一種基于注意力聯(lián)邦蒸餾的推薦方法*
2021-02-25 12:16:10馬天翼
軟件學(xué)報(bào) 2021年12期
諶 明,張 蕾,馬天翼
(浙江省同花順人工智能研究院,浙江 杭州 310012)
近年來(lái),隨著電商平臺(tái)和移動(dòng)互聯(lián)網(wǎng)的迅猛發(fā)展,人們已經(jīng)步入信息過(guò)載的時(shí)代.推薦系統(tǒng)作為連接用戶(hù)和信息的橋梁,正變得越來(lái)越重要.目前,主流的推薦系統(tǒng)主要基于大數(shù)據(jù)下的離線(xiàn)和在線(xiàn)推薦[1,2],但該類(lèi)推薦系統(tǒng)往往需要收集大量用戶(hù)個(gè)人信息以及瀏覽、購(gòu)買(mǎi)等用戶(hù)行為記錄,存在數(shù)據(jù)隱私泄露的風(fēng)險(xiǎn).隨著《中華人民共和國(guó)網(wǎng)絡(luò)安全法》、歐盟《通用數(shù)據(jù)保護(hù)條例》等一系列嚴(yán)格的數(shù)據(jù)隱私保護(hù)法律法規(guī)出臺(tái),對(duì)此類(lèi)數(shù)據(jù)的收集提出更多限制措施.另外,出于政策法規(guī)、商業(yè)競(jìng)爭(zhēng)等因素,不同機(jī)構(gòu)間的數(shù)據(jù)很難互通[3].針對(duì)以上問(wèn)題,聯(lián)邦學(xué)習(xí)范式被提出[4,5].該范式可使模型在不上傳用戶(hù)隱私數(shù)據(jù)的前提下進(jìn)行聯(lián)合建模,同時(shí)與領(lǐng)域和算法無(wú)關(guān),可實(shí)現(xiàn)在不同數(shù)據(jù)結(jié)構(gòu)、不同機(jī)構(gòu)間協(xié)同建模,有效保護(hù)用戶(hù)隱私和數(shù)據(jù)安全[6].
隨著5G(the 5th generation mobile communication technology)技術(shù)的普及,用戶(hù)設(shè)備端數(shù)據(jù)的上傳速度和下載速度將高達(dá)10Gbps 級(jí)別,同時(shí),移動(dòng)設(shè)備的響應(yīng)時(shí)間將降至僅1 毫秒級(jí)別,相比4G(the 4th generation mobile communication technology)下載速度快6.5 萬(wàn)倍[7];用戶(hù)數(shù)據(jù)的爆炸式增長(zhǎng)對(duì)機(jī)器學(xué)習(xí)模型的訓(xùn)練速度提出更高要求,與此同時(shí),推薦系統(tǒng)隨著模型的復(fù)雜度越高,聯(lián)邦學(xué)習(xí)需要交換的權(quán)重系數(shù)也越多,給聯(lián)邦學(xué)習(xí)下的模型移動(dòng)端通信開(kāi)銷(xiāo)帶來(lái)了嚴(yán)峻的挑戰(zhàn)[8].知識(shí)蒸餾可用于將參數(shù)大的復(fù)雜網(wǎng)絡(luò)(教師模型)中的知識(shí)遷移到參數(shù)量小的簡(jiǎn)單網(wǎng)絡(luò)(學(xué)生模型)中去,用更少的復(fù)雜度來(lái)獲得更高的預(yù)測(cè)效果[9].針對(duì)聯(lián)邦學(xué)習(xí)設(shè)備間模型參數(shù)多和通信開(kāi)銷(xiāo)大,Jeong 等人[10]將知識(shí)蒸餾引入聯(lián)邦學(xué)習(xí)場(chǎng)景,用于壓縮每臺(tái)設(shè)備模型參數(shù)的體量并減少通信次數(shù).但除上述挑戰(zhàn)和問(wèn)題外,推薦系統(tǒng)在數(shù)據(jù)上仍存在著如下問(wèn)題.
(1) 用戶(hù)間行為數(shù)據(jù)差異較大,通常行為數(shù)據(jù)體現(xiàn)為長(zhǎng)尾分布,使得設(shè)備間數(shù)據(jù)存在高度異質(zhì)性;
(2) 真實(shí)推薦場(chǎng)景下數(shù)據(jù)大都為非獨(dú)立同分布(non-IID),但大部分推薦算法往往仍基于獨(dú)立同分布(IID)假設(shè)[11],該假設(shè)忽略了非獨(dú)立同分布可能造成的數(shù)據(jù)、模型上的異質(zhì)性.
在聯(lián)邦蒸餾的場(chǎng)景下,以上問(wèn)題會(huì)造成不同設(shè)備數(shù)據(jù)之間的差異,進(jìn)而造成設(shè)備模型之間的差異.而知識(shí)蒸餾的引入,會(huì)進(jìn)一步地?cái)U(kuò)大教師模型與學(xué)生模型之間的分布差異,使全局模型收斂速度慢,準(zhǔn)確率低.針對(duì)以上問(wèn)題,還沒(méi)有針對(duì)推薦場(chǎng)景的聯(lián)邦蒸餾算法及框架被提出.
本文提出基于注意力聯(lián)邦蒸餾的推薦方法,該方法相比Jeong 等人[10]提出的聯(lián)邦蒸餾算法做了如下改進(jìn).在聯(lián)邦蒸餾的聯(lián)合目標(biāo)函數(shù)中加入KL 散度(Kullback-Leibler divergence)和正則項(xiàng),減少因教師網(wǎng)絡(luò)和學(xué)生網(wǎng)絡(luò)間的差異對(duì)全局模型造成的影響,提升模型穩(wěn)定性和泛化性能;在聯(lián)邦蒸餾設(shè)備端流程中引入改進(jìn)的多頭注意力(multi-head attention)機(jī)制,使特征編碼信息更加豐富,提升整體模型精度;提出一種自適應(yīng)學(xué)習(xí)率的訓(xùn)練策略,利用混合優(yōu)化的方法優(yōu)化聯(lián)邦蒸餾的聯(lián)合目標(biāo)函數(shù),提高模型收斂速度,抵消注意力編碼增加的計(jì)算量.該方法是目前第一個(gè)面向推薦系統(tǒng)場(chǎng)景的聯(lián)邦蒸餾方法.
1 相關(guān)研究
1.1 聯(lián)邦學(xué)習(xí)
數(shù)據(jù)的隱私保護(hù)一直是推薦系統(tǒng)的重要研究方向,聯(lián)邦學(xué)習(xí)可在不共享隱私數(shù)據(jù)的情況下進(jìn)行協(xié)同訓(xùn)練,能夠有效地解決數(shù)據(jù)隱私問(wèn)題[12].國(guó)內(nèi)外一些學(xué)者對(duì)其進(jìn)行了研究.Google AI 團(tuán)隊(duì)提出了聯(lián)邦學(xué)習(xí)方法,該方法在不收集用戶(hù)數(shù)據(jù)的情況下,在每臺(tái)設(shè)備上獨(dú)立完成模型訓(xùn)練,再將梯度數(shù)據(jù)進(jìn)行隱私保護(hù)加密傳輸?shù)街行墓?jié)點(diǎn)服務(wù)器(聯(lián)邦中心),最后,中心節(jié)點(diǎn)根據(jù)匯總結(jié)果將更新后的梯度(全局模型)再回傳到每臺(tái)設(shè)備上,從而完成每臺(tái)設(shè)備的梯度和模型更新,解決了用戶(hù)數(shù)據(jù)孤島問(wèn)題[13-14].目前,機(jī)器學(xué)習(xí)的很多領(lǐng)域都已引入聯(lián)邦學(xué)習(xí),如聯(lián)邦遷移學(xué)習(xí)[15]、聯(lián)邦強(qiáng)化學(xué)習(xí)[16]、聯(lián)邦安全樹(shù)[17]等.Yurochkin 等人[18]提出了貝葉斯無(wú)參聯(lián)邦框架,通過(guò)實(shí)驗(yàn)證明了效率上的有效性,模型壓縮比更低.Liu 等人[19]提出一種遷移交叉驗(yàn)證機(jī)制的聯(lián)邦學(xué)習(xí),能夠?yàn)槁?lián)邦內(nèi)的設(shè)備模型帶來(lái)性能提升;他們還提出靈活可拓展的方法,為神經(jīng)網(wǎng)絡(luò)模型提供額外的同態(tài)加密功能.Zhuo 等人[20]提出一種新的聯(lián)邦強(qiáng)化學(xué)習(xí)方法,為每臺(tái)設(shè)備構(gòu)建新的Q 網(wǎng)絡(luò),解決了構(gòu)建高質(zhì)量的策略難度大的問(wèn)題;更新本地模型時(shí)對(duì)信息使用高斯差分保護(hù),提升了用戶(hù)的隱私保護(hù)能力.Kewei 等人[21]提出一個(gè)聯(lián)邦提升樹(shù)系統(tǒng),可以讓多個(gè)機(jī)構(gòu)共同參與學(xué)習(xí),可以有效地提升分類(lèi)準(zhǔn)確率,同時(shí)讓用戶(hù)對(duì)自己的數(shù)據(jù)有更多的控制權(quán).也有學(xué)者在聯(lián)邦學(xué)習(xí)中引入其他算法,并對(duì)聯(lián)邦學(xué)習(xí)效率問(wèn)題進(jìn)行研究.Sharma 等人[22]提出一種隱私保護(hù)樹(shù)的Boosting 系統(tǒng),能夠在精度上與非隱私保護(hù)的算法保持一致.Ghosh 等人[23]提出了一種離群對(duì)抗方法,將所有節(jié)點(diǎn)和異常的設(shè)備一起考慮,解決了魯棒異質(zhì)優(yōu)化問(wèn)題,并給出了分析誤差的下界.雖然聯(lián)邦學(xué)習(xí)能夠解決數(shù)據(jù)隱私問(wèn)題,但隨著用戶(hù)數(shù)據(jù)量和模型復(fù)雜度的增加,存在著模型參數(shù)多和移動(dòng)端通信開(kāi)銷(xiāo)大等問(wèn)題.學(xué)者們希望使得通信負(fù)載與模型大小無(wú)關(guān),只與輸出大小有關(guān).將教師模型中的知識(shí)遷移到學(xué)生模型中,降低復(fù)雜度的同時(shí)仍能保持較好的預(yù)測(cè)精度,知識(shí)蒸餾便是這樣一種知識(shí)遷移的方法.
1.2 知識(shí)蒸餾
Hinton 等人[24]提出了知識(shí)蒸餾,將教師網(wǎng)絡(luò)相關(guān)的軟目標(biāo)作為損失函數(shù)的一部分,以誘導(dǎo)學(xué)生網(wǎng)絡(luò)的訓(xùn)練,實(shí)現(xiàn)知識(shí)遷移.Yim 等人[25]使用矩陣來(lái)刻畫(huà)層與層之間的特征關(guān)系,然后用L2 損失函數(shù)去減少教師模型和學(xué)生模型之間的差異,并讓學(xué)生模型學(xué)到這種手段,而不僅僅是利用目標(biāo)損失函數(shù)進(jìn)行知識(shí)的遷移.Heo 等人[26]利用對(duì)抗攻擊策略將基準(zhǔn)類(lèi)樣本轉(zhuǎn)為目標(biāo)類(lèi)樣本,對(duì)抗生成的樣本誘導(dǎo)學(xué)生網(wǎng)絡(luò)的訓(xùn)練,從而有效提升學(xué)生網(wǎng)絡(luò)對(duì)決策邊界的鑒別能力.但硬標(biāo)簽會(huì)導(dǎo)致模型產(chǎn)生過(guò)擬合現(xiàn)象,對(duì)此,Yang 等人[27]提出了一個(gè)更合理的方法,并沒(méi)有去計(jì)算所有類(lèi)的額外損失,而是挑選了幾個(gè)具有最高置信度分?jǐn)?shù)的類(lèi)來(lái)軟化標(biāo)簽,提高模型的泛化性能.
近些年,有學(xué)者提出將聯(lián)邦學(xué)習(xí)和知識(shí)蒸餾結(jié)合起來(lái).Jeong 等人[10]提出了一種分布式模型聯(lián)邦蒸餾訓(xùn)練算法,能夠有效解決用戶(hù)通信開(kāi)銷(xiāo)大的問(wèn)題.采用生成對(duì)抗網(wǎng)絡(luò)生成數(shù)據(jù),解決用戶(hù)生成的數(shù)據(jù)樣本非獨(dú)立同分布的問(wèn)題.Han 等人[28]提出一種保護(hù)隱私的聯(lián)邦強(qiáng)化蒸餾框架,由事先設(shè)置的狀態(tài)和策略組成,通過(guò)交換每臺(tái)設(shè)備的策略值,從而共同訓(xùn)練本地模型,解決了代理隱私泄露問(wèn)題.然而這些方法在解決非獨(dú)立同分布問(wèn)題上主要采用生成對(duì)抗網(wǎng)絡(luò)或強(qiáng)化學(xué)習(xí)的方法將非獨(dú)立同分布數(shù)據(jù)轉(zhuǎn)為獨(dú)立同分布數(shù)據(jù),在實(shí)際應(yīng)用中復(fù)雜性較大.
針對(duì)前述文獻(xiàn)和方法的不足,尤其是因聯(lián)邦學(xué)習(xí)回傳梯度參數(shù)的方法參數(shù)多、計(jì)算量大、模型訓(xùn)練過(guò)程無(wú)法自適應(yīng)調(diào)節(jié)學(xué)習(xí)率、蒸餾算法訓(xùn)練速度慢等問(wèn)題,本文在第2 節(jié)提出并詳細(xì)描述一種基于注意力機(jī)制的聯(lián)邦蒸餾推薦方法.
2 一種基于注意力聯(lián)邦蒸餾的推薦方法(AFD)
2.1 符號(hào)定義
推薦系統(tǒng)中通常包括召回和排序兩個(gè)階段:召回階段對(duì)歷史數(shù)據(jù)用協(xié)同過(guò)濾或其他召回算法召回一批候選Item 列表,排序階段對(duì)每個(gè)用戶(hù)的候選Item 列表進(jìn)行CTR(click-through rate)預(yù)測(cè),最后選取排序靠前Top-n的Item 作為推薦結(jié)果.
假設(shè)整個(gè)系統(tǒng)包含設(shè)備集K(共|K|臺(tái)設(shè)備),每臺(tái)設(shè)備包含Item 特征和用戶(hù)特征,則設(shè)備k(k∈K)中的用戶(hù)特征為Uk,Item 特征為Ik.r為第k臺(tái)設(shè)備上的特征總數(shù).Xk為設(shè)備k的本地?cái)?shù)據(jù),yk為設(shè)備k的本地?cái)?shù)據(jù)對(duì)應(yīng)的標(biāo)簽,pk為設(shè)備k上的本地?cái)?shù)據(jù)對(duì)應(yīng)的學(xué)生模型預(yù)測(cè)結(jié)果.E為全局訓(xùn)練輪數(shù),t為所有數(shù)據(jù)的標(biāo)簽值(t∈T,T為標(biāo)簽集).Sk為聯(lián)邦中心收集到的設(shè)備k的Logits 向量集合(本文的Logits 向量皆為經(jīng)過(guò)softmax操作后的歸一化的 向量值),即為學(xué)生模型;S/k為除去設(shè)備k后其他設(shè)備的Logits,為教師模型,為除去設(shè)備k后其他設(shè)備的Logits 平均值.本文提出方法所使用的主要符號(hào)定義見(jiàn)表1.

Table 1 Definitions of main symbols表1 主要符號(hào)定義
2.2 方法整體流程
本文提出的基于注意力和聯(lián)邦蒸餾的推薦方法(AFD)運(yùn)行在多個(gè)分布式設(shè)備中,包括在設(shè)備端運(yùn)行的學(xué)生網(wǎng)絡(luò)和運(yùn)行在服務(wù)器端負(fù)責(zé)收集、整合、分發(fā)教師模型參數(shù)的聯(lián)邦中心.協(xié)作流程如圖1 所示.

Fig.1 Collaboration flow of attentive federated distillation圖1 注意力聯(lián)邦蒸餾協(xié)作流程
具體描述如下:
(1) 每臺(tái)設(shè)備初始化一個(gè)基于深度神經(jīng)網(wǎng)絡(luò)的推薦(或點(diǎn)擊率預(yù)測(cè))模型(如卷積神經(jīng)網(wǎng)絡(luò)、DeepFM[29]等)作為學(xué)生模型,使用設(shè)備本地?cái)?shù)據(jù)進(jìn)行模型訓(xùn)練.其中,本地設(shè)備使用Attention 機(jī)制(見(jiàn)第2.4 節(jié))對(duì)本地用戶(hù)特征和商品特征進(jìn)行編碼,融合特征交叉信息得到特征Embedding 表達(dá),并將這些表達(dá)作為本地模型的輸入進(jìn)行訓(xùn)練.使用Attention 機(jī)制可捕捉更多興趣特征,同時(shí),編碼本身可減少本地用戶(hù)數(shù)據(jù)泄露的風(fēng)險(xiǎn);
(2) 本地模型訓(xùn)練收斂后,設(shè)備獲取模型參數(shù),并將模型參數(shù)上傳至聯(lián)邦中心.這里,上傳的模型參數(shù)與常規(guī)聯(lián)邦學(xué)習(xí)中的不同:聯(lián)邦蒸餾方法上傳的參數(shù)為本地學(xué)生模型最后Softmax層計(jì)算出的Logits 向量(每個(gè)推薦目標(biāo)標(biāo)簽對(duì)應(yīng)的Logits 向量,取多輪訓(xùn)練的平均值),而聯(lián)邦學(xué)習(xí)方法上傳的則是模型權(quán)重矩陣.對(duì)推薦標(biāo)簽數(shù)量較少或點(diǎn)擊率預(yù)測(cè)任務(wù)(二分類(lèi)),使用聯(lián)邦蒸餾方法可大大減少上傳參數(shù)的體量,緩解大規(guī)模設(shè)備下可能造成的通信擁堵;
(3) 聯(lián)邦中心使用聯(lián)邦學(xué)習(xí)算法將接收到的每臺(tái)設(shè)備上傳的標(biāo)簽平均Logits 向量整合為新的全局Logits向量.具體地,針對(duì)每臺(tái)設(shè)備,聯(lián)邦中心將其他設(shè)備發(fā)送的Logits 向量使用聯(lián)邦學(xué)習(xí)算法構(gòu)建出該臺(tái)設(shè)備的教師模型,并將教師模型分發(fā)到每臺(tái)設(shè)備中(該步驟具體流程詳見(jiàn)表3);
(4) 設(shè)備接收教師模型,通過(guò)結(jié)合自適應(yīng)學(xué)習(xí)率策略(見(jiàn)第2.5 節(jié))優(yōu)化聯(lián)合損失函數(shù)(見(jiàn)第2.3 節(jié)),并以此指導(dǎo)學(xué)生網(wǎng)絡(luò)的訓(xùn)練.聯(lián)合損失函數(shù)包含教師網(wǎng)絡(luò)、學(xué)生網(wǎng)絡(luò)的損失,同時(shí)還包含教師網(wǎng)絡(luò)與學(xué)生網(wǎng)絡(luò)之間的差異度.該步驟算法流程詳見(jiàn)表2.
以上描述中,步驟(1)和步驟(3)中的推薦算法和聯(lián)邦學(xué)習(xí)算法不限,可根據(jù)實(shí)際需求自由組合.在下面的章節(jié),我們將詳細(xì)描述圖1 流程及表2、表3 算法中使用的策略.

Table 2 Attentional federated distillation—Processes on devices表2 注意力聯(lián)邦蒸餾算法——設(shè)備流程

Table 3 Attentional federated distillation—Processes on the federated center表3 聯(lián)邦注意力蒸餾算法——聯(lián)邦中心流程
2.3 聯(lián)邦蒸餾
現(xiàn)有的聯(lián)邦學(xué)習(xí)算法是對(duì)模型權(quán)重進(jìn)行平均,由于推薦系統(tǒng)中模型復(fù)雜,權(quán)重參數(shù)眾多,分配到每臺(tái)設(shè)備上,模型參數(shù)回傳到聯(lián)邦中心,會(huì)占用大量的資源,并且聯(lián)邦中心計(jì)算權(quán)重平均值也是一筆巨大的時(shí)間開(kāi)銷(xiāo).當(dāng)采用現(xiàn)有聯(lián)邦蒸餾算法的損失函數(shù)進(jìn)行優(yōu)化時(shí),僅僅分別計(jì)算了教師網(wǎng)絡(luò)和學(xué)生網(wǎng)絡(luò)與真實(shí)標(biāo)簽的誤差值,卻忽略了教師網(wǎng)絡(luò)和學(xué)生網(wǎng)絡(luò)本身的差異性給模型帶來(lái)了影響,容易造成模型過(guò)擬合.通過(guò)實(shí)驗(yàn)發(fā)現(xiàn),教師網(wǎng)絡(luò)和學(xué)生網(wǎng)絡(luò)本身的差異性對(duì)模型的推薦效果具有較大的影響.為了減少學(xué)生網(wǎng)絡(luò)和教師網(wǎng)絡(luò)之間差異大造成的影響,本文提出了一種新的目標(biāo)函數(shù).相比于傳統(tǒng)目標(biāo)函數(shù)只計(jì)算本地設(shè)備預(yù)測(cè)值與真實(shí)值之間的誤差,本文提出的目標(biāo)函數(shù)除了利用其他設(shè)備作為教師模型來(lái)指導(dǎo)本地學(xué)生模型訓(xùn)練,還將學(xué)生模型與教師模型之間的差別作為優(yōu)化目標(biāo)的一部分加入損失函數(shù),降低設(shè)備間數(shù)據(jù)差異造成的影響.
首先,設(shè)備k(k∈K)的本地學(xué)生模型及聯(lián)邦中心分發(fā)的教師模型在該設(shè)備上的損失函數(shù)可分別定義為

其中,f(·)為損失函數(shù),pk和yk分別為設(shè)備k中學(xué)生模型對(duì)本地測(cè)試數(shù)據(jù)的預(yù)測(cè)值及其真實(shí)值,為教師模型 對(duì)本設(shè)備測(cè)試數(shù)據(jù)的預(yù)測(cè)值.假設(shè)全局模型共需訓(xùn)練E輪,則訓(xùn)練e輪(e∈[1,E])后的聯(lián)合損失函數(shù)由學(xué)生模型損失、教師模型損失以及學(xué)生模型與教師模型差異組成(表2 第6 行),具體定義如下:

其中,α,β分別為學(xué)生模型和教師模型損失的權(quán)重參數(shù),λ為正則項(xiàng)權(quán)重參數(shù),ωk為設(shè)備k的模型參數(shù)(如神經(jīng)網(wǎng)絡(luò)中的Weights 和Bias),||·||2為L(zhǎng)2 范數(shù).為節(jié)省參數(shù)通信量(傳統(tǒng)聯(lián)邦學(xué)習(xí)算法如FedAvg 需傳輸模型參數(shù))并增強(qiáng)模型的泛化性能,本文方法在聯(lián)合損失函數(shù)中增加了L2 正則項(xiàng)(見(jiàn)公式(3)).由于高度偏斜的非獨(dú)立同分布(non- IID)數(shù)據(jù)會(huì)讓學(xué)生模型之間的分布差異增大,降低整個(gè)模型的收斂效率,本文通過(guò)使用KL 散度(Kullback- Leibler divergence)來(lái)衡量學(xué)生模型和教師模型之間的差異,并將該差異作為全局損失函數(shù)的一部分進(jìn)行優(yōu)化.差異計(jì)算方式如下:

公式(3)中,當(dāng)e=1 時(shí)(即第1 輪全局模型訓(xùn)練),此時(shí)聯(lián)邦中心尚未收集首輪本地設(shè)備的模型Logits,本地設(shè)備無(wú)需從聯(lián)邦中心接受教師模型的Logits,此時(shí),聯(lián)合損失僅包含本地學(xué)生模型的損失;當(dāng)e>1 時(shí),聯(lián)邦中心已完成首輪模型收集并分發(fā)教師模型,則本地學(xué)生模型的優(yōu)化可同時(shí)使用學(xué)生模型、教師模型及學(xué)生-教師模型差異進(jìn)行聯(lián)合優(yōu)化.同時(shí),為加速模型收斂速度,本文提出一個(gè)可自動(dòng)切換優(yōu)化算法及選擇合適學(xué)習(xí)率的優(yōu)化策略,用于優(yōu)化聯(lián)合損失函數(shù)(見(jiàn)第2.5 節(jié)).優(yōu)化后的本地學(xué)生模型對(duì)本地設(shè)備數(shù)據(jù)進(jìn)行預(yù)測(cè),得出新本地模型對(duì)應(yīng) 每個(gè)數(shù)據(jù)標(biāo)簽的Logits,并通過(guò)下式更新設(shè)備k對(duì)應(yīng)標(biāo)簽t的Logits(表2 第10 行):


聯(lián)邦蒸餾的過(guò)程減少了傳統(tǒng)聯(lián)邦學(xué)習(xí)過(guò)程中的模型權(quán)重回收和分發(fā)造成的時(shí)間和通信開(kāi)銷(xiāo),能夠有效提升整體效率.同時(shí),通過(guò)加入KL 散度,將教師模型和學(xué)生模型之間的差異性加入到損失函數(shù)中進(jìn)行優(yōu)化,從而緩解了數(shù)據(jù)差異帶來(lái)的影響,提升模型的推薦性能.然而,聯(lián)邦蒸餾雖然可以緩解Non-IID 的影響,但若設(shè)備之間數(shù)據(jù)差異較大或數(shù)據(jù)量較少,仍然需要其他優(yōu)化手段來(lái)提高模型的精度.在下面的章節(jié)中,本文方法利用特征注意力編碼得到特征間更多的交互信息來(lái)豐富本地特征.
2.4 特征Attention編碼
在推薦場(chǎng)景中,用戶(hù)興趣和產(chǎn)品的種類(lèi)具有多樣性,一個(gè)用戶(hù)可能對(duì)多個(gè)種類(lèi)產(chǎn)品感興趣,一個(gè)種類(lèi)可能有多個(gè)產(chǎn)品,但最終影響模型結(jié)果可能只有其中一部分.以付費(fèi)服務(wù)推薦場(chǎng)景為例:當(dāng)一個(gè)用戶(hù)同時(shí)購(gòu)買(mǎi)了兩個(gè)付費(fèi)產(chǎn)品,很難區(qū)分他對(duì)哪個(gè)產(chǎn)品更感興趣;但如果其中一個(gè)產(chǎn)品連續(xù)購(gòu)買(mǎi)多次,另一個(gè)產(chǎn)品只購(gòu)買(mǎi)過(guò)一次,那么說(shuō)明連續(xù)購(gòu)買(mǎi)年數(shù)這一特征,對(duì)模型的分類(lèi)具有更高的權(quán)重影響.同時(shí),對(duì)于不同的用戶(hù),可能是因?yàn)椴煌奶卣鞫鴽Q定最后是否會(huì)購(gòu)買(mǎi).這類(lèi)場(chǎng)景下,對(duì)用戶(hù)交互過(guò)的商品和候選商品做特征Attention 編碼尤為重要,可以有效地捕捉用戶(hù)對(duì)不同商品及不同特征之間的差異性.由于不同的用戶(hù)關(guān)注的興趣點(diǎn)不同,用戶(hù)興趣呈現(xiàn)多樣性變化,主流的深度神經(jīng)網(wǎng)絡(luò)(DNN)模型對(duì)用戶(hù)的歷史行為是同等對(duì)待,且忽略了時(shí)間因素對(duì)推薦結(jié)果的影響[30],離當(dāng)前越近的特征越能反映用戶(hù)的興趣.然而,現(xiàn)有的基于聯(lián)邦學(xué)習(xí)的推薦方法未考慮特征之間的交互關(guān)系.為了充分利用歷史特征及特征交互信息,本文通過(guò)加入一個(gè)改進(jìn)的Attention 機(jī)制,在特征向量進(jìn)入模型訓(xùn)練之前通過(guò)Attention 機(jī)制計(jì)算用戶(hù)行為權(quán)重,得出每個(gè)用戶(hù)不同的興趣表征.目前,基于Attention 機(jī)制的方法[31,32]通常在輸出層前加入Attention 層,以捕捉用戶(hù)和Item 的二階交叉信息.與這些方法不同,我們并未在模型輸出層前加入Attention 層,而是在模型輸入前使用.這樣做有如下目的:1) 保證框架靈活性,避免侵入現(xiàn)有本地模型的結(jié)構(gòu); 2) 盡可能豐富輸入特征的信息,提高模型精度.
對(duì)于每一個(gè)用戶(hù),有一個(gè)等長(zhǎng)于特征總數(shù)r的Attention 編碼,其中,Attention 編碼的每一個(gè)維度表示該特征的權(quán)重(即重要程度).由于用戶(hù)線(xiàn)上的交互特征通常非常稀疏,當(dāng)一個(gè)用戶(hù)的特征值只有一個(gè)非零特征時(shí),這個(gè)特征會(huì)得到很高的Attention 得分;而當(dāng)一個(gè)用戶(hù)有多個(gè)非零特征時(shí),受限于Softmax計(jì)算的Logits 值,各個(gè)特征的Attention 得分反而不高,重點(diǎn)信息難以全部保留.本文使用的Attention 方法主要包含兩點(diǎn)改進(jìn):1) 由于不同設(shè)備中數(shù)據(jù)特征維度空間不同,提出一種映射方法將不同設(shè)備數(shù)據(jù)映射到相同維度,進(jìn)而允許其進(jìn)行Attention操作;2) 增加Attention 編碼的維度,增強(qiáng)特征交互的表征能力.
(1) Attention 編碼映射
由于每臺(tái)設(shè)備的數(shù)據(jù)特征空間不相同,首先需要將所有特征統(tǒng)一映射到一個(gè)dim維的Embedding 矩陣.具體地,通過(guò)創(chuàng)建特征embedding 向量[feature_count,dim],將單階或多階特征映射到[b,r,dim].其中,feature_count為所有特征的類(lèi)別總數(shù),b為一個(gè) minibatch 的數(shù)據(jù)量(如 16,32),每批次訓(xùn)練數(shù)據(jù)維度為[b,max_feature],max_feature為所有特征的維度總和,r為特征總數(shù)量.映射過(guò)程中,若特征為單階,如連續(xù)數(shù)值型特征,則特征Embedding 為該數(shù)字在Embedding 向量中對(duì)應(yīng)的特征;若特征為多階,如One-Hot 特征,則使用多階特征所有特征值在Embedding 向量中對(duì)應(yīng)特征的和作為該多階特征的Embedding.具體搜索矩陣對(duì)第i個(gè)特征的Attention權(quán)重計(jì)算方式如下:

其中,Q為搜索矩陣,Si為特征i的查詢(xún)鍵值,(·)T為矩陣轉(zhuǎn)置.映射后的Q維度為[b,1,dim],Si維度為[b,r,dim],Vi維度為映射到[b,r,dim].P(·)為查詢(xún)項(xiàng)與搜索矩陣的相似度,同時(shí)也為搜索矩陣Q對(duì)特征的權(quán)重系數(shù),維度為[b,1,r].最后,再通過(guò)Softmax操作歸一化到[0,1].具體如下:

(2) 增加Attention 的維度
傳統(tǒng)的self-attention 是在序列內(nèi)部做attention 操作,每次使用一個(gè)用戶(hù)的特征去查詢(xún)其和所有其他特征的匹配程度,共進(jìn)行r輪相同操作得到attention 值.對(duì)于每個(gè)用戶(hù),只有一個(gè)等長(zhǎng)于r的Attention 矩陣,Attention 矩陣的大小為[b,r].但推薦場(chǎng)景的數(shù)據(jù)集通常很稀疏,當(dāng)一個(gè)用戶(hù)只有一個(gè)非零特征時(shí),這個(gè)特征會(huì)得到很高的分值;而當(dāng)一個(gè)用戶(hù)有多個(gè)非零特征時(shí),重點(diǎn)特征的權(quán)重值反而難以取得較高的得分.本文方法將得到的搜索矩陣Q做矩陣變換,首先將權(quán)重系數(shù)矩陣由[b,1,r]轉(zhuǎn)為[b×r,1],再利用矩陣乘法將結(jié)果與[1,m]相乘得到[b×r,m],再將權(quán)重系數(shù)矩陣轉(zhuǎn)為[b,m,r].其中,m為新增加的Attention 的維度.對(duì)于每個(gè)特征,有m個(gè)等長(zhǎng)于r的Attention 值,變換后矩陣的大小由[b,1,r]變?yōu)閇b,m,r],從而增加Attention 的維度m,促使不同的Attention 關(guān)注不同的部分,減少了因召回商品數(shù)量不同造成的影響.通過(guò)求均值,將[b,m,r]變?yōu)閇b,1,r],得到Attention 值ai,再根據(jù)權(quán)重系數(shù)對(duì)Vi進(jìn)行加權(quán)求和,得到搜索矩陣Q的Attention 值.具體如下:

雖然特征Attention 編碼能夠豐富編碼信息,提升模型精度,但由于增加了特征維度,可能會(huì)降低模型的訓(xùn)練速度.最后,本文提出一種分段自適應(yīng)學(xué)習(xí)率訓(xùn)練策略,通過(guò)切換不同的優(yōu)化器來(lái)加快模型收斂速度.
2.5 分段自適應(yīng)學(xué)習(xí)率策略
目前,已有文獻(xiàn)實(shí)證發(fā)現(xiàn):在聯(lián)邦學(xué)習(xí)及分布式訓(xùn)練中,Adam 等基于動(dòng)量的優(yōu)化方法會(huì)直接影響到聯(lián)邦學(xué)習(xí)的效果.尤其在非獨(dú)立同分布(non-IID)數(shù)據(jù)下,本地設(shè)備模型的更新方向可能與全局模型差別較大,從而造成全局模型效果下降[33,34].同時(shí),推薦系統(tǒng)是一個(gè)復(fù)雜的非線(xiàn)性結(jié)構(gòu),屬于非凸問(wèn)題,存在很多局部最優(yōu)點(diǎn)[35].
Bottou等人指出:SGD雖然可以加快訓(xùn)練速度,但因?yàn)镾GD更新比較頻繁,會(huì)造成嚴(yán)重的震蕩陷入局部最優(yōu)解[36,37].聯(lián)邦學(xué)習(xí)需要在典型的異構(gòu)數(shù)據(jù)的情況下,通過(guò)全局?jǐn)?shù)據(jù)優(yōu)化每臺(tái)設(shè)備上的模型,因此需要一種快速、能適應(yīng)稀疏和異構(gòu)分布數(shù)據(jù)的優(yōu)化策略.Gao 等人提出了多種自適應(yīng)方法來(lái)縮放梯度,解決了在數(shù)據(jù)稀疏的情況下存在性能差的問(wèn)題,但僅僅通過(guò)平均梯度平方值的方法無(wú)法提升收斂速度[38,39].Shazeer 等人提出了一種分段調(diào)整學(xué)習(xí)率方法,采用分段訓(xùn)練的方式,在不損失精度的情況下提升了訓(xùn)練速度,但需要根據(jù)經(jīng)驗(yàn)來(lái)選擇切換的時(shí)機(jī)和切換后的學(xué)習(xí)率[40,41].
針對(duì)以上問(wèn)題,本文基于Wang 等人的工作[38],提出了一種分段自適應(yīng)學(xué)習(xí)率優(yōu)化方法,該方法的主要?jiǎng)?chuàng)新點(diǎn)為:1) 優(yōu)化梯度下降過(guò)程,改進(jìn)動(dòng)量的計(jì)算方法,解決正相關(guān)性帶來(lái)的收斂困難問(wèn)題;2) 讓算法在訓(xùn)練過(guò)程中自動(dòng)由Adam 無(wú)縫轉(zhuǎn)換到SGD 的混合優(yōu)化策略,從而保留兩種優(yōu)化算法的各自?xún)?yōu)勢(shì),大幅縮短聯(lián)合損失函數(shù)的收斂時(shí)間,并且保證了模型的準(zhǔn)確性.
本地設(shè)備學(xué)生模型的目標(biāo)函數(shù)為最小化聯(lián)合損失(見(jiàn)公式(3)),即minGL,ω為學(xué)生模型參數(shù)(如神經(jīng)網(wǎng)絡(luò)模型中的Weights,Bias 等),則在時(shí)刻z目標(biāo)函數(shù)關(guān)于模型參數(shù)的梯度Rz為

在基于動(dòng)量的優(yōu)化算法中,動(dòng)量表示參數(shù)在參數(shù)空間移動(dòng)的方向和速率.目標(biāo)函數(shù)關(guān)于參數(shù)的梯度二階動(dòng) 量等價(jià)于當(dāng)前所有梯度值的平方和.目標(biāo)函數(shù)關(guān)于模型參數(shù)的一階動(dòng)量mz和二階動(dòng)量Vz分別為Rz和的指數(shù)移動(dòng)平均.二階動(dòng)量Vz通過(guò)除以實(shí)現(xiàn)對(duì)Rz尺度的縮放控制,反映了梯度下降的速率.但在Adam 算法中,動(dòng)量的計(jì)算本質(zhì)上為動(dòng)量Vz與梯度Rz的正相關(guān)性計(jì)算,會(huì)導(dǎo)致大梯度的影響減弱,小梯度的影響增強(qiáng),最終會(huì)讓收斂變得困難.本文假設(shè)過(guò)去時(shí)刻的參數(shù)梯度相互獨(dú)立,因此可以利用過(guò)去q時(shí)刻的參數(shù)梯度Rz-q計(jì)算Vz,而無(wú)需引入相關(guān)性計(jì)算.具體地,該策略從最近的q時(shí)刻的參數(shù)梯度中選擇一個(gè)最優(yōu)值,即:

為解決上面討論的正相關(guān)性計(jì)算帶來(lái)的收斂困難問(wèn)題,本文提出了優(yōu)化后的二階動(dòng)量計(jì)算方法:

其中,μ1為權(quán)重參數(shù).公式(12)使用最近q時(shí)刻的最優(yōu)梯度代替當(dāng)前梯度,避免了計(jì)算二階動(dòng)量所需的相關(guān)性計(jì)算.同樣地,一階動(dòng)量的計(jì)算也可去相關(guān)性,即:在計(jì)算一階動(dòng)量時(shí),也利用最近q時(shí)刻的參數(shù)梯度來(lái)更新mz.具體如下:

其中,μ2為權(quán)重系數(shù).由公式(12)和公式(13)可得到時(shí)刻z的下降梯度:

其中,μ3為梯度下降的權(quán)重系數(shù).最后,根據(jù)下降梯度更新z+1 時(shí)刻的學(xué)生模型參數(shù)ωz+1:

由于基于動(dòng)量的Adam 算法會(huì)直接影響聯(lián)邦學(xué)習(xí)的收斂效果,本文在學(xué)生模型訓(xùn)練過(guò)程前半段采用Adam優(yōu)化,后半段采用SGD 優(yōu)化,同時(shí)解決訓(xùn)練過(guò)程中相關(guān)性導(dǎo)致的模型收斂困難和收斂速度慢的問(wèn)題.其中,優(yōu)化算法的切換條件及切換后SGD 的學(xué)習(xí)率為該分段策略的兩個(gè)關(guān)鍵點(diǎn).
(1) 算法切換條件.
聯(lián)邦學(xué)習(xí)中,利用自適應(yīng)學(xué)習(xí)率的方法(如Adam)存在切換時(shí)間選擇困難的問(wèn)題:如切換過(guò)快,則無(wú)法提升收斂速度;切換過(guò)慢,則可能陷入局部最優(yōu)解,影響收斂效果.受Wang 等人提出的從Adam 切換到SGD 的條件[38]的啟發(fā),當(dāng)滿(mǎn)足迭代輪數(shù)大于1 且修正后的學(xué)習(xí)率與原始的學(xué)習(xí)率的絕對(duì)值小于指定閾值ξ時(shí)進(jìn)行切換,即:

其中,ηz為每個(gè)迭代都計(jì)算的修正后的SGD 學(xué)習(xí)率,與原始的學(xué)習(xí)率之差的絕對(duì)值小于閾值,則認(rèn)為已經(jīng) 滿(mǎn)足切換條件,則切換為SGD 并以調(diào)整后的學(xué)習(xí)率繼續(xù)訓(xùn)練.接下來(lái)介紹如何確定SGD 切換后的學(xué)習(xí)率.
(2) 切換算法后,SGD 的學(xué)習(xí)率.
SGD 階段需確定的學(xué)習(xí)率包括初始學(xué)習(xí)率及修正后的學(xué)習(xí)率.Wang 等人提出將SGD 下降的方向分解為Adam 下降的方向和其正交方向上的兩個(gè)方向之和[38],本文方法與前者的區(qū)別在于對(duì)正交分解后的方向進(jìn)行修正.由于Adam 計(jì)算學(xué)習(xí)率使用的是二階動(dòng)量的累積,要想計(jì)算出SGD 階段學(xué)習(xí)率大小,需要對(duì)SGD 的下降方向進(jìn)行分解.本文將SGD下降的方向分解為Adam下降的方向和其正交方向上的兩個(gè)方向分別乘以0.5(cos60°)再求和,其余部分與Wang 等人的方法一致[38].假設(shè)模型優(yōu)化已由Adam 切換為SGD 階段,首先要沿著模型預(yù)測(cè)方向(pk)走一步,而后沿著其正交方向走完相應(yīng)步數(shù).在當(dāng)前時(shí)刻z,正交分解后的SGD 在Adam 下降方向上的 正交投影為,等價(jià)于Adam 的下降方向,即:


為了減少擾動(dòng),使用移動(dòng)平均值來(lái)修正對(duì)學(xué)習(xí)率的估計(jì),修正后的學(xué)習(xí)率如下:

其中,σ為SGD 權(quán)重系數(shù).
3 實(shí)驗(yàn)及分析
3.1 數(shù)據(jù)集及實(shí)驗(yàn)設(shè)置
我們?cè)贛ovielens[42]數(shù)據(jù)集和同花順Level2 數(shù)據(jù)集上驗(yàn)證AFD 及策略的有效性.Movielens 數(shù)據(jù)集包含 2 000 個(gè)用戶(hù)及用戶(hù)特征、3 300 部電影以及電影的標(biāo)簽屬性信息.實(shí)驗(yàn)中,選取電影評(píng)價(jià)數(shù)大于15 的電影和評(píng)價(jià)電影數(shù)量大于等于10 的用戶(hù)作為訓(xùn)練樣本[43].本文還在同花順真實(shí)場(chǎng)景金融數(shù)據(jù)集中進(jìn)行驗(yàn)證,數(shù)據(jù)集主要包含用戶(hù)對(duì)Level2 產(chǎn)品的購(gòu)買(mǎi)情況統(tǒng)計(jì),特征包括了用戶(hù)ID、用戶(hù)歷史購(gòu)買(mǎi)信息、設(shè)備信息、用戶(hù)對(duì)該產(chǎn)品的評(píng)價(jià)、用戶(hù)自身屬性特征、產(chǎn)品特征等.其中,離散特征18 項(xiàng),連續(xù)特征22 項(xiàng).實(shí)驗(yàn)中對(duì)特征進(jìn)行預(yù)處理,包括缺失特征補(bǔ)全、去掉用戶(hù)編碼和標(biāo)簽字段缺失的用戶(hù)、去掉用戶(hù)非空特征數(shù)量小于3 的數(shù)據(jù)等.預(yù)處理完成后,訓(xùn)練集共有32 萬(wàn)用戶(hù)及40 項(xiàng)特征,共78 萬(wàn)條樣本數(shù)據(jù);測(cè)試集共有12 萬(wàn)用戶(hù),40 項(xiàng)特征共25 萬(wàn)條樣本數(shù)據(jù).實(shí)驗(yàn)過(guò)程中,對(duì)原始數(shù)據(jù)進(jìn)行去噪和脫敏處理,采用交叉驗(yàn)證的方式,將訓(xùn)練集和測(cè)試集分成4 份,并分發(fā)到4 臺(tái)模擬設(shè)備,模擬聯(lián)邦實(shí)際應(yīng)用場(chǎng)景,每臺(tái)設(shè)備上的數(shù)據(jù)相互獨(dú)立.
為了對(duì)比不同聯(lián)邦推薦算法的推薦準(zhǔn)確率,我們將本文提出的基于注意力聯(lián)邦蒸餾的推薦算法AFD 結(jié)合卷積神經(jīng)網(wǎng)絡(luò)(CNN)與結(jié)合聯(lián)邦學(xué)習(xí)的其他3 種推薦算法進(jìn)行對(duì)比實(shí)驗(yàn),這3 種推薦算法包括:
(1) FWD:聯(lián)邦學(xué)習(xí)(FedAvg)結(jié)合Wide&Deep 算法[44];
(2) FDIN:聯(lián)邦學(xué)習(xí)(FedAvg)結(jié)合深度興趣網(wǎng)絡(luò)(DIN)算法[45];
(3) FD+CNN:聯(lián)邦蒸餾算法[10]結(jié)合卷積神經(jīng)網(wǎng)絡(luò).AFD+CNN 方法在不使用本文提出的3 個(gè)策略的情況下等價(jià)于FD+CNN.
AFD 與以上3 個(gè)模型的對(duì)比見(jiàn)表4.
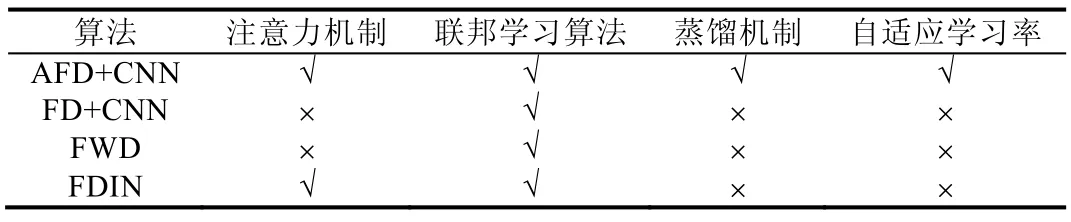
Table 4 Comparisons between AFD and baselines表4 AFD 算法和基準(zhǔn)模型對(duì)比
本文模型及實(shí)驗(yàn)使用Tensorflow 實(shí)現(xiàn),并且在Nvidia GeForce GTX 1080Ti GPU 上進(jìn)行實(shí)驗(yàn).AFD 及3 種方法的實(shí)驗(yàn)設(shè)置如下.
(1) AFD+CNN:attention 的維度m設(shè)為32.網(wǎng)絡(luò)層參數(shù)設(shè)置,CNN 層數(shù)為5,隱藏層的大小hidden_units 設(shè)為128,兩個(gè)卷積核為[64,64],最大池化層為[64,1],3 個(gè)全連接層為120,60 和2;
(2) FWD:Deep 部分全連接層為128,64 和2;
(3) FDIN:隱藏層單元數(shù)為32,全連接層為80,40 和2;
(4) FD+CNN:CNN 層數(shù)為5,2 個(gè)卷積層,1 個(gè)最大池化層,2 個(gè)全連接層.
3.2 評(píng)價(jià)指標(biāo)
本文采用如下指標(biāo)作為實(shí)驗(yàn)結(jié)果的評(píng)價(jià)指標(biāo).
? Time:模型迭代指定輪數(shù)運(yùn)行的時(shí)間;
? Loss:模型損失函數(shù)(為與其他模型統(tǒng)一,AFD 評(píng)估學(xué)生模型原始損失,而非聯(lián)合損失);
? AUC:ROC 曲線(xiàn)下面積,用來(lái)反映分類(lèi)器的分類(lèi)能力;
? ACC:準(zhǔn)確率,表示分類(lèi)正確的樣本數(shù)占樣本總數(shù)的比例;
? NDCG(normalized discounted cumulative gain):歸一化折損累積增益;
? MAE(mean average error):評(píng)估算法推薦質(zhì)量的指標(biāo),通過(guò)計(jì)算實(shí)際分值與預(yù)測(cè)分值的差異,來(lái)衡量推薦是否準(zhǔn)確.
3.3 實(shí)驗(yàn)結(jié)果及分析
? 實(shí)驗(yàn)1:不同聯(lián)邦推薦算法下的精度實(shí)驗(yàn).
在兩個(gè)數(shù)據(jù)集上的準(zhǔn)備率對(duì)比結(jié)果如圖2 所示,結(jié)果表明,本文提出的AFD 算法準(zhǔn)確率高于其他3 種基準(zhǔn)方法.在Movielens 數(shù)據(jù)集上,AFD 算法的平均準(zhǔn)確率最高達(dá)到了0.84,FDIN 的準(zhǔn)確率高于FD 和FWD 算法.在Level2 數(shù)據(jù)集上,AFD 算法的準(zhǔn)確率達(dá)到0.92 左右,FD+CNN 的準(zhǔn)確率為0.81 左右,FWD 準(zhǔn)確率僅為0.67 左右,FDIN 約為0.83 左右,AFD 相比不使用本文提出的3 個(gè)策略的FD+CNN 算法在準(zhǔn)確率上提升了13%.可以看出: FD+CNN在使用聯(lián)邦蒸餾機(jī)制后,模型精度與FDIN相當(dāng).FDIN由于使用了Attention機(jī)制,總體精度優(yōu)于除AFD外的其他方法.
表5 為4 臺(tái)設(shè)備中的MAE 及全局模型的MAE.由表5 可以看出:由于數(shù)據(jù)分布情況不同,4 臺(tái)設(shè)備中模型精度有較大差別.同一設(shè)備,FWD 誤差值最大,FDIN 和FD 算法MAE 均小于FWD 算法.在Movielens 數(shù)據(jù)集上,FWD 算法的MAE 值最大,推薦效果最差,而AFD 算法MAE 值比FD 算法平均誤差減少了約20%.在Level2數(shù)據(jù)集上,FD 和FDIN 算法MAE 結(jié)果近似,而AFD 算法比以上兩種算法平均誤差減少了約17%.同時(shí),AFD 在4 臺(tái)設(shè)備中均取得了最好的結(jié)果,表明AFD 相對(duì)于其他3 種基準(zhǔn)算法推薦性能表現(xiàn)最佳.
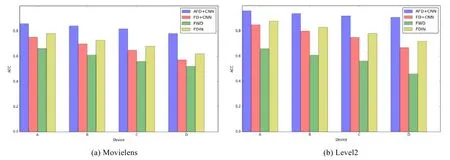
Fig.2 ACC on different datasets圖2 不同數(shù)據(jù)集下的ACC
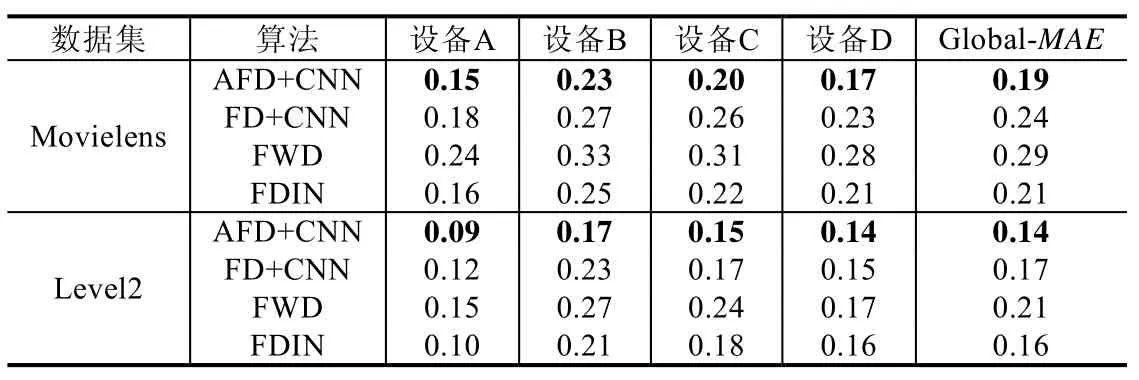
Table 5 MAE on Movielens and Level2 datasets表5 Movielens 和Level2 數(shù)據(jù)集下的MAE
由圖3 可以看出:使用NDCG@5 作為評(píng)價(jià)指標(biāo),AFD 算法在4 臺(tái)設(shè)備上的NDCG 值均高于其他3 種基準(zhǔn)模型.其中,在Movielens 數(shù)據(jù)集上,AFD 的NDCG 平均值達(dá)到0.92,FWD 的NDCG 平均值為0.82,FD 和FDIN的NDCG 平均值接近(約為0.85).AFD 比以上兩種算法NDCG 值提升了約8%;在Level2 數(shù)據(jù)集上,AFD 的NDCG 平均值在0.96,FWD 的NDCG 平均值在0.85,FD 和FDIN 的NDCG 平均值在0.87.AFD 比以上兩種算法NDCG 值提升了10%.

Fig.3 NDCG on different datasets圖3 不同數(shù)據(jù)集下的NDCG
由圖4 可以看出,AFD 算法AUC 值均高于基準(zhǔn)算法.其中,在Movielens 數(shù)據(jù)集上,AFD 算法的AUC 為0.78;在Level2 數(shù)據(jù)集上,AFD 算法的AUC 為0.86,FDIN 和FWD 算法的AUC 僅為0.66,FD+CNN 算法的AUC 為0.76.
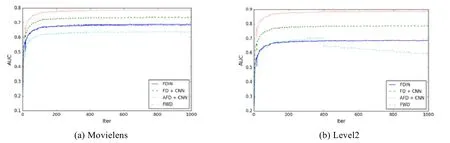
Fig.4 AUC on different datasets圖4 不同數(shù)據(jù)集下的AUC
由圖5 可以看出:隨著迭代輪數(shù)的增加,AFD 可在迭代輪數(shù)小于200 輪時(shí)收斂,收斂速度略?xún)?yōu)于其他3 種算法.同時(shí),AFD 在兩個(gè)數(shù)據(jù)集上均取得了更低的損失:在Movielens 數(shù)據(jù)集上,AFD 的Loss 約為0.2;在Level2 數(shù)據(jù)集上,AFD 的Loss 可達(dá)到0.1 左右,均低于其他3 種基準(zhǔn)算法.以上實(shí)驗(yàn)結(jié)果表明:本文提出的AFD 算法收斂速度更快,總體推薦性能更好.

Fig.5 Loss on different datasets圖5 不同數(shù)據(jù)集下的Loss
? 實(shí)驗(yàn)2:自適應(yīng)學(xué)習(xí)率在聯(lián)邦蒸餾中的有效性驗(yàn)證.
為了驗(yàn)證改進(jìn)后的自適應(yīng)學(xué)習(xí)率方法的有效性,將算法的運(yùn)行時(shí)間作為評(píng)價(jià)指標(biāo),對(duì)比AFD 與FWD,FDIN和FD 不同迭代輪數(shù)下的運(yùn)行時(shí)間.實(shí)驗(yàn)結(jié)果如圖6 所示.
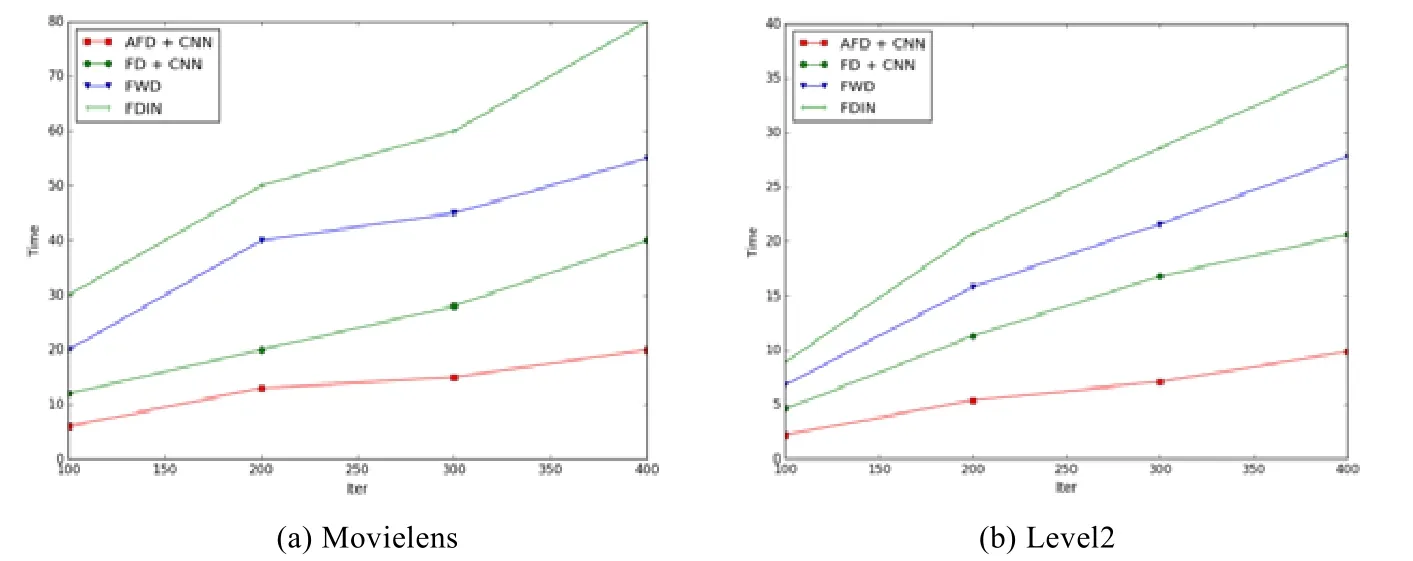
Fig.6 Running time of algorithmson different datasets圖6 不同數(shù)據(jù)集上算法運(yùn)行時(shí)間
從結(jié)果中可看出:在Movielens 數(shù)據(jù)集上,AFD 算法的耗時(shí)明顯低于其他3 種基準(zhǔn)算法,耗時(shí)曲線(xiàn)較平緩;在Level2 數(shù)據(jù)集上,FWD 和FDIN 算法的運(yùn)行時(shí)間較長(zhǎng),隨著迭代輪數(shù)的增加,運(yùn)行時(shí)長(zhǎng)呈線(xiàn)性增長(zhǎng),FD 算法運(yùn)行時(shí)長(zhǎng)小于以上兩種算法.而采用自適應(yīng)學(xué)習(xí)率策略的AFD 算法在相同輪數(shù)下耗時(shí)最短,同時(shí),在200 輪以后,運(yùn)行時(shí)長(zhǎng)曲線(xiàn)增長(zhǎng)更緩慢.在迭代400 輪左右,AFD 累計(jì)運(yùn)行時(shí)長(zhǎng)為9.8 分鐘,FD+CNN 運(yùn)行時(shí)長(zhǎng)為20.6 分鐘,AFD算法較FD+CNN 算法訓(xùn)練時(shí)間縮短52%左右,說(shuō)明自適應(yīng)學(xué)習(xí)率的方法能夠有效的提升訓(xùn)練速度.
? 實(shí)驗(yàn)3:Attention 機(jī)制的有效性驗(yàn)證.
本實(shí)驗(yàn)將AFD 中的Attention 編碼策略結(jié)合在其他3 個(gè)基準(zhǔn)模型中,分別為聯(lián)邦蒸餾算法結(jié)合CNN 及注意力機(jī)制(FD+CNN+ATN)、聯(lián)邦學(xué)習(xí)結(jié)合Wide&Deep 算法和注意力機(jī)制(FWD+ATN)和聯(lián)邦學(xué)習(xí)結(jié)合深度興趣網(wǎng)絡(luò)和注意力機(jī)制(FDIN+ATN).將NDCG、AUC、相同條件下訓(xùn)練時(shí)長(zhǎng)(迭代次數(shù)400,minibatch 大小128,學(xué)習(xí)率0.001)和設(shè)備端MAE 作為對(duì)比指標(biāo),在Movielens 數(shù)據(jù)集和Level2 數(shù)據(jù)集上對(duì)比實(shí)驗(yàn)結(jié)果見(jiàn)表6.
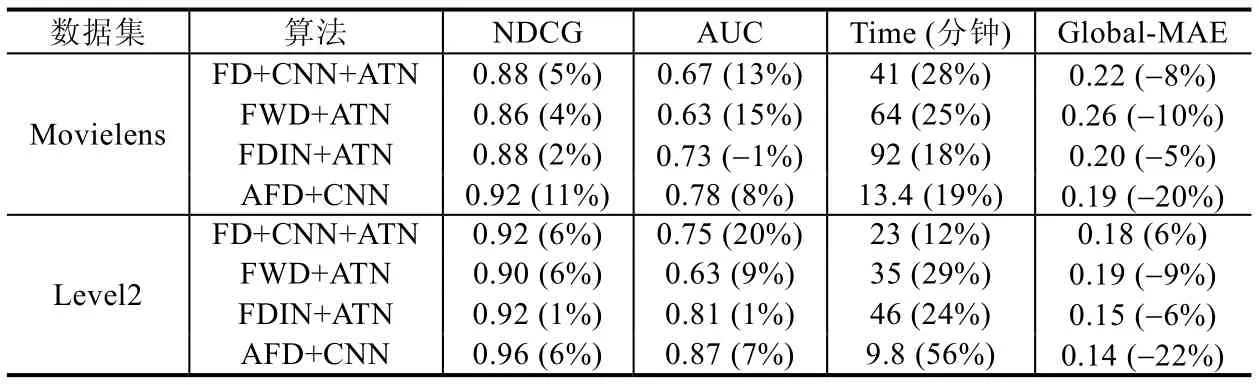
Table 6 Comparisons between baselines using attentional mechanism表6 各基準(zhǔn)模型使用Attention 機(jī)制后的效果對(duì)比
表6 中,括號(hào)內(nèi)的數(shù)字為加入Attention 機(jī)制后的方法相比未加入之前方法的提升/減少幅度.NDCG 和AUC該數(shù)字越大越好,運(yùn)行時(shí)間和MAE 則越小越好.在Movielens 數(shù)據(jù)集中,FD+CNN 加入注意力機(jī)制后,NDCG@5值提升約5%,AUC 值提升約13%,Global-MAE 誤差減少約8%,相同條件下訓(xùn)練時(shí)長(zhǎng)卻增加了約28%,說(shuō)明加入注意力機(jī)制雖然對(duì)FD+CNN 算法精度有明顯提升,但增加了計(jì)算量.FDIN 加入注意力機(jī)制后,Global-MAE 有明顯降低,但NDCG 指標(biāo)和AUC 幾乎不變,訓(xùn)練時(shí)長(zhǎng)增加了約18%,說(shuō)明加入注意力機(jī)制對(duì)FDIN 算法精度提升有限.這是由于FDIN 已經(jīng)在內(nèi)部對(duì)集成了Attention 操作.對(duì)比實(shí)驗(yàn)中除FDIN 外,其他模型精度均有明顯提升,但會(huì)增加算法的計(jì)算量,增加訓(xùn)練時(shí)間.從同花順Level2 數(shù)據(jù)分析,可以進(jìn)一步得出相同的結(jié)論.
? 實(shí)驗(yàn)4:Attention 編碼后特征之間的關(guān)聯(lián)性分析.
本實(shí)驗(yàn)對(duì)Attention 編碼后特征之間的關(guān)聯(lián)性進(jìn)行分析,結(jié)果見(jiàn)圖7.其中,圖7 的橫縱坐標(biāo)均為L(zhǎng)evel2 用戶(hù)和產(chǎn)品標(biāo)簽字段,顏色由淺到深表示兩個(gè)特征的關(guān)聯(lián)度逐級(jí)提高,關(guān)聯(lián)度較高的特征能夠獲得較高的權(quán)重得分.

Fig.7 Visualization of feature interactions on Level2 dataset after attentional encoding圖7 Level2 數(shù)據(jù)集下進(jìn)行注意力編碼后的特征交互可視化
可以看出,一些特征如level2_total_buy_time(Level2 產(chǎn)品歷史購(gòu)買(mǎi)次數(shù)),total_eventclicknum(Level2 產(chǎn)品歷史點(diǎn)擊次數(shù)),last7onlinetime(過(guò)去7 天的在線(xiàn)時(shí)長(zhǎng))等之間存在較強(qiáng)的特征交互,表明用戶(hù)活躍度如點(diǎn)擊次數(shù)和在線(xiàn)時(shí)長(zhǎng)等特征對(duì)產(chǎn)品購(gòu)買(mǎi)影響較大,符合現(xiàn)實(shí)業(yè)務(wù)中的觀察結(jié)論.該結(jié)果表明:本文提出的Attention 策略可以提取出更豐富的特征表征信息(無(wú)需通過(guò)Attention 網(wǎng)絡(luò)進(jìn)行訓(xùn)練),增強(qiáng)設(shè)備數(shù)據(jù),提升模型精度.
? 實(shí)驗(yàn)5:3 個(gè)改進(jìn)策略對(duì)聯(lián)邦蒸餾的有效性驗(yàn)證.
在最后一個(gè)實(shí)驗(yàn)中,驗(yàn)證本文3 個(gè)策略對(duì)聯(lián)邦蒸餾方法框架的貢獻(xiàn)程度,分別為聯(lián)邦蒸餾加入KL 散度和正則項(xiàng)(FD+KLR)、聯(lián)邦蒸餾加入改進(jìn)后的注意力機(jī)制(FD+ATN)和聯(lián)邦蒸餾中加入自適應(yīng)學(xué)習(xí)率優(yōu)化策略(FD+ ADA).為了驗(yàn)證3 個(gè)改進(jìn)策略對(duì)聯(lián)邦蒸餾的有效性,將NDCG、AUC、相同條件下訓(xùn)練時(shí)長(zhǎng)(迭代次數(shù)400,minibatch 大小128,學(xué)習(xí)率0.001)和MAE 作為對(duì)比指標(biāo).對(duì)比實(shí)驗(yàn)結(jié)果見(jiàn)表7.
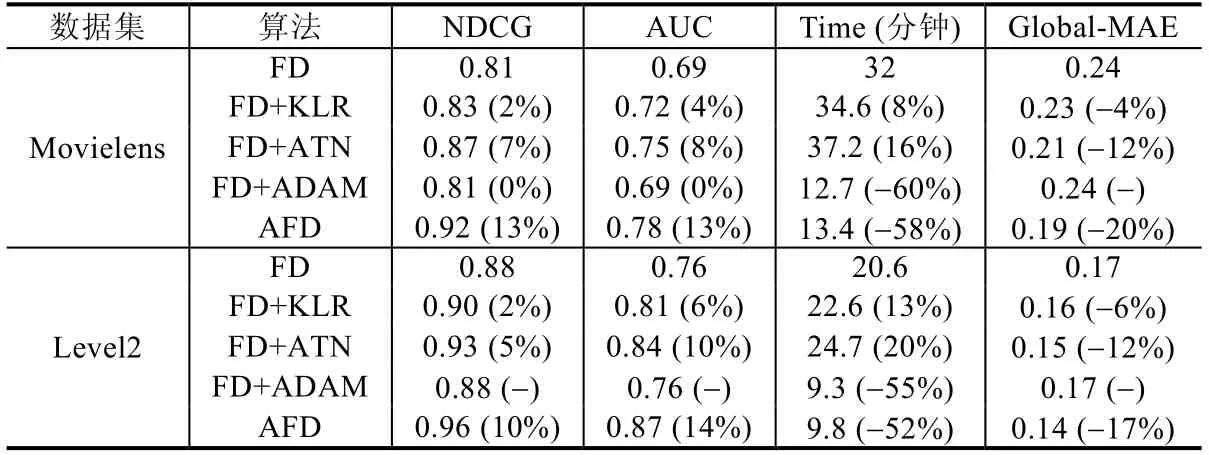
Table 7 Comparisons between three strategies表7 3 個(gè)策略的效果對(duì)比
從表7 結(jié)果可以看出:在Movielens 數(shù)據(jù)集中:比較加入改進(jìn)算法前后的NDCG@5 指標(biāo),AFD 最高為0.92,FD+ATN 為0.87,分值最低的是FD+ADA 為0.81;加入注意力機(jī)制比原始聯(lián)邦蒸餾算法有約7%的提升,其次是FD+ KLR,相比原始聯(lián)邦蒸餾算法有約2%的提升;比較加入改進(jìn)算法前后的AUC 值,加入FD+ATN 相比原始聯(lián)邦學(xué)習(xí)算法有約8%的提升;對(duì)比加入改進(jìn)算法前后的MAE,FD+KLR 和FD+ATN 相比FD+ADAM 誤差減少了約4%和12%;從精度來(lái)看,提升最明顯的是加入注意力機(jī)制(ATN),其次是引入KL 和正則項(xiàng)的聯(lián)合損失優(yōu)化策略(KLR),而自適應(yīng)學(xué)習(xí)率策略(ADA)對(duì)精度的提升有限;但從訓(xùn)練收斂速度角度,ADA 策略取得了最大的收益,較只加入KLR 訓(xùn)練時(shí)間減少了約60%,說(shuō)明該策略能大大提升學(xué)生模型的訓(xùn)練速度;FD+ATN 耗時(shí)最多,說(shuō)明ATN 策略大幅提高了計(jì)算量;KLR 策略因只對(duì)目標(biāo)函數(shù)做優(yōu)化,對(duì)性能影響較少.從同花順Level2 數(shù)據(jù)結(jié)果分析可以進(jìn)一步得出相同的結(jié)論.
綜上所述,在聯(lián)邦蒸餾框架中加入注意力機(jī)制可以大幅提升模型的性能;加入KL 散度和正則項(xiàng)的聯(lián)合優(yōu)化策略可以減少特征之間的差異性帶來(lái)的影響,從而提升模型的精度;最后,加入自適應(yīng)學(xué)習(xí)率的訓(xùn)練策略在不損失或較小損失模型精度的情況下,可以大幅縮短模型的訓(xùn)練時(shí)間.加入3 個(gè)改進(jìn)策略后,本文提出的AFD 在實(shí)驗(yàn)數(shù)據(jù)集上獲得了最優(yōu)的性能.
4 結(jié) 論
本文提出了一種改進(jìn)的聯(lián)邦蒸餾推薦方法,包括一個(gè)標(biāo)準(zhǔn)的模型優(yōu)化聯(lián)邦蒸餾算法.該算法引入了3 種策略:(1) 為增強(qiáng)設(shè)備中的數(shù)據(jù)特征,引入了一個(gè)改進(jìn)的注意力編碼機(jī)制;(2) 針對(duì)設(shè)備間數(shù)據(jù)差異可能帶來(lái)的影響,引入了一個(gè)評(píng)估學(xué)生模型與教師模型差異指標(biāo)及正則項(xiàng)的聯(lián)合優(yōu)化方法;(3) 為抵消注意力編碼機(jī)制帶來(lái)的計(jì)算量提升,提出一個(gè)改進(jìn)的自適應(yīng)學(xué)習(xí)率方法來(lái)切換不同優(yōu)化方法,選擇合適的學(xué)習(xí)率來(lái)加快模型收斂速度,使得訓(xùn)練時(shí)間縮短了52%左右.最后,通過(guò)實(shí)驗(yàn)在Movielens 數(shù)據(jù)集和同花順Level2 線(xiàn)上數(shù)據(jù)集驗(yàn)證策略的有效性.實(shí)驗(yàn)結(jié)果表明:相比于3 種基準(zhǔn)算法,本文提出的算法相比于原始聯(lián)邦蒸餾算法訓(xùn)練時(shí)間縮短52%,模型的準(zhǔn)確率提升了13%,平均絕對(duì)誤差減少了約17%,NDCG 值提升了約10%,展示了良好的收斂效率和推薦精度.在未來(lái)的研究中可嘗試的方向是:將聯(lián)邦蒸餾與強(qiáng)化學(xué)習(xí)結(jié)合起來(lái),為不同的設(shè)備制定不同的策略,無(wú)需回傳或僅少量回傳模型參數(shù)即可達(dá)到與回收模型相同的收斂效果,以大幅降低通信量.
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
商用汽車(chē)(2016年11期)2016-12-19 01:20:16
商用汽車(chē)(2016年6期)2016-06-29 09:18:54
商用汽車(chē)(2016年4期)2016-05-09 01:23:12
