基于分組TCAM的T比特高性能路由器快速查找更新技術
2021-02-25 05:50:16劉宗寶李之乾
計算機工程與設計 2021年2期
劉宗寶,趙 鑫,張 力,李之乾,張 琨
(中國航天科工集團第二研究院 七〇六所,北京 100854)
0 引 言
信息技術的發展推動核心路由器的線速轉發率達到40 Gbps以上[1],路由查找是核心路由器實現高性能線速轉發的關鍵技術。目前路由查找算法主要有軟件查找算法和硬件查找算法,基于軟件的路由查找方法需要多次內存操作才能完成路由查找,無法滿足高速接口線速轉發的要求。基于硬件的路由查找算法大多基于TCAM(ternary content addressable memory)[2-4]技術實現,執行速度快,可以在一個時鐘周期內完成路由表項的匹配查詢,優先級編碼器(priority encoder,PE)從多個匹配結果中選擇最長前綴匹配(longest prefix match,LPM)作為查找結果,因此TCAM特別適合于高性能路由器,實現快速路由查找和轉發。但是,傳統TCAM的更新性能較差[5]:路由表是動態變化的并且規模大幅增長,TCAM中路由表項按照前綴長度降序排列,為保證路由表項的優先級,對路由表項的插入、刪除等更新操作會造成大量的內存移動[6],最壞情況下的更新算法復雜度為O(N)(N為TCAM中的路由表項數量),導致路由查找性能大幅下降,無法滿足高性能路由器線速查找轉發的要求。
針對TCAM路由表項的更新算法國內外學者進行了大量的研究,提出了許多性能優化的算法,參見文獻[7-9]等。PLO-OPT更新算法是對選擇移動更新算法的改進,即空閑前綴表項從TCAM的底部移動到了TCAM的中間,因此一次更新操作最多需要L/2次(L是路由前綴的長度)路由表項移動。CAO_OPT更新算法把路由表轉化為trie樹,只對同一條鏈路(從根節點到葉子節點)上的規則排序[10],一次更新操作最多需要D/2次(D是相互重疊的前綴的最大個數)路由表項移動。目前大部分基于TCAM的路由表項更新算法都要求前綴表項按照前綴長度排序,時間復雜度高,影響了路由查找更新性能。為滿足高性能路由器數據交換對快速路由查找功能的需求,本文提出了一種基于分組TCAM的T比特高性能路由器查找更新方法。
1 T比特高性能路由器系統架構
T比特高性能路由器的系統架構為分布轉發、集中控制,如圖1所示,主要由熱備份主控板、交換網板和多個接口業務板組成,各板之間通過高速背板總線互聯。主控板是T比特高性能路由器的核心,完成以太網數據包處理、網絡管理等功能,并為其它各板提供高精度的時鐘源。交換網板具有高性能交換芯片,完成T比特級的高速數據包轉發。接口業務板具有單獨的控制系統,支持IPv4、IPv6、MPLSVPN、Qos/H-Qos、GRE、組播VPN等全業務功能。
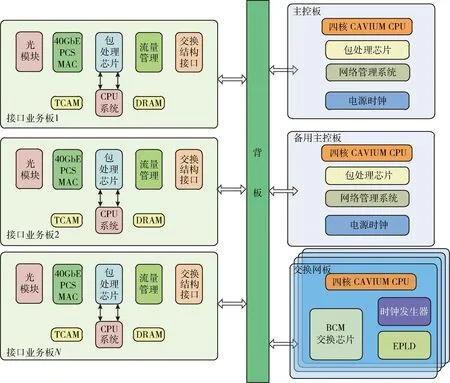
圖1 T比特高性能路由器系統架構
2 基于分組TCAM的路由查找更新
2.1 路由查找更新架構
本文提出的基于分組TCAM的路由查找更新架構如圖2(a)所示,TCAM被分成幾組TCAM1~TCAMmax,每組內各TCAM表項的前綴互不相交,即TCAMi,j∪TCAMi,k=Ф,因此TCAMi(i∈{1,max})是互不相交路由表項的集合,TCAMi中最多只有一個匹配前綴。max為路由表項前綴的最大長度,根據網絡環境的不同可動態變化。由于在執行某項前綴的插入、刪除等更新操作時,不需要對其它前綴進行操作,因此相比于傳統TCAM,本文提出的路由查找更新架構的操作執行速度更快,算法復雜度低,高性能路由器的查找轉發效率更高。本文提出的架構中還有一個TCAMex為傳統TCAM結構,用于存儲無法放在TCAMi中的路由表項。選擇邏輯基于最長前綴匹配算法(LPM)實現。
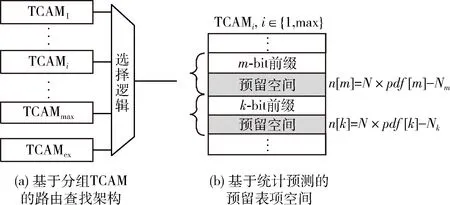
圖2 基于分組TCAM的高性能路由器查找更新架構
TCAMi(i∈{1,max})和TCAMex采用基于統計預測的預留表項空間設計,如圖2(b)所示,灰色部分表示預留的空間,預留空間大小由前綴的概率密度函數確定,對于TCAMi,前綴長度為m的表項預留空間為ni[m]=NTCAM×pdf[m]/(max+1),前綴為k的表項預留空間為ni[k]=NTCAM×pdf[k]/(max+1),詳細計算過程在2.2.2節。通過基于統計預測的預留表項空間設計,有效減少了路由表項前綴的插入操作引起的其它表項的移動,路由表項更新效率大幅提升。
2.2 路由查找更新算法
2.2.1 搜索算法
搜索算法基于最長前綴匹配(LMP)搜索技術,具體實現過程為:對于TCAM1~TCAMmax,每個TCAMi獨立地并行執行前綴匹配過程match(TCAMi, ip_addr),其中ip_addr為目的IP地址。由于TCAMi中的前綴互不相交,因此每個TCAMi中最多搜索到一個與ip_addr匹配的前綴;然后從多個匹配的前綴中選擇entry[k].length值最大的前綴,相應的entry[k]即為ip_addr的路由查找結果,并返回路由轉發表中相應的輸出端口號(entry[k].outport)。如果所有TCAMi中沒有匹配的前綴,前綴長度entry[i].length值為0,根據路由轉發表中默認的表項信息進行轉發。搜索算法的步驟如下:
Search(ip_addr)
(1) fori= 1 to ex
(2) entry[i] = match(TCAMi, ip_addr)
(3) endfor
(4) 對于滿足上述條件的路由表項entry[i](i∈{1,ex}), 根據LMP原則, 尋找k∈i, 使得entry[k]. length值最大
(5) return entry[k].outport
2.2.2 基于統計預測的預留表項空間算法
對于骨干網絡,路由表項前綴的統計特性變化較小。基于統計預測的預留表項空間算法根據高性能路由器的歷史表項數據,計算路由表項前綴的統計分布特性,進行預留表項空間的預測和分配,當有新的表項插入時,直接添加在預留空閑位置。算法步驟如下:
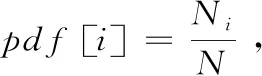
(2)計算長度為i的前綴的總預留空間大小n[i]=NTCAM×pdf[i];
(3)TCAMi中為長度為i的前綴預留大小為n[i]=NTCAM×pdf[i]/(max+1)的空間,路由表項動態更新時,新的路由表項直接插入預留空間內。
2.2.3 插入算法
路由轉發表中插入一個新的路由表項(前綴為p)的過程如下Insert(p)函數所示。首先,從TCAMi~TCAMmax中尋找出前綴p可以插入的所有TCAMi(i∈{1,max}),要求前綴p與TCAMi中的任意前綴互不相交;如果存在滿足上述條件的TCAMi,并且TCAMi中至少有一個空閑表項位置,標志變量available[i]值為true;否則,前綴p的預留空間被占用,available[i]值為false。如果available[i]值為true并且存在多個TCAMi,插入函數insert_to_tcam()從可用的TCAMi中隨機選擇一個插入位置;如果available[i]值為false,則TCAM0~TCAM6中不存在可用的空閑表項位置,前綴p插入傳統TCAMex。
insert_to_tcam()函數對傳統TCAMex的插入操作需要滿足傳統TCAM的順序約束,插入過程需要進行多次的內存移動;而TCAM1~TCAMmax中的路由表項無順序約束,因此對TCAM1~TCAMmax的插入操作可在任意空閑位置執行。
Insert(p)
(1) fori= 1 to max
(2) Initialize available[i] = false
(3) If(對于任意的前綴ep∈TCAMi,p和ep是不相交的, 并且TCAMi中有空余位置)
(4) available[i] = true
(5) endif
(6) endfor
(7) if(available[i] = false, 對于任意的0≤i≤max)
(8) insert_to_tcam(p, TCAMex)
(9) else
(10) 從available[i]中任意選取k, insert_to_tcam(p, TCAMk)
(11) endif
2.2.4 刪除算法
從轉發表中刪除前綴p的過程如下Delete(p)函數所示。首先,需要尋找哪個TCAM含有前綴p(假設為k);然后,前綴可從TCAMk中刪除。對于TCAM1~TCAMmax,刪除過程不需要任何內存移動。對于傳統TCAM,內存移動次數因更新算法的不同而有差異;如果相鄰位置是空閑的,每次刪除過程需要至少一次前綴移動操作。
Delete(p)
(1) 尋找k,使得p∈TCAMk
(2) delete_from(p, TCAMk)
3 實驗驗證與分析
為驗證本文提出算法的性能,搭建了測試驗證環境,如圖3所示,由T比特高性能路由器、Spirent網絡測試儀、以太網交換機、便攜式PC機等組成。其中網絡性能測試軟件使用Spirent公司的TestCenter STP-N11U,版本為v4.33.0086。
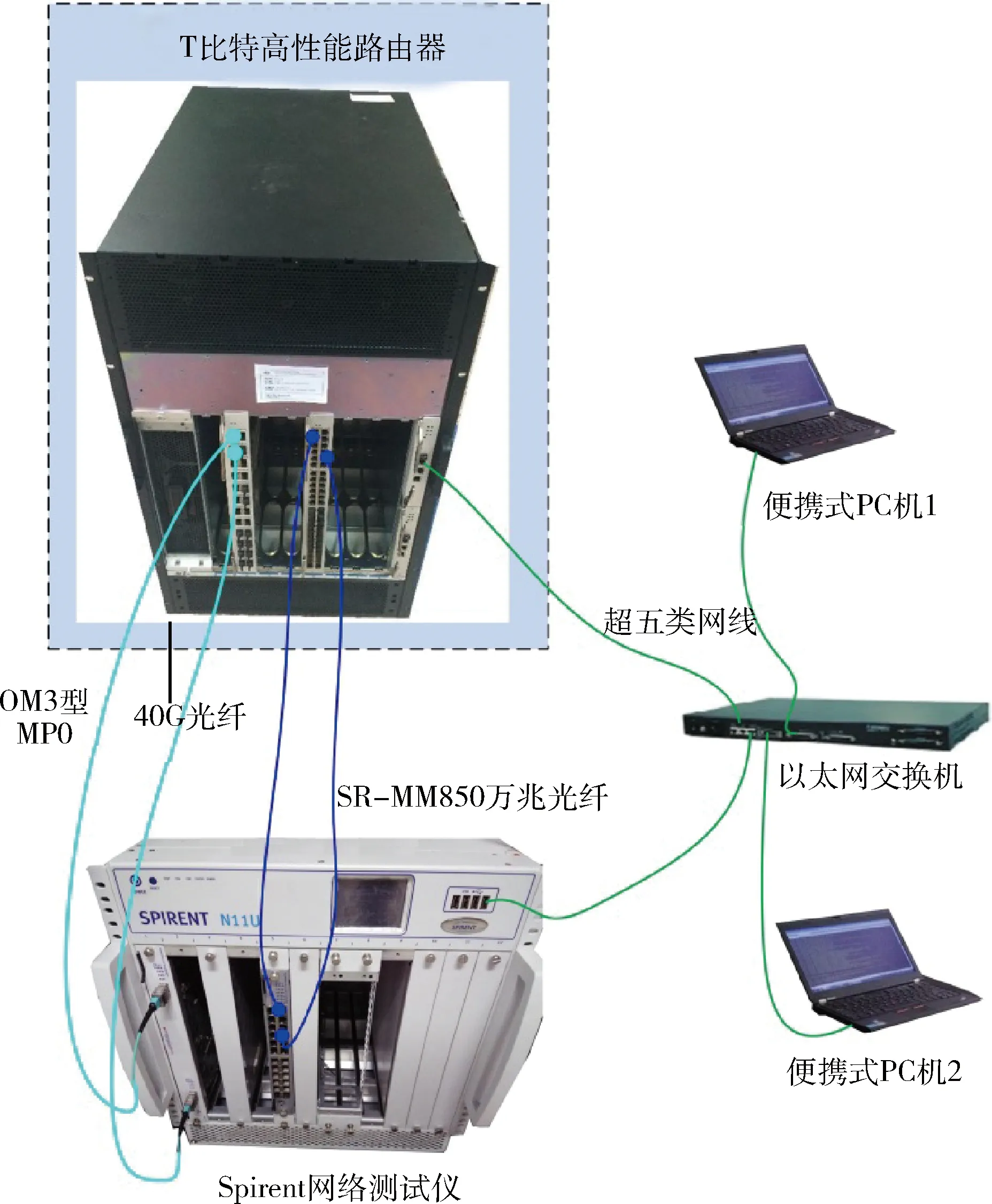
圖3 測試驗證環境
本文采用IPMA的MAE-WEST和MAE-EAST[11,12]路由表作為仿真數據來源,見表1。
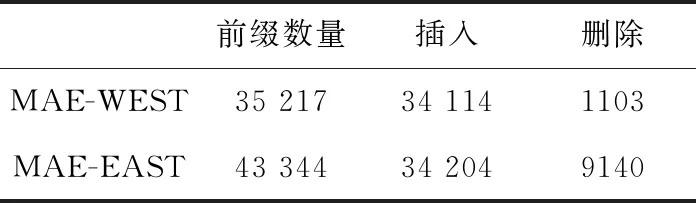
表1 仿真數據統計
圖4是數據1和數據2的前綴數量和內存移動次數關系,可以看出,96%的前綴只需要1次內存移動,僅有不到4%的前綴需要2次以上的內存移動。
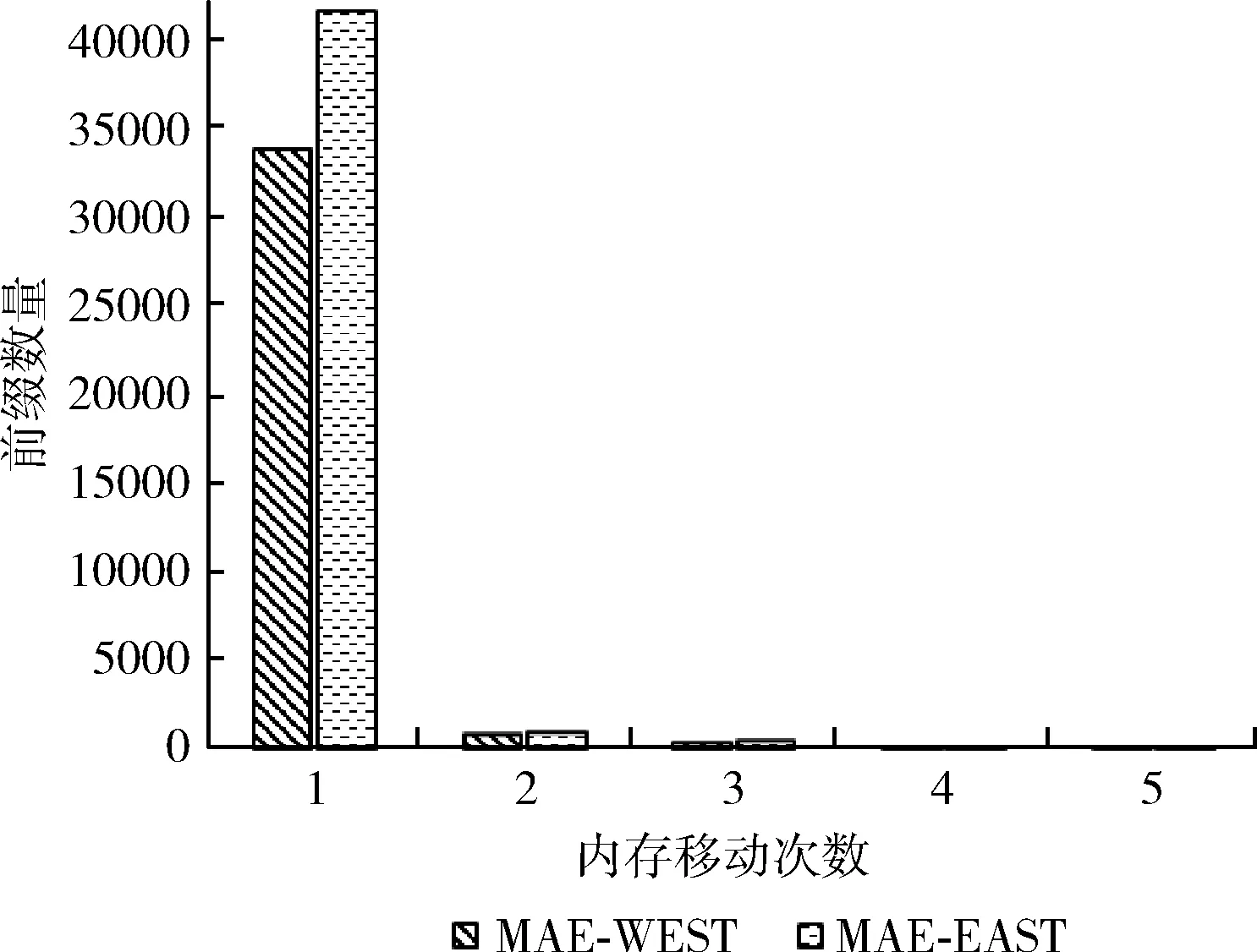
圖4 前綴數量和內存移動次數關系
分別采用本文提出的算法以及經典的PLO_OPT算法、CAO_OPT算法,計算MAE-WEST和MAE-EAST路由表每次更新操作(插入、刪除)的平均內存移動次數,結果見表2和表3。從對比結果可以看出,由于本文算法的路由表項沒有順序約束和優先級編碼器,并且進行了預留表項空間的設計,對于插入和刪除操作,本文算法的平均內存移動次數遠小于PLO_OPT算法和CAO_OPT算法。由于傳統TCAMex的存在,本文算法的插入操作和刪除操作所需的平均內存移動次數不相同。需要指出,該算法以計算概率密度函數為代價,通過減少內存移動次數降低了路由表項更新的時間復雜度, 但相比于頻繁的內存移動操作,概率密度函數的計算復雜度較小。

表2 不同算法每次更新操作的平均內存移動次數(MAE-WEST)

表3 不同算法每次更新操作的平均內存移動次數(MAE-EAST)
對采用本文提出的算法的T比特高性能路由器的轉發性能(吞吐量、時延)進行測試,測試中選用的數據包長分別為64、128、256、512、1024、1280、1518,測試時間為30 s,端口流量負載為100%,網絡的轉發方式選擇Full meshed全雙工對發。運行Spirent公司的TestCenter RF2544測試集,測試界面如圖5所示。
測試的T比特高性能路由器的吞吐量及時延分別如圖6、圖7所示。可以看出,在以上7種數據包大小時,路由器的測試吞吐量與理論最大吞吐量吻合,包大小為1518 bytes時可達最大80 Gbps的線速轉發,報文的丟包率為0。路由器的轉發時延最大為6.12 μs(包大小1518 bytes)。測試結果表明,本文提出的算法可有效提高T比特高性能路由器的線速查找轉發性能。
4 結束語
針對傳統TCAM查找更新方法時間復雜度高、效率低的問題,以及T比特路由器對高性能查找轉發的需求,本文提出了一種基于分組TCAM的路由查找更新架構,TCAM被分成幾組互不相交的路由表項的集合,路由表項不需要按優先級進行排序;提出了基于統計預測的預留表項空間算法,預留空間大小由前綴的概率密度函數確定,根據歷史表項數據分配相應的空間大小。搭建了測試驗證環境,測試結果表明,基于本文設計的TCAM的內存移動次數有效降低,T比特高性能路由器可達最大80 Gbps的線速轉發,轉發時延最大為6.12 μs。因此,本文提出的基于分組TCAM的T比特高性能路由器查找更新技術,可有效提高T比特路由器的查找轉發性能,支撐未來網絡發展的需要。

圖5 TestCenter測試界面
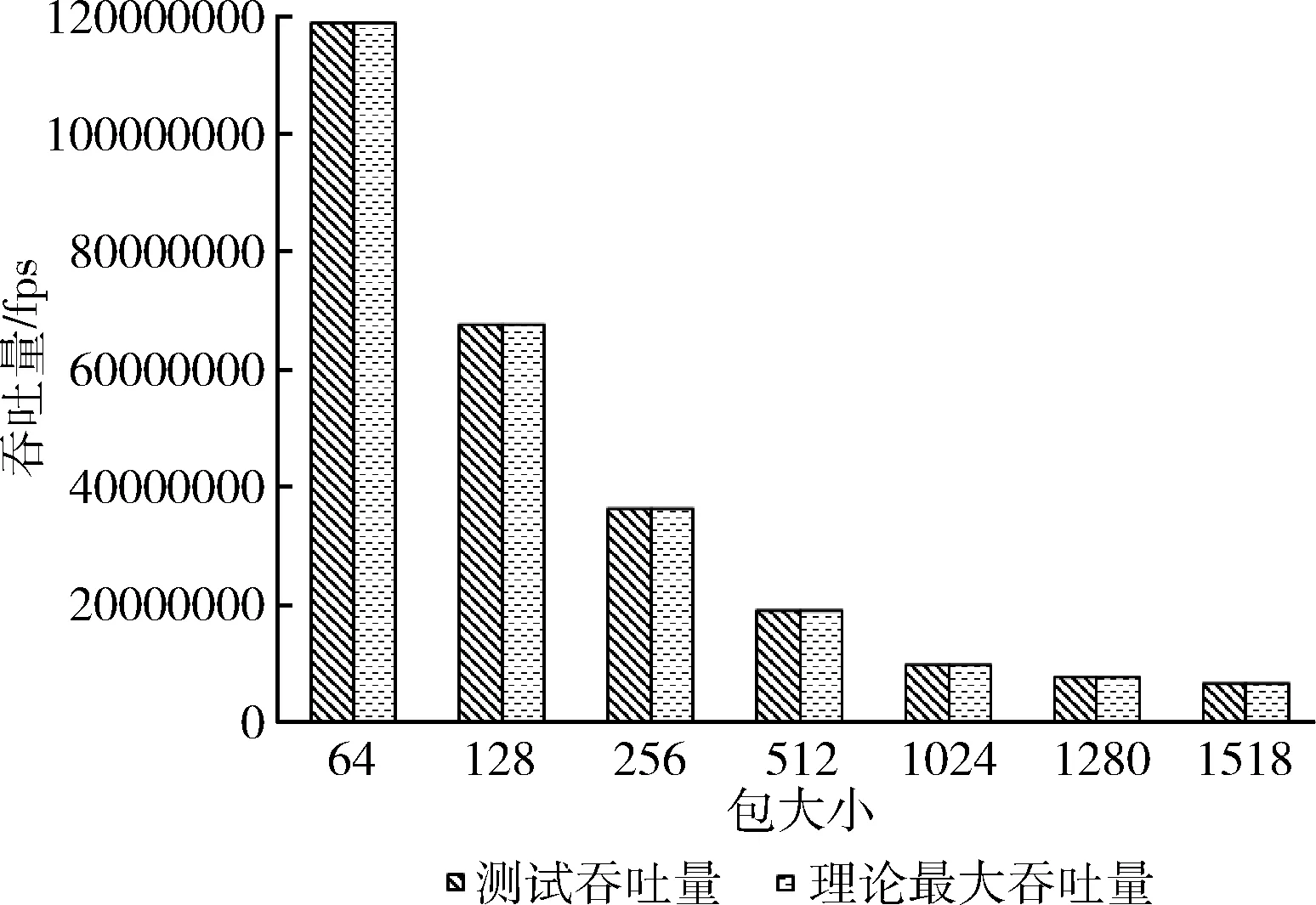
圖6 包轉發吞吐量測試比較
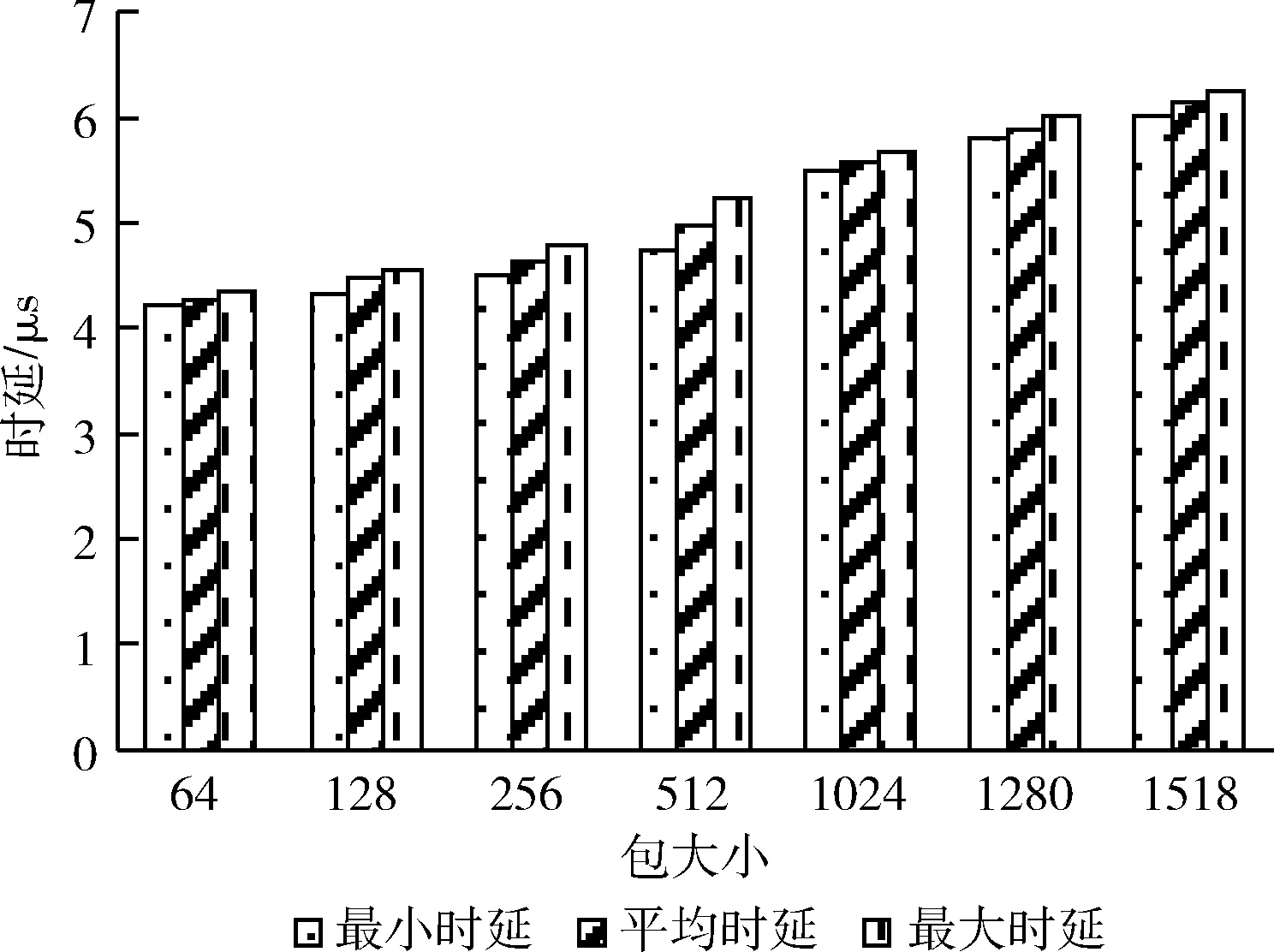
圖7 系統轉發時延比較
由于T比特路由器的動態變化特性,基于時變概率密度函數的預留表項空間算法是下一步的研究方向。
