
基于等維新息灰色馬爾科夫的地鐵客流量預測*
2021-02-05 15:27:40王亞飛
中國安全生產科學技術 2021年1期
關鍵詞:模型
路 倩,王亞飛,楊 玲,白 鑫
(1.首都經濟貿易大學 管理工程學院,北京 100070; 2.北京城市系統工程研究中心,北京 100035)
0 引言
目前,我國地鐵建設已步入快速發展階段,較多城市開通了地鐵(包括輕軌)。據有關部門統計,2019年國內各大城市地鐵建設總里程約4 600 km,是10 a前地鐵建設里程的4倍[1]。因舒適性高、運載量大、速度快且受天氣影響較小等優勢,地鐵成了城市軌道交通網絡中發展最為迅速的交通方式[2]。越來越多的人們選擇地鐵作為出行工具,但有限的地鐵車站和站內容量與日益增大的客流量相互矛盾,地鐵人群擁擠并采取限時管制措施已成為地鐵車站常態[3]。而且地鐵車站通常設于地下空間,與其他交通工具所處的外部空間相比相對狹小,通道、安全出口的設置有限,如果發生突發事件極易發生擁擠與踩踏,甚至引起人群恐慌從而導致二次事故的形成[4]。因此對地鐵客流量進行預測,掌握一定時期的客流數量和客流變化規律,對地鐵站的運營管理及保障公共安全具有重要意義。
國內外學者對軌道交通客流預測已經進行大量研究,四階段預測法、灰色模型、回歸模型、SVM支持向量機等均為應用較廣泛的預測方法[5]。Girish等[6]運用深度神經網絡對地鐵客流進行預測,得出性能優于傳統的客流出行需求預測模型的結論;Roos等[7]通過改進期望最大化算法降維,學習動態貝葉斯參數和方法進行預測,預測效果令人滿意,但面對突變客流時預測效果欠佳;Liu等[8]將改進優化粒子群算法與最小二乘支持向量機相結合,同時加入purning算法進行客流預測,得出此方法預測小樣本非線性數據效果良好;葉紅霞[9]引用非集計模型分析突發事件下乘客出行行為特征,建立突發事件情境下的客流分步預測算法;劉先超等[10]利用Eviews軟件確定時間序列模型參數,建立較為理想的SARIMA模型,并以青島3號線客流為基礎進行驗證;王茁等[11]引用BP神經網絡模型對軌道交通日客流總量進行預測,預測計算精度達到87.3%,但僅適用于軌道交通開通初期的客流預測;仇建華等[12]以軌道交通突發客流量為研究對象,引用基于貝葉斯稀疏理論的相關向量機模型進行預測,得出模型經優化后其泛化能力更強,能夠精準預測的結論。
關于地鐵客流預測方面,國內外學者所取得的成果較豐富。但是,多數預測方法需要大量原始樣本數據進行長時間的訓練和優化處理,得出的結果才能令人滿意,對于波動數據的預測能力普遍較弱。為解決此問題,本文提出等維新息灰色GM(1,1)模型與馬爾科夫理論相結合的地鐵客流組合預測模型,結合所需樣本少和對波動大的數據精準預測2種特點,以期為相關單位了解地鐵客流趨勢和采取管控措施等提供參考。
1 組合預測模型的構建
1.1 灰色GM(1,1)建模過程
設X(0)為由n個數據組成的非負原始數據序列,X(0)={x(0)(1),x(0)(2),…,x(0)(k),…,x(0)(n)}。
在進行預測之前需要對數據序列進行檢驗處理,確定是否滿足建立灰色預測模型的條件。通常用數列的級比σ(0)(k)(k=1,2,…,n)的大小與所屬區間的對應程度來檢驗是否符合建模要求,如式(1)所示:
(1)
式中:n為數據個數。
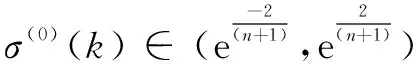
1)對原始數列進行一階累加生成,弱化數據的波動性和隨機性,形成新的數據序列X(1)(k)={x(1)(1),x(1)(2),…,x(1)(n)}。其中x(1)(k)計算如式(2)所示:
(2)
式中:i為原始數據序列的位數;k為新數據數列的位數。
2)新生成序列近似服從指數規律,對其建立預測模型,如式(3)所示:
(3)
式中:a為模型的發展系數,反映X(1)以及X(0)的變化趨勢;u為模型的灰作用量,反映數據之間的變化關系。
3)引入數據矩陣B,Yn,運用最小二乘估計一階線性微分方程的待估參數a,u,如式(4)所示:
(4)
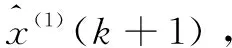
(5)
5)累減還原得式(6):
(6)
1.2 等維新息灰色GM(1,1)模型預測原理
等維新息灰色GM(1,1)模型是將原始數據序列經過灰色預測得到1個預測值x(0)(n+1),將得到的預測值加入原始數據序列最后,摘除原始數據序列的第1個數值x(0)(1),總體保持數據序列{x(0)(2),x(0)(3),…,x(0)(n+1)}的數據個數不變,運用組成的新數據序列進行GM(1,1)模型,得出預測值的下一個值。如此不斷地加入新數據,刪除舊數據,直到完成預測目標為止[13]。等維新息灰色預測模型流程如圖1所示。
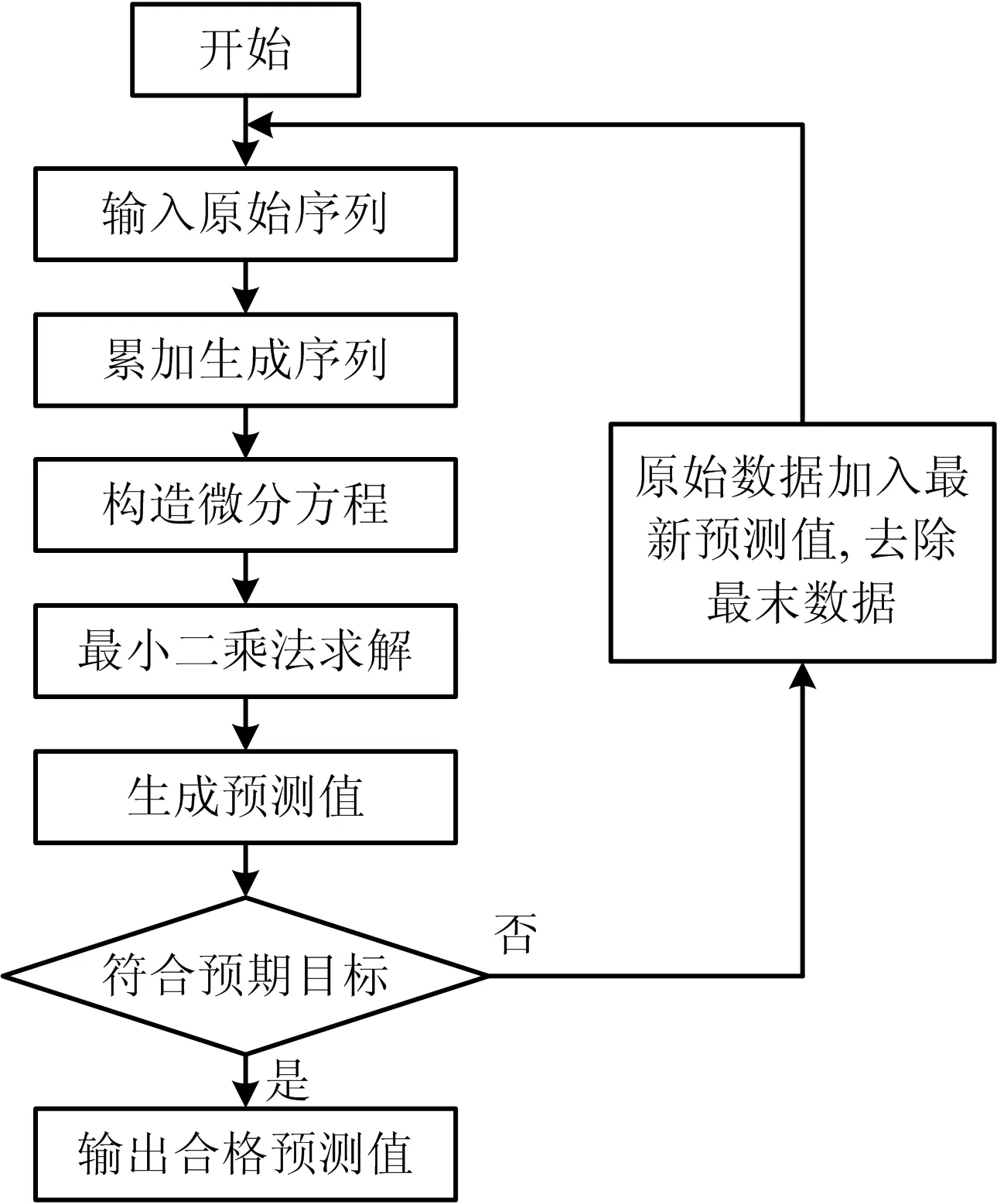
圖1 預測流程Fig.1 Prediction flow chart
一般來說,在等維新息灰色GM(1,1)預測模型中,原始數據序列的數據個數不能少于4[14]。在實際建模過程中,也需要考量模型的精度和實現效果來確定原始數據的使用個數,并非所有的原始數據均使用效果最好。
1.3 模型精度檢驗
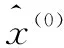
1)后驗差比值檢驗
殘差序列如式(7)所示:
(7)
殘差序列均值計算如式(8)所示:
(8)
相對誤差計算如式(9)所示:
(9)
平均相對誤差計算如式(10)所示:
(10)
方差比計算如式(11)所示:
(11)
2)小概率誤差檢驗
小概率誤差計算如式(12)所示:
(12)
一般情況下,將模型精度劃分為4個等級,具體各指標見表1[15],表1中3個精度指標若有1個不滿足當前精度等級即視為預測精度未達到當前等級。

表1 模型精度等級劃分Table 1 Classification of model accuracy
1.4 馬爾科夫模型修正過程
當建立的模型精度經檢驗不合格時,需要考慮對原模型進行修正,從而提高預測精度。馬爾科夫模型根據狀態之間的轉移概率描述過程的變化狀態[16]。模型步驟如下:
1)狀態劃分
根據馬爾科夫鏈,按照等概率原則將數據序列分成若干狀態,任一狀態區間可表示為:Em∈[E1m,E2m],其中,E1m和E2m為狀態E的上下限。狀態劃分數量與實際值和預測值的相對誤差范圍以及樣本的數量有較大關系。為提高對波動數據修正的有效性,并提高客流預測精度,本文將狀態劃分為3個。
2)計算概率,確定狀態轉移矩陣
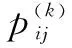
(13)
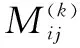
狀態概率組成的k步狀態轉移矩陣如式(14)所示:
(14)
式中:R(k)為由狀態概率組成的k步狀態轉移矩陣。
若V(0)為初始狀態Ei的初始向量,則經過k步轉移之后,狀態向量V(k)如式(15)所示:
V(k)=V(0)×R(k)
(15)
在實際應用中,一般只需考察1步轉移概率矩陣R。
3)計算預測值
馬爾科夫運行過程無后效性,假設預測對象處于Ek狀態(k=1,2,…,m),則只需了解狀態轉移矩陣第k行的概率即可,如果在某一行中第i列的轉移概率值最大,那么可以認為下一時刻預測對象由Ek狀態轉向Ei狀態的可能性最大[17]。當矩陣中第k行有2個或者2個以上概率相同時,如果第k行為第1行或最后1行,則取靠兩邊的列;如果為中間行,則取靠中間的列[18]。
4)計算修正后的預測值
預測對象下一步所處狀態Ej,其區間值為[E1j,E2j],則通過模型預測值的修正公式如式(16)所示:
(16)
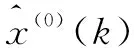
2 實例分析
本文以北京軌道線網日均客運量為研究對象,選取2009—2018年全網日均客流量作為原始數據序列,數據見表2。

表2 2009—2018年北京軌道線網日均客運量分布Table 2 Distribution of average daily passenger flow in Beijing rail transit network from 2009 to 2018
2.1 北京地鐵客流量灰色GM(1,1)預測
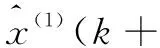
2.2 客流量等維新息灰色GM(1,1)預測
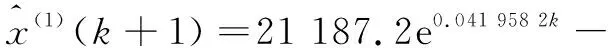
灰色GM(1,1)模型和等維新息灰色GM(1,1)模型的預測結果見表3。

表3 灰色GM(1,1)模型和等維新息灰色GM(1,1)模型的預測結果Table 3 Prediction results of grey GM(1,1) model and equal dimension and new information grey GM(1,1) model 萬人·次
以上2種預測模型精度對比結果見表4。
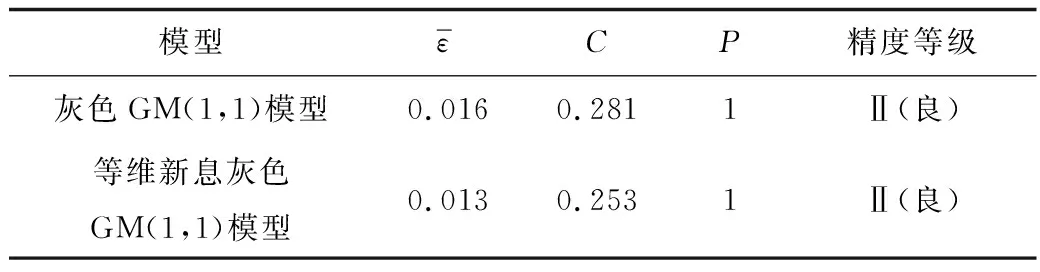
表4 2種模型的預測精度對比Table 4 Comparison on prediction accuracies of two models
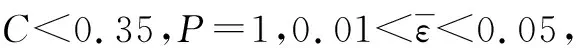
2.3 預測結果馬爾可夫模型修正
將由等維新息灰色GM(1,1)預測的獲取相對誤差值劃分為3種狀態,分別記為E1=(0.14%,2.17%),E2=(-1.90%,0.14%),E3=(-3.43%,-1.90%)。從以上狀態分類中可獲得2013—2018年統計范圍的狀態轉移情況,見表5。
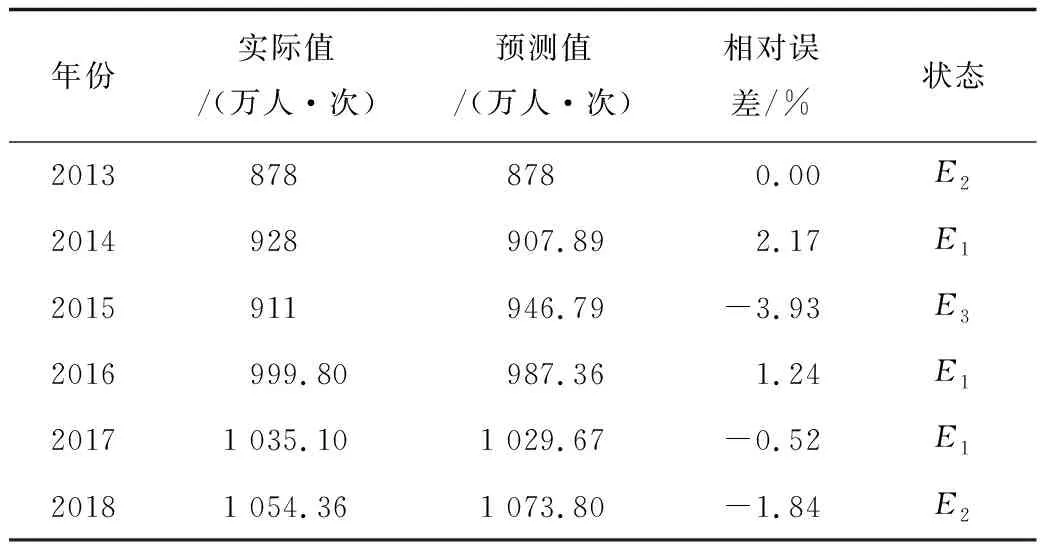
表5 狀態劃分情況Table 5 Status division
由表5可知,E1共出現了3次,E2共出現了2次,E3共出現了1次。根據式(13)~(14),1步轉移矩陣根據原始狀態樣本數和轉移的樣本數的比值為:
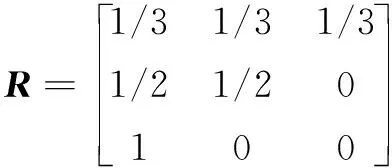
多步狀態轉移矩陣R(k)=(R)k。
當預測值相對誤差較小時,不需要利用馬爾科夫模型修正(一般小于1%),故2013年、2017年的預測值不需要修正。以2014年的預測值修正為例,計算經過灰色等維新息馬爾科夫模型修正后的預測值,2014年度的預測誤差處于狀態E1,按照上述狀態轉移概率,下一步狀態轉移位置為E3,則根據式(16),修正后的預測值為:
同理,其他年份的預測值,可用馬爾科夫修正其他年份的客流量預測值,修正結果見表6。
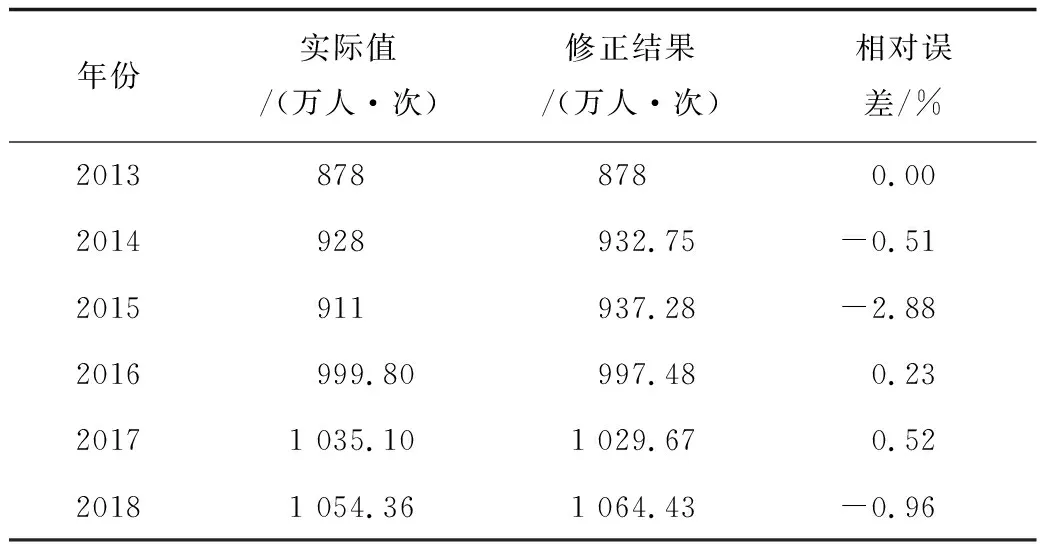
表6 馬爾科夫修正結果Table 6 Results of Markov correction
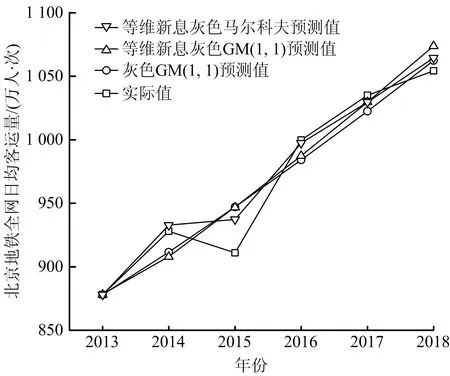
圖2 3種模型預測結果曲線Fig.2 Curves for prediction results of three models
3種模型的相對誤差對比圖如圖3所示。其中,ε1為灰色GM(1,1)模型進行預測后與原始數據的相對誤差;ε2為等維新息灰色GM(1,1)模型進行預測后與原始數據的相對誤差;ε3為等維新息灰色馬爾科夫模型預測后與原始數據的相對誤差。對比3種模型的相對誤差,整體來看等維新息灰色馬爾科夫模型表現更好,誤差更小。
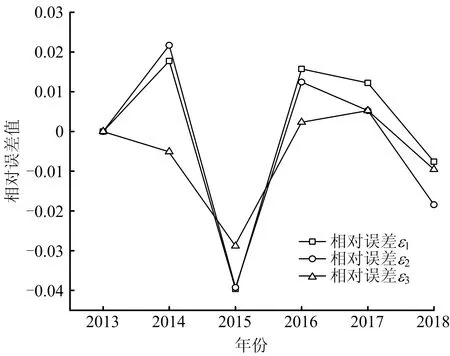
圖3 3種模型相對誤差值對比Fig.3 Comparison on relative error values of three models
運用等維新息灰色GM(1,1)模型對2019—2021年3 a北京地鐵的全網日均客運量進行預測。首先預測2019年北京地鐵的全網日均客運量,根據馬爾科夫模型的預測經驗,選擇距預測年份最近的3 a作為預測基礎年份,根據各年份的狀態及轉移步數,得到北京地鐵的全網日均客運量的累積轉移概率見表7,2016年、2017年和2018年3 a向2019年轉變的狀態轉移概率相加,得到的最大數值是1.56%,處在E1(0.14%,2.17%)的范圍內,所以未來1 a最有可能存在于狀態E1。根據同樣的方法計算未來2,3 a的狀態轉移概率,從而得出當年的客流量值。
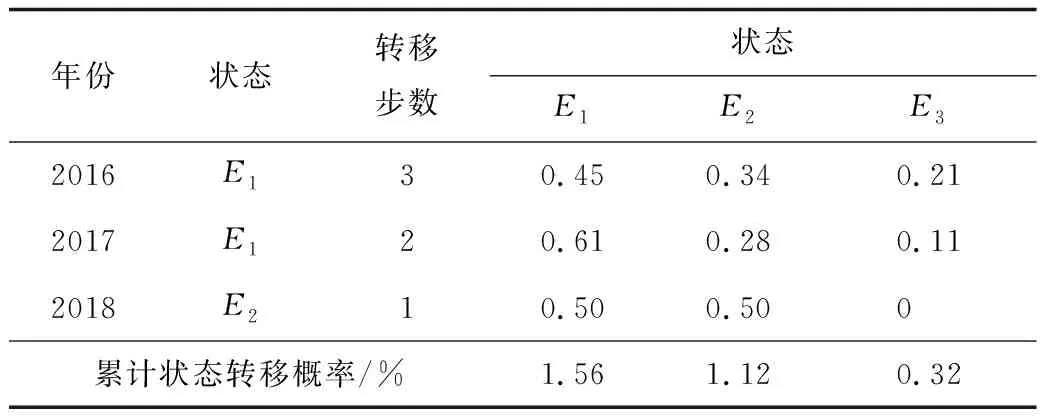
表7 2019年北京地鐵的全網日均客運量狀態預測Table 7 Prediction on status of average daily passenger flow in whole network of Beijing Subway in 2019

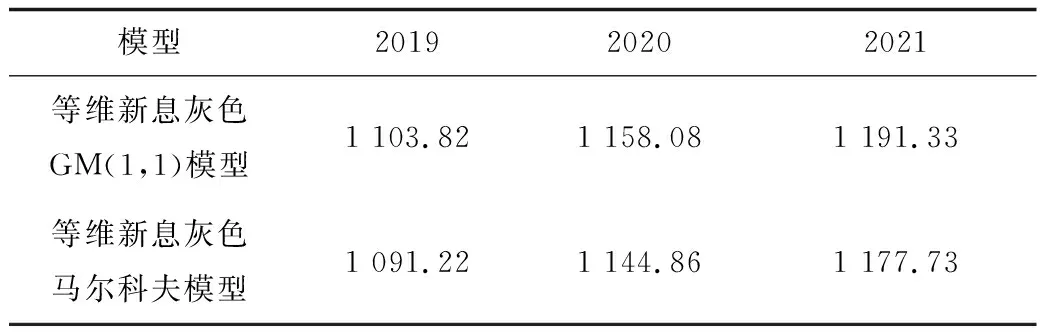
表8 2019—2021年全網日均客運量預測值Table 8 Prediction values of average daily passenger flow in whole network from 2019 to 2021 萬人·次
由北京市軌道交通指揮中心提供的數據可知2019年日均客運量為1 085.58萬人次,可以看出等維新息灰色馬爾科夫預測值與實際值更為接近,正常情況下未來北京地鐵的全網日均客運量仍然會呈現逐年增長的態勢,可以根據預測值來采取管控措施或進行資源設備的合理配置,使地鐵利用率實現最大化。
3 結論
1)為精準預測地鐵客流量,了解地鐵客流的變化趨勢,采用等維新息灰色馬爾科夫模型,對比灰色GM(1,1)、等維新息灰色GM(1,1)2種模型,相對誤差值、后驗差比值和小概率誤差精度的表現均有提高,可以看出等維新息灰色馬爾科夫預測模型在地鐵客流量預測方面表現優越,對比其他2種方法,預測精度表現為Ⅰ級(優)。
2)提出的模型結合使用樣本數量少的灰色模型和處理波動數據序列能力優異的馬爾科夫模型2種模型的特點,運用小樣本預測地鐵全網日均客運量,預測精度更高,預測曲線具有波動性,更加符合我國歷年來全網日均客運量的變化特點。
3)運用新模型預測3 a的客運量,發現未來的客運量趨勢仍持續走高,需要提前采取管控措施應對未來的客流增長趨勢,以便保障乘客通行安全和地鐵高效運營。
4)等維新息灰色馬爾科夫模型的預測精度相對其他2種模型預測精度更高,但波動較大的時間節點仍存在較大誤差,下一步將考慮對這些誤差較大的時間節點預測值進行再處理,以達到更加精準的效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
