 是與TU 大小有關的偏移量。為了更精準地估計碼率,本文引入與QP 相關的模型參數α(QP)其在QP 取值為22、27、32、37 時分別等于0.86、0.89、0.92、0.95。預估失真與真實失真關系如圖11 所示。
失真估計算法具體流程如下。
輸入量化系數矩陣Q,變換系數矩陣Y。
輸出預估失真DEst。
步驟1遍歷系數矩陣Q,計算Tij=Qij?iQBits,得到近似重構后的變換系數。
步驟2計算dij=(Pij?Qij?iQBits)2,為該系數縮放后失真。
步驟3去除縮放比例,由式(13)得到
步驟4矩陣Q遍歷結束,引入α(QP)模型參數,累加得
由以上可以看出,失真的計算在進行前向變換量化的時候就已經計算完畢,省去了逆變換、逆量化、重構等過程。這種做法雖然忽視了逆量化、逆變換因取整和位移等操作造成的誤差,但是這些誤差的數值很小,在可接受范圍內,同時可以節省大量的時間。從圖11 可以看出,預估失真與真實失真有著很強的線性關系,這也證明了本文失真估計算法的優越性。
6 實驗結果分析
為了評估文中所提出的快速碼率失真估計算法,采用HEVC 參考代碼HM16.0 進行實驗,實驗配置為:RA 模式,關閉RDOQ 功能,關閉變換跳過功能,其余均為默認配置。實驗中QP 取值為:22、27、32、37。實驗采用H.265 標準測試序列[17]進行測試,碼率變化率(BD-BR)[18]當作評價指標。
為了衡量計算復雜度的變化,本文定義了時間變化率TΔ 定義如下:

圖11 預估失真與真實失真的關系
其中,TProRDO為本算法進行RDO 過程所消耗的時間,THMRDO為原始HEVC 算法進行RDO 過程所消耗的時間,ΔT為正表示編碼時間的減少,與HM 算法相比,本文快速算法的率失真性能和整體表現見表2。其中,*表示僅使用碼率預估的性能損失,**表示碼率與失真預估的性能損失。表2中還列出了近年來典型的碼率失真估計算法,并做了比較。
與原始HM 算法相比,只使用碼率估計算法,參考文獻[9]的算法BD-BR 總體上升1.32%,本文算法BD-BR 總體上升0.96%,性能提升0.36%,對于有較多細節畫面的視頻序列,例如PartyScene、BQsquare、BasketballPass 和SlideEditing,參考文獻[9]的算法BD-BR 分別上升1.92%、1.68%、1.31%、1.81%,性能損失較為嚴重,本文算法在這些序列下BD-BR 分別上升0.75%、0.43%、0.37%、1.24%,皆優于參考文獻[9]。對于平穩的序列,例如 FourPeople、Johnny 和KristenAndSara,參考文獻[9]算法BD-BR 分別上升1.17%、1.35%、1.57%。同樣地,本文算法BD-BR分別上升1.09%、1.16%、1.12%,因此無論是在具有較多細節還是較為平穩的視頻序列中,本文算法皆優于參考文獻[9]提出的算法。
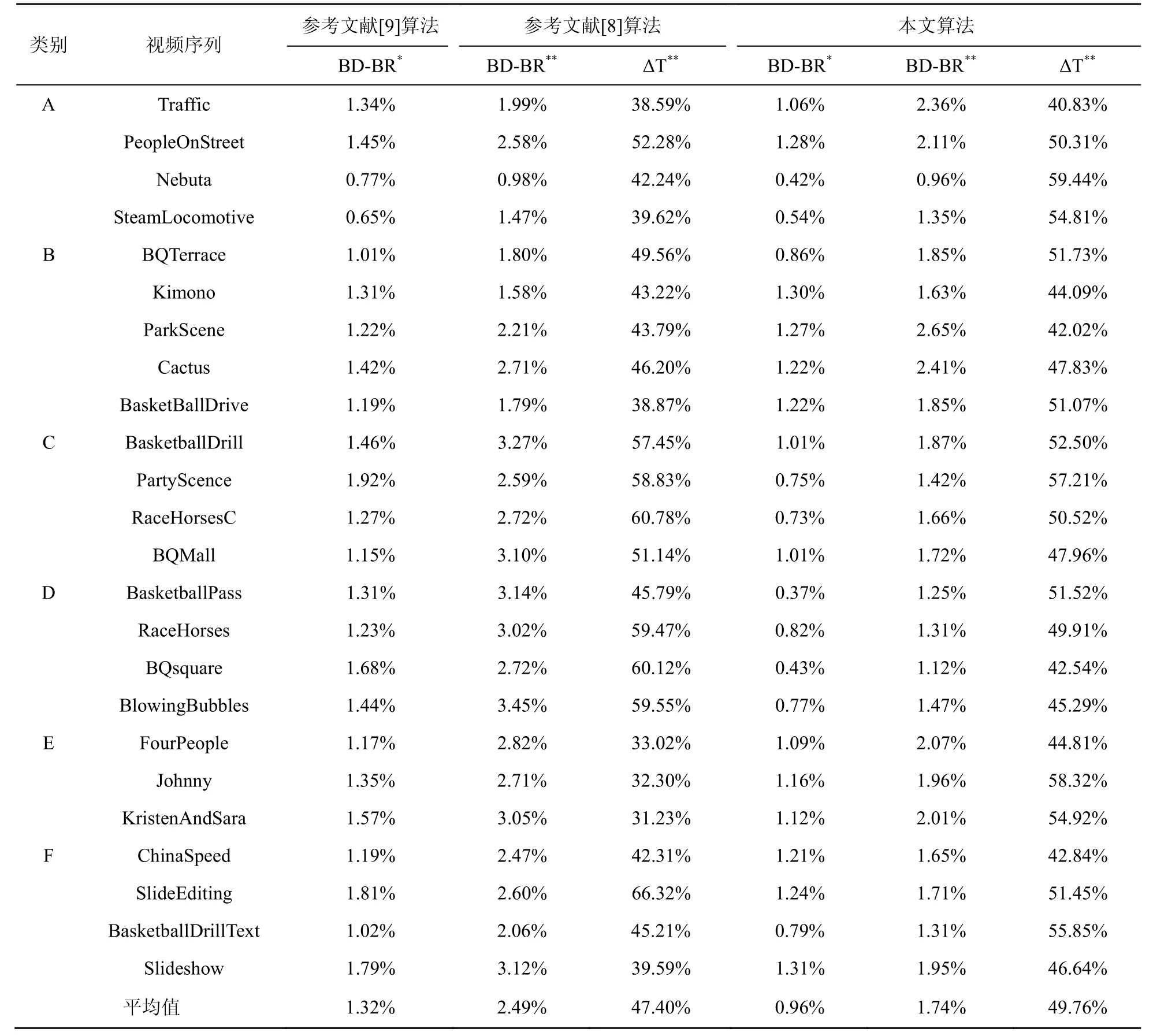
表2 在Random Access 下的模型性能
在同時使用碼率估計與失真估計算法時,相較于原始HM 算法,參考文獻[8]的算法BD-BR總體上升2.49%,同時RDO 時間節省47.40%。對于高分辨率的視頻序列,如Traffic、Nebuta、Kimono,其BD-BR 分別上升1.99%、0.98%、1.58%,性能損失較低;對于低分辨率的序列,即D 類視頻序列,其BD-BR 上升分別為3.14%、3.02%、2.72%、3.45%,性能損失較大,這說明參考文獻[8]的算法在高分辨率的序列上有著較好的性能。在時間節省方面,參考文獻[8]的算法在序列SlideEditing 和RaceHorses 可以達到66.32%和60.78%,但是在Johnny 和KristenAndSara 序列下,其時間節省僅為32.30%與31.23%,最大值與最小值之間相差35%,這說明參考文獻[8]的算法時間節省并不均勻,其算法不具有較強的普適性。本文在同時使用碼率與失真估計算法時,BD-BR 總體上升了1.74%,RDO 時間節省49.76%,相較于參考文獻[8]的算法,性能有0.75%的性能提升,同時多獲得了2.36%的時間節省。對于高分辨率的視頻序列,如Traffic、Nebuta、Kimono,其BD-BR分別上升2.36%、0.96%、1.63%;在低分辨率視頻序列(D 類)下,本文算法BD-BR 僅上升1.25%、1.31%、1.12%、1.47%,這證明了本文算法有著更好的率失真性能。在序列Nebuta 中,本文可以達到59.44%的RDO 時間節省,為測試序列中的最大值;在序列Traffic 中可以達到40.82%的RDO時間節省,為最小值,其相差大約19%,與參考文獻[8]算法的35%相比,可以證明本文算法節省時間更加均勻,有著更好的普適性。
在A 類高分辨率視頻序列中,由于編碼每幀圖像所需碼率較多,會進行較多的RDO 模式決策過程,這意味著使用碼率失真估計算法會產生較大誤差,本文算法在A 類視頻序列性能平均損失僅為1.69%。在分辨率較低的D 類序列中,在RA 模式下,編碼每幀所需的碼率較少,但這也意味著更多的系數被量化為0,導致失真計算會有較大的誤差,本文算法在D 類序列上平均損失僅為1.28%,表2 數據表明在各個分辨率下,都有著優于參考文獻[8]算法和參考文獻[9]算法的性能表現。圖12~圖15 為在各個分辨率下的視頻序列R-D 性能曲線,對比了原始的HM16.0 算法和本文的碼率失真估計算法,可以看出本文的算法性能在各個分辨率下都極其接近原始HM 算法的性能,這也證明了本文算法的優越性。

圖12 序列ParkScene(1 920 dpi×1 080 dpi)的R-D 曲線
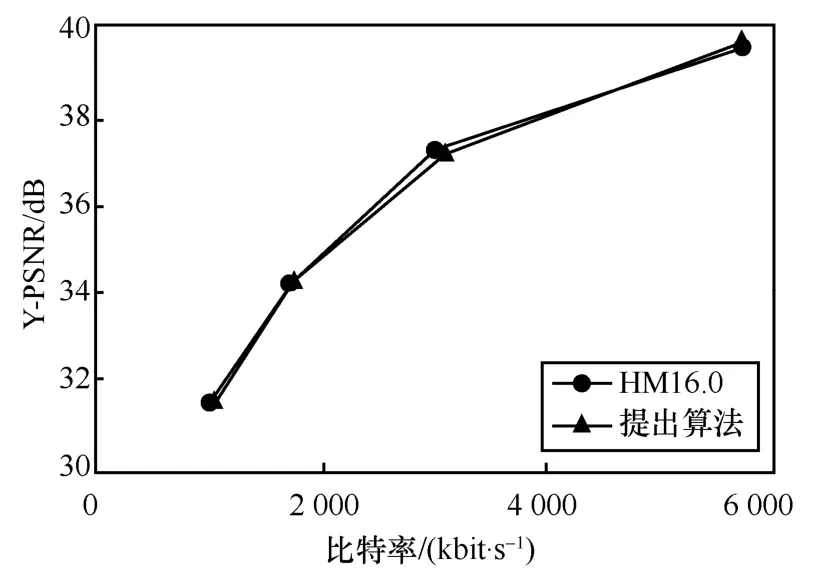
圖13 序列BQMall(832 dpi×480 dpi)的R-D 曲線

圖14 序列BQsquare(416 dpi×240 dpi)的R-D 曲線
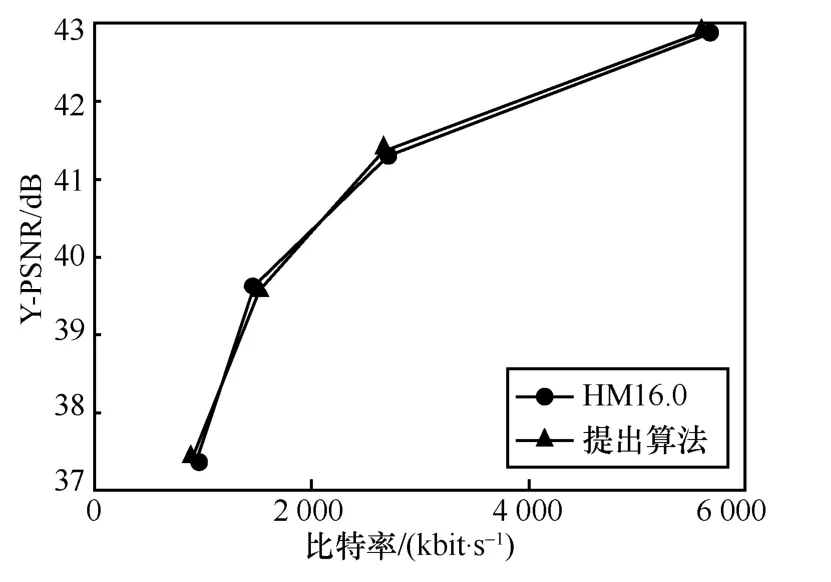
圖15 序列Johnny(1 280 dpi×720 dpi)的R-D 曲線
7 結束語
本文針對HEVC 率失真優化過程中復雜的碼率與失真計算問題,提出一種快速碼率失真估計算法。通過實驗證明,本文算法與目前典型算法而言,在性能與時間節省方面都有著較大的提升,后續工作主要有兩部分:一是對權重系數進行進一步優化,探索其與位置參數的動態關系,使得碼率模型能夠更精準地估計碼率;二是探索碼率與失真模型在全幀內編碼中的應用,找出其與幀間編碼參數之間的差異,使得模型能夠適應更復雜的編碼場景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
