基于多神經(jīng)網(wǎng)絡(luò)協(xié)作的電子病歷命名實體識別方法
2021-02-25 08:49:46張運中劉慧君
計算機應(yīng)用與軟件 2021年2期
張運中 紀 斌 余 杰 劉慧君
1(湖南省電子口岸服務(wù)中心 湖南 長沙 410001)2(國防科技大學計算機學院 湖南 長沙 410073)3(中國工程物理研究院計算機應(yīng)用研究所 四川 綿陽 621999)
0 引 言
隨著電子病歷的迅速普及和醫(yī)療大數(shù)據(jù)時代的到來,自然語言處理(Natural Language Processing, NLP)技術(shù)在醫(yī)學領(lǐng)域的應(yīng)用與發(fā)展已經(jīng)成為當前的研究熱點。NLP相關(guān)技術(shù),如句子的分詞、實體識別等,可以從臨床醫(yī)療記錄中提取有科研價值信息,幫助科研人員進行的學術(shù)研究,從而可以支持醫(yī)療研究和輔助治療方案決策[1]。
命名實體識別(Named Entity Recognition, NER)是自然語言處理里的一項基礎(chǔ)任務(wù)。狹義上,NER是識別出人名、地名和組織機構(gòu)名這三類命名實體[2]。臨床醫(yī)療命名實體識別是醫(yī)療信息抽取最基礎(chǔ)的任務(wù),國內(nèi)諸多有影響力的學術(shù)會議將其作為評測任務(wù)以推進其研究與發(fā)展,如中國知識圖譜與語義計算大會(China Conference on Knowledge Graph and Semantic Computing, CCKS)[3]、中國健康信息處理會議(China Health Information Processing Conference, CHIP)等。這些評測任務(wù)既推動了醫(yī)療命名實體識別的研究與發(fā)展,也為后續(xù)的研究提供了一批高質(zhì)量的數(shù)據(jù)集。
CHIP2018發(fā)布中文電子病歷臨床醫(yī)療命名實體識別評測任務(wù)[4],此項評測任務(wù)來自工業(yè)界的真實應(yīng)用,因此更具有研究價值和挑戰(zhàn)性。此次評測任務(wù)的目的是從電子病歷中抽取出三種惡性腫瘤相關(guān)的命名實體,并發(fā)布了600份人工標注的病歷作為訓練數(shù)據(jù),200份無標注的病歷作為測試數(shù)據(jù),在本文中分別用CHIP TR和CHIP TE標識。由于這三種實體的復雜性和特殊性質(zhì),單一神經(jīng)網(wǎng)絡(luò)模型難以有效地完成本任務(wù)。針對此任務(wù),本文提出了一種基于多神經(jīng)網(wǎng)絡(luò)協(xié)作的復雜醫(yī)療命名實體識別方法,通過多種神經(jīng)網(wǎng)絡(luò)模型協(xié)作的方式實現(xiàn)了復雜醫(yī)療命名實體有效識別,并且通過句子級別上的模型遷移應(yīng)用解決了訓練數(shù)據(jù)集較小及數(shù)據(jù)分布不一致的問題。本文的貢獻可總結(jié)如下:
(1) 對于難以通過單一的神經(jīng)網(wǎng)絡(luò)模型完成的真實復雜醫(yī)療命名實體識別任務(wù),深入分析實體特點,挖掘?qū)嶓w間的依賴關(guān)系,提出基于多神經(jīng)網(wǎng)絡(luò)協(xié)作的復雜醫(yī)療命名實體識別方法,有一定的工程實踐價值。
(2) 本文方法相對于其他使用規(guī)則的方法有更好的泛化能力,在CHIP 2018評測任務(wù)中取得了第二名的成績。
(3) 本文方法的改進版本取得了CCKS2019評測任務(wù)一的第一名,為后續(xù)的相關(guān)研究提供了一個有效的基線成績。
1 相關(guān)研究
醫(yī)學命名實體識別指的是確定醫(yī)學領(lǐng)域文本中的專業(yè)術(shù)語的邊界,然后基于領(lǐng)域信息對它們進行分類[5]。目前醫(yī)學命名實體識別的主要方法分為淺層機器學習和深度學習的方法。淺層機器學習方法主要包括HMM、ME、CRF、SVM,以及上述分類模型的改進等[6]。Wang等[7]驗證了基于CRF的Gimli方法,在JNLPBA 2004數(shù)據(jù)集上取得了72.23%的F1值;于楠等[8]提出了多特征融合的條件隨機場方法,可以準確識別中文電子病歷中疾病和癥狀實體,同時也可準確識別未登錄詞。淺層機器學習方法在很大程度上依賴于人工特征的設(shè)計。為減少復雜的人工特征,Tang等[9]采用CRF模型進行生物醫(yī)學實體識別,在基本人工特征的基礎(chǔ)上加入不同的詞向量特征,在JNLPBA 2004數(shù)據(jù)集上取得了71.39%的F1值。Chang等[10]利用少量的人工特征和詞向量結(jié)合的方式構(gòu)建CRF模型并添加后處理,在JNLPBA 2004語料上取得了71.77%的F1值。
在使用深層神經(jīng)網(wǎng)絡(luò)進行醫(yī)學命名實體識別的研究中,Yao等[11]首先在無標注的生物醫(yī)學文本上利用神經(jīng)網(wǎng)絡(luò)生成詞向量,然后建立多層神經(jīng)網(wǎng)絡(luò),在JNLPBA 2004數(shù)據(jù)集上取得了71.01%的F1值。Li等[12]采用BiLSTM模型在BioCreative II GM的數(shù)據(jù)集上取得了88.6%的F1值,同時在JNLPBA 2004語料上取得了72.76%的F1值。李麗雙等[13]提出了一種基于CNN-BLSTM-CRF神經(jīng)網(wǎng)絡(luò)模型,在Biocreative II GM和JNLPBA 2004數(shù)據(jù)集上達到了最優(yōu)的F1值。
此外,基于規(guī)則的方法將手工編寫的規(guī)則與文本進行匹配來識別命名實體,是一種非常有效地命名實體識別的方法[14]。但基于規(guī)則方法需要領(lǐng)域?qū)I(yè)知識和專業(yè)的人員編寫規(guī)則,并且規(guī)則跨領(lǐng)域遷移應(yīng)用能力較差,基本不具有泛化能力。
2 實體識別方法
2.1 實體定義與分析
CHIP2018評測任務(wù)中的腫瘤原發(fā)部位、原發(fā)腫瘤大小、腫瘤轉(zhuǎn)移部位定義[15-16]如下:
(1) 腫瘤原發(fā)部位:腫瘤原發(fā)的身體部位,區(qū)別于腫瘤轉(zhuǎn)移部位。通常情況下,腫瘤原發(fā)部位的下文為“癌”“惡性腫瘤”“MT”“CA”等。
(2) 原發(fā)腫瘤大小:描述原發(fā)腫瘤長度、面積或體積的量度,包括,常見度量單位有mm、cm等。
(3) 腫瘤轉(zhuǎn)移部位:原發(fā)腫瘤的轉(zhuǎn)移部位,理論上除腫瘤原發(fā)部位外,腫瘤可向身體任何其他部位轉(zhuǎn)移。
從上述三種實體的定義中可以得出,作為一種描述腫瘤大小的量度,原發(fā)腫瘤大小依賴于腫瘤原發(fā)部位。一個基于統(tǒng)計得到的事實是原發(fā)腫瘤大小與腫瘤原發(fā)部位在電子病歷中是句子級別共存的,也就是說在絕大多數(shù)情況下原發(fā)腫瘤大小和腫瘤原發(fā)部位出現(xiàn)在同一個句子中。
腫瘤原發(fā)部位和腫瘤轉(zhuǎn)移部位都屬于身體部位或組織,在電子病歷中這兩種實體較為稀疏。一般情況下,一份病歷中只有一個腫瘤原發(fā)部位,數(shù)個腫瘤轉(zhuǎn)移部位。但電子病歷中包含大量的不屬于兩類實體的身體部位。并且對于腫瘤轉(zhuǎn)移部位來說,只有“轉(zhuǎn)移”這一特征描述詞可以用于辨別一個身體部位是否屬于腫瘤轉(zhuǎn)移部位,但這種辨別能力隨著句子長度的增加而削弱。現(xiàn)在主流的神經(jīng)網(wǎng)絡(luò)模型大多將命名實體識別作為序列標注任務(wù),其基于統(tǒng)計原理的本質(zhì)決定了當電子病歷中包含了大量的與抽取任務(wù)無關(guān)的身體部位時,腫瘤轉(zhuǎn)移部位的抽取不會有優(yōu)異的性能。
基于上述分析,將CHIP2018評測任務(wù)分解為三個子任務(wù):腫瘤原發(fā)部位抽取,原發(fā)腫瘤大小抽取和腫瘤轉(zhuǎn)移部位抽取。
2.2 方法設(shè)計
圖1為基于神經(jīng)網(wǎng)絡(luò)模型的復雜臨床醫(yī)療命名實體抽取方法架構(gòu)。
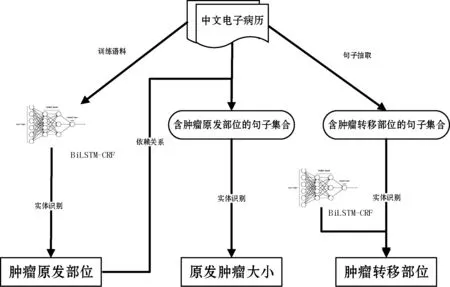
圖1 臨床醫(yī)療命名實體抽取方法架構(gòu)
(1) 腫瘤原發(fā)部位抽取。腫瘤原發(fā)部位的抽取是一個典型的命名實體識別過程,采用經(jīng)典的BiLSTM-CRF模型抽取腫瘤原發(fā)部位,模型框架結(jié)構(gòu)如圖2所示。

圖2 BiLSTM-CRF模型框架結(jié)構(gòu)圖
BiLSTM-CRF模型實現(xiàn)句子級別的命名實體識別。模型的第一層是embedding層,其作用是在將句子輸入到模型之前,將句子轉(zhuǎn)換為向量表達。從圖2中可以看出,本文中的BiLSTM-CRF模型基于字符embedding。具體來說,就是將句子中的每個字符用字符embedding表示,最后得到關(guān)于句子的向量表示序列。假設(shè)一個句子X含有n個字,則該句的向量表達可表示為X=(x1,x2,…,xn),其中xi∈Rd,d是字符embedding的維度。
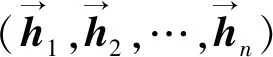
模型的第三層是CRF層,進行句子級的序列標注。CRF層的參數(shù)矩陣是一個維度為(k+2)×(k+2)的狀態(tài)轉(zhuǎn)移矩陣A,其中Aij表示從第i個標簽到第j個標簽的轉(zhuǎn)移得分,因此在為句子的一個字符進行標注的時候可以利用此前已經(jīng)標注過的標簽信息。假設(shè)y=(y1,y2,…,yn)為一個長度等于句子長度的標簽序列,那么模型對于句子X的標簽序列等于y的計算公式如下:
式中:Pi,yi表示將xi標注為yi的概率,由隱狀態(tài)Hi計算得到。
模型在預(yù)測過程時使用動態(tài)規(guī)劃的Viterbi算法來求解最優(yōu)路徑[8]。
BiLSTM-CRF模型的超參數(shù)設(shè)置如表1所示,用 BiLSTM-CRF-T標識。訓練數(shù)據(jù)采用BIO[15]的標注模式,依據(jù)人工標注信息將CHIP TR處理成適合模型訓練的格式。用B-TU、I-TU代表腫瘤原發(fā)部位首字和非首字,用O標注不屬于命名實體的字符。一個數(shù)據(jù)標注示例如圖3所示。
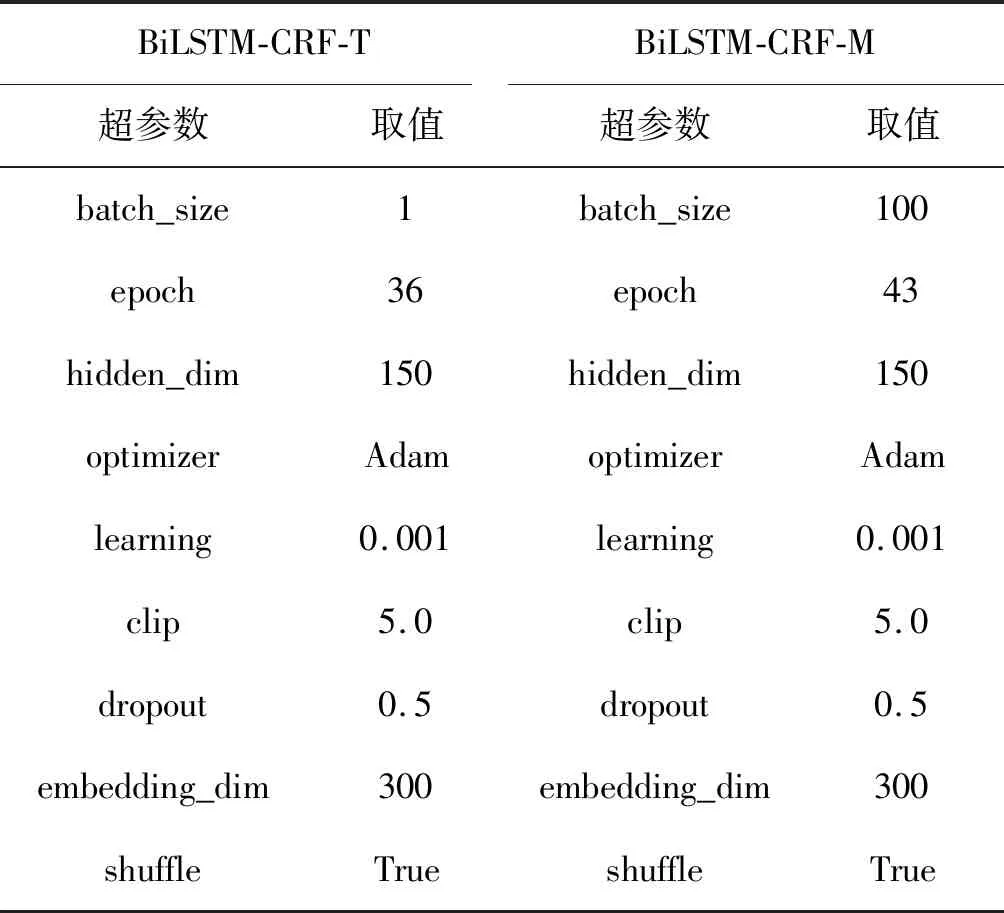
表1 神經(jīng)網(wǎng)絡(luò)模型的超參數(shù)設(shè)置
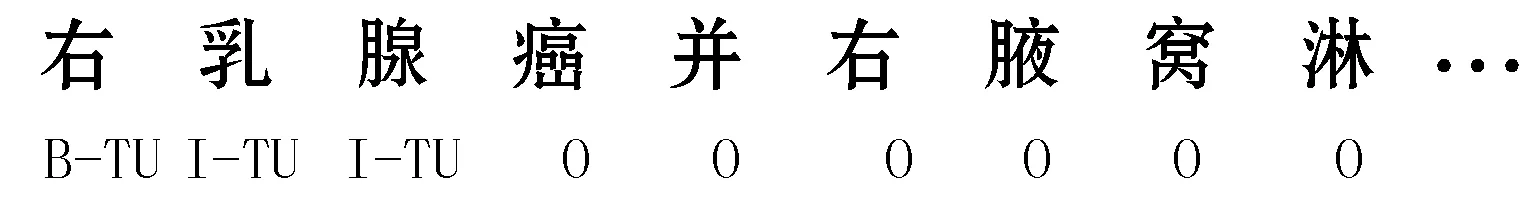
圖3 語料標注示例
(2) 原發(fā)腫瘤大小抽取。原發(fā)腫瘤大小是由數(shù)字、長度單位(mm或cm)、表示乘法的二元符號(*、×、X等)組成按照一定的規(guī)則構(gòu)成的描述原發(fā)腫瘤的量度。本文采用了基于規(guī)則的方法抽取原發(fā)腫瘤大小,其抽取流程如下:
① 預(yù)處理電子病歷。將“?”“?”“;”“;”等標點符號替換為“。”,并依據(jù)“。”分割電子病歷,得到句子集合。
② 句子篩選。對于第①步得到的句子集合中的每個句子,若其不包含腫瘤原發(fā)部位,則將其從句子集合中移除。將句子集合中剩余的句子組合成為短文本。
③ 實體抽取。依據(jù)電子病歷中的原發(fā)腫瘤大小的度量的符號組成規(guī)則,編寫正則表達式(如式(1)所示),并用其抽取第②步獲取的短文本中的度量。
RE=′(d?d?d?.?d?d(([cm][mm]?)|(.?.?[*×
X~].?d?d?d?.?d?))*[cm][mm])′
(1)
原發(fā)腫瘤大小的抽取依賴于腫瘤原發(fā)部位的抽取結(jié)果,因此若腫瘤原發(fā)部位的抽取錯誤,則可能會導致原發(fā)腫瘤大小抽取錯誤,引起錯誤傳播。
(3) 腫瘤轉(zhuǎn)移部位抽取。腫瘤轉(zhuǎn)移部位與其他兩種實體無明顯的內(nèi)在關(guān)系,并且“轉(zhuǎn)移”作為唯一特征,難以用來抽取長句中的多個腫瘤轉(zhuǎn)移部位。一種啟發(fā)式的抽取方法如下:
① 電子病歷預(yù)處理。一個基于統(tǒng)計得到的事實是:包含腫瘤轉(zhuǎn)移部位的句子中絕大多數(shù)包含“轉(zhuǎn)移”;在包含其他關(guān)鍵字的情況下,如“考慮轉(zhuǎn)移”、“不除外轉(zhuǎn)移”等,此句的前一句中包含的腫瘤轉(zhuǎn)移部位,統(tǒng)計得到的關(guān)鍵字如下所示。基于關(guān)鍵字列表編寫規(guī)則篩選包含腫瘤原發(fā)部位的句子。
關(guān)鍵字列表={考慮轉(zhuǎn)移,轉(zhuǎn)移,傾向轉(zhuǎn)移,傾向為轉(zhuǎn)移,轉(zhuǎn)移可能,不除外轉(zhuǎn)移,轉(zhuǎn)移不除外,轉(zhuǎn)移待排,疑轉(zhuǎn)移,轉(zhuǎn)移可能,轉(zhuǎn)移不除外,考慮為轉(zhuǎn)移,可疑淋巴結(jié)轉(zhuǎn)移,考慮轉(zhuǎn)移性淋巴結(jié),轉(zhuǎn)移性可能,轉(zhuǎn)移瘤可能,考慮多發(fā)轉(zhuǎn)移,轉(zhuǎn)移征象可能,轉(zhuǎn)移瘤不除外,轉(zhuǎn)移不能除外,考慮骨轉(zhuǎn)移,轉(zhuǎn)移待除外,考慮為轉(zhuǎn)移瘤,轉(zhuǎn)移可能性大,考慮肺轉(zhuǎn)移,考慮為骨轉(zhuǎn)移,轉(zhuǎn)移?,轉(zhuǎn)移均不除外,均考慮轉(zhuǎn)移不除外,均為骨轉(zhuǎn)移改變,均考慮轉(zhuǎn)移}
② 使用BiLSTM-CRF模型抽取句子中的解剖部位。
③ 處理解剖部位,獲取腫瘤轉(zhuǎn)移部位實體。后處理包括實體去重、實體特殊格式處理。其中特殊格式實體主要為補全與淋巴結(jié)相關(guān)的實體,如:“左側(cè)腮腺、雙頸、右側(cè)鎖骨上區(qū)間隙多發(fā)淋巴結(jié),考慮轉(zhuǎn)移”的神經(jīng)網(wǎng)絡(luò)模型識別結(jié)果為“左側(cè)腮腺”“雙頸”“右側(cè)鎖骨上區(qū)”“淋巴結(jié)”,需要將上述實體補全為“左側(cè)腮腺淋巴結(jié)”“雙頸淋巴結(jié)”“右側(cè)鎖骨上區(qū)淋巴結(jié)”。
CHIP TR和CHIP TE中腫瘤原發(fā)部位、原發(fā)腫瘤大小、腫瘤轉(zhuǎn)移部位的數(shù)量統(tǒng)計如表2所示。可以看出,兩個數(shù)據(jù)集中的腫瘤轉(zhuǎn)移部位的實體較為稀疏,因此從解剖部位數(shù)量和種類上來看,基于CHIP TR不足以支撐訓練性能優(yōu)異的神經(jīng)網(wǎng)絡(luò)模型。在此,引入了CCKS2018評測任務(wù)一發(fā)布的600份電子病歷數(shù)據(jù)集,該數(shù)據(jù)集由清華大學知識工程實驗室和醫(yī)渡云(北京)技術(shù)有限公司聯(lián)合提供。本文用CCKS TR標識該數(shù)據(jù)集,CCKS TR中有8 542個帶有標注信息的解剖部位,完全可以滿足神經(jīng)網(wǎng)絡(luò)模型的訓練需求。盡管CCKS TR和CHIP數(shù)據(jù)集應(yīng)用場景不同,但是二者在解剖部位的表現(xiàn)形式上是一樣的。基于CCKS TR訓練的神經(jīng)網(wǎng)絡(luò)模型遷移應(yīng)用于篩選的CHIP數(shù)據(jù)集的句子上既可以消除數(shù)據(jù)不一致帶來的影響,又解決了CHIP數(shù)據(jù)集實體稀疏的問題。應(yīng)用于腫瘤轉(zhuǎn)移部位的抽取BiLSTM-CRF模型結(jié)構(gòu)與圖2所示的模型結(jié)構(gòu)一致。模型的參數(shù)設(shè)置如表1所示,用BiLSTM-CRF-M標識。
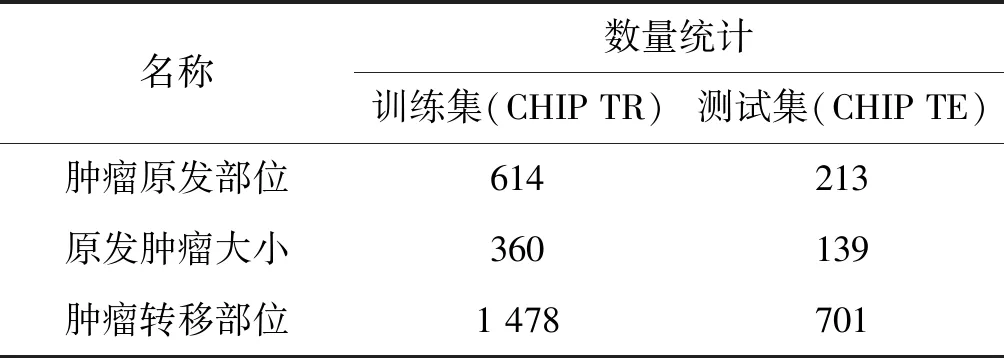
表2 CHIP2018數(shù)據(jù)集實體統(tǒng)計
3 實 驗
3.1 評估標準
本文共使用兩種評估標準:標準評估和權(quán)重評估。
(1) 標準評估。標準準確率(P)、召回率(R)和F1值(F1)作為標準評估的評估指標,分別使用以下三個公式計算:
(2)
(3)
(4)
(2) 權(quán)重評估。權(quán)重評估由CHIP2018評測任務(wù)定義,用于計算帶權(quán)重的準確率、召回率和F1值。若用T、S、M分別表示腫瘤原發(fā)部位、原發(fā)腫瘤大小、腫瘤轉(zhuǎn)移部位,那么在權(quán)重評估標準下TP、FP、FN的計算公式如下:
TP=0.2×TPT+0.3×TPS+0.5×TPM
(5)
FP=0.2×FPT+0.3×FPS+0.5×FPM
(6)
FN=0.2×FNT+0.3×FNS+0.5×FNM
(7)
而標準評估標準下三者的計算公式如下:
TP=TPT+TPS+TPM
(8)
FP=FPT+FPS+FPM
(9)
FN=FNT+FNS+FNM
(10)
3.2 實驗結(jié)果
本文方法在CHIP TE上的測試結(jié)果如表3所示,測試結(jié)果由CHIP 2018評測平臺提供。

表3 命名實體識別方法在CHIP TE數(shù)據(jù)集上的評估結(jié)果%
可以看出,本文方法在CHIP TE上獲得了78.38%的權(quán)重F1值,在此次評測任務(wù)中排名第二。此次評測任務(wù)的前四名的成績統(tǒng)計如表4所示。

表4 CHIP2018評測任務(wù)一前四名成績 %
可以看出,在排名前四的方法中,本文方法是唯一基于神經(jīng)網(wǎng)絡(luò)的方法。相比于基于規(guī)則的方法,本文方法減少了編寫規(guī)則的工作量,有更好的泛化能力。
CCKS2019發(fā)布了一項與CHIP2018任務(wù)形式相同的評測任務(wù),并且提供了900份電子病歷作為訓練數(shù)據(jù)集。為驗證本文方法的泛化能力,將其遷移應(yīng)用到CCKS2019數(shù)據(jù)集上,測試結(jié)果如表5所示。

表5 命名實體識別方法在CCKS2019數(shù)據(jù)集上的評估結(jié)果 %
可以看出,本文方法在CCKS2019數(shù)據(jù)集上取得了帶權(quán)重的69.09%的F1值,比在CHIP TE上的評估結(jié)果低9.29個百分點。深入研究后發(fā)現(xiàn),兩次評測任務(wù)標準的不完全一致是導致本文方法性能下降較大的原因:在CHIP2018評測任務(wù)中,腫瘤原發(fā)部位的是不帶有方位詞的,但在CCKS2019評測任務(wù)中要求帶有方位詞;CCKS2019評測任務(wù)不需要對淋巴結(jié)相關(guān)的實體進行補全。在3.2節(jié)給出的例子中,BiLSTM-CRF模型的識別結(jié)果就是CCKS2019要求的正確結(jié)果。
依據(jù)CCKS2019評測任務(wù)一的具體任務(wù)定義形式對本文方法進行改進,最終在CCKS2019評測任務(wù)一中取得了第一名的成績[17]。簡而言之,本文方法的有效性和泛化能力在CCKS2019數(shù)據(jù)集中得到了驗證。
4 結(jié) 語
本文提出一種基于神經(jīng)網(wǎng)絡(luò)的電子病歷命名實體識別方法,探究了融合使用多種神經(jīng)網(wǎng)絡(luò)模型實現(xiàn)復雜的、難以通過單一神經(jīng)網(wǎng)絡(luò)模型完成的醫(yī)療命名實體識別,有一定的工程實踐價值。在CHIP2018和CCKS2019評測任務(wù)中,本文方法及改進方法分別取得了優(yōu)異的成績,驗證了本文方法的有效性和泛化能力,為后續(xù)相關(guān)研究提供了一個有效的基線成績。
未來仍然還需要許多的工作來完善本文方法。首先,本文方法中仍然使用了基于規(guī)則的方法抽取原發(fā)腫瘤大小和包含腫瘤轉(zhuǎn)移部位句子,因此未來的工作之一是使用基于神經(jīng)網(wǎng)絡(luò)的方法替換基于規(guī)則的方法,以進一步提高本文方法的性能和泛化能力。其次,本文方法中使用的兩個BiLSTM-CRF模型均是基于隨機初始化的字符embeddings,而領(lǐng)域相關(guān)的預(yù)訓練的字符embeddings可以有效提高命名實體識別性能[18-19],因此未來的第二個工作是預(yù)訓練領(lǐng)域相關(guān)的字符embeddings,以進一步提高本文方法的性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
