一種結合聚集圖嵌入的社會化推薦算法
2021-02-05 03:26:12周林娥游進國
小型微型計算機系統 2021年1期
周林娥,游進國
(昆明理工大學 信息工程與自動化學院,昆明 650500)
1 引 言
隨著互聯網的快速發展,大規模數據的出現,使得用戶需花費太多的時間和精力去選擇自己需要的信息.基于此,推薦系統作為一種“信息推送”的重要方法進入人們的視野并廣泛應用于各種電商及音樂平臺.然而,用戶的需求是不斷變化的且推薦的準確率仍需提升,信息過載問題依然存在.首先,在傳統推薦系統中,大多數用戶通常只是消費很少的項目且一些用戶可能不愿意對消費的商品評價,使得數據稀疏問題更加的突出,其次,由于受利益的驅使,買家可能會對商品進行不真實的打分,比如購買商品時賣家可能會用一些紅包來獲得買家的好評等等.因此,我們需要借助其他信息為用戶提供更加準確的推薦,由于社交網絡的發展和各種社交平臺的出現,可以利用觀察到的社交信息來緩解傳統推薦系統的數據稀疏問題,許多基本方法[1,2]融合了社交關系提高了推薦的準確性,顯示了社交信息納入推薦系統非常重要.為了提高推薦表現最近的工作[3,4]把直接觀察到的社交信息融入到矩陣分解(MF)和貝葉斯個性化排名(BPR)框架中.目前基于社交網絡的推薦仍然存在一些問題:由于垃圾郵件的存在及社交關系的復雜性,使得社交關系帶有噪音,現實世界中顯式的社會關系非常稀疏.另外,社交網絡過大需占據巨大的存儲空間.因而,直接使用原圖推薦存在一定的局限性.
近來,網絡表示學習的出現使得推薦有了進一步的發展,一種利用網絡表示學習進行個性化商品推薦的方法PGE[5],通過分別獲取商品和用戶的低維向量表示并計算他們的相似度主要解決時間因素對用戶購物偏好的影響.另外還有一些方法,使用帶有重啟模型的廣義隨機游走來建模用戶,并基于貝葉斯個性化排名的學習方法了解網絡中鏈接的權重從而進行推薦.盡管基于網絡表示學習的方法已經有一定的改善,但直接使用其來進行推薦存在兩個不足.首先,計算復雜度高并且占據太大的存儲空間.另外,在網絡上的一些鏈接可能不能傳遞有意義的語義信息,直接使用表示學習方法進行推薦表現欠佳.其次,這些方法涉及數據矩陣的特征分解這對于大型的現實世界網絡而言效率不高.
考慮到網絡嵌入方法本身也能抵抗稀疏和嘈雜的數據.具體而言,我們可以考慮節點本身及周圍節點之間的特性(即鄰近性);另外,可以基于網絡中節點的結構特性(即結構等效性)[6,7].因此,必須允許節點表示遵循兩條原則:學習嵌入節點的表示保證來自同一網絡的緊密聯系即鄰近性,以及學習表示相似角色的節點具有相似嵌入的表示即同構性.但大多數存在的網絡嵌入方法只側重于網絡的一部分信息且未考慮存儲及可拓展性問題,考慮如何把這些信息更合理有效的整合和利用到推薦系統中.因此,本文提出了一種基于聚集圖表示學習的推薦方法SGE-BPR(Summarized Graph Embedding Bayesian Personalized Ranking).考慮網絡本身所反映的特征和豐富的語義信息,該方法首先考慮結構一致性利用圖聚集算法提取聚集圖數據,更好的保存原圖信息的同時把相似性高的節點聚合到一起,隨后使用隨機游走策略生成有偏差的節點序列.通過網絡嵌入計算相似性并捕獲用戶偏好信息且融合到貝葉斯個性化排序模型,方法一定程度上減輕了數據稀疏性并緩解了噪音問題,有效彌補了直接使用原圖進行推薦的不足.
本文的主要貢獻如下:
1)首先,利用圖聚集技術把結構相似的節點聚合到一起提取聚集圖數據,然后進行有偏的隨機游走.并從圖聚集和圖嵌入、社會化推薦及基于表示學習的推薦等方面進行展開和分析.
2)利用skip-gram學習向量的表示并計算用戶的相似性,結合貝葉斯個性化排序模型提出一個新穎的圖嵌入推薦模型SGE-BPR來提高推薦性能.
3)使用四個真實世界的數據進行實驗,驗證方法的有效性.
2 相關工作
本文回顧相關工作的研究,并從圖聚集、圖嵌入和社會化推薦及基于表示學習的推薦進行討論.
2.1 圖聚集和圖嵌入
隨著數據量的增大,圖挖掘逐漸成為熱門的研究領域,當前對圖聚集的研究工作主要有:文獻[8]引入信息增益考慮分組間和分組內的結構對集聚圖的影響并提出了兩種聚集圖構建算法,要尋找高質量的聚集圖需要計算重構誤差使得原圖的鄰接矩陣與聚集圖的期望鄰接矩陣盡可能的相似,從而來衡量原圖與聚集圖之間的誤差.文獻[9]提出了圖結構查詢并采用最小描述長度(MDL)表示圖壓縮問題,該方法保證了查詢的準確性.文獻[10]通過研究通常的聚集類型,提出利用多項式時間近似算法來計算給定大小的最可能的聚集方式并生成使重構誤差最小的聚集圖.
最初提出網絡表示學習是為了學習低維潛在因子來保留大多數網絡結構.然而,這些方法計算復雜、效率低而不適用于當前的大型信息網絡.文獻[11]總結了近來出現的網絡表示學習方法并驗證了這些方法,并對大規模復雜網絡表示學習進行了展望.隨著skip-gram[12]算法的出現其顯示了在建模句子方面的優勢.受此想法的啟發,DeepWalk[13]被用來從網絡中學習一個語言模型,使用隨機游走從網絡中產生節點序列,然后把它放到skip-gram模型中最終輸出表示.緊密的節點傾向于有相似的上下文,因此嵌入后具有更相近的節點序列.LINE[14]在圖上定義了一階相似度和二階相似度,一階相似度用來保留兩個節點之間的直接聯系的緊密程度,二階相似度用來保留兩個節點鄰居的相似程度.node2vec[15]是另一種隨機游走的代表性方法,它拓展了DeepWalk并同時兼顧深度優先和廣度優先的搜索優勢從而獲得更好的表示效果.GraRep[16]模型從矩陣分解的角度考慮了更高階的上下文信息,捕獲了圖的全局結構.對于基于節點和邊的預測任務以及現有圖的深度網絡體系結構的有監督的特征學習的最新成果[17-19].這些方法直接最小化了損失函數使用多層非線性的下游預測任務轉換可產生高精度,但訓練時間長,可擴展性差.
2.2 社會化推薦
融入社會關系的協同過濾算法稱為社會化推薦算法.近年來,國內外學者針對社交關系對推薦的影響展開深入的研究.在早期,研究者們主要考慮顯式的社會關系來促進推薦.這些工作如下:文獻[20]提出RSTE一種新穎的概率因子分析框架將用戶的偏好和他們信任的朋友的興趣融合在一起.文獻[21]提出一種融合用戶隱含偏好的推薦算法,用權重矩陣來衡量用戶相似度和信任度.文獻[3]中提出基于MF的信任,通過考慮隱含鄰居的影響獲取用戶的信任和用戶的評級.SBPR[4]算法在BPR模型上融入了社交關系從而得到了更好的推薦效果.文獻[22-25]提出BPR及相關的解決項目排名問題的方法.文獻[26]基于FM(因子分解機)提出一種通過相似度和信任值來估計社會影響傳播并考慮了人群計算來提高推薦的準確性.除上述研究外,Taheri等人[27]提出Hell-Trust SVD方法提取隱含社會關系和評級并結合到活躍用戶的項目預測中.
2.3 基于表示學習的推薦
隨著表示學習的發展,一些利用表示學習推薦的方法隨之出現,在生成頂點上下文時,一種基于網絡嵌入的社交推薦方法稱為CUNE[25]通過構建用戶協作網絡識別可信的語義朋友融入MF和BPR框架用于推薦.文獻[28]基于社交網絡屬性,提出一個SAEN模型,對不同用戶進行多樣性和個性化推薦.文獻[29]基于商品間的互補性和用戶對商品的忠誠度兩個維度提出triple2vec一種新的表示學習,進而提出一種考慮忠誠度的推薦算法來計算購買偏好.文獻[30]提出了基于圖神經網絡的協同過濾算法NGCF,將用戶-項目的高階交互編碼進嵌入中來提升表示能力進而提升整個推薦效果.文獻[31]提出了一種基于生成對抗訓練框架的社會化推薦模型,對模型進行端到端的訓練,取得了很好的效果.文獻[32]基于超圖網絡模型構建了一種通過節點特征相似度,不斷的迭代和挖掘關系屬性的圖網絡進化算法.文獻[33]提出一種SLATEQ的強化學習算法,將長期收益加入排序多目標中進行建模優化,優化了推薦系統中同時展示給用戶多個項目情況的長期收益.文獻[34]提出一種互補性發現模型通過商品價格和商品購買記錄來發掘商品間的互補關系.文獻[5]提出一種利用網絡表示學習進行個性化商品推薦的方法PGE,該方法構建商品網絡并通過表示學習獲取低維向量表示且通過歷史記錄及時序性線性計算出動態的用戶偏好從而對相似度進行評估.
上述工作的核心思想是基于社交關系進行推薦.然而,大數據時代,空間效率及可拓展性也是必須考慮的重要因素.考慮現有研究的不足,本文的工作主要是采用基于信息增益的圖聚集算法[8](GSum_EG),獲取聚集圖數據.然后,借鑒node2vec的思想在聚集圖上隨機游走后學習學習有效的圖結構生成節點向量,隨后通過聚集圖映射表進行節點向量的還原并尋找相似用戶.最后,將信息融合到貝葉斯排序模型進行項目推薦.
3 一種結合聚集圖嵌入的社會化推薦算法
3.1 問題定義
為了更好的闡述,本文先對相關概念進行描述并形式化聚集圖的表示學習問題,具體如下所示:
定義1.聚集圖[8]:一個聚集圖S=(Vs,Es,P)是輸入圖G=(V,E)的壓縮表達,其中Vs是V中k是中個組的一個劃分,Es是相應的超邊的集合,P與每條邊相關聯,表示兩個超點之間或者一個超點自身的連接概率.聚集圖S的正式定義如下所示:

ES={(Vi,Vj)|?u∈Vi,v∈Vj,(u,v)∈E};
p:ES→R=[0,1].


定義2.聚集圖的表示學習[11]:給定聚集圖G=(V,E),其表示學習是:G對應的頂點特征X是一個高度稀疏的矩陣,其維數通常為|V|×m(m(是頂點屬性的特征空間大小),對每個頂點v∈V,低維向量表示學習rv∈Rk,k實質上遠小于|V|,rv表示為一個稠密的實數向量表示.
3.2 總體框架
圖1為本文提出的總體框架.如圖1(a)在社交網絡中,頂點表示節點,邊表示節點之間的社交關系.圖1(b)為圖1(a)的聚集圖,其中每個頂點代表一個超點,邊代表超邊,邊上的值代表權重,超點1對應的節點集合為{x,d,e},超點2對應的節點集合為{a,b,c},超點3對應的節點集合為{g,f},超點4對應的節點集合為{y,i,j},超點5對應的節點集合為{h}.圖1(c)為在聚集圖上產生的隨機游走節點序列.圖1(d)輸入為聚集圖的節點,當預測節點1時,使用skip-gram嵌入,輸出為其他節點出現在中心節點1周圍的概率.圖1(e)計算節點的表示向量的相似度將其輸入到貝葉斯排序模型,最終輸出推薦列表.
3.3 聚集圖及隨機游走
在社交網絡中,采用基于信息增益的圖聚集算法[8](GSum_EG)保留原圖關鍵的結構關系并去除帶有噪音的數據獲取聚集圖,由于信息熵越小包含的原圖信息越多,因此尋找信息增益最大的分組即信息熵最小的分組,依次調整直至所有節點調整完,最終得到聚集圖.
考慮到聚集圖的鄰近性及同構性,即聚集圖上距離越近的節點及結構相近的節點相似的可能性更大.相連比較緊密的節點應該有相似的嵌入.在圖1中假設(a)為聚集圖,超點x和超點y屬于同構性節點,超點x和超點d屬于鄰近性節點,因而采用同時兼顧兩種特性的方法進行有偏的隨機游走,捕獲相似節點.
設f(u)是將頂點u映射為嵌入向量的映射函數,對于圖中頂點u的近鄰頂點集合.通過以下公式計算近鄰頂點出現的概率:
(1)
為使上述問題得到最優化解,進行如下兩方面的假設:條件獨立性假設:假設給定起始頂點下,其近鄰頂點出現的概率與近鄰集合中其余頂點無關.用如下公式表示:
(2)

圖1 SGE-BPR方法說明Fig.1 Illustration of summarized graph embedding bayesian personalized ranking method
特征空間對稱性假設:一個頂點作為起始頂點和作為近鄰頂點的時候共用同一嵌入向量.(與LINE[13]中的2階相似度,一個頂點作為起始點和近鄰點的時候是擁有不同的嵌入向量不一樣)在這個假設下,上述條件概率公式可表示為:
(3)
由上述假設可得最終的目標函數如下:
(4)
其中Zu代表每個節點的函數,表示為:
(5)
為了減少計算量的同時更好的保留聚集圖的原始信息并獲得潛在的信息,采用有偏的隨機游走獲取頂點的近鄰序列.受node2vec[14]啟發,給定當前頂點v,訪問下一個頂點x的概率為:
(6)
其中πvx是頂點v和頂點x之間未歸一化的轉移概率,z是歸一化常數.
引入兩個超參數p和q來控制游走的策略,假設當前隨機游走經過邊(t,v)到達頂點v時,πvx=αpq(t,x).wvx設,其中wvx是頂點v和x之間的權值.
(7)
其中dtx為頂點v到x的最短路徑的距離.超參數p和q對游走策略均有影響.其中p決定再訪問節點的可能性,為返回參數.若p值調高(p>max(q,1)),這樣可以保證在兩步內采樣已訪問過的節點的可能性比較低;若p調低(p
3.4 聚集圖的表示學習
對于每種類型的游走方案,我們可以獲得基于聚集圖的隨機游走步行序列,這是一個旨在學習的skip-gram模型通過預測節點上下文的節點嵌入向量.通常,目標是使上下文出現的概率最大化,在給定的中心節點下Sw0=(w0,w1,….,wM)即:形式上,給定一系列單詞,目標函數是:
(8)
其中b是上下文的窗口大小,p(wt′|wt)定義為Softmax函數.同樣,我們最大化每個節點共現的概率隨機行走Wv固定長度L:
(9)
其中τ是vt′上下文的窗口大小,即vt′-τ…vt+τ.因此,skip-gram學習了一個嵌入E的特征,其中包含|V|×l個自由參數(V是聚集圖上所有節點的集合和E的每一行表示特定用戶的特征向量大小l.真實世界網絡規模龐大,為了高效的計算,分層Softmax應用于近似p(vt′|E(vt)為了避免在Softmax中歸一化函數的復雜性計算.我們模擬以每個節點為根的行走生成語義社會語料庫并使用隨機梯度下降訓練.
3.5 項目推薦
表示學習后可直接通過計算相似性進行推薦但這種方式效果并不理想,因此考慮把獲得的用戶信息融合到貝葉斯排序模型.結合實際,通常為用戶推薦項目是以一個有序的列表呈現的,用Pu表示用戶消費的項目(喜歡或購買的項目),Nu表示沒有消費的項目(沒有興趣或沒有訪問過的項目).
受SBPR[4]的啟發,其充分利用了社交關系的優勢,并拓展了排序算法BPR[21],如下:
xua≥xub,xub≥xuc,a∈Pu,b∈SPu,b∈Nu
(10)
其中xu.表示用戶u對其中一個項目的偏好.SPu表示對項目集I至少有一個確定的朋友,但沒有任何積極的反饋.
根據上述拓展并結合模型需要進行如下修改,給定Pu,IPu,Nu項目排名如下:
xui≥xuk≥xuj,i∈Pu,k∈IPu,j∈Nu
(11)
其中IPu表示用戶沒有過正反饋但是至少有一個語義朋友,因此自然可以想到u喜歡k超過j,u更喜歡k.這種假設可以很好的解釋朋友信任朋友的推薦并且其項目排名高于觀察到的消極項目.每個用戶的優化標準表示如下:
(12)
其中Tu=Pu∪IPu,Hu=IPu∪Nu.如果i∈Pu并且k∈IPu時,σ(u,i,k)=1,反之σ(u,i,k)=0.以此類推,如果k∈IPu并且j∈Nu時,σ(u,k,j)=1,反之σ(u,k,j)=0.因此,后驗概率如下:
(13)

(14)
本文使用隨機梯度下降進行訓練,SGE-BPR使用如下的梯度方程對每個觀察到的結構進行參數更新.
(15)
3.6 SGE-BPR算法
算法.SGE-BPR算法
輸入:The summarized graphG=(V,E), walk lengthn,embedding dimensionX, context sizeb, negative samplesM, returnp, in-outq.
輸出:Recommendation list.
/*計算轉移概率并初始化*/
1.π=MW(G,P,q);
2.G′=(V,E,π);
3.Initialize walks to Empty,initialize node embeddingsX;
/*聚集圖上隨機游走并嵌入*/
4. forl=1 tordo
5. for all nodesu∈V
6. RW=node2vecWalk(G′,u,n);
7. add walk to walks;
8.X=skip-gram(X,RW,b);
/*計算相似度并進行推薦*/
9. for useriinV
10. for userjinV
11. sim=cos(X[i],X[j]);
12. add sim to user similarity list;
13. Integrate sim into BPR model and generate the recommendation list.
如上給出了SGE-BPR算法的主要步驟.其中1-3行表示聚集圖上轉移概率的計算及初始化.第6行表示聚集圖上的隨機游走,第8行表示skip-gram嵌入,9-12行表示相似度的計算并加入到相似列表.
通過分析SGE-BPR算法可知,算法的可靠性主要由聚集圖的質量來決定,即聚集圖是否能保證原圖信息的完整性和準確性.下面通過理論分析和實驗來進行簡要的證明.
證明:由聚集圖的相關研究可知,信息熵可以衡量原圖信息的完整性[8].假設聚集圖包含k個超點,當k=n(n為原圖的頂點數)時,信息熵H(Gn)=0;當k=1(一個超點)時,此時的信息熵最大.綜上信息熵為0≤H(Gk)≤H(G1).進一步推論可知,k越大,信息熵越小,原圖信息越完整,而k值可由用戶自己控制,因而輸入圖為聚集圖不影響算法的可靠性.最后通過karate數據集的具體例子來驗證該算法在原圖和聚集圖的表現,進一步說明算法的可靠性.該數據集有34個用戶U={ui|i=1,2,…,34},若k=20其聚集圖包含20個超點,在嵌入后對其向量進行還原(根據聚集圖映射表最終得到34個用戶的向量表示),這樣處理能降低信息的損失,最后融入到BPR算法中,其結果如表1所示,從中可以觀察到聚集圖和原圖在推薦的表現方面很相似.綜上所述,該方法是可靠的.
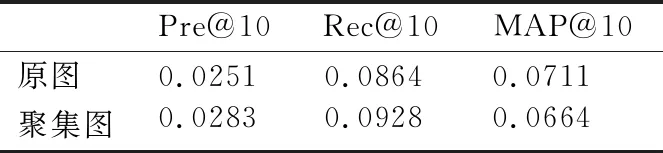
表1 算法可靠性驗證Table 1 Algorithm reliability verification
與最初的帶有社會關系的個性化排序模型[23]及其他基于社會化BPR改進的方法相比,SGE-BPR使用圖聚集技術捕獲了結構相似的節點并豐富了社交排名的假設,且考慮了表示學習的拓展性及空間存儲等更符合大規模圖的實際情況,因而不僅保護了用戶的信息且獲得較好的推薦效果,另外通過相關實驗證明其更好的提高了社會化推薦的表現.
4 實驗結果與分析
在這一部分,我們將進行實驗來驗證方法的有效性.
4.1 實驗設計
根據第3節所述設計實現融合聚集圖表示學習的推薦方法,并對數據進行驗證.實驗環境為PC機Windows 10系統、Intel Core i5處理器、8GB內存,開發環境為PyCharm,采用Python 3.6進行算法的實現.采用4個常見的社交推薦數據集FilmTrust(1)http://www.librec.net/datasets.html,LastFM(2)https://grouplens.org/datasets/hetrec-2011/,Ciao(3)https://www.librec.net/datasets.html,Epinions(4)http://www.librec.net/datasets.html.對于每一個數據集本文使用80%作為訓練集,10%作為交叉驗證集,10%作為測試集,使用五折交叉驗證,對比平均表現.數據集如表2所示.

表2 數據集Table 2 Datasets
4.2 效果比較
為了證明本文方法的有效性,與顯式的社會信息相關的貝葉斯排名模型進行比較.基線方法如下:BPR[21]是一種假設用戶購買過的物品的偏好排序優于用戶未購買過的物品,利用用戶對物品反饋情況進行個性化排序的方法.SBPR[4]是一種利用顯式的社會信息拓展BPR模型的方法.CUNE[25]提出利用網絡嵌入技術獲得top-k隱性朋友.為了評估本文模型的性能,本文選擇3種評價指標:準確率(Precision)和召回率(Recall)和排序指標平均精度均值MAP(Mean average precision)進行度量.
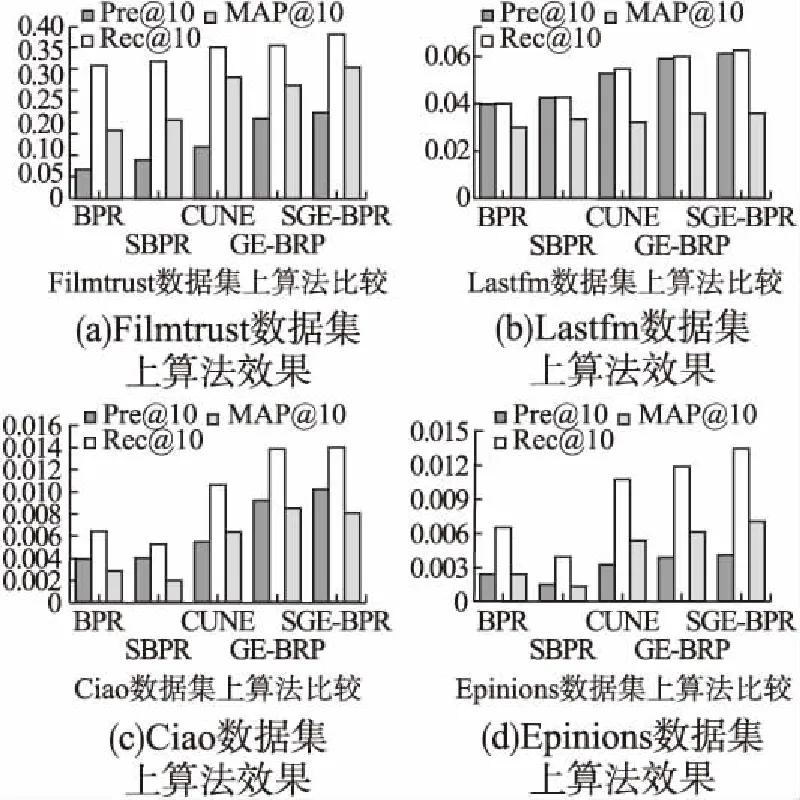
圖2 4個數據集上算法效果比較Fig.2 Comparison of algorithm effects on four datasets
參數設置:對于所有的基線方法,基于先前工作的建議及實驗,設置如下:正則化系數λX=0.01,潛在特征維數d=20,對兩種網絡嵌入方法,CUNE和SGE-BPR步數n=20,每一步的長度l=20,窗口大小b=5,負樣本數量M=5.
如圖2所示,不同的推薦方法推薦表現不一樣,從圖中可以觀察到:首先,4個數據集上顯示本文方法優于其他基線方法同時我們對本文中的方法在原圖(GE-BPR)和聚集圖上的效果做了比較,在聚集圖上的效果優于原圖.其次,3種網絡嵌入方法推薦表現優于其他普通的排序方法,可能的原因是網絡拓撲結構可以幫助更好的獲得潛在的社會關系通過網絡嵌入能緩解數據稀疏因而提高了在推薦上的表現.最后,使用隱式關系最終的推薦結果好于直接使用顯式關系的結果,我們的方法加強了顯式關系且降低了計算復雜度從而推薦效果好于直接使用隱式或顯式關系的方法.
為了證明SGE-BPR算法的效率,我們同時對比同一算法下原圖和聚集圖的表現,進行實驗驗證了在3種指標下,本文的算法在原圖和聚集圖上進行時間的對比(見表3).

表3 算法運行時間對比Table 3 Algorithm running time comparison
從表3中可以看出,聚集圖上的算法效率更高,特別是當數據量增大的時候,聚集圖上表現了明顯的優勢,可能的原因是聚集圖上的噪音少于原圖且聚集圖的節點表示得到的向量更高效.另外有研究表明,基于隨機游走的采樣策略所占內存少于其他方式,比如矩陣分解的方法[16],一般而言對于無監督的圖嵌入來說,使用skip-gram模型本身也存在一定的優勢且聚集圖是對原圖的聚集,因而節省空間.

圖3 4個數據集上維度的影響Fig.3 Effect of dimensions on four datasets
在方法SGE-BPR上我們主要對比了維度為10,20,40,60,80這5種不同維度下,準確率(Pre@10)、召回率(Rec@10)和平均精度均值(Map@10)的變化.從圖3左圖我們可以看到剛開始時小幅度的上升,隨后平穩之后小幅度的下降,當維度達到一定閾值時所反映的信息比較完全,因此呈現穩定而后再增加維度不利于信息的獲取.而右圖波動幅度較大但變化趨勢類似,因此綜合而言本文維度值取20是合理且有效的,便于達到更好的推薦效果.
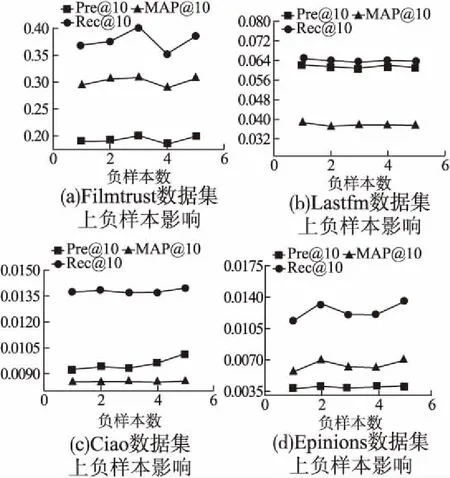
圖4 4個數據集上負樣本數目的影響Fig.4 Effect of negative sample numbers on four datasets
在方法SGE-BPR上我們主要對比了負采樣數為1,2,3,4,5這5種不同負樣本數,準確率(Pre@10)、召回率(Rec@10)和平均精度均值(Map@10)的變化.從圖4中我們可以看到剛開始時小幅度的上升,隨后平穩之后小幅度的下降,當負樣本達到一定閾值時所反映的信息比較完全,因此呈現穩定而后再增加負采樣時不利于信息的獲取.因此本文負采樣本數取5是合理且有效的.
5 結 語
本文主要利用聚集圖上的表示學習挖掘潛在的信息從而加強顯式關系提高推薦,受網絡嵌入的啟發,本文設計了一種新穎的SGE-BPR項目排名方法,使用聚集圖表示學習并融合貝葉斯個性化排名模型.實驗結果顯示我們的方法優于傳統的基于模型的方法及顯式的社會推薦模型.
下一步工作將進一步考慮時間因素對推薦的影響,優化聚集圖上隨機游走方案,將模型拓展并結合到異構圖中進行推薦.
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
