時間序列特征表示與相似性度量研究綜述
2021-02-05 18:10:32孫冬璞
計算機與生活 2021年2期
孫冬璞,曲 麗
哈爾濱理工大學計算機科學與技術學院,哈爾濱 150080
當今社會是一個數據信息爆炸的時代,時間序列作為其中一種普遍的數據類型,在日常生活中無處不在。如今已經成為數據挖掘領域[1]研究的主要方向,廣泛應用于金融、氣象、醫學[2]、電子科技、教育、工業等多個領域。人們可以通過時間序列的歷史數據挖掘出其中的潛在價值信息并預測未來趨勢。簡言之,時間序列是一組根據時間先后順序不斷變化的數列,如果直接對原時間序列進行處理,無法避免產生耗時長,時間復雜度高,成本高的問題。因此,選擇一種簡單的轉換方式,將數據量大、動態性強、易受噪聲干擾的高維密集型時間序列轉換為低維離散型時間序列,發現不同時間序列之間的關系,探索其中的規律,達到降低研究成本的目的,就變得尤為重要。
特征表示是一種將數量冗長的高維時間序列映射到低維數據空間的常用方法,在提取局部特征信息仍然能夠反映整體時間序列信息的前提下,過濾掉低頻信息,既保證了時間序列的基本信息和形態特征,又有效地實現了數據降維去噪。這種方法為提高數據挖掘效率奠定了良好基礎。
相似性度量作為數據挖掘領域另一個重要的過程,應用于大部分時間序列的預處理階段。一般情況下,在對時間序列進行分類、聚類、回歸分析之前,如果通過相似性度量發現序列之間的內在規律,篩選出重要的時間序列,對于提高數據挖掘的效率非常有利。針對不同類型的時間序列,采取合適的相似性度量方法能夠更加客觀地反映時間序列之間的關系。除了基于形狀的相似性度量、基于模型的相似性度量方法和基于數據壓縮的相似性度量方法外,常用的相似性度量方法還有興趣模式發現、異常模式處理、序列可視化[3-5]等。
本文主要從時間序列的特征表示和相似性度量方面對目前時間序列的研究現狀進行總結。
首先,針對時間序列特征表示方法,本文從非數據適應性方法、數據自適應性方法、基于模型的方法三方面進行闡述說明,比較了多種常用方法的優缺點、時間復雜度、不同特征表示方法之間的區別以及適用條件。
其次,針對時間序列相似性度量,本文從基于形狀的相似性度量、基于模型的相似性度量、基于數據壓縮的相似性度量三方面進行系統描述。對各種方法是否支持去噪、是否滿足三角不等式等方面進行了說明,并且對常用的經典模型如歐氏距離(Euclidean distance,ED)、隱馬爾科夫模型(hidden Markov model,HMM)、最長公共子序列(longest common subsequence,LCSS)、自回歸滑動平均模型(autoregressive moving average model,ARMA)等進行了系統的介紹。
最后,本文對時間序列未來研究發展方向進行了展望,提出了引入聚類算法、分類算法、預測算法、權值、斜率、魯棒性技術等研究方法。這些方法能夠一定程度地降低時間序列噪聲,提高挖掘精度。
1 時間序列特征表示方法研究現狀
時間序列特征表示是一種能夠將原始高維時間序列轉化為另一個低維領域的近似表示數據,進而對數據降維的常用方法。例如小波變換,通過對時間軸函數的伸縮平移區分高頻和低頻信號,然后投射到低維數據空間上,使投射后的時間序列盡可能地反映原始時間序列信息。有效的特征表示方法往往能以簡潔的方式表達該時間序列的特征信息,起到對時間序列降維去噪,減少計算量的效果,為進一步提高數據挖掘效率奠定了良好基礎。目前已經研究出多種關于時間序列特征表示的方法。根據時間序列數據的不同轉換方式,大體將特征表示方法分為非數據適應性方法、數據自適應性方法、基于模型的方法三類。不同方法之間存在著一定的區別和聯系,歸類分析如圖1 所示。
1.1 非數據適應性方法
非數據適應性方法能夠將高維度時間序列數據轉換到其他的低維度數據空間,且數據本身相對獨立,和轉換過程、特征系數選擇無關。該方法適用于表示大小(等長)不變并且每條時間序列的轉換參數一致的分段時間序列。基于不同非數據適應性方法特性的比較如表1 所示。
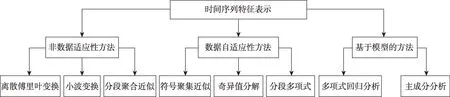
Fig.1 Classification of time series feature representation methods圖1 時間序列特征表示方法分類
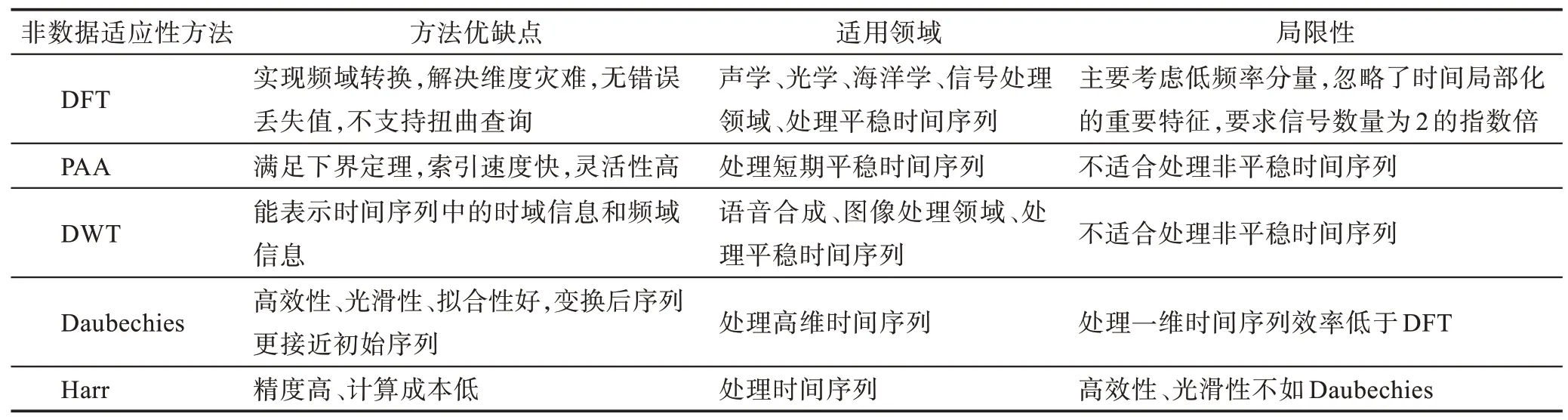
Table 1 Comparison of non-data adaptive methods表1 非數據適應性方法的比較
1993 年,Agrawal 等人[6]提出了一種使用傅里葉變換(discrete Fourier transform,DFT)將時間序列的特征域變換到頻域的表示方法。其時間復雜度為O(nlb(n))。該方法通過將信號分解,形成頻率幅度大小不同的頻率譜,然后通過R*-tree 將其運用到索引和相似度查詢中。該方法有效解決了時間序列數據挖掘中“特征抽取完備性”和“維度災難”的問題。它的優點是沒有錯誤的丟失值,數值相對精準。缺點是不支持時間扭曲查詢,主要考慮低頻率分量,忽略了高頻率分量和時間局部化的重要特征。該方法經常被應用于例如聲學、光學、海洋學、信號處理等領域。Keogh 等人[7]提出了分段聚合近似表示方法(piecewise aggregate approximation,PAA),該方法在滿足下界定理的前提下,時間復雜度最快能達到O(n),適用于處理短期平穩變化的時間序列。該方法通過在索引速度和靈活性等方面與傳統的奇異值分解(singular value decomposition,SVD)和離散小波變換(discrete wavelet transform,DWT)進行比較,證明其在時間序列相似性度量和索引上更具有優勢。Keogh 等人[8]還提出了一種基于逐段線性分割的方法(partial least squares regression,PLS),該方法不僅能夠較為準確地確定時間序列的形狀,而且能夠快速地對時間序列進行聚類和分類分析。除此之外,頻譜分析也是非數據適應性的一種常見方法。Chan 等人[9]提出的離散小波變換(discrete wavelet transform,DWT)經常被應用于處理平穩信號的時間序列信息,其時間復雜度為O(n)。該方法有效結合了泛函數、調和分析、數值分析等數學分析方法。優點是既能夠表示時間序列中的時域信息,又能夠表示頻域信息。此特性被廣泛應用于語音合成、圖像處理等領域。相比較而言,DFT 只能表示頻域信息并且要求信號數量為2 的指數倍,信號結果不夠穩定,具有一定的局限性。繼而,Popivanov 等人[10]對比了不同小波變換對時間序列相似性搜索的效率并得出結論,多貝西小波(Daubechies wavelet,DbN)比哈爾小波(Haar wavelet,Harr)的高效性、光滑性和擬合性都更好一些,并且使用小波變換后的時間序列更加接近初始的時間序列。但是,Haar 小波在時間序列結果的精度上優于Daubechies和Coiflet小波,并且計算成本低。除了一維時間序列外,通過Haar 變換得到的序列精度接近最優,其性能明顯優于DFT。此外,PIP(perceptually important points)方法[11]通常用于非等長時間序列之間的比較,被廣泛應用于金融領域當中。

Table 2 Comparison of data adaptive methods表2 數據自適應性方法的比較
由于國內對于時間序列特征表示方面的研究起步較晚,而且主要集中在國內的重點高校和科研所當中[12]。因此,研究成果與國外相比較還有一定的提升空間。
1.2 數據自適應性方法
數據自適應性是一種數據和參數隨著時間變化而變換的方法。與非數據適應性方法不同,數據適應性方法允許各條時間序列的轉換參數是不一致的,該方法既依賴于單條時間序列,又受整體時間序列數據集的影響,相對獨立性較差。對于數據自適應性方法的比較如表2 所示。
Lin 等人[13]提出了一種符號聚集近似(symbolic aggregate approximation,SAX)表示方法,時間復雜度能達到O(n)的級別。該方法能夠實現將高維非離散時間序列轉化為低維離散符號化時間序列,有效達到降維去噪的效果。該方法優點是滿足下界定理,可以將字母存儲為位而不是雙精度,并且允許維度減少,大大節省了空間。研究者根據該方法可以更好地進行字符串處理、生物信息學應用、股票數據聚類等操作。缺點是該方法只適用于能等分且服從高斯分布的離散型和字母型時序數據,并且符號化過程只采取時間序列的均值作為局部特征提取,只能反映原始時間序列的總體變化趨勢,不能客觀描述各段的局部信息,容易忽略時間序列形態變化和特征點等信息,造成數據中其他信息的缺失,而且當兩個時間序列各段的均值一致而各段趨勢不同時,SAX 的局限性更明顯。
Lkhagva 等人[14]在SAX 基礎上提出了擴展方法(extension of symbolic aggregate approximation,ESAX),考慮加入時間序列段的均值、極大值和極小值等特征點元素,能夠更加準確地反映時間序列的形態,在進行相似性搜索時,該方法效率更高,但是下界性沒有得到充分證明。除此之外,可轉位符號聚合近似(indexable symbolic aggregate apprximation,iSAX)的多分辨率符號表示方法,能夠實現快速精確搜索和超快速近似搜索。其中,iSAX 與SAX 的不同在于是否通過二進制形式替代字母形式表示每個分段。iSAX方法創建的層次結構索引不能包含重疊的區域,是一種支持大量數據集進行索引的表示方法,可以索引多達億個數量級的時間序列[15]。奇異值分解(singular value decomposition,SVD)[16]表示方法也是一種數據適應性方法,因為運行時間復雜度高達O(Mn2),代價成本較高,應用并不廣泛,往往應用于文本處理領域,用來處理數據的底層結構。Ye 等人[17-18]提出的shapelets 子序列的概念,是一種能夠最大限度突出時間序列主要特征的子序列表示方法,具有準確性高、分類速度快、可解釋性強的特點。該方法搭建起了時間序列和形狀之間相互表示的橋梁。Sun 等人[19]提出了一種基于趨勢距離的符號聚合近似表示方法(SAX trend distance,SAX-TD),通過時間序列段的起點和終點構建趨勢距離,是一種融合了SAX 距離和趨勢距離的新距離度量表示方法。該方法的缺點是在構建距離時,難免伴隨著存儲維度和運行時間的增加。除此之外,分段多項式也是常見的數據自適應性方法。
1.3 基于模型的方法
基于模型的方法是提前假定時間序列數據是由某個模型產生,然后通過對該模型設定合適的參數或者系數,實現對時間序列的特征表示。
Azzouzi 等人[20]提出隱馬爾科夫模型(HMM)來捕獲時間序列變量間的依賴關系和測量值中的串行相關性。該模型被廣泛應用于語音識別、音字轉換等自然語言處理領域。Kalpakis 等人[21]提出了求和自回歸移動平均模型(autoregressive integrated moving average model,ARIMA),該模型能夠更加高效直觀地表示時間序列特征信息,主要應用于醫療領域對流行病的預測和食品領域對食品安全性預測方面。Nanopoulos 等人[22]提出一種基于統計模型(含方差、均值等)的特征提取方法,采用局部特征表示整體時間序列。李愛國等人[23]提出了一種分段多項式回歸模型,將時間序列分為多段表示。Fuchs等人[24-26]提出了一種基于正交多項式的時間序列表示方法,實現了正交多項式和最小二乘法的融合,運用正交基向量形成特征空間,并將數值較大的坐標系數作為特征序列。這類方法往往被用于在線分割。Sebastiani 等人[27]使用馬爾科夫鏈模型(Markov chain model,MC)表示時間序列中的動態特征。馬爾科夫鏈模型是一種對時間、狀態離散化處理,帶有記憶情況的隨機過程模型,經常用于對人均GDP、股票和彩票預測、全國電信業務總量的預測。另外,主成分分析法也是常用的一種基于模型的方法。基于模型的表示方法往往具有較強的可解釋性,若兩條時間序列可以由具有相同參數的同一數據集模型表示,那么認為它們是相似的。此類方法的關鍵在于選擇合適的模型和提前了解時間序列數據產生過程的信息。只有選擇與產生過程相符合的模型才能獲得更好的結果。基于模型的主要方法特性比較如表3所示。
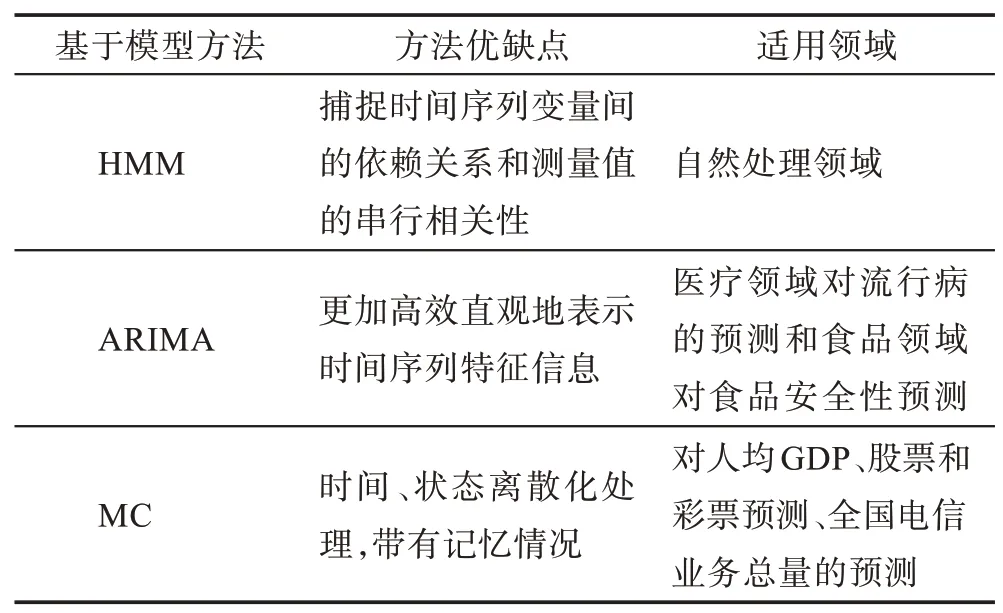
Table 3 Characteristics comparison of model-based methods表3 基于模型方法的特性比較
主要的時間序列特征表示方法的時間復雜度如表4 所示。

Table 4 Time complexity of feature representation methods表4 特征表示方法的時間復雜度
2 時間序列相似性度量研究現狀
時間序列相似性度量通常采用衡量兩個不同時間序列之間距離遠近程度的方式來驗證兩個序列是否相似。目前時間序列相似性度量研究主要通過在原有研究基礎上提出新的時間序列相似性度量方法,評估該方法對時間序列數據挖掘精度的影響。時間序列相似性度量方法分為基于形狀的相似性度量方法、基于模型的相似性度量方法和基于數據壓縮的相似性度量方法等。不同相似性度量方法特性存在一定的差異性和聯系,如表5 所示。
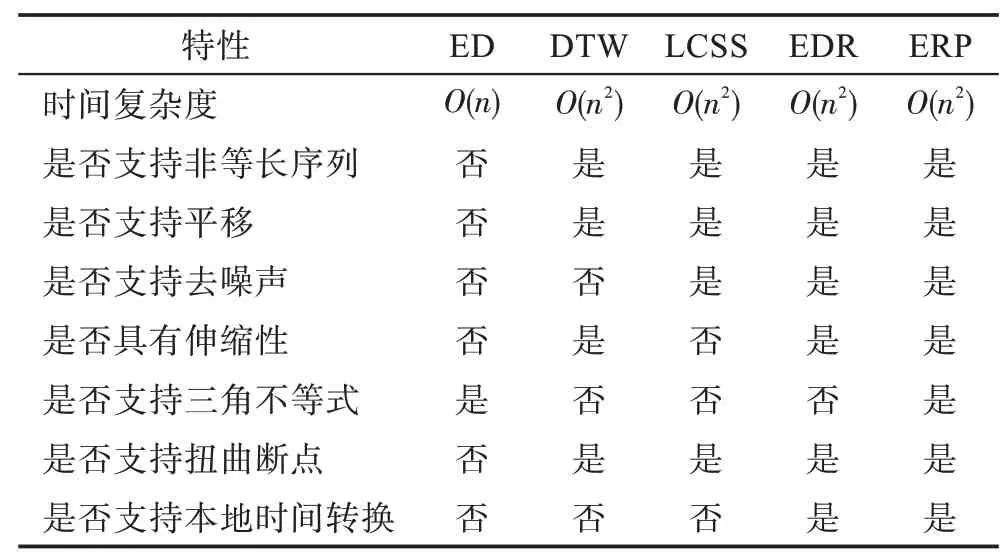
Table 5 Features comparison of similarity measurement methods表5 相似性度量方法特性比較
相似性度量在應用于時間序列數據挖掘領域時,一般與聚類算法相結合。通常此類方法首先將等長時間序列通過降維的方法處理為不等長的時間序列,然后進行等長處理,選取兩個時間序列的公共點元素,構成新的時間序列集合,利用得到的時間點集合再對時間序列進行二次劃分,最后得到新的等長時間序列。此過程雖然會提高計算的復雜性,但是便于操作,基本不會對結果造成較大的偏差。
2.1 基于形狀的相似性度量
基于形狀的相似性度量方法多種多樣。表6 對主要方法的特性進行了分析比較。

Table 6 Comparison of similarity measurement methods based on shape表6 基于形狀的相似性度量方法的比較
歐氏距離(ED)是一種基于形狀相似性的常見鎖步度量方式。當兩個時間序列長度相等且均為數值型序列時,該方法通過公式計算兩個序列上時間點的距離。在模糊距離中,漢明距離和灰色關聯分析法也可以應用在字符串形狀相似性度量中。其中漢明距離通過對等長字符串序列對應位進行異或運算,統計結果為1 的個數。1 的個數越多,相似性越低。漢明距離有一個鮮明的特點就是它比較的兩個字符串必須等長,否則距離不成立。它的核心原理是如何通過字符替換(最初應用在通訊中實際上是二進制的0-1 替換),能將一個字符串替換成另外一個字符串。灰色關聯分析法是通過對時間序列進行無量綱化處理,確定參數數據序列和若干比較數據序列的幾何形狀來判斷相似程度,然后根據關聯度和關聯系數衡量關聯性的強弱。灰色關聯分析法的特點在于思路清晰,可以在很大程度上減少由于信息不對稱帶來的損失,并且對數據要求較低,工作量較少。其中LP 范式為最常見的距離度量形式,時間復雜度為O(n),并且滿足三角不等式,一般用于索引、聚類和分類上。該距離方法缺點是對相位漂移比較敏感,受噪音干擾較大,對于時間序列的形狀縮放和位移無法準確識別,某種情況下,度量結果往往存在很大誤差。因此,該度量方式通常依賴于數據的歸一化處理。在經過特征表示之后再進行相似性搜索時,該空間下的距離度量需要滿足下界定理[28-31]。動態時間彎曲(dynamic time warping,DTW)是一種通過對時間軸進行彎曲、拉伸或收縮來計算兩個時間序列間相似性的方法。該方法既可以處理兩個等長時間序列,也可以處理兩個不等長的時間序列,而且允許時間序列的點自行拷貝之后再進行等長匹配,支持平移,能夠很好地處理時間漂移問題,克服了歐氏距離對于序列變形后不能準確匹配的問題,具有效率優于歐氏距離和三角形相似性[30,32-35]的特點,并且允許不同時間軸上的時間序列進行相似性匹配。但是存在不支持噪聲處理、本地時間轉換和三角不等式,且時間復雜度較高等問題,隨著時間序列維度的遞增,算法的效率并不高。針對其不足,Sakoe 等人[36]和Itakura[37]分別提出Sakoe-Chiba 條形約束和平行四邊形約束方法,通過在動態規劃過程中引入全局約束的方法,一定程度上減少了計算量,來實現算法效率的提高。該方法將路徑規劃(也稱路徑彎曲)過程限制在一定區域內,不僅避免了不必要的路徑規劃,而且有效防止過度匹配導致準確率下降的問題。Keogh 等人將基于DTW 的精確索引應用于時間序列挖掘中[38]。除此之外,DTW 在計算多元時間序列最佳彎曲路徑時,雖然能夠較好地反映時間序列形態變化問題,但容易出現不合理的匹配導致產生多條匹配路徑,從而無法選擇最精準的路徑的問題。Gorecki 等人[39]考慮到局部形態特征處理問題,提出了分別用動態時間彎曲和微分動態時間彎曲求取多元時間序列距離后再用參數線性組合度量的方法,但僅考慮一階數值導數可能會失去全局形態或重要的特征。Keogh 等人[40]提出了一種擴展方法為DDTW(derivative dynamic time warping),根據時間序列中某個點的相鄰信息選取適當的計算方式構造出新的時間序列,達到實現新的序列不再對異常值敏感的目的。在此基礎上,自適應代價動態時間彎曲的多元時間序列度量方法(adaptive cost multivariate dynamic time warping,ACM-DTW)[41],通過對時間序列點距離矩陣賦予權重,來達到較好的匹配效果,權重由自適應代價函數計算獲取。
基于互相關的距離度量方法(cross-correlation based distance)具有降低噪聲影響和概括時間結構的特點[42]。當兩個時間序列大體形態都很相似,此時歐氏距離和動態時間彎曲方法都無法測量,僅僅在小范圍內存在彎曲或斷點時,可以采用最長公共子序列(LCSS)距離度量方法。該方法對于噪聲的處理能力比較強,但是對于處理時間軸的伸縮和振幅平移問題有待于進一步提高,而且不支持三角不等式[43-45]。LCSS 方法采用將兩個時間字符串最大的公共字符串長度與最長字符串相除的百分比作為衡量兩時間序列相似性的度量標準[46]。實序列編輯距離(edit distance on real sequence,EDR)是一種能夠有效對時間序列進行降噪,降低序列位移和誤差敏感度的方法。該方法通過閾值模式將時間序列元素量化為0/1表示,降低了時間序列的噪聲,對于異常數據的處理具有更好的魯棒性,但是該方法并不滿足三角不等式[47-48]。實補償編輯函數(edit distance with real penalty,ERP)是一種允許在兩條不同長度的序列間通過添加符號達到等長效果的度量方法[49-50]。該方法對數據的噪聲、位移和縮放具有較強的魯棒性,通過使用一個恒定的參考點來達到尋找彎曲路徑中最小路徑的目的。該方法滿足三角不等式,并且能夠有效處理本地時間轉換問題[51-52]。動態時間彎曲、最長公共子序列、實序列編輯距離、實補償編輯函數方法的時間復雜度均為O(n2)。
2.2 基于模型的相似性度量
Ge 等人[53-54]采用隱馬爾科夫模型進行相似性度量,加入了分段線性表示來實現捕獲變量之間的依賴關系,又能夠衡量時間序列測量相關性。Panuccio等人[55]采取標準化的方法對HMM 距離進行處理,判斷時間序列的擬合性能好壞。ARMA 模型[21]是一種通過模型參數或演變參數確定原始序列相似性關系的方法。ARIMA 模型[56]全稱為自回歸積分滑動平均模型,該模型首先判斷序列的平穩性,若為非平穩序列,通過差分運算過濾掉非平穩趨勢的點,然后確定時間序列的自回歸參數和滑動平均參數。空間裝配距離(spatial assembling distance,SpADe)[57]也是一種基于模型的相似性度量方法。基于模型的相似性度量與基于形狀的相似性度量相比,優勢在于可以提前將數據的知識通過計算結合進來。并且通過某個序列所建模型生成另外序列的概率值來衡量兩個序列的相似度。
2.3 基于數據壓縮的相似性度量
皮爾遜相關系數和相關距離(Perason's correlation coefficient and related distance)[58]是一種不隨數據點的比例和位置而變化的相似性度量方法。基于分段正常化的相似性度量(piecewise normalization)[59]是一種涉及不同大小的時間間隔或“窗口”的相似性度量方法。基于倒頻譜的相似性度量(cepstrum)[60]是一種頻譜測量方法,能夠短時間內實現對數振幅頻譜的反傅里葉變換。
基于概率距離的相似性度量(probability-based distance)[61]能夠將多種季節性模式融合匯總。基于條件Kolmogorov 復雜性的距離度量或數據壓縮距離度量(compression-based distance measure,CDM)[62-63]通過數據壓縮比率大小反映時間序列相似性。該方法壓縮率越大,相似性越高,反之亦然。但是對算法的連接和壓縮過程要求較高,適合處理較長的離散化時間序列。Lang 等人[64]提出了基于字典壓縮的相似性度量(dictionary-based compression)方法,應用于相似性度量的字典壓縮評分。類似的KL(Kullback-Leibler)距離相似性度量[65]、基于分段概率的相似性度量(piecewise probabilistic)[66]、基于余弦小波函數的相似性度量(cosine wavelets)[67]、基于自相關的相似性度量(autocorrelation)[68]也是比較常用的基于數據壓縮的相似性度量方法。基于數據壓縮的相似性度量來自于計算理論研究和生物信息學研究的一些結果,是一個比較新穎的想法。數據壓縮是指在不丟失有用信息的前提下,縮減數據量以減少存儲空間,或者按照一定的算法對數據進行重新組織,減少數據的冗余和存儲空間的一種技術方法。現有的相似性度量方法對短時間序列有較好的效果,但是對于較長的時間序列,它們的評估成本會迅速下降。因此應該為數據選擇壓縮工具和壓縮參數的最佳組合。例如,CDM 取決于特定壓縮器(gzip、bzip2 等)的選擇以及壓縮參數。如今這些方法的應用范圍也較廣泛,如醫學上的心電圖測量、生物識別中的面部識別、物理學中的粒子跟蹤等。除此之外,這些時間序列相似性度量方法對于查詢數據庫、分類和聚類十分有用。
3 未來研究方向
隨著科技的不斷發展,時間序列被廣泛應用于多個領域,為社會的經濟發展做出了巨大的貢獻。例如在醫學領域,時間序列用來檢測病人群體中的異常個體;金融領域中檢測異常收入支出,防止發生詐騙行為;工業領域檢測設備異常,防患于未然等。
時間序列一般用作數據挖掘的預處理步驟,降低高維數據維度,達到提高數據挖掘精度的效果。
如今時間序列相似性度量發展蓬勃,但是仍然存在一些問題值得重視。因此,針對時間序列相似性度量的未來研究方向提出了幾種規劃:
(1)一般對于時間序列相似性的研究比較理想化,多數相似性度量方法均在假設獲取的訓練集是相對準確的前提下進行研究。但是在實際情況中,時間序列數據的采集和運行結果往往受到周圍環境的影響,伴隨著大量噪聲的產生。因此,如何將相關魯棒統計學的技術運用在相似性度量的學習方法中,達到更為理想的效果還有待于研究。
(2)同一數據集運用不同的相似性度量方法時,精度的結果測量往往存在很大差異。因此,為了更好地完成數據挖掘的各類任務,在此基礎上,可以考慮融合數據挖掘聚類算法將時間序列數據進行分組,每個分組內的時間序列數據相似性越高,不同分組之間相似度越低,則聚類效果越好。因此,選擇合適的數據挖掘算法融合相似性度量方法提高結果精確度是一個值得研究的課題。
(3)考慮在時間序列的相似性度量方法上融合機器學習的分類算法。比如支持向量機、樸素貝葉斯、決策樹等,也可以達到提高相似性度量結果精確度的目的,可以作為未來研究的方向之一。
(4)如今定位技術和基于位置服務的應用發展迅速,過程中會有文本、圖像數據等海量軌跡數據產生。因此,如果對不同時間點車輛運行的路段信息、軌跡方向信息、運行軌跡長度信息(包括運行軌跡存在交叉等情況)采用合適的距離度量函數進行計算,對軌跡相似性度量進行深入研究,將有益于城市規劃、智慧出行的發展。
(5)目前為止,對于時間序列相似性度量研究主要為靜態低維的時間序列。對于動態高維時間序列的研究成果較少,這就要求時間序列相似性度量方法具有高效、平穩、低成本的特點,因此通過相似性度量方法改進優化實現這些特點,值得進一步研究。
4 結束語
時間序列往往具有高維性、數據量大、隨著時間變化而變化的特點。隨著大數據時代的蓬勃發展,時間序列越來越普遍存在于人們的日常生活中。因此,根據時間序列的高維特性適當地降低維度,發現不同時間序列之間的關系,探索其中的規律,挖掘潛在價值就變得尤為重要。本文從時間序列的特征表示和相似性度量方面對目前時間序列的研究現狀進行了闡述和總結,分析比較了各種方法的優缺點、時間復雜度及方法之間的區別和適用條件,最后對時間序列的未來研究方向提出了幾點展望。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
