支持隱私保護的社交網絡信息傳播方法
2021-02-05 18:10:40謝小杰王梓森李錦濤
計算機與生活 2021年2期
高 昂,梁 英,謝小杰,王梓森,李錦濤
1.中國科學院計算技術研究所,北京 100190
2.中國科學院大學計算機科學與技術學院,北京 100049
3.移動計算與新型終端北京市重點實驗室,北京 100190
社交網絡作為一種新興的網絡傳媒,不僅大大加快了信息傳播的速度,也使信息能夠更高效和廣泛地傳播。人們將社交網絡廣泛應用于推薦系統、病毒式營銷、廣告投放、專家發現等領域,充分享受信息傳播帶來的種種益處。然而,信息的快速傳播給用戶帶來許多便利的同時,也造成了隱私泄漏的隱患。
在現有的社交網絡中,信息發布者為保護其隱私,可以通過設置僅對指定好友可見等方式來限制能看到信息的對象。但大部分社交平臺都提供了轉發功能,允許看到信息的對象繼續轉發該信息,從而造成隱私泄漏。
一些社交平臺提供了設置不可見對象的功能,即使信息經過多次轉發,對于指定的對象仍不可見。例如,假設A發送了一條信息,B再轉發來自A的信息,C再轉發來自B的信息,D是B或C的好友,但如果A設置了對象D不可見,那么D也沒法通過B或C的轉發來看見這條信息。然而,這樣的功能并不能完全阻止隱私泄漏的發生。例如,如果B不是直接轉發A,而是用自己的語言描述了A發送的信息中的信息后進行發送,假設D是B或者某個轉發B信息的人的好友,那么D就能夠看到這條信息,從而獲取A的隱私,在本文中將這種行為稱為轉述。可見,在社交網絡中用戶的轉發和轉述行為都有可能造成隱私泄漏,而且通過轉述行為造成的隱私泄漏很難被發現或阻止。
當前對社交網絡的研究主要集中于影響力最大化和隱私保護,然而,現有影響力傳播相關的研究沒有考慮用戶的隱私保護需求,隱私保護相關的研究沒有關注用戶的影響力;同時,現有的信息傳播模型很難有效建模社交網絡中隱私泄漏傳播過程。這為社交網絡的研究帶來了三點挑戰:(1)如何保障用戶的個性化隱私保護需求;(2)如何最大化用戶發布的信息的影響力;(3)如何平衡隱私保護和信息傳播的矛盾。
例如,用戶在社交網絡上發布信息或推薦系統推送信息時,如何選擇相關用戶(種子節點)推送信息,使得所發布的信息通過社交網絡傳播能讓更多的人看到(影響力最大化),同時不被黑名單用戶捕捉;同樣,通過病毒營銷做品牌推薦時,如何選擇社交網絡中感興趣的投放用戶(種子節點)推送信息,使得傳播的人數最多(影響力最大化),且避免傳播到非目標用戶群體(黑名單用戶)。
為了解決上述問題,本文首先以獨立級聯模型為基礎,設計了支持轉發行為、轉述行為的社交網絡信息傳播模型,實現對隱私泄漏來源的補充和修正;然后基于社交網絡信息傳播模型,提出了一種信息傳播網絡構建方法,實現對轉發行為、轉述行為融合建模,有效支撐包含轉述關系的信息傳播機制;最后,基于支持轉述行為的信息傳播網絡,提出了一種支持隱私保護的影響力最大化方法,通過節點泄漏概率上限計算,結合隱私保護約束和啟發式影響力最大化算法來選擇種子集合,實現在滿足隱私保護約束的同時,最大化信息傳播的影響力。通過在爬取的新浪微博數據集上進行實驗驗證和實例分析,結果表明本文方法能夠確保在保護用戶隱私的情況下,最大化傳播影響力。
本文主要貢獻包括:
(1)提出了一種支持轉述關系的社交網絡信息傳播模型,針對僅有轉發方式激活新節點的社交網絡傳播模型,增加了模型對轉述行為的支持,能夠有效建模社交網絡中的轉發和轉述行為,為通過轉述行為傳播造成的隱私泄漏追蹤提供數學模型支持。
(2)提出了一種支持轉述行為的信息傳播網絡構建方法,通過求解用戶關注網絡的轉發邊、轉述邊及無行為的三分類問題,判斷網絡中用戶是否參與傳播,預測消息傳播到用戶時的傳播行為概率分布,補充了傳統社交網絡信息傳播途徑遺漏問題。
(3)提出了一種支持隱私保護的社交網絡信息傳播影響力最大化方法LocalGreedy,通過遞增策略構造種子集合,計算節點局部影響子圖,快速計算種子集合傳播產生的影響力,提出節點泄漏態概率上限計算方法,確保種子集合滿足隱私保護約束限制,減少了時間開銷,平衡了影響力和隱私保護的矛盾。
1 相關工作
當前對社交網絡的信息傳播和隱私保護的相關研究主要分為四部分,包括:信息傳播模型、信息傳播預測、影響力傳播和社交網絡訪問控制。
1.1 信息傳播模型
典型的應用于社交網絡的信息傳播模型包括獨立級聯模型[1]、線性閾值模型[2]和傳染病模型[3]。左遙等[4]以獨立級聯模型為基礎,提出了一種用于描述社會化問答網站知識傳播過程的傳播網絡模型,并進一步給出了一種社會化問答網站知識傳播網絡推斷方法。蔡淑琴等[5]基于線性閾值模型和價值共創理論,提出了一種針對負面口碑特征的社會化網絡傳播及企業價值共創策略的模型,并通過仿真實驗,分析了影響負面口碑在社交網絡中爆發的主要影響因素。趙劍華等[6]以傳統的SIR(susceptible infected recovered)傳染病模型為基礎,綜合考慮用戶的心理特征和行為因素,提出了一種新的社交網絡輿情傳播動力學模型,并選用粒子群算法,以2016 年微博上發生的熱點事件為例,求解模型參數的最優解,并進行實驗數據驗證。線性閾值模型的隨機性僅取決于節點被影響閾值的隨機性,且在閾值選擇上有較大的困難;傳染病模型僅適用于對傳播過程的宏觀描述,但未考慮具體的傳播路徑;而獨立級聯模型通過使用邊上的概率來描述信息傳播的強度或發生的可能性,具有較好的擴展性。因此,獨立級聯模型將作為本文提出的信息傳播模型的基礎。
1.2 信息傳播預測
信息傳播預測是指通過一定的方法學習社交網絡中用戶的興趣和行為規律,從而對用戶是否會參與某條信息的傳播進行預測。按照基本假設的不同,用戶信息傳播預測的研究可分為4 類:基于用戶歷史行為的預測、基于用戶文本興趣的預測、基于用戶所受群體影響的預測以及基于聯合特征學習的預測。Pan 等[7]通過捕捉用戶歷史行為中與傳播相關的特征,結合協同過濾和傳播過程的特點建立聯合推薦模型,從而預測基于轉發行為的信息傳播過程。Zhang 等[8]提出了一種結合用戶文本、網絡結構和時間等信息的傳播預測方法,利用非參數統計模型對轉發行為進行推斷,進而預測信息傳播過程。Bian等[9]定義了興趣導向的影響、社會導向的影響和流行病導向的影響,并基于這三種影響的綜合分析來決定用戶是否執行轉發操作。Luo 等[10]基于聯合特征學習,聯合考慮轉發歷史、用戶影響力、時間和用戶興趣等因素,在一個學習排名的框架內,研究各因素對轉發行為的影響。信息傳播預測方法較為豐富,是社交網絡信息傳播分析的重要組成部分。但是,現有研究往往將轉發作為信息傳播的唯一方式,而忽略了其他可能的傳播行為。
1.3 影響力傳播
影響力傳播刻畫影響力在社交網絡中的傳播模式,即節點的狀態如何影響網絡中相鄰節點的狀態,并將該狀態在網絡上進行擴散。優化影響力的傳播是影響力傳播建模的主要目的,而影響力最大化問題是該研究的核心內容,目前的研究方法主要分為三類:根據傳播模型的具體特點設計啟發式算法;對蒙特卡洛貪心算法進行效率優化;以社區發現作為中間步驟,將影響力問題從用戶級別轉化到社區級別。啟發式算法基于直觀或經驗構造,旨在有限時間、空間損耗下對影響力最大化問題給出可行解。Jung 等[11]通過綜合影響排序、影響估計方法,提高算法運行的魯棒性及穩定性;Goyal 等[12]通過引入多個優化策略,以在較短運行時間和較低內存使用下保證最大化影響力種子集合質量。由于貪心策略無法在較短時間內迅速處理包含百萬量級的大規模網絡輸入,因此對蒙特卡洛貪心算法的優化常通過降低運行時間[13],或使用基于草圖[14]的方法解決影響力最大化問題。影響力問題向社區級別轉化的方式從解決啟發式算法無法提供性能保證的角度出發,最大化影響力。Shang 等[15]通過預先計算用戶社區影響,自頂向下選取種子集合,進而實現影響力最大化;Li等[16]提出了一種基于社區發現的種子選擇算法,實現了對最大化問題中種子集合的有效選擇。影響力最大化問題未考慮用戶的隱私保護需求,但相關研究中的啟發式算法相對于其他方法通常有著更快的運行時間和更好的可擴展性,因此本文使用影響力最大化的啟發式算法作為基礎,提出支持隱私保護的社交網絡信息傳播方法。
1.4 社交網絡訪問控制
社交網絡中用戶的隱私包括個人信息和交流信息,為了保證用戶的信息只被用戶信任的人訪問,需要實現用戶節點間的信息訪問控制進行隱私保護。Singh 等[17]設計了一種支持高可用性和實時內容傳播的集中式社交網絡模型,通過學習用戶的社交行為來決定用戶的隱私。Aiello 等[18]提出了一種基于分布式散列表的在線社交網絡架構LotusNet,通過一個靈活細粒度的自主訪問控制單元來控制私有資源,使得用戶可以更簡便地調整他們的隱私設置。然而在實際中,無論是集中式解決方案還是分布式解決方案都不能像預期的那樣保護普適社交網絡通信。為此,一類由二維信任度進行訪問控制的方案被提出[19-20],通過利用信息節點屬性計算節點間二維信任度,并根據二維信任度實現對用戶隱私的訪問控制。但是,現有針對隱私問題的訪問控制研究主要通過對用戶信息采取受限訪問或信任管理措施,忽略了保護用戶隱私的同時最大化信息的影響力傳播。
綜上所述,在已有的信息傳播預測研究中,研究者未考慮將轉述作為信息傳播方式的可能性,這會造成對傳播信息進行溯源時傳播路徑的遺漏,從而在信息傳播建模中發生轉述行為時,無法捕捉隱私信息的泄漏。在影響力最大化問題研究中,各式算法雖從不同角度探索最大化影響力的最佳方案,卻忽略了傳播過程中的隱私保護問題。而對于社交網絡,用戶隱私作為最常見的信息載體,缺少隱私保護措施的影響力傳播方案顯然難以直接應用于實際環境。雖然現有的社交網絡訪問控制研究可以應用于用戶隱私保護,但是研究者僅關注用戶隱私保護問題,忽略了用戶影響力需求。因此,本文針對現有信息傳播模型不能很好建模用戶隱私泄漏產生的原因,以及相關研究難以平衡用戶隱私保護和信息傳播需求的問題,開展了支持隱私保護的社交網絡信息傳播方法研究,在支持最大化信息影響力傳播的同時保護用戶隱私。本文方法的主要應用:
(1)對于個人用戶:發布信息時,只需指定黑名單用戶,算法就能自動給出信息的推送對象,使得信息不會泄漏到黑名單用戶。
(2)對于商家:通過將非目標用戶設置為黑名單,可使用算法發現社交網絡中哪些用戶更有進行廣告投放的價值,進行精準推送。
2 支持轉述行為的信息傳播模型
在用戶發布信息后,關注用戶的好友是信息的直接接收者,信息通過好友的轉發和轉述行為進行傳播。在現有僅考慮轉發行為的傳播模型中,用戶的黑名單對象仍能通過傳播過程中的轉述行為獲取用戶信息。因此,本文的研究問題是構建支持轉述行為的傳播模型,使得信息在滿足隱私保護約束條件下,最大化信息傳播的影響力。
研究思路是基于時間相近、位置相鄰、內容相似規則推斷轉述關系,通過好友關系進行消息傳播預測,利用轉發、轉述關系構成消息傳播網絡,并基于貪心策略計算種子集合獲取信息傳播范圍,最終通過局部影響子圖與泄漏概率上限計算使社交網絡信息傳播過程滿足隱私保護約束的同時最大化傳播影響力。首先給出本文的概念定義。
2.1 概念定義
2.1.1 基本元素
信息是社交網站中的基本單元,它由社交網絡的用戶所發布,可能完全公開(對所有人可見),也可能只對部分人可見,表示為M,信息的發布用戶表示為User(M)。每條信息有唯一標識符,記作mid。在本文中,信息僅針對用戶文本,M和mid間一一對應,對M和mid不作區分,根據上下文不同可以混用。
用戶是社交網站的使用者,也是信息發布者。每個用戶有唯一標識符,記為uid,并用集合U表示社交網絡的用戶集合。在本文中,uid和u間一一對應,對uid和u不作區分,根據上下文不同可以混用。
2.1.2 用戶行為
當用戶在社交網絡中發布一條原創信息M時,將該行為記為Actpost。當社交網絡中的用戶接收到一條信息時,可能會產生不同的行為,這里將其區分為三種類型:
(1)轉發(Forward):用戶u收到信息后,通過社交網絡提供的轉發功能來進一步傳播該信息,該行為記作Actforward。用Forward(M) 表示信息M的轉發信息集合,則M'∈Forward(M)表示信息M'是信息M的轉發信息。
(2)轉述(Mention):用戶u收到信息后,發布了一條新信息,但該新信息與用戶u收到的原信息包含相似的信息,該行為記作Actmention。雖然這種行為從形式上是發布了一條全新的信息,但這里將其視為一種對所收到信息進行傳播的行為,與Actpost進行區分。用Mention(M)表示信息M的轉述信息集合,則M'∈Mention(M)表示信息M'是信息M的轉述信息。
(3)無行為(No Action):用戶u收到信息后,未以任何形式在社交網絡中對該信息進行傳播,該行為記作Actno。
定義1(用戶行為)社交網絡中的用戶行為被定義為式(1)的四元組:
其中,uid是觸發行為的用戶的標識符;acttype是用戶行為的類型,其取值范圍如式(2);time是用戶產生該行為的時間;mid是用戶產生行為的信息的標識符,主要有四種情況:
(1)當acttype=Actpost時,mid是用戶發布的原創信息的標識符;
(2)當acttype=Actforward時,mid是用戶轉發后的信息的標識符;
(3)當acttype=Actmention時,mid是用戶轉述后的信息的標識符;
(4)當acttype=Actno時,mid為空。
例1如圖1 所示,以新浪微博為例,用戶“_奶啤超好喝的”發布了一條信息(參見圖1(a)),接收到信息的用戶“p123TAT”可能存在三種行為:轉發(參見圖1(b))、轉述(參見圖1(c))和無行為。
2.1.3 用戶類型
在社交網絡的不同場景中,用戶會扮演不同的角色類型,下面分社交關系場景和信息傳播場景進行說明:
(1)社交關系場景:在社交關系場景中使用到的用戶類型包括兩種:關注者、被關注者。關注者(Follower)是關注了用戶u的社交網絡用戶,用Follower(u)表示用戶u的關注者集合,Follower(u)?U。被關注者(Followee)是被用戶u關注的社交網絡用戶,用Followee(u) 表示被用戶u關注的被關注者集合,Followee(u)?U。
(2)信息傳播場景:用戶在信息傳播場景中有兩種不同的用戶類型:影響者和被影響者。假設用戶v轉發或轉述了用戶u發布的信息M,則稱用戶u為影響者,用戶v為被影響者。
2.1.4 隱私設置
用戶u在社交網絡中發布的信息M只會被一部分社交網絡用戶直接接收到,并顯示在其關注者動態中,收到信息M的用戶集合記作Viewer(M),Viewer(M)?Follower(u),默認情況下Viewer(M)=Follower(u)。
定義2(信息的黑名單)對于信息M,用戶對信息設置的黑名單記作Blacklist(M),Blacklist(M)?U,黑名單被用作用戶的隱私保護。當信息M是原創信息時,Viewer(M)=Follower(u)–Blacklist(M)。對于一個信息轉發序列
在不同的應用場景下,隱私有著不同的定義。本文將隱私泄漏對象定義為用戶在發布信息時設置的黑名單節點。用戶通過設置黑名單實現對隱私的傳播控制,對于用戶發布的信息M,如果在傳播過程中,黑名單節點接收到信息的概率超過用戶預先設定的泄漏概率上限,則稱隱私發生了泄漏。
2.2 社交網絡信息傳播模型
2.2.1 信息傳播方式
定義3(信息傳播網絡)信息M的傳播網絡是一個有向無環圖GM:
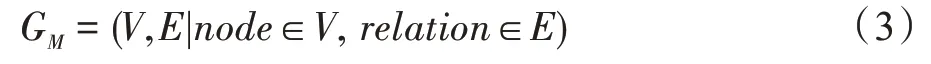
(1)V是網絡中所有節點(node)的集合,其中每個node定義如式(4)。
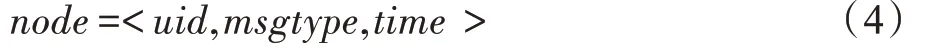
其中,uid是用戶標識符;msgtype描述用戶在信息傳播過程中發布的信息的類型,取值集合為{Equaled,Derived},Equaled 表示用戶發布的信息是信息M的等同信息;Derived 表示用戶發布的信息是信息M的衍生信息;time表示用戶發布信息的時間。
(2)E是網絡中所有關系(relation)的集合:圖GM中從nodein到nodeout的邊代表信息在用戶之間的傳播方式,定義為:
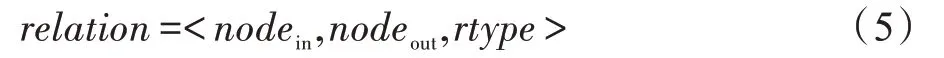
其中,nodein表示傳播的上游節點,即影響者;nodeout表示傳播的下游節點,即被影響者;rtype表示該關系的類型,rtype∈{Forwarded,Mentioned},Forwarded 代表的是nodeout節點對應信息是nodein節點對應信息的轉發,Mentioned 代表的是nodeout節點對應信息是nodein節點對應信息的轉述。
2.2.2 傳播模型定義
在現實的社交網絡中,信息的傳播往往不局限于社交網絡中的轉發功能,還存在著轉述關系。轉發關系易于追蹤和控制,而轉述關系難以追蹤與控制。而在傳統的社交網絡傳播模型,如獨立級聯模型[1]中,每條邊只對應一個屬性,這種局限性使得難以在該模型下區分轉發關系和轉述關系。因此,為了支持轉述行為,本文的社交網絡傳播模型在獨立級聯模型的基礎上進行擴展,通過引入邊的類型以及類型對應的概率分布來描述用戶行為,以便更好地研究社交網絡下的信息傳播和隱私泄漏。
定義4(社交網絡傳播模型)定義社交網絡傳播模型為有向圖G=(V,E,T,P),其中V表示社交網絡中的節點且V=U,eu,v∈E表示社交網絡中從節點u指向節點v的有向邊,tu,v∈T表示節點u和v間連邊的類型,每條邊eu,v僅能屬于一種類型。其中連邊類型與社交網絡中用戶的動作類型一一對應,Tp對應Actforward,Tq對應Actmention,Tr對應Actno。

Pu,v表示節點u和節點v的連邊類型的概率分布,其中u,v∈V。當節點u變為活躍態時,其有且僅有一次機會嘗試以Pu,v的概率分布影響節點v。
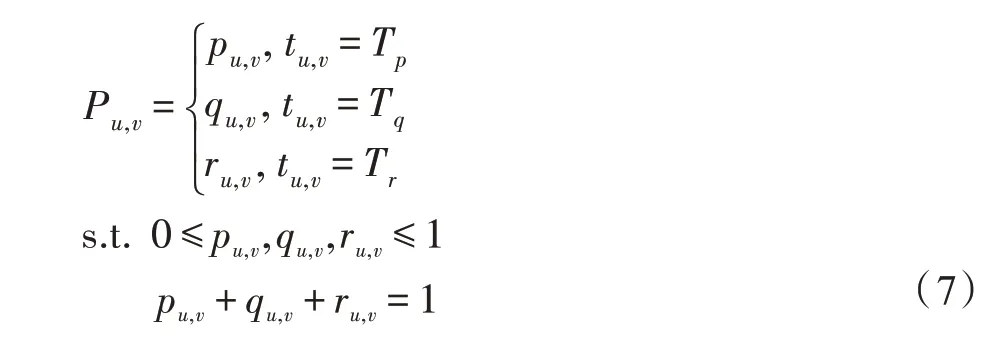
其中,pu,v表示eu,v是一條轉發邊的概率;qu,v表示eu,v是一條轉述邊的概率;ru,v表示eu,v是一條普通邊(無行為)的概率。
對于一條即將發布的新信息M,基于社交網絡信息傳播模型,通過用戶行為的概率分布對信息傳播進行預測,可以確定信息M的傳播過程,從而為最大化影響力和隱私保護提供支持。
定義5(泄漏路徑)定義R(G,u,v)表示社交網絡G上從節點u到節點v的路徑集合。對一條路徑P=
注意,正常情況下包含轉述關系的傳播路徑無法追蹤,定義泄漏路徑是為了在傳播過程中對包含轉述關系的傳播路徑和只包含轉發關系的傳播路徑進行區分,并不意味著信息發生了泄漏。
在社交網絡G中選取一定數量節點構成種子集合S,其中S?V,假設存在路徑集合使節點v的狀態被影響,則影響的方式有兩種:
(1)到達:H(G,S,v)中包含傳播路徑,但不包含泄漏路徑,產生概率用P(G,S,v)表示,簡寫為P(S,v),v被稱為到達態節點。
(2)泄漏:H(G,S,v)中包含至少一條泄漏路徑,產生概率用Q(G,S,v)表示,簡寫為Q(S,v),v被稱為泄漏態節點。
如定義2 所示,對于到達方式,因為傳播路徑上只存在轉發關系,在信息M的傳播過程中,接收用戶對信息所設置的黑名單,會并入到信息M的黑名單中,因此信息M即使被多輪轉發也不會對黑名單中的用戶可見;對于泄漏方式,因為轉述關系難以追蹤,所以與到達方式相比,確定信息是否泄漏到黑名單節點更加困難。
定義6(影響力)定義IG(S)表示選取S作為社交網絡G上信息傳播的種子集合時產生的總影響力,其中:
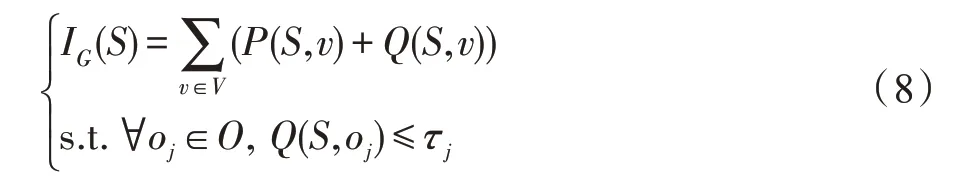
式(8)的約束條件中,O表示社交網絡中的關鍵節點集合,表示黑名單對象,O?V。參數τj表示用戶希望在選擇種子節點集合S時,如果能夠保證信息泄漏到節點oj的概率不超過τj,則種子集合S是合法的。O中每個節點都對應一項隱私保護約束,是一種更一般化的黑名單設置。集合F社交網絡中的可選節點集合,F?V,在實際應用中通常對應信息發布者的關注者集合。需要注意的是,種子集合S必須是集合F的子集,即S?F。
影響力通過到達方式獲得的影響力與泄漏方式獲得的影響力之和計算而得出。在滿足隱私保護約束前提下,通過求解種子集合S,使得用戶發布的信息在社交網絡信息傳播模型中獲得最大的影響力。隱私保護約束由發布信息的用戶設定,包括限制獲取信息的黑名單節點oj以及信息泄漏到oj的概率上限τj。黑名單節點的個數等于在影響力最大化計算時的隱私保護約束個數,在每個黑名單節點上,接收信息的概率都不能超過用戶預先設定的泄漏概率上限。
例2圖2 所示的是基于社交網絡傳播模型構建的信息傳播過程,用戶0 為發布信息M的節點,設可選節點集合F={1,2,3},種子集合S={1,2},關鍵節點集合O={7},信息由種子集合S獲取,并傳播到了其他節點上。對于路徑P1=<2,5> 和P2=<2,5,6>,因為只存在轉發邊,所以P1和P2是傳播路徑,節點5 和節點6 是到達態節點;對于路徑P3=<1,4>,P4=<1,4,7> 和P5=<2,5,7>,因為存在轉發邊,所以P3、P4和P5是泄漏路徑,節點4 和節點7 是泄漏態節點。在保證信息M傳播到黑名單節點7 的概率小于預先設定的上限的情況下,信息M傳播的總影響力大小可由傳播路徑P1、P2和泄漏路徑P3、P4和P5的概率和計算得出。
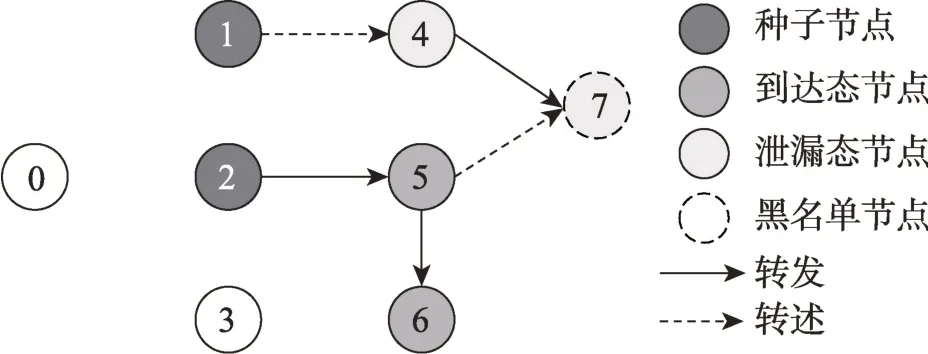
Fig.2 Process of information communication based on model of social network communication圖2 基于社交網絡傳播模型構建的信息傳播過程
3 支持轉述行為的傳播網絡構建方法
對于用戶即將發布的新信息,為了在滿足預先設定的隱私保護約束的同時,最大化信息傳播的影響力,需要基于社交網絡傳播模型,對信息的傳播過程進行預測。而社交網絡傳播模型依賴于用戶行為的概率分布,因此需要構建已發布信息的傳播網絡來訓練用戶行為分類器,從而獲得用戶行為的概率分布。構建支持轉述行為的信息傳播網絡的具體步驟為:
(1)對于用戶已經發布的信息,通過轉述關系推斷,構建信息的傳播網絡,獲取三種用戶行為:轉發、轉述和無行為的標注數據。
(2)利用構建好的訓練數據,通過提取用戶屬性、發布內容和網絡拓撲結構等特征,訓練用戶行為分類器。
(3)對于即將發布的新信息,基于用戶關注關系網絡,結合社交網絡信息傳播模型,通過用戶行為分類器對用戶的三種行為轉發、轉述和無行為的概率分布進行預測,構建信息的傳播過程。
一旦確定了信息傳播過程,就可以通過選取合適的種子集合,使得經由種子集合傳播的信息到達黑名單節點的概率小于泄漏概率上限,在保證隱私保護約束的同時,最大化影響力。
3.1 方法概述
3.1.1 問題定義
構建傳播網絡的難點在于,從社交網絡獲取到的用戶行為只有Actpost和Actforward兩種,而實際上所獲取到的全部Actpost(原創發布行為)中有一部分應當屬于Actmention(轉述行為),與傳播網絡相關,需要進行區分。
定義7(信息傳播網絡構建問題)已知一個用戶us發布信息M的行為Actions=
定義8(添加節點操作)向傳播網絡中添加節點的操作定義為Gafter=AddNode(G,nodeold,nodenew,rtype) 。其中G表示操作前的傳播網絡;Gafter表示操作后的傳播網絡;rtype表示將要添加的關系,取值集合為{Forwarded,Mentioned};nodeold表示G中的一個節點,將作為新添加關系的影響者;nodenew表示添加的新節點,將作為新添加關系的被影響者。
傳播網絡構建過程主要通過添加節點操作完成,初始時建立代表用戶us發布信息M的節點,之后按照時間順序將信息所影響的節點加入到網絡中。
3.1.2 方法步驟
傳播網絡構建的主要過程是將信息M發布后其他用戶發布的等同信息與衍生信息與之進行關聯。對于轉發行為列表Lf,列表中的信息包含了其整個轉發序列的關系,因此很容易添加到傳播網絡中。對于發布行為列表Lp,根據定義4,其中的一部分信息是信息M的衍生信息,對應行為類型Actmention,需要添加到傳播網絡GM中。而另一部分則是其他用戶的原創信息,對應行為類型Actpost,與傳播網絡GM無關。
傳播網絡構建的基本思路是依據時間順序,依次嘗試將當前Action中的信息與傳播網絡中的已有節點建立關系。基本步驟如下:
(1)建立傳播網絡GM的初始節點,
(2)將列表Lf與列表Lp合并后排序得到列表L;
(3)遍歷列表L,假設當前遍歷到的行為是
(4)如果acttype=Actmention,則為信息M'新建節點nodenew,并更新信息傳播網絡GM=AddNode(GM,nodeold,nodenew,Forwarded);
(5)如果acttype=Actpost,則為信息M'新建節點nodenew,并更新信息傳播網絡GM=AddNode(GM,nodeold,nodenew,Mentioned)。
3.2 轉述關系推斷
社交網絡中的用戶行為數據中不包含轉述行為,需要推斷哪些原創信息是其他信息的轉述。轉述關系的推斷基于以下原則:
(1)發布時間相近:兩條信息的發布時間間隔較短。
(2)網絡位置相鄰:轉述信息的發布者是原始信息發布者的關注者。
(3)信息內容相似:兩條信息的主要內容相似。
對于Actiona=
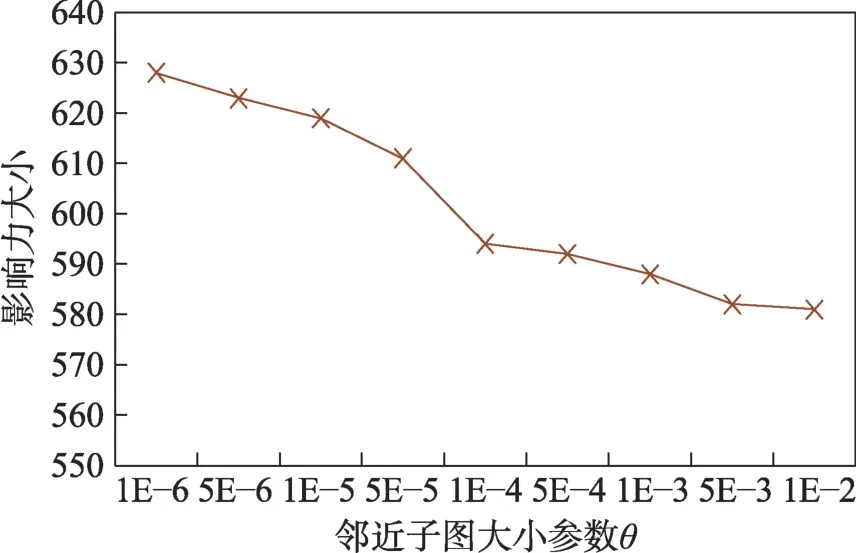
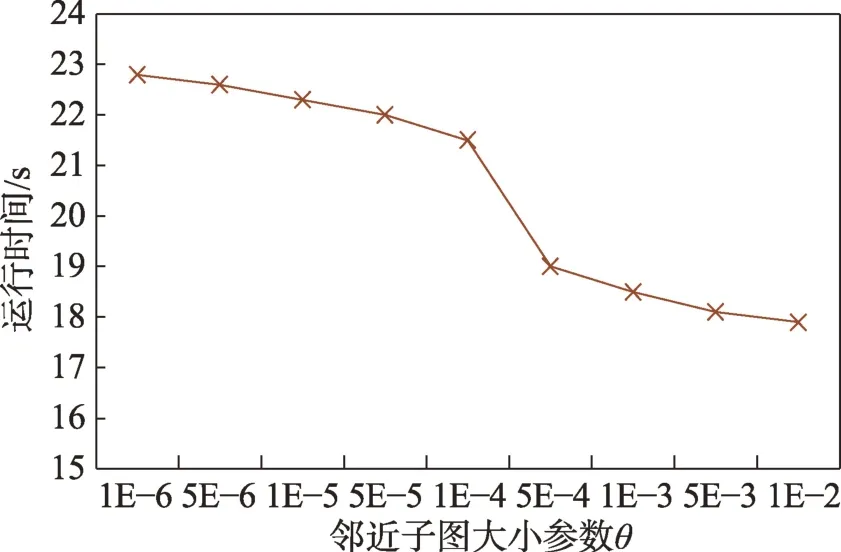
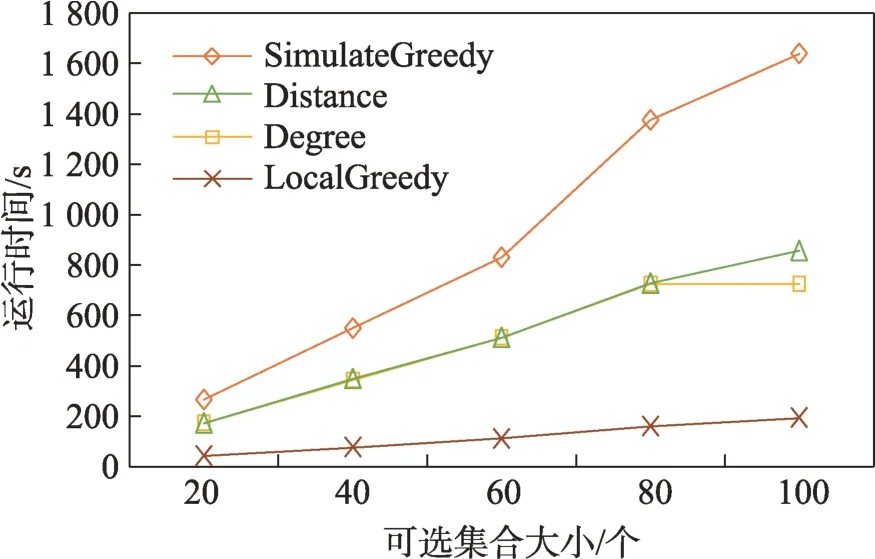
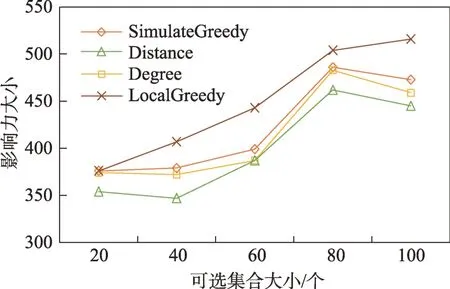
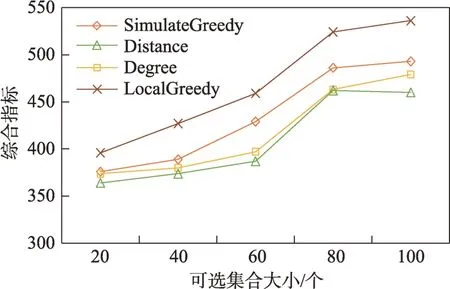
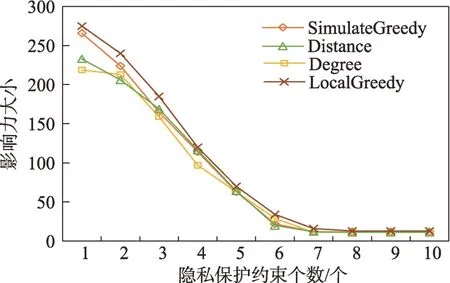
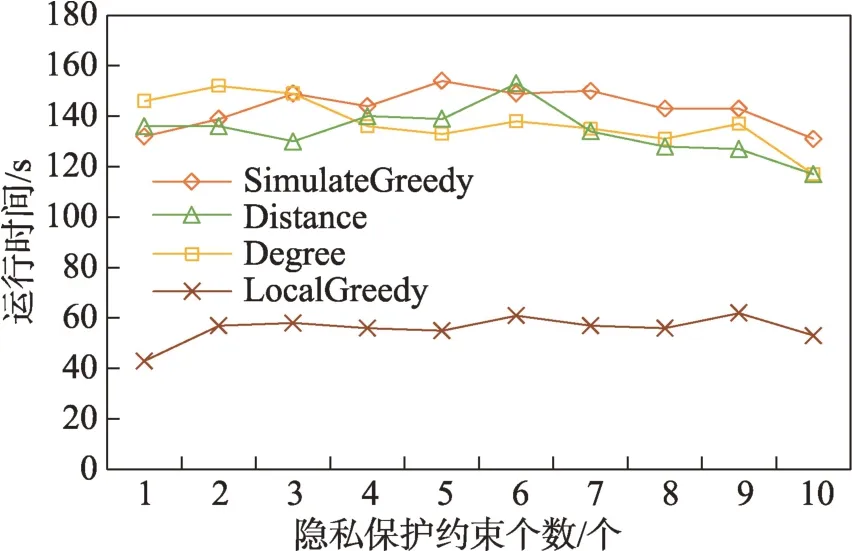
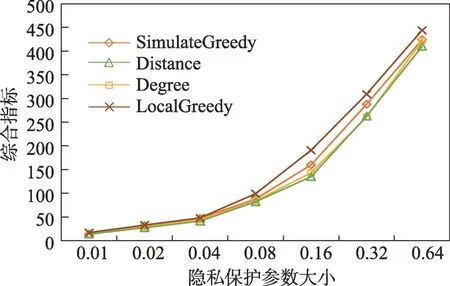
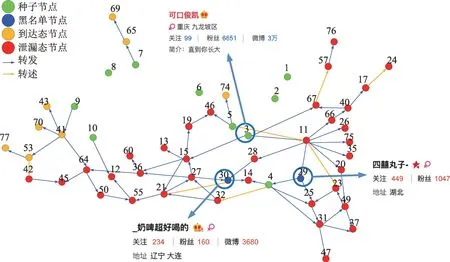
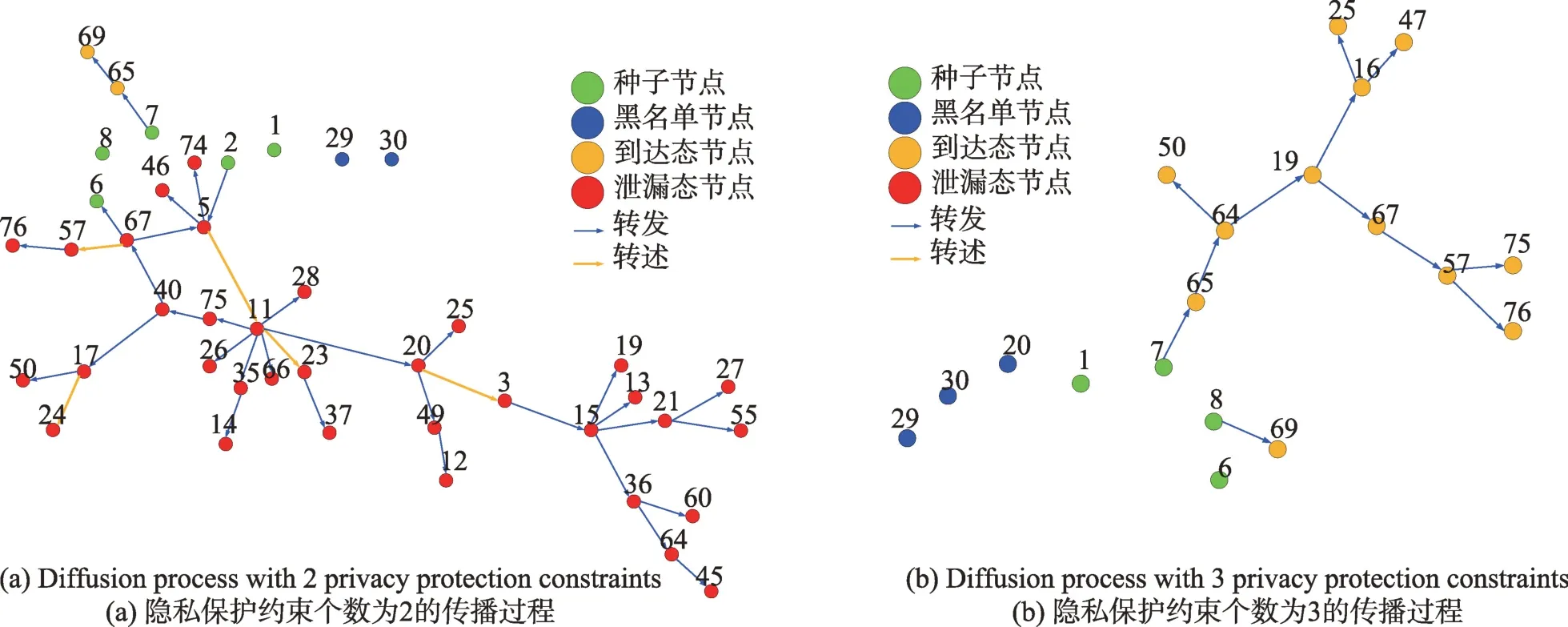
(1)時間相近規則:ta (2)位置相鄰規則:ub∈Follower(ua)。 (3)內容相似規則:Similar(Ma,Mb)=true。 時間相近與位置相鄰規則的判斷易于實現,本文不予贅述,下面討論內容相似規則計算方法。 Similar(M',M)函數通過設置信息的文本相似度函數DocSim(M',M) 的閾值Thdoc和單詞相似度函數WordSim(M',M)的閾值Thword實現,式(9)給出轉述關系推斷規則中內容相似規則的計算方法。 其中,信息的文本相似度函數形式為DocSim:{ 式中,vM、vM'分別為信息M、M'的文本表示,vM、vM'∈Rd。信息的單詞相似度函數形式為WordSim:{ 式中,wordlist(M)、wordlist(M')分別為信息M、M'的單詞序列。 為了做到既能保護用戶在社交網絡中的隱私又最大化用戶的影響力,當用戶輸入將要發布在社交網絡中的信息時,需要能夠對該信息在網絡節點間的傳播方式進行預測。 定義9(信息傳播預測問題)已知一個用戶將要產生的發布信息行為Actions= (1)信息M的等同信息或衍生信息到達用戶u時,用戶u轉發該信息給用戶v的概率pu,v,u∈U,v∈Follower(u); (2)信息M的等同信息或衍生信息到達用戶u時,用戶u轉述該信息給用戶v的概率qu,v,u∈U,v∈Follower(u)。 定義10(用戶關注關系網絡R)R=(VR,ER)記作社交網絡的用戶關注關系網絡,VR是R的節點集合,ER是R的邊集合,滿足以下條件: (1)R是一個有向圖; (2)VR=V; (3)v∈Follower(u)?(u,v)∈ER。 信息傳播的預測問題,可以轉換為社交網絡中用戶關注關系網絡R的三分類問題,即將R中所有邊的類型對應到傳播網絡中轉發邊、轉述邊或無行為三種類型中,這些邊的類型由定義4(社交網絡傳播模型)中的3 種行為(轉發行為Tp、轉述行為Tq和無行為Tr)激活新節點后生成,再通過生成訓練樣本、提取樣本特征、訓練分類模型完成分類。其中生成訓練樣本可以通過使用歷史數據構建的傳播網絡獲得,這里不再贅述。本文使用的特征參考了文獻[21]中提出的內容特征、拓撲結構特征、交互特征以及用戶特征。 根據定義4 的信息傳播模型以及隱私保護約束限制,算法的優化目標如式(12): 式(12)中,IG(S)表示種子集合S在社交網絡G上產生的影響力大小;F表示種子節點的可選集合,即種子集合S必須是F的一個子集;O表示網絡中的關鍵節點集合,默認情況下為設置的黑名單,用戶希望信息以盡可能低的概率泄漏到集合O中的節點;Q(S,oj)≤τj表示隱私保護約束,即選取的種子集合S必須保證信息泄漏到節點oj的概率小于τj,集合O中的每個元素都對應一項隱私保護約束。 隱私保護約束限制下的影響力最大化問題的難點主要有三點: (1)如何選擇種子節點集合,集合F的子集個數有2|F|個,枚舉所有的子集會造成巨大的時間開銷; (2)如何估計種子節點集合產生的影響力的大小,并在社交網絡上產生盡可能高的影響力; (3)如何保證算法生成的種子集合能夠滿足隱私保護約束的要求。 為應對隱私保護約束限制下的影響力最大化問題的三個難點,本節提出了支持隱私保護的影響力最大化方法LocalGreedy。針對種子集合選取時枚舉所有子集的問題,基于貪心策略遞增構造種子集合,避免枚舉造成的時間開銷;給出計算節點的局部影響子圖的方法,快速估計通過種子集合傳播產生的影響力;為確保種子集合滿足隱私保護約束限制,提出了推導節點泄漏態概率上限的計算方法,判斷種子集合是否滿足隱私保護約束,避免使用蒙特卡洛方法產生的時間開銷。本節依次按照種子集合選擇策略、影響大小估計方法以及節點泄漏概率上限計算,分三方面進行算法設計。 為應對4.1 節中的難點(1),本文采用遞增的方法生成種子集合S,初始時令S為空集,并在每輪迭代過程中向集合S添加一個元素。每輪迭代時,在所有添加后滿足隱私泄漏條件約束的節點中,選擇讓影響力增量最大的元素。定義Δ(S)表示算法每次選擇的依據如式(13): 種子集合的選擇基于貪心策略,其依據主要體現在以下兩方面: (1)隱私保護約束與集合S存在單調性,當集合S不符合隱私保護約束的限制時,集合S的任意超集也不符合隱私保護約束的限制,因此從空集開始遞增構造,可以及時中止算法,避免多余的計算; (2)IG(S)同時滿足單調性和子模性,因此每次選擇使得IG(S)遞增量最大的元素添加具有一定的理論保證。 傳統的蒙特卡洛方法在時間效率上十分低效,本節提出一個非蒙特卡洛模擬的方法,快速計算選定種子節點集合后每個節點狀態的概率分布。對于一條長度為l-1 的路徑P= 定義11(最大理想路徑)對于社交網絡G=(V,E,T,P)中從節點u到節點v的所有路徑R(G,u,v),定義最大理想路徑為節點u到節點v間影響權重最大的路徑MIP(u,v),具體如式(14)。 考慮單個節點v被影響的概率,當wp(MIP(u,v))很小時,即使節點u被影響,信息經過其到達節點v的概率通常也會很小,也就是說節點v是否被影響與節點u是否被影響基本無關。那么在估計節點v被影響的概率時,可以只考慮其鄰近區域的節點和邊構成的子圖。 定義12(局部影響子圖) 對于信息傳播模型G=(V,E,T,P)包含節點v的子圖,定義節點v關于θ的局部影響子圖如式(15)。 其中,θ是一個參數,MIA(θ,v) 由所有滿足約束wp(MIP(u,v))>θ的路徑MIP(u,v)取并集得到。 顯然當θ越小時,MIA(θ,v)所表示的節點v的局部影響子圖所包含的邊越多。并且根據定義,局部影響子圖MIA(θ,v)是樹形結構,因此可以使用動態規劃在線性時間復雜度下計算節點v被影響的概率。 本文所提影響力計算方法在僅考慮MIA(θ,v)中的節點和邊的情況下計算節點v最后處于各狀態的概率,處于到達狀態的概率表示為ap(S,v,MIA(θ,v)),處于泄漏狀態的概率表示為aq(S,v,MIA(θ,v))。在不引起混淆的情況下,將ap(S,v,MIA(θ,v))簡寫為ap(v),將aq(S,v,MIA(θ,v))簡寫為aq(v)。更進一步,通過計算所有節點的局部影響子圖獲取各個節點的ap(S,v,MIA(θ,v))和aq(S,v,MIA(θ,v)),可以在不使用蒙特卡洛模擬的情況下,得到種子集合S產生的總的影響力大小的估計值: 通過式(16)可以在不使用蒙特卡洛方法的情況下,高效估計種子節點集合產生的影響力,算法效率僅與節點數n和節點的平均鄰接區域大小Bθ有關,時間復雜度為O(n×Bθ)。加上計算每個節點的局部影響子圖的復雜度,總復雜度為O(n×Bθ×lbBθ)。 考慮節點集合O中的任一節點o,要想使得Q(S,o)<τ,那么對于節點o的入鄰居集合Nin(o),其中的元素處于泄漏狀態的概率不應過大。定義uq(v)表示Q(S,v)的上限,則可以通過以下規則來推斷uq(v)的范圍,使每個節點獲得一個盡可能小的上限,下面給出計算條件。 (1)如果oj∈O,則uq(oj)≤τj; (2)如果uq(v)≤x,則?u∈Nin(v),uq(u)≤x/(pu,v+qu,v)。 uq(v)的值越小則可以通過檢驗式(17)的條件是否滿足,更大地提升算法的效果和效率。 具體地,本文所提節點泄漏概率上限計算方法使用uq(v)來判斷當前的種子集合是否會違反隱私保護約束帶來的限制,即檢查?u∈V,aq(v,θ,MIA(θ,u))≤uq(v)條件是否得到滿足。 節點泄漏概率上限計算方法的本質是對最短路徑算法的一種擴展,通過將原本僅對關鍵節點的限制推廣至全圖,從而在獲取到uq(v)之后,就可以與本文所提影響力計算方法結合,估計種子集合產生的影響力的同時判斷是否滿足隱私保護約束。 為了構建傳播網絡,需要真實的社交網絡數據,這里選擇使用爬蟲爬取新浪微博中用戶的公開信息作為實驗數據。爬取的數據可以分成3 類:微博數據、個人信息數據和社交關系數據。最終爬取到的微博數據中用戶總數為2 903 403,微博總數為23 068 115條,其中轉發微博有7 006 235 條。爬取的微博內容均為用戶在2018 年國慶期間所發布的內容。 對于轉述關系推斷,根據時間相近、位置相鄰規則獲取微博數據子集。并利用內容相似規則,推斷轉述信息,作為轉述關系的標注數據,由于多數包含相同語義的轉述信息的單詞相似度較低,為確保推斷正確的同時獲得更多標注數據,經過多次調整,將文本相似度閾值設置為Thdoc=0.7,單詞相似度閾值設置為Thword=0.12,推斷出258 179 條轉述信息。然后,按照2∶1∶10 的比例生成轉發、轉述和無行為3 種類型的訓練數據,并使用GDBT(gradient Boosting decision tree)[22]和交叉驗證來訓練用戶行為分類器,得到accuracy、micro-F1 和macro-F1 分別為81.2%、84.4%和80.9%,能夠滿足后續預測用戶在接收信息時產生的行為概率分布的需求。 因為在現有微博數據集上無法獲得用戶設置的黑名單節點,所以在進行實驗評估時,通過隨機的方式進行模擬。 隱私保護約束個數(黑名單節點個數)默認情況下為3 個,對應的隱私保護參數(泄漏概率上限)的默認取值范圍為[0,0.1]。不同的算法在進行對比時,使用同一組隱私保護約束和參數。 5.2.1 評價指標與實驗環境 本文使用以微博數據為基礎構建的傳播網絡作為實驗用的社交網絡,并使用3 種指標進行評價: (1)影響力指標:對于算法生成的種子集合S,使用種子集合S滿足隱私保護約束限制時的影響力IG(S)的均值作為評價指標,稱作影響力指標。影響力指標越大時,算法產生的種子集合在傳播過程中產生的影響力越大,效果越好。 (2)綜合指標:考慮到算法的目標有兩個,最大化傳播產生的影響力和滿足隱私保護約束下的限制,這里定義函數F(G,S)作為算法的評價指標,以下均簡寫為F(S),稱作綜合指標: 即當種子集合S不滿足隱私保護約束限制時,F(S)為0,其他情況下F(S)等于種子集合S在網絡上產生的影響力大小IG(S)。對于綜合指標,當算法產生的種子集合S滿足隱私保護約束限制的概率越大時,該指標越大,說明算法效果越好。除此之外,當算法產生的種子集合S產生的影響力越大時,該指標也越大。因此,F(S)是對算法的隱私保護效果和傳播影響力大小的綜合考量指標。 (3)運行時間指標:對于效果相近的算法,更短的運行時間意味著更好的效率,實驗統計各算法的運行時間以評估其效率。 本文的實驗均在單機平臺下完成,包括Ubuntu 16.04.10 操作系統,1 塊Intel Xeon Silver 4110 CPU,2塊NVIDIA GeForce GTX 1080Ti (11 GB) GPU,32 GB內存。所有算法均使用Python3.6 實現。 5.2.2 對比實驗設計 現有的影響力最大化方法主要分為3 種:啟發式算法、蒙特卡洛方法的優化方法、基于社群的算法。由于基于社群的算法難以擴展到用戶隱私保護需求的情形中,而基于蒙特卡洛的方法具有一定的理論保證,且基于節點度和節點在網絡中的距離是常見啟發式算法中的依據,因此本文的對比實驗選取了具有代表性的3 種蒙特卡洛方法:SimulateGreedy 算法、Degree 算法[21]、Distance 算法[21]。其中Degree 算法、Distance 算法均為啟發式算法,算法中的蒙特卡洛模擬部分僅用來判斷種子集合是否滿足隱私保護約束。 (1)SimulateGreedy 算法:依據貪心規則遞增地構造種子集合,需要使用蒙特卡洛來估計影響力大小以及是否滿足隱私保護約束限制。 (2)Degree 算法:以節點的度數為主要依據的度啟發算法,一開始將所有節點按節點度數從大到小進行排序,然后順次嘗試加入種子集合中,需要進行蒙特卡洛模擬。 (3)Distance 算法:以節點到其他所有節點的平均距離為主要依據的啟發式算法,一開始將所有節點按從小到大進行排序,然后順次嘗試加入種子集合中,需要進行蒙特卡洛模擬。 (4)LocalGreedy 算法(本文算法):初始時使用算法CalculateBound 計算每個節點的uq(v),估計種子集合影響力時使用算法LocalInfluence。該算法也遞增地構造種子集合,但不再需要蒙特卡洛模擬。 SimulateGreedy 算法使用蒙特卡洛方法來計算種子集合的影響力,當模擬輪數較大時有較好的理論保證。節點的度數以及節點到其他節點的平均距離是影響力計算研究中經常使用的特征,在影響力最大化研究中也經常被作為算法設計的依據,因此本文將Degree算法與Distance算法作為對比算法。 除了使用F(S)和IG(S)作為判斷算法的效果好壞的依據外,實驗中還依據算法的運行時間來評價其效率。 (1)鄰近子圖大小參數θ對算法的影響 因為LocalGreedy 算法通過參數θ來計算每個節點的局部影響子圖,所以不同的參數θ意味著不同大小的鄰近子圖,從而對算法的效果和效率產生影響。圖3 和圖4 分別繪制了以鄰近子圖大小參數θ作為橫坐標時,算法的影響力指標和運行時間的折線圖。 Fig.3 Influence of θ on effect of LocalGreedy圖3 鄰近子圖大小θ對LocalGreedy 算法效果的影響 Fig.4 Influence of θ on running time of LocalGreedy圖4 鄰近子圖大小θ對LocalGreedy 算法運行時間的影響 當LocalGreedy 算法的參數θ越大時,節點的局部影響子圖越小,考慮的邊數會減少,因而效果會變差,但運行時間會縮短。圖3 與圖4 展示的實驗結果符合預期。綜合圖3 與圖4 的結果,當θ=5E-5 時,算法在運行時間與影響力上取得較好的均衡。 (2)算法各指標對比 圖5、圖6、圖7 分別繪制了以可選集合大小作為橫坐標時,算法的運行時間、影響力指標、綜合指標的折線圖。 Fig.5 Comparison of algorithms running time圖5 算法運行時間對比 Fig.6 Comparisons of algorithms influence index圖6 算法影響力對比 Fig.7 Comparisons of algorithms composite index圖7 算法綜合指標對比 從圖5 中可以看出,隨著可選集合大小的增長,SimulateGreedy 算法的運行時間的增長趨勢最大,Degree 算法和Distance 算法基本相當,本文算法也就是LocalGreedy 算法增長趨勢最小。從運行的絕對時間來看,也是本文算法最好,Degree 算法與Distance算法相當接近,SimulateGreedy算法需要的時間最長。 當可選集合大小變大時,因為可以用作種子集合的節點變多,算法的效果應當越來越好,這從圖6和圖7 都得到了驗證。另外,從圖中還可以看出,運行時間最長的SimulateGreedy 算法在效果上稍好于兩種啟發式算法,而基于節點度數的啟發式算法又更優于基于平均距離的啟發式算法。結合上述的算法效果對比可以得出結論,本文算法不僅在運行時間上相對于主流算法有明顯提升,并且在效果上有一定的優勢。 (3)隱私保護約束對算法的影響 當關鍵節點集合O越大時,隱私保護的約束個數越多,算法求解過程中的限制越多。圖8 和圖9 分別繪制了以隱私保護約束個數作為橫坐標時,算法的影響力指標和運行時間對比的折線圖。當隱私保護的約束個數變多時,本文算法的運行時間有極小的增長趨勢,運行時間優勢明顯。并且在各種不同隱私保護約束個數的情況下,本文算法的效果仍優于其他算法。 Fig.8 Influence of the number of privacy protection constraints on effect圖8 隱私保護約束個數對效果的影響 Fig.9 Influence of the number of privacy protection constraints on running time圖9 隱私保護約束個數對時間的影響 圖10 展示了改變隱私保護參數τ的大小時,算法的綜合指標的變化情況。τ值越大時,隱私保護的約束越弱,算法生成的種子集合越容易滿足隱私保護約束限制,從而產生更高的影響力。本文算法在τ≤0.04 時效果與其他算法相當,對于更大的τ值,本文算法在效果上具有一定的優勢。 Fig.10 Influence of privacy protection parameter on composite index圖10 隱私保護參數大小對綜合指標的影響 本節選取新浪微博用戶關注網絡中一個包含80個用戶節點,985 條關注關系的子圖進行實例展示。設置可選節點集合F={1,2,3,4,5,6,7,8,9,10},集合F同時也是要在社交網絡中發布信息的用戶的關注者集合。并設置關鍵節點集合(黑名單用戶集合)O={29,30},其中標號為29 的用戶微博名為四囍丸子,標號為30 的用戶微博名為奶啤超好喝的,用戶希望信息在傳播過程中不會泄漏到這兩名用戶。 在圖11、圖12 中,綠色節點表示種子集合中的節點,藍色節點表示黑名單用戶,橙色節點表示節點處于到達態,紅色節點表示節點處于泄漏態,其余未受影響的節點未在圖中畫出。圖中的藍色邊表示轉發關系,橙色邊代表轉述關系。 圖11 展示了無隱私保護約束時的傳播過程,此時S=F,可選集合中的所有節點均加入種子集合中,即用戶將信息發布給所有關注者。從圖中可以看出,信息泄漏到了節點編號為29 和30 的兩個黑名單用戶。下面分析信息如何泄漏到節點30 的黑名單用戶,從信息傳播路徑可以看到,存在泄漏路徑<3,15,21,30>,其中邊(21,30)為轉述邊(泄漏路徑中包含至少一條轉述邊),信息通過轉述邊泄漏到了節點30對應的用戶。如果只考慮轉發關系,雖然存在傳播路徑<3,11,28,30>,但是因為節點30 是黑名單中的用戶,信息對該用戶不可見,不會認為產生了隱私泄漏。 圖12(a)展示了為黑名單中用戶添加隱私保護約束后的傳播過程,此時算法為了滿足隱私保護約束,并最大化傳播影響力,輸出S={1,2,6,7,8},可選節點集合中容易形成泄漏路徑的節點未被算法選擇為信息到達節點。例如節點3,微博用戶名可口俊凱,該節點有較高概率通過節點11 形成到節點29 的泄漏路徑,以及通過節點15 形成到節點30 的泄漏路徑。從圖中還可以看出,算法輸出的種子集合不僅滿足了用戶的隱私保護需求(不存在從種子節點到黑名單節點的泄漏路徑),并且還產生了大的影響力,被影響的節點數并沒有明顯減少。 Fig.11 Diffusion process without privacy protection constraints圖11 無隱私保護約束時的傳播過程 Fig.12 Diffusion process with privacy protection constraints圖12 隱私保護約束的傳播過程 圖12(b)展示了添加新的黑名單節點(編號20)后的傳播過程,此時算法輸出S={1,6,7,8},容易形成到節點20 的泄漏路徑的節點2 被排除。實例展示了本文算法可以使社交網絡用戶在信息不泄漏到一部分特定用戶的情況下,讓信息在其他用戶中取得較高的影響力。 針對社交網絡信息傳播過程中,最大化影響力傳播與用戶隱私保護的矛盾,提出了一種支持轉述關系的社交網絡信息傳播模型和推斷方法,以及種子集合選擇算法IncrementGreedy、局部影響計算算法LocalInfluence和節點泄漏概率算法CalculateBound,并在此基礎上提出了LocalGreedy 算法。在爬取的新浪微博數據集上進行了實驗驗證和實例分析,結果表明LocalGreedy 算法能夠確保在保護用戶隱私的情況下,最大化傳播的影響力。 未來研究工作將基于本文提出的模型和方法,進一步挖掘社交網絡信息傳播的特點和隱私泄漏的原因,考慮信息在傳播過程中信息量的變化,并在傳播網絡構建過程中引入更多的特征。
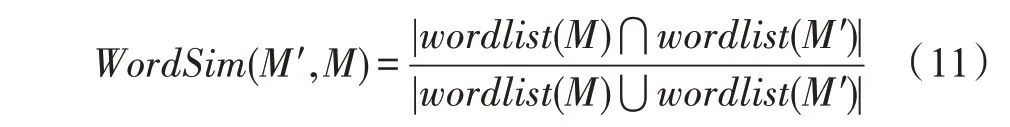
3.3 信息傳播預測
4 支持隱私保護的影響力最大化方法(Local-Greedy)
4.1 方法概述
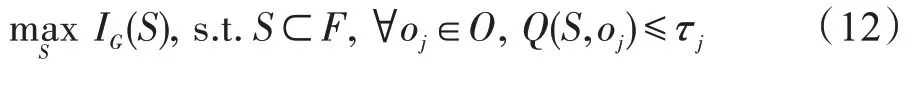
4.2 種子集合選擇策略
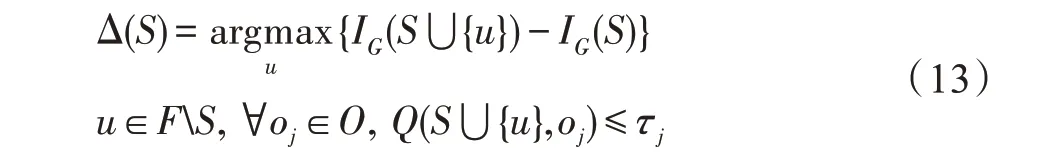
4.3 影響力計算方法
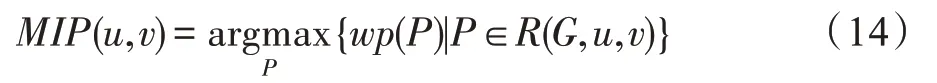
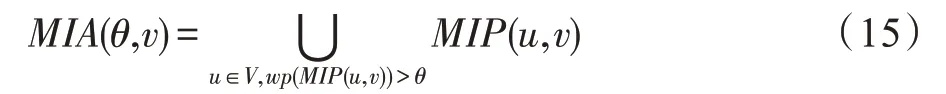
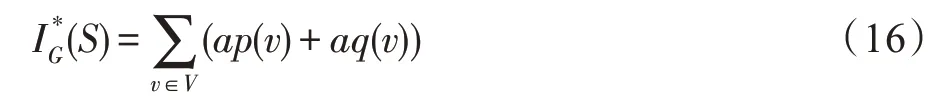
4.4 節點泄漏概率上限計算
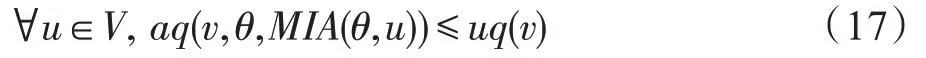
5 實驗與效果評估
5.1 實驗數據
5.2 實驗設計
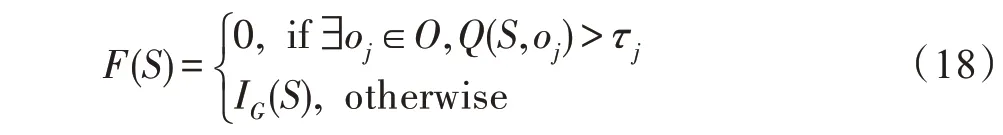
5.3 結果與分析
5.4 實例展示
6 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
