引入深度強化學習思想的腦-機協作精密操控方法
2021-02-22 01:46:28張騰張小棟張英杰陸竹風朱文靜蔣永玉
西安交通大學學報 2021年2期
張騰,張小棟,2,張英杰,2,陸竹風,朱文靜,蔣永玉
(1.西安交通大學機械工程學院,710049,西安;2.西安交通大學陜西省智能機器人重點實驗室,710049,西安)
隨著人工智能技術的發展,對具有仿人高級認知能力、能在復雜環境中執行非設定任務的智能機器人的需求日趨緊迫,但是單憑人工智能技術尚無法滿足。因此,研究者提出了人-機智能融合方法,該方法結合了人的直觀推理、自組織學習以及處理非結構化信息的能力,同時兼具機器強大的計算能力、存儲容量和不知疲倦的特性,目的在于充分發揮人和機器兩者的優勢。隨著人-機智能融合系統所面臨任務和場景的復雜化,研究者在人-機智能融合的基礎之上,提出了一系列腦-機智能融合增強技術,例如腦控汽車[1]、腦控無人機[2]、腦控外骨骼機器人[3]、腦控輪椅[4]以及腦控假肢[5-6]等。然而,在精密操控領域(例如醫療、軍事和太空探索等),與肢體操控方式相比,腦控方式在穩定性和安全性上還存在風險。因此,目前在精密操控領域依然以人的肢體操控方式為主,例如手術機器人[7]、排爆機器人[8]、武器操控系統[9]以及在軌對星球表面遙操作系統[10]等。經過研究發現,在人-機交互的精密操控領域,由于缺乏操控者和機器之間信息的雙向交互,無法實現對操控者意圖的精密感知;同時,由于人腦精神狀態(例如疲勞、專注度和腦力負荷等)的變化會影響肢體操控的精度和安全性。
對此,有關學者在精密操控領域引入腦-機接口技術,在不改變肢體操控方式的前提下,使用表面腦電信號(EEG)檢測操控者的精神狀態,并根據操控者的精神狀態對機器人的指令進行補償調控,以實現精密操控。目前國內外相關的研究主要分為兩個方面:操控者精神狀態檢測研究和基于精神狀態的補償控制研究。
在操控者精神狀態檢測研究方面:Dijksterhuis等要求駕駛員在駕駛任務中,執行不同難度等級的駕駛任務,利用EEG識別駕駛員的腦力負荷,平均識別精度達到95%[11];朱成杰等提出在飛行任務中EEG的各種節律波會隨著飛行員疲勞狀態和腦力負荷的變化而改變,因此利用EEG檢測技術可有效識別飛行員的疲勞狀態和腦力負荷[12];Wang等在多屬性任務組(MATB)中,要求受試者執行3種難度等級的MATB任務,以2~100 Hz的EEG傅里葉變換系數為特征,對受試者腦力負荷的識別精度進行測試,結果表明其識別精度可達80%左右[13]。上述研究均證明了EEG可有效地反映操控者的精神狀態,但是目前的研究還僅停留在精神狀態的檢測和識別方法上,并未考慮精神狀態和操控品質之間的聯系。
在基于精神狀態的補償控制研究方面:Wilson提出了一種自適應自動化系統,該系統可根據人的腦力負荷動態分配機器和人之間的任務屬性和等級,目的在于提高操控品質[14];Jia等在遙操作任務下,根據操控者的精神狀態實時調控機器人的速度和響應時間參數,目的在于提高操控的精度和安全性[15];楊少增采用模糊建模方法建立了人的精神狀態估計和預測模型,以使操作員所承擔的任務與其當前的狀態兩者相匹配[16]。然而,目前大多數的研究,多預先設定所謂的精神狀態“好與壞”的表現特征,從而主觀認為當檢測到精神狀態“好”的特征時就增加任務難度,反之則降低任務難度,忽略了精神狀態的多樣性(尤其是在跨個體和跨時間角度上精神狀態的多樣性更強),從而導致精神狀態和控制指令之間失匹配,無法有效提高操控品質和安全性。
綜合上述兩方面的研究現狀,發現兩個方面多單獨研究,沒有形成一體化的腦-機協作模型;同時,基于精神狀態的補償控制方面主觀性強,未考慮到精神狀態的多樣性。因此,針對人-機交互精密操控領域亟待解決的這兩大基礎共性問題,本文以機器人最基本的軌跡跟蹤任務為應用目標,提出一種引入深度強化學習思想的腦-機協作精密操控方法。首先結合人在上層規劃與機器在精細控制上的優勢,提出雙環路的人-機之間信息交互機制,進而建立一種基于深度強化學習的一體化的腦-機協作方法模型;然后設計相應的精神狀態實時監控方法,開發一套具有工程應用價值的腦-機協作精密操控算法;最后擬搭建具有3種難度等級的軌跡跟蹤虛擬環境,并設計訓練實驗、驗證實驗和對照實驗,以驗證腦-機協作精密操控方法的有效性。
1 雙環路人機信息交互機制
本文融合人在上層規劃與機器在精細控制上的各自優勢,提出了由主動操控環路和被動調控環路組成的雙環路人-機信息交互機制,如圖1所示。考慮到人在上層決策、突發情況處理方面的優勢,因此在軌跡跟蹤任務中,使操控者對機器人方向指令的控制具有優先權。在主動操控環路中,操控者通過操控裝置發送方向指令給機器人,同時通過視覺等信息對機器人的運行狀態進行監督,實時地調整方向指令,并對突發的錯誤進行糾正;考慮到機器在精細控制上的優勢,使計算機對機器人速度指令的控制具有優先權。在被動調控環路中,引入深度強化學習思想[17],創新性的將操控者大腦作為環境對象,將控制算法作為智能體對象,建立一體化腦-機協作方法模型,其以反應操控者精神狀態的EEG微分熵特征作為輸入,以機器人速度指令作為輸出。模型經過多次自主訓練,將多樣性的精神狀態和機器人的控制指令相匹配,從而促進人-機之間相互適應和監督,實現人腦和計算機協同合作(簡稱腦-機協作)執行精密操控任務。

圖1 雙環路人機信息交互機制
在一體化腦-機協作模型訓練階段:操控者通過肢體操控方式發送方向指令的同時,腦電設備采集大腦EEG并傳給控制算法,控制算法根據當前EEG生成相應的速度指令,機器人根據方向指令和速度指令執行相應任務。此外,操控者在監視和操控機器人時,會引發精神狀態變化(例如:機器人犯錯會引發大腦警覺;操控任務復雜且長時間執行任務會由于高腦力負荷而引發大腦疲勞;操控任務過于單一會引發大腦專注度下降等)。精神狀態的變化會影響肢體操控的精度和安全性,因此腦電采集設備將EEG實時輸入控制算法,控制算法及時決策機器人的速度指令。機器人每執行一次完整實驗,控制算法會根據任務完成精度和時間兩個指標計算獎勵值并更新模型中網絡參數,直到控制算法中網絡模型收斂并達到獎勵最大化。在一體化腦-機協作模型驗證階段:將訓練好的控制算法參數導入到機器人的控制器中,通過所建立深度神經網絡感知操控者精神狀態,利用強化學習方法根據精神狀態決策機器人的速度指令,從而實現腦-機協作精密操控。此模型利用深度強化學習理論建立腦-機之間一體化的架構,真正實現了雙環路的交互機制。
2 腦-機協作方法數學模型
本文所建立的腦-機協作方法模型屬于“免模型強化學習”范疇,因此,本文根據蒙特卡羅采樣原理[18],從任意起始精神狀態s1出發,使用某種策略G進行采樣,執行該策略i步并獲得軌跡τ,詳細的采樣過程如圖2所示。獲得采樣軌跡τ的概率可由下式表示
pθ(τ)=p(s1)pθ(a1|s1)p(s2|s1,a1)pθ(a2|s2)
p(s3|s2,a2)…pθ(ai|si)p(si+1|si,ai)=
(1)
式中:si(i=1,…,k)表示第i時刻的精神狀態(以下簡稱狀態);ai(i=1,…,k)表示第i時刻的機器人速度調節動作(以下簡稱動作);pθ(τ)是指給定策略神經網絡參數θ的情況下,出現采樣軌跡τ的概率;p(s1)是指初始狀態s1出現的概率;pθ(ai|si)是指給定當前狀態si,采取動作ai的概率;p(si+1|si,ai)是指采取當前狀態si和動作ai之后,基于該條件概率返回下一個狀態si+1的概率。
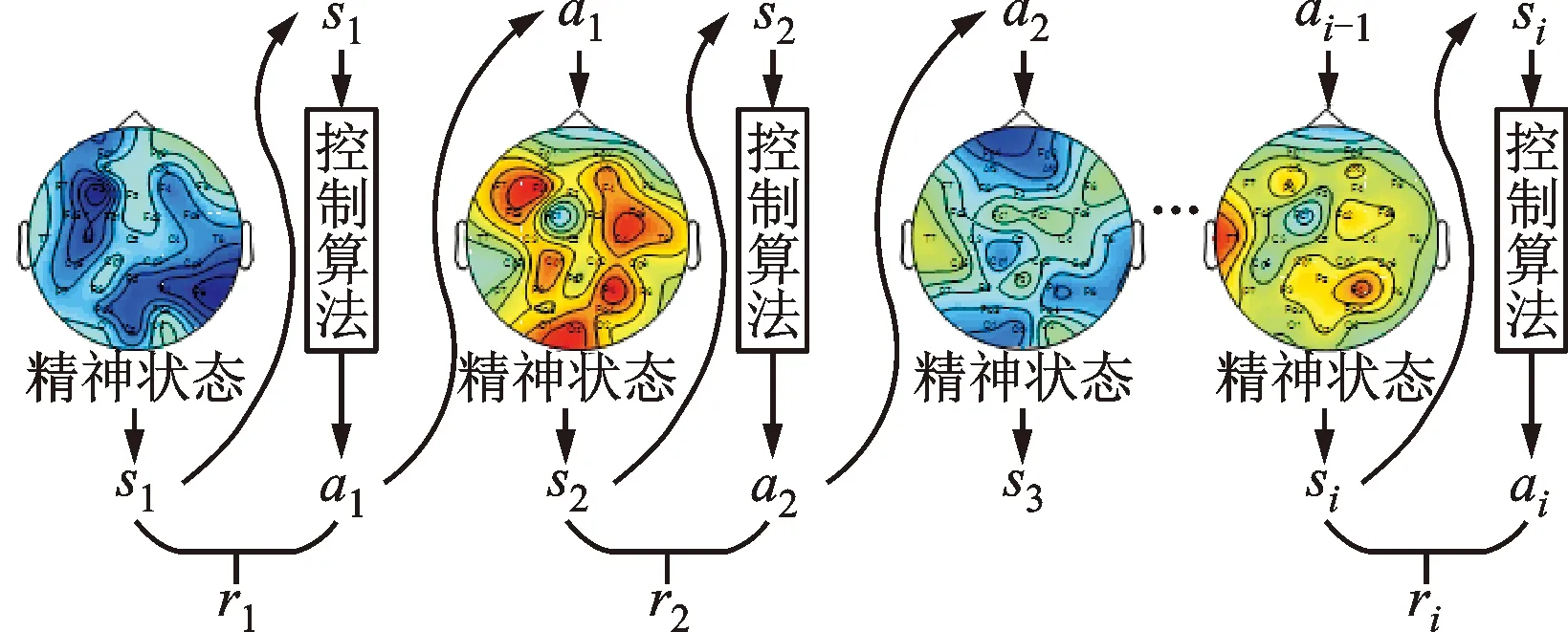
圖2 腦-機協作方法模型蒙特卡羅采樣示意圖
對于某一個采樣軌跡τ,可以得到其對應的獎勵,通過優化控制算法,可以得到不同的獎勵。由于控制算法采取的動作以及出現某一個狀態是隨機的,最終的目標是找到一個具有最大期望獎勵的策略神經網絡參數,因此目標函數如下
(2)
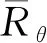

(3)
式中:n為采樣次數;N為總采樣數。由式(1)和式(3)可得
(4)
為了使獎勵值R(τ)不受采樣隨機性的影響,這里引入一個基準線b,因此梯度公式優化為
(5)
式中:精神狀態si由所采集到的EEG的微分熵特征來表示;機器人速度指令ai由神經網絡的輸出值而獲得;獎勵值R根據機器人執行任務品質評分獲得,詳細介紹見第3節。首先將原始EEG進行濾波和降采樣預處理;其次進行小波分解與重構;最后計算微分熵特征。其中,小波分解與重構過程如下
(6)
式中:xj表示第j個頻帶的EEG;L表示分解層數;Aj表示近似分量;Dj表示不同尺度的細節分量[19]。
對于固定長度的腦電序列可進行如下近似處理計算微分熵[20]
(7)
式中:s(x)表示微分熵特征值;f(x)表示時間序列的概率密度函數;μ和σ分別表示高斯分布的均值和標準差。
最后,利用梯度下降法更新策略神經網絡的參數θ,直到網絡模型收斂,具體算法如下
(8)
3 腦-機協作精密操控算法
為了將反映精神狀態的實時EEG輸入給控制算法的模型,每次實驗總是提取計算機內存中最后1 000 ms長的EEG作為輸入信號。對輸入信號的處理主要分為3個階段:①預處理,采用4階巴特沃茲帶通濾波器處理EEG,保留0.5~45.0 Hz的頻帶信號,然后進行降采樣處理;②小波變換處理,采用5階Daubechies小波基函數,從EEG中分解并重構出5種節律波,小波分解原理如圖3所示;③特征提取,分別計算32個通道的5種節律波的微分熵特征,形成160維的特征數據矩陣S,S即作為反映操控者精神狀態的特征輸入給腦-機協作方法模型。
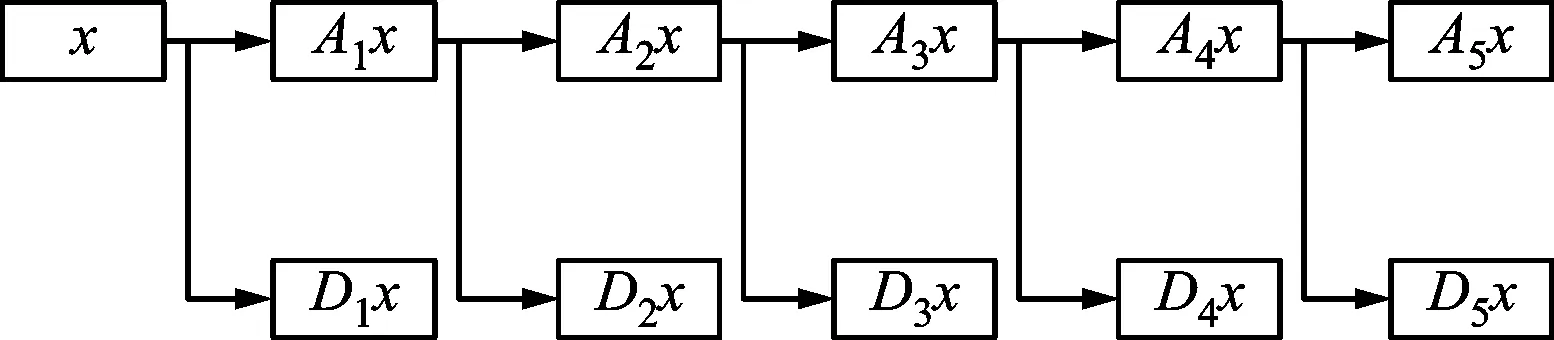
圖3 5層小波分解原理圖
在腦-機協作方法模型中為了兼顧算法精度和響應速度,本文建立了3層全連接神經網絡,詳細的網絡拓撲結構如圖4所示。網絡輸入為精神狀態(即表征精神狀態的特征矩陣S),輸出為機器人速度指令ai。其中輸入層有160個神經元,隱含層有80個神經元,輸出層有4個神經元,分別表示4種無量綱的速度等級(0.5、1、2和2.5)。隱含層采用tanh激活函數[21],輸出層經過softmax函數[22]處理之后,利用隨機策略選擇速度指令ai,其中概率值高的被選中幾率高,反之,被選中的幾率低,目的在于符合“探索”和“利用”平衡的原則(EEb),從而獲得最大的獎勵。獎勵值R由軌跡跟蹤精度和完成時間兩項指標組成,詳細表達式如下
(9)
式中:Y表示機器人的行走軌跡;O表示目標軌跡;T表示每實驗一次完成的時間;g表示時間系數;M表示整個軌跡的總步數。將數據組(s,a,R)輸入給目標函數,根據自適應矩估計梯度下降法(ADAM)[23]更新神經網絡參數,其中學習率(rL)設置為0.001。訓練階段每執行一次完整實驗,模型更新一次,直到模型收斂為止。
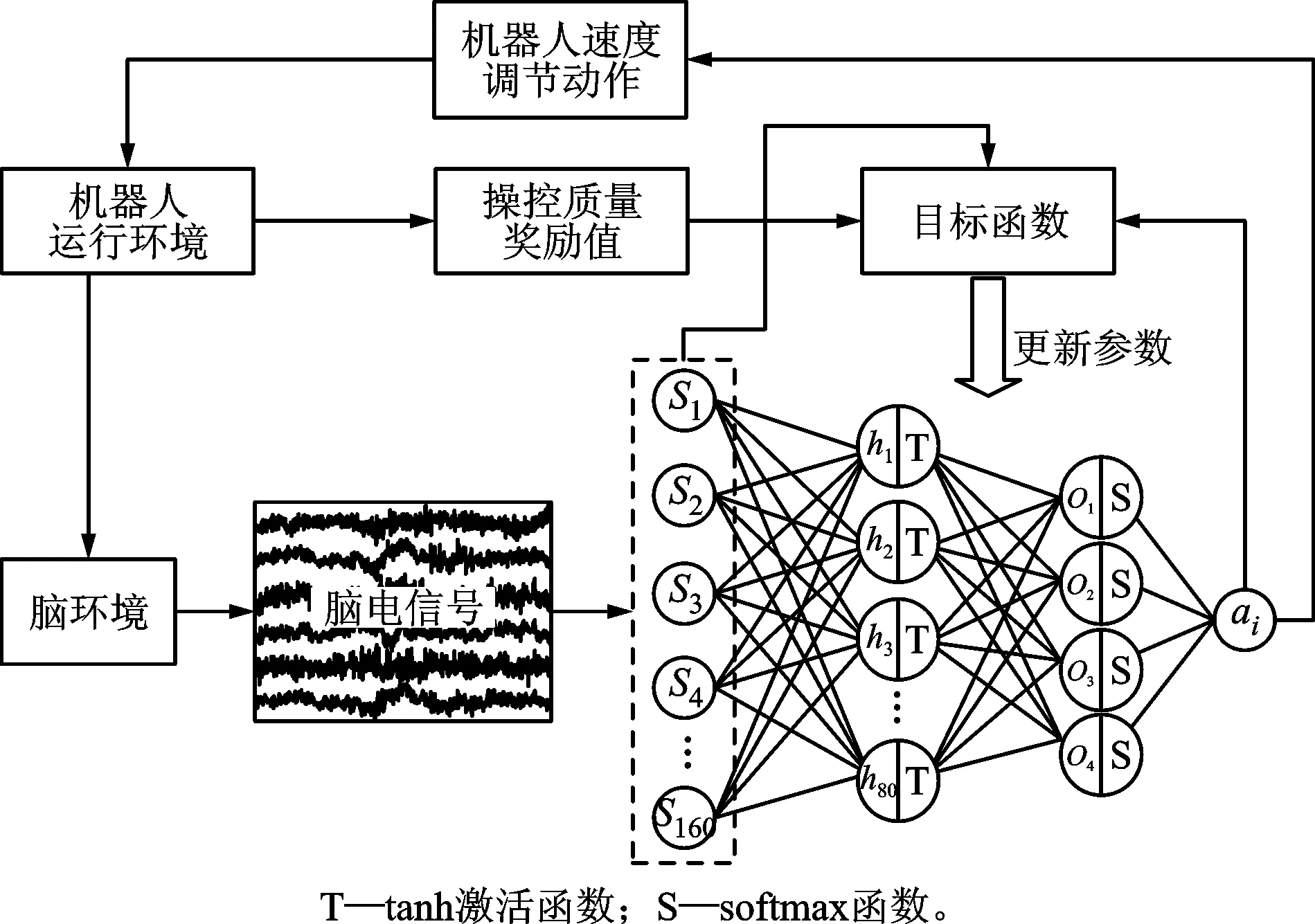
圖4 腦-機協作方法模型參數更新原理圖
4 實驗驗證分析
4.1 環境平臺及實驗系統創建
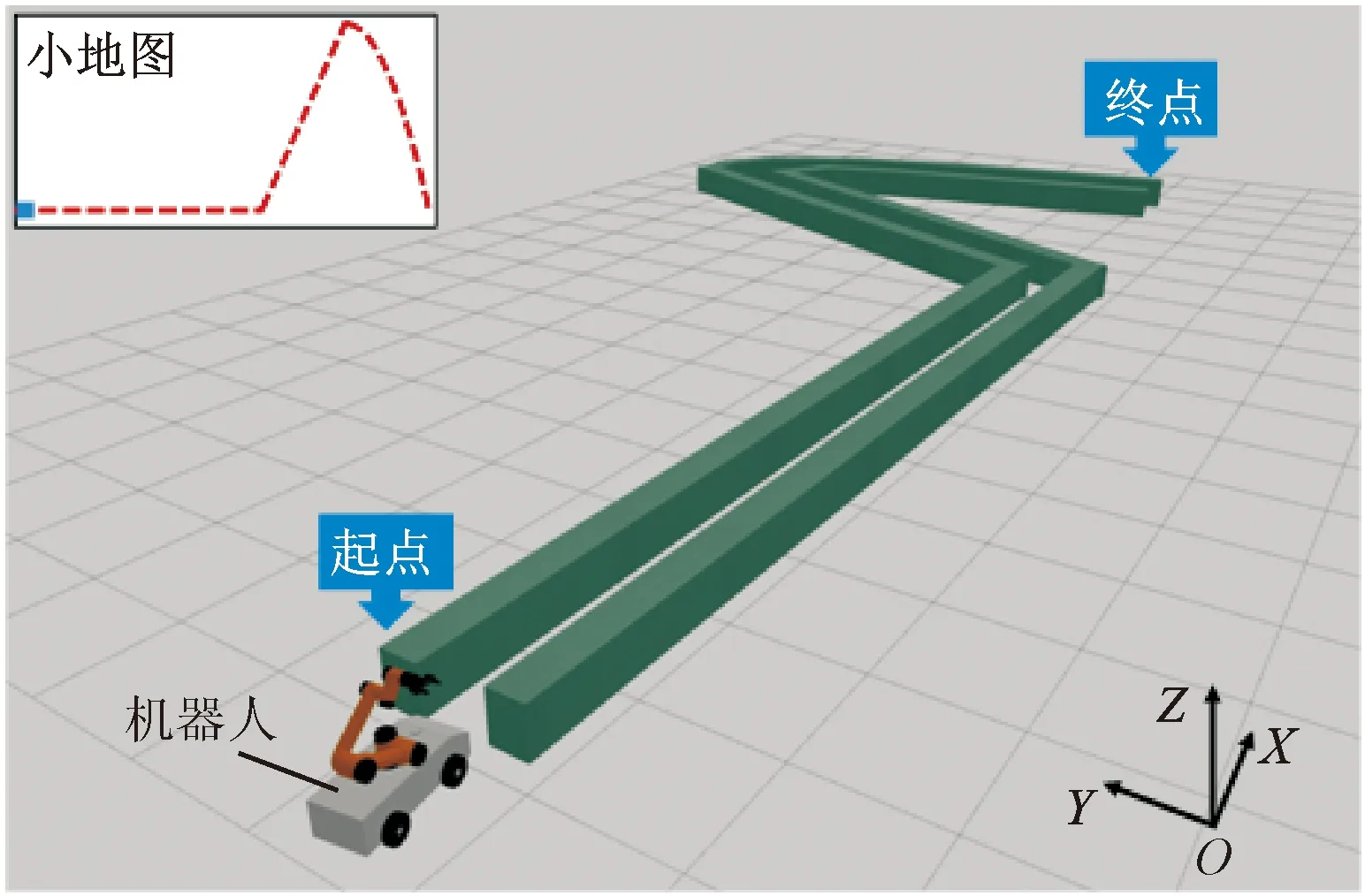
(a)軌跡跟蹤環境
為了驗證腦-機協作方法的有效性,本文以精密操控機器人執行軌跡跟蹤任務為例。此任務作為遠程操控特種機器人排爆、消防、救援等領域關鍵的任務之一受到廣泛關注。本實驗搭建了一個腦-機協作操控的軌跡跟蹤環境平臺,具體如圖5a所示,操控者通過鼠標控制機器人執行軌跡跟蹤任務。為了增加實驗的多樣性,設計了水平直線、斜線和曲線3種難度等級的軌跡。實驗場景如圖5b所示,其中機器人的方向指令由操控者通過鼠標控制,速度指令由計算機中的控制算法根據操控者精神狀態的變化不斷地調節,機器人結合方向和速度兩項指令,執行規定的任務。在軌跡跟蹤任務中,操控者通過觀察機器人的運行狀態,不斷調整方向指令,同時計算機中的控制算法通過檢測人腦精神狀態實時調整機器人的速度指令,從而通過腦-機協作,實現對機器人的精密操控。每完成一次完整實驗,控制算法會記錄機器人行走的軌跡和完成時間,并根據此兩項指標計算獎勵值,具體計算方法如式(9)。控制算法中的神經網絡模型根據獎勵值更新參數,直到神經網絡模型收斂。
實驗采用博睿康公司(Neuracle)開發的32通道的腦電采集設備,如圖6a所示,其采樣頻率為1 000 Hz,通過無線路由與電腦相連。本實驗按照國際10-20系統選擇腦電通道,具體電極分布位置如圖6b所示。

(a)采集設備
4.2 受試者及實驗步驟
本次實驗共有5名受試者(標記為Sub1~Sub5,其中1名為女性),年齡均在23~30歲,無精神疾病史,視力或矯正視力在1.0以上。實驗過程中要求受試者靜坐在電腦屏幕前,通過鼠標控制屏幕中的機器人執行軌跡跟蹤的任務。每完成3種預設軌跡(水平直線、斜線及曲線)的跟蹤任務即為完成一次實驗的全過程。實驗共分為3個階段,分別為訓練階段、驗證階段和對照階段。訓練階段用來訓練腦-機協作方法模型參數;驗證階段是將訓練好的腦-機協作方法模型輸入到機器人的控制器中,進行驗證實驗;對照階段不使用腦-機協作方法(即傳統方法),其他設置與驗證階段相同。訓練階段實驗執行65次,前5次用來練習軌跡跟蹤任務,防止因為操作的熟練度不同而影響實驗結果,后60次為正式實驗。每20次中間有1 min的休息時間。對照階段實驗和驗證階段實驗各執行25次,前5次均用來練習軌跡跟蹤任務,后20次為正式實驗,具體實驗步驟如圖7所示。
考慮到精神狀態的多樣性,每名受試者在一天之中不同的時間段進行實驗(例如Sub1的實驗時間為20:00~22:00;Sub2和Sub5的實驗時間為9:00~11:00;Sub3的實驗時間為14:30~16:30;Sub4的實驗時間為16:30~18:30),適當增加了表征精神狀態的EEG數據的多樣性。考慮到每名受試者實驗的舒適度,實驗時長為2 h。
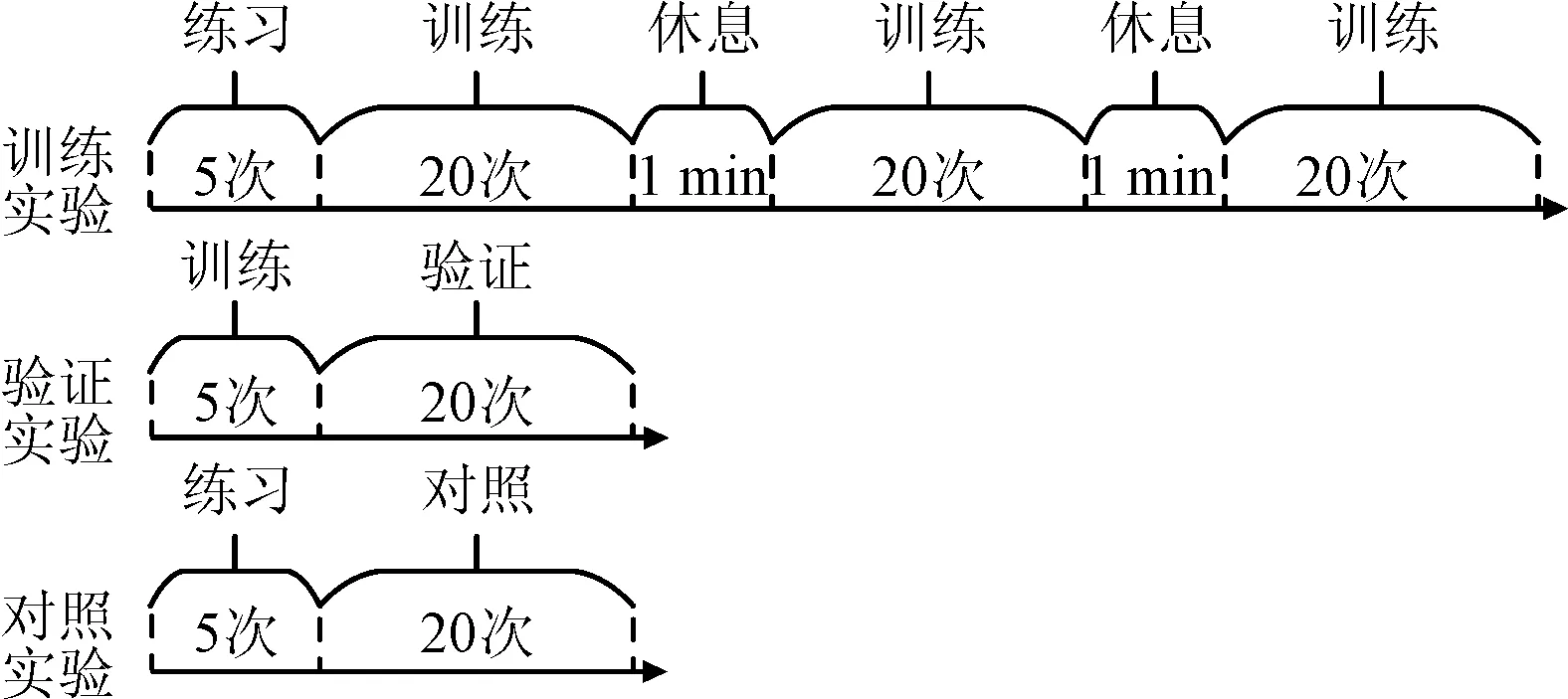
圖7 實驗步驟示意圖
4.3 ADAM優化器學習率分析
通過研究發現ADAM優化器中學習率會影響腦-機協作方法模型的訓練效果。分析其原因是由于在模型收斂過程中發生了梯度消失或梯度爆炸的現象。因此為了驗證此猜測,這里進行一個離線的測試,選擇受試者Sub1的對照組實驗數據,以圖4中的3層全連接神經網絡為基礎,建立精神狀態影響下的操控品質預測網絡,分別設置6種ADAM優化器學習率rL參數,分析學習率與損失函數值之間的關系,具體如圖8所示。損失函數值越小,代表神經網絡收斂性越好,訓練效果越好,反之損失函數值越大,則神經網絡收斂性差,訓練效果差。當rL≥0.1時,由于梯度爆炸原因使誤差曲線出現了二次震蕩的現象,并且rL值越大,震蕩越劇烈,波峰的橫坐標值越大,從而造成收斂速率慢,訓練效果差。當rL≤0.01時,由于避免了梯度爆炸而使震蕩現象消失。在0.001~0.01之間,rL值越小,初始損失函數值越低,整體收斂效果越好,但是當rL值降低至0.000 1時,由于梯度消失的原因使收斂速率驟然變慢,當迭代50次時,損失函數值是rL=0.001時的15倍,是rL=0.01的28倍;當迭代100次時,損失函數值是rL=0.001時的5.8倍,是rL=0.01時的5倍。實驗結果顯示:當rL在0.001附近時,既可以避免由于梯度爆炸造成的訓練模型魯棒性差的問題,又可以避免由于梯度消失造成的訓練模型收斂過緩的問題,因此可達到最優的訓練效果。
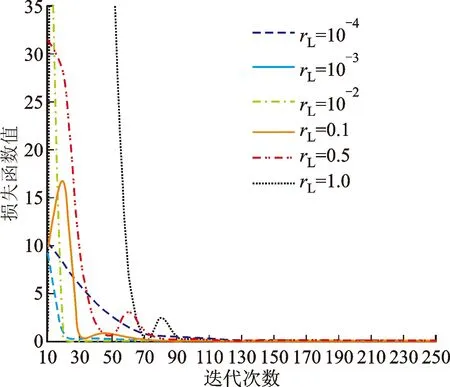
圖8 學習率與損失函數值間關系
4.4 操控品質分析
為了驗證面向精密操控軌跡跟蹤任務的腦-機協作方法的有效性,這里主要通過腦-機協作方法模型收斂性和軌跡跟蹤任務完成品質兩個方面分析。選擇具有代表性的受試者Sub1為例進行討論,該受試者一共進行了8組訓練實驗,其模型收斂曲線如圖9所示,縱坐標為獎勵值,代表操控品質。圖中置信區間的上限和下限分別為95%。前22次實驗曲線呈現劇烈震蕩狀態,并且置信區間范圍較大,說明數據概率分布不穩定。之后模型逐漸穩定,并達到收斂,獎勵值穩定在相對較高的1.92水平,其置信區間范圍變窄,說明數據概率分布穩定,操控品質維持在相對較高水平。但是,其中仍然存在輕微波動,例如第39和第49次實驗的獎勵值出現明顯的降低,這是因為在訓練過程中,腦-機協作方法模型在輸出動作指令時按照EEb原則,存在輸出非最優速度的概率,會導致受試者的操控品質降低。
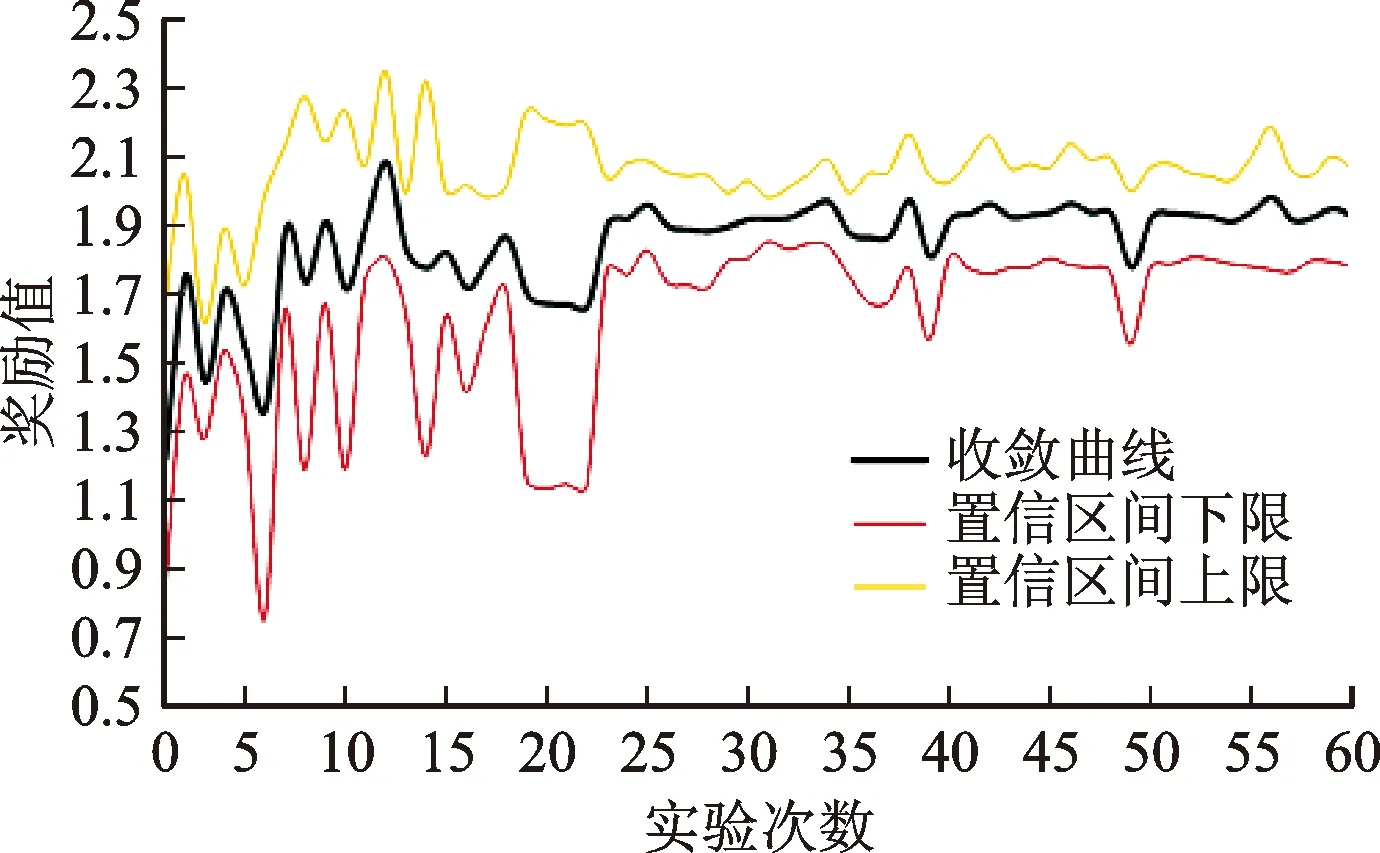
圖9 訓練模型收斂曲線圖
將受試者Sub1訓練實驗中的腦-機協作方法模型參數導入到驗證實驗中,對操控品質進行分析,驗證實驗與對照實驗對比曲線如圖10所示。由圖10可以看到,對照實驗曲線在20次實驗中劇烈振蕩,這是由于對照實驗中機器人的速度無法與操控者的精神狀態匹配,導致獎勵值變化劇烈,且大多數獎勵值很低,操控品質很差。相反,驗證實驗曲線在20次實驗中始終保持在一個相對較高的獎勵值水平上輕微浮動,說明操控品質良好。原因在于腦-機協作方法可根據操控者的精神狀態匹配最優的機器人速度,從而有效提高了操控品質。
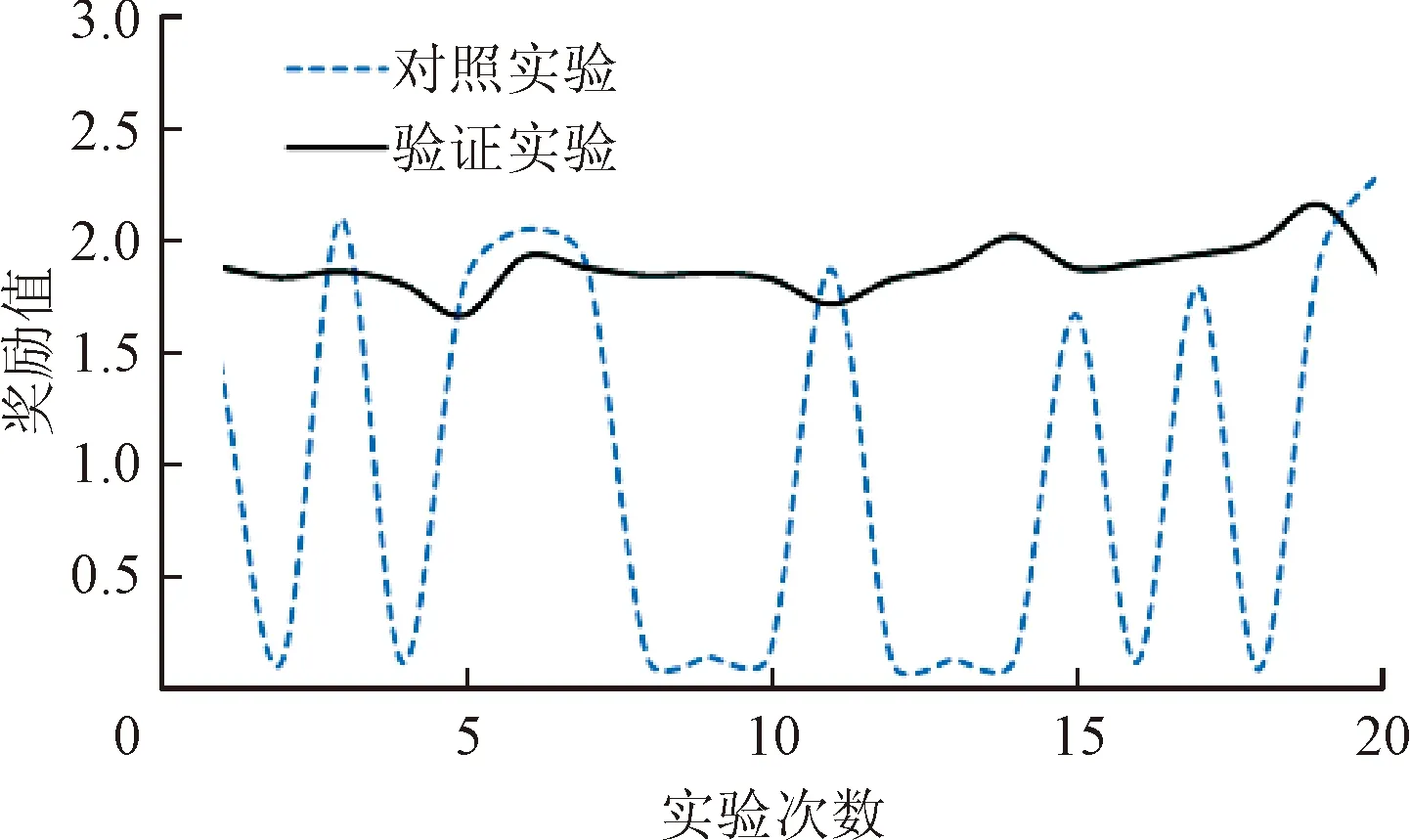
圖10 操控品質曲線對比圖
為了更直觀的討論腦-機協作方法在軌跡跟蹤任務中的有效性,分別記錄了受試者Sub1在驗證實驗和對照實驗中的10次軌跡,具體如圖11所示。從對照實驗相對波動的軌跡上可知,由于其頻繁出現目標軌跡缺失現象,從而操控者需要不斷地調整方向指令,這不僅導致機器人與障礙物碰撞的次數增加、整個任務所花費的時間變長,而且增加了腦力負荷和負面情緒。而對于使用了該方法的驗證實驗,其軌跡跟蹤精度要優于對照實驗,目標軌跡缺失現象較少,不需要操控者頻繁調整方向指令,操作更精準和高效。

(a)驗證實驗結果
為了進一步證明腦-機協作方法的普遍有效性,對所有受試者的操控品質進行了對比分析,結果如表1所示。表1中各指標計算公式如下
(10)
式中:H表示水平直線軌跡的步數;B表示斜線軌跡的步數;C表示曲線軌跡的步數;Rh、Rb、Rc和Rave(為3者之和)分別代表水平直線、斜線、曲線以及整條軌跡的歸一化獎勵值,其值越大代表軌跡跟蹤精度越好,反之,軌跡跟蹤精度越差;Rt代表時間指標獎勵值,其值越大代表完成時間越短,反之,完成時間越長。因此,Rave+Rt的值越大表示操控品質越好,反之,操控品質越差。表1結果顯示:相比較于對照實驗,5名受試者驗證實驗的平均操控品質提高了59.36%,證明了腦-機協作方法的普遍有效性。其中平均軌跡跟蹤精度和完成時間兩項指標分別提高了36.55%和22.81%,說明此方法不僅提高了軌跡跟蹤任務的控制精度,而且縮短了操控的時間。

表1 軌跡跟蹤任務操控品質對比表
5 結 論
本文面向人-機交互的精密操控領域,針對人、機之間缺乏信息雙向交互,以及操控精度和安全性受操控者精神狀態影響的兩大問題,通過引入腦-機接口技術,提出了一種腦-機協作精密操控方法研究。通過人機信息交互機制創建、腦-機協作精密操控數學模型推導與算法研究,以及實驗驗證分析,得出如下主要結論:①結合人在上層規劃與機器在精細控制上的各自優勢,可以創建一種雙環路人-機之間信息交互機制;②通過引入深度強化學習思想,以表征操控者精神狀態的EEG微分熵特征作為模型的輸入,以機器人速度指令作為模型的輸出,可以獲得一體化的腦-機協作方法模型;③基于精神狀態實時監控,采用3層全連接神經網絡感知模型,可以實現腦-機協作精密操控算法;④通過軌跡跟蹤虛擬環境和任務場景創建,能夠實現對腦-機協作方法的實驗驗證分析。實驗結果表明:本文方法明顯提高了軌跡跟蹤任務的控制精度,縮短了任務執行時間。本文方法不僅實現了腦-機協作精密操控軌跡跟蹤任務,而且借助此項任務的研究,探討了一體化的腦-機協作模型的構建,促進了腦-機之間的信息雙向、實時交互,實現人-機交互系統的互適應、互監督和互增長。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
