一種龍芯平臺上多媒體指令優化時地址非對齊問題的解決方案
2021-02-04 13:51:46李正平程洋洋
小型微型計算機系統 2021年1期
李正平,程洋洋
(安徽大學 電子信息工程學院, 合肥 230039)
1 引 言
現代計算機中內存空間都是按照byte劃分的,對于內存中的基本數據類型的變量,如果它們的起始地址能夠被其自身的大小整除,則將該變量稱為自然對齊數據,反之稱為非對齊數據[1].
不同硬件平臺在非對齊數據的處理方面存在很大差異[2].如以MIPS和ARM為代表的精簡指令集計算機對地址要求較為嚴格,需要地址自然對齊;而以X86為代表的復雜指令集計算機就不需要.通常來說,若不按照適合其平臺要求對數據存放進行對齊,會在存取效率上帶來損失.比如在MIPS平臺上,如果一個int型數據(假設為32位系統)存放在4的整數倍的地址上,那么一個讀周期就可以讀出;而如果存放在非4的整數倍的地址上,就可能會需要2個讀周期,并對兩次讀出的結果的高低字節進行拼湊才能得到該int型數據,這顯然會在存取效率上下降很多[3].在龍芯平臺多媒體指令優化時,優化函數一旦訪問非對齊數據會嚴重抵銷優化函數的性能提升,影響程序的執行效率.因此,保證優化函數在數據非對齊時也能有較高的性能是一個需要解決的問題.
針對非對齊數據存在的問題,許多學者進行了大量研究,提出了許多行之有效的解決方案.其中,IBM公司的Eichenberger A E[4]提出了一種在內存非對齊的情況下對循環進行矢量化處理的方案,即自動重組寄存器中的數據,以滿足硬件提出的對齊要求;浪潮(北京)電子信息產業有限公司[5]在初始化時就把非對齊地址根據映射表中記錄的偏移量糾正為對齊地址,這樣上層應用看到的就全是對齊地址.以上介紹的是基于軟件層面的解決方案,國防科學技術大學余成龍[6]從硬件上對高性能應用程序的訪存結構進行建模,設計并實現SIMD分離緩沖行非對齊訪存結構與雙體cache非對齊訪存結構來提高訪存性能等.
以上所提到的方法在非對齊訪存問題上都有一定的效果和意義[7],解決方法是由問題決定的,都服務于各種針對性的問題,本身無優劣之分.因此,具體問題還要具體分析[8].針對在龍芯平臺上多媒體指令優化過程中遇到的非對齊訪存造成優化函數性能下降的問題,本文提出了接口自適應擇優算法.該算法在軟件層面上利用龍芯平臺在指令集層面上設計的非對齊存取指令,先為這些指令設計非對齊訪存接口,并在源代碼中根據程序上下文環境選擇合適的非對齊訪存接口去存取數據.最后,以LibYUV庫的多媒體指令優化結果驗證了所提算法在數據非對齊的情況下依舊有較高的性能.
2 龍芯多媒體指令優化中非對齊訪存問題
龍芯多媒體指令是一套支持基于字節、半字、字以及雙字整數并行操作的指令集,能夠加速多媒體運算.龍芯多媒體指令直接使用FPU 的浮點寄存器(64 位,32 個)作為多媒體指令寄存器來實現整數的并行操作,因此通常用存取浮點類型數據的指令來存取需并行計算的整數[9].
浮點包括單精度和雙精度兩種類型,分別使用4個和8個字節表示.在龍芯平臺下分別使用lwc1/swc1、ldc1/sdc1(浮點存取指令)來存取浮點類型數據,其中 lwc1/swc1要求目標數據必須是4字節對齊,ldc1/sdc1要求目標數據是8字節對齊.大多數情況下,數據也確實是按照上述一樣對齊的.但有時可能會錯誤的使用ldc1/sdc1來存取4字節對齊的浮點數據,有時甚至傳遞進函數處理的多媒體數據流就是非對齊的,這樣硬件會拋出異常,程序會中斷執行;通過操作系統內核響應alignment fault異常進入異常處理流程中,把對非對齊的數據訪問操作轉換為通過多次訪存操作和拼接操作的過程.這個過程由于上下文切換以及引入的多次訪存和拼接操作必然大幅影響程序的執行效率[10].

圖1 gslwrc1/gslwlc1指令的數據加載過程Fig.1 Data loading process of gslwrc1 / gslwlc1 instruction
對于以上問題,龍芯自定義通用指令gslwrc1/gslwlc1、gsswrc1/gsswlc1、gsldrc1/gsldlc1、gssdrc1/gssdlc1分別在地址非對齊的情況下存取需并行操作的數據.其中gslwrc1/gslwlc1表示從非對齊的內存地址空間中取字的最低/最高有效部分存放到浮點寄存器中,gsswrc1/gsswlc1表示存儲浮點寄存器中字的低/高有效部分到非對齊的內存地址空間.gsldrc1/gsldlc1作用同gslwrc1/gslwlc1,gssdrc1/gssdlc1作用同gsswrc1/gsswlc1,只是操作的目標數據是雙字.
現以gslwrc1/gslwlc1指令為例對非對齊訪存指令的數據加載過程做出說明.Gslwlc1指令用以從非對齊的內存地址空間中取字W的最高有效部分存放到浮點寄存器中,這個地址在內存中是以任意字節為邊界開始的.浮點寄存器$f0中字的最低有效部分(右)則維持不變,浮點寄存器$f0的63..32位是不確定的;同理,gslwrc1指令用以從非對齊的內存地址空間中取字的最低有效部分存放到浮點寄存器中,兩條指令結合使用才能完成從一個非對齊地址讀取一個字數據.如圖1所示,gslwlc1在這種情況下只加載一個字W的最高字節到浮點寄存器$f0中,字W的余下低3個字節則由gslwrc1完成加載.
3 非對齊訪存接口和接口自適應擇優算法
龍芯下現有的訪存接口名稱分別為:_mm_load_si64、_mm_store_si64、_mm_load_si32和_mm_store_si32.其中,_mm_store_si64的接口實現如下:
extern __inline void FUNCTION_ATTRIBS
_mm_store_si64(__m64 *dest,__m64 src)
{
asm("sdc1 %1,%0 "
:"=m" (*dest)
:"f" (src)
:"memory"
);
}
使用龍芯多媒體指令技術進行函數優化時,需要函數參數地址是自然對齊的,使用現有訪存接口即可完成數據的加載和儲存操作.但有時候會出現多媒體指令優化后函數性能不提升反而下降的情況,這一般跟函數訪問了非對齊地址有關.為了解決這個問題,我們設計了新的訪存接口.
3.1 非對齊訪存接口
對于確定為非對齊的參數地址,利用龍芯非對齊訪存指令,本文分別定義了32位/64位的非對齊訪存接口,用以在多媒體指令優化時地址非對齊的時候使用,非對齊訪存接口名稱分別為:_mm_loadu_si64、_mm_storeu_si64、_mm_loadu_si32和_mm_storeu_si32.其中,_mm_storeu_si64接口實現如下:
extern __inline void FUNCTION_ATTRIBS
_mm_storeu_si64(__m64 *dest,__m64 src)
{
asm("gssdlc1 %1,7+%0 "
"gssdrc1 %1,%0 "
:"=m" (*dest)
:"f" (src)
:"memory"
);
}
非對齊訪存接口雖然解決了非對齊訪存性能下降的問題,但兩條非對齊存取指令相對單條浮點存取指令來說執行效率依舊較低.有時開發人員無法確定待訪問地址是否對齊,便無法確定使用現有對齊訪存接口還是非對齊訪存接口.因此需要根據程序上下文,自動選擇合適的指令接口.基于此,又設計了自適應多媒體指令訪存接口:_mm_gsload_si64、_mm_gsstore_si64、_mm_gsload_si32和_mm_gsstore_si32.在提高多媒體指令優化程序的性能的同時,可以防止花費較長的時間來判斷待訪問地址所使用的訪存指令.其中,_mm_gsstore_si64的接口實現如下:
extern __inline void FUNCTION_ATTRIBS
_mm_gsstore_si64(__m64 *dest,__m64 src)
{
if (!(((long)dest) & 7)) {
asm("sdc1 %1,%0 "
:"=m" (*dest)
:"f" (src)
:"memory"
);
} else {
asm("gssdlc1 %1,7(%0) "
"gssdrc1 %1,0(%0) "
:
:"r" (dest),"f" (src)
:"memory"
);
}
}
3.2 接口自適應擇優算法
非對齊訪存接口可以解決非對齊問題,自適應多媒體指令訪存接口用以解決兩條非對齊指令性能偏低的問題.因此,在具體實踐過程中,若確定地址是4字節或8字節對齊的情況下使用現有訪存接口:_mm_load_si32、_mm_store_si32、_mm_load_si64和_mm_store_si64;若不確定地址是否對齊的情況下,且同一地址只進行了一次訪存操作則使用自適應多媒體指令防存接口:_mm_gsload_si32、_mm_gsstore_si32、_mm_gsload_si64和_mm_gsstore_si64;若不確定地址是否對齊且同一地址進行了多次訪存操作則需對地址進行判斷,若地址是4字節或8字節對齊,使用接口_mm_load_si32、_mm_store_si32、_mm_load_si64和_mm_store_si64,否則使用接口_mm_loadu_si32、_mm_storeu_si32、_mm_loadu_si64和_mm_storeu_si64.具體算法流程如圖2所示,通過上述操作可使優化函數在地址非對齊時不會出現性能大幅下降的情況.

圖2 接口自適應擇優算法流程圖Fig.2 Flow chart of interface adaptive optimization algorithm
4 LibYUV實驗結果和分析
LibYUV是Google開源的實現各種YUV與RGB色彩空間之間相互轉換、旋轉、縮放的庫,并且自帶豐富的測試用例用于保證各個平臺的優化在功能和性能上的可靠性.在保證龍芯多媒體指令優化功能測試正確的前提下,利用其性能測試來評測多媒體指令優化提升的效果[11].在這一過程中,發現在使用龍芯多媒體指令優化后,大多數測試用例普遍獲得了不錯的性能提升;但有些測試用例出現了性能沒有提升,反而急劇下降的情況[12].經過GDB逐條指令分析,確定了這與程序訪問非對齊地址有關,性能下降的測試用例后綴名帶有_unaligned標記,但一些不帶_unaligned標記的測試用例有時也會出現非對齊訪存性能下降問題.從源代碼中分析測試用例的設計,_unaligned標記的測試用例故意移動了指向待操作數據的指針,造成起始地址偏移到非對齊地址上,這是設計者為了LibYUV的可移植性和可靠性做出的特殊處理.
利用LibYUV的性能測試手段,表1隨機列舉了若干函數與其對應的測試用例在3種情形下的性能統計數據,數值越小代表性能越好.其中“原始函數”表列代表函數未優化前測試用例的執行時間,它是計算性能提升比例的基準值.

(1)
表1中“優化函數應用算法前/提升比例”表列是使用多媒體指令對函數進行優化后測試用例的執行時間,以及與基準值的比例,負號表示性能下降,計算方式如公式(1)所示.需要注意的是此處使用多媒體指令進行函數優化,優化時按通用做法使用現有訪存接口.如果數據是對齊的,優化函數會有普遍的性能提升;如果測試用例需要訪問非對齊地址上的數據,會造成優化函數性能的下降.
表1中“接口自適應擇優算法/提升比例”表列表示在多媒體指令優化的基礎上,應用接口自適應擇優算法,把先前多媒體指令優化的訪存接口按算法邏輯進行簡單替換.即若能確定數據是對齊的,多媒體指令優化函數不需要改變,依舊使用現有訪存接口;若不確定數據是否對齊且只執行一次訪存操作,把訪存接口替換為自適應多媒體指令訪存接口;若確定數據是非對齊的,把訪存接口替換為非對齊訪存接口.
圖3用折線圖的形式描述了表1中性能統計數據的變化情況.圓點標記的曲線代表多媒體指令優化函數應用接口自適應擇優算法前,正方形標記的曲線代表在多媒體指令優化的基礎上應用自適應擇優算法.
如圖3所示,圓點標記的曲線普遍在零刻度線以下,9個測試用例中有6個出現了性能下降,即在地址非對齊時多媒體指令優化函數性能非但沒有提升反而普遍低于原始函數的性能.余下的3個測試用例雖然性能得到提升,但提升比例較小,不符合多媒體指令優化的預期收益.優化后的SobelXRow_C函數性能下降最為明顯,下降了1.07倍.可見在龍芯平臺上進行多媒體指令優化,優化函數訪問非對齊數據時會抵消并行計算帶來的性能提升,造成程序性能的下降.
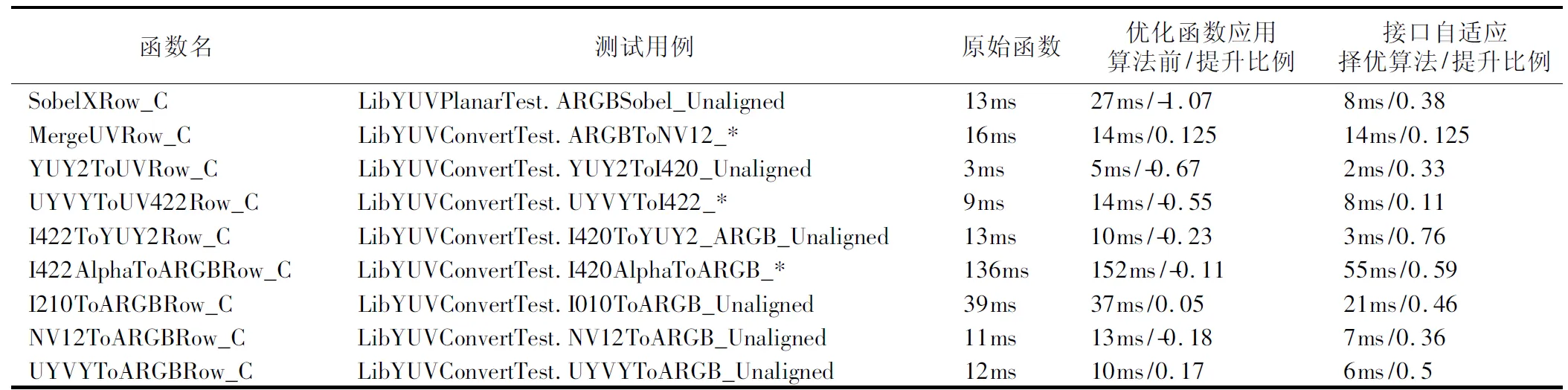
表1 LibYUV的性能統計數據表Table 1 Performance statistics of LibYUV
圖3中正方形標記的曲線全部高于圓點標記的曲線,且所有的數據都為正值,9個測試用例平均有40%的性能提升,比較符合預期,表明了所提算法在數據非對齊的情況下依舊有較高的性能.I422ToYUY2Row_C函數性能提高比例最大,提升76%,9個函數最低的也有11%的性能提升.MergeUVRow_C的優化函數性能在應用自適應擇優算法前后并未變化,說明此函數操作的數據是自然對齊的.

圖3 優化函數應用接口自適應擇優算法前后對比曲線圖Fig.3 Before and after comparison curve of optimization function apply interface adaptive optimization algorithm
在LibYUV庫優化過程中,除了使用多媒體指令技術進行優化外,還增加對非對齊訪存問題的處理,并且針對某些特殊運算進行算法級優化,比如飽和處理、循環展開和盡可能消除乘法運算等,取得了不錯的成果.開發人員在進行多媒體指令優化時,可以考慮使用接口自適應擇優算法,既能提高優化函數的性能,又能保證優化函數在數據非對齊場景下的性能.
5 總 結
論文根據龍芯處理器的特點,為非對齊訪存指令設計調用接口,并提出接口自適應擇優算法,解決了龍芯多媒體指令優化時地址非對齊造成優化函數性能下降的問題.
論文的另一部分工作是對LibYUV庫使用龍芯多媒體指令進行了全面優化,提高了LibYUV在龍芯平臺上的表現能力,相關工作成果已推送至谷歌LibYUV開源社區.在下一步的工作中,要繼續使用龍芯多媒體指令完成其它媒體庫的優化工作,增強國產計算機平臺上對不同多媒體格式的轉換效率.隨著龍芯生態體系的不斷完善以及應用普及的不斷擴大,國產CPU將會迎來更好的明天.
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
房地產導刊(2022年5期)2022-06-01 06:20:14
名師在線·上旬刊(2021年3期)2021-09-10 04:20:48
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
消費導刊(2018年10期)2018-08-20 02:56:28
河南電力(2016年5期)2016-02-06 02:11:40
