命名實體識別的遷移學習研究綜述
2021-02-05 18:10:34李艷玲
計算機與生活 2021年2期
李 猛,李艷玲,林 民
內蒙古師范大學計算機科學技術學院,呼和浩特 010022
命名實體識別(named entity recognition,NER)是自然語言處理(natural language processing,NLP)的一項非常重要的基礎任務,旨在自動檢測文本中的命名實體并將其分類為預定義實體類型,例如人名、地名、組織機構名等,是人機對話系統、機器翻譯、關系抽取等的前置任務[1]。傳統以及深度NER[2-6]方法已經取得了非常高的識別精度,但是訓練模型需要大規模標注數據,模型性能與標注數據量成正比,在訓練語料匱乏的特定領域(如醫學、生物等)和小語種(如蒙古語、維吾爾語等)上,性能差強人意。由于訓練集和測試集要求獨立同分布,因此導致將已有的模型運用到其他領域或者語言上性能差強人意。
遷移學習旨在利用源域中大量標注數據和預訓練模型提高目標任務學習性能,憑借其對數據、標注依賴性小和放寬了獨立同分布約束條件等優點[7-8],已經成為解決資源匱乏NER 的強大工具。NER 的遷移學習方法早期工作主要集中在基于數據的方法,利用并行語料庫、雙語詞典等作為橋梁將知識(如標注、特征表示等)從高資源語言投影到低資源語言,主要用于跨語言NER 遷移。后來研究者將源模型部分參數或特征表示遷移到目標模型上,不需要額外的對齊信息,實現了跨領域和跨應用NER 遷移并取得了非常好的效果。最近NER 對抗遷移學習受到越來越多研究人員的關注,引入由生成對抗網絡(generative adversarial networks,GAN)[9]啟發的對抗技術,生成一種“域無關特征”,進而實現源域知識到目標域的遷移,幫助目標任務提高學習性能,同時有效緩解了負遷移問題。
劉瀏等人[10]從NER 定義、評測會議、主流研究方法等角度,介紹了NER 任務的發展歷程;Li 等人[11]詳細地總結和分析了NER 的深度學習方法,以及深度NER任務面臨的挑戰和未來發展方向。Pan和Yang[12]的綜述是一項開創性工作,對遷移學習進行了定義和分類,并回顧了2010 年之前的研究進展;Weiss 等人[13]介紹并總結了許多同構和異構遷移學習方法;Zhuang 等人[8]從數據和模型角度對40 多種具有代表性的遷移學習模型進行了介紹和對比。以上綜述都是對NER 或遷移學習單方面的闡述,沒有詳細地介紹兩者結合的方法。本文從基于數據遷移學習、基于模型遷移學習、對抗遷移學習這三方面對目前NER 任務的遷移學習方法進行了研究和調查。
1 命名實體識別
1.1 傳統NER 方法
傳統的NER 方法大致有三類:基于規則、無監督學習和基于特征的有監督學習[1,12]。基于規則的方法依賴語言學家和領域專家手工制定的語義語法規則,通過規則匹配識別各種類型的命名實體,基于規則的方法雖然能夠在特定語料上(字典詳盡且大小有限)獲得很好的效果,但是構建這些規則不僅耗時,難以覆蓋所有規則,而且可擴展性和可移植性比較差。無監督學習方法利用在大型語料庫上獲得的詞匯資源、詞匯模型和統計信息,使用聚類[14]推斷命名實體類型。基于特征的有監督學習方法通過監督學習,將NER 任務轉換為序列標注任務,根據標注數據,將每個訓練樣本用精心設計的特征表示出來,然后利用機器學習算法訓練模型,從看不見的數據中學習相似的模式,其缺點是需要大量人工標注訓練數據和人為構造、選擇的有效特征[15]。
基于規則的方法主要有LaSIE-Ⅱ[16]、NetOwl[17]、Facile[18]。基于特征的有監督學習算法主要有隱馬爾可夫模型(hidden Markov model,HMM)[19]、決策樹(decision trees)[20]、最大熵模型(maximum entropy model,MEM)[21]、支持向量機(support vector machines,SVM)[22]、條件隨機場(conditional random fields,CRF)[23]等。
1.2 深度NER 方法
近年來,隨著深度神經網絡的迅猛發展,NER 的深度學習方法已成為主流。深度學習有三個優勢:(1)深度神經網絡可以進行非線性變換,進而從數據中學習到更復雜的特征;(2)深度學習可以從原始數據中自動學習特征;(3)深度NER 模型屬于端到端模型[8]。
NER的深度學習方法一般分為三個階段[8],如圖1所示,分別是分布式表示、特征提取器和標簽解碼器。分布式表示把單詞或字符映射到低維實值密集向量中,其中每個維度代表一個隱藏特征,它可以自動從文本中學習語義和句法特征,分布式表示有三種:詞向量(word embedding)[24]、字符向量(character embedding)[15]和混合表示[3]。特征提取器通過接收上一層的向量對上下文特征表示進行學習,常用的特征提取器有卷積神經網絡(convolutional neural networks,CNN)[2]、Transformer[25]、循環神經網絡(recurrent neural network,RNN)[26]以及它的兩種變體門控循環單元(gated recurrent unit,GRU)[27]和長短時記憶網絡(long short-term memory,LSTM)[3]。標簽解碼器是最后一個階段,以上下文特征為輸入,生成標簽序列,常見的解碼方式有Softmax[24]、CRF、RNN。
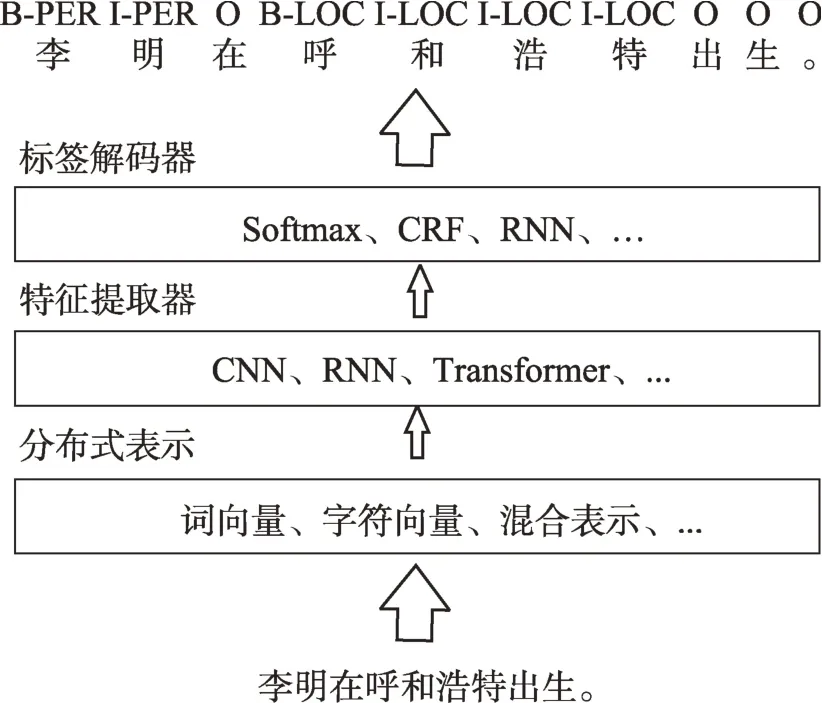
Fig.1 Deep learning for NER flowchart圖1 NER 深度學習流程圖
1.3 深度NER 的難點
(1)資源匱乏。深度學習需要大規模標注數據才能很好地訓練模型,但數據標注非常耗時且昂貴,尤其對于許多資源匱乏的語言和特定領域,如蒙古語、醫學、軍事領域。當標注數據較少時,由于無法充分學習隱藏特征,深度學習的性能會大大降低,而且深度學習模型可移植性很差,無法將已有數據和模型應用到資源匱乏領域[7]。因此,采用半監督學習和無監督學習實現資源的自動構建和補足,以及遷移學習等方法都可作為解決該問題的研究方向[28]。
(2)非正式文本。非正式文本即表達不符合書面語法規范的文本,如人機對話系統用戶提問、Twitter 和微博等社交媒體上的文章評論等用戶生成文本,由于其語句簡短、口語化、內容寬泛、語意含糊、包含諧音字,使NER 變得非常困難,甚至無法識別。例如:“我中獎了”寫成“我中了”;“杯具”表示“悲劇”;“xswl”代表“笑死我了”。Li等人使用主動學習將微博文本NER 的F1 值提高到了67.23%,但是仍需要人工標記[29]。可以使用注意力機制和遷移學習結合深度學習完成對非正式文本的識別。
(3)命名實體多樣性。隨著信息化時代的來臨,移動互聯網的普及,數據規模海量化,命名實體及其類型趨于多樣化,同時也在不斷演變[30]。傳統的實體類型只有人名、地名和組織機構名,但是現實生活中實體類型復雜多樣,不同領域存在不同的實體類型,需要識別更詳細的實體類型,例如交通查詢領域,需要出發地、目的地、時間、交通工具等實體類型。可以使用遷移學習技術,重復利用已有數據和模型,實現細粒度NER。
(4)命名實體歧義性。自然語言中存在大量歧義問題,這給NER 帶來很大挑戰。在不同文化、背景、領域下,同一實體可能含有不同的含義,例如:“香格里拉”可能是“香格里拉市”也有可能是“香格里拉酒店”。因此需要充分理解上下文語義關系進行識別,可以使用實體鏈接、注意力機制、特征融合、圖神經網絡等方法,挖掘更詳細、更深層次的語義信息,從而消除命名實體的歧義性[28]。
(5)實體嵌套。實體嵌套指實體內部有一個或多個其他實體,例如:“中國駐俄羅斯大使館”這一組織機構名中包含了“中國”和“俄羅斯”兩個地名。嵌套實體中包含了實體與實體之間豐富的語義關系,充分利用嵌套實體的嵌套信息,可以幫助人們更詳細、更深層次地理解文本。Xu 等人使用SVM 和CNN抽取中文嵌套實體的語義關系[31]。Xia 等人使用MGNER(multi-grained NER)模型,重構了命名實體識別的流程,對嵌套實體進行識別[32]。
2 遷移學習
隨著信息化時代的來臨,傳統機器學習以及深度學習已經取得了巨大的成功,并已經應用到許多實際生活中。但是它們嚴重依賴于大量具有相同數據分布的標記訓練數據,然而實際應用中,收集足夠的訓練數據是非常困難的。半監督學習、無監督學習可以放寬對大量標注數據的需求進而可以解決部分問題,但是訓練的模型性能不盡如人意[8]。遷移學習是機器學習中解決訓練數據不足這一基本問題的重要方法,旨在利用來自源域的知識提高目標任務學習性能[8]。它放寬了機器學習中的兩個基本假設:(1)用于學習的訓練樣本與新測試樣本滿足獨立同分布條件;(2)必須有足夠可利用的訓練樣本才能學習得到一個性能不錯的模型[33]。在遷移學習中,給定源域DS(含有大量標注數據,如英語、新聞領域等)和源任務TS,目標域DT(只有少量或完全沒有標注數據,如蒙古語、社交媒體領域、醫學領域等)和目標任務TT,其中DS≠DT或者TS≠TT。遷移學習已經廣泛地應用于NLP、計算機視覺等領域,是當前機器學習中的研究熱點。
2.1 傳統遷移學習方法
傳統遷移學習方法分為基于數據和基于模型的方法。基于數據方法主要使用實例加權和特征轉換,以減小源域樣本和目標域樣本之間的分布差異。Dai 等人提出了TrAdaboost[34],將Adaboost 算法擴展到了遷移學習中,提高可用源域實例權重,降低不可用源域實例權重。Huang 等人提出核均值匹配法(kernel mean matching,KMM),通過再生核希爾伯特空間(reproducing kernel Hilbert space,RKHS)中匹配源域和目標域實例之間的均值,估計源域和目標域概率分布,使得帶權源域和目標域概率分布盡可能相近[35]。Pan 等人提出遷移成分分析(transfer component analysis,TCA)[36],采用最大均值誤差(maximum mean discrepancy,MMD)[37]作為度量準則測量邊緣分布差異,以分散矩陣作為約束條件,將源域和目標域之間的分布差異最小化。
基于模型方法是指利用源域和目標域之間的相似性和相關性,將已訓練好的部分源域模型或特征表示遷移到目標模型上,以提高目標模型的性能。Duan等人提出領域自適應機(domain adaptation machine,DAM)通用框架,借助在多個源域上分別預先訓練的基本分類器,為目標域構造一個魯棒的分類器[38]。為了解決分類問題,Tommasi 等人提出了一種單模型知識遷移方法(single-model knowledge transfer,SMKL),該方法基于最小二乘SVM,從源域選擇一個預先獲得的二進制決策函數,然后遷移其參數到目標模型[39]。Yao 等人在TrAdaBoost 的基礎上做了多源擴展,提出了TaskTrAdaBoost,首先在每個源域上執行AdaBoost構造一組候選分類器,然后每次迭代挑選出在目標域上具有最低分類誤差的候選分類器并為其分配權重,最后將所選分類器組合產生最終預測[40]。
2.2 深度遷移學習方法
深度學習目前是機器學習領域最流行的方法,許多研究者利用深度學習技術構建遷移學習模型,已經成為解決深度學習數據依賴和訓練數據不足等問題的重要方法。深度遷移學習分為兩類:非對抗方法和對抗方法。
非對抗方法復用在源域中預先訓練好的部分深度神經網絡,將其遷移至目標模型中。Tzeng 等人提出深度域混淆(deep domain confusion,DDC)解決深度網絡的自適應問題,在源域與目標域之間添加了一層適應層和MMD,讓深度遷移網絡在學習如何分類的同時,減小源域實例與目標域實例之間的分布差異[41]。Long 等人對DDC 進行了擴展,提出了深度自適應網絡(deep adaptation network,DAN)[42],在深度神經網絡中加入多層適應層和表征能力更好的MK-MMD[43]。Long 等人在DAN 網絡的基礎上又提出了聯合自適應網絡(joint adaptation network,JAN),相比于DAN 只考慮邊緣分布自適應,JAN 使用效果更好的多層聯合分布自適應[44]。
對抗方法引入由GAN 網絡啟發的對抗技術,使模型無法識別特征來自源域還是目標域,進而完成源域知識到目標域的遷移,同時有效緩解了負遷移問題。Ganin 等人提出了結構簡單的領域對抗神經網絡(domain-adversarial neural networks,DANN)[45],其由特征提取器、標簽預測器和領域分類器組成,特征提取器的作用類似于GAN 網絡生成器,其目的是生成“域無關”的特征表示,領域分類器起著類似于判別器的作用,試圖檢測提取的特征是來自源域還是目標域,通過在領域分類器和特征提取器之間使用對抗技術,學習一種“域無關特征”。Tzeng 等人提出了一種對抗領域自適應的通用框架ADDA(adversarial discriminative domain adaptation)[46],利用判別模型、無條件權重共享和GAN 損失,解決領域之間的數據分布問題。Zhang等人提出了一種部分領域自適應的方法,稱為基于重要性加權對抗網絡的領域自適應(importance weighted adversarial nets-based domain adaptation,IWANDA)[47],不再使用一個共享特征提取器,而是分別為源域和目標域提供特定域的特征提取器。
3 命名實體識別的遷移學習方法
3.1 基于數據遷移學習
NER 的基于數據遷移學習方法大多利用額外高資源語言標注數據作為遷移學習的弱監督訓練,以對齊信息作為橋梁,如雙語詞典[48]、并行語料庫[49]和單詞對齊[50]等,將知識(標注、詞向量、特征表示等)從高資源語言投影到低資源語言。基于數據方法在跨語言NER 中顯示出相當大的優越性,但是對高資源語言標注數據和對齊信息的規模和質量非常敏感,并且僅限于跨語言遷移。
3.1.1 標注和表示投影法
為了提高跨語言NER 的性能以及針對目標語言中沒有人工標注,Ni 等人提出兩種弱監督跨語言NER 方法[49]標注和表示投影法,以及兩種共解碼方案基于排除-O 置信度和基于等級的共解碼方案。
標注投影法利用并行語料庫、翻譯等對齊語料,將高資源語言中的標注遷移到對應目標語言上,并開發了一種獨立于語言的數據選擇方案,可以從嘈雜的數據中選擇高質量標注投影數據。給定目標語言句子y,以及質量得分閾值q和實體數量閾值n,其投影質量得分q(y),如式(1)所示:

式中,e代表y中的每個實體,代表e用投影標注l′(e)標記的相對頻率,n(y)是y中的實體總數。數據選擇方案必須滿足q(y)≥q,n(y)≥n。
表示投影法,首先使用以詞向量為輸入的前饋神經網絡模型訓練英語NER 系統,然后將目標語言的詞向量通過線性映射M f→e投影到英語向量空間中;最后使用訓練好的英語NER 系統對目標語言進行標記。可通過加權最小二乘法得到線性映射M f→e,如式(2)所示:
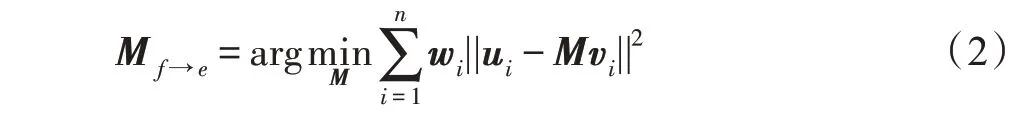
其中,wi表示訓練詞典中英語目標語言單詞對(xi,yi)的權重,ui、vi分別表示英語單詞xi和目標語言單詞yi的詞向量。
共解碼方案可以有效地結合兩種投影法的輸出,提高識別精度。基于排除-O 置信度的共解碼方案是選擇置信度分數較高的標注投影法或表示投影法生成的標簽,優先選擇一種方法的非O 標簽(即實體標簽)。基于等級的共解碼方案,給予標注投影法更高優先級,即組合輸出包括標注投影法檢測到的所有實體,以及與標注投影法不沖突的所有表示投影法檢測到的實體。當標注投影法為一段x都生成了O 標簽,則表示投影法檢測到x的實體標簽不會與標注投影沖突。例如:標注投影法的輸出標簽序列為(B-PER,O,O,O,O),表示投影法的輸出標簽序列為(B-ORG,I-ORG,O,B-LOC,I-LOC),那么基于等級的共解碼方案合并輸出為(B-PER,O,O,B-LOC,ILOC)。
Ni 的貢獻在于為標注投影法開發了一種語言無關數據選擇方案,以及兩種共解碼方案,有效地提高了NER 的識別精度。兩種投影法都具有較高靈活性,但是容易受到雙語單詞對的對齊準確率和英語NER 系統準確率的影響。
3.1.2 雙語詞典特征表示遷移法
為了豐富低資源語言的語義表示以及緩解詞典外單詞問題,Feng 等人提出了雙語詞典特征表示遷移法,將雙語詞典特征表示和詞級實體類型分布特征作為目標NER 模型的額外輸入,并設計一個詞典擴展策略估計詞典外單詞的特征表示[51]。
雙語詞典特征表示:根據來自高資源語言的翻譯,對每個低資源語言單詞的所有翻譯詞向量使用雙向長短時記憶網絡(bi-directional long short-term memory,BiLSTM)或注意力機制提取特征表示veci。每個翻譯項目T都由一個或多個高資源語言單詞組成,例如:中文單詞“美國”有四個英文翻譯“America”“United States”“USA”和“The United States of America”。
詞典擴展策略,用于估計詞典外單詞的雙語詞典特征表示。給定低資源語言單詞xi及其對應詞向量wi和雙語詞典特征表示veci。使用線性映射函數,如式(3)所示,作為兩個語義空間之間的轉換,最小化式(4)以優化映射矩陣M,在獲得M之后,對每個詞典外單詞oi用式(5)估算其特征表示veoi:
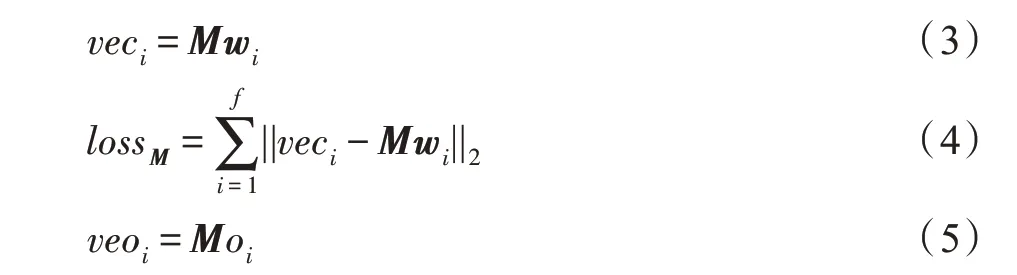
單詞實體類型的分布特征是每個單詞被標記為每種實體類型的概率。實驗中只使用了三種最常見的命名實體類型,即P(人名)、L(地名)、O(組織名)以及隨機生成一個表示非實體的類型N,因此構造了四個實體類型向量{EP,EO,EL,EN},Ej∈Rd。然后,使用標準余弦函數計算低資源詞向量wi與實體類型向量Ej之間的語義相關性,如式(6)所示。最后,每個低資源和高資源語言單詞都分配有一個維數為4 的實體類型分布特征,eij={eP,eO,eL,eN}。

最后,將低資源詞向量wi、低資源字符向量ci、雙語詞典翻譯特征veci或veoi以及實體類型分布特征eij的連接詞向量Wi={wi,ci,veci,eij}作為BiLSTMCRF 模型的輸入。
該方法開創性地使用雙語詞典特征表示和單詞實體類型的分布特征表示,豐富了低資源語言的語義表示,并設計了一種詞典擴展策略,有效地緩解了詞典外單詞問題,在低資源NER 性能上取得很大的提升。該方法具有非常好的可擴展性,可以將高資源語言的其他知識(例如:WordNet、知識圖譜等)整合到體系結構中,還可以擴展到其他NLP 任務(例如:意圖識別、情感分析)。
3.2 基于模型遷移學習
NER 的基于模型遷移學習不需要額外的高資源語言對齊信息,主要利用源域和目標域之間的相似性和相關性,將源模型部分參數或特征表示遷移到目標模型,并自適應地調整目標模型[52]。例如:Ando和Zhang[53]提出了一種遷移學習框架,該框架在多個任務之間共享結構參數,并提高了包括NER 在內多種任務的性能。Collobert等人[2]提出一個獨立于任務的卷積神經網絡,并采用聯合訓練將知識從NER 和詞性標注(part-of-speech tagging,POS)任務遷移到組塊識別任務。Wang 等人[54]利用標簽感知MMD 完成特征遷移,實現了跨醫學專業NER 系統。Lin 等人[55]在現有的深度遷移神經網絡結構上引入單詞和句子適應層,彌合兩個輸入空間之間的間隙,在LSTM 和CRF 層之間也引入了輸出適應層,以捕獲兩個輸出空間中的變化。考慮到目標數據的領域相關性差異,Yang 等人[56]受知識蒸餾(knowledge distillation,KD)的啟發,提出了一種用于序列標記領域自適應的細粒度知識融合模型,首先對目標域句子和單詞的領域相關性進行建模,然后在句子和單詞級別上對源域和目標域進行知識融合,有效平衡了目標模型從目標域數據學習和從源模型學習之間的關系。
3.2.1 基于RNN 的遷移學習
RNN 及其變體已被大量應用于NER 任務,并取得了非常高的識別精度。Yang 等人利用神經網絡通用性,提出了一種基于RNN的序列標注遷移學習框架(RNN-based transfer learning,RNN-TL)[52],通過源任務和目標任務之間共享模型參數和特征表示,提高目標任務的學習性能。并利用不同級別的共享方案,在一個統一的模型框架下處理跨域、跨應用和跨語言遷移。
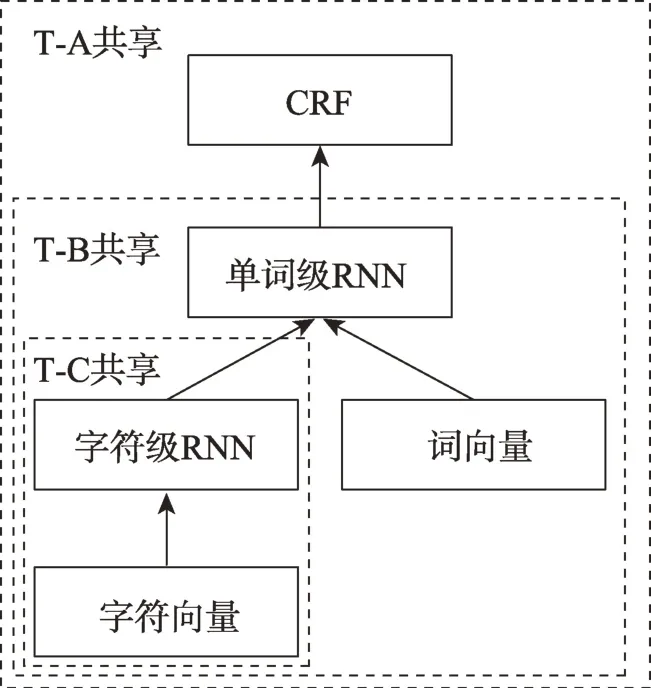
Fig.2 RNN-based transfer learning model圖2 基于RNN 的遷移學習模型
該遷移方法在一個統一的RNN-CRF 框架下,在低資源跨域、跨應用和跨語言的序列標注任務上取得了不錯的效果,尤其是在跨領域方面。但是還存在一定不足:跨語言遷移只能是字母相似的語言;對于遷移的參數和特征表示沒有進行任何篩選工作,這使得負遷移對模型性能產生消極影響。
3.2.2 參數和神經適應器遷移
NER 的實體類型隨時間在不斷變化,為了解決目標領域出現新的實體類型而導致重新標注數據和訓練模型的問題,Chen 等人[57]提出了一種解決方案:在目標模型的輸出層添加新的神經元并遷移源模型部分參數,然后在目標數據上進行微調(fine-tuned),此外還設計一種神經適應器學習源數據和目標數據之間的標簽分布差異,遷移過程如圖3 所示。
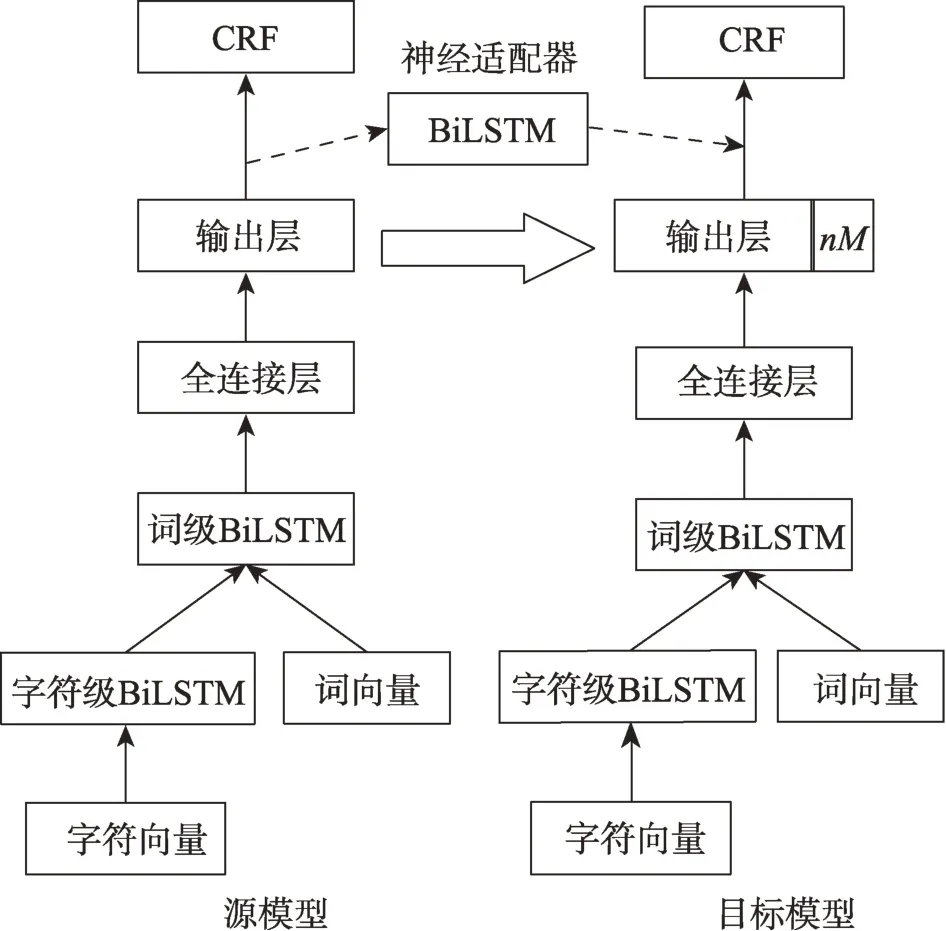
Fig.3 Parameters and neural adapter transfer model圖3 參數和神經適應器遷移模型
在目標模型輸出層擴展nM個神經元用于學習新實體類型,其中n取決于數據集標簽格式(例如:如果數據集為BIO 格式,則n=2,因為對于每個命名實體類型,將有兩種輸出標簽B-NE 和I-NE),M是新命名實體類型的數量。遷移源模型參數時,目標模型輸出層參數用正態分布X~N(μ,σ2)得出的權重進行初始化;其他參數都用源模型中相對應參數進行初始化。
神經適應器使用BiLSTM 實現,將源模型輸出層輸出連接到目標模型相應輸出上,作為目標CRF 的附加輸入。可以為目標模型學習兩個任務之間的標簽分布差異,以減少數據標簽不一致的影響。
該方案使用源模型的參數和神經適應器實現模型遷移,是一種非常簡單的遷移方法,解決了目標領域出現新實體類型而導致重新標注數據和訓練模型的問題。同時神經適應器可以解決標簽不一致,且具有提高遷移模型性能的能力。
3.3 對抗遷移學習
NER 的基于模型遷移學習方法雖然取得了很好的性能,但是還存在以下問題有待解決:(1)沒有考慮資源間的差異,強制在語言或領域之間共享模型參數和特征表示;(2)資源數據不平衡,高資源語言或領域的訓練集規模通常比低資源訓練集規模大得多[58],忽略了領域間的這些差異,導致泛化能力差。因此研究者引入受GAN 網絡啟發的對抗技術,學習一種“域無關特征”,實現源域知識到目標域的遷移,同時有效緩解了負遷移問題。
NER 的對抗遷移學習流程如圖4 所示。對抗鑒別器選擇有利于提高目標任務性能的源任務特征,同時防止源任務的特定信息進入共享空間。訓練完成之后,對抗鑒別器和共享特征提取器達到平衡:對抗鑒別器無法區分共享特征提取器中的特征表示來自源域還是目標域。但是訓練達到這個平衡點需要花費大量時間,還有可能發生模型崩潰。

Fig.4 NER adversarial transfer learning flowchart圖4 NER 對抗遷移學習流程圖
3.3.1 自注意力機制對抗遷移網絡
取96孔板,加入100 μL不同濃度(0.625、1.250、2.500、5.000、10.000、20.000、40.000 mg/mL)的揮發油乙醇溶液,然后再分別加入100 μL新配制的ABTS工作液,室溫條件下靜置反應10 min后,用酶標儀在波長405 nm下測定其吸光度。分別以無水乙醇和維生素C作為空白和陽性對照,每個揮發油濃度重復3次。
Cao 等人首次將對抗遷移學習應用于NER 任務,提出自注意力機制的中文NER 對抗遷移學習模型[59]。充分利用中文分詞(Chinese word segmentation,CWS)任務更加豐富的詞邊界信息,并通過任務鑒別器和對抗損失函數過濾中文分詞任務的特有信息,以提高中文NER 任務性能。同時在BiLSTM 層后加入自注意力機制明確捕獲兩個字符之間的長距離依賴關系并學習句子內部結構信息。
任務鑒別器,通過Maxpooling 層和softmax 層識別特征來自哪個領域,可以表示為式(7)、式(8):
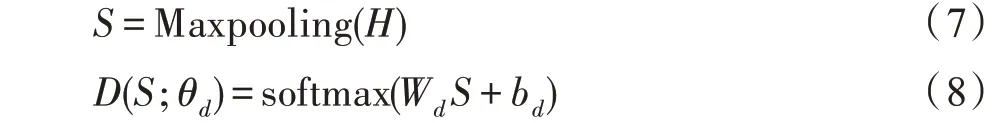
其中,H表示共享自注意力的輸出,θd表示任務鑒別器的參數,Wd∈RK×2dh和bd∈RK是可訓練參數,K是任務數。
通過引入對抗損失函數LAdv,如式(9)所示,防止中文分詞任務的特定信息進入共享空間。LAdv訓練共享特征提取器以產生共享特征,使得任務鑒別器無法可靠地判斷特征的領域。通過在softmax 層下方添加一個梯度反轉層完成minimax 優化,使共享BiLSTM 生成一個特征表示來誤導任務鑒別器。
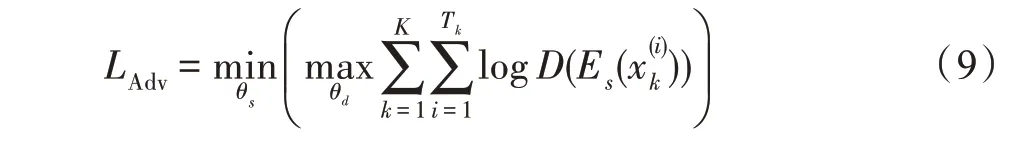
式中,θs表示共享特征提取器可訓練參數,Es表示共享特征提取器,Tk是任務k訓練實例的數量,是任務k的第i個實例。
該模型首次將對抗遷移學習應用于NER 任務,在WeiboNER 數據集[60]和SighanNER 數據集[61]上,將F1 值分別從BiLSTM-CRF 模型的51.01%和89.13%提高到了53.08%和90.64%,并通過實驗驗證了遷移學習、對抗訓練、自注意力機制各個方法對于模型的有效性。
3.3.2 雙重對抗遷移網絡
Zhou 等人提出了雙重對抗遷移網絡(dual adversarial transfer network,DATNet)[58],在通用深度遷移單元上引入兩種對抗學習:一是用廣義資源對抗鑒別器(generalized resource-adversarial discriminator,GRAD),解決資源數據不均衡和資源差異問題;二是對抗訓練,分別在字符向量和詞向量層添加以一個小范數? 為界的擾動,以提高模型的泛化能力和魯棒性。
DATNet 根據特征提取器的差異,有兩種體系結構:一是特征提取器有共享BiLSTM 和資源相關BiLSTM 的DATNet-F;二是特征提取器只有共享BiLSTM 而沒有資源相關BiLSTM 的DATNet-P。
GRAD 通過權重α平衡高低資源的訓練規模差異較大的影響,使源域和目標域中提取的特征表示更加兼容,共享BiLSTM 的輸出與領域無關,并為每個樣本提供自適應權重,從而使模型訓練的重點放在困難樣本上。為了計算GRAD 的損失函數,如式(10)所示,共享BiLSTM 的輸出序列首先通過自注意力機制編碼為單個向量,然后通過線性變換投影到標量r:
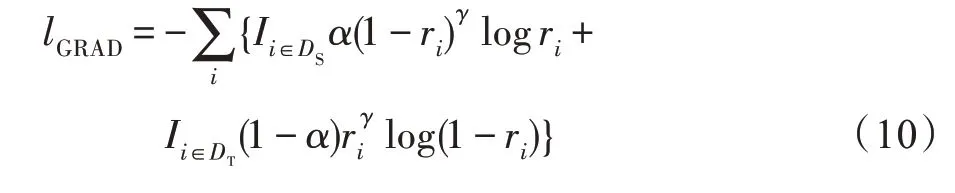
式中,Ii∈DS和Ii∈DT是標識函數,分別表示特征來自源域還是目標域;參數γ衡量困難和簡單樣本損失貢獻對比,通過測量預測值與真實標簽之間的差異控制各個樣本的損失貢獻。權重α和分別減少了高資源樣本和簡單樣本的損失貢獻。
對抗訓練就是在原始樣本的基礎上添加以一個小范數?為界的擾動ηx,計算如式(11)所示:
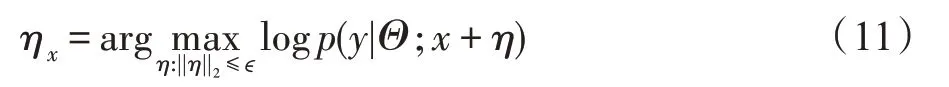
其中,Θ是當前模型參數集。ηx按照文獻[62]中的策略,通過如下線性化方法近似估算,g=?xlogp(y|Θ;x),?可在驗證集上確定。在每個訓練步驟中,由Θ參數化當前模型找到的擾動ηx,并通過xadv=x+ηx構造一個對抗樣本,然后進行原始樣本和對抗樣本混合訓練以提高模型泛化能力。對抗訓練損失函數lAT的計算如式(12)所示:
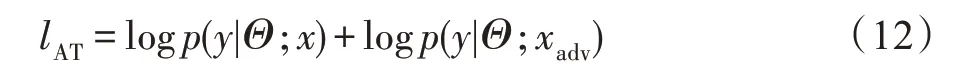
其中,logp(y|Θ;x)、logp(y|Θ;xadv)分別表示原始樣本及其對抗樣本的損失。DATNet 分別在字符級和詞級向量層使用對抗訓練,可以根據式(11)計算字符向量擾動ηc、源域詞向量擾動ηWS和目標域詞向量擾動ηWT。
DATNet 很好地解決了表示差異和數據資源不平衡的問題,提高了模型的泛化能力,并在跨語言和跨域NER 遷移上取得顯著改進。通過實驗,DATNet-P 架構更適合具有相對更多訓練數據的跨語言遷移,而DATNet-F 架構更適合具有極低資源和跨域遷移的跨語言遷移。
4 評價指標及NER 方法比較
4.1 命名實體識別評價指標
目前,NER 最常用的評價標準有精確率(Precision)、召回率(Recall)和F1 值(F1-score)等。
精確率,在給定數據集中,標注正確實體數占所有被標注實體數的比例,如式(13)所示:

召回率,在給定數據集中,標注正確實體數占數據集中所有實體數的比例,如式(14)所示:

Table 1 Statistics of NER datasets表1 NER 數據集統計信息

F1 值,同時考慮精確率和召回率,是平衡精確率和召回率的綜合指標,如式(15)所示:
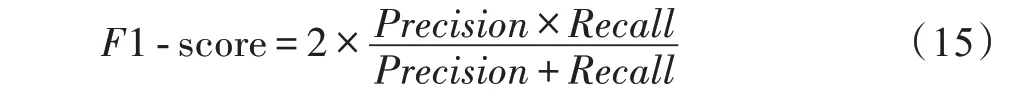
其中,TP(true positive)表示真陽性,識別出的正確實體數;FP(false positive)表示假陽性,識別出的錯誤實體數;FN(false negative)表示假陰性,未被識別出的實體數。
4.2 遷移學習評價指標
為了驗證遷移學習模型的性能,通常是在同一數據集下,將實驗模型與深度神經網絡模型、其他遷移學習模型的精確率、F1 值等進行比較。
4.3 NER 方法性能比較
為了評估NER 遷移學習方法的性能,本文以CoNLL2003 英語NER 數據集[63]為源域,CoNLL2002西班牙語和荷蘭語NER 數據集[64]以及WNUT-2017英語Twitter NER 數據集[65]為目標域進行實驗。這些數據集的統計信息如表1 所示,使用官方的訓練集、驗證集和測試集的劃分方法。實驗中使用30 維字符向量、50 維詞向量,LSTM 隱狀態的數量設置為100 維。
表2 是一些NER 方法的F1 值比較,可以看出雙語詞典特征表示在跨語言遷移方面取得了非常好的效果,相比于LSTM-CRF 在西班牙語和荷蘭語上的F1 值分別提升了3.01 個百分點和6.65 個百分點,由于領域之間沒有標準的對齊信息,該方法無法進行跨領域遷移;DATNet 的兩個變體優于其他方法,在3個數據集上都有很大提升,DATNet-P 更適合跨域遷移,而DATNet-F 在跨語言上更有優勢。與多任務學習[66]相比,遷移學習最關心的是目標任務,而不是同時提升所有的源任務和目標任務。
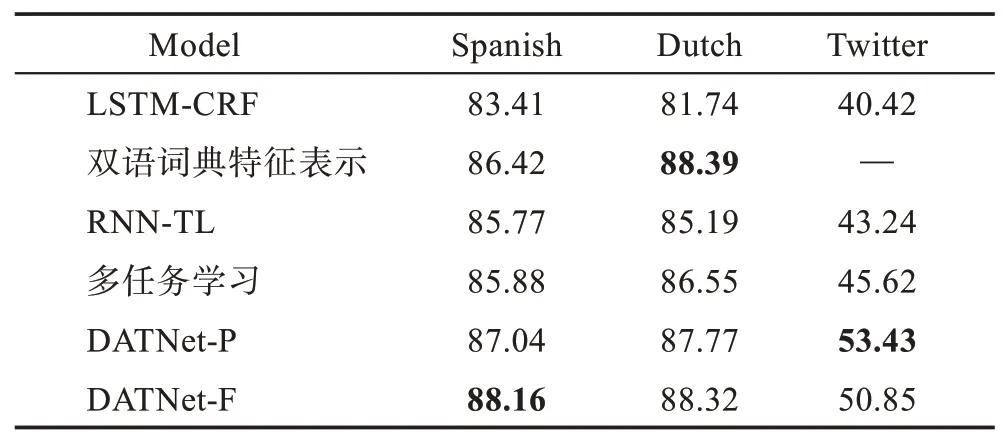
Table 2 NER method performance comparison(F1-score)表2 NER 方法性能比較(F1 值)%
5 總結與展望
本文主要對應用于NER 任務的遷移學習方法從基于數據、基于模型和對抗遷移學習三方面進行了歸納總結。遷移學習對于解決NER 任務的資源匱乏、實體類型多樣化等問題,取得了非常好的效果。基于數據遷移學習在跨語言遷移任務中取得很大成功,但也僅限于跨語言遷移。基于模型遷移學習不需要額外的高資源語言表示,將源模型的部分參數和特征遷移到目標模型上。對抗遷移學習以其獨特的對抗訓練思想,生成一種“域無關特征”,實現源域知識到目標域的遷移,幫助目標任務提高學習性能,同時有效緩解了負遷移問題,是目前發展潛力最大的NER 遷移學習方法,也是今后的研究重點。
隨著對NER 遷移學習的深入研究,還有一些新的問題需要解決:
(1)負遷移是遷移學習道路上最大的阻礙,雖然尋找源域和目標域之間相關性衡量標準以及對抗遷移學習可以緩解該問題,但是這些方法都有其自身的局限性。如何更好地解決負遷移問題,有待進一步深入研究。
(2)對于多步傳導式遷移學習,如何尋找一個或幾個既能照顧到目標域也能照顧到源域的中間領域,幫助相關性不大的兩個領域之間實現遷移學習,以達到充分利用已有的大量數據,是遷移學習未來的一個研究方向。
(3)在NER 對抗遷移學習中如何構建更加強大的對抗鑒別器,幫助共享特征提取器和對抗鑒別器之間更快達到平衡點,處理多源域NER 對抗遷移學習任務,以及更好地解決負遷移問題,是下一步研究的主要工作。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
